Java---线程池讲解
什么是线程池
假设小明是一个女生,小明目前有一个男朋友(假设为A),但是过了一段时间,小明想换一个男朋友。
这时她就需要完成两步:
1:和A分手
2:和下一个男生(假设为B)培养感情
不容忽视的是,以上两步都需要消耗一定的时间和精力。
那我们有什么办法可以提高一下效率呢?
比如小明可以在和A进行分手的这段时间里,就已经在和B培养感情了,这样只要和A分手之后,B就立即可以成为小明的男朋友了。
也就是只要感情培养到位,此时只要分手完毕,此时下一个小哥哥就可以上位了。(下一个小哥哥此时就成为是“备胎”)
由于小明对换男朋友的需求比较高,一个备胎可能不够用,需要同时和多个备胎聊天,此时这多个备胎就构成了“备胎池”。
在Java中,线程池的作用就是为了让我们可以高效地创建和销毁线程的。
那么有的同学可能就会问了,为什么我们直接创建线程的开销要比从线程中取线程的开销要大呢?
这里我们就要引入操作系统中的内核态和用户态这两个概念了~~~
内核态和用户态
在一个操作系统之中,一份内核是要个所有的应用程序提供服务和支持的。
下面我们用小明去银行办理业务来详细说明一下内核态和用户态
假设银行的柜员要小明出示一下身份证复印件,此时小明并没有复印件。
小明可以选择两个解决办法
1:交给柜员,让柜员去复印
2:去大厅中的自己复印机那里自己去复印
在上述过程中,柜员就相当于是内核,而柜台前的各个用户就相当于是一个个应用程序
我们接下来对这两个过程做一个比较:
前者的过程相对来讲是不可控的,因为柜员在给小明复印身份证之前,也有可能在处理别的事情。
而我们自己去复印,这个过程和前者相比是可控的。
对应到计算机中:
如果一段代码是在应用程序中完成的,那么我们就认为整个执行过程是可控的。
与之对应的是,如果一段代码的执行需要进入到内核当中,由内核负责完成一系列工作,我们通常认为这个过程是不可控的。
因此我们通常认为,可控的过程要比不可控的过程更高效。
由于线程池很重要,所以Java标准库中也提供了我们可以直接使用的线程池。接下来我们就来详细讲解一下。
Java标准库中的线程池讲解
ThreadPooleExecuter当中就准备好了一些线程。
它其中的核心方法是submit(Runnable),我们通过Runnable描述一段我们要执行的任务,然后我们借用submit方法把任务放到线程池当中,此时线程池里的线程就会执行任务。
这个类的构造方法中最多可以有七个参数,接下来我们就来讲一下这七个参数分别是啥意思。
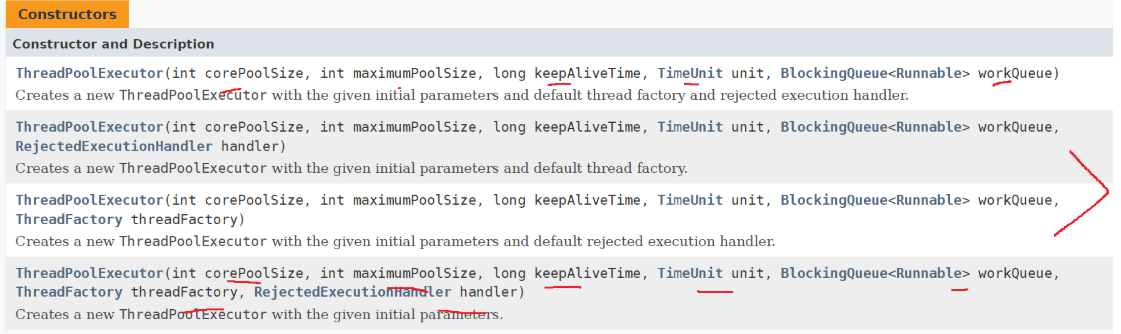
参数讲解
int corePoolsize:这表示核心线程数,即一个线程池一旦创建,这里面本身就包含一些线程,这些线程直到整个线程池销毁,它们才会销毁。
int maximumPoolsize:这表示最大线程数:这其中就包括了核心线程和非核心线程。
通过前面的学习我们知道,线程数量并不是越多越好。所以这些非核心线程在系统不繁忙的时候就销毁,系统繁忙的时候就再进行创建。
long keepAliveTime:这表示非核心线程允许空闲的最大时间。
Timeunit unit:上面的 keepAliveTime传入的是一个数值,但是具体是多长时间还并没有明确,这个类型的数据实际是一个枚举类型,比如秒,毫秒。
这两个参数加在一起就可以明确这个最大时间具体是多少了。
BlockingQueue<Runnable> workQueue
这就表示一个工作队列。
线程池本质上也是一个生产者消费者模型,我们调用submit就是在生产任务,而线程池里的线程就是在消费任务。生产和消费之间需要有一个队列来去传递数据,而这里的workQueue就起到了这样的作用。
ThreadFactory threadFactory
工厂模式就可以解决构造方法中的一些缺陷,我们先来看一下下面这段代码:
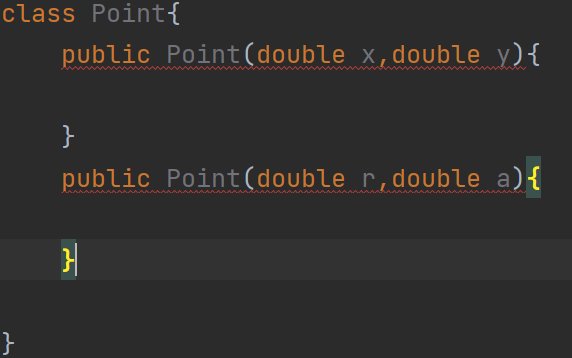
我们期望的是这两个构造方法可以构成“重载”,但是重载要求的是参数的个数或者参数的类型不同,为了解决这一缺陷,我们就引入了“工厂模式”。
下面我们着重来讲解一下工厂模式是如何解决这个缺陷的。
详解工厂模式
class Point{
}class Factory{public static Point makePointBYXY(double x,double y){Point P=new Point();
// 通过x和y对P进行属性设置return P;}public static Point makePointBYRA(double r,double a){Point P=new Point();
// 通过r和a对P进行属性设置return P;}
}public class Demo4 {public static void main(String[] args) {Point p=Factory.makePointBYRA(10,20);}
}代码如上所示,这其中的makePointBYXY 和makePointBYRA就称为工厂方法,提供工厂方法的类就可以称之为“工厂类”。
工厂方法的核心就是通过静态方法,把构造对象new初始化的过程给封装起来,但是它可以提供多组静态方法,从而实现不同情况的构造。
这个Java标准库中提供的工厂模式就是为了便于我们对线程进行统一的构造和初始化。
RejectedExecutionHandler handler 拒绝策略
由于我们的submit是把要执行的任务添加到任务队列当中,而我们这里的任务队列是一个阻塞队列,当队列满的时候,再向其中添加元素,正常来讲会进行“阻塞等待”。
但在线程池当中,发现当入队操作无法执行(也就是队列已经满了的时候)并不会真的进行“阻塞等待”,而是会执行拒绝策略相关的代码。
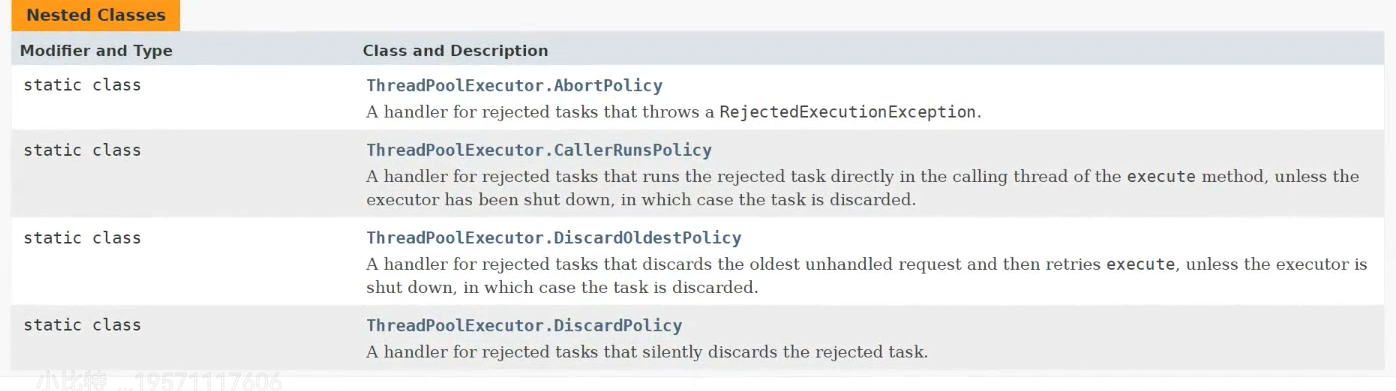
具体一共有四种处理办法:下面我们来对这四种办法做一个较为详细的解释。ThreadPoolExecutor.AbortPolicy
这个处理办法会让线程池直接抛出异常(有可能会让线程池无法正常工作)
ThreadPoolExecutor.CallerRunsPolicy
这会让调用submit的线程自行执行任务
ThreadPoolExecutor.DiscardOldestPolicy
这会丢弃原先队列中最老的任务
ThreadPoolExecutor.DiscardPolicy
这会丢弃最新的任务,也就是当前submit的这个任务
Java标准库中也提供了另一组类,针对ThreadPoolExecutor进行了进一步地封装,用来简化线程池的使用。接下来我们就来讲一下Executors类。
Executors
这个类中提供了不同的静态方法,以便我们可以创建不同的线程
newFixedThreadPool方法创建的是固定线程数量的线程池,即核心线程数和最大线程数一致。
newCachedThreadPool方法所创建线程池其中的最大线程数是一个很大的数字。
下面我们用代码来演示一下。
public static void main(String[] args) {ExecutorService executorService =Executors.newFixedThreadPool(4);ExecutorService executorService2 =Executors.newCachedThreadPool();for (int i = 0; i < 1000; i++) {int id=i;executorService.submit(()->{System.out.println("hello "+ id +","+Thread.currentThread().getName());});}} 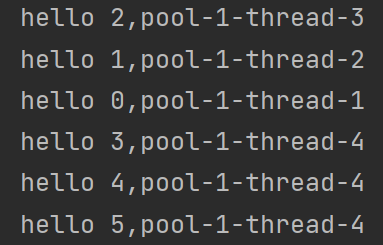
上述代码的运行结果如上,id的数值是乱序的原因如下:
上述循环过程是循环往线程池中去添加任务,这个线程池中共有4个线程,比如第一个线程拿到的id为0,但是当他还没有执行到输出语句的时候,系统就有可能调度执行其他的线程了。
简言之就是:线程之间是抢占式执行的 有可能执行到一半 就切换到其它线程执行了。
总结
其实线程池的核心思路特别简单:提前备好 线程,要用的时候直接拿,不用再重新创建,用完也不立马销毁,而是放回池里下次再用。
这样既避免了频繁创建 / 销毁线程的高开销,又能高效处理大量任务。