MySQL数据库(四)—— 使用MyCat实现MySQL主从读写分离实战指南
文章目录
- 前言
- 一、MySQL读写分离概述
- 1.1 工作原理
- 1.2 为什么要读写分离
- 1.3 实现方式
- 1.3.1 应用程序层实现
- 1.3.2 中间件层实现
- 二、什么是MyCat
- 三、MyCat安装与配置
- 3.1 环境准备
- 3.2 下载与解压
- 3.3 创建专用用户
- 3.4 目录结构说明
- 3.5 Java环境配置(也可以使用openJDK)
- 四、MyCat核心配置实战
- 4.1 环境变量配置
- 4.2 主机名解析配置
- 4.3 核心配置文件详解
- 4.3.1 用户权限配置(server.xml)
- 4.3.2 逻辑库与数据分片配置(schema.xml)
- 4.3.3 关键参数解析
- 4.3.4 其他参数解析
- 4.4 启动MyCat服务
- 五、MySQL主从环境搭建
- 5.1 主库配置(192.168.10.110)
- 5.2 从库配置(192.168.10.120/123)
- 六、读写分离效果验证
- 6.1 测试环境准备
- 6.2 读写分离验证步骤
- 总结
前言
在现代高并发数据库应用场景中,单台MySQL服务器往往难以应对读写混合的压力。读写分离技术通过将数据库的写操作和读操作分配到不同的服务器节点,能有效提升系统性能和可用性。
MyCat作为开源的数据库中间件,提供了简单高效的读写分离解决方案。本文将详细介绍如何使用MyCat实现MySQL主从读写分离,包含完整的实验步骤和配置详解。
一、MySQL读写分离概述
1.1 工作原理
MySQL读写分离的核心思想是将数据库操作分为两类:
- 主库(Master):专门处理写操作(
INSERT、UPDATE、DELETE) - 从库(Slave):专门处理读操作(
SELECT) - 数据同步机制:主库通过二进制日志将数据变更同步到从库
数据流转过程:主库写入 → 二进制日志 → 从库读取并应用变更 → 从库数据与主库保持一致
1.2 为什么要读写分离
- 性能瓶颈突破:单台服务器性能有限,分担负载提升整体吞吐量
- 锁争用缓解:主库处理写操作(X锁),从库处理读操作(S锁),减少锁冲突
- 存储引擎优化:从库可使用MyISAM引擎(查询性能更优),主库使用InnoDB(保证事务安全)
- 高可用保障:主从架构提供冗余,主库故障时可快速切换到从库
1.3 实现方式
1.3.1 应用程序层实现
- 优点:部署简单,适用于中等压力系统
- 缺点:代码耦合度高,不支持高级功能,大型系统不适用
1.3.2 中间件层实现
- 优点:架构灵活,支持透明分库分表,提供故障转移和监控
- 常用中间件:
- MyCat(社区活跃,本文重点)
- Cobar(阿里开源,已停更)
- OneProxy(商业收费,高并发稳定)
- Vitess(YouTube使用,架构复杂)
- Kingshard/Atlas/MaxScale等
- Amoeba(轻量级,配置简单,专注于读写分离和负载均衡)
二、什么是MyCat
MyCat是开源的企业级数据库中间件,核心特性包括:
- 支持完整ACID事务
- 可替代MySQL集群或Oracle集群
- 融合内存缓存、NoSQL、HDFS等大数据技术
- 核心功能:分库分表、读写分离、故障切换
三、MyCat安装与配置
3.1 环境准备
- Master服务器:192.168.10.110 mysql5.7
- Slave1服务器:192.168.10.120 mysql5.7
- Slave2服务器:192.168.10.123 mysql5.7
- 客户端服务器:192.168.10.119 测试
3.2 下载与解压
# 官方下载地址(备用)
wget https://github.com/MyCATApache/Mycat-download/blob/master/1.6-RELEASE/Mycat-server-1.6-RELEASE-20161028204710-linux.tar.gz# 解压到安装目录
tar -xf Mycat-server-1.6-RELEASE-*.tar.gz -C /usr/local/
cd /usr/local/mycat

3.3 创建专用用户
useradd mycat
passwd mycat # 设置密码
chown -R mycat.mycat /usr/local/mycat # 授权
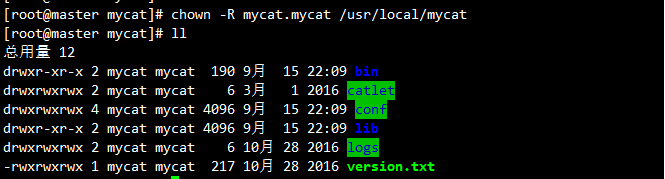
3.4 目录结构说明
bin/:可执行文件和 shell 脚本conf/:配置文件server.xml:服务器参数、用户授权schema.xml:逻辑库和数据分片配置rule.xml:分片规则
lib/:依赖 JAR 文件logs/:日志文件(配置在log4j.xml)
3.5 Java环境配置(也可以使用openJDK)
# 安装JDK 1.8+
tar xf jdk-8u191-linux-x64.tar.gz -C /usr/java/# 配置环境变量
echo 'export JAVA_HOME=/usr/java/jdk1.8.0_191' > /etc/profile.d/java.sh
echo 'export PATH=$JAVA_HOME/bin:$PATH' >> /etc/profile.d/java.sh
echo 'export CLASSPATH=$JAVA_HOME/jre/lib/ext:$JAVA_HOME/lib/tools.jar' >> /etc/profile.d/java.sh# 生效配置
source /etc/profile.d/java.sh
java -version # 验证安装
四、MyCat核心配置实战
4.1 环境变量配置
# 创建MyCat环境变量
vim /etc/profile.d/mycat.sh
==============================================================
#!/bin/bash
export MYCAT_HOME=/usr/local/mycat
export PATH=$MYCAT_HOME/bin:$PATH
==============================================================# 生效配置
source /etc/profile.d/mycat.sh

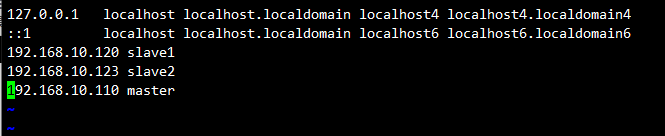
4.2 主机名解析配置
# 编辑/etc/hosts添加集群节点
192.168.10.120 slave1
192.168.10.123 slave2
192.168.10.110 master
4.3 核心配置文件详解
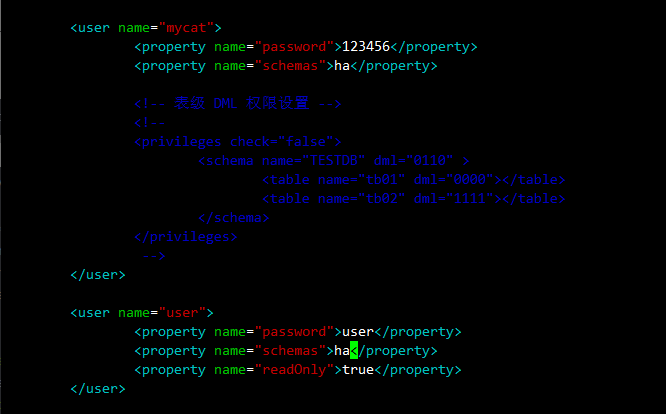
4.3.1 用户权限配置(server.xml)
vim /usr/local/mycat/conf/server.xml
<!-- 管理用户,具有读写权限 -->
<user name="mycat"><property name="password">123456</property><property name="schemas">ha</property><!-- 表级 DML 权限设置 --><!-- <privileges check="false"><schema name="TESTDB" dml="0110" ><table name="tb01" dml="0000"></table><table name="tb02" dml="1111"></table></schema></privileges> --></user><user name="user"><property name="password">user</property><property name="schemas">ha</property><property name="readOnly">true</property></user>
4.3.2 逻辑库与数据分片配置(schema.xml)
首先,进行备份:
mv /usr/local/mycat/conf/schema.xml /usr/local/mycat/conf/schema.xml.bak
vim /usr/local/mycat/conf/schema.xml
# 直接复制(一主一从)
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://org.opencloudb/">
<schema name="ha" checkSQLschema="false" sqlMaxLimit="100" dataNode='dn1'>
</schema>
<dataNode name="dn1" dataHost="dthost" database="ha"/>
<dataHost name="dthost" maxCon="500" minCon="10" balance="1" writeType="0" dbType="mysql" dbDriver="native" switchType=" -1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="master" url="192.168.10.110:3306" user="mycat" password="123456">
</writeHost>
<writeHost host="slave1" url="192.168.10.120:3306" user="mycat" password="123456" />
</dataHost>
</mycat:schema>==============================================================================# 一主两从
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/"><!-- 定义逻辑库 schema --><schema name="ha" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1"></schema><!-- 数据节点 --><dataNode name="dn1" dataHost="dthost" database="ha"/><!-- 数据主机组 --><dataHost name="dthost" maxCon="500" minCon="10" balance="1" writeType="0" dbType="mysql" dbDriver="native" switchType="-1" slaveThreshold="100"><!-- 心跳语句 --><heartbeat>select 1</heartbeat><!-- 主库 (写) --><writeHost host="master" url="192.168.10.110:3306" user="mycat" password="123456"><!-- 从库 (读) --><readHost host="slave1" url="192.168.10.120:3306" user="mycat" password="123456"/><readHost host="slave2" url="192.168.10.123:3306" user="mycat" password="123456"/></writeHost></dataHost>
</mycat:schema>
4.3.3 关键参数解析
-
balance(读负载均衡策略)
0:不开启读写分离1:所有读节点参与负载均衡(推荐)2:随机分配读请求3:读请求只分发给从节点
-
writeType(写节点策略)
0:写操作只发往第一个writeHost1:写操作随机分配(已废弃)
-
switchType(故障切换策略)
-1:不自动切换1:自动切换(默认)2:基于MySQL主从状态切换3:基于Galera Cluster切换
4.3.4 其他参数解析
-
Mycat schema 配置的 XML 根节点
<mycat:schema xmlns:mycat="http://org.opencloudb/"> -
schema 节点
<schema name="ha" checkSQLschema="false" sqlMaxLimit="100" dataNode='dn1'> </schema># name="ha":定义 schema 名称为 ha,客户端通过 use ha 来访问。 ## checkSQLschema="false":关闭 SQL schema 检查,加快解析。 ### sqlMaxLimit="100":单条 SQL 返回最大 100 行。 #### dataNode='dn1':指定使用的数据节点为 dn1。 -
dataNode 节点
<dataNode name="dn1" dataHost="dthost" database="ha"/>#name="dn1":定义数据节点的名字,这个名字需要是唯一的。##dataHost="dthost":绑定到名为 dthost 的 dataHost。 (该属性用于定义该分片属于哪个数据库实例)###database="ha":访问的物理数据库名为 ha。 (该属性用于定义该分片属性哪个具体数据库实例上的具体库) -
dataHost 节点
<dataHost name="dthost" maxCon="500" minCon="10" balance="1" writeType="0" dbType="mysql" dbDriver="native" switchType="-1" slaveThreshold="100">maxCon / minCon:连接池最大/最小连接数。balance="1":负载均衡策略,1 表示轮询。writeType="0":写策略,只写到第一个可用节点。dbType="mysql":数据库类型 MySQL。dbDriver="native":使用原生驱动。switchType="-1":切换策略,-1 表示自动。slaveThreshold="100":从库延迟阈值(行数或毫秒,取决于版本) -
心跳检测
<heartbeat>select user()</heartbeat> #用来检测数据库连接是否活跃 -
writeHost 节点
<writeHost host="slave1" url="192.168.10.120:3306" user="mycat" password="123456"/> <writeHost host="slave2" url="192.168.10.123:3306" user="mycat" password="123456"/>配置两个写节点(主库)。writeType="0" 表示只写第一个 writeHost(slave1)。第二个 writeHost 在此配置下不会被写入使用。
数据流向 schema → dataNode → dataHost → writeHost 的结构,
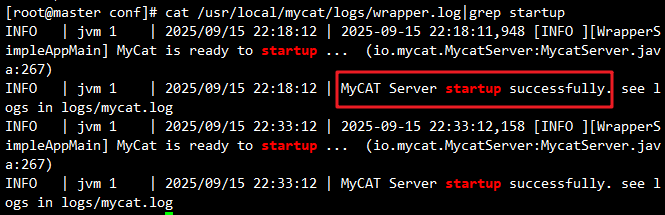
4.4 启动MyCat服务
# 切换到MyCat安装目录
cd /usr/local/mycat/bin# 启动服务
./mycat start# 查看启动日志
cat /usr/local/mycat/logs/wrapper.log
启动成功标志:日志中出现MyCAT Server startup successfully信息
五、MySQL主从环境搭建
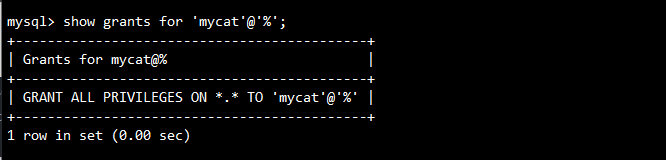
5.1 主库配置(192.168.10.110)
-- 创建MyCat连接账号并赋权
grant all privileges on *.* to 'mycat'@'%' identified by '123456';
flush privileges;
5.2 从库配置(192.168.10.120/123)
参考MySQL数据库(三)—— MySQL主从复制实战指南 与 读写分离原理讲解,将主从复制配置完毕。
# 配置好主从复制的基础上直接为mycat用户赋权
grant all privileges on *.* to 'mycat'@'%' identified by '123456';
六、读写分离效果验证
6.1 测试环境准备
# 在客户端(192.168.10.119)安装MySQL客户端
yum install -y mariadb-server
systemctl start mariadb.service# 连接MyCat管理端口
mysql -u mycat -p123456 -h 192.168.10.110 -P 8066
# 通过mycat服务器代理访问mysql ,在通过客户端连接mysql后写入的数据只有主服务会记录,然后同步给从服务器
6.2 读写分离验证步骤
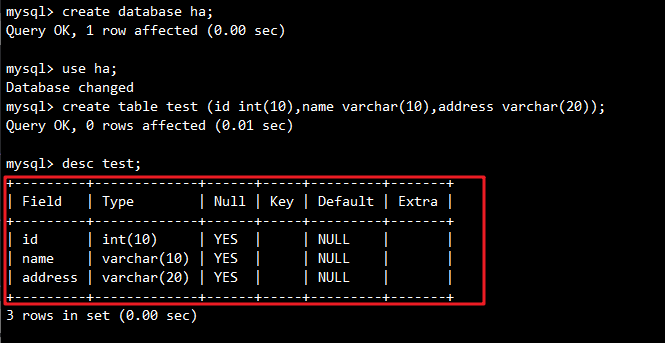
在主服务器上:
create database ha;use ha;
create table test (id int(10),name varchar(10),address varchar(20));
在两台从服务器上:
stop slave; #关闭同步
use ha;
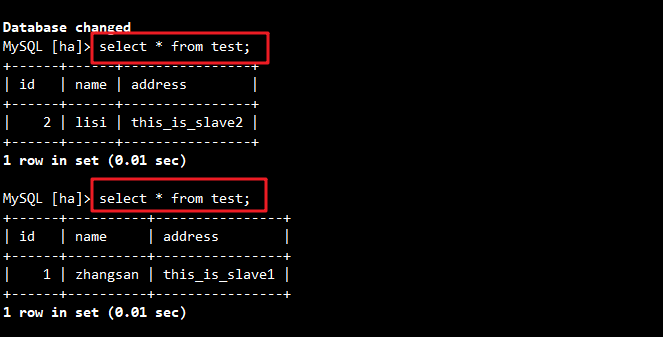
//在slave1上:
insert into test values('1','zhangsan','this_is_slave1');//在slave2上:
insert into test values('2','lisi','this_is_slave2');//在主服务器上:
insert into test values('3','wangwu','this_is_master');
//在客户端服务器上:
use ha;
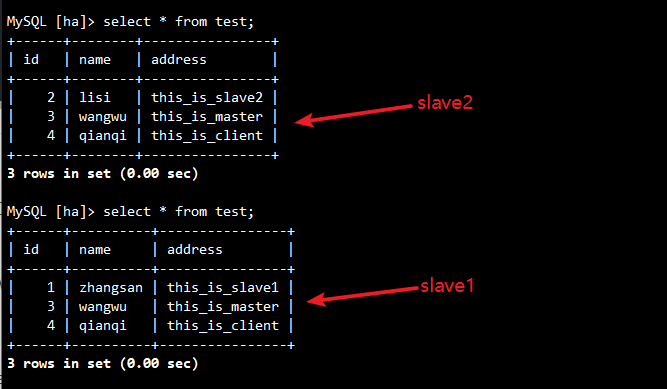
select * from test; //客户端会分别向slave1和slave2读取数据,显示的只有在两个从服务器上添加的数据,没有在主服务器上添加的数据
//在客户端服务器上:
insert into test values('4','qianqi','this_is_client'); //只有主服务器上有此数据

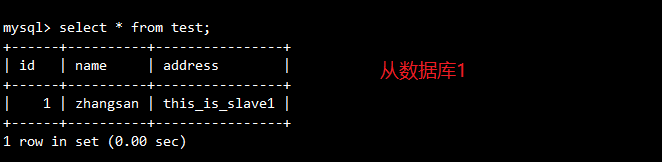

//在两个从服务器上执行 start slave; 即可实现同步在主服务器上添加的数据
start slave;
//在客户端执行查询
select * from test;
总结
通过本实验,我们完成了完整的MySQL主从读写分离环境搭建:
- 架构理解:掌握了MySQL主从复制原理和MyCat中间件的工作机制
- 环境搭建:
- 成功部署MyCat中间件
- 配置MySQL主从复制集群
- 核心配置:
- 掌握schema.xml中balance/writeType等关键参数
- 理解读写分离路由规则
- 效果验证:
- 通过暂停从库同步验证读分离效果
- 通过数据插入验证写操作路由
- 验证主从数据最终一致性
实际生产环境中还需注意:
- 主从延迟监控(Seconds_Behind_Master)
- MyCat连接池优化(maxCon/minCon)
- 读写分离失效场景处理(如强制走主库查询)
- 高可用方案(MyCat集群+Keepalived)
MyCat作为成熟的数据库中间件,能有效解决MySQL在高并发场景下的性能瓶颈,是企业级数据库架构的重要组件。通过本实验,您已经掌握了MyCat实现读写分离的核心技能,为进一步学习分库分表打下坚实基础。