逻辑回归模型:基于鸢尾花数据集的多分类任务全流程
逻辑回归(Logistic Regression)虽名为 “回归”,实则是机器学习中经典的分类算法,可用于二分类或多分类任务。本文以鸢尾花数据集为案例,从数据加载、预处理到模型训练、评估,详细讲解逻辑回归在多分类任务中的完整实现流程,并深入解析模型核心参数。
一、项目背景与核心目标
1. 数据集与任务定义
本次使用的鸢尾花(Iris)数据集是机器学习入门经典数据集,包含 150 条样本,每条样本含 4 个形态特征(花萼长度、花萼宽度、花瓣长度、花瓣宽度),目标是区分 3 种不同品种的鸢尾花(Setosa、Versicolor、Virginica),属于多分类任务。
2. 核心目标
- 构建逻辑回归模型,基于 4 个特征实现鸢尾花品种的多分类预测;
- 掌握数据标准化对逻辑回归模型的影响;
- 用多维度指标(准确率、精确率、召回率、F1 值、混淆矩阵)评估模型性能;
- 解析逻辑回归核心参数,理解参数调优的基本思路。
二、技术工具与环境准备
- 编程语言:Python 3.9
- 核心库说明:
库名 核心用途 pandas/numpy数据存储与数值计算 sklearn.datasets加载鸢尾花内置数据集 sklearn.preprocessing特征标准化(消除量纲影响) sklearn.linear_model逻辑回归模型实现 sklearn.model_selection数据集拆分(训练集 / 测试集) sklearn.metrics模型分类性能评估(准确率、混淆矩阵等)
三、逻辑回归模型实现步骤详解
1. 导入依赖库
首先导入所有需要的工具库,避免后续代码中重复引入:
# 数据处理库
import pandas as pd
import numpy as np
# 数据集加载
from sklearn import datasets
# 模型与预处理工具
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
# 模型评估指标
from sklearn.metrics import (accuracy_score, precision_score, recall_score, f1_score,confusion_matrix, classification_report
)2. 加载并理解数据集
通过sklearn.datasets直接加载内置的鸢尾花数据集,无需手动下载文件:
# 加载鸢尾花数据集
iris = datasets.load_iris()# 提取特征矩阵(X)和目标变量(y)
X = iris.data # 4个特征:花萼长度、花萼宽度、花瓣长度、花瓣宽度
y = iris.target # 目标标签:0(Setosa)、1(Versicolor)、2(Virginica)# 查看数据基本信息
print("数据集基本信息:")
print(f"特征矩阵形状:{X.shape}({X.shape[0]}条样本,{X.shape[1]}个特征)")
print(f"目标变量形状:{y.shape}")
print(f"目标标签含义:{dict(enumerate(iris.target_names))}") # 标签与品种的对应关系3. 特征标准化:消除量纲影响
逻辑回归模型基于 “特征权重” 判断类别,若特征量纲差异大(如 “花萼长度” 取值 5-7cm,“花瓣宽度” 取值 0.2-2.5cm),会导致模型过度偏向数值大的特征。因此需通过标准化将所有特征转换为 “均值 = 0,标准差 = 1” 的分布:
# 初始化标准化器
scaler = StandardScaler()# 对特征矩阵进行标准化(拟合+转换)
X_scaled = scaler.fit_transform(X)# 查看标准化后的数据(以前5个样本为例)
print("\n标准化后的前5个样本特征:")
print(pd.DataFrame(X_scaled, columns=iris.feature_names).head())标准化作用
- 使所有特征处于同一数值量级,避免模型对 “大数值特征” 过度敏感;
- 加速逻辑回归优化算法(如
lbfgs)的收敛速度,避免因数值差异导致迭代不收敛。
4. 拆分训练集与测试集
将标准化后的数据集按 “8:2” 比例拆分为训练集(用于模型拟合)和测试集(用于评估泛化能力):
# 拆分数据集:test_size=0.2表示测试集占20%,random_state=42确保结果可复现
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42
)# 查看拆分后的数据维度
print("\n拆分后数据集维度:")
print(f"训练集特征:{X_train.shape},训练集标签:{y_train.shape}")
print(f"测试集特征:{X_test.shape},测试集标签:{y_test.shape}")拆分逻辑
- 训练集:120 条样本(150×80%),用于学习特征与类别的映射关系;
- 测试集:30 条样本(150×20%),模拟 “新数据”,验证模型在未见过的数据上的表现;
random_state=42:固定随机种子,确保每次运行代码时拆分结果一致,便于调试。
5. 构建并训练逻辑回归模型
逻辑回归通过 “Sigmoid 函数” 将线性回归结果映射到 [0,1] 区间,实现分类。对于多分类任务,默认采用 “一对多(OvR)” 或 “多对多(Multinomial)” 策略(sklearn中通过multi_class参数控制)。
# 初始化逻辑回归模型
# max_iter=200:增加最大迭代次数(默认100),避免因数据复杂导致迭代不收敛
model = LogisticRegression(max_iter=200)# 用训练集训练模型(学习特征权重)
model.fit(X_train, y_train)# 查看模型核心参数(特征权重与截距)
print("\n逻辑回归模型参数:")
print(f"特征权重(4个特征对应3个类别):\n{model.coef_}") # 形状:3类×4特征
print(f"截距(3个类别对应3个截距):\n{model.intercept_}")模型参数解读
- 特征权重(coef_):每行对应 1 个类别,每列对应 1 个特征。权重绝对值越大,该特征对该类别的区分贡献越大;权重正负表示 “特征值增大时,类别概率上升 / 下降”;
- 截距(intercept_):每个类别对应 1 个截距,类似线性回归的常数项,调整类别概率的基准线;
- max_iter=200:因标准化后的数据收敛更快,此处设置 200 次迭代可确保模型收敛(若未收敛,会出现警告)。
6. 模型预测:对测试集分类
用训练好的模型对测试集特征进行预测,得到两类结果:类别标签(直接预测属于哪个类别)和类别概率(预测属于每个类别的概率):
# 预测测试集的类别标签(0/1/2)
y_pred = model.predict(X_test)# 预测测试集属于每个类别的概率(每行和为1)
y_pred_proba = model.predict_proba(X_test)# 查看前5条测试数据的预测结果
print("\n测试集前5条数据预测结果:")
result_df = pd.DataFrame({"真实标签": y_test[:5],"预测标签": y_pred[:5],"类别0概率": y_pred_proba[:5, 0].round(4),"类别1概率": y_pred_proba[:5, 1].round(4),"类别2概率": y_pred_proba[:5, 2].round(4)
})
print(result_df)预测逻辑
predict():选择概率最大的类别作为预测标签;predict_proba():返回每个样本属于 3 个类别的概率,可用于进一步分析(如 “预测置信度”)。
7. 模型评估:多维度量化性能
分类任务需从多个角度评估模型,避免单一指标(如准确率)掩盖问题(如类别不平衡)。此处使用 5 个核心指标:
#7、模型评估
accuracy = accuracy_score(y_test,y_pred)
precision = precision_score(y_test,y_pred,average = 'weighted')
recall = recall_score(y_test,y_pred,average = 'weighted')
f1 = f1_score(y_test,y_pred,average='weighted')
confusion = confusion_matrix(y_test,y_pred)
report = classification_report(y_test,y_pred)
print("accuracy:",accuracy)
print("precision:",precision)
print("recall:",recall)
print("f1:",f1)
print("confusion_matrix:",confusion)
print("report:",report)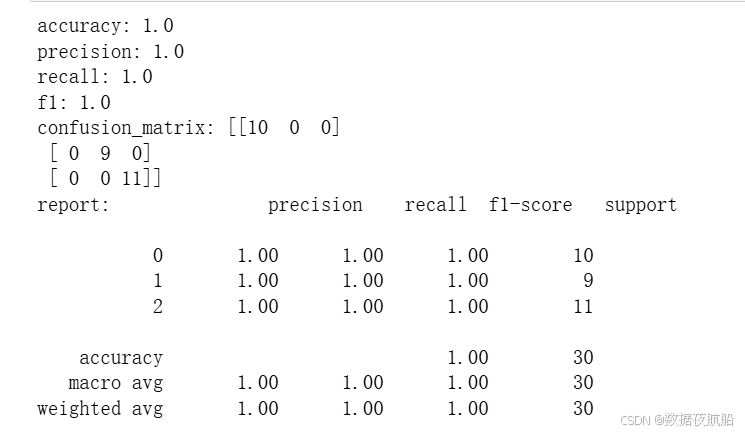
评估结果解读
Accuracy=1.0(100%):说明测试集样本全部预测正确,模型在鸢尾花数据集上表现极佳;- 混淆矩阵:对角线元素为 “预测正确的样本数”,非对角线为 “预测错误数”,若对角线全满(如
[[10,0,0],[0,9,0],[0,0,11]]),表示无错误分类; - 分类报告:每个类别的
precision/recall/f1-score均为 1.0,说明模型对所有类别都能完美区分(鸢尾花数据集特征区分度高,因此易达到该效果)。
四、逻辑回归核心参数深度解析
sklearn.linear_model.LogisticRegression的参数众多,直接影响模型性能与泛化能力。以下是关键参数的解读与调优建议:
1. 核心参数表
| 参数 | 取值范围 | 核心作用 | 调优建议 |
|---|---|---|---|
penalty | 'l2'(默认)、'l1'、'elasticnet'、'none' | 正则化类型,防止过拟合 | - 特征多且稀疏:用'l1'(会压缩部分特征权重为 0,实现特征选择)- 需平衡 L1/L2:用 'elasticnet'(需配合l1_ratio)- 数据简单:用默认 'l2' |
C | 正数(默认 1.0) | 正则化强度的倒数(C越小,正则化越强) | - 过拟合(训练准、测试差):减小C(如 0.1、0.01)- 欠拟合(训练差、测试差):增大 C(如 10、100) |
solver | 'lbfgs'(默认)、'liblinear'、'sag'、'saga' | 优化算法(求解模型参数的方法) | - 小数据集(<1 万样本):'liblinear'(仅支持二分类和 OvR 多分类)- 大数据集: 'sag'/'saga'(随机梯度下降,速度快)- 多分类(Multinomial): 'lbfgs'/'saga' |
multi_class | 'auto'(默认)、'ovr'、'multinomial' | 多分类策略 | - 二分类:'ovr'(等价于'multinomial')- 多分类: - 样本少: 'ovr'(简单,计算快)- 样本多: 'multinomial'(直接建模多类别概率,更精准) |
max_iter | 正整数(默认 100) | 最大迭代次数,确保模型收敛 | - 数据复杂 /C大(正则化弱):增大max_iter(如 200、500)- 出现 “未收敛警告” 时,优先调大此参数 |
class_weight | None(默认)、'balanced'、字典 | 类别权重,处理类别不平衡 | - 类别不平衡(如正样本占 10%,负样本占 90%):用'balanced'(按类别频率自动分配权重)- 需自定义权重:传入字典(如 {0:1, 1:10},表示类别 1 权重是类别 0 的 10 倍) |
2. 常用方法
模型训练后,可通过以下方法获取信息或进一步预测:
fit(X, y):用训练集拟合模型(核心方法);predict(X):预测类别标签;predict_proba(X):预测类别概率(可用于置信度分析);score(X, y):计算准确率(等价于accuracy_score(y, predict(X)));get_params():获取当前模型的所有参数(便于复现);set_params(**params):修改模型参数(无需重新初始化)。
五、完整可运行代码
#1、导入库
import pandas as pd
import numpy as np
from sklearn import datasets
from matplotlib import pyplot as plt
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score,precision_score,recall_score,f1_score,confusion_matrix,classification_report#2、加载数据
iris = datasets.load_iris() # 加载鸢尾花数据集
x = iris.data #特征矩阵
y = iris.target # 目标变量#3、数据处理
#特征标准化
sc = StandardScaler()
x = sc.fit_transform(x)#4、将数据拆解为测试集和训练集
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.2,random_state=42)#5、创建模型并训练模型
model = LogisticRegression(max_iter=200) # 模型迭代次数,默认是100,取值越大,迭代次数越多,越能保证模型收敛
model.fit(x_train,y_train)#6、模型预测
y_pred = model.predict(x_test)#7、模型评估
accuracy = accuracy_score(y_test,y_pred)
precision = precision_score(y_test,y_pred,average = 'weighted')
recall = recall_score(y_test,y_pred,average = 'weighted')
f1 = f1_score(y_test,y_pred,average='weighted')
confusion = confusion_matrix(y_test,y_pred)
report = classification_report(y_test,y_pred)
print("accuracy:",accuracy)
print("precision:",precision)
print("recall:",recall)
print("f1:",f1)
print("confusion_matrix:",confusion)
print("report:",report)👏觉得文章对自己有用的宝子可以收藏文章并给小编点个赞!
👏想了解更多统计学、数据分析、数据开发、机器学习算法、数据治理、数据资产管理和深度学习等有关知识的宝子们,可以关注小编,希望以后我们一起成长!