【论文阅读—智能驾驶】Diving Deeper Into Pedestrian Behavior Understanding
论文链接:https://arxiv.org/abs/2407.00446
研究问题:文章研究的是“行人行为理解”,重点关注三个方面——行人的意图估计(比如行人是不是打算过马路)、动作预测(比如行人接下来会走还是停)、以及事件风险评估(比如是否可能发生危险)。
数据和任务:作者用到了两个常见的行人数据集 JAAD 和 PIE,并在这些数据上定义和说明了这三个任务。
新的评测基准:他们提出了一个新的“评测标准”,包括三类新的指标,用来更全面地衡量模型在这些任务上的表现。
实验与比较:他们用四个最先进的预测模型(SOTA)做了实验,对比了在不同任务、不同输入信息下的表现,特别分析了“意图估计”和“动作预测”的区别,以及两者之间如何互补。
发现与结论:通过实验,他们发现了一些关于数据、任务和模型的新规律,并提出了未来研究的方向。
一句话总结:这篇论文就是在比较和评估现有模型在“行人会怎么走、打算做什么、会不会有风险”这三个问题上的表现,并提出了一个新的测试方法,让研究者更清楚这些任务的区别和互补性。
Introduction
研究背景和问题
交通安全中,预测行人行为非常重要。简单来说,就是要判断行人会不会走到车的前面。现在很多方法会用车载摄像头或传感器的视频来预测,比如行人是不是要过马路。
现有问题
任务混淆:在研究中,常常把“意图预测”(行人是不是打算过马路)和“动作预测”(行人下一步会不会真的走)混在一起用,特别是一些数据集提供了两种任务的数据之后,研究者经常把两个概念当成一样的。
风险评估不足:单纯预测“意图”或“动作”只能说明有潜在风险,但不能直接反映预测结果对车本身的实际影响。
评估方法局限:目前大多数评估方式只是计算平均准确率,但这不够。因为对于安全来说,更重要的是:
-
模型能不能提前预测?
-
预测在车辆逐渐接近行人时,能不能保持稳定一致?
-
模型结果能不能容易解释?
本文贡献
作者提出了几个新的改进点:
-
明确区分并给出“意图预测”和“动作预测”的正式定义;
-
引入一个新的任务——事件风险评估,用来衡量预测的行人行为对车辆的影响;
-
提出新的评价指标,重点考察预测的及时性、平衡性和一致性;
-
在三个任务上测试最新的模型,特别比较了意图预测和动作预测的区别、影响因素,并分析模型在两个任务上的一致性。
一句话总结:这部分介绍了行人行为预测的重要性,同时指出目前研究中“意图”和“动作”经常混为一谈,现有评估方法也不够科学。作者提出要明确区分任务、增加风险评估,并设计新指标来更真实地评价模型对交通安全的作用。
Related Work
三个任务的定义
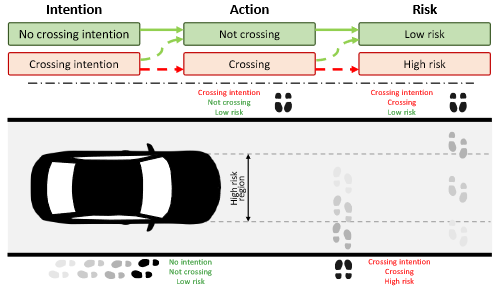
作者把“理解行人行为”拆成三个连续的任务:
-
意图估计 (Intention Estimation):行人有没有“打算”过马路(这是心理上的想法,看不见,只能通过一些迹象推测)。
-
动作预测 (Action Prediction):行人会不会真的开始过马路(这是能看见的动作,发生在未来)。
-
事件风险评估 (Event Risk Assessment):行人的动作会不会对车造成危险,比如会不会进入车的行驶路线。
换句话说:先有意图 → 再有动作 → 最后看动作是否对车有风险。
意图 vs 动作
早在19世纪,人类行为理论里就区分了“意图”和“行动”:意图是心理目标,行动是可见行为。
在智能驾驶研究里,很多论文虽然写着“意图预测”或“动作预测”,但其实大多数都是在做“动作预测”。作者在这篇论文里,严格区分这两者:
- 意图存在于现在(比如行人打算过马路)。
- 动作是即将发生的未来行为(比如行人真的走出来)。
实际上,很多系统会结合两者使用,以提高预测准确率,但作者选择单独评估,来更清楚地比较二者的区别。
事件风险评估
单纯预测行人的意图或动作,还不能直接说明“车会不会受到威胁”。
轨迹预测模型会预测行人未来的坐标点,但需要额外分析才能判断风险。
作者提出一种更直接的方法:在“车的视角”(驾驶员看到的画面里),定义一个与车身位置对齐的“风险区域”,然后判断行人未来是否会进入这个危险区域,从而评估风险。
模型与数据集
目前研究中最常用的两个行人数据集是 JAAD 和 PIE,它们包含:
-
视频(车内单目摄像头拍的)、
-
标注(行人位置、姿态、行为描述、车辆信息)。
模型会用不同的输入特征来做预测:
-
视频画面
-
行人姿态
-
行人边框位置
-
或者这些的组合。
模型评估的不足
过去的评估方法主要用分类指标:准确率、召回率、精度、AUC、F1 等。
这些方法虽然能反映整体表现,但有几个问题:
-
过于平均化:只看整体分数,掩盖了不同情况下的差异。
-
缺乏一致性分析:没法看模型在不同时间点、不同预测时长下的稳定性。
-
风险敏感度不足:没法衡量模型对不同危险级别的应对。
作者提出了新的指标,用来专门衡量模型在及时性(预测得早不早)、一致性(预测稳不稳定)、和风险敏感性方面的表现。
一句话总结:这部分回顾了已有研究,指出大家常常混淆“意图”和“动作”,风险评估也不够直接,评估方法又过于平均化。于是,作者提出要把三类任务分开,并设计新的指标,才能更真实地评价模型对安全的帮助。
Experiment Setup
实验对象
作者挑选了 4 个最先进的行人预测模型来做对比:
-
SFGRU
-
BiPed
-
PCPA
-
PedFormer
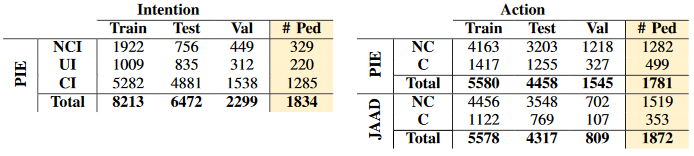
他们在两个常用的行人数据集上测试:
-
PIE
-
JAAD
数据处理
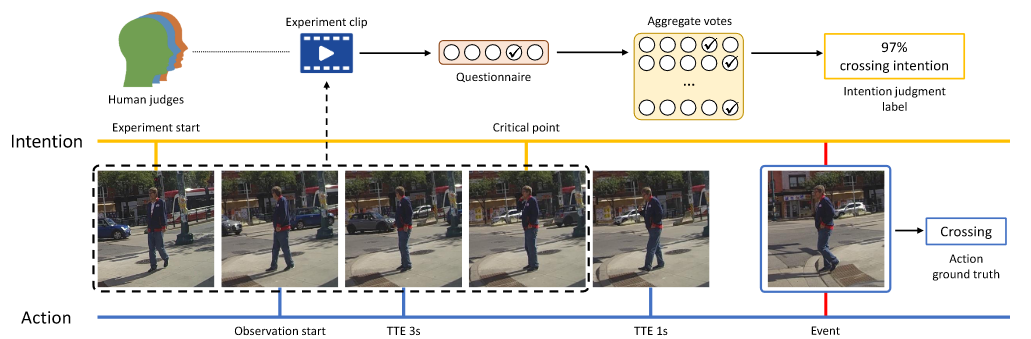
意图和动作标注
-
在 PIE 里,意图是让人类观察视频后打分(比如觉得行人是不是有过马路的想法),这些分数取平均作为“意图标签”,所以是概率性的(0~1之间)。
-
在 JAAD 里,意图只是简单的“有/没有”,但因为存在偏差,所以作者只用了 PIE 的意图数据。
-
动作(是否真的过马路)在两个数据集里都有,比较明确。
数据划分

-
每个样本的“观察时间”设为 0.5 秒(15 帧)。
-
意图预测:把 0~1 的意图分成三类:不打算过马路、不确定、打算过马路。
-
动作预测:只保留距离“开始过马路事件”还有 1~3 秒的数据。
-
风险评估:把画面分成 12 个竖直区域,代表不同风险等级(中间 = 高风险,边缘 = 低风险),预测 3 秒后的风险情况。
模型说明
-
BiPed 和 PedFormer:多任务模型,既预测行人轨迹(未来位置),也预测动作。
-
SFGRU 和 PCPA:单任务模型,只预测“会不会过马路”。
-
作者对这些模型稍微改了一下,让它们也能做意图预测和风险评估。
评价指标
(1) 基础指标
常见的分类指标:准确率(Acc)、AUC、F1、精确率(Prec)、平衡准确率(bAcc)、平均精度(mAP)。
(2) 加权指标
-
动作预测:越接近过马路那一刻越容易预测,但越早预测越有价值 → 所以给离事件更远的预测更高权重。
-
风险评估:行人出现在正前方更危险 → 所以正中间区域的预测权重更高,边缘更低。
(3) 每个行人级别的指标(稳定性)
为了衡量模型预测的一致性,作者提出了新方法:
-
Soft metrics:平均每个行人轨迹上多个片段的结果。
-
Hard metrics:如果一个行人轨迹中有一次预测错了,就算整体错。
-
Confidence delta:看模型对同一个行人的预测置信度,随时间是不是波动很大。
Evaluation: Intention and Action
模型在基准测试上的表现
意图预测 (Intention Estimation)

-
SFGRU 在区分不同行人意图方面表现最好,特别是它的 soft precision(精度)比第二名高 33%。
-
不过所有模型在 一致性(hard metrics) 上都很差,也就是说,同一个行人的预测结果经常波动。
-
在稳定性指标(conf∆,置信度变化)上,SFGRU 波动最小,所以算是最稳定。
动作预测 (Action Prediction)
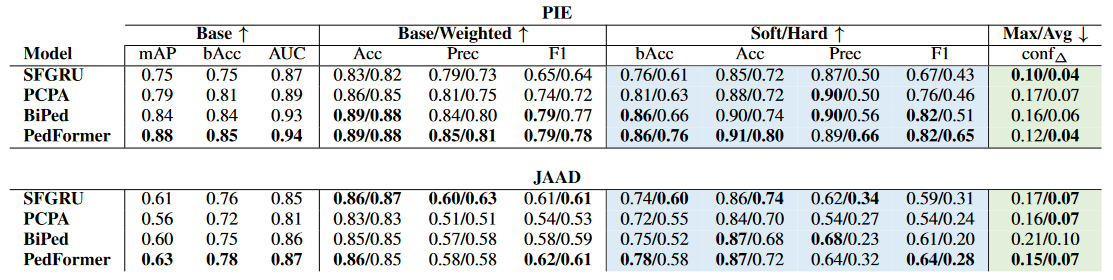
-
在 PIE 数据集 上,PedFormer 最好,尤其在 hard metrics 上比其他模型高出 6~14%。说明预测动作时,行人轨迹和车辆动态信息特别重要。
-
在 JAAD 数据集 上(动态信息不精确),结果就混合了:PedFormer 在大多数指标上好一些,但 SFGRU 在准确率和精度上更好。
-
总体来看,PIE 更适合测试动作预测,而 JAAD 的数据噪声更多。
上下文对表现的影响
意图预测:意图主要是人的“目标”,比如要去对面商店 → 这种目标不容易受环境因素影响。
-
模型需要依赖 视觉特征(比如头部朝向、姿态)来判断意图。
-
所以用图像和姿态的模型(SFGRU、PCPA)在意图预测上表现更好。
动作预测:预测行人会不会真的走出来,主要取决于 动态因素(行人走向、车辆速度)。
- 所以在动作预测上,依赖轨迹和车辆动态的模型(PedFormer)效果最好。
不同场景下的表现
用 PIE 数据集 分场景分析:
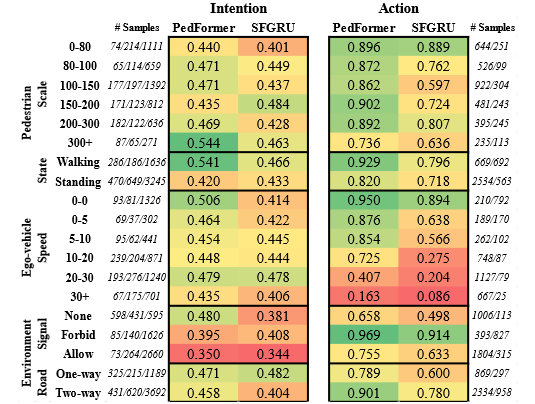
行人因素:
-
走着的行人 → 更容易预测意图和动作。
-
站着的行人 → 最难预测,模型性能大幅下降。
-
行人的“大小(scale)”影响不明显,结果有些随机性。
车辆因素:
-
动作预测对车速特别敏感:
-
车停着时,预测准确率很高(95%)。
-
车速快时,准确率掉到只有 8%。
-
-
意图预测对车速影响不大,因为意图更多取决于行人的目标。
环境因素:
-
红灯 → 行动预测更难,因为行人行为变数更多。
-
双向路比单向路预测更容易,可能是数据集中双向路更“规矩”,而单向路里乱穿马路多。
-
总体来说,环境对 意图预测 影响不大,但对 动作预测 影响显著。
意图与动作的一致性
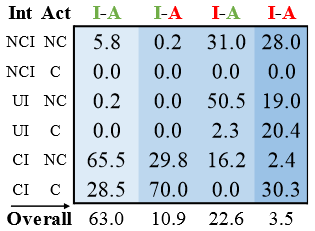
作者测试了同一个模型(PedFormer)在 意图 和 动作 两个任务上的预测是否一致:
-
两个都对:63%
-
两个都错:3.5%
-
只对一个:33.5%
-
只预测对意图(11%):说明有些线索能看出意图,但不能保证一定会行动。
-
只预测对动作(22.6%):多数情况是“没有走”,但很难从站着的行人看出他们有没有想走。
-
结论是:意图预测和动作预测是互补的,有些场景下意图更有用,有些场景下动作更可靠。
Event Risk Assessment
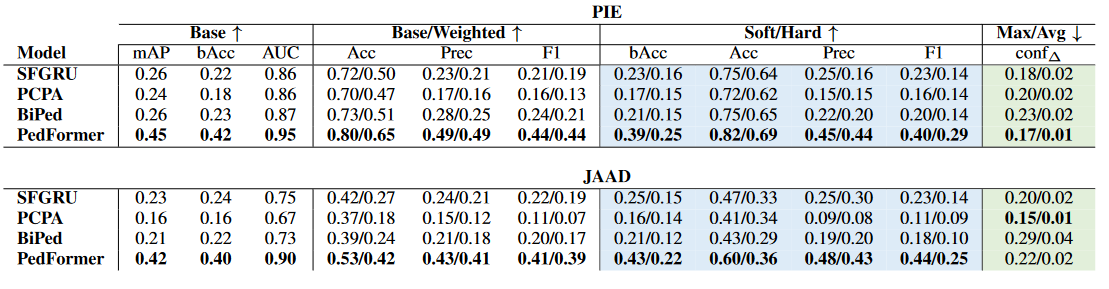
1. 任务目标
事件风险评估的目的,就是判断某个行人未来的位置会不会对车(ego-vehicle)造成危险。方法是:预测行人未来会出现在画面中的哪个区域,越靠近车辆中心,风险越高。
2. 模型表现
-
PedFormer:整体上最好,因为它更依赖“动态信息”(行人运动 + 车辆运动),适合判断风险。
-
PCPA:在 JAAD 数据集上,在稳定性指标(conf∆)上表现最好。
-
SFGRU:有些场景下也比 PedFormer 更好,特别是需要更多视觉信息时。
3. 结果分析
-
边缘区域预测更准:在画面边缘,模型表现最好。原因是:
-
边缘区域的数据更多;
-
那里的行人大多数只是站着,并不会突然走到路中间,所以风险不大,也更容易预测。
-
-
中心区域更难:
-
行人如果在画面正中(也就是车前方),就更可能过马路。
-
这种情况下,预测就更困难,因为需要精确判断运动趋势。
-
PedFormer 在这种情况更强,但它的表现波动也大,比如在某些风险等级上,准确率会突然下降 20%。
-
-
视觉 vs 动态信息:
-
PIE 数据集:有些场景下,单靠动态信息不够,还需要视觉线索(例如行人姿态、外观)。
-
JAAD 数据集:因为车的动态信息不准确,所以两个模型都只能靠“行人边框的变化”来推理,整体效果差一些。
-