scikit-learn pipeline做数据预处理 模板参考
代码
pipeline制定每个字段预处理逻辑.
pipeline对训练数据进行预处理转换
pipeline对测试数据即新数据进行预处理转换
import pandas as pd
import numpy as np
from sklearn.pipeline import Pipeline
from sklearn.compose import ColumnTransformer
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import FunctionTransformer, StandardScaler, OneHotEncoder, OrdinalEncoder
from sklearn.preprocessing import KBinsDiscretizer# ====== 样例数据,增加分桶特征列和 LabelEncoder 类别列 ======
df_train = pd.DataFrame({"age": [25, 38, np.nan, 52, 41],"income": [8.5, 12.3, 5.1, np.nan, 10.2],"city": ["Beijing", "Shanghai", "Beijing", "Shenzhen", "Hangzhou"],"gender": ["M", "F", "F", "M", None],"signup_date": pd.to_datetime(["2023-01-05", "2022-11-17", "2023-03-01", "2021-08-20", "2022-12-31"]),"score": [56, 72, 45, 89, 77], # 连续变量,用来做“分桶”"education": ["Bachelors", "Masters", "HighSchool", "PhD", "Masters"] # 需要做 LabelEncoder 的列
})df_new = pd.DataFrame({"age": [33, 60],"income": [7.2, 20.0],"city": ["Nanjing", "Shanghai"], "gender": ["F", "F"],"signup_date": pd.to_datetime(["2024-02-10", "2020-07-15"]),"score": [65, 95],"education": ["PhD", "Unknown"] # “Unknown” 在训练中未见过
})# ====== 定义哪些列是哪类 ======
# 数值列
num_cols = ["age", "income"]
# 种类列
cat_cols = ["city", "gender"]
# 日期列
date_cols = ["signup_date"]
# 分桶列
bucket_cols = ["score"]
# 需labelEncoder列
label_encode_cols = ["education"]# ====== 自定义日期特征抽取 ======
def extract_date_parts(X: pd.DataFrame):return pd.DataFrame({"signup_year": X["signup_date"].dt.year,"signup_month": X["signup_date"].dt.month}, index=X.index)date_feat_names = ["signup_year", "signup_month"]# ====== 定义各类 transformer ======# 数值列处理
num_transformer = Pipeline([("imputer", SimpleImputer(strategy="mean")),("scaler", StandardScaler())
])# 类别列做 one-hot
cat_transformer = Pipeline([("imputer", SimpleImputer(strategy="most_frequent")),("onehot", OneHotEncoder(handle_unknown="ignore", sparse_output=False))
])# 日期列处理
date_transformer = Pipeline([("extract_date", FunctionTransformer(extract_date_parts, validate=False)),("imputer", SimpleImputer(strategy="most_frequent")),("scaler", StandardScaler())
])# 分桶变换:对 “score” 做分桶
bucket_transformer = Pipeline([# 可以先填缺失(如果有),这里假设无缺失("kbins", KBinsDiscretizer(n_bins=3, encode="ordinal", strategy="quantile")),# 如果想 one-hot 编码分桶结果,可以 encode="onehot" 或后面加 OneHotEncoder# 如 bucket_transformer = Pipeline([# ("kbins", KBinsDiscretizer(n_bins=3, encode="onehot", strategy="quantile"))# ])
])# LabelEncoder 类别列处理:注意 LabelEncoder 本身一般用于 y /目标或单列标签,不太适合直接 ColumnTransformer 多列
# 对 feature 列做类别编码一般用 OrdinalEncoder(适合可有新的类别设定 unknown)或 OneHot
# 这里用 OrdinalEncoder,并设置 handle_unknown 参数
from sklearn.preprocessing import OrdinalEncoderlabel_transformer = Pipeline([("imputer", SimpleImputer(strategy="most_frequent")),("ordinal", OrdinalEncoder(handle_unknown="use_encoded_value", unknown_value=-1))
])# ====== 组合 ColumnTransformer ======preprocessor = ColumnTransformer(transformers=[("num", num_transformer, num_cols),("cat", cat_transformer, cat_cols),("date", date_transformer, date_cols),("bucket", bucket_transformer, bucket_cols),("label_ed", label_transformer, label_encode_cols)],remainder="drop"
)# ====== Pipeline(只做预处理) ======preproc_pipeline = Pipeline([("preprocessor", preprocessor)
])# ====== 在训练数据上 fit + transform =====X_train_np = preproc_pipeline.fit_transform(df_train)
# 获取列名
num_names = num_cols
cat_names = preproc_pipeline.named_steps["preprocessor"].named_transformers_["cat"] \.named_steps["onehot"].get_feature_names_out(cat_cols).tolist()
date_names = date_feat_names
bucket_names = [f"score_bin" ] # 用 encode="ordinal" 时, 输出一列 bin 编号
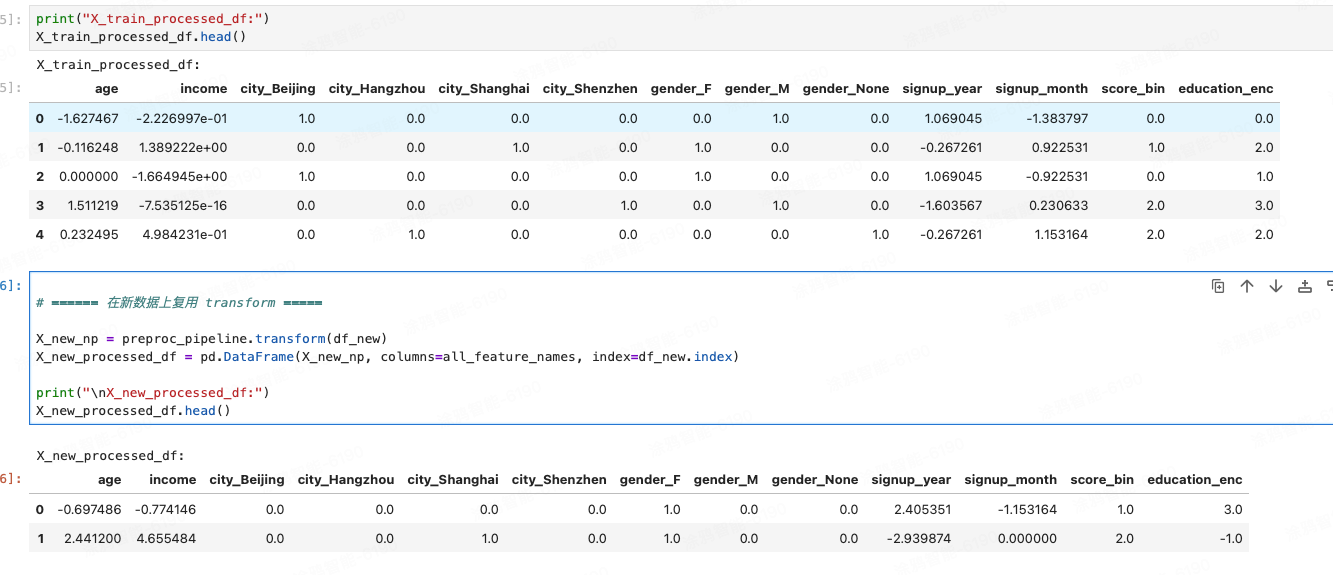
label_name = ["education_enc"] # ordinal 编码后名字all_feature_names = num_names + cat_names + date_names + bucket_names + label_nameX_train_processed_df = pd.DataFrame(X_train_np, columns=all_feature_names, index=df_train.index)print("X_train_processed_df:")
X_train_processed_df.head()# ====== 在新数据上复用 transform =====X_new_np = preproc_pipeline.transform(df_new)
X_new_processed_df = pd.DataFrame(X_new_np, columns=all_feature_names, index=df_new.index)print("\nX_new_processed_df:")
X_new_processed_df.head()输出
作用:
不需要每个字段labelEncoder等分别导出导入复用. 可以所有预处理放pipeline中,后续整体使用.