金融数据---获取问财数据
整理需要利用第三方库pywencai
安装代码
pip install pywencai当然也可以利用清华安装
py -m pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pywencai前提需要安装node。执行js代码,下载地址
下载 | Node.jswww.nodejs.tech/zh-cn/download/current
https://www.nodejs.tech/zh-cn/download/current例子获取今天涨停数据
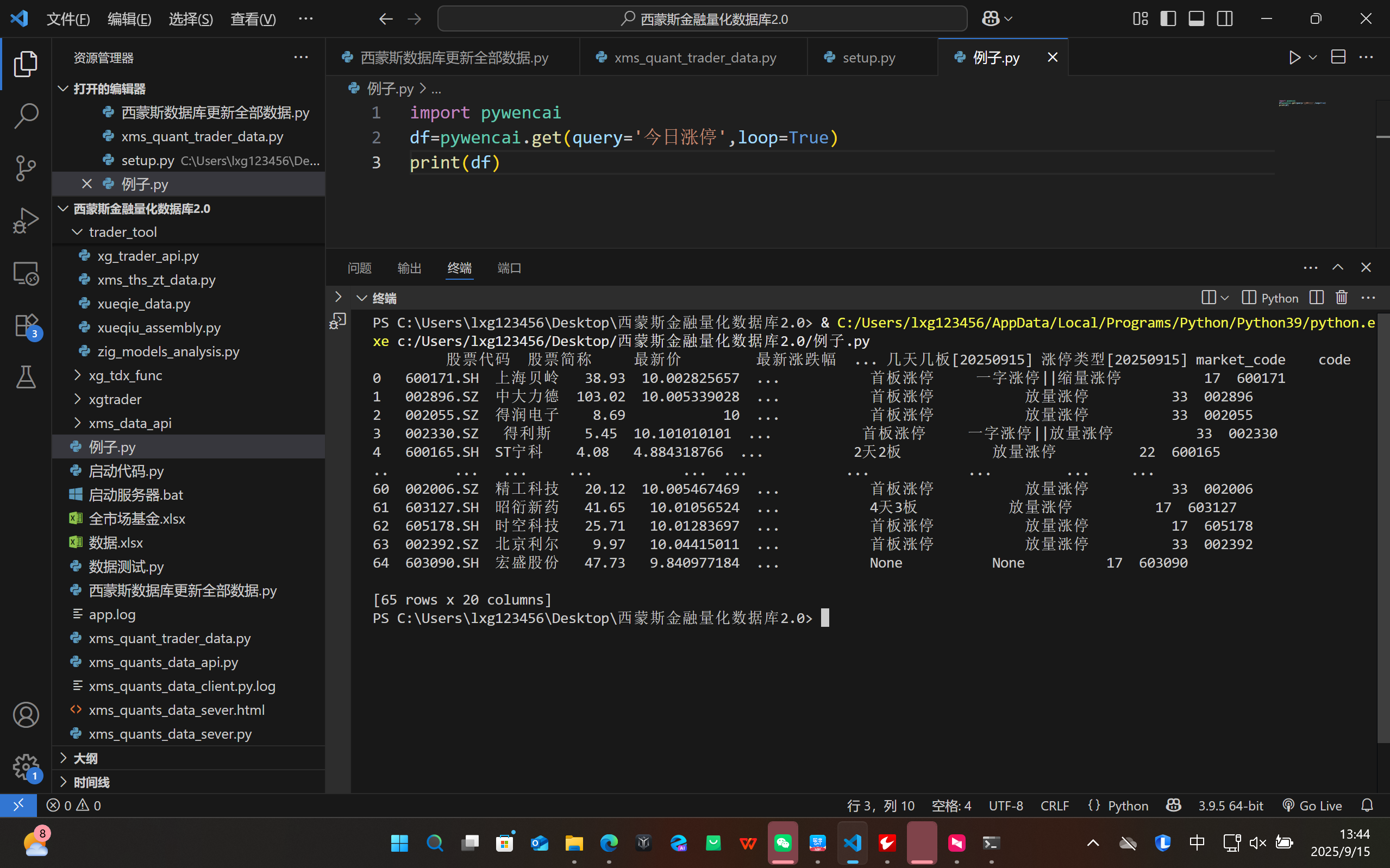
import pywencai
df=pywencai.get(query='今日涨停',loop=True)
print(df)获取的数据
股票代码 股票简称 最新价 最新涨跌幅 ... 几天几板[20250915] 涨停类型[20250915] market_code code
0 600171.SH 上海贝岭 38.93 10.002825657 ... 首板涨停 一字涨停||缩量涨停 17 600171
1 002896.SZ 中大力德 103.02 10.005339028 ... 首板涨停 放量涨停 33 002896
2 002055.SZ 得润电子 8.69 10 ... 首板涨停 放量涨停 33 002055
3 002330.SZ 得利斯 5.45 10.101010101 ... 首板涨停 一字涨停||放量涨停 33 002330
4 600165.SH ST宁科 4.08 4.884318766 ... 2天2板 放量涨停 22 600165
.. ... ... ... ... ... ... ... ... ...
60 002006.SZ 精工科技 20.12 10.005467469 ... 首板涨停 放量涨停 33 002006
61 603127.SH 昭衍新药 41.65 10.01056524 ... 4天3板 放量涨停 17 603127
62 605178.SH 时空科技 25.71 10.01283697 ... 首板涨停 放量涨停 17 605178
63 002392.SZ 北京利尔 9.97 10.04415011 ... 首板涨停 放量涨停 33 002392
64 603090.SH 宏盛股份 47.73 9.840977184 ... None None 17 603090[65 rows x 20 columns]
PS C:\Users\lxg123456\Desktop\西蒙斯金融量化数据库2.0>前提的参数
API
get(**kwargs)
根据问财语句查询结果参数
query
必填,查询问句老版本的question参数1.0版本以后会弃用,请以后统一使用query参数sort_key
非必填,指定用于排序的字段,值为返回结果的列名sort_order
非必填,排序规则,至为asc(升序)或desc(降序)page
非必填,查询的页号,默认为1perpage
非必填,每页数据条数,默认值100,由于问财做了数据限制,最大值为100,指定大于100的数值无效。loop
非必填,是否循环分页,返回多页合并数据。默认值为False,可以设置为True或具体数值。当设置为True时,程序会一直循环到最后一页,返回全部数据。当设置具体数值n时,循环请求n页,返回n页合并数据。query_type
非必填,默认为stock,当查询的类型不是股票的时候需要传,取值如下:取值 含义
stock 股票
zhishu 指数
fund 基金
hkstock 港股
usstock 美股
threeboard 新三板
conbond 可转债
insurance 保险
futures 期货
lccp 理财
foreign_exchange 外汇
retry
非必填,默认为10,表示请求失败后的重试次数。sleep
非必填,默认为0,表示循环请求时,每次请求间隔多少秒。log
非必填,默认为False,是否在控制台打印日志。pro
非必填,默认为False,付费版传True,必须传入cookie参数才能使用付费版cookie
必填,默认为Nonepywencai.get(question='近3个月每日市盈率', pro=True, cookie='xxxx')
cookie获取方法,复制请求头中的Cookie字段值cookierequest_params
非必填,默认为{},可以设置额外的request参数pywencai.get(query='昨日涨幅', sort_order='asc', loop=True, log=True, request_params={ 'proxies': proxies })
具体参数参看:https://requests.readthedocs.io/en/latest/api/#requests.requestno_detail
非必填,默认为False,当为True时,查询一些详情类问题不再会返回字典,而返回None,可以保证查询结果类型一直为pd.DataFrame或None。find
非必填,默认为None,可以传一个数组,例如['600519', '000010'],数组内的对应标的会排列在DataFrame的最前面。【注意】 1、该参数只有结果范围DataFrame时有效。2、配置该参数后,loop参数会失效,结果只会返回前100条。user_agent
非必填,默认为None,可以自己传user_agent,不使用随机的生成的user_agent返回值
当查询的是列表时,该方法返回一个pandas的Dataframe当查询的是详情时,该方法返回一个字典,字典中可能包含若干个文本和Dataframe