【论文阅读】LG-VQ: Language-Guided Codebook Learning
这篇论文的核心目标是:
- 解决现有VQ(向量量化)图像生成模型中的码本(codebook)一般只关注单模态信息(视觉低层次细节),因此在多模态如图文相关任务(如文本生成图片、图片描述、VQA)时效果不佳,原因是缺乏文本语义和跨模态对齐。
- 论文提出LG-VQ框架,在VQ模型训练时,引入预训练文本语义指导码本学习,通过两个关键的对齐模块,把CLIP等跨模态预训练模型的文本知识有效迁移进码本,使其能在多模态任务下表现更好。
主要结构与方法细节
1. VQ-VAE基本原理
- VQ-VAE/ VQ-GAN 等 VQ方法:是用离散码本,把图片编码成一组离散token,然后再解码还原图片。码本用学习得到的 K 个向量,每个图片块被分配到最相近的码本向量,整个图片用一组token描述(量化索引)。
- 训练时包含:
- 重建损失:原始图片和重建图片的 L2 距离
- 码本损失/collapse防止:让码本分布更加丰富且接近编码特征
- 承诺损失:鼓励编码器输出稳定映射到码本空间
但传统做法只关注视觉内容,码本不具备文本语义或跨模态知识。
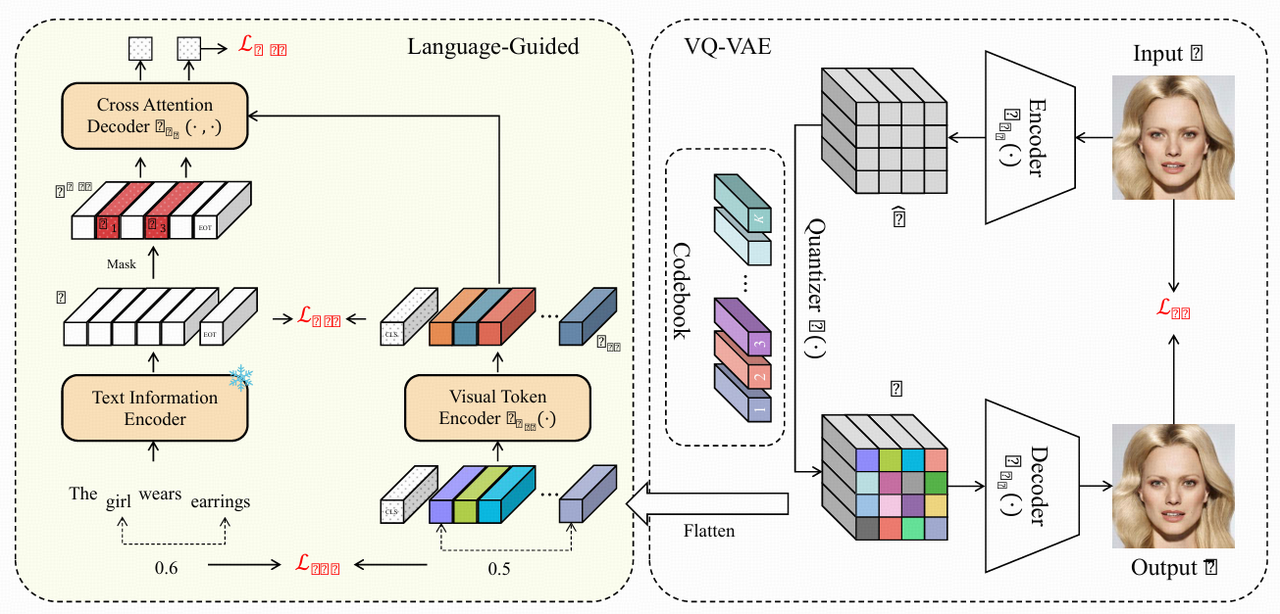
2. LG-VQ整体架构
LG-VQ在VQ-VAE的基础上,加了语言引导模块,包含如下三类损失,分别实现文本-视觉的对齐与语义迁移:
a) Semantic Alignment Module(语义对齐模块)
- 全局语义对齐(Global Semantic Alignment):
- 用CLIP文本编码器把图片描述文本转成embedding,最后一个 [EOT] token表示整个句子的全局语义。
- 用ViT对离散代码序列做编码,特设一个[CLS]全局token表示图片全局语义。
- 用InfoNCE损失,最大化同一对(图片[CLS] embedding 与文本[EOT] embedding)的相似度,最小化不同对间的相似度,实现模态间对齐。
- Masked Text Prediction(掩码文本预测):
- 随机遮盖文本中的部分词,用图片离散token序列(视觉码本)通过自注意力+cross-attention解码器预测被遮盖的词,即用图片token填补文本丢失内容。
- 用交叉熵损失优化,进一步增强跨模态语义一致性。
b) Relationship Alignment Module(关系对齐模块)
- 仅有全局语义对齐还不够复杂推理(如图文问答/描述等),还需要对齐词间语义关系。
- 对于文本中的任意两个词(如“woman”, “racket”),用CLIP编码获取其embedding;用ViT编码的视觉token序列在码本空间中找最相近的码本embedding,与对应词embedding建立关系。然后用损失函数约束码本向量间关系要贴合词embedding的语义关系(理论上cosine similarity距离一致)。
- 这样不仅模仿词之间的语义,也把词间关系迁移到视觉码本,提升码本的推理表示能力。
c) 总训练损失
- 总损失为VQ-VAE原始损失 + 三个文本引导损失(全局语义对齐 + 掩码预测 + 关系对齐),每种损失有权重调节。
3. 训练与实验
- CLIP用于获取强跨模态文本语义,不需要联合训练文本和图片,直接用CLIP做指导,迁移文本知识到视觉码本。
- 方法对现有VQ-VAE/VQ-GAN完全兼容、可无缝集成,训练流程变化不大。
- 在多个公开数据集(TextCaps、CelebA-HQ、CUB-200、COCO)做实验证明:
- 无论是图片重建,还是多模态任务(文本生成图像、图像描述、VQA),LG-VQ的性能都优于现有方法(尤其在跨模态任务上)。
LG-VQ提出了一种语言引导码本学习方法,把预训练的文本语义知识迁移到VQ模型的视觉码本,通过“语义对齐、关系迁移和掩码预测”三种损失,把图片的离散token与文本在语义和关系上强力对齐,消除了传统码本在多模态任务里的“模态鸿沟”,让图片离散代码同时具备高质量视觉表达和丰富语义信息,从而提高图片生成/重建、文本生成图片、图片描述、VQA等各类任务效果。
LG-VQ通过语言指导,把图片的离散码本编码空间和文本语义空间深度对齐,让图片生成和多模态任务都能用同一套高语义、多关系的码本,解决模态不匹配和表达贫乏的问题。