【论文笔记】Self-Supervised Point Cloud Prediction for Autonomous Driving
原文链接:https://ieeexplore.ieee.org/abstract/document/10571593
0. 概述
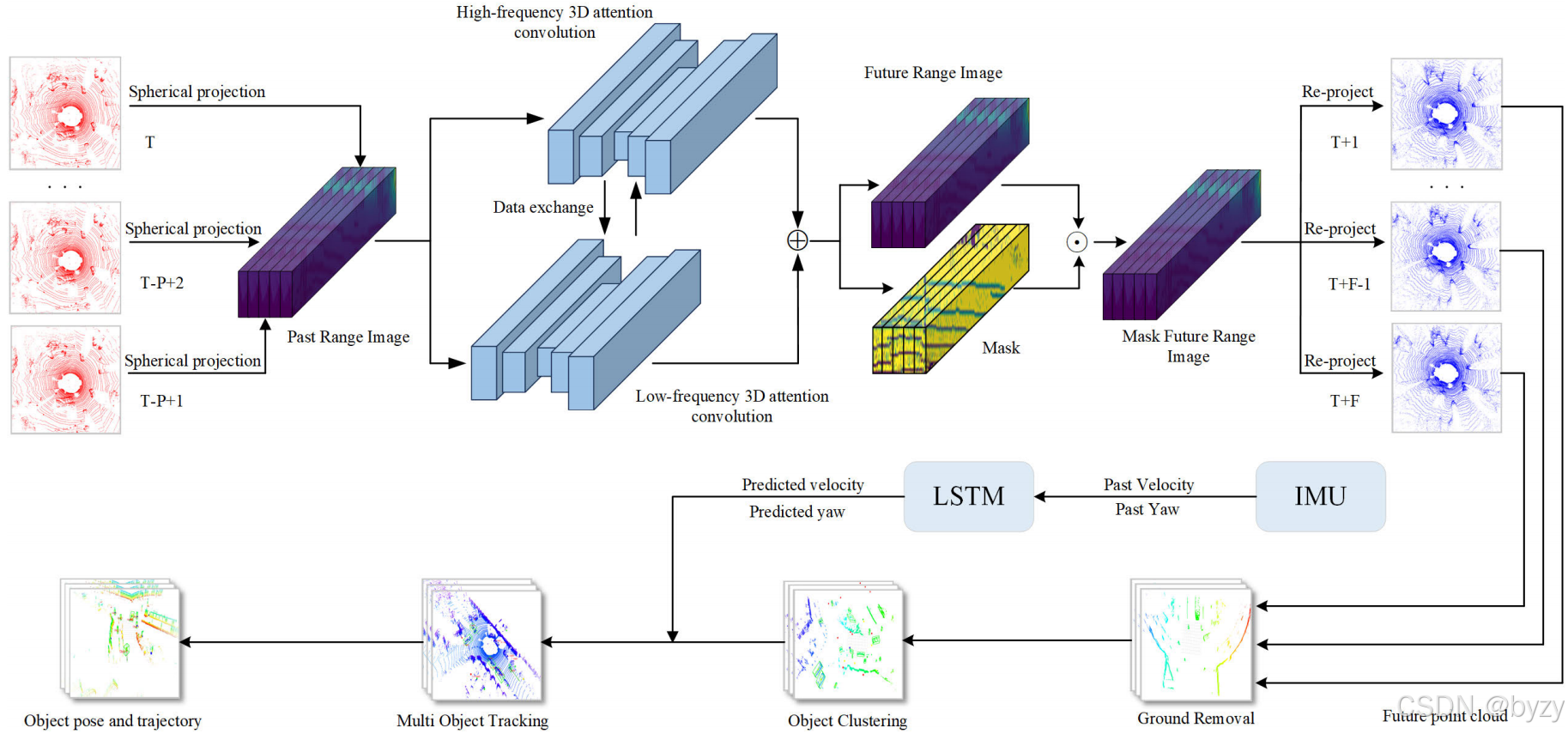
本文的目标是进行自监督3D点云预测,以及多目标检测和跟踪。给定过去帧的点云序列,首要目标是预测将来的点云序列,同时在预测的点云上进行目标检测与跟踪任务。
首先将激光雷达点云投影为距离图像,并合并为3D时空张量,输入编码器-解码器结构中。该结构包含TCNet,3D八度卷积,和3D动作注意力模块,用于提取不同时间范围内的时空信息。输出为预测的距离图像,并进一步转化为3D点云。最后,对预测点云进行聚类和跟踪。
1. 点云到距离图像的投影和反投影
给定点p=(x,y,z)p=(x,y,z)p=(x,y,z),其在距离图像上的坐标为(u,v)(u,v)(u,v):
(u,v)=(12[1−arctan(y/x)π]W,[1−arcsin(z/r)+fupf]H)(u,v)=(\frac12[1-\frac{\arctan(y/x)}\pi]W,[1-\frac{\arcsin(z/r)+f_{up}}f]H)(u,v)=(21[1−πarctan(y/x)]W,[1−farcsin(z/r)+fup]H)
其中(H,W)(H,W)(H,W)为距离图像的分辨率,f=fup+∣fdown∣f=f_{up}+|f_{down}|f=fup+∣fdown∣为激光雷达的垂直视角范围。r=∥p∥2r=\|p\|_2r=∥p∥2为距离。若多个点投影到相同像素,则反投影时只保留最近点。
2. TSMNet
2.1 3D动作注意力
3D动作注意力包含3个子模块:时空刺激(STE)模块,通道刺激(CE)模块和运动刺激(ME)模块。设输入为X∈RN×T×C×H×WX\in\mathbb R^{N\times T\times C\times H\times W}X∈RN×T×C×H×W:
- STE模块进行在通道维度进行均值池化并通过T,H,WT,H,WT,H,W维度的3D卷积得到XS∈RN×T×1×H×WX_S\in\mathbb R^{N\times T\times 1\times H\times W}XS∈RN×T×1×H×W,随后进行Sigmoid得到时空注意力图MSM_SMS,最后
YS=X+X⊙MSY_S=X+X\odot M_SYS=X+X⊙MS - CE模块沿H,WH,WH,W维度进行均值池化,并通过一组卷积得到XC∈RN×T×C×1×1X_C\in\mathbb R^{N\times T\times C\times 1\times 1}XC∈RN×T×C×1×1,随后进行Sigmoid得到通道注意力图MCM_CMC,最后
YC=X+X⊙MCY_C=X+X\odot M_CYC=X+X⊙MC - ME模块压缩通道维度得到XM∈RN×T×C′×H×WX_M\in\mathbb R^{N\times T\times C'\times H\times W}XM∈RN×T×C′×H×W后,通过2D卷积得到XM∗X^*_MXM∗。把XMX_MXM与XM∗X^*_MXM∗的过去T−1T-1T−1帧距离图像取出并相减,并与全0图像(对应当前帧)拼接,得到XME∗∗∈RN×T×C′×H×WX^{**}_{ME}\in\mathbb R^{N\times T\times C'\times H\times W}XME∗∗∈RN×T×C′×H×W。通过池化、卷积和Sigmoid函数后,得到运动注意力图MM∈RN×T×C×1×1M_M\in\mathbb R^{N\times T\times C\times 1\times 1}MM∈RN×T×C×1×1。最后
YM=X+X⊙MMY_M=X+X\odot M_MYM=X+X⊙MM - 最后将子模块的输出求和并通过3D卷积,得到Y∈RN×T×C×H×WY\in\mathbb R^{N\times T\times C\times H\times W}Y∈RN×T×C×H×W。
2.2 3D八度卷积

3D八度卷积的通道包括低频通道与高频通道。低频通道占比α\alphaα,图像尺寸仅有高频通道的一半;高低频通道之间通过上下采样进行信息交互,如上图图所示。
2.3 编码器-解码器
本文从PPP帧过去点云的距离图像预测FFF帧未来点云的距离图像,即输入特征大小为(N,1,P,H,W)(N,1,P,H,W)(N,1,P,H,W),通道数为1,NNN为batch size。
编码器(由TCNet,3D八度卷积和3D动作注意力模块组成)以上述特征为输入。首先通过3D八度卷积(如2.2节图),之后3D动作注意力模块分别处理高频和低频特征,得到大小为(N,(1−α)C,P−t,Hh,Ww)(N,(1-\alpha)C,P-t,\frac Hh,\frac Ww)(N,(1−α)C,P−t,hH,wW)的高频下采样特征和大小为(N,αC,P−t,H2h,W2w)(N,\alpha C,P-t,\frac H{2h},\frac W{2w})(N,αC,P−t,2hH,2wW)的低频下采样特征(ttt为减小的时间维数)。
解码器与编码器结构成镜像,将编码器输出的特征上采样特征到(N,2,F,H,W)(N,2,F,H,W)(N,2,F,H,W)。第一个通道表示距离,第二个通道表示点有效的可能性,仅该值大于0.5的点才会被保留。
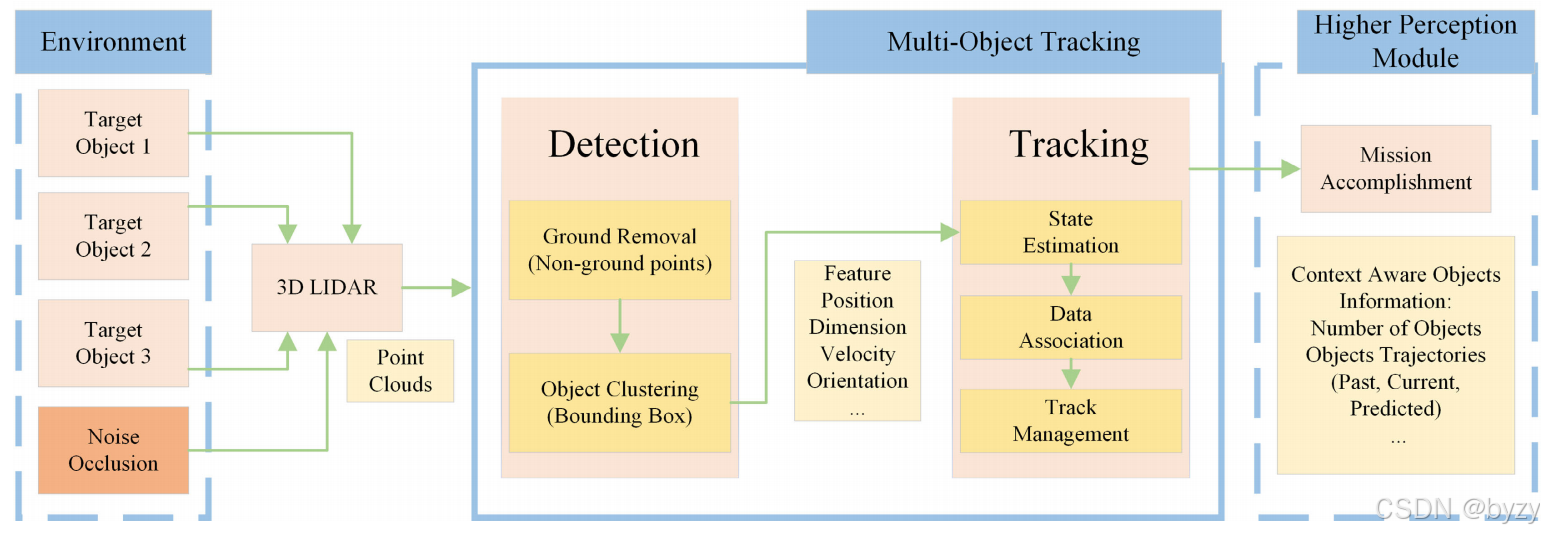
3. 点云聚类和跟踪
首先移除地面点,随后进行聚类,得到聚类物体,最后进行跟踪得到物体的未来姿态和3D轨迹。
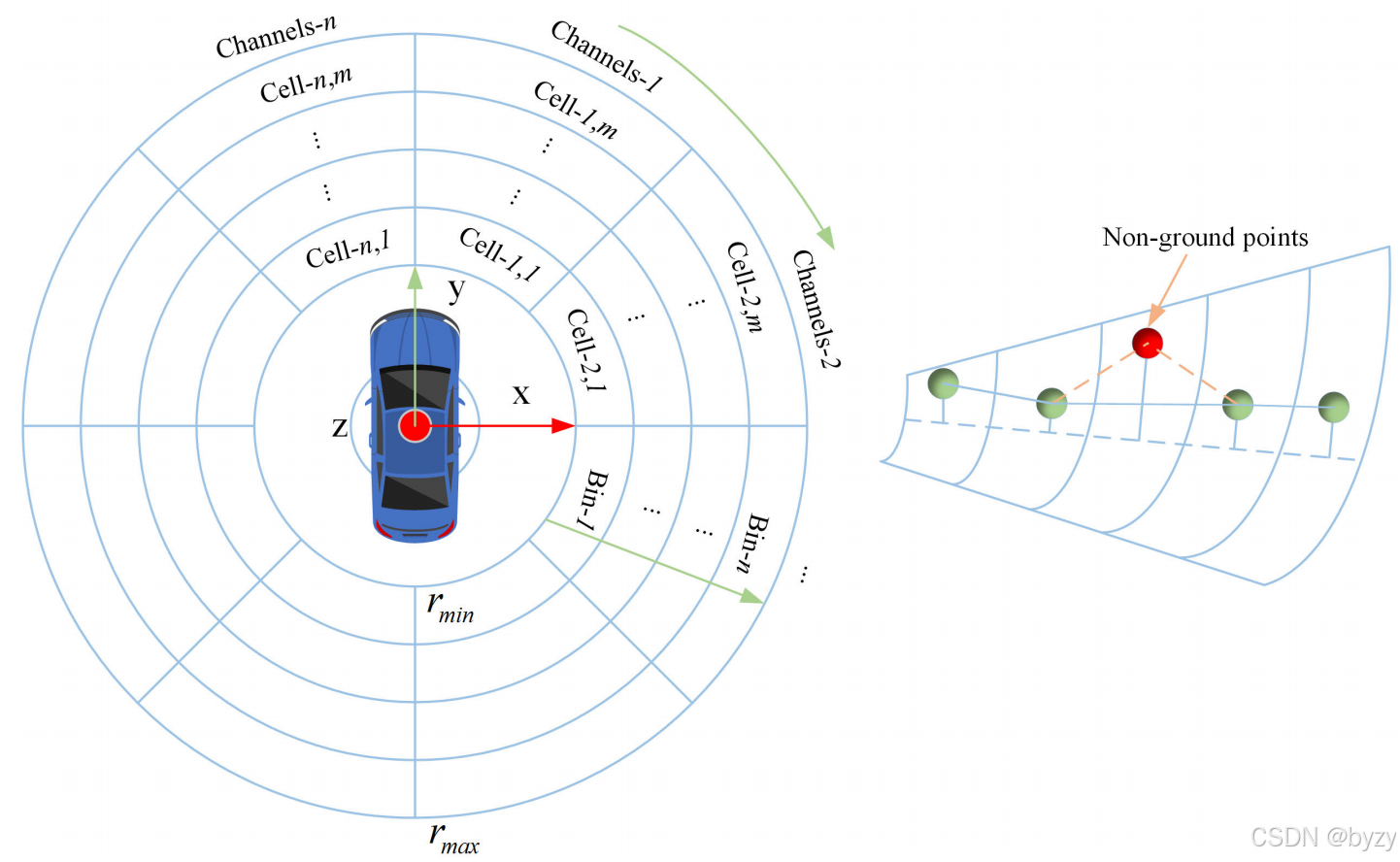
使用基于斜率的通道分类方法识别地面点:
channels(pi)=arctan(yi/xi)2π,bin(pi)=xi2+yi2−rmin2πchannels(p_i)=\frac{\arctan(y_i/x_i)}{2\pi}, bin(p_i)=\frac{\sqrt{x_i^2+y_i^2}-r_{\min}}{2\pi}channels(pi)=2πarctan(yi/xi),bin(pi)=2πxi2+yi2−rmin
其中rminr_{\min}rmin为来自自车的点不可见的半径,rmaxr_{\max}rmax为传感器有效范围。如下图所示,激光雷达点pi=(xi,yi,zi,Ii)p_i=(x_i,y_i,z_i,I_i)pi=(xi,yi,zi,Ii)被划分到不同极坐标网格内。地面高度范围[Thmin,Thmax][T_{h\min},T_{h\max}][Thmin,Thmax]由网格的局部最低点确定;根据相邻网格局部最低点之间的斜率是否超过斜率阈值TslopeT_{slope}Tslope,以及网格内局部最低点与其它点的高度差是否超过阈值ThT_hTh,可识别地面点。进一步通过连续性检查和中值过滤优化地面估计。
使用基于连通域的方法对非地面点进行聚类。首先将点转化为二值占用网格,选择其中一个网格作为中心网格,并检查所有邻域网格,分配相同的聚类ID。重复这一步骤,直到所有占用网格均有聚类ID。
使用基于IMM-UKF-JPDAF(交互式多模型-无迹卡尔曼滤波-联合概率数据关联滤波器)的方法进行跟踪;最后利用LSTM预测的车辆速度和朝向对跟踪目标进行轨迹管理。