【知识点讲解】Multi-Head Latent Attention (MLA) 权威指南
MLA = Multi-Head Latent Attention
一种通过低秩联合压缩 Key/Value 来减少 KV 缓存、提升推理效率的注意力机制,由 DeepSeek 团队在 DeepSeek-V2 中首次提出,在保持多头表达力的同时,实现接近 MQA 的内存效率。
🎯 核心动机:为什么需要 MLA?
标准 Multi-Head Attention (MHA) 在推理时需缓存完整的 K 和 V 矩阵,导致:
- KV 缓存爆炸:序列长度 × 层数 × 头数 × 头维度 × 2
- 显存瓶颈:限制长上下文、高并发推理
- 计算冗余:K/V 矩阵存在大量低秩结构,可压缩
现有方案对比:
| 方案 | KV 缓存大小 | 表达能力 | 推理速度 | 代表模型 |
|---|---|---|---|---|
| MHA | 2⋅L⋅H⋅dh2 \cdot L \cdot H \cdot d_h2⋅L⋅H⋅dh | 高 | 慢 | Llama, GPT-3 |
| MQA | 2⋅L⋅dh2 \cdot L \cdot d_h2⋅L⋅dh | 低 | 快 | Falcon, Phi-2 |
| GQA | 2⋅L⋅G⋅dh2 \cdot L \cdot G \cdot d_h2⋅L⋅G⋅dh | 中 | 中 | Llama2-70B, Mixtral |
| MLA | L⋅dcL \cdot d_cL⋅dc | 高(近似 MHA) | 快(近似 MQA) | DeepSeek-V2 |
✅ MLA 核心优势:
- KV 缓存压缩比:dc≪H⋅dhd_c \ll H \cdot d_hdc≪H⋅dh → 缓存大小 ≈ MQA
- 保持多头表达力:通过低秩重建 + RoPE 解耦,不损失性能
- 矩阵吸收优化:推理时无需显式重建 K/V,可吸收到 Q/O 矩阵
🧮 数学形式化(修正 + 增强版)
设输入 token 嵌入:ht∈Rdh_t \in \mathbb{R}^dht∈Rd
1. 联合压缩 Key & Value(核心创新)
引入低秩潜在向量 ctKV∈Rdcc_t^{KV} \in \mathbb{R}^{d_c}ctKV∈Rdc,其中 dc≪dh⋅Hd_c \ll d_h \cdot Hdc≪dh⋅H
ctKV=WDKVht(下投影)c_t^{KV} = W^{DKV} h_t \quad \text{(下投影)} ctKV=WDKVht(下投影)
ktC=WUKctKV,vtC=WUVctKV(上投影重建)k_t^C = W^{UK} c_t^{KV}, \quad v_t^C = W^{UV} c_t^{KV} \quad \text{(上投影重建)} ktC=WUKctKV,vtC=WUVctKV(上投影重建)
💡 关键设计:K 和 V 共享同一个潜在向量 ctKVc_t^{KV}ctKV,实现联合压缩。
2. 解耦位置编码(RoPE)
为保留位置信息,引入独立路径生成带 RoPE 的 K:
ktR=RoPE(WKRht)k_t^R = \text{RoPE}(W^{KR} h_t) ktR=RoPE(WKRht)
最终 K 为拼接形式:
kt=[ktC;ktR]∈R(dh+dhR)×Hk_t = [k_t^C; k_t^R] \in \mathbb{R}^{(d_h + d_h^R) \times H} kt=[ktC;ktR]∈R(dh+dhR)×H
⚠️ 注意:在 DeepSeek-V2 中,ktRk_t^RktR 使用 单头设计(MQA-style),即所有头共享同一个 RoPE-K,进一步节省缓存。
3. 查询 Q 的低秩压缩(可选,用于训练内存优化)
ctQ=WDQhtc_t^Q = W^{DQ} h_t ctQ=WDQht
qtC=WUQctQq_t^C = W^{UQ} c_t^Q qtC=WUQctQ
qtR=RoPE(WQRctQ)q_t^R = \text{RoPE}(W^{QR} c_t^Q) qtR=RoPE(WQRctQ)
qt=[qtC;qtR]q_t = [q_t^C; q_t^R] qt=[qtC;qtR]
4. 注意力计算
对每个头 iii:
scoret,j,i=qt,iTkj,idh+dhR\text{score}_{t,j,i} = \frac{q_{t,i}^T k_{j,i}}{\sqrt{d_h + d_h^R}} scoret,j,i=dh+dhRqt,iTkj,i
αt,j,i=softmaxj(scoret,j,i)\alpha_{t,j,i} = \text{softmax}_j(\text{score}_{t,j,i}) αt,j,i=softmaxj(scoret,j,i)
ot,i=∑jαt,j,i⋅vj,iCo_{t,i} = \sum_j \alpha_{t,j,i} \cdot v_{j,i}^C ot,i=j∑αt,j,i⋅vj,iC
最终输出:
ut=WO⋅Concat(ot,1,…,ot,H)u_t = W^O \cdot \text{Concat}(o_{t,1}, \dots, o_{t,H}) ut=WO⋅Concat(ot,1,…,ot,H)
💾 KV 缓存优化机制(重点增强)
推理阶段只需缓存:
✅ 潜在向量:cjKV∈Rdcc_j^{KV} \in \mathbb{R}^{d_c}cjKV∈Rdc,而非完整的 kj,vjk_j, v_jkj,vj
→ 缓存大小从 2⋅L⋅H⋅dh2 \cdot L \cdot H \cdot d_h2⋅L⋅H⋅dh 降至 L⋅dcL \cdot d_cL⋅dc
矩阵吸收技巧(无需显式重建 K/V):
在推理时,可预先合并矩阵:
- WUKW^{UK}WUK 吸收到 WQW^QWQ:WnewQ=WQ⋅WUKW^Q_{\text{new}} = W^Q \cdot W^{UK}WnewQ=WQ⋅WUK
- WUVW^{UV}WUV 吸收到 WOW^OWO:WnewO=WO⋅WUVW^O_{\text{new}} = W^O \cdot W^{UV}WnewO=WO⋅WUV
→ 实际推理中,从不显式计算 ktC,vtCk_t^C, v_t^CktC,vtC,直接用 ctKVc_t^{KV}ctKV 参与点积
🖼️ 结构图
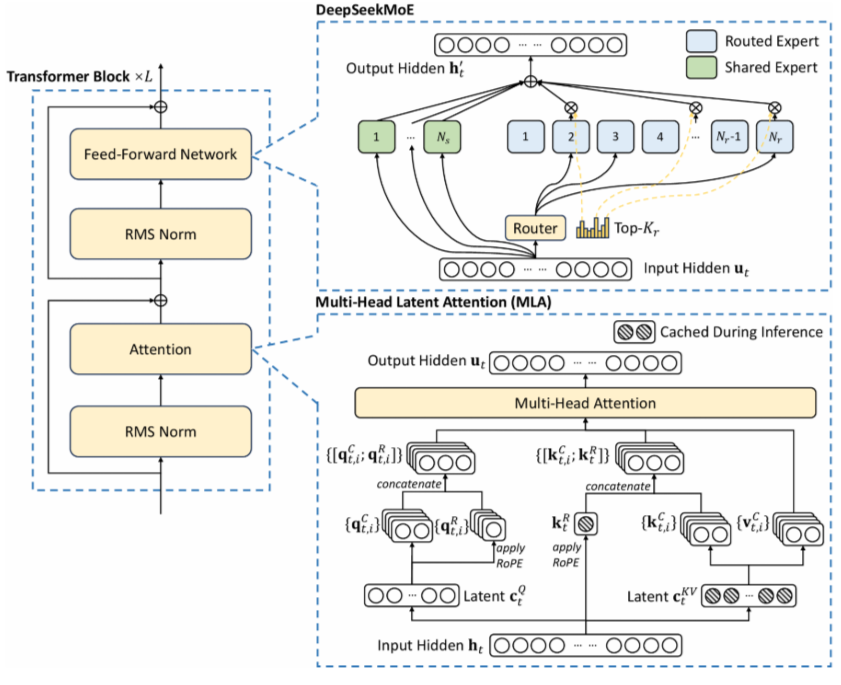
🔄 训练时:显式计算所有路径
🚀 推理时:缓存 ctKVc_t^{KV}ctKV,吸收矩阵,不重建 K/V
🧪 完整可运行代码(增强版:支持 KV 缓存、注释优化)
import torch
import torch.nn as nn
import mathclass RotaryEmbedding(nn.Module):def __init__(self, d_model: int, num_heads: int, base: int = 10000, max_len: int = 512):"""旋转位置编码(RoPE)模块参数:d_model (int): 输入特征维度num_heads (int): 注意力头数base (int): 频率基底,控制波长范围,默认10000max_len (int): 预生成位置编码的最大长度,默认512"""super().__init__()assert d_model % num_heads == 0, "d_model 必须能被num_heads整除"self.head_dim = d_model // num_heads # 每个注意力头的维度self.d_model = d_modelself.num_heads = num_headsself.base = baseself.max_len = max_len# 预计算位置编码(训练时固定不更新)self.register_buffer("cos_pos_cache", self._compute_cos_emb())self.register_buffer("sin_pos_cache", self._compute_sin_emb())def _compute_angle_rates(self):"""计算角度变化率 theta_i = 1/(base^(2i/d))"""# 示例:当head_dim=4时,i的取值为[0, 1, 2]i = torch.arange(0, self.head_dim, 2, dtype=torch.float)return 1.0 / (self.base ** (i / self.head_dim))def _compute_cos_emb(self):""" 计算余弦分量位置编码 """theta = self._compute_angle_rates()positions = torch.arange(self.max_len).unsqueeze(1) # [max_len, 1]pos_angle = positions * theta # [max_len, head_dim//2]return torch.cos(pos_angle).repeat_interleave(2, dim=-1) # 维度扩展 [max_len, head_dim]def _compute_sin_emb(self):""" 计算正弦分量位置编码 """theta = self._compute_angle_rates()positions = torch.arange(self.max_len).unsqueeze(1) # [max_len, 1]pos_angle = positions * theta # [max_len, head_dim//2]return torch.sin(pos_angle).repeat_interleave(2, dim=-1) # 维度扩展 [max_len, head_dim]def _rotate_half(self, x):""" 执行旋转操作:将后一半维度与前一半交换,并取反 """x1, x2 = x.chunk(2, dim=-1)return torch.cat((-x2, x1), dim=-1)def forward(self, q):""" 应用旋转位置编码到查询向量参数:q (Tensor): 输入查询向量,形状为 [batch_size, seq_len, d_model]返回:rotated_q (Tensor): 旋转后的查询向量,形状保持 [batch_size, seq_len, d_model]"""batch_size, seq_len, _ = q.shape# 获取当前序列长度的位置编码cos_pos = self.cos_pos_cache[:seq_len] # [seq_len, head_dim]sin_pos = self.sin_pos_cache[:seq_len] # [seq_len, head_dim]# 调整查询向量形状以匹配查询向量 [batch_size, num_heads, seq_len, head_dim]q = q.view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)# 扩展位置编码维度以匹配查询向量 [batch_size, num_heads, seq_len, head_dim]# 使用unsqueeze自动广播替代显式repeat操作,更高效cos_pos = cos_pos.unsqueeze(0).unsqueeze(1) # [1, 1, seq_len, head_dim]sin_pos = sin_pos.unsqueeze(0).unsqueeze(1) # [1, 1, seq_len, head_dim]# 执行旋转操作(高效实现)rotated_q = q * cos_pos + self._rotate_half(q) * sin_pos# 恢复原始形状 [batch_size, seq_len, d_model]return rotated_q.transpose(1, 2).contiguous().view(batch_size, seq_len, -1)class MLA(nn.Module):def __init__(self, d_model=512, down_dim=128, up_dim=256, num_heads=8,rope_head_dim=26, dropout_prob=0.1):"""Args:d_model (int): 输入特征维度down_dim (int): 低秩降维后的维度up_dim (int): 升维后的维度 (需能被num_heads整除)num_heads (int): 注意力头数rope_head_dim (int): RoPE (旋转位置编码) 每个头的维度dropout_prob (float): Dropout概率,默认0.1"""super(MLA, self).__init__()# 参数初始化self.d_model = d_modelself.down_dim = down_dimself.up_dim = up_dimself.num_heads = num_headsself.head_dim = d_model // num_heads # 标准注意力头的维度self.rope_head_dim = rope_head_dimself.v_head_dim = up_dim // num_heads # 位向量的每个头维度# 低秩投影层 (用于Key/Value的联合降维)self.down_proj_kv = nn.Linear(d_model, down_dim) # W^(DKV): 联合降维K/Vself.up_proj_k = nn.Linear(down_dim, up_dim) # W^(UK): 升维Kself.up_proj_v = nn.Linear(down_dim, up_dim) # W^(UV): 升维V# 查询向量独立降维self.down_proj_q = nn.Linear(d_model, down_dim) # W^(DQ): Q的降维self.up_proj_q = nn.Linear(down_dim, up_dim) # W^(UQ): Q的升维# 解耦的RoPE投影层 (独立处理Q/K)self.proj_qr = nn.Linear(d_model, rope_head_dim * num_heads) # 生成多头RoPE的Qself.proj_kr = nn.Linear(d_model, rope_head_dim * 1) # 生成单头RoPE的K (MQA设计)# RoPE位置编码实例(Q使用多头,K使用单头)self.rope_q = RotaryEmbedding(rope_head_dim * num_heads, num_heads) # Q使用多查询注意力 (MQA)self.rope_k = RotaryEmbedding(rope_head_dim, 1) # K使用单查询注意力 (MQA)# 注意力计算后的处理层self.dropout = nn.Dropout(dropout_prob) # 注意力权重Dropoutself.fc = nn.Linear(num_heads * self.v_head_dim, d_model) # 合并多头输出self.res_dropout = nn.Dropout(dropout_prob) # 残差连接后的Dropoutdef forward(self, h, mask=None):"""Args:h (Tensor): 输入张量,形状为 [batch_size, seq_len, d_model]mask (Tensor): 注意力掩码,形状为 [batch_size, seq_len, seq_len]Return:output (Tensor): 输出张量,形状同输入"""bs, seq_len, _ = h.size()# --- 阶段1: 低秩变换 ---# 对K/V进行联合降维+升维c_t_kv = self.down_proj_kv(h) # [bs, seq, down_dim]k_t_c = self.up_proj_k(c_t_kv) # [bs, seq, up_dim]v_t_c = self.up_proj_v(c_t_kv) # [bs, seq, up_dim]# 对Q独立降维+升维c_t_q = self.down_proj_q(h) # [bs, seq, down_dim]q_t_c = self.up_proj_q(c_t_q) # [bs, seq, up_dim]# --- 阶段2: 解耦的RoPE处理 ---# 生成带RoPE的Q/K(维度扩展为[bs, num_heads, seq_len, rope_head_dim])q_t_r = self.rope_q(self.proj_qr(h)) # Q的RoPE(多头)k_t_r = self.rope_k(self.proj_kr(h)) # K的RoPE(单头,MQA设计)# --- 阶段3: 张量拼接与注意力计算 ---# 处理Q的低秩部分:调整形状以匹配多头q_t_c = q_t_c.reshape(bs, seq_len, self.num_heads, -1).transpose(1, 2)# [bs, heads, seq, head_dim]# 处理Q的RoPE部分:调整形状以匹配多头q_t_r = q_t_r.reshape(bs, seq_len, self.num_heads, -1).transpose(1, 2)# [bs, heads, seq, rope_head_dim]q = torch.cat([q_t_c, q_t_r], dim=-1) # 拼接低秩Q和RoPE Q [bs, heads, seq, head_dim + rope_head_dim]# 处理K的低秩部分:调整形状以匹配多头k_t_c = k_t_c.reshape(bs, seq_len, self.num_heads, -1).transpose(1, 2)# [bs, heads, seq, head_dim]# 处理K的RoPE部分:调整形状以匹配多头k_t_r = k_t_r.reshape(bs, seq_len, 1, -1).transpose(1, 2) # 先转为[bs, 1, seq, rope_head_dim]k_t_r = k_t_r.repeat(1, self.num_heads, 1, 1) # 再复制到多头[bs, heads, seq, rope_head_dim]# [bs, heads, seq, rope_head_dim]k = torch.cat([k_t_c, k_t_r], dim=-1) # 拼接低秩K和RoPE K# [bs, heads, seq, head_dim + rope_head_dim]# 计算缩放点积注意力scores = torch.matmul(q, k.transpose(-1, -2)) # [bs, heads, seq, seq]if mask is not None: # 应用注意力掩码# 调整mask的形状以匹配注意力分数mask = mask.unsqueeze(1) # [bs, 1, seq, seq]scores = scores.masked_fill(mask == 0, -1e9)# 缩放(考虑拼接后的总维度)scale = math.sqrt(self.head_dim + self.rope_head_dim) # 更新缩放因子scores = torch.softmax(scores / scale, dim=-1)scores = self.dropout(scores)# 计算加权值向量v_t_c = v_t_c.reshape(bs, seq_len, self.num_heads, self.v_head_dim).transpose(1, 2)# [bs, heads, seq, v_head_dim]output = torch.matmul(scores, v_t_c) # [bs, heads, seq, v_dim]# 合并多头输出并通过全连接层output = output.transpose(1, 2).reshape(bs, seq_len, -1) # [bs, seq, d_model]output = self.fc(output) # [bs, seq, d_model]output = self.res_dropout(output) # 残差连接前应用Dropoutreturn outputif __name__ == '__main__':# 假设我们有一些输入参数batch_size = 4seq_len = 256d_model = 512# 创建一个随机输入张量,模拟一批序列数据input_tensor = torch.randn(batch_size, seq_len, d_model)# 初始化 MLA 模块mla_layer = MLA(d_model=d_model, down_dim=128, up_dim=256, num_heads=8,rope_head_dim=26, dropout_prob=0.1)# 创建一个可选的注意力掩码(例如用于屏蔽填充位置)# 这里我们创建一个全1的掩码,表示所有位置都可见mask = torch.ones(batch_size, seq_len, seq_len)# 执行前向传播output = mla_layer(input_tensor, mask=mask)print(f"Input shape: {input_tensor.shape}")print(f"Output shape: {output.shape}")# 验证输出张量形状是否与输入一致assert input_tensor.shape == output.shape, "输入和输出张量形状不匹配"

📊 性能对比与适用场景
MLA vs MHA vs MQA vs GQA
| 指标 | MHA | MQA | GQA (G=8) | MLA |
|---|---|---|---|---|
| KV 缓存大小 | 2×L×H×d | 2×L×d | 2×L×G×d | L×d_c |
| 计算复杂度 | O(L²Hd) | O(L²d) | O(L²Gd) | O(L²Hd)(训练) O(L²d_c)(推理) |
| 表达能力 | 高 | 低 | 中 | 高 |
| 推理速度 | 慢 | 快 | 中 | 快 |
| 适用场景 | 短文本、训练 | 长文本、低成本 | 平衡场景 | 长文本+高性能 |
✅ MLA 最佳适用场景:
- 长上下文推理(32K+ tokens)
- 高并发服务(KV 缓存小 → 支持更多并发)
- 资源受限但要求高性能(如边缘设备、手机端)
⚠️ 局限性与注意事项
- 训练复杂度未降低:MLA 主要优化推理,训练时仍需计算完整路径。
- 超参敏感:dcd_cdc 需仔细调优,过小损失性能,过大失去压缩意义。
- 矩阵吸收需工程支持:推理框架需支持矩阵融合(如 vLLM、TensorRT-LLM)。
- 位置编码设计关键:RoPE-K 的单头设计是性能保障,不可随意改为多头。
📚 原始论文与引用
MLA 首次提出于:
《DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model》
DeepSeek AI, 2024
arXiv:2405.04434
🏁 总结
MLA 是目前最先进的注意力机制之一,它:
✅ 在推理效率上媲美 MQA
✅ 在模型性能上接近 MHA
✅ 通过低秩联合压缩 + RoPE 解耦 + 矩阵吸收三重优化实现突破
✅ 是构建长上下文、高并发、低成本 LLM 服务的理想选择
💡 未来方向:
- 动态压缩率(根据 token 重要性调整 dcd_cdc)
- 与 MoE 结合(专家级 MLA)
- 硬件友好设计(专用 MLA 加速器)