RocketMQ-高性能消息中间件的原理
📚 章节 1:RocketMQ 简介与核心概念
在当今的互联网时代,随着系统规模的不断扩大和业务复杂度的日益增加,如何高效、可靠地处理海量数据和复杂的业务流程,成为了每个技术团队面临的挑战。正是在这样的背景下,RocketMQ 应运而生,成为了分布式消息队列领域的一颗璀璨明星。
1.1 什么是 RocketMQ?
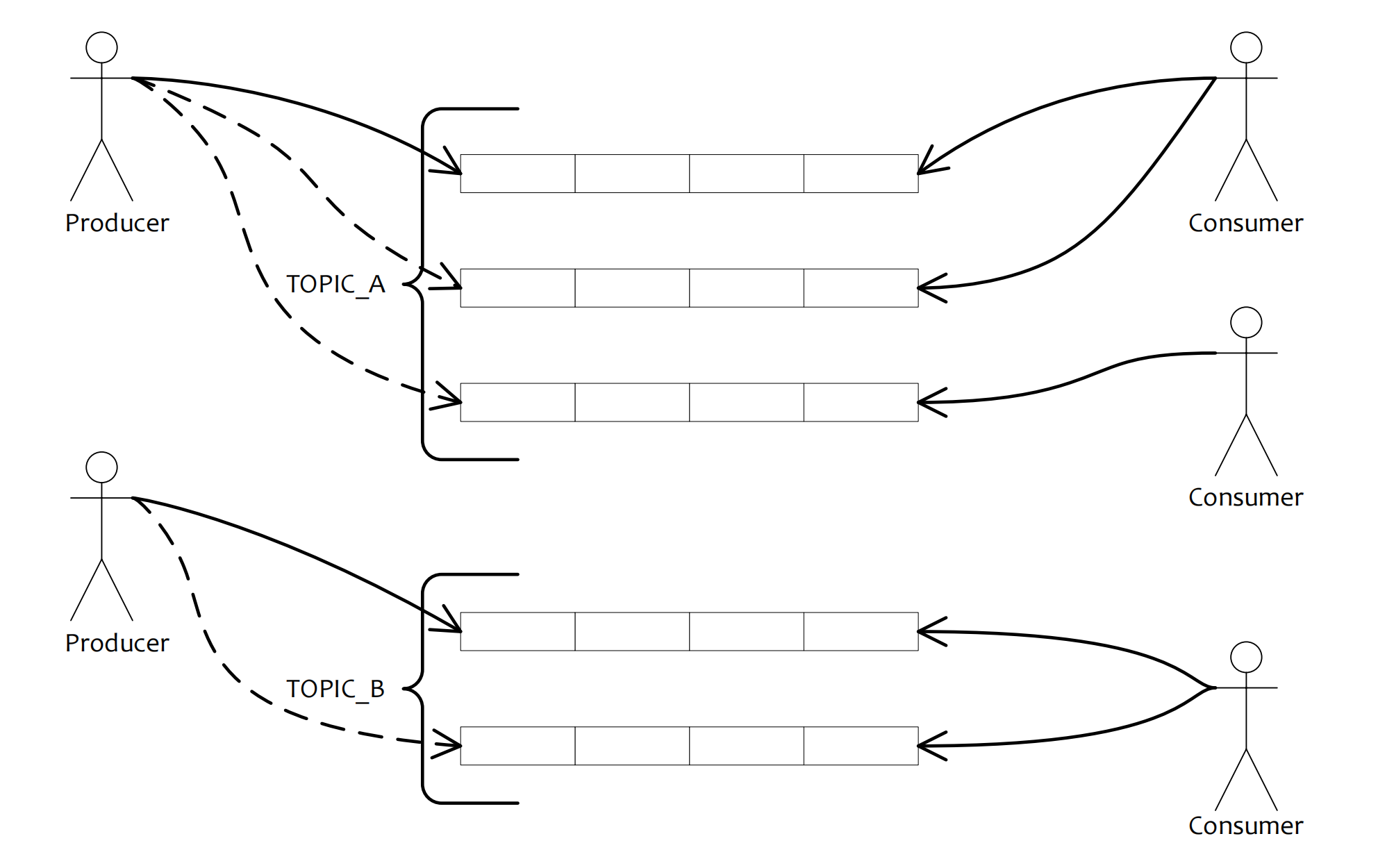
以发布订阅模式为主要方式,学习和参考了kafak的优秀设计,以topic和队列的方式提供消息收发工作。它的主要特性如下:
-
亿级消息的堆积能力,单个队列中的百万级消息的累积容量。
-
高可用性:Broker服务器支持多Master多Slave的同步双写,以及异步复制模式,其中同步双写可保证消息不丢失。
-
高可靠性:生产者将消息发送到Broker端有三种方式,同步、异步、单向。其中同步和异步都可以保证消息成功发送。Broker对于消息消息刷盘有2种策略:同步刷盘和异步刷盘,其中同步刷盘可以保证消息成功的存储到磁盘中。消费者的消费模式也有集群消费和广播消费两种,默认是集群消费,如果集群模式中有消费者挂了,一个组里的其他消费者会接替其消费。综上所述,是高可靠的。
-
支持分布式事务消息:二阶段提交实现金融级事务保障。。
-
支持消息过滤:tag支持server端过滤。
-
支持顺序消息:支持全局和分区顺序,根据业务特性实现对应的业务顺序场景。
-
支持定时消息和延迟消息:采用时间轮算法,消息自带定时延时功能。
1.2 RocketMQ 的定义与发展历程
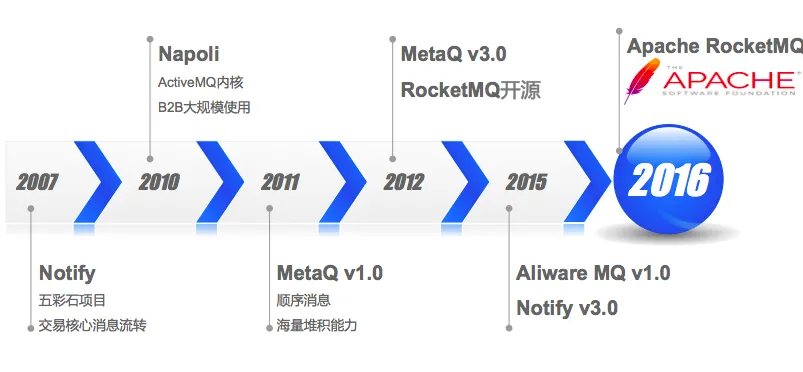
RocketMQ 是由阿里巴巴集团开发并开源的一款高性能、高吞吐量的分布式消息中间件。它最初诞生于阿里巴巴的内部系统,用于支撑其庞大的电商业务。2012年,RocketMQ 正式开源,并在2016年成为 Apache 基金会的顶级项目。经过多年的发展,RocketMQ 不仅在阿里巴巴内部得到了广泛应用,还在全球范围内赢得了众多企业的青睐,成为了处理高并发、大规模分布式系统的首选消息队列之一。
RocketMQ 的设计理念是“简单、高效、可靠”。它采用了分布式架构,支持水平扩展,能够轻松应对亿级消息的处理需求。同时,RocketMQ 提供了丰富的功能,如消息顺序性保证、事务消息、消息回溯等,满足了不同业务场景的需求。
1.3 消息队列的核心作用:解耦、异步、削峰填谷
图例出自阿里云官方产品背景,技术原理和使用场景是一样的。
消息队列作为分布式系统中的重要组件,其核心作用可以概括为两点:解耦异步和削峰填谷。
异步解耦:
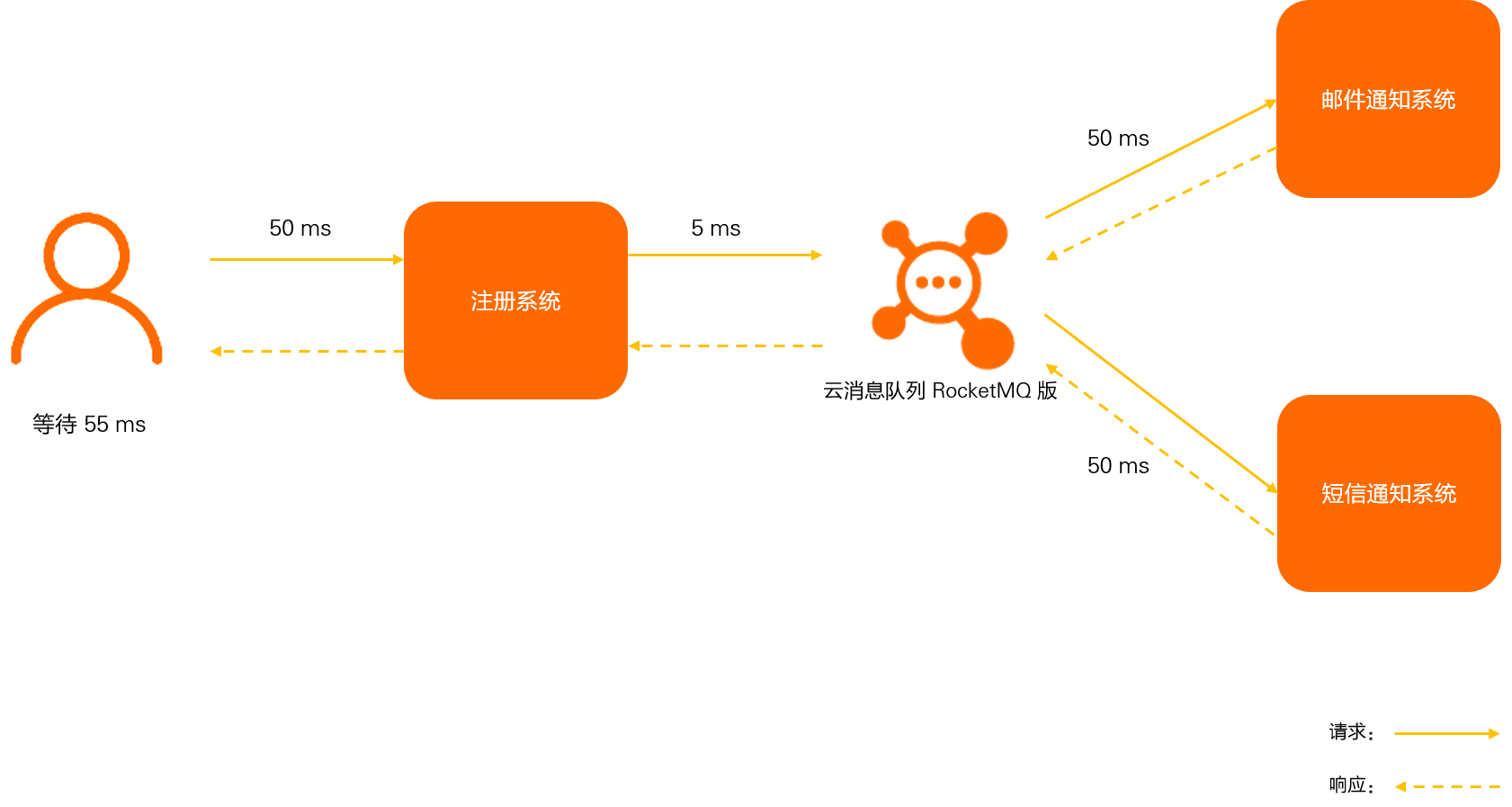
对于用户来说,注册功能实际只需要注册系统存储用户的账户信息后,该用户便可以登录,后续的注册短信和邮件不是即时需要关注的步骤。
削峰填谷:
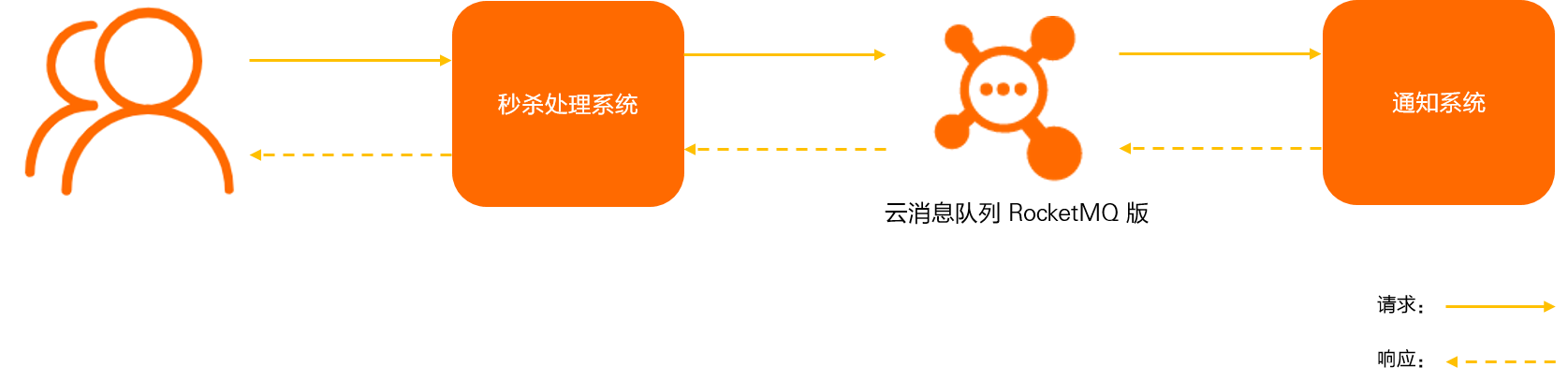
在高并发场景下,系统往往会面临突发的流量高峰,导致资源紧张甚至系统崩溃。消息队列通过缓冲机制,能够将突发的请求流量平滑地分散到不同的时间段进行处理,从而避免系统在高峰期过载。这种“削峰填谷”的能力,使得系统能够更加稳定地运行,保证了业务的连续性。
数据流处理:
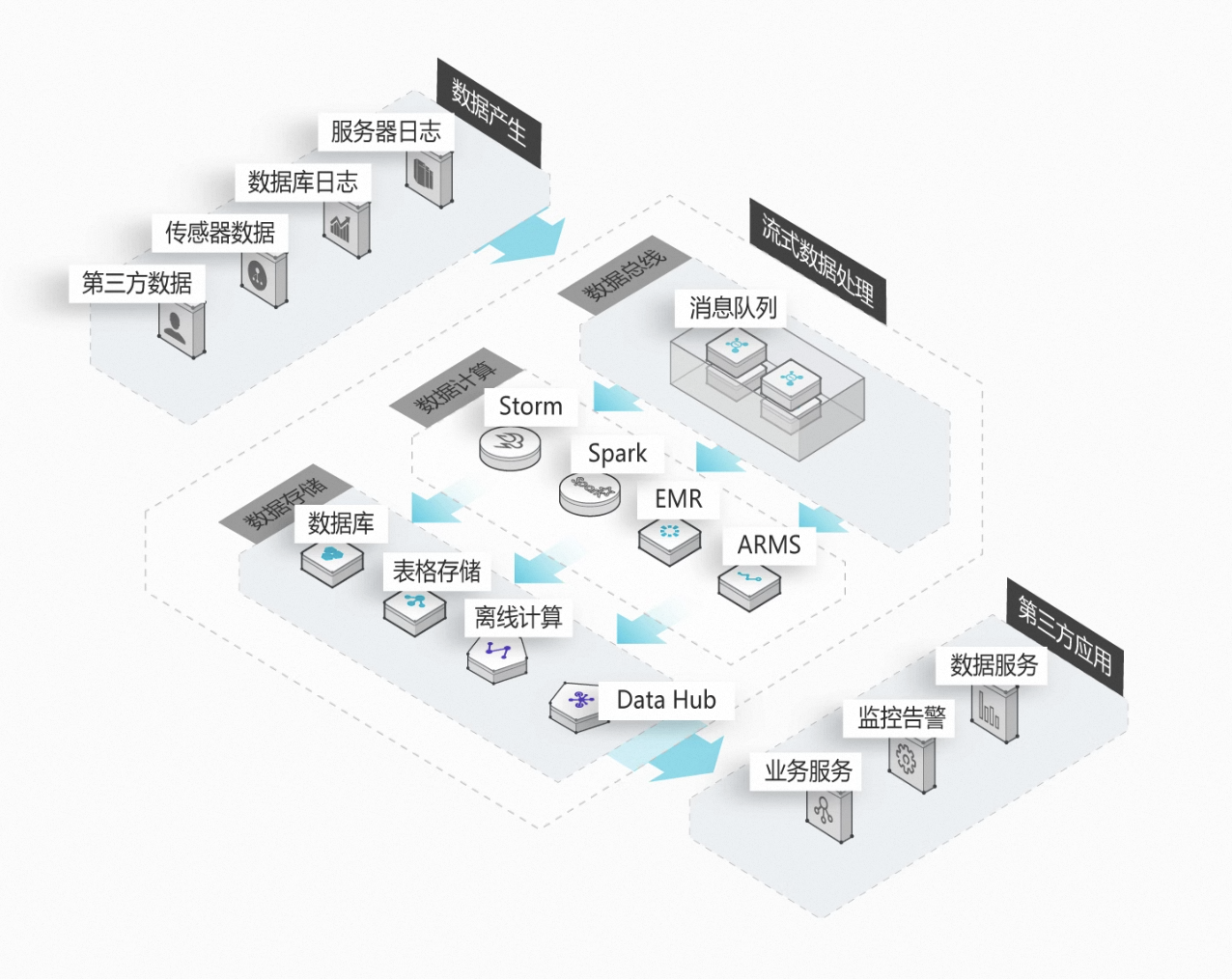
与传统批处理相比,消息队列可以很好承接与业务数据产生数据,数据源(如日志、传感器、用户行为等)通常以流的形式持续产生。消息队列作为数据管道,能够高效地接收、缓冲和传输这些实时数据,实现实时数据分析。
1.4 应用场景
RocketMQ 的应用场景非常广泛,涵盖了电商、金融、物流、社交等多个领域。例如,在电商系统中,RocketMQ 可以用于订单处理、库存更新、物流跟踪等环节;在金融系统中,它可以用于交易处理、风控监控、消息通知等场景。无论是实时数据处理,还是异步任务调度,RocketMQ 都能够提供高效、可靠的解决方案。
接下来,我们将深入探讨 RocketMQ 的架构设计、核心功能以及如何在实际项目中应用它来解决具体问题。
1.5 RocketMQ 的核心概念
在深入使用 RocketMQ 之前,理解其核心概念是至关重要的。这些概念不仅是 RocketMQ 架构的基础,也是我们设计和优化消息系统的关键。让我们逐一探讨这些核心概念,帮助您更好地掌握 RocketMQ 的工作原理。
1. Producer(生产者)
Producer 是消息的发送者,负责将消息发布到 RocketMQ 的 Broker 中。Producer 可以是任何需要发送消息的应用程序或服务。在 RocketMQ 中,Producer 支持同步发送、异步发送和单向发送三种模式,以满足不同场景下的需求。
-
同步发送:Producer 发送消息后,会等待 Broker 的响应,确保消息成功送达。
-
异步发送:Producer 发送消息后,不会等待响应,而是通过回调函数处理发送结果–发送到服务端。
-
单向发送:Producer 发送消息后,不关心发送结果,适用于对消息可靠性要求不高的场景–仅发送到本地网卡。
2. Consumer(消费者)
Consumer 是消息的接收者,负责从 Broker 中拉取消息并进行处理。RocketMQ 支持两种消费模式:集群消费和广播消费。
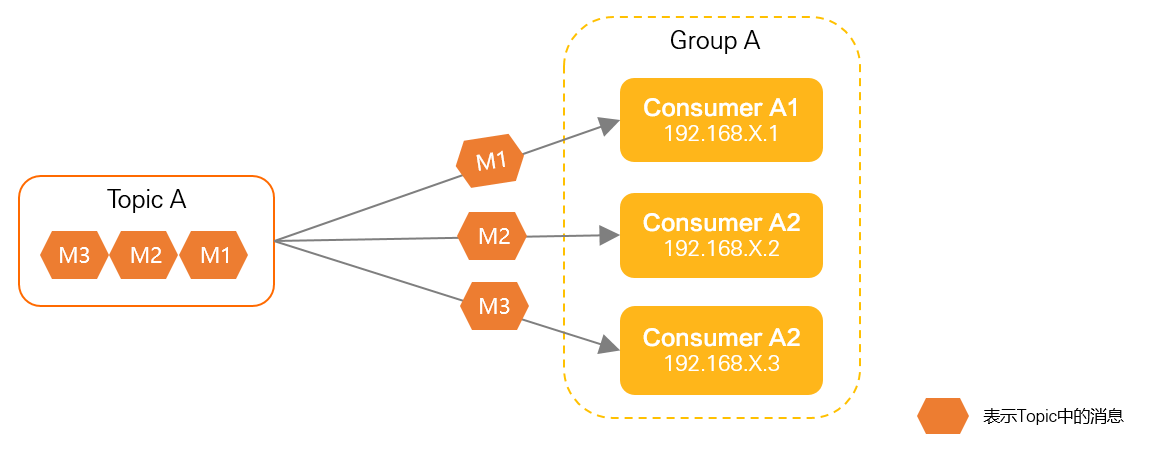
- 集群消费:同一个 Consumer Group 中的多个 Consumer 实例共同消费消息,每条消息只会被一个 Consumer 实例处理。这种方式适用于负载均衡和高可用场景。
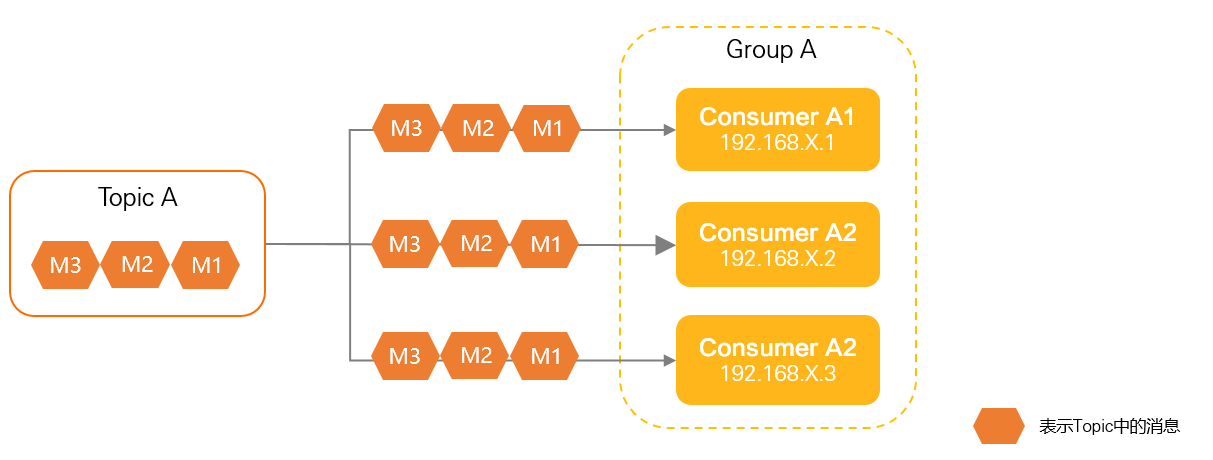
- 广播消费:同一个 Consumer Group 中的每个 Consumer 实例都会收到所有消息,适用于需要所有消费者都处理相同消息的场景。
3. Broker
Broker 是架构中最最重要的部分,就跟kafak一样,有状态服务,broker提供的核心功能是消息存储与传输。 同样是集群部署,broker通过名字区分是哪个broker群组,通过Id区分是master还是slave,Master 也可以部署多个,主故障时会进行选举来容忍故障,此时单个副本组可读不可写。每个 Broker 与 Name Server 集群中的所有节点建立长连接,定时注册 Topic 信息到所有 Name Server。
4. Topic(主题)
Topic 是消息的逻辑分类,Producer 将消息发送到指定的 Topic,Consumer 订阅感兴趣的 Topic 来接收消息。一个 Topic 可以被多个 Producer 和 Consumer 使用,是消息路由的基本单位。
- 分区(Queue):每个 Topic 可以分为多个 Queue,Queue 是消息存储和消费的最小单元。通过增加 Queue 的数量,可以提高消息的并发处理能力。
5. Message(消息)
Message 是 RocketMQ 中数据传输的基本单位,包含消息体、消息标签、消息键等信息。消息体是实际传输的数据,消息标签和消息键用于消息的分类和过滤。
-
消息顺序性:RocketMQ 支持顺序消息,确保同一个 Queue 中的消息按照发送顺序被消费。
-
事务消息:RocketMQ 提供了事务消息机制,支持分布式事务的处理,确保消息的最终一致性。
6. NameServer(命名服务器)
自研的"服务注册发现",每个节点都是无状态的,可集群部署,节点之间无任何信息同步,它解决的事情是: topic在哪些机器上、某个机器有哪一些topic。
7. Consumer Group(消费者组)
Consumer Group 是一组具有相同 Group ID 的 Consumer 实例,用于实现消息的负载均衡和故障转移。在集群消费模式下,同一个 Consumer Group 中的 Consumer 实例会均匀地分配消息,确保每条消息只被一个实例处理。
8. Tag(标签)
Tag 是消息的附加属性,用于对消息进行更细粒度的分类和过滤。Consumer 可以订阅特定 Tag 的消息,从而只接收感兴趣的消息内容,这一点与kafak不同,为业务开发附上更丰富的过滤逻辑,且在server端过滤,消费性能也有保障,同时支持普通文本和sql语法过滤。
9. Message Queue(消息队列)
Message Queue 是 Topic 的分区,每个 Queue 是一个独立的存储和消费单元。Producer 将消息发送到指定的 Queue,Consumer 从 Queue 中拉取消息进行处理。通过增加 Queue 的数量,可以提高消息的并发处理能力。
10. Offset(偏移量)
Offset 是消息在 Queue 中的位置标识,用于记录 Consumer 的消费进度。Consumer 通过维护 Offset 来确保消息的可靠消费,避免重复消费或消息丢失,关系结构即: 1group->n客户端->n队列→n位点进度,位点进度结构为双层map结构,首层map key为group和topic的组合key,第二层map key为队列id,value为进度数字,每个客户端会间隔一定时间或者优雅下线时向broker上报自己的队列消费位点。
通过理解这些核心概念,将能够更好地设计和优化基于 RocketMQ 的消息系统。在接下来的章节中,我们将深入探讨 RocketMQ 的架构设计、核心功能以及如何在实际项目中应用它来解决具体问题。
📚 章节 2:RocketMQ 架构设计
2.1 RocketMQ 的架构概览
整体架构图
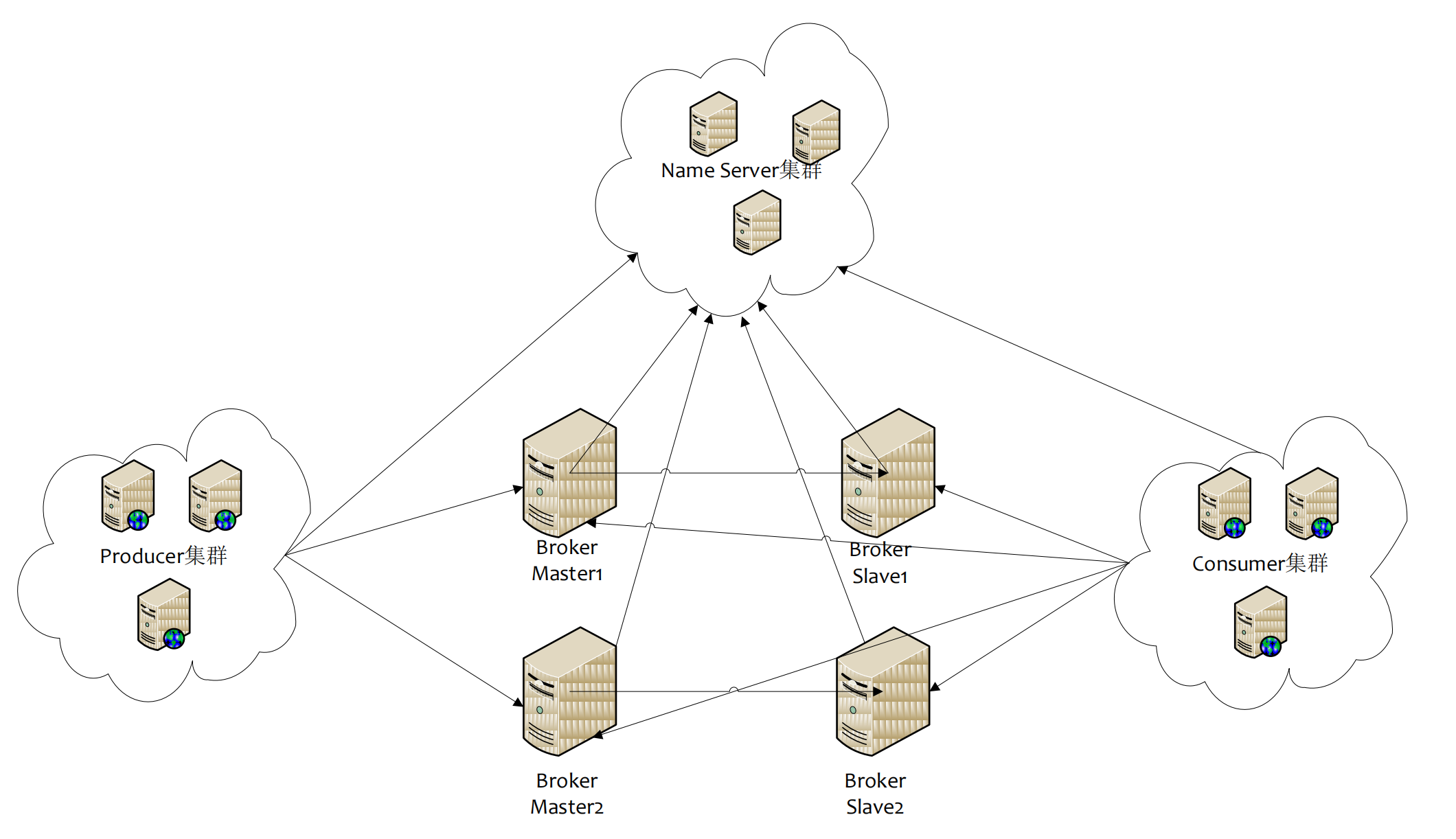
-
Name Server 是一个几乎无状态节点,可集群部署,节点之间无任何信息同步。
-
Broker 部署相对复杂,Broker 分为 Master 与 Slave,一个 Master 可以对应多个 Slave,但是一个 Slave 只能
-
对应一个 Master,Master 与 Slave 的对应关系通过指定相同的 BrokerName,不同的 BrokerId 来定义,BrokerId
-
为 0 表示 Master,非 0 表示 Slave。Master 也可以部署多个。每个 Broker 与 Name Server 集群中的所有节
-
点建立长连接,定时注册 Topic 信息到所有 Name Server。
-
Producer 与 Name Server 集群中的其中一个节点(随机选择)建立长连接,定期从 Name Server 取 Topic 路
-
由信息,并向提供 Topic 服务的 Master 建立长连接,且定时向 Master 发送心跳。Producer 完全无状态,可
-
集群部署。
-
Consumer 与 Name Server 集群中的其中一个节点(随机选择)建立长连接,定期从 Name Server 取 Topic 路
-
由信息,并向提供 Topic 服务的 Master、Slave 建立长连接,且定时向 Master、Slave 发送心跳。Consumer
-
既可以从 Master 订阅消息,也可以从 Slave 订阅消息,订阅规则由 Broker 配置决定。
消息存储机制
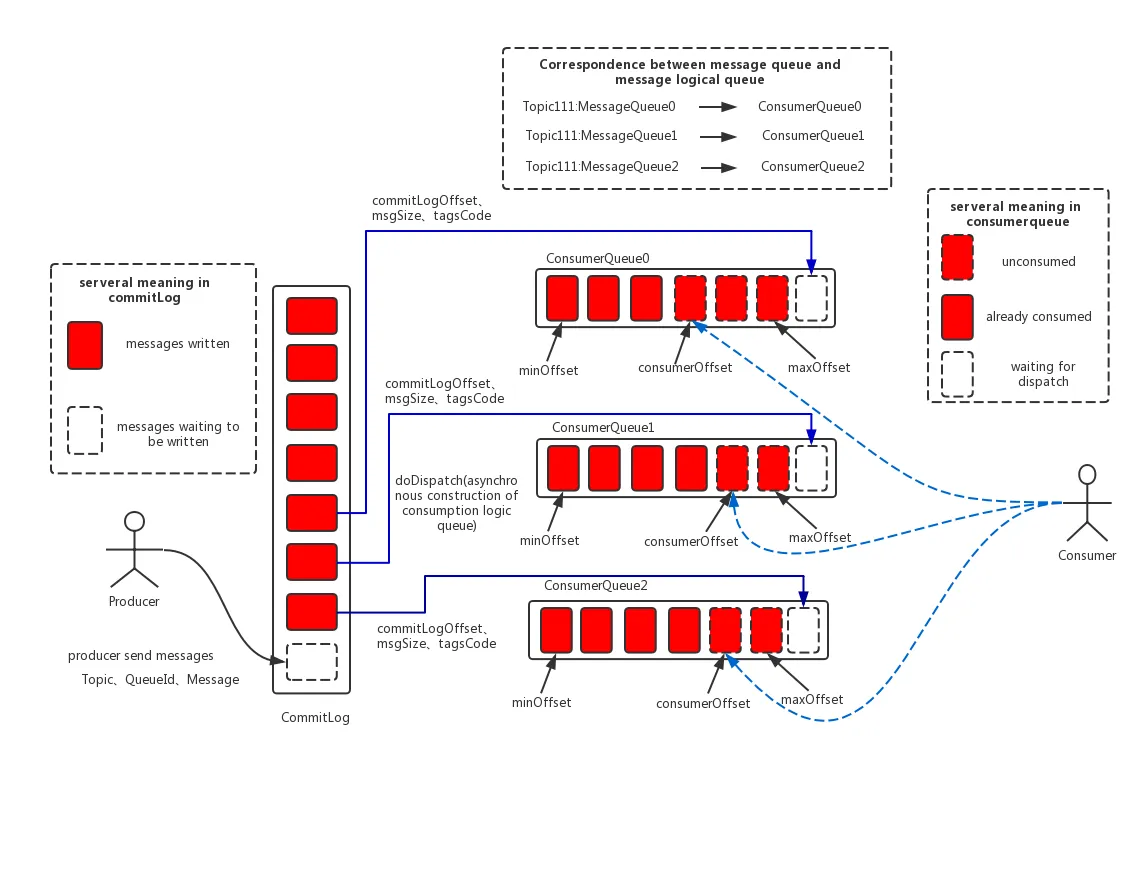

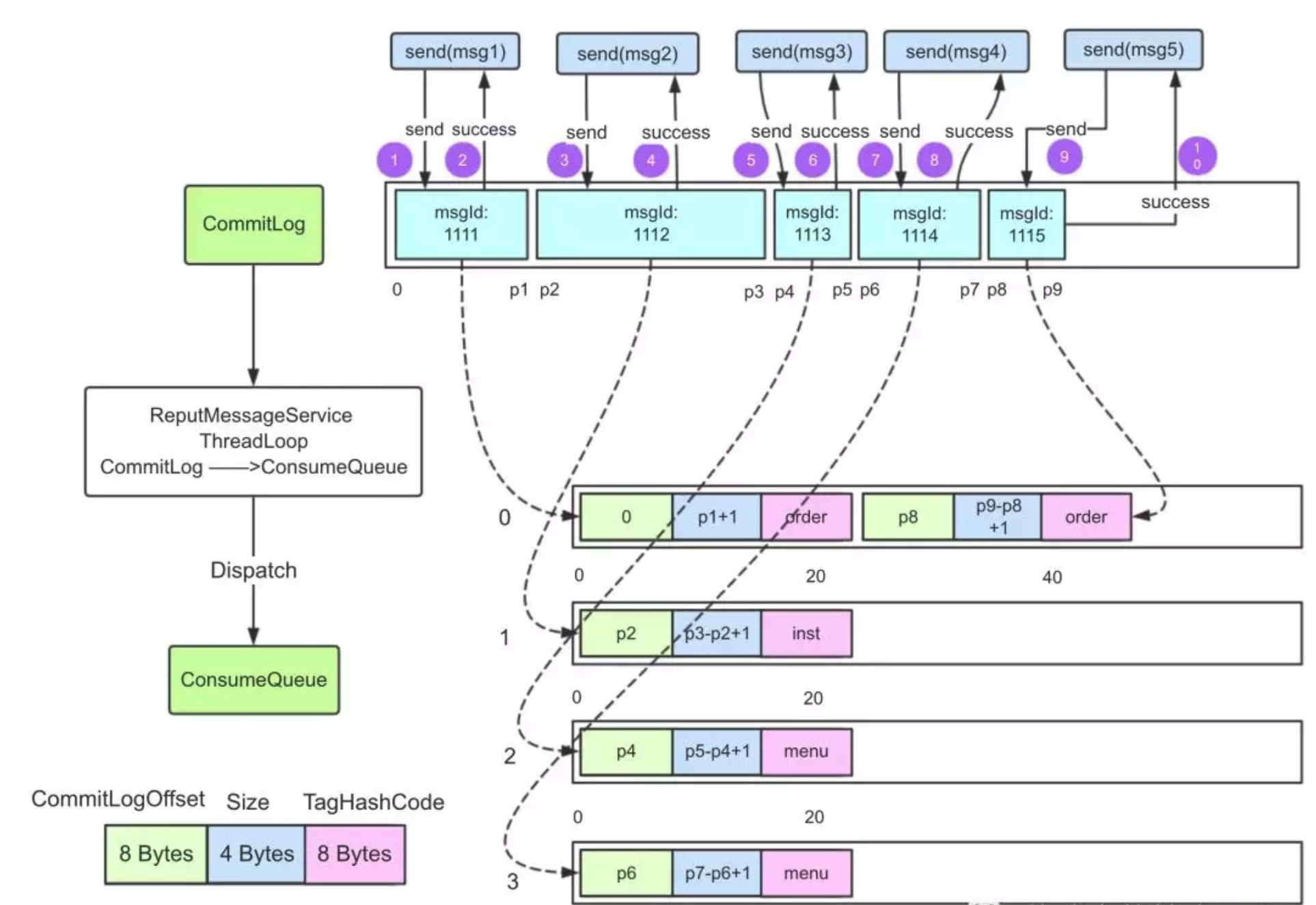
- CommitLog:消息的物理存储,所有topic的消息,都会被串行的顺序追加在这个日志里,高效利用pagecache和磁盘顺序写的优势,是实现高性能写入的设计核心,一个文件一个G,文件以最小偏移量命名,默认每隔3天会进行清理。
-
ConsumeQueue:消息的逻辑索引,解决了commitlog随机查询性能问题,将topic下的消息按照队列进行分组,每一条消息20个字节,8字节用于存储commitLog中消息的实际偏移量,4字节存储消息大小,4字节用于存储消息tag hashcode,消费者查询消息根据topic和逻辑偏移量定位ConsumeQueue位置,再根据获取的物理日志偏移量去commitLog查询,与commitLog一样,高效利用了pagecache和mmap。
-
消息刷盘策略:
a) 同步刷盘:消息写入Broker内存后,需立即写入commitLog文件,成功后通知Producer,确保数据不丢失,但响应时间较长。
b) 异步刷盘:消息存入内存即通知Producer成功,随后异步写入commitLog,吞吐量高,但存在数据丢失风险。
同步刷盘适合高可靠性场景,异步刷盘适合高吞吐量场景。
高可用设计
NameServer高可用
工作机制:
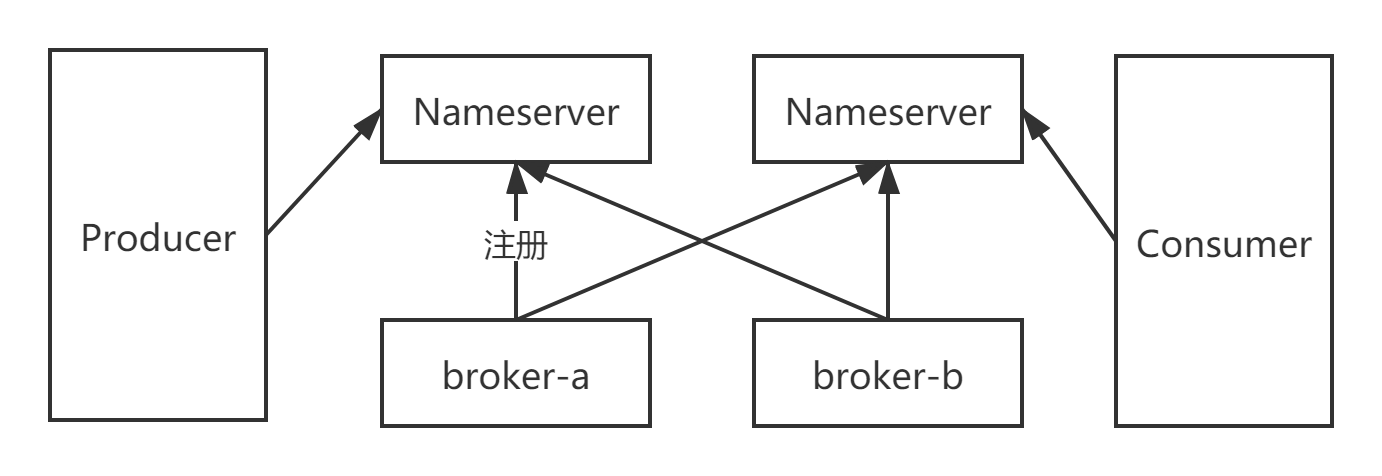
简要来说,就是每个broker都需要和所有nameserver按一定时间间隔发送心跳包(自身的topic路由数据),而客户端通过nameserver这一层注册中心的角色,获取路由信息用来收发消息找到对应的目标broker服务器,同时按一定频率不断更新到本地缓存中。这样不禁联想到早期的kafka使用zookeeper来做注册中心,为什么RocketMQ要自研一个新的注册中心呢?这里需要区别一下业界主流的注册中心的设计思路: CP || AP. 以dubbo使用zookeeper作为服务治理为例:
CP架构
基于 ZooKeeper 的注册中心有一个显著的特点是服务的动态变更,消费者可以实时感知,在 Dubbo 中,一个服务进行在线扩容,增加一批的消息服务提供者,消费者能立即感知,并将新的请求负载到新的服务提供者,这种模式在业界有一个专业术语:PUSH 模式。
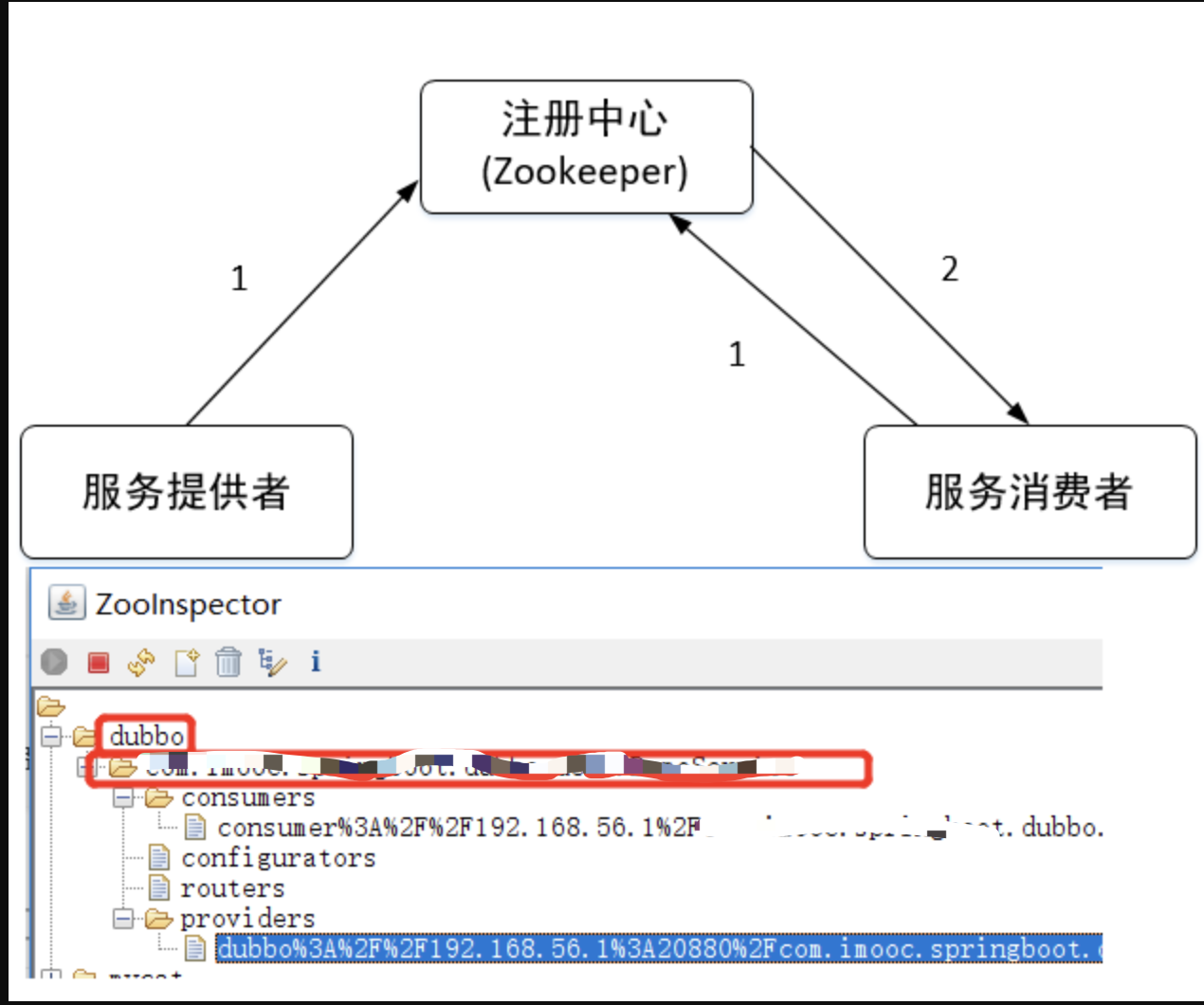
基于Zooeeper的服务发现机制,通过事件驱动实现动态注册与订阅,流程如下:
-
服务注册:提供者启动时在
/dubbo/{serviceName}/providers创建临时节点,若服务异常,节点随会话结束自动移除。 -
服务订阅:消费者启动时在
/dubbo/{serviceName}/consumers创建临时节点,并监听提供者路径。当提供者列表变化时,ZooKeeper推送最新节点信息,消费者更新本地缓存,确保调用实时性。
ZooKeeper的优势在于实时性,但其CP模型可能导致可用性降低。例如,集群选举或网络分区时,注册与订阅功能可能暂时中断。
在服务发现场景中,数据一致性并非核心问题。以Dubbo为例,消费者获取的提供者列表短暂不一致仅可能导致负载不均衡,最终一致性即可满足需求。
AP架构
RocketMQ 的 Nameserver 并没有采用诸如 ZooKeeper 的注册中心,而是选择自己实现,如果大家看过 RocketMQ 的源代码,就会发现该模块就 5~6 个类,总代码不超过 5000 行,简单就意味着高效
在 RocketMQ 中,Broker 每 30 秒向 Nameserver 发送一次心跳包,其中包含主题的路由信息(如读写队列数量、权限等)。Nameserver 通过 HashMap 更新这些信息,并记录最后一次接收到心跳的时间戳。Nameserver 每 10 秒清理一次已宕机的 Broker,判断依据是当前时间与最后一次心跳时间差超过 120 秒。
消息生产者每 30 秒从 Nameserver 拉取一次路由信息,因此无法实时感知 Broker 的增减。这种 PULL 模式的特点在于,即使路由信息发生变化,客户端也无法立即获知,只能依赖定时任务更新。例如,在大促结束后缩容时,直接停止 Broker 进程会导致 Nameserver 立即更新路由信息,但生产者需要等待下次拉取才能感知,期间可能会向已下线的 Broker 发送消息,导致失败。
RocketMQ 的 Nameserver 集群节点之间不通信,各自独立运行,这种设计虽然简单,但会导致各节点的路由信息不一致。然而,RocketMQ 的设计者选择不解决这一问题,以保持 Nameserver 的高性能,将问题的解决交给使用者。
对于消息发送端,路由信息的不一致可能导致消息分布不均衡,但不会造成严重问题,因为最终会达到一致性。对于消息消费端,消费者连接不同的 Nameserver 可能导致队列分配不均,甚至重复消费。如果消费者实现了幂等性,这种影响是可控的。
通过引入消息发送重试和故障规避机制,RocketMQ 确保了消息发送的高可用性。Nameserver 的设计体现了架构设计中的权衡与取舍,无需追求完美,而是注重简单与高效。
broker高可用
先说结论,自建部署实现broker最佳推荐方案: 多主多从+同步双写+异步刷盘
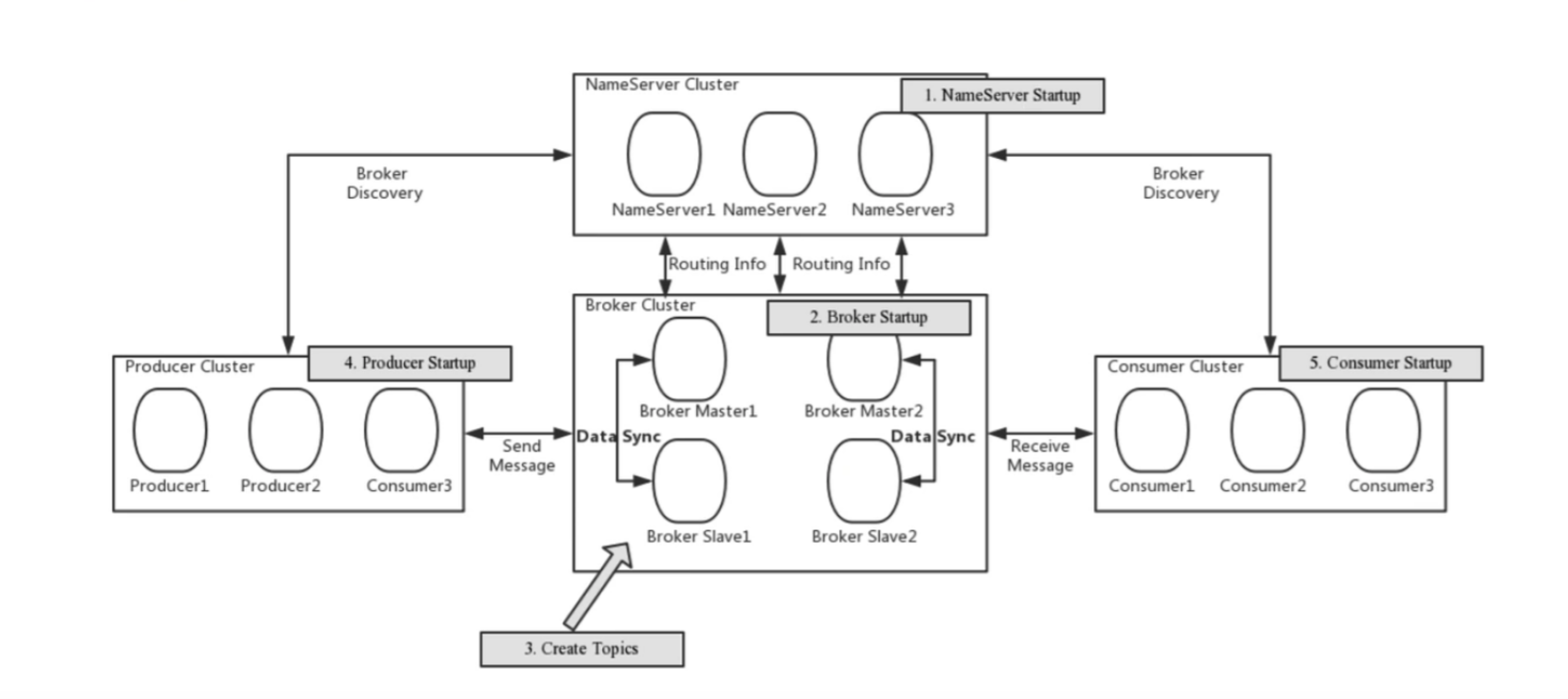
在RocketMQ中,采用Master-Slave架构,每台Master至少配备一个Slave,形成多对主从关系。HA(高可用性)机制通过同步双写实现,即主从节点均写入成功后才向应用返回成功,确保数据热备份。同时,通过异步刷盘方式提升系统吞吐量。该模式的优缺点如下:
优点:
- 数据与服务均无单点故障,Master宕机时消息无延迟,服务与数据可用性极高。
缺点:
-
性能略低于异步复制模式,发送消息的响应时间(RT)稍长;
-
当前版本不支持主节点宕机后Slave自动切换为Master;
-
若需将Slave升级为Master,需手动停止Slave节点,修改配置并重启,操作较为繁琐。
raft选主故障转移
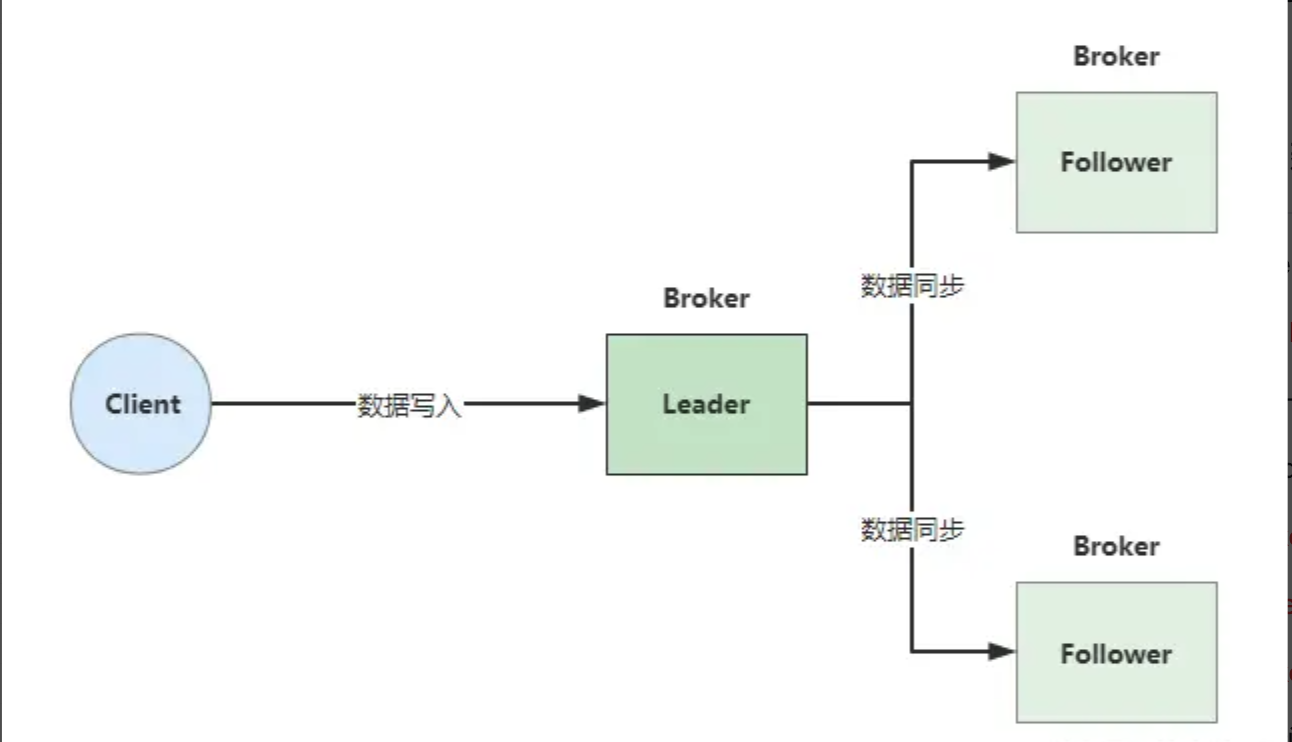
DLedger是RocketMQ实现高可用的核心技术,主要功能包括:
-
CommitLog的统一管理:DLedger提供API直接读取CommitLog,便于构建ConsumerQueue等模块。
-
数据同步与仲裁:Leader节点接收写请求后,将数据广播给所有Follower节点。Follower节点存储数据后,向Leader发送ACK确认。如果超过半数节点存储成功,Leader向客户端返回写入成功。
在引入DLedger之前,Broker主节点故障后需手动切换。DLedger基于Raft协议实现自动故障转移,具体流程如下:
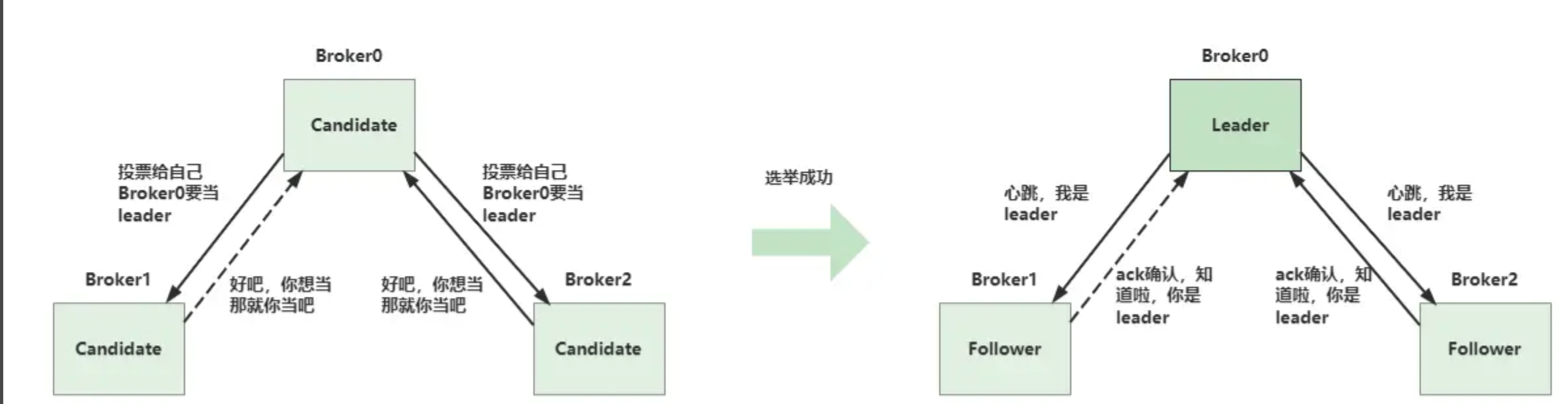
-
角色划分:
-
Leader:负责数据写入和同步,维护心跳。
-
Follower:存储Leader同步的数据,响应心跳。
-
Candidate:参与Leader选举。
-
-
选举流程:
-
集群启动或Leader故障时,所有节点进入Candidate状态。
-
某一节点(如Broker0)发起选举,投票给自己并通知其他节点。
-
其他节点同意后,Broker0获得超过半数投票,成为新Leader。
-
新Leader通知其他节点,将其状态改为Follower。
-
-
故障检测与重新选举:
-
Follower节点通过定时器检测Leader心跳。若超时未收到心跳,则认为Leader故障,触发重新选举。
-
新Leader选举成功后,生产者从NameServer获取新的路由信息,继续发送消息。
-
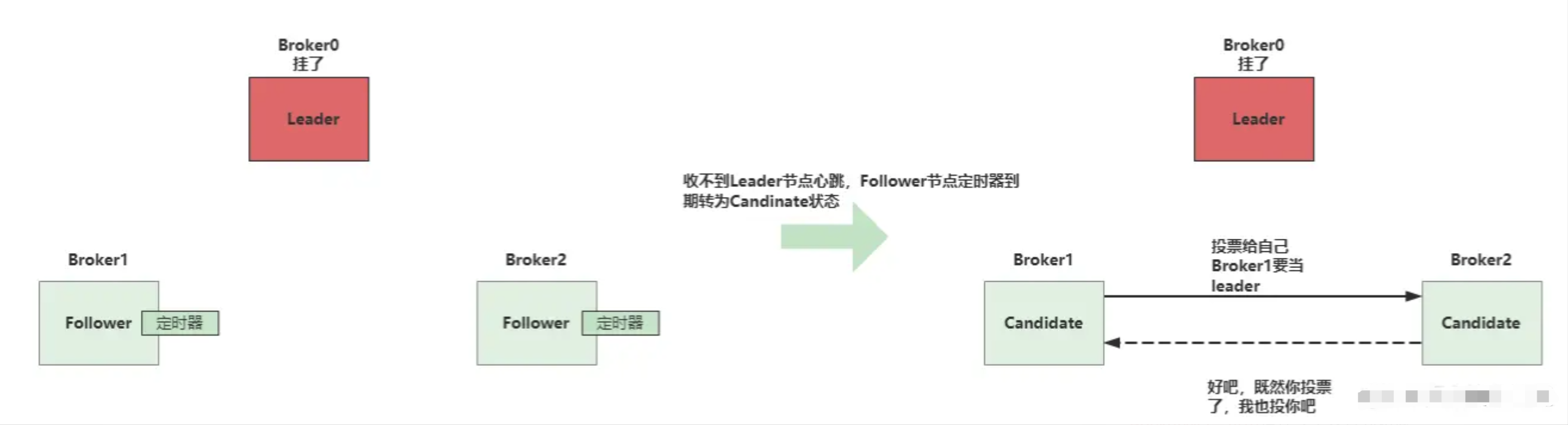
通过DLedger和Raft协议,RocketMQ实现了高可用性、数据冗余和自动故障转移,确保消息系统的稳定性和可靠性。
2.2 消息消费机制
Push 模式 vs Pull 模式
PUSH与PULL的定义
**PUSH模式**
客户端与服务端建立长连接,服务端在有数据时立即将数据推送给客户端。
-
RocketMQ的实现:PUSH模式实际上是通过PULL模式封装实现的,客户端不断从Broker拉取消息并提交到线程池处理,从而实现“伪推送”。
PULL模式(kafka)
客户端主动向服务端请求拉取数据。 -
RocketMQ的实现:客户端定期向Broker发起拉取请求,如果有数据则消费,没有数据则等待。
PUSH与PULL的特点
-
PUSH模式的特点
-
优点:
-
对客户端友好,无需处理无数据的情况。
-
实现类似实时推送的效果,适合大多数场景。
-
-
缺点:
- 服务端无法感知客户端的处理能力,可能导致消息堆积在客户端。
-
-
PULL模式的特点
-
优点:
- 客户端主动控制拉取频率,避免消息堆积。
-
缺点:
-
无法实时感知数据变化,拉取间隔难以控制:
-
间隔过长,消息消费不及时;
-
间隔过短,产生大量无效请求。
-
-
-
RocketMQ的长轮询机制
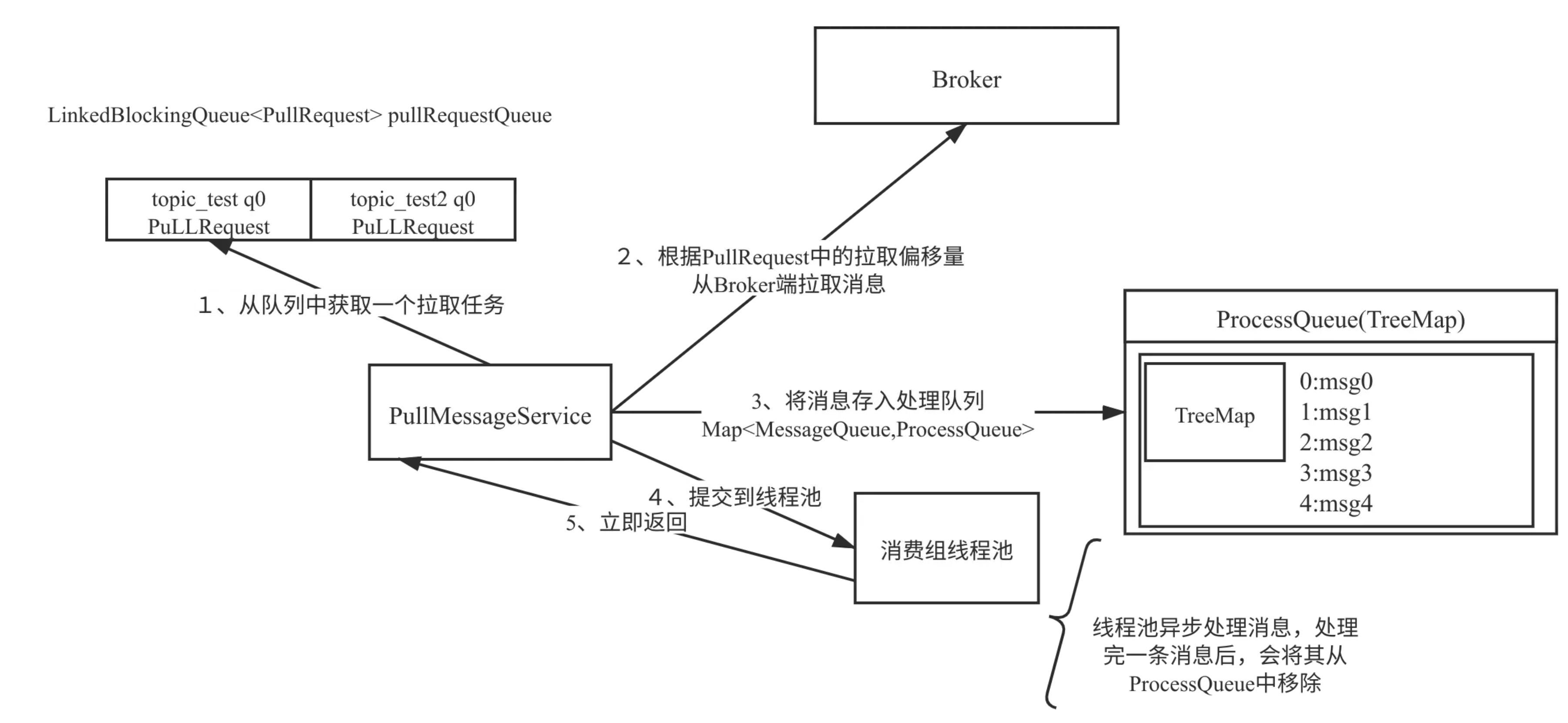
为了在PULL模式下保证消息消费的实时性,RocketMQ采用了长轮询机制:
-
客户端定期向Broker发起拉取请求(以一个队列为维度拉取,每次拉取32条)。
-
如果Broker有数据,立即返回数据给客户端。
-
如果Broker没有数据,客户端线程会阻塞等待(默认阻塞时间为15秒)。
-
在阻塞期间,如果Broker有新数据到达,会立即唤醒客户端线程并返回数据。
实现细节:
-
长轮询的逻辑主要在
PullRequestHoldService类中实现。 -
通过长轮询,RocketMQ在PULL模式下实现了接近PUSH模式的实时性。
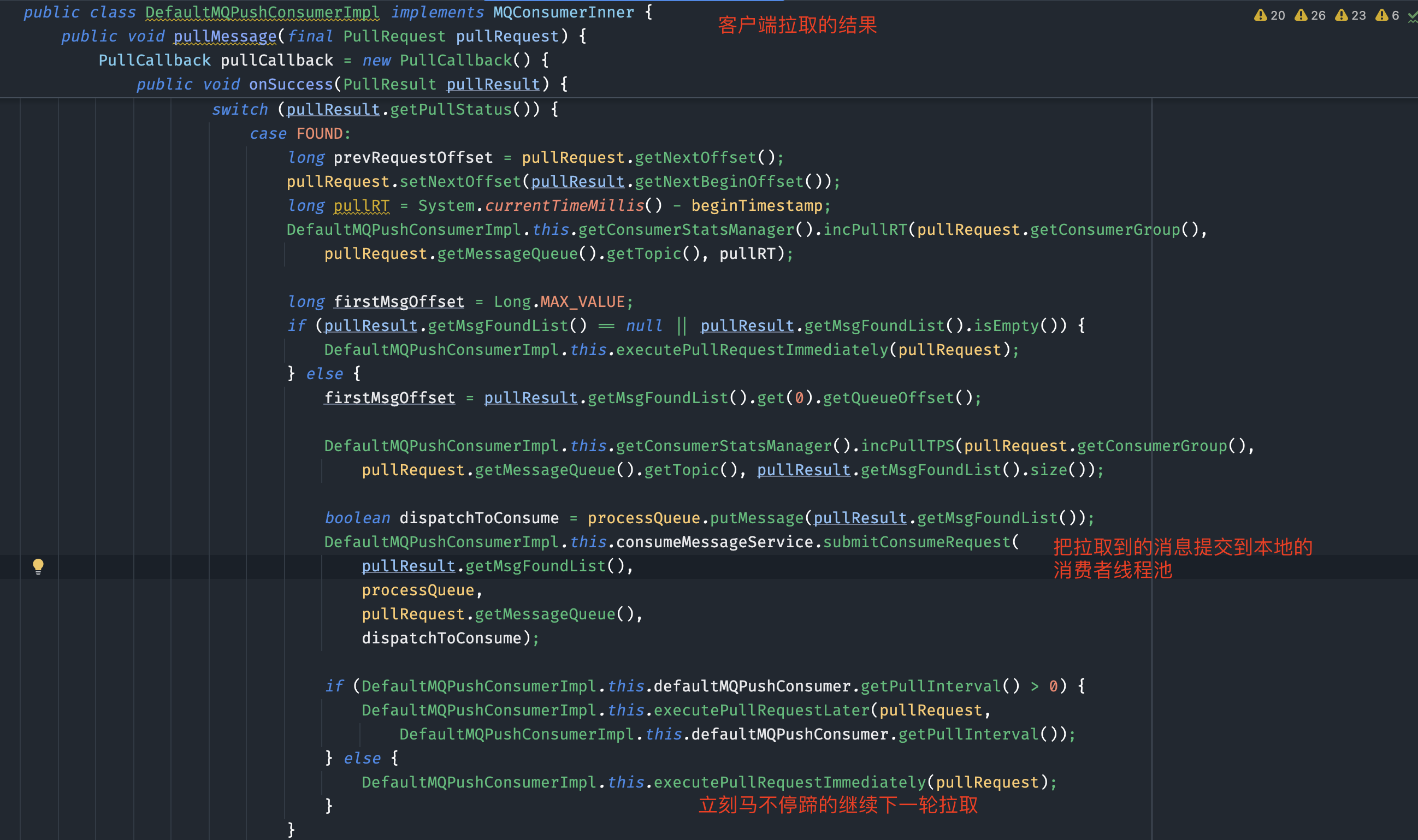
以下是RocketMQ消息拉取与消费的核心关键点总结:
1. 队列分配与拉取请求
-
队列分配:
消费组通过负载均衡机制分配到多个队列。一个消费组可以订阅多个主题,例如topic_test和topic_test1,每个主题可能分配到一个或多个队列。 -
PullRequest对象:
每个拉取请求封装在PullRequest对象中,包含队列信息、拉取偏移量等。
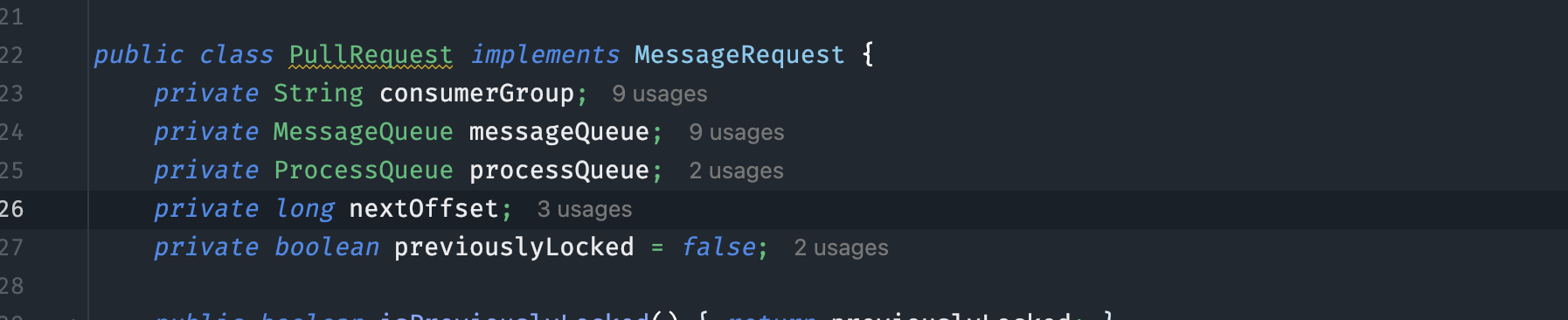
2. 消息拉取过程
-
拉取请求发起:
从pullRequestQueue中轮流取出PullRequest对象,根据其中的拉取偏移量向Broker发起拉取请求。 -
拉取消息数量:
默认每次拉取32条消息,可通过pullBatchSize参数调整。 -
返回结果:
Broker返回消息列表,并更新PullRequest对象中的下一次拉取偏移量。
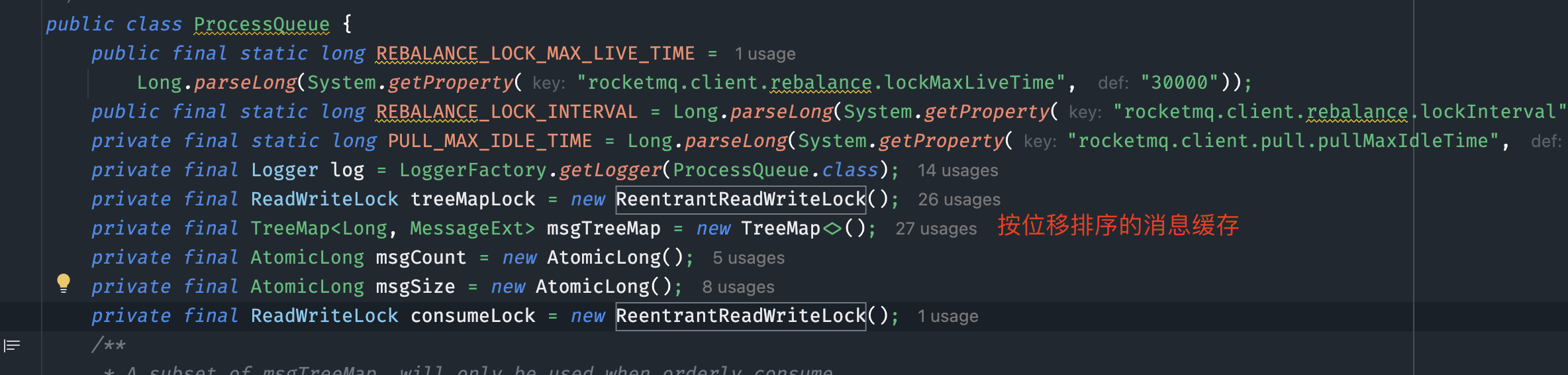
3. 消息存储与处理
-
ProccessQueue:
-
Key:消息在消费队列(
consumequeue)中的偏移量。 -
Value:具体的消息对象。
-
-
线程池提交:
将消息提交到消费组内部的线程池进行异步处理,并立即返回。 -
继续拉取:
将PullRequest对象重新放入pullRequestQueue,继续拉取下一个队列的消息。
4. 消息消费与进度汇报

-
消息消费:
消费组线程池处理完一条消息后,将其从ProccessQueue中移除。 -
消费进度汇报:
向Broker汇报消息消费进度,确保下次重启时能从上次消费的位置继续消费。
5. 消息拉取与消费的线程分离
-
拉取线程:负责从Broker拉取消息并放入
ProccessQueue。 -
消费线程:负责从
ProccessQueue中取出消息并进行处理。 -
异步机制:拉取与消费由不同线程处理,提高吞吐量和效率。
消费者负载均衡策略
我们知道,不管是在kafka,还是rocketmq中,集群消费模式下每个队列(分区)都只会被同一个消费者组内同一个客户端消费,在5.0版本以下的rocketmq中,使用的是客户端负载均衡策略,整体的消费和负载均衡实现是这样的:
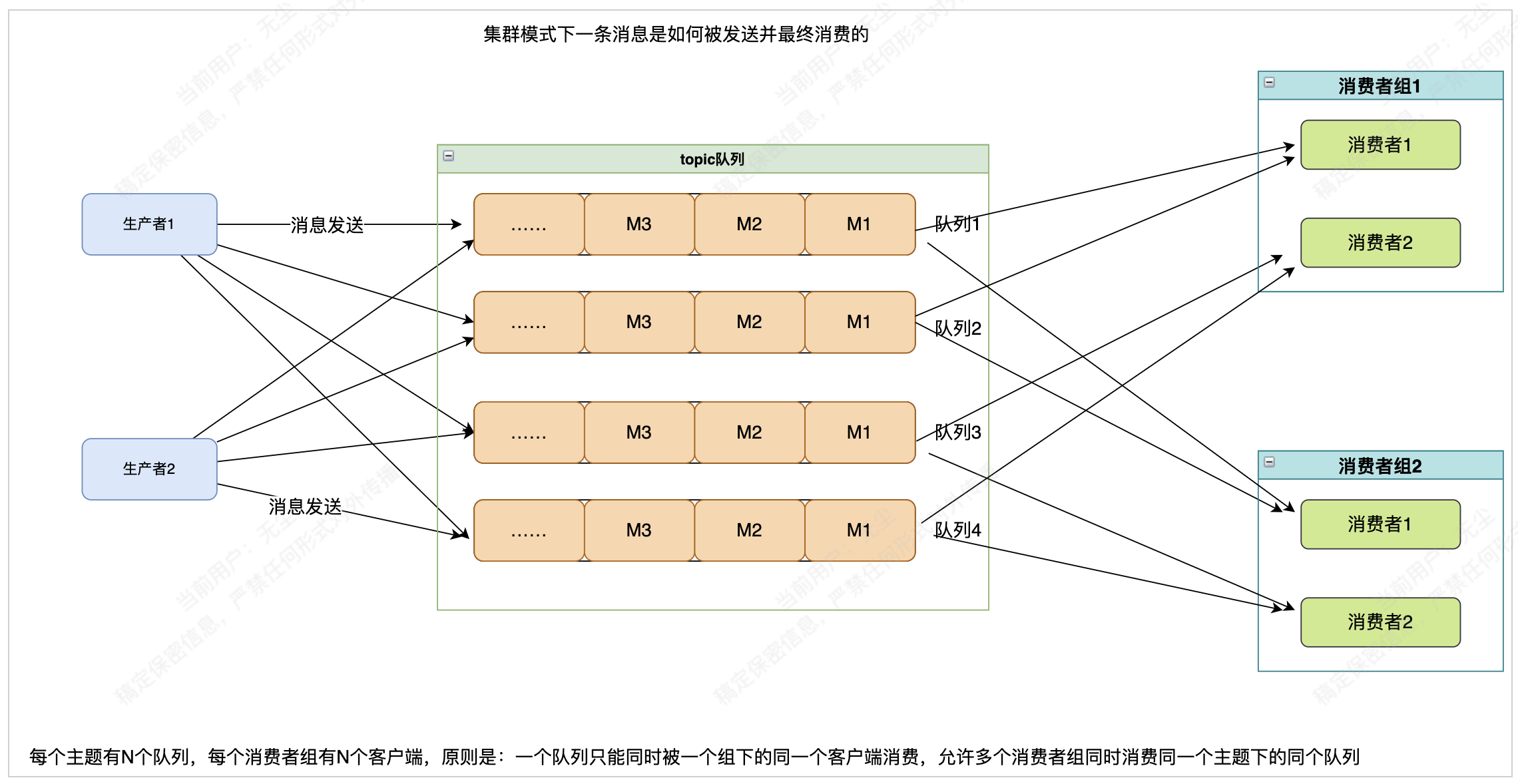
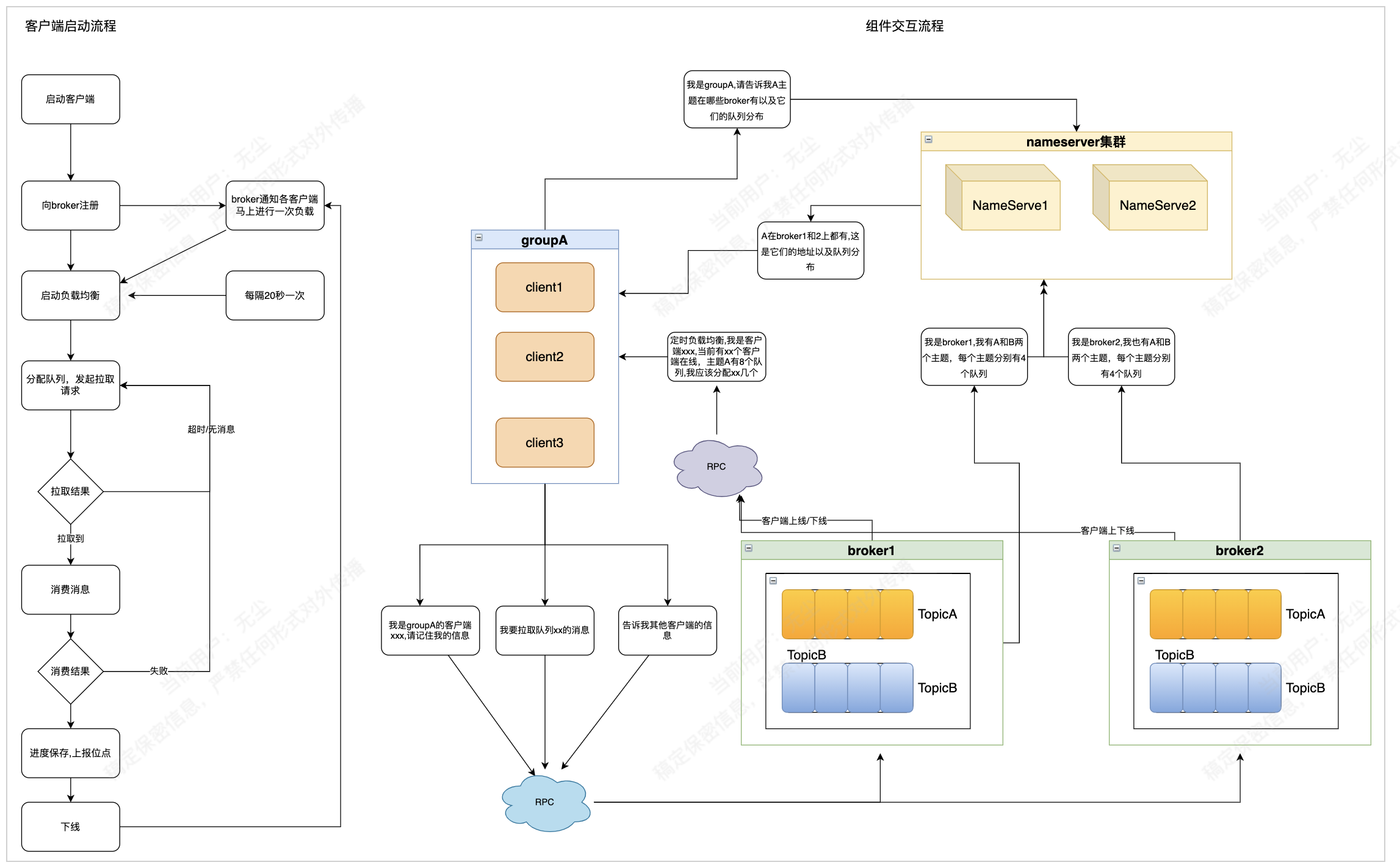
简单来说,就是通过上面我们的整体架构介绍,每个group组客户端启动的时候,会和所有目标broker和nameserver保持心跳和长连接关系,也就知道了某个要消费的topic当前有多少队列,分别分布在哪一些broker上,这个是路由信息。每个客户端按照统一的算法去获取自己应该要获得队列,然后存在本地队列里,再循环向服务端拉取。在客户端上下线的过程中,服务端会广播给所有在线的客户端立即做一次负载均衡,来保证消息都能被负载到(所以消费会受限于队列数,和kafak一样当客户端大于队列数时会存在客户端无法消费的情况,在5.0版本POP的出世这一点得到很大的提升),下面是内置的一些常用的客户端算法:
AllocateMessageQueueAveragely
平均连续分配算法。主要的特点是一个消费者分配的消息队列是连续的,也是默认算法。
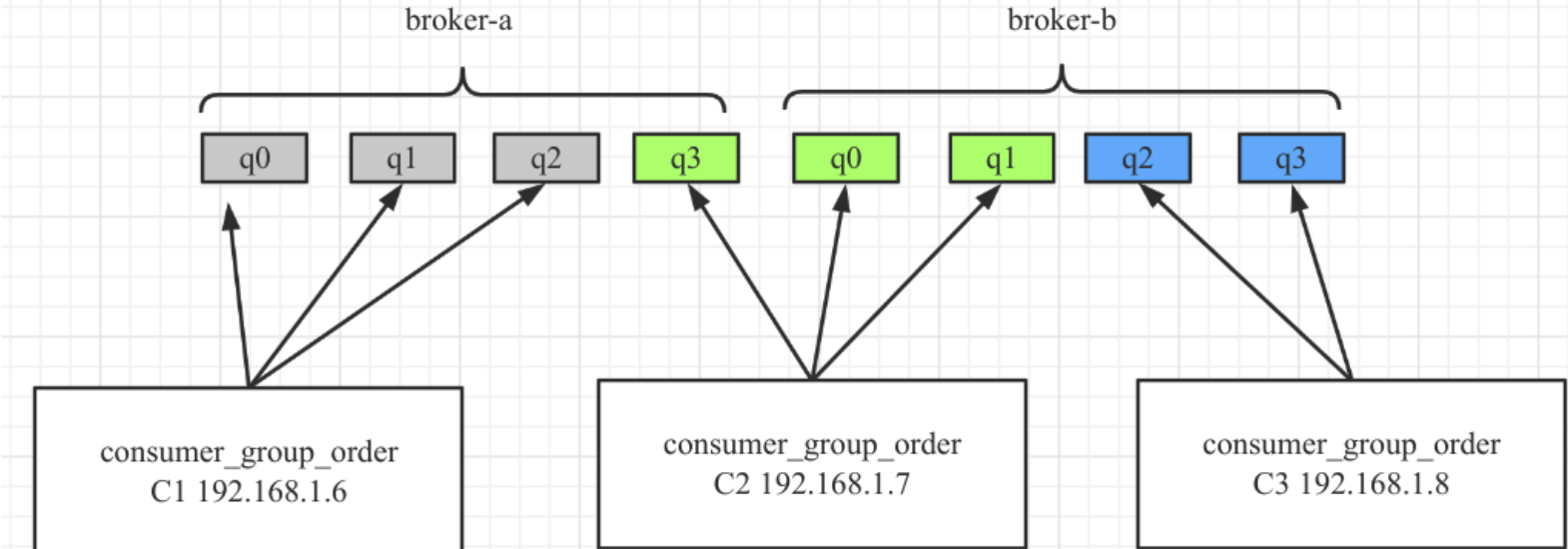
AllocateMessageQueueAveragelyByCircle
平均轮流分配算法,其分配示例图如下:
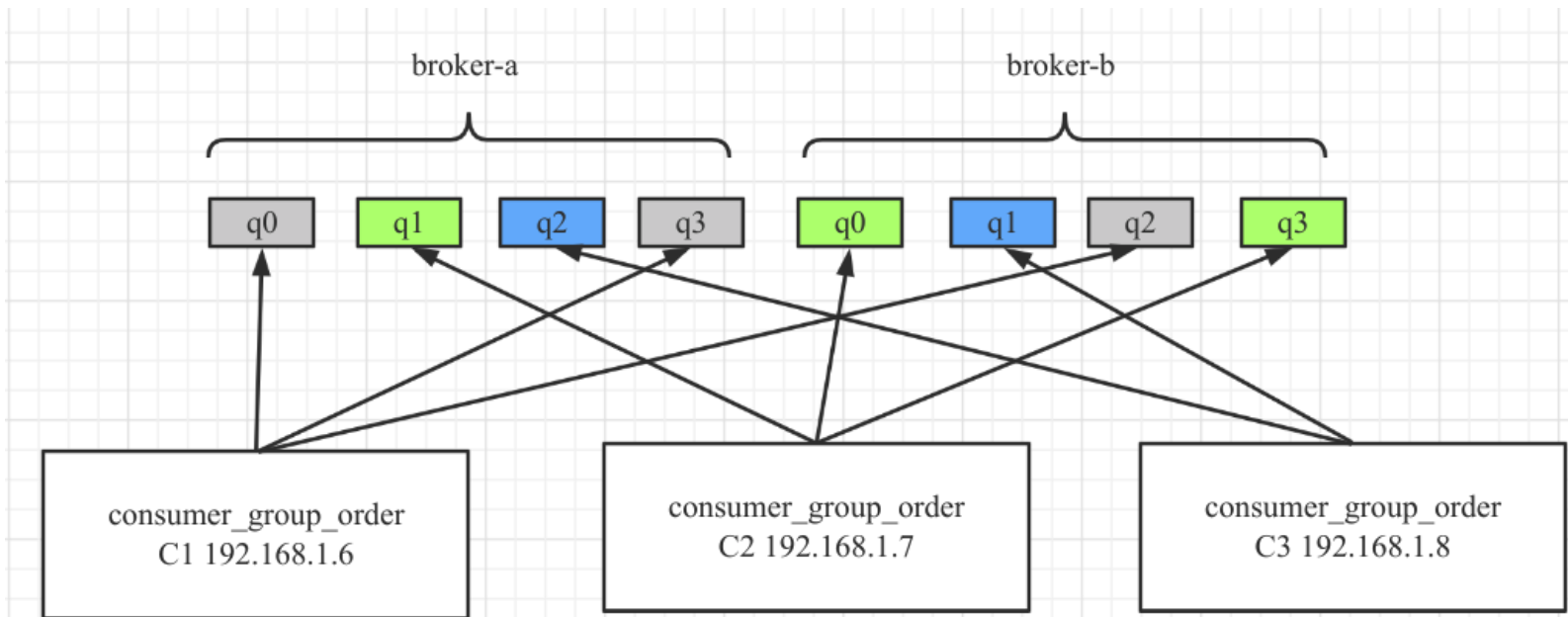
AllocateMachineRoomNearby
机房内优先就近分配。其分配示例图如下:
由于设置 consumerIdCs 为 A 机房,故 B 机房中的队列并不会消息。
AllocateMessageQueueConsistentHash
在这里并不是一个好的算法,不去描述。
负载均衡入口代码:
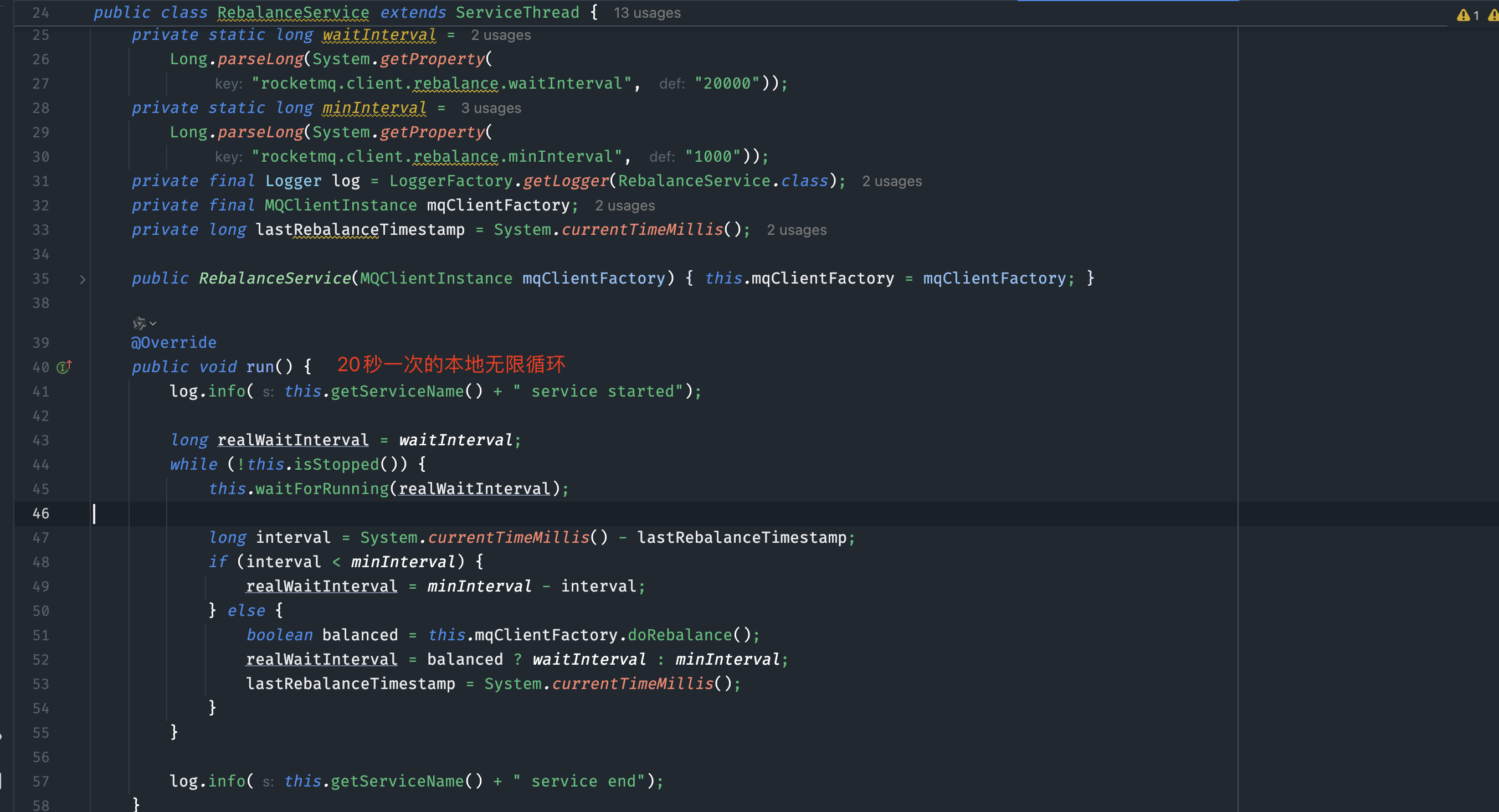
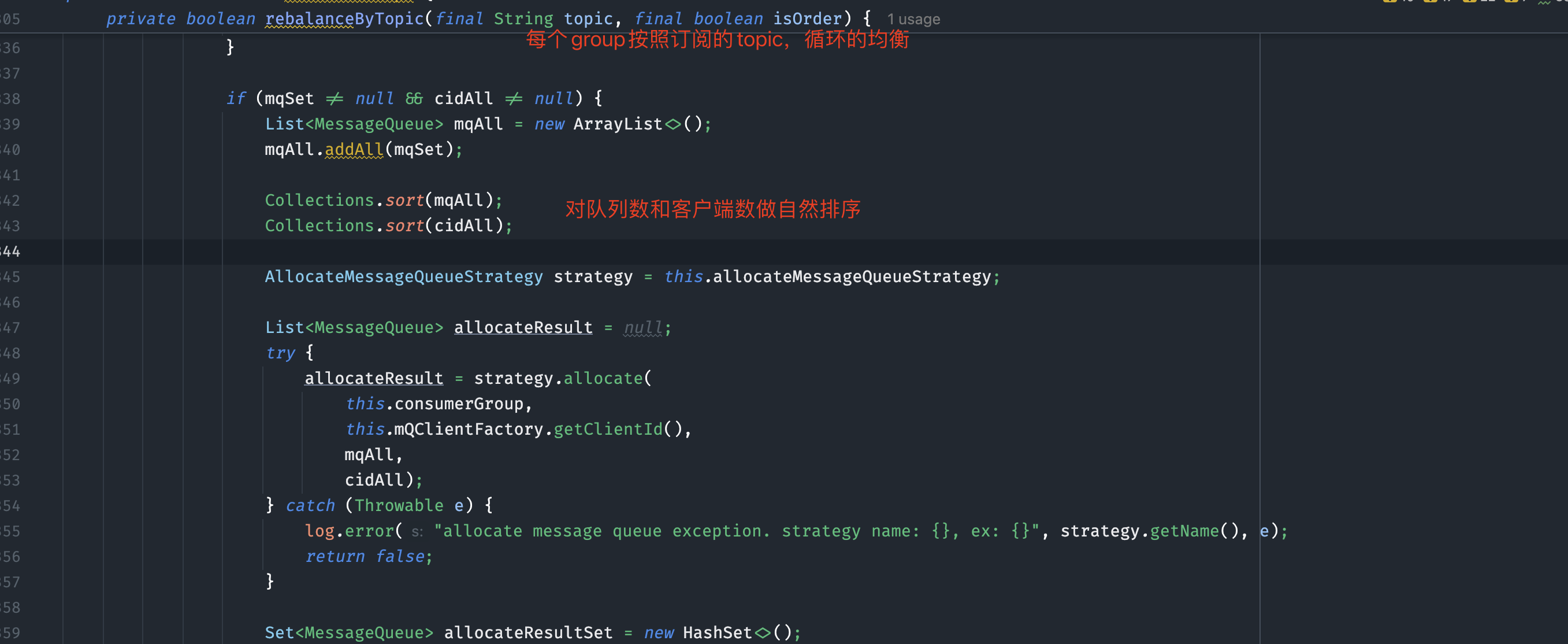
消费位点提交策略
在RocketMQ中,消息消费进度的汇报机制是一个关键设计,既要保证消息不丢失,又要尽量减少重复消费的可能性。以下是针对问题及其解决方案的详细分析:
问题描述
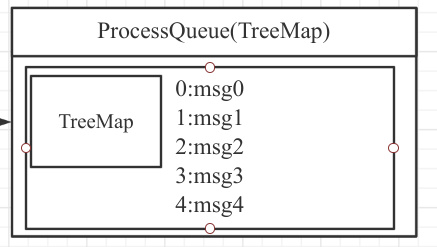
-
场景:
处理队列(ProccessQueue)中有5条消息,偏移量分别为0、1、2、3、4。线程池并发消费时,偏移量为3的消息(msg3)先于偏移量为0、1、2的消息处理完成。 -
问题:
如果直接汇报msg3的偏移量作为消费进度,当消费者异常退出并重启后,会从msg3开始消费,导致msg0、msg1、msg2丢失。
RocketMQ的解决方案
RocketMQ采用以下策略解决该问题:
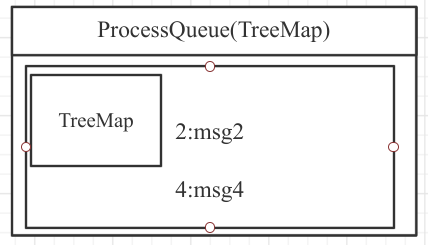
-
移除已消费消息:
消息消费完成后,将其从ProccessQueue中移除。 -
汇报最小偏移量:
-
例如,
ProccessQueue中剩余消息的偏移量为0、1、2、4,则汇报的消费进度为0。 -
这样即使消费者异常重启,也能从最小的偏移量重新消费,避免消息丢失。
-
优缺点分析
-
优点:
-
消息不丢失:通过汇报最小偏移量,确保未处理的消息不会被跳过。
-
简单高效:实现逻辑简单,性能开销小。
-
-
缺点:
-
可能重复消费:如果消费者异常重启,已处理但未汇报的消息可能会被重复消费。
-
不保证消息幂等性:RocketMQ默认不处理重复消息,需业务方自行实现幂等性。
-
消费进度提交流程
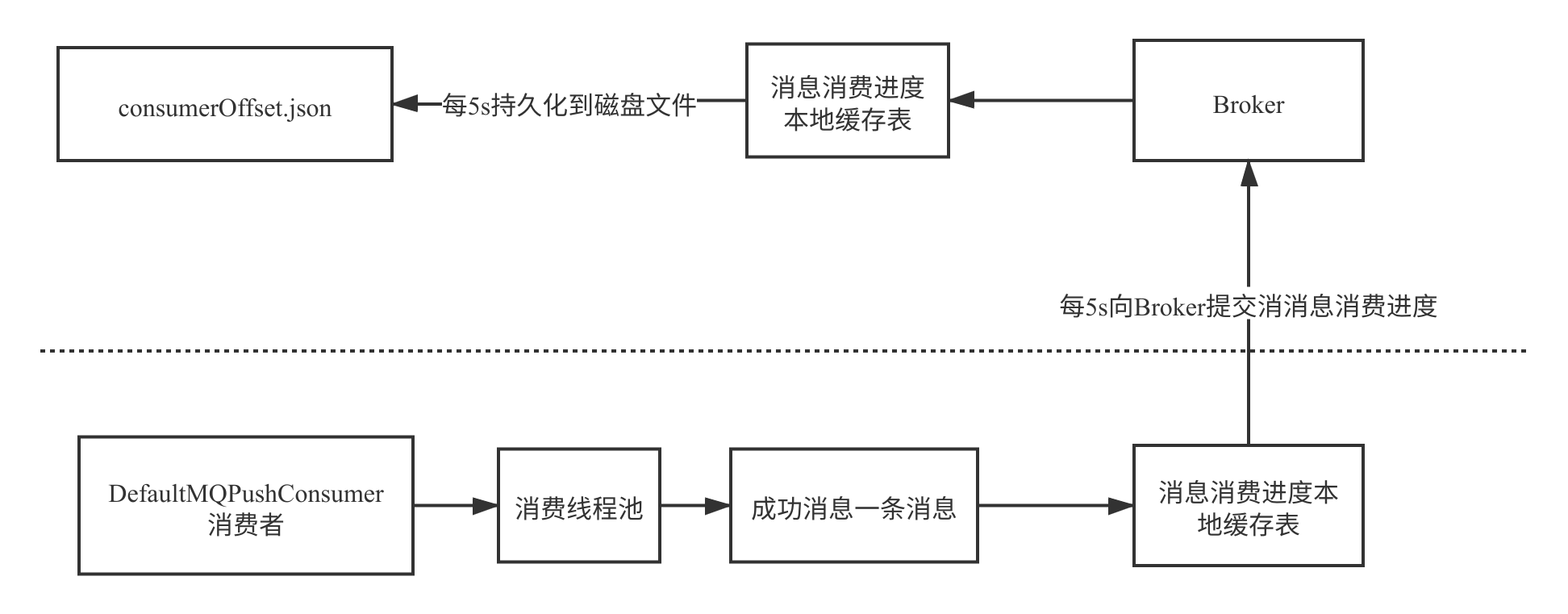
-
本地缓存:
消费进度首先存储在本地缓存表中,以减少与Broker的网络交互。 -
定时上报:
消费者定时将本地缓存中的消费进度上报到Broker。 -
Broker存储:
Broker将消费进度存储在本地缓存表中,并定时刷写到磁盘。
消息重试及死信队列
在消息队列中,消息消费并非总能成功,失败时需通过消息重试和死信队列进行补偿。
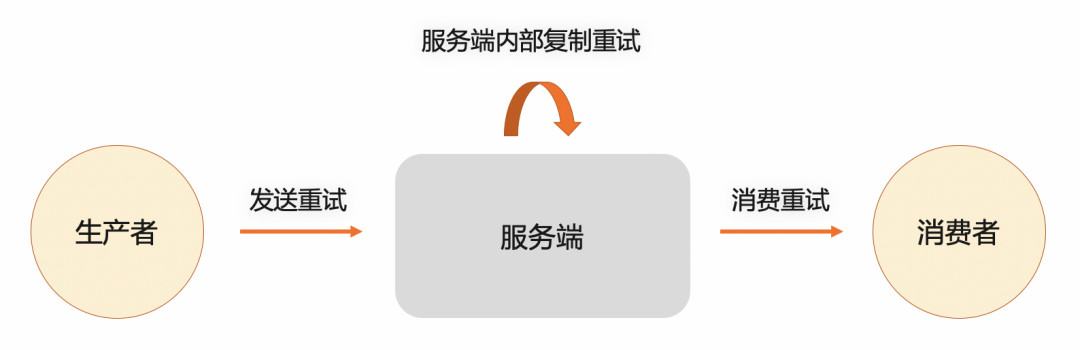
生产者消息重试
生产者在发送消息时可能因网络等问题失败,此时会触发重试机制。在 Spring Boot 中,可通过配置文件或代码设置重试次数:
- 配置文件方式:
rocketmq.producer.retry-times-when-send-async-failed=2
rocketmq.producer.retry-times-when-send-failed=2
- 代码方式:
DefaultMQProducer producer = new DefaultMQProducer();
producer.setRetryTimesWhenSendFailed(2);
producer.setRetryTimesWhenSendAsyncFailed(2);
源码实现方式:
消费者消息重试
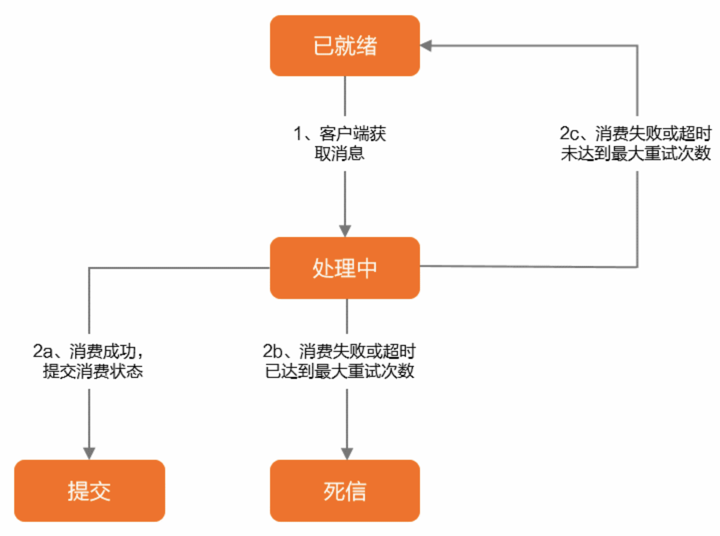
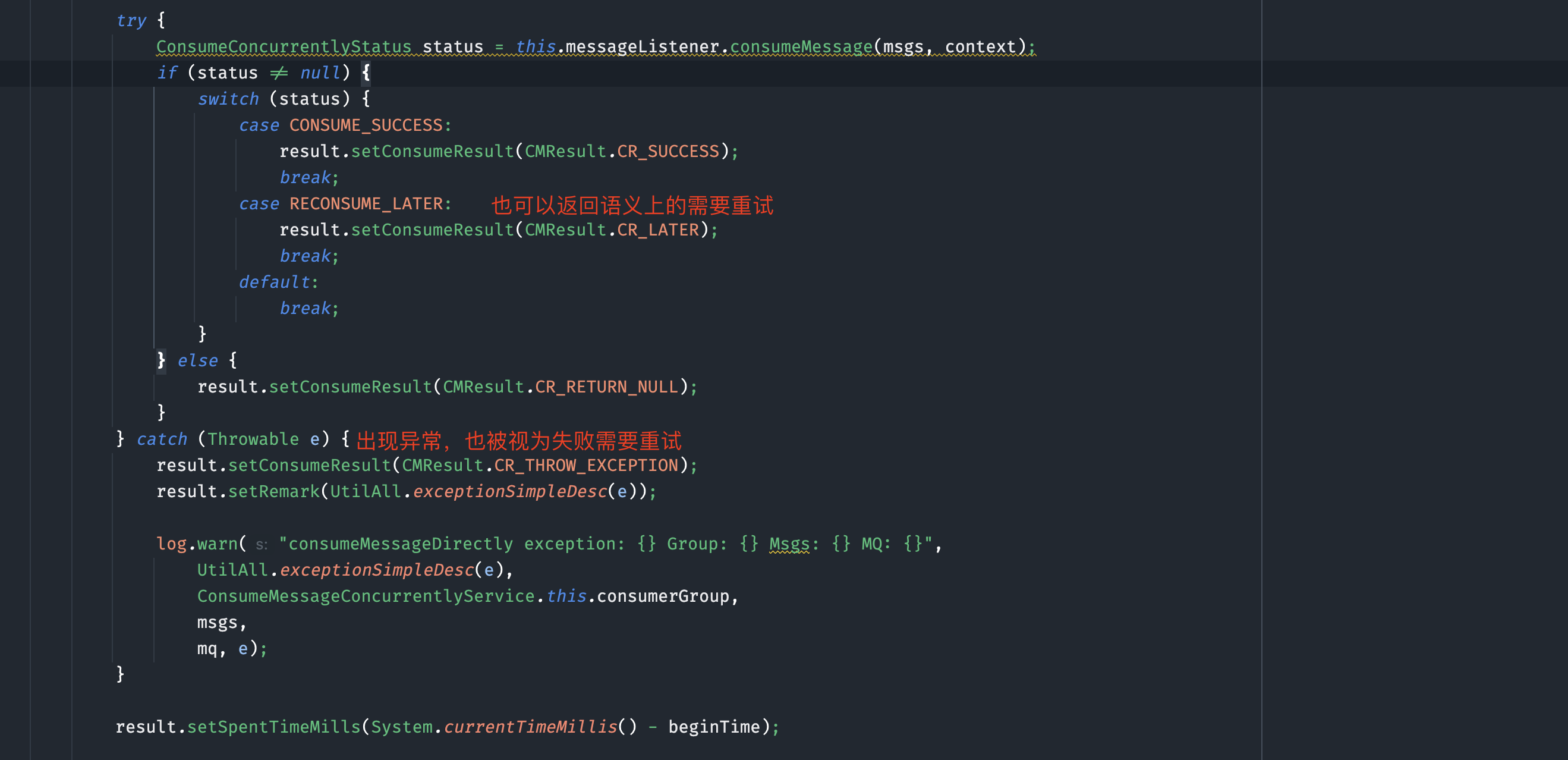
RocketMQ 支持两种消费模式:集群消费和广播消费。重试机制仅适用于集群消费,每个group不仅会消费自己订阅的消息,而且server端会统一创建一个名字为 %RETRY%{group名字}的主题,所有group消费失败的消息最终都会投递到这个主题中被group消费,而不是我们理解的原来topic中再消费一遍消息。
消费方式
-
并发消费:
-
多线程同时消费同一队列,消息顺序无法保证,也称为无序消费。
-
消费失败后,消息会被重新投递到服务端,期间继续消费后续消息。
-
失败消息会被投递到特殊 Topic:
%RETRY%ConsumerGroupName。 -
顺序消费:
-
消息按 FIFO 顺序消费,失败后会在客户端本地重试,避免打乱顺序。
-
每次重试间隔为 1 秒,需监控处理失败情况,避免阻塞。
重试默认会在服务端做阶梯式的延时,如果没有特殊设置,默认重试16次,级别如下
| 第几次重试 | 重试间隔 | 第几次重试 | 重试间隔 |
|---|---|---|---|
| 1 | 10秒 | 9 | 7分钟 |
| 2 | 30秒 | 10 | 8分钟 |
| 3 | 1分钟 | 11 | 9分钟 |
| 4 | 2分钟 | 12 | 10分钟 |
| 5 | 3分钟 | 13 | 20分钟 |
| 6 | 4分钟 | 14 | 30分钟 |
| 7 | 5分钟 | 15 | 1小时 |
| 8 | 6分钟 | 16 | 2小时 |
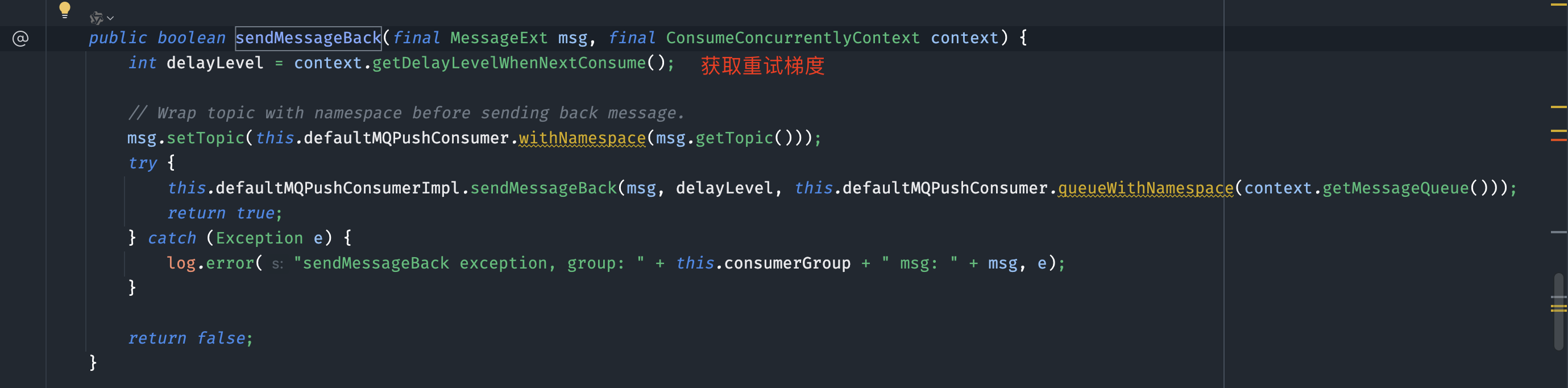
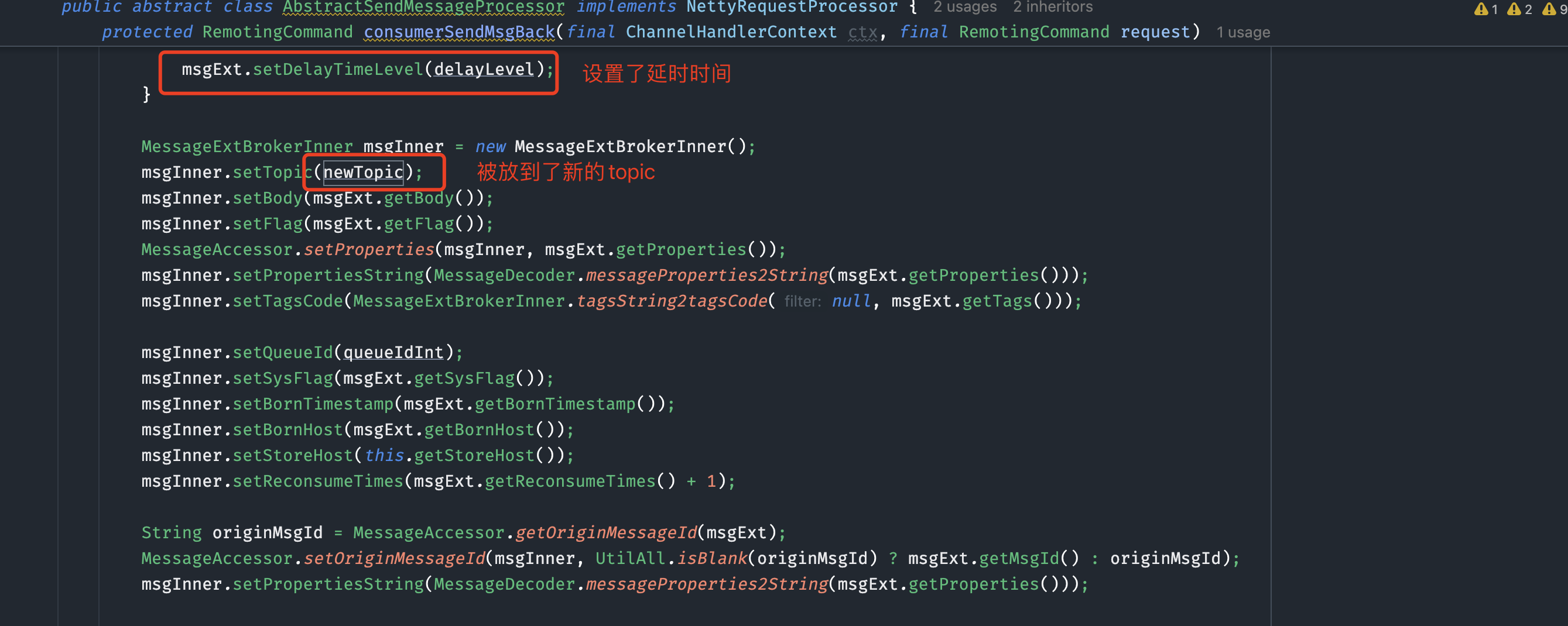
消费过程出现任何异常,或者手动返回需要重试,都会被客户端立即投递到server端,此时server端会判断这条消息当前的重试次数以及重试梯度,放到一个中转的延时topic中,等待时间到再被投递到重试topic中。
实现源码:
死信队列
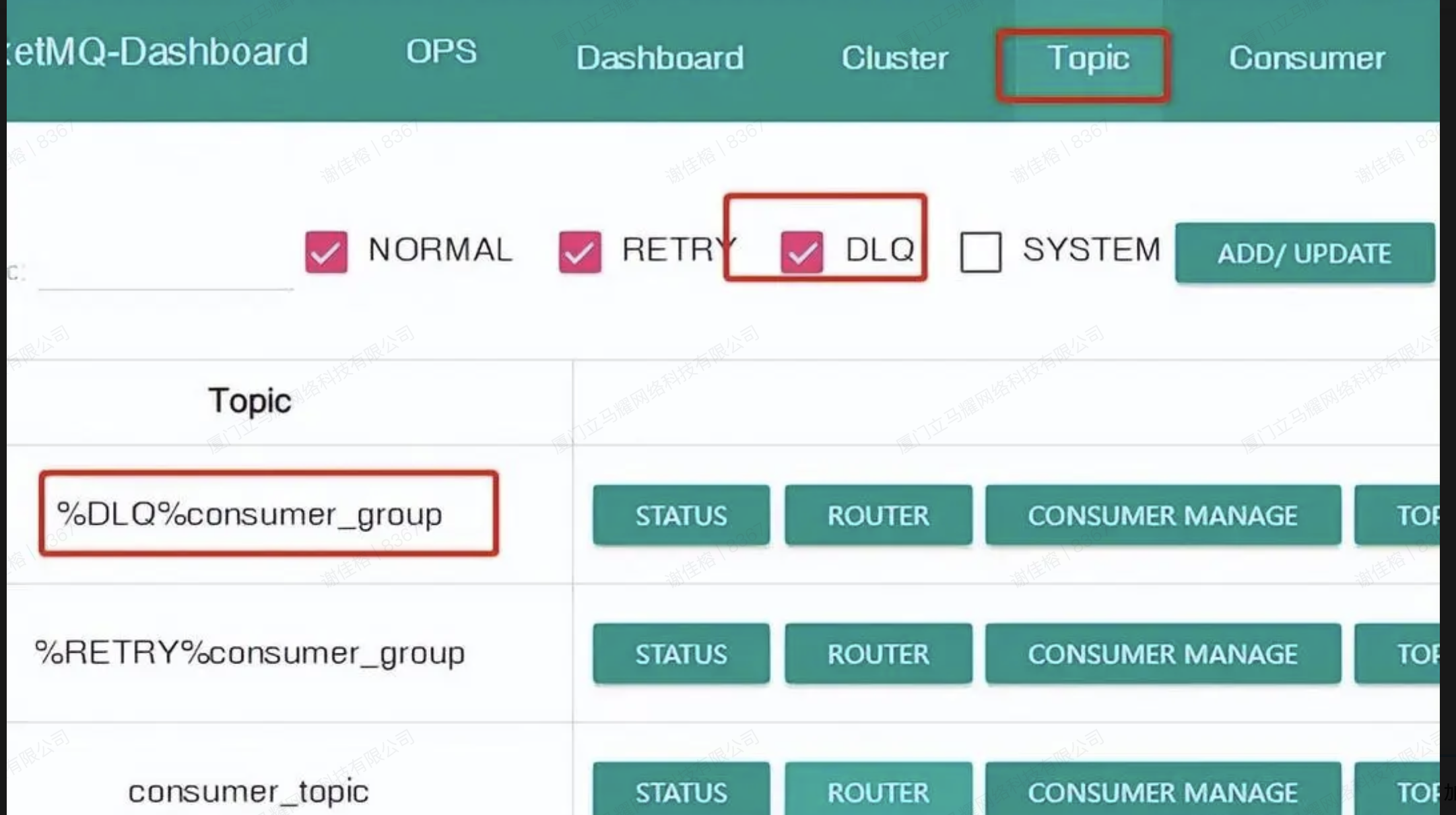
当消息达到最大重试次数仍消费失败时,会被转移到死信队列。死信队列是特殊 Topic 下的唯一队列,命名格式为 %DLQ%ConsumerGroupName。死信消息不再被消费,可通过 RocketMQ Admin 或 Dashboard 查询。
📚 章节 3:RocketMQ 的高性能设计-零拷贝
先看一下传统机械硬盘的物理存储
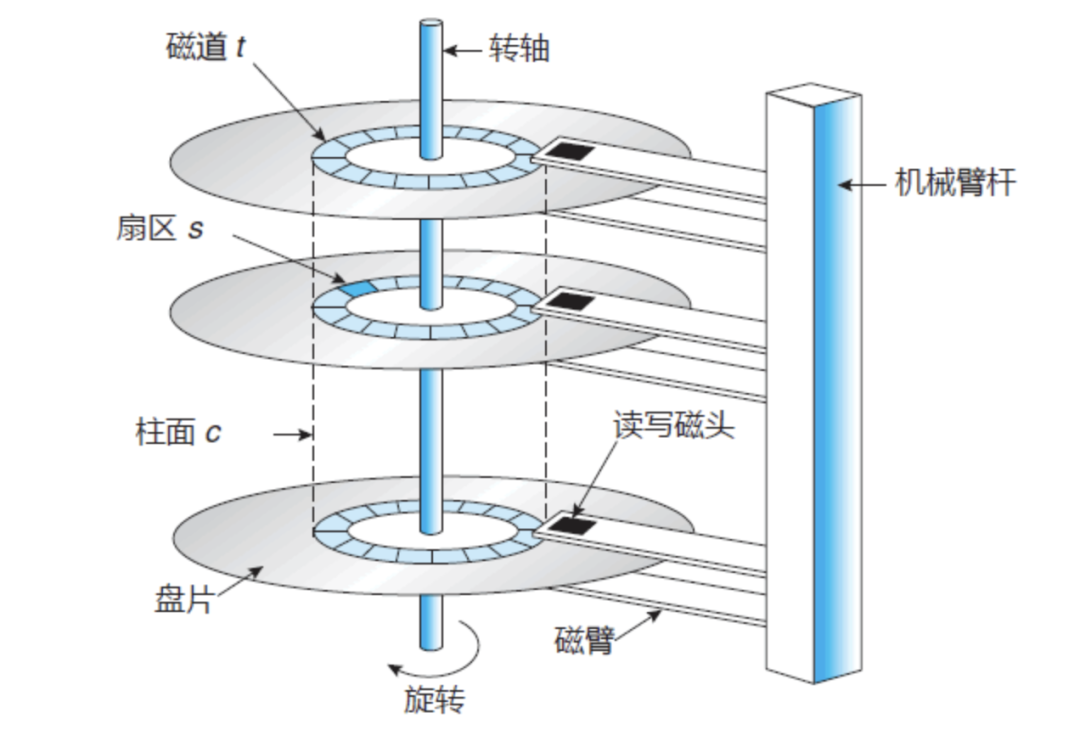
磁盘IO的时候,需要先臂杆移动磁头进行寻道(最耗时),定位到磁道后,由转轴带动磁头进行旋转寻址,定位到数据再进行读取和传输。
零拷贝在Java从业者和许多高性能中间件中,都是难以跳过的一个知识点。所谓零拷贝,并不是一次拷贝都没有,而是指计算机执行操作时,CPU 不需要先将数据从某处内存复制到另一个特定区域,从而可以减少上下文切换以及 CPU 的拷贝时间。下面花一些时间从操作系统的角度来描述一下是个怎么个事。
IO中断
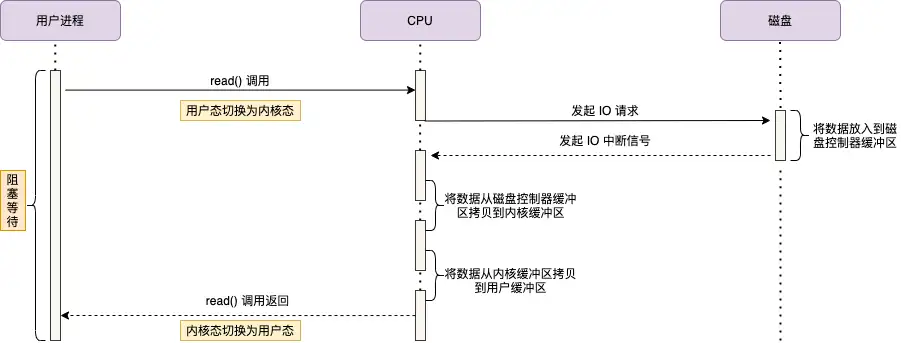
在 DMA(直接内存访问)技术出现之前,应用程序与磁盘之间的 I/O 操作完全依赖 CPU 的中断机制来完成。以下是其工作原理:
-
用户进程发起请求:
用户进程通过read系统调用读取数据,从用户态切换到内核态,并进入阻塞状态等待数据返回。 -
CPU 发起 I/O 请求:
CPU 向磁盘发送 I/O 请求,磁盘将数据存入磁盘控制器的缓冲区。 -
磁盘中断 CPU:
数据准备完成后,磁盘向 CPU 发送 I/O 中断信号。 -
数据拷贝:
CPU 将磁盘缓冲区中的数据复制到内核缓冲区,再从内核缓冲区复制到用户缓冲区。 -
状态切换与恢复:
用户进程从内核态切换回用户态,解除阻塞,等待 CPU 的下一个执行周期。
问题与瓶颈
在整个过程中,CPU 必须亲自参与数据的搬运,且在此期间无法执行其他任务。当通过千兆网卡或磁盘传输大量数据时,CPU 的资源会被大量消耗,导致效率低下。
DMA 的解决方案
DMA 技术通过引入专用的硬件控制器,允许外设(如磁盘、网卡)直接与内存交换数据,无需 CPU 参与。这显著减少了 CPU 的负担,提高了系统的整体性能。
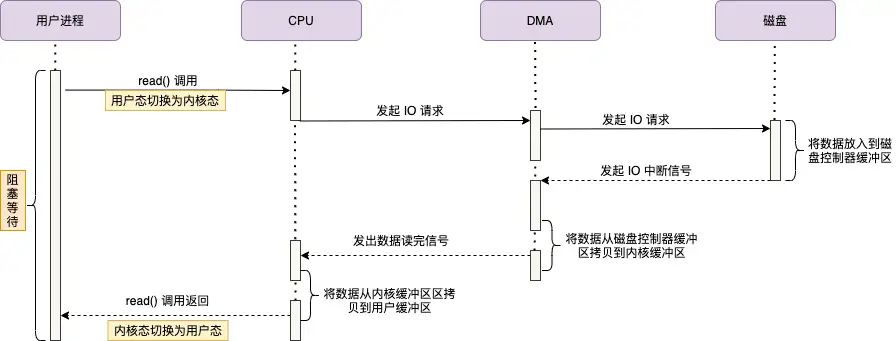
-
用户进程发起请求:
用户进程通过read系统调用读取数据,从用户态切换到内核态,并进入阻塞状态等待数据返回。 -
CPU 调度 DMA:
CPU 向 DMA 磁盘控制器发送调度指令,随后不再参与数据传输过程。 -
DMA 控制器执行 I/O:
DMA 控制器向磁盘发起 I/O 请求,将数据从磁盘拷贝到磁盘控制器的缓冲区。 -
数据拷贝到内核缓冲区:
数据读取完成后,DMA 控制器将数据从磁盘控制器缓冲区拷贝到内核缓冲区。 -
DMA 通知 CPU:
DMA 控制器向 CPU 发送信号,通知数据读取完成。 -
CPU 拷贝数据到用户空间:
CPU 将数据从内核缓冲区拷贝到用户缓冲区。 -
状态切换与恢复:
用户进程从内核态切换回用户态,解除阻塞,等待 CPU 的下一个执行周期。
传统的IO
下图分别对应传统 I/O 操作的数据读写流程,整个过程涉及 4 次上下文切换、 2 次 CPU 拷贝、2 次 DMA 拷贝总共 4 次拷贝。
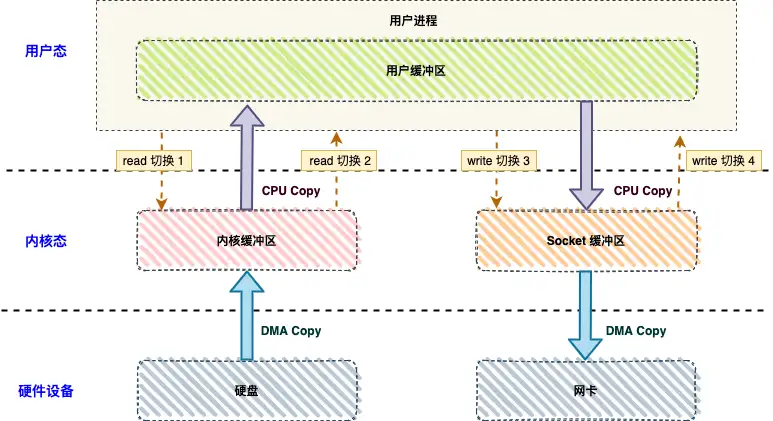
在传统文件传输中,上下文切换和数据拷贝是性能瓶颈:
上下文切换(4 次)
-
read():用户态 → 内核态 → 用户态。
-
write():用户态 → 内核态 → 用户态。
数据拷贝(4 次)
-
DMA:磁盘 → 内核缓冲区。
-
CPU:内核缓冲区 → 用户缓冲区。
-
CPU:用户缓冲区 → Socket 缓冲区。
-
DMA:Socket 缓冲区 → 网卡。
这也是rabbitmq性能低于rocketmq和kafak的主要原因之一,后两者都使用了零拷贝技术来提升IO性能。
mmap+write(RocketMQ实现方式)
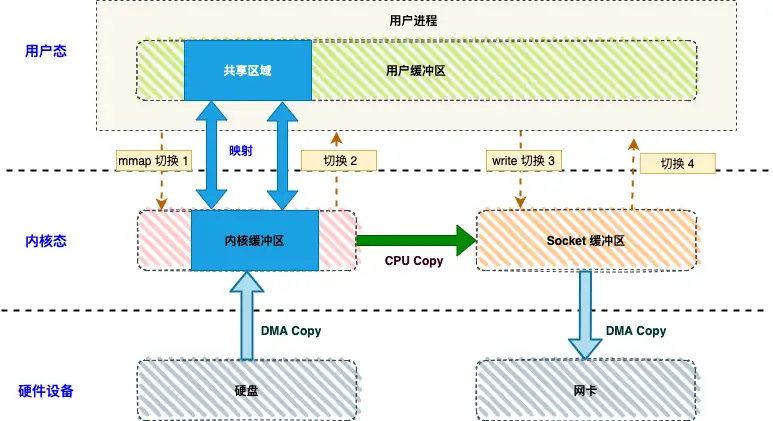
使用 mmap 进行文件读写的流程如下:
-
mmap 系统调用:
-
用户进程调用
mmap(),从用户态切换到内核态。 -
内核将用户空间的缓冲区与内核读缓冲区进行内存映射。
-
CPU 使用 DMA 将数据从磁盘或内存拷贝到内核读缓冲区。
-
切换回用户态,
mmap返回。
-
-
write 系统调用:
-
用户进程调用
write(),从用户态切换到内核态。 -
CPU 将读缓冲区的数据拷贝到网络缓冲区。
-
DMA 将数据从网络缓冲区拷贝到网卡进行传输。
-
切换回用户态,
write返回。
-
mmap+write使得整个数据传输减少了一次CPU拷贝(内核数据->应用缓冲区),跳过用户态,应用程序可以使用虚拟内存直接映射到文件,只通过内存指针来访问到磁盘文件,这种使用方式高效利用了DMA和操作系统缓存,相比较RabbitMQ的传统IO操作极大的提供了数据传输性能,但是对于文件大小有一些限制(如RocketMQ CommitLog使用mmap映射日志文件固定是1个G)。
sendfile(Kakfa实现方式)
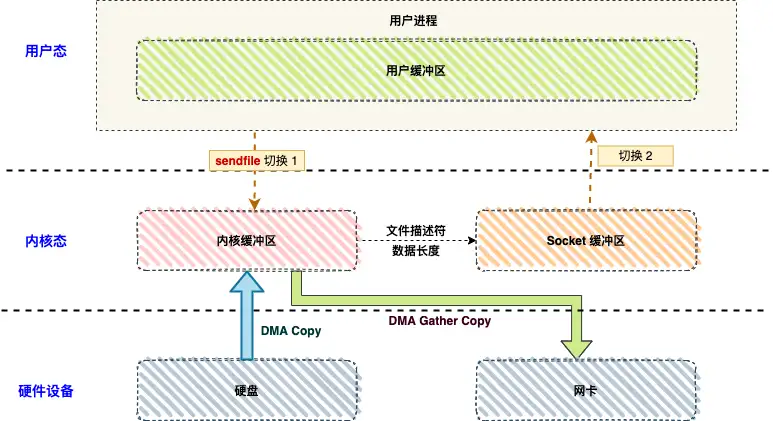
基于 sendfile + DMA gather copy 的零拷贝方式,文件传输流程如下:
-
sendfile 系统调用:
- 用户进程调用
sendfile(),从用户态切换到内核态。
- 用户进程调用
-
DMA 拷贝:
- CPU 使用 DMA 将数据从磁盘或内存拷贝到内核读缓冲区。
-
文件描述符与长度拷贝:
- CPU 将读缓冲区的文件描述符和数据长度拷贝到网络缓冲区。
-
DMA gather 拷贝:
- 基于文件描述符和数据长度,DMA 控制器将数据从读缓冲区直接批量拷贝到网卡。
-
状态切换:
- 从内核态切换回用户态,
sendfile返回。
- 从内核态切换回用户态,
性能优势
-
上下文切换:2 次(
sendfile调用和返回)。 -
CPU 拷贝:0 次。
-
DMA 拷贝:2 次(磁盘到内核缓冲区,内核缓冲区到网卡)–DMA比CPU拷贝快上百倍。
而Kafka和RocketMQ在消息读写的时候,尽可能的利用了PageCache(操作系统级别的缓存,用来缓存磁盘读取的数据),所以如果消息读写频繁,基本上磁盘IO会大大减少,都是访问内存,所以在运维层面,像Kakfa、RocketMQ、ElasticSearch等高性能中间件再部署的时候往往需要大内存,假设100G,按照经验一般会预留一半给操作系统,而JVM内存只使用一半。
RocketMQ为什么不和Kafka一样使用sendfile?
既然sendfile零拷贝技术效率更高,RocketMQ早期版本也是基于Kafka java版本重写改进的,那RocketMQ为什么不用sendfile技术? 看一下两种中间件的对比:
RocketMQ mmap+write
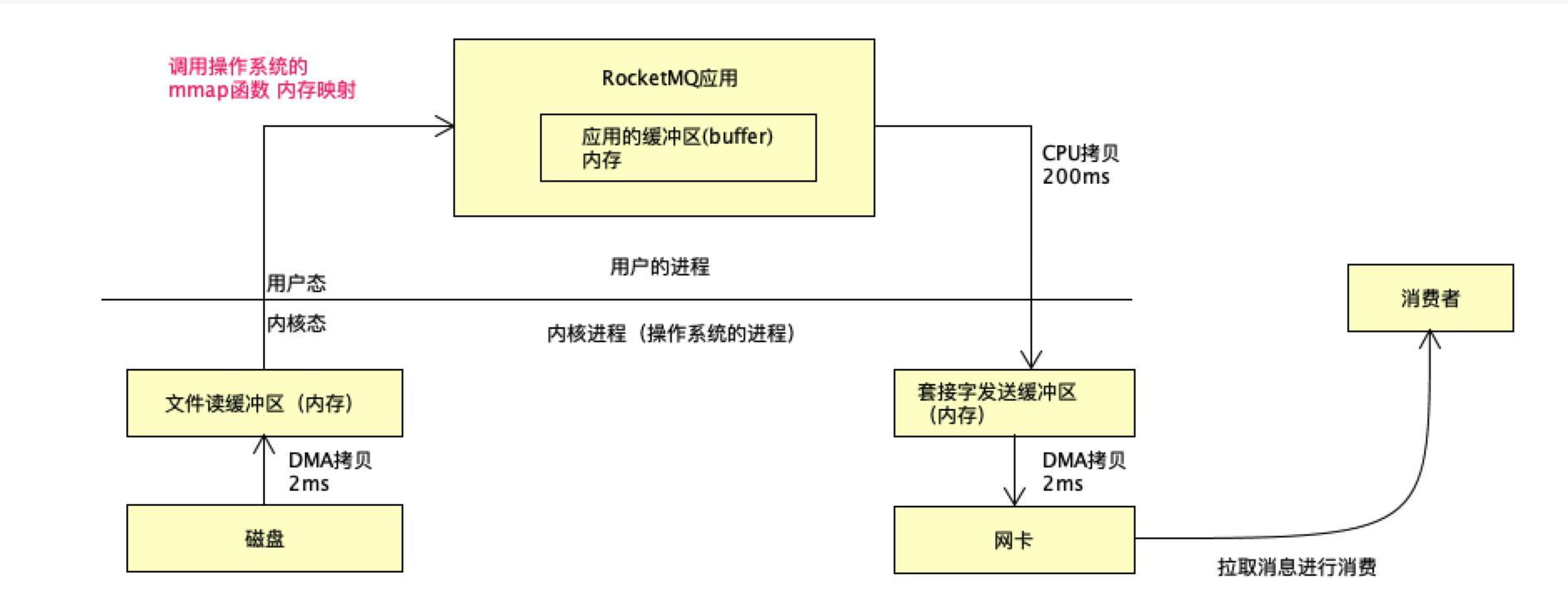
Kafka sendFile
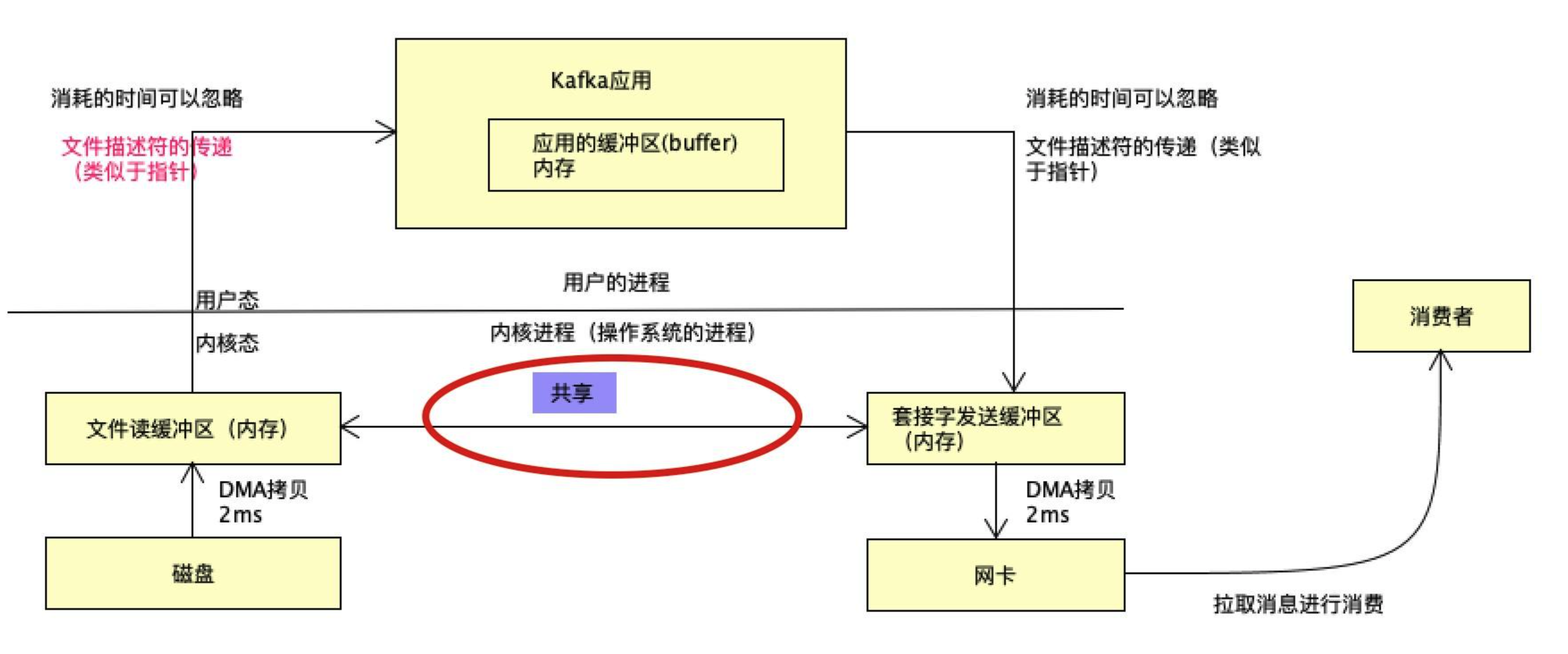
本质原因: 因为它们的设计理念不一样,Kafka更偏向于大数据场景的日志采集,要求绝对的高性能,没有太多业务上的花活,而RocketMQ为业务而生,在高性能的前提下,要尽可能满足业务上的一些高级特性:比如延迟消息、死信、事务,如果使用sendfile,相当于整个数据不过应用层,是无法实现的。
RocketMQ要支持延迟消息,数据最好要进入应用,不能单纯拿一个文件描述符做延迟消息,这也是为什么Kafka没有延迟消息的原因。
事实上: RocketMQ 使用mmap+write,结合pagecache,性能虽弱于Kafka,但对于业务来说,已经是极大够用。
📚 章节 4:RocketMQ 的高级特性
4.1 消息过滤
RocketMQ在设计上为业务赋能,增加了代表业务含义的 tag 逻辑,即一个topic发出去的消息可以打上标记,消费方消费的时候可以指定topic+tag实现精准消费,一切过滤逻辑在服务端。比如在商业化中台中,订单履约是一个非常常见的场景。交易系统经典设计流程:
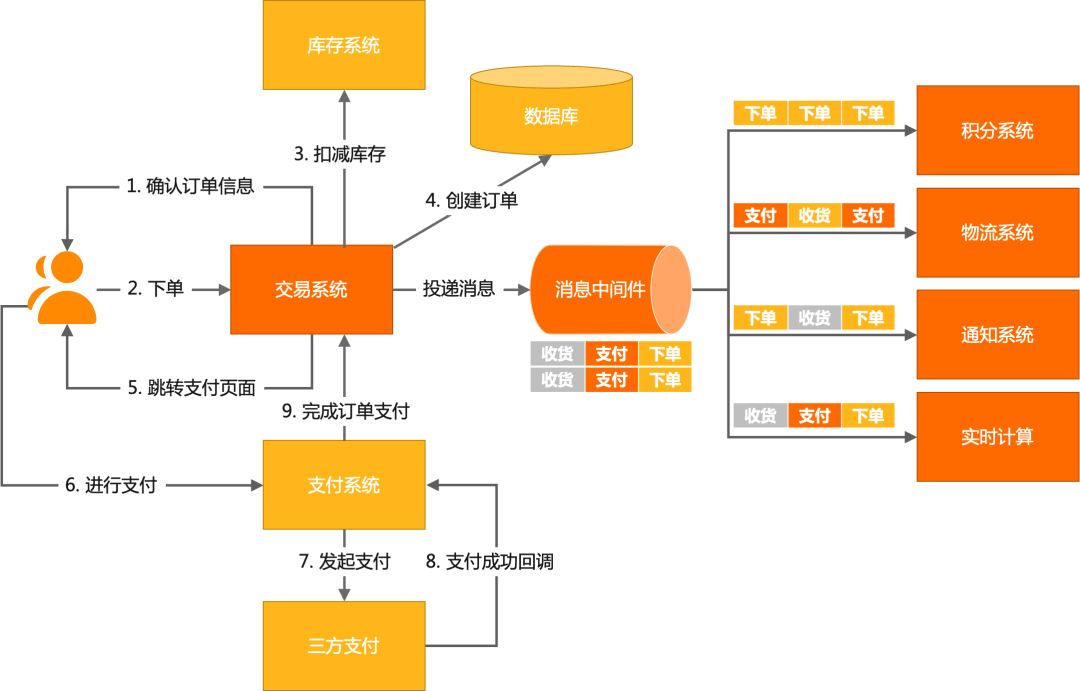
在交易链路中,订单处理流程涉及多个步骤(如下单、扣减库存、支付等),下游系统(如积分、物流、通知、实时计算)对订单消息的需求各不相同。如果没有消息过滤功能,通常有以下两种解决方案:
1. 主题拆分
-
实现方式:
将不同消息发送到不同的 Topic,例如:-
下单消息发送到
order_createTopic。 -
支付消息发送到
order_payTopic。 -
收货消息发送到
order_receiveTopic。
-
-
问题:
-
生产者成本高:需要为每个消费场景创建和维护多个 Topic。
-
消费者成本高:消费者可能需要订阅多个 Topic,增加维护复杂度。
-
顺序性无法保证:订单的下单、支付等操作需要顺序处理,但拆分后顺序性难以保证。
-
2. 消费者硬编码过滤
-
实现方式:
消费者接收所有消息,根据消息内容硬编码过滤。 -
问题:
-
网络带宽浪费:所有消息都推送到消费者,增加了网络负载。
-
资源消耗大:消费者需要在内存和 CPU 上进行大量过滤计算。
-
消息过滤的优势
消息过滤功能通过服务端实现,解决了上述问题:
-
生产者:只需向一个 Topic 投递消息,无需维护多个 Topic。
-
消费者:根据订阅规则,服务端按需投递消息,减少网络带宽和资源消耗。
-
顺序性保证:消息在同一个 Topic 中,保证了顺序性。
举例
-
积分系统:只订阅“下单”消息,服务端过滤后仅推送下单消息。
-
物流系统:只订阅“支付”和“收货”消息,服务端过滤后仅推送相关消息。
-
实时计算系统:订阅所有消息,服务端推送完整数据。
代码:
import org.apache.rocketmq.client.consumer.DefaultMQPushConsumer;
import org.apache.rocketmq.client.consumer.listener.ConsumeConcurrentlyStatus;
import org.apache.rocketmq.client.consumer.listener.MessageListenerConcurrently;
import org.apache.rocketmq.client.exception.MQClientException;
import org.apache.rocketmq.common.message.MessageExt;public class OrderConsumer {public static void main(String[] args) throws MQClientException {// 创建消费者实例,指定消费者组名DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("OrderConsumerGroup");// 设置 NameServer 地址consumer.setNamesrvAddr("localhost:9876");// 订阅订单 Topic,并指定 Tag 过滤条件// 假设订单消息的 Tag 为 "PAID" 或 "UNPAID"consumer.subscribe("OrderTopic", "PAID || UNPAID");// 注册消息监听器consumer.registerMessageListener((MessageListenerConcurrently) (msgs, context) -> {for (MessageExt msg : msgs) {// 处理订单消息System.out.printf("收到订单消息: %s, Tag: %s, Body: %s %n",msg.getMsgId(), msg.getTags(), new String(msg.getBody()));}// 返回消费状态return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;});// 启动消费者consumer.start();System.out.println("订单消费者已启动,等待消息...");}
}4.2 延时/定时消息
业务场景
正常业务中,我们经常会遇到一个常见的需求: 用户下单后30分钟未支付,该订单要关闭,库存释放。
常规的解决思路一般是两种:
-
开协程/线程,延时执行。-- 程序挂掉,业务逻辑出错。
-
起一个定时任务,定时的扫描数据库表,将大于30分钟未支付的订单关闭。-- 实现简单,但是对于DB压力较大。
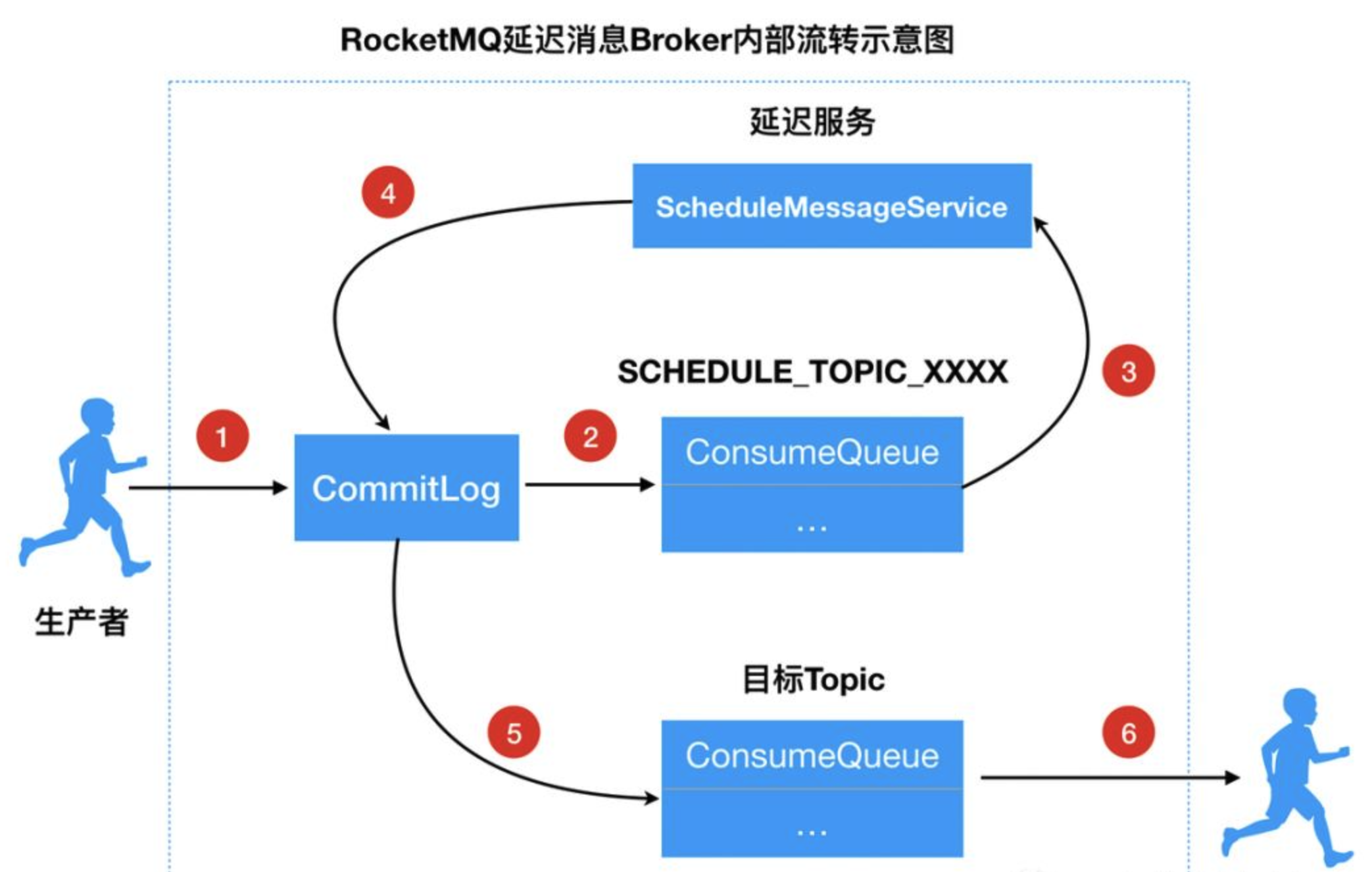
RocketMQ自带延时队列可以很好的解决这个场景,正常的消息在投递后会立马被消费者所消费,而延时消息在投递时,需要设置指定的延时级别(不同延迟级别对应不同延迟时间),即等到特定的时间间隔后消息才会被消费者消费,这样就将数据库层面的压力转移到了MQ中,也不需要手写定时器,降低了业务复杂度,同时MQ自带削峰功能,能够很好的应对业务高峰,以下是它内部实现的原理:

Message msg=new Message();
msg.setTopic("TopicA");
msg.setTags("Tag");
msg.setBody("this is a delay message".getBytes());
//设置延迟level为5,对应延迟1分钟
msg.setDelayTimeLevel(5);
producer.send(msg);
从设计上,在发送消息的时候,只需要在消息体上设置一个延时的属性即可。服务端会判断到这个属性,然后按照它的延时等级,投放到对应中转队列中,队列中的消息按延时等级递增,所以队首的消息一定是最早需要被延时的消息,等待内部定时轮询到这条消息,再投放到对应的目标队列,整个过程分成两步:
- 服务端改写topic,中转到延时队列中
- 内部定时转发到目标队列
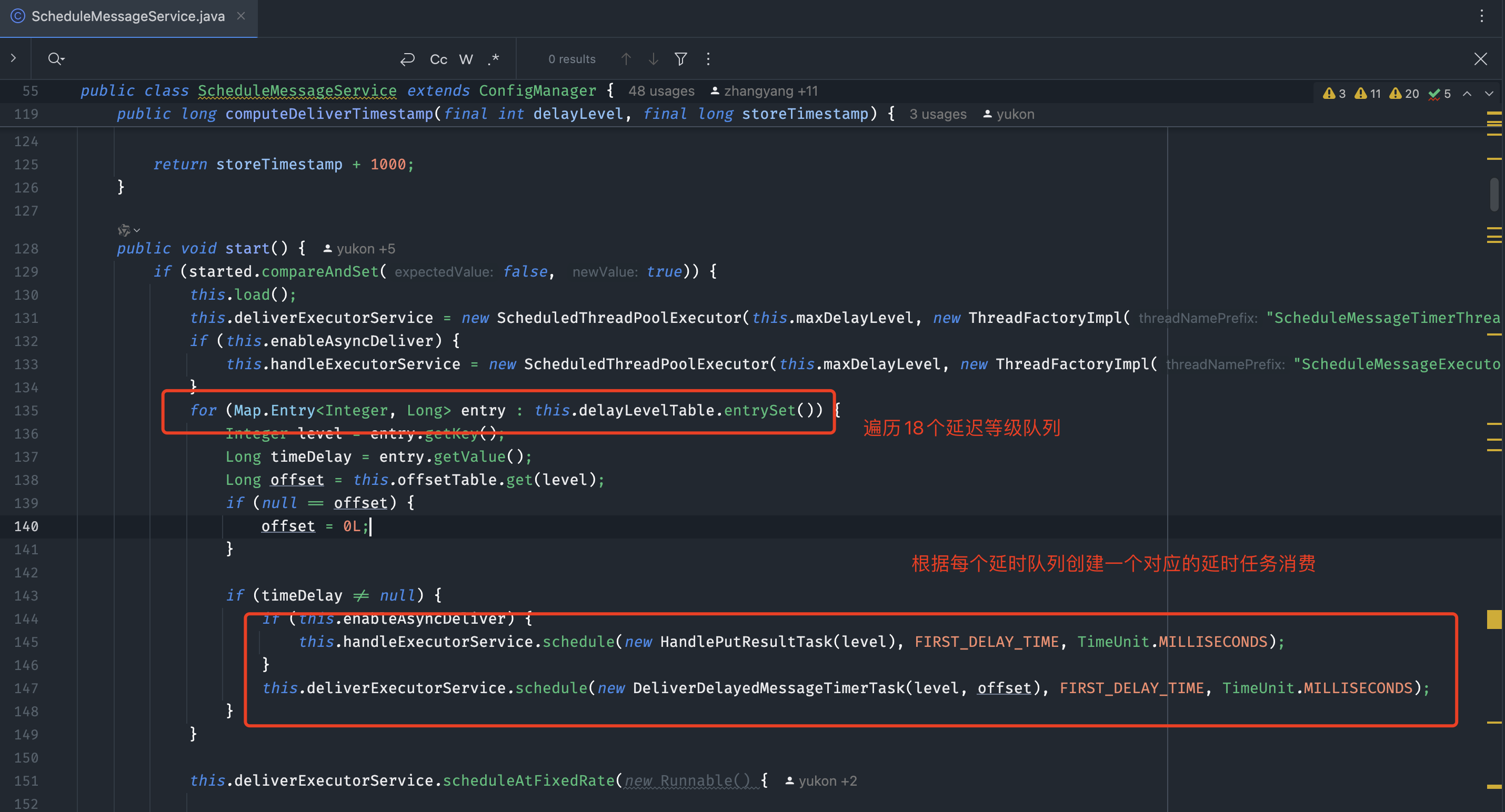
需要注意的是,每个TimeTask在检查消息是否到期时,首先检查对应队列中尚未投递第一条消息,如果这条消息没到期,那么之后的消息都不会检查。如果到期了,则进行投递,并检查之后的消息是否到期。
补充一下: 上面所提的消息重试,实际上内部就是去掉了默认18个等级的前两个实现的梯度重试,所以可以看出来,RocketMQ在设计的时候,尽可能的对公共部分做了抽象方便上层复用。但是等级延时并不能完美解决业务问题,它无法支持到秒级精度和更长延时的要求,所以5.0版本使用时间轮算法支持了大范围的定时/延时消息。
4.3 事务消息
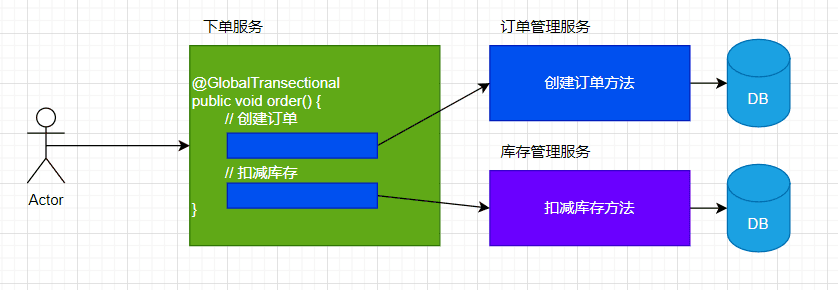
分布式事务在分布式系统中是一个很常见的难以解决的问题,从设计上来看分成三派:
-
XA协议- 从DB层来满足协议,基于2PC思想,但是对于性能有很大的损耗,且存在单点和阻塞问题
-
补偿事务: TCC/SAGA, 编写业务补偿代码拆分多个本地事务,每一个操作对应一个补偿动作,引入TC或者事件流机制来让事务流转起来,如seata–写起来比较复杂。
-
最终一致性: 允许过程中不一致,使用消息或者其他中间件,拆分整体事务,加入兜底和校验逻辑来保障最终一致性,如ebay的本地消息表、微信支付的最大努力通知机制、和接下来要说的RocketMQ的事务消息。
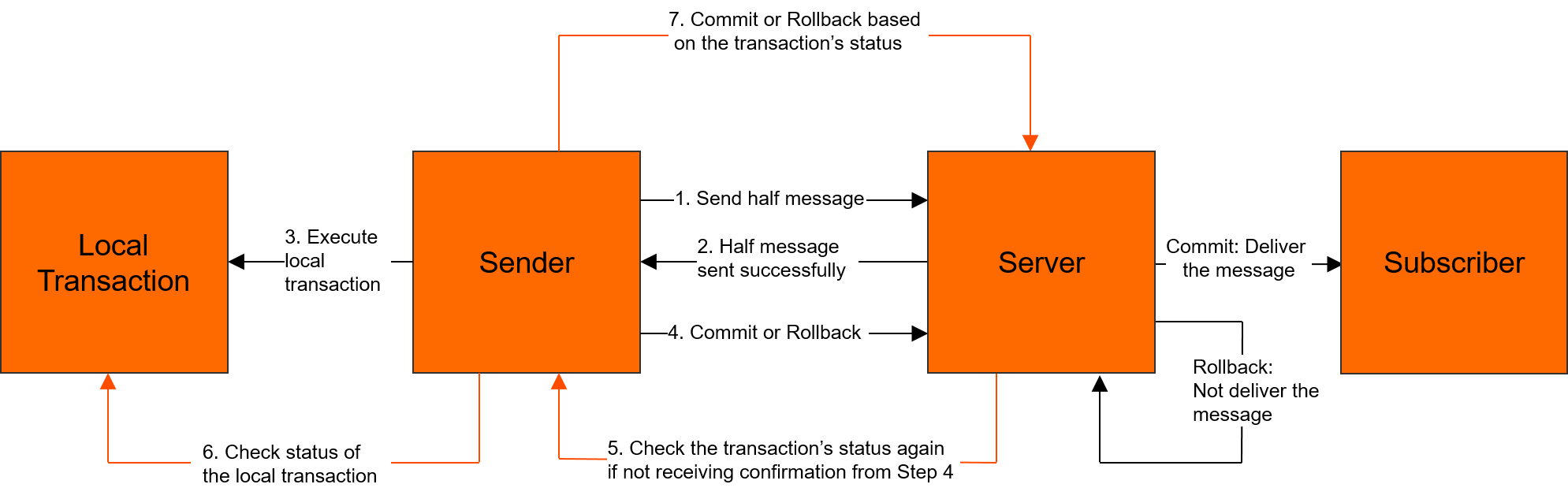
RocketMQ在设计上依然利用了"暂存队列"的思想,结合2PC-两阶段提交来保障本地事务和MQ层的原子性。
假设有一个订单支付场景:
用户支付成功后,需要发送一条消息通知其他系统(如库存系统)。
为了确保消息发送和本地事务(如更新订单状态)的一致性,使用 RocketMQ 的事务消息机制。
使用代码如下:
import org.apache.rocketmq.client.producer.LocalTransactionState;
import org.apache.rocketmq.client.producer.TransactionListener;
import org.apache.rocketmq.client.producer.TransactionMQProducer;
import org.apache.rocketmq.common.message.Message;
import org.apache.rocketmq.common.message.MessageExt;import java.util.concurrent.*;public class TransactionMessageProducer {public static void main(String[] args) throws Exception {// 创建事务消息生产者,指定生产者组名TransactionMQProducer producer = new TransactionMQProducer("TransactionProducerGroup");// 设置 NameServer 地址producer.setNamesrvAddr("localhost:9876");// 创建线程池,用于执行本地事务和回查逻辑ExecutorService executorService = new ThreadPoolExecutor(2, 5, 100, TimeUnit.SECONDS,new ArrayBlockingQueue<>(2000),r -> {Thread thread = new Thread(r);thread.setName("transaction-msg-thread");return thread;});producer.setExecutorService(executorService);// 设置事务监听器producer.setTransactionListener(new TransactionListener() {@Overridepublic LocalTransactionState executeLocalTransaction(Message msg, Object arg) {// 执行本地事务(如更新订单状态)try {System.out.println("执行本地事务,订单ID: " + new String(msg.getBody()));// 模拟本地事务成功return LocalTransactionState.COMMIT_MESSAGE;} catch (Exception e) {// 本地事务失败,回滚消息return LocalTransactionState.ROLLBACK_MESSAGE;}}@Overridepublic LocalTransactionState checkLocalTransaction(MessageExt msg) {// 检查本地事务状态(RocketMQ 会定期调用此方法进行回查)System.out.println("回查本地事务状态,订单ID: " + new String(msg.getBody()));// 假设本地事务已成功return LocalTransactionState.COMMIT_MESSAGE;}});// 启动生产者producer.start();// 创建消息,指定 Topic 和消息体Message msg = new Message("OrderTopic", "12345".getBytes());// 发送事务消息producer.sendMessageInTransaction(msg, null);System.out.println("事务消息已发送");// 关闭生产者(实际生产环境中不需要立即关闭)// producer.shutdown();}
}import org.apache.rocketmq.client.producer.LocalTransactionState;
import org.apache.rocketmq.client.producer.TransactionListener;
import org.apache.rocketmq.client.producer.TransactionMQProducer;
import org.apache.rocketmq.common.message.Message;
import org.apache.rocketmq.common.message.MessageExt;import java.util.concurrent.*;public class TransactionMessageProducer {public static void main(String[] args) throws Exception {// 创建事务消息生产者,指定生产者组名TransactionMQProducer producer = new TransactionMQProducer("TransactionProducerGroup");// 设置 NameServer 地址producer.setNamesrvAddr("localhost:9876");// 创建线程池,用于执行本地事务和回查逻辑ExecutorService executorService = new ThreadPoolExecutor(2, 5, 100, TimeUnit.SECONDS,new ArrayBlockingQueue<>(2000),r -> {Thread thread = new Thread(r);thread.setName("transaction-msg-thread");return thread;});producer.setExecutorService(executorService);// 设置事务监听器producer.setTransactionListener(new TransactionListener() {@Overridepublic LocalTransactionState executeLocalTransaction(Message msg, Object arg) {// 执行本地事务(如更新订单状态)try {System.out.println("执行本地事务,订单ID: " + new String(msg.getBody()));// 模拟本地事务成功return LocalTransactionState.COMMIT_MESSAGE;} catch (Exception e) {// 本地事务失败,回滚消息return LocalTransactionState.ROLLBACK_MESSAGE;}}@Overridepublic LocalTransactionState checkLocalTransaction(MessageExt msg) {// 检查本地事务状态(RocketMQ 会定期调用此方法进行回查)System.out.println("回查本地事务状态,订单ID: " + new String(msg.getBody()));// 假设本地事务已成功return LocalTransactionState.COMMIT_MESSAGE;}});// 启动生产者producer.start();// 创建消息,指定 Topic 和消息体Message msg = new Message("OrderTopic", "12345".getBytes());// 发送事务消息producer.sendMessageInTransaction(msg, null);System.out.println("事务消息已发送");// 关闭生产者(实际生产环境中不需要立即关闭)// producer.shutdown();}
}在使用上,消费者没有任何不同。生产者需要注册一个本地事务监听器,实现本地事务操作和事务回查的方法,只要本地事务成功,消息一定会被投递到目标队列,事务失败,消息也绝不会被发送到对应主题,而消费是否成功依赖于MQ的重试机制来保障,即可达到本地事务+MQ原子性和消费方最终一致性。
4.4 顺序消息
在资金管理系统中,资金的转入、转出、冻结、解冻等操作需要严格按照顺序记录。如果消息乱序,可能会导致资金账务不一致。
示例:
-
消息1:资金转入
-
消息2:资金冻结
如果消息2先于消息1被消费,冻结操作会失败,导致资金状态异常。此时,顺序消息就派上用场了。
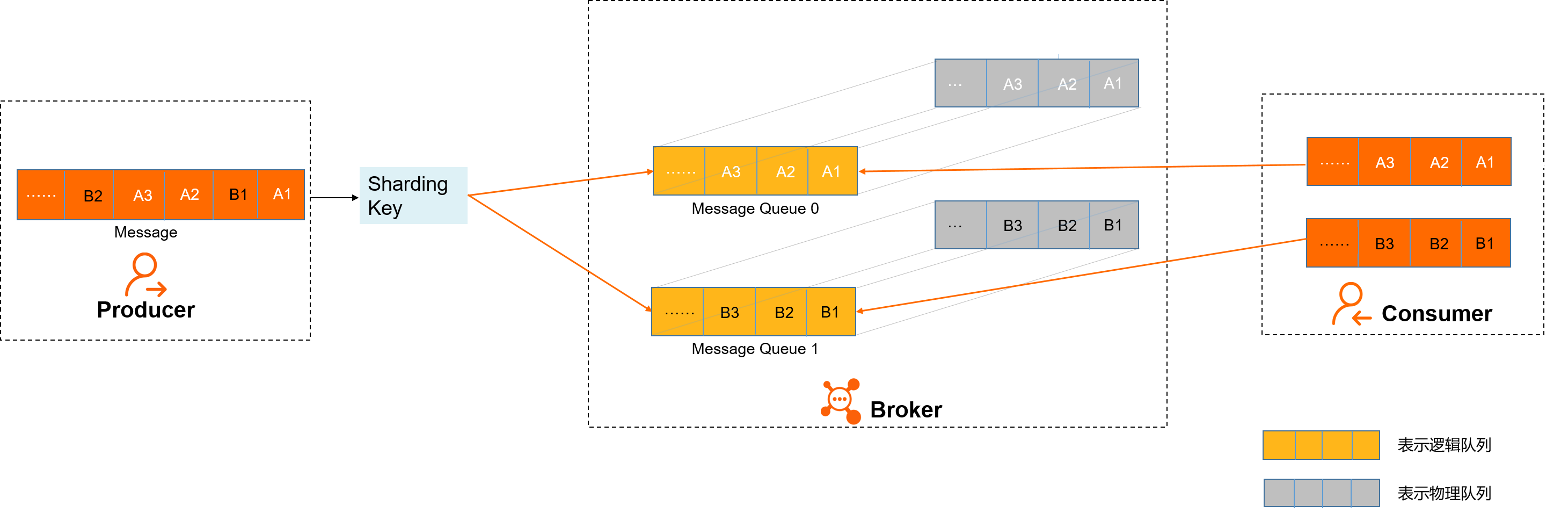
- 消息发送
如上图所示,A1、B1、A2、A3、B2、B3是订单A和订单B的消息产生的顺序,业务上要求同一订单的消息保持顺序,例如订单A的消息发送和消费都按照A1、A2、A3的顺序。如果是普通消息,订单A的消息可能会被轮询发送到不同的队列中,不同队列的消息将无法保持顺序,而顺序消息发送时云消息队列 RocketMQ 版支持将Sharding Key相同(例如同一订单号)的消息序路由到一个队列中。
云消息队列 RocketMQ 版服务端判定消息产生的顺序性是参照同一生产者发送消息的时序。不同生产者、不同线程并发产生的消息,云消息队列 RocketMQ 版服务端无法判定消息的先后顺序。
- 消息存储
如上图所示,顺序消息的Topic中,每个逻辑队列对应一个物理队列,当消息按照顺序发送到Topic中的逻辑队列时,每个分区的消息将按照同样的顺序存储到对应的物理队列中。
- 消息消费
云消息队列 RocketMQ 版按照存储的顺序将消息投递给Consumer,Consumer收到消息后也不对消息顺序做任何处理,按照接收到的顺序进行消费。
Consumer消费消息时,同一Sharding Key的消息使用单线程消费,保证消息消费顺序和存储顺序一致,最终实现消费顺序和发布顺序的一致。
代码使用方式:
import org.apache.rocketmq.client.producer.DefaultMQProducer;
import org.apache.rocketmq.client.producer.MessageQueueSelector;
import org.apache.rocketmq.common.message.Message;
import org.apache.rocketmq.common.message.MessageQueue;import java.util.List;public class OrderedProducer {public static void main(String[] args) throws Exception {// 创建生产者实例,指定生产者组名DefaultMQProducer producer = new DefaultMQProducer("OrderedProducerGroup");// 设置NameServer地址producer.setNamesrvAddr("localhost:9876");// 启动生产者producer.start();// 模拟订单消息String[] orders = {"OrderA", "OrderB"};for (String order : orders) {for (int i = 1; i <= 3; i++) {// 创建消息,指定Topic、Tag和消息体Message msg = new Message("OrderedTopic", "TagA", (order + "-" + i).getBytes());// 发送消息,使用MessageQueueSelector确保同一订单的消息发送到同一队列producer.send(msg, new MessageQueueSelector() {@Overridepublic MessageQueue select(List<MessageQueue> mqs, Message msg, Object arg) {// 根据订单ID选择队列String orderId = (String) arg;int index = Math.abs(orderId.hashCode()) % mqs.size();return mqs.get(index);}}, order); // 传递订单ID作为参数System.out.println("Sent: " + order + "-" + i);}}// 关闭生产者producer.shutdown();}
}import org.apache.rocketmq.client.consumer.DefaultMQPushConsumer;
import org.apache.rocketmq.client.consumer.listener.ConsumeOrderlyContext;
import org.apache.rocketmq.client.consumer.listener.ConsumeOrderlyStatus;
import org.apache.rocketmq.client.consumer.listener.MessageListenerOrderly;
import org.apache.rocketmq.common.message.MessageExt;import java.util.List;public class OrderedConsumer {public static void main(String[] args) throws Exception {// 创建消费者实例,指定消费者组名DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("OrderedConsumerGroup");// 设置NameServer地址consumer.setNamesrvAddr("localhost:9876");// 订阅Topic和Tagconsumer.subscribe("OrderedTopic", "TagA");// 注册消息监听器,使用MessageListenerOrderly保证顺序消费consumer.registerMessageListener(new MessageListenerOrderly() {@Overridepublic ConsumeOrderlyStatus consumeMessage(List<MessageExt> msgs, ConsumeOrderlyContext context) {for (MessageExt msg : msgs) {System.out.println("Received: " + new String(msg.getBody()));}return ConsumeOrderlyStatus.SUCCESS;}});// 启动消费者consumer.start();System.out.println("Consumer started.");}
}实现原理
发送有序(简单,实际就是实现了本地的队列选择策略)
消费有序(复杂)
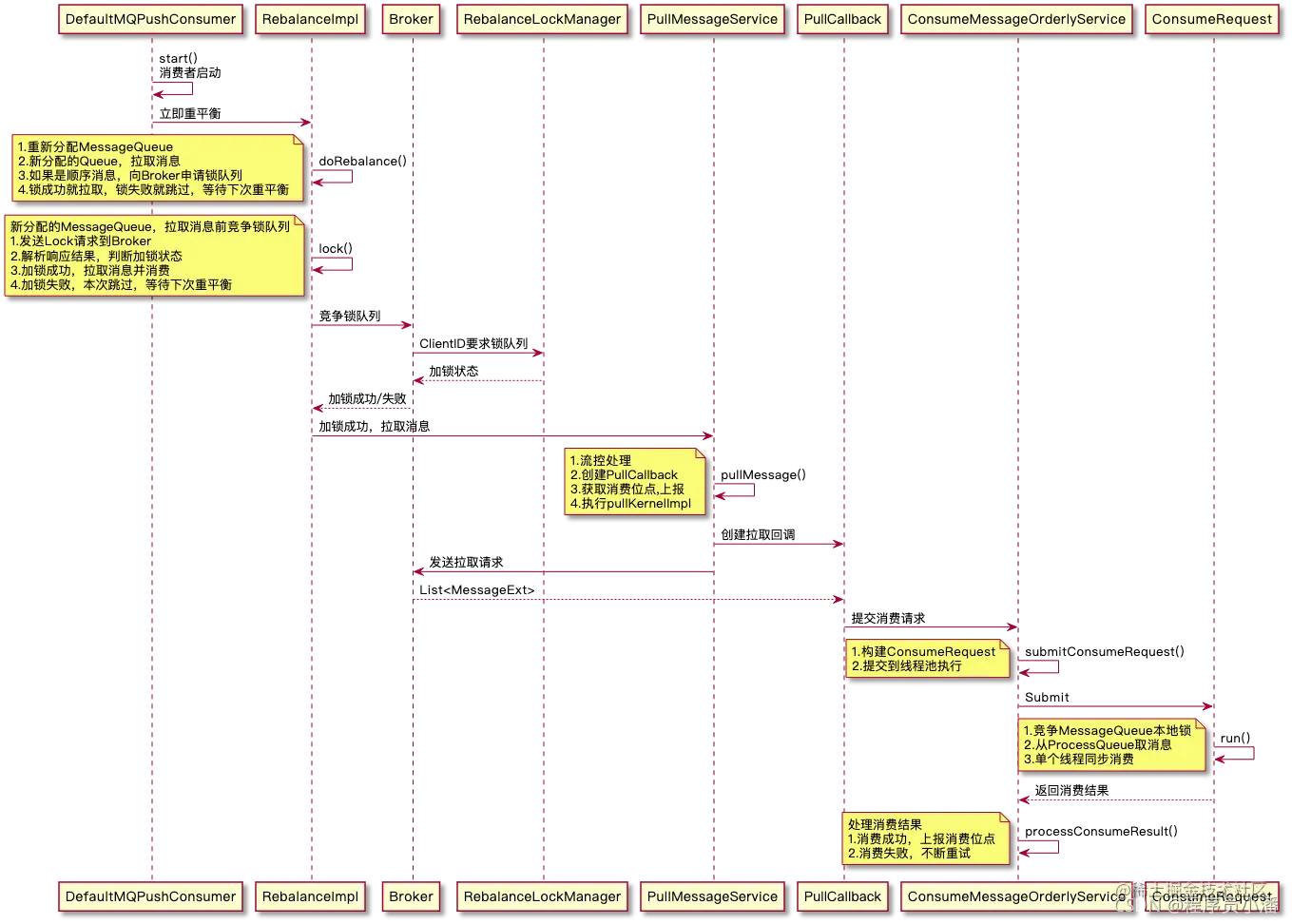
- 在系统启动时,Consumer会立即执行一次重平衡操作,为其分配MessageQueue。对于新分配的队列,Consumer会开始拉取消息。然而,在处理顺序消息时,Consumer在拉取消息前需要向Broker申请锁定队列。如果成功锁定,Consumer即可拉取并消费消息;若锁定失败,则表明该队列正被其他Consumer占用。为了确保消息的顺序性和避免重复消费,当前Consumer会暂停拉取操作,等待下一次重平衡(默认间隔为20秒)再进行尝试
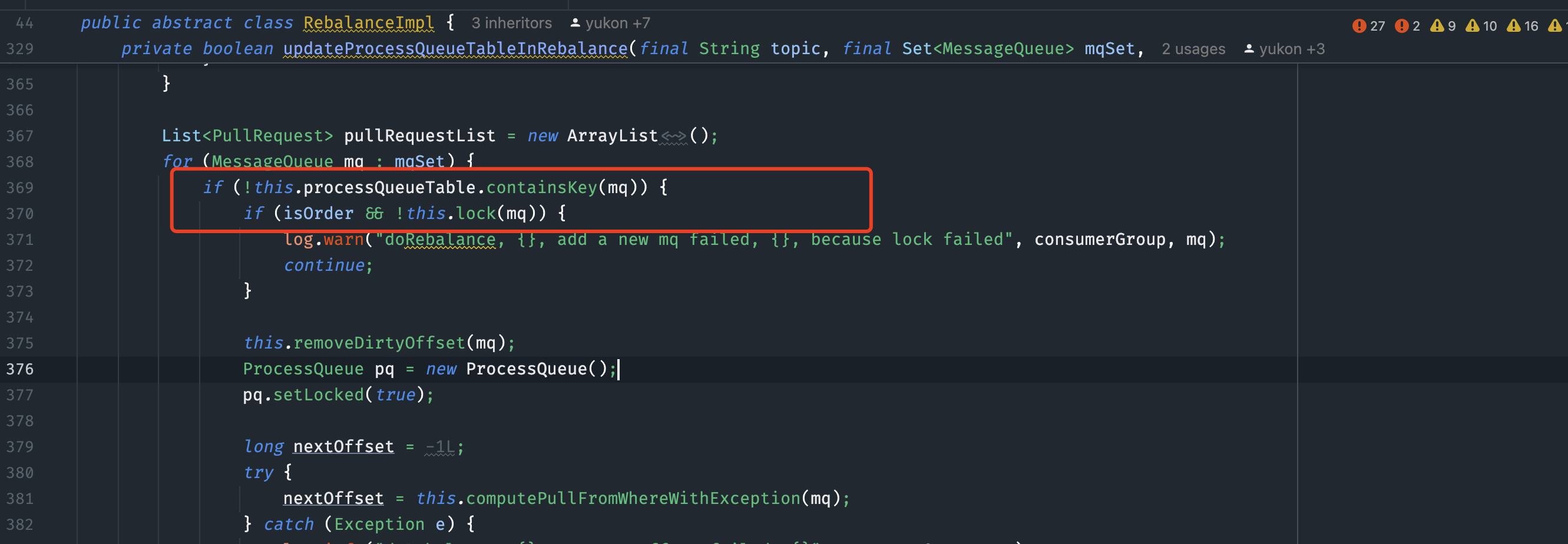
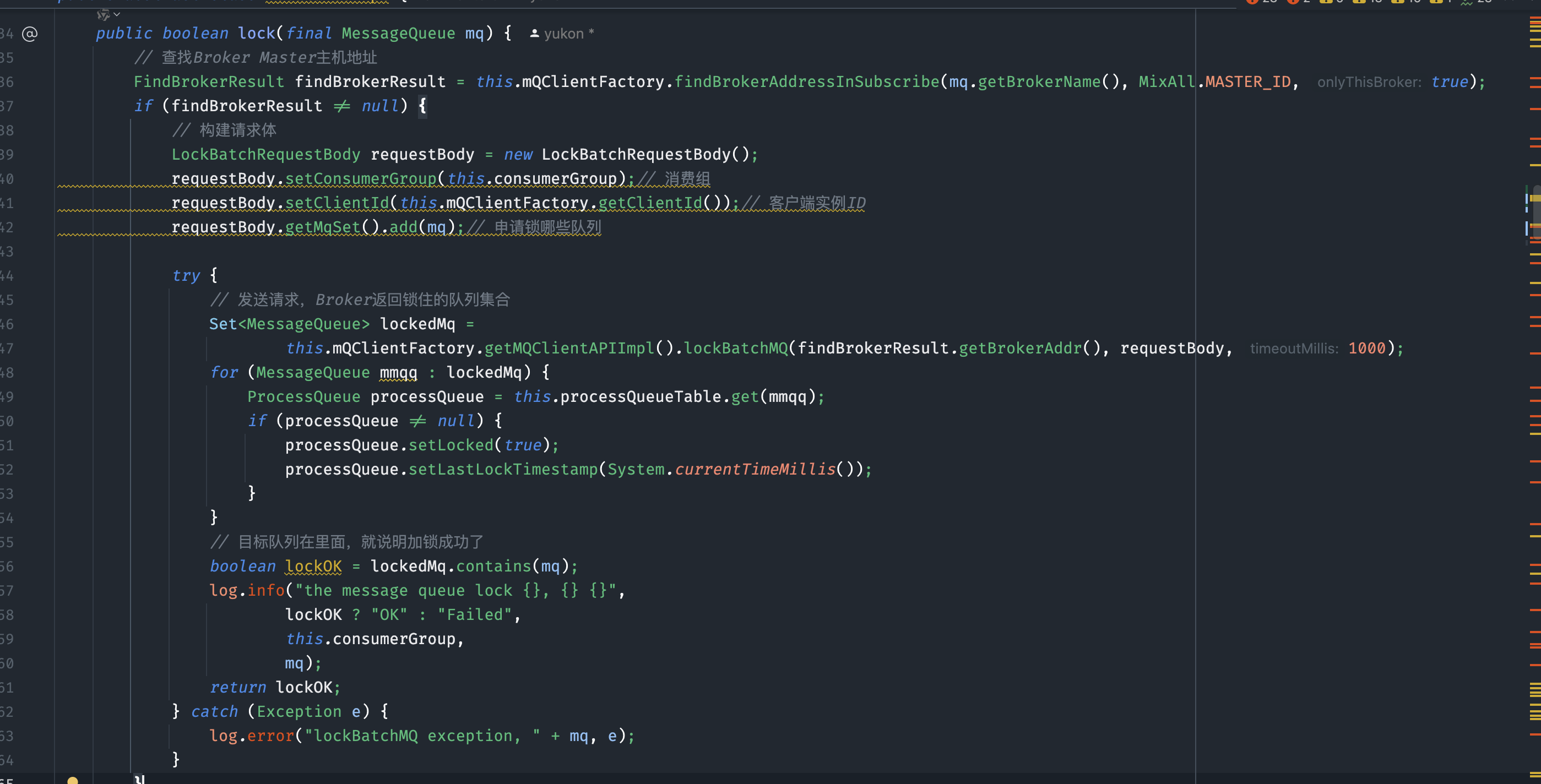
- Consumer在锁定队列时,需要向Broker发起锁请求。Broker负责维护全局的锁状态。具体流程如下:首先,Consumer会定位Broker的Master主机地址,随后构建一个锁请求体(例如
LockBatchRequestBody),其中包含消费组名称、客户端ID以及需要锁定的队列集合。接着,Consumer将请求发送给Broker。Broker处理请求后,会返回当前Consumer成功锁定的队列列表。Consumer根据返回结果判断是否加锁成功,从而决定是否继续拉取消息。
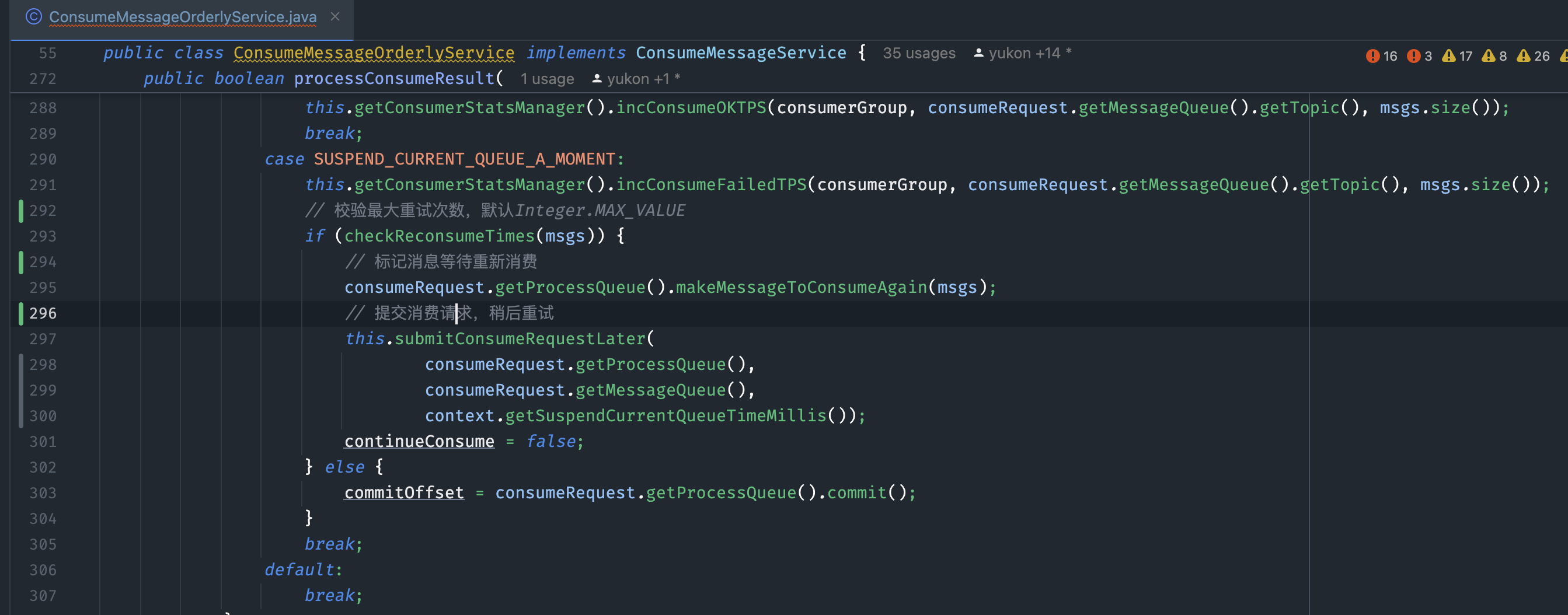
3.加锁成功,提交给OrderService处理,内部使用synchronized确保只有一个单线程来消费消息,并且丛本地重试(无法跳过)
注意点:
-
全局顺序消息实际上就是只有一个队列的topic,性能会比较差。
-
一个消费者不可以又消费顺序消息和其他消息,是互斥的。
-
本地是单线程消费,所以如果消费逻辑很重,会导致消费阻塞。
📚 章节 5:RocketMQ 常见踩坑的点
订阅关系不一致



因为我们上面说过,group端有负载均衡策略,会按照所有队列数和所有客户端数进行本地负载,因此要求一个group下的所有客户端必须保持完全一致的订阅关系,否则就会出现消息丢失、积压等危险问题。
消息堆积
消息堆积的意思是本地消费速度过慢导致队列中位点迟迟无法更新,堆积了大量待处理消息。我的建议是:
-
业务逻辑中尽量不要做太耗时的操作,如果有尽量从业务代码上做优化,提升消费性能。
-
本地可以适当调大消费线程数和机器规格。
-
业务上的正常增长,RocketMQ本身是支持PB级消息堆积的,如果需要快速消费完,可以扩容客户端来解决(4.0版本受限于队列数,而5.0 POP模式则可以无视队列限制,随意扩客户端来完成消息未读的负载均衡)
-
一些历史垃圾消息,可以通过控制台按位点或者时间戳来重置位点就能立刻解决。
消费幂等
RocketMQ的设计理念是 At Least once(至少一次),也就是说我们自身要做好业务幂等,不能依赖于中间件来保障。