【Lesson 3】CUDA 编程模型:线程、块、网格 —— Ubuntu 22.04 + RTX 30/40 系列实战
目录
0. 回顾 & 环境检查
1. 为什么需要线程/块/网格?
2. 内置变量
3. 全局线程 ID 公式
4. 实战 1:向量加法
5. 实战 2:二维图像反转(负片)
6. Nsight Compute 看线程利用率
7. 常见坑 & Debug Tips
8. 小结 & 下节预告
0. 回顾 & 环境检查
Lesson 2 我们跑通了第一个Hello World CUDA。 在继续之前,先确认一下 GPU 信息:
$ nvidia-smi $ nvcc --version
能看到类似 CUDA Version: 11.8 就 OK。接下来所有代码都在 Ubuntu 22.04 + CUDA 11.x 下验证通过。
1. 为什么需要线程/块/网格?
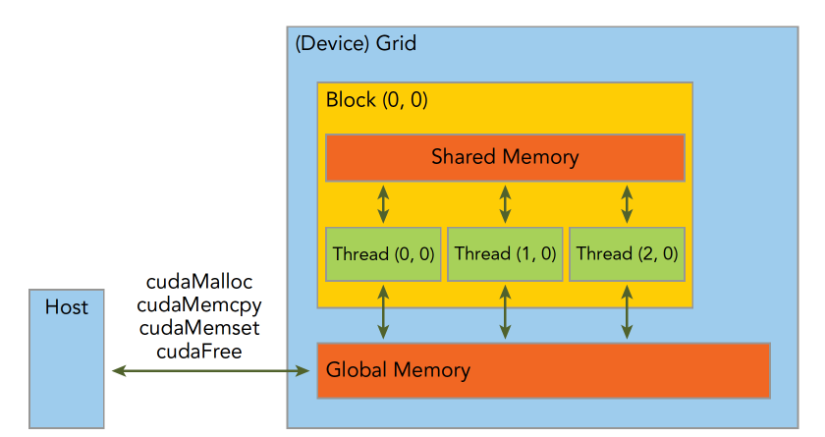
CPU 上我们用 for(i=0;i<N;i++) 串行干活;GPU 上要并行,就得把 N 个任务拆成 “线程” → “线程块” → “网格” 三层结构。
| 层级 | 英文 | 最大尺寸(Ampere) | 主要作用 |
|---|---|---|---|
| 线程 | thread | 1024/块 | 最小执行单元 |
| 线程块 | block | 1024×1024×64 | 共享内存、同步 |
| 网格 | grid | 2^31-1 个块 | 全局索引 |
一句话:grid 是“整个任务”,block 是“工作组”,thread 是“工人”。
2. 内置变量
在核函数里,CUDA 直接给你以下 dim3 变量:
threadIdx.x threadIdx.y threadIdx.z blockIdx.x blockIdx.y blockIdx.z blockDim.x blockDim.y blockDim.z gridDim.x gridDim.y gridDim.z
dim3 可以是一维、二维或三维,例如:
dim3 blockSize(16, 16); // 每块 16×16 = 256 线程 dim3 gridSize(32, 32); // 网格 32×32 = 1024 块
3. 全局线程 ID 公式
-
threadIdx:线程在 当前 block 中的索引 -
blockIdx:当前线程块在 网格 中的索引 -
blockDim:每个线程块中的线程数量 -
gridDim:网格中线程块的数量
最常见的一维情况:
int globalId = blockIdx.x * blockDim.x + threadIdx.x;
二维图像处理:
int x = blockIdx.x * blockDim.x + threadIdx.x; int y = blockIdx.y * blockDim.y + threadIdx.y; int idx = y * width + x;
4. 实战 1:向量加法
文件:vec_add.cu
#include <stdio.h>
#include <cuda_runtime.h>
__global__ void vecAdd(const float* A, const float* B, float* C, int n)
{int i = blockIdx.x * blockDim.x + threadIdx.x;if (i < n) C[i] = A[i] + B[i];
}
int main()
{int n = 1 << 24; // 16M 元素size_t bytes = n * sizeof(float);
float *h_A, *h_B, *h_C;cudaMallocHost(&h_A, bytes);cudaMallocHost(&h_B, bytes);cudaMallocHost(&h_C, bytes);
for (int i = 0; i < n; ++i) { h_A[i] = 1.0f; h_B[i] = 2.0f; }
float *d_A, *d_B, *d_C;cudaMalloc(&d_A, bytes);cudaMalloc(&d_B, bytes);cudaMalloc(&d_C, bytes);
cudaMemcpy(d_A, h_A, bytes, cudaMemcpyHostToDevice);cudaMemcpy(d_B, h_B, bytes, cudaMemcpyHostToDevice);
int threads = 256;int blocks = (n + threads - 1) / threads;vecAdd<<<blocks, threads>>>(d_A, d_B, d_C, n);
cudaMemcpy(h_C, d_C, bytes, cudaMemcpyDeviceToHost);
// 校验float maxError = 0.0f;for (int i = 0; i < n; ++i) maxError = fmax(maxError, fabs(h_C[i] - 3.0f));printf("Max error: %f\n", maxError);
cudaFree(d_A); cudaFree(d_B); cudaFree(d_C);cudaFreeHost(h_A); cudaFreeHost(h_B); cudaFreeHost(h_C);return 0;
}
编译 & 运行:
$ nvcc -o vec_add vec_add.cu $ ./vec_add Max error: 0.000000
5. 实战 2:二维图像反转(负片)
文件:img_negate.cu
#include <opencv2/opencv.hpp>
#include <cuda_runtime.h>
__global__ void negateKernel(uchar3* img, int width, int height)
{int x = blockIdx.x * blockDim.x + threadIdx.x;int y = blockIdx.y * blockDim.y + threadIdx.y;if (x >= width || y >= height) return;
int idx = y * width + x;img[idx].x = 255 - img[idx].x;img[idx].y = 255 - img[idx].y;img[idx].z = 255 - img[idx].z;
}
int main()
{cv::Mat h_img = cv::imread("lena.jpg", cv::IMREAD_COLOR);if (h_img.empty()) { printf("Load image failed\n"); return -1; }
int width = h_img.cols;int height = h_img.rows;uchar3 *d_img;cudaMalloc(&d_img, width * height * sizeof(uchar3));cudaMemcpy(d_img, h_img.data, width * height * sizeof(uchar3), cudaMemcpyHostToDevice);
dim3 block(16, 16);dim3 grid((width + 15) / 16, (height + 15) / 16);negateKernel<<<grid, block>>>(d_img, width, height);
cudaMemcpy(h_img.data, d_img, width * height * sizeof(uchar3), cudaMemcpyDeviceToHost);cv::imwrite("lena_neg.jpg", h_img);
cudaFree(d_img);return 0;
}
编译时需要 OpenCV:
$ sudo apt install libopencv-dev $ nvcc -o img_negate img_negate.cu `pkg-config --cflags --libs opencv4`
6. Nsight Compute 看线程利用率
$ ncu ./vec_add
在 ncu 报告里关注:
-
SM 利用率(%)
-
Active Threads / Active Warps
-
Occupancy(理论 vs 实际)
7. 常见坑 & Debug Tips
| 坑 | 解决办法 |
|---|---|
invalid configuration argument | blockDim.x * blockDim.y * blockDim.z > 1024 |
| 结果全 0 | 忘了 cudaMemcpy 或 kernel 没 launch |
| 性能差 | block大小不是 32 的倍数 → warps 没填满 |
| printf 没输出 | kernel 里用 printf 需要 cudaDeviceSynchronize() |
8. 小结 & 下节预告
今天我们学会了:
-
用
threadIdx/blockIdx计算全局索引 -
一维向量加法和二维图像处理
-
用 Nsight Compute 看线程利用率