Flink快速上手使用
先把Flink的开发环境配置好。
创建maven项目:db_flink
首先在model中将scala依赖添加进来。
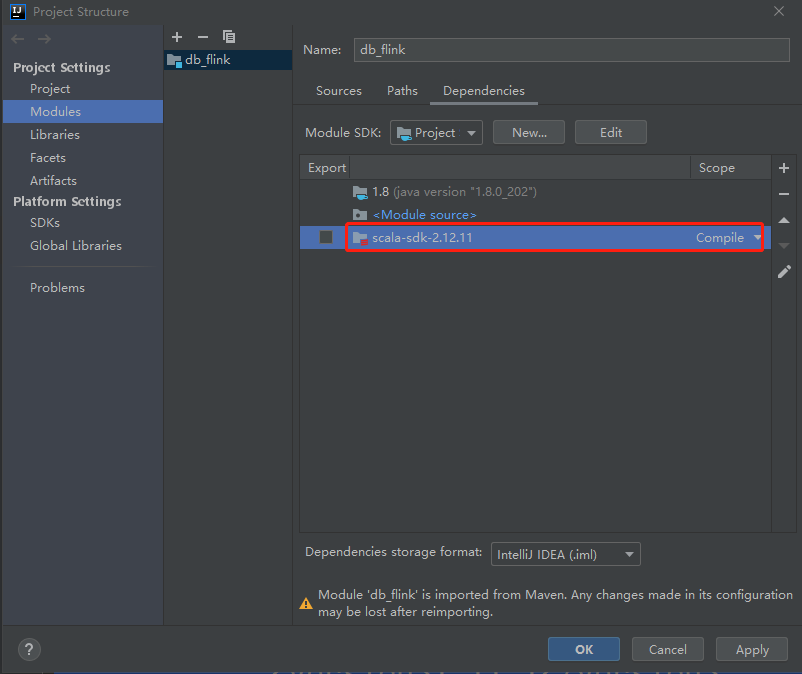
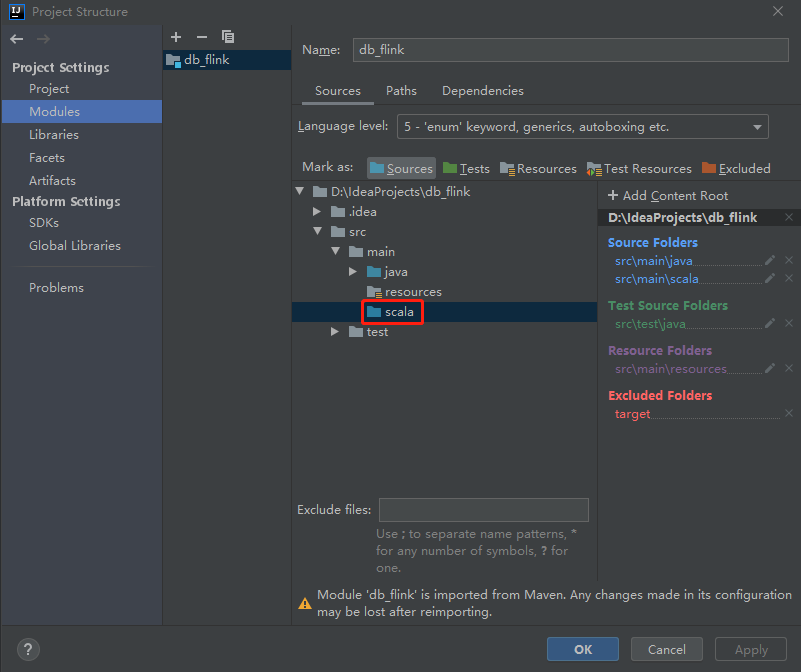
然后创建scala目录,因为针对flink我们会使用java和scala两种语言
创建包名
在src/main/java下创建com.imooc.java
在src/main/scala下创建com.imooc.scala
接下来在pom.xml中引入flink相关依赖,前面两个是针对java代码的,后面两个是针对scala代码的,最后一个依赖是这对flink1.11这个版本需要添加的
<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-java</artifactId> <version>1.11.1</version> <scope>provided</scope>
</dependency>
<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-java_2.12</artifactId> <version>1.11.1</version> <scope>provided</scope>
</dependency>
<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-scala_2.12</artifactId> <version>1.11.1</version> <scope>provided</scope>
</dependency>
<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-scala_2.12</artifactId> <version>1.11.1</version> <scope>provided</scope>
</dependency>
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients_2.12</artifactId><version>1.11.1</version>
</dependency>Flink Job开发步骤
在开发Flink程序之前,我们先来梳理一下开发一个Flink程序的步骤
1:获得一个执行环境
2:加载/创建 初始化数据
3:指定操作数据的transaction算子
4:指定数据目的地
5:调用execute()触发执行程序
注意:Flink程序是延迟计算的,只有最后调用execute()方法的时候才会真正触发执行程序
和Spark类似,Spark中是必须要有action算子才会真正执行。Streaming WordCount
需求
通过socket实时产生一些单词,使用flink实时接收数据,对指定时间窗口内(例如:2秒)的数据进行聚合统计,并且把时间窗口内计算的结果打印出来
代码开发
下面我们就来开发第一个Flink程序。
先使用scala代码开发
package com.imooc.scalaimport org.apache.flink.api.java.functions.KeySelector
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.windowing.time.Time/*** 需求:通过Socket实时产生一些单词,* 使用Flink实时接收数据* 对指定时间窗口内(例如:2秒)的数据进行聚合统计* 并且把时间窗口内计算的结果打印出来* Created by xuwei*/
object SocketWindowWordCountScala {/*** 注意:在执行代码之前,需要先在bigdata04机器上开启socket,端口为9001* @param args*/def main(args: Array[String]): Unit = {//获取运行环境val env = StreamExecutionEnvironment.getExecutionEnvironment//连接socket获取输入数据val text = env.socketTextStream("bigdata04", 9001)//处理数据//注意:必须要添加这一行隐式转换的代码,否则下面的flatMap方法会报错import org.apache.flink.api.scala._val wordCount = text.flatMap(_.split(" "))//将每一行数据根据空格切分单词.map((_,1))//每一个单词转换为tuple2的形式(单词,1)//.keyBy(0)//根据tuple2中的第一列进行分组.keyBy(tup=>tup._1)//官方推荐使用keyselector选择器选择数据.timeWindow(Time.seconds(2))//时间窗口为2秒,表示每隔2秒钟计算一次接收到的数据.sum(1)// 使用sum或者reduce都可以//.reduce((t1,t2)=>(t1._1,t1._2+t2._2))//使用一个线程执行打印操作wordCount.print().setParallelism(1)//执行程序env.execute("SocketWindowWordCountScala")}}
注意:在idea等开发工具里面运行代码的时候需要把pom.xml中的scope配置注释掉在bigdata04上面开启socket
[root@bigdata04 ~]# nc -l 9001
hello you
hello me
hello you hello meidea控制台可以看到如下效果
(hello,1)
(you,1)
-------------------------------------------------------
(hello,1)
(me,1)
-------------------------------------------------------
(hello,2)
(me,1)
(you,1)
注意:此时代码执行的时候下面会显示一些红色的log4j的警告信息,提示缺少相关依赖和配置将log4j.properties配置文件和log4j的相关maven配置添加到pom.xml文件中
<!-- log4j的依赖 -->
<dependency><groupId>org.slf4j</groupId><artifactId>slf4j-api</artifactId><version>1.7.10</version>
</dependency>
<dependency><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId><version>1.7.10</version>
</dependency>此时再执行就没有红色的警告信息了,但是使用info日志级别打印的信息太多了,所以将log4j中的日志级别配置改为error级别
log4j.rootLogger=error,stdoutlog4j.appender.stdout = org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target = System.out
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss,SSS} [%t] [%c] [%p] - %m%njava代码如下:
package com.imooc.java;import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;/*** 需求:通过socket实时产生一些单词* 使用Flink实时接收数据* 对指定时间窗口内(例如:2秒)的数据进行聚合统计* 并且把时间窗口内计算的结果打印出来* Created by xuwei*/
public class SocketWindowWordCountJava {public static void main(String[] args) throws Exception{//获取运行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();//连接socket获取输入数据DataStreamSource<String> text = env.socketTextStream("bigdata04", 9001);//处理数据SingleOutputStreamOperator<Tuple2<String, Integer>> wordCount = text.flatMap(new FlatMapFunction<String, String>() {public void flatMap(String line, Collector<String> out) throws Exception {String[] words = line.split(" ");for (String word : words) {out.collect(word);}}}).map(new MapFunction<String, Tuple2<String, Integer>>() {public Tuple2<String, Integer> map(String word) throws Exception {return new Tuple2<String, Integer>(word, 1);}}).keyBy(new KeySelector<Tuple2<String, Integer>, String>() {public String getKey(Tuple2<String, Integer> tup) throws Exception {return tup.f0;}})//.keyBy(0).timeWindow(Time.seconds(2)).sum(1);//使用一个线程执行打印操作wordCount.print().setParallelism(1);//执行程序env.execute("SocketWindowWordCountJava");}
}Batch WordCount
需求:统计指定文件中单词出现的总次数
下面来开发Flink的批处理代码
scala代码
package com.imooc.scalaimport org.apache.flink.api.scala.ExecutionEnvironment/*** 需求:统计指定文件中单词出现的总次数* Created by xuwei*/
object BatchWordCountScala {def main(args: Array[String]): Unit = {//获取执行环境val env = ExecutionEnvironment.getExecutionEnvironmentval inputPath = "hdfs://bigdata01:9000/hello.txt"val outPath = "hdfs://bigdata01:9000/out"//读取文件中的数据val text = env.readTextFile(inputPath)//处理数据import org.apache.flink.api.scala._val wordCount = text.flatMap(_.split(" ")).map((_, 1)).groupBy(0).sum(1).setParallelism(1)//将结果数据保存到文件中wordCount.writeAsCsv(outPath,"\n"," ")//执行程序env.execute("BatchWordCountScala")}
}
注意:这里面执行setParallelism(1)设置并行度为1是为了将所有数据写到一个文件里面,我们查看结果的时候比较方便还有就是flink在windows中执行代码,使用到hadoop的时候,需要将hadoop-client的依赖添加到项目中,否则会提示不支持hdfs这种文件系统。
在pom.xml文件中增加
<dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>3.2.0</version>
</dependency>此时执行代码就可以正常执行了。
执行成功之后到hdfs上查看结果
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -cat /out
hello 2
me 1
you 1java代码如下:
package com.imooc.java;import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.AggregateOperator;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;/*** 需求:统计指定文件中单词出现的总次数* Created by xuwei*/
public class BatchWordCountJava {public static void main(String[] args) throws Exception{//获取执行环境ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();String inputPath = "hdfs://bigdata01:9000/hello.txt";String outPath = "hdfs://bigdata01:9000/out2";//读取文件中的数据DataSource<String> text = env.readTextFile(inputPath);//处理数据DataSet<Tuple2<String, Integer>> wordCount = text.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {public void flatMap(String line, Collector<Tuple2<String, Integer>> out)throws Exception {String[] words = line.split(" ");for (String word : words) {out.collect(new Tuple2<String, Integer>(word, 1));}}}).groupBy(0).sum(1).setParallelism(1);//将结果数据保存到文件中wordCount.writeAsCsv(outPath,"\n"," ");//执行程序env.execute("BatchWordCountJava");}
}执行代码,然后到hdfs上面验证结果
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -cat /out2
hello 2
me 1
you 1Flink Streaming和Batch的区别
流处理Streaming
执行环境:StreamExecutionEnvironment
数据类型:DataStream
批处理Batch
执行环境:ExecutionEnvironment
数据类型:DataSet