开始 ComfyUI 的 AI 绘图之旅-SDXL文生图和图生图(全网首发,官网都没有更新)(十四)
一、什么是Stable Diffusion?
Stable Diffusion是2022年发布的深度学习文本到图像生成模型。它主要用于根据文本的描述产生详细图像,尽管它也可以应用于其他任务,如内补绘制、外补绘制,以及在提示词指导下产生图生图的转变。
它是一种潜在扩散模型,由慕尼黑大学的CompVis研究团体开发的各种生成性人工神经网络之一。[3]它是由初创公司StabilityAI、CompVis与Runway合作开发,并得到EleutherAI和LAION的支持。截至2022年10月,StabilityAI筹集了1.01亿美元的资金。
Stable Diffusion的源代码和模型权重已分别公开发布在GitHub和Hugging Face,可以在大多数配备有适度GPU的电脑硬件上运行。而以前的专有文生图模型(如DALL-E和Midjourney)只能通过云计算服务访问。
1.Stable Diffusion 模型版本
来源:https://zh.wikipedia.org/zh-cn/Stable_Diffusion
| 版本号 | 发行日期 | 参数 | 注释 |
|---|---|---|---|
| 1.1, 1.2, 1.3, 1.4 | 2022年8月 | 都由CompVis发行。没有版本1.0。1.1引发1.2,而1.2引发1.3和1.4二者[33]。 | |
| 1.5 | 2022年10月 | 983M | 以1.2而非1.4的权重初始化。由RunwayML发行。 |
| 2.0 | 2022年11月 | 从头在过滤后的数据集上重新训练[36]。 | |
| 2.1 | 2022年12月 | 以2.0的权重初始化。 | |
| XL 1.0 | 2023年7月 | 3.5B | XL 1.0基础模型有35亿个参数,使其比以前版本大了约3.5倍。[39] |
| XL Turbo | 2023年11月 | 提取自XL 1.0而以更少扩散步骤运行。[41] | |
| 3.0 | 2024年2月(早期预览) | 800M到8B | 模型家族。 |
| 3.5 | 2024年10月 | 2.5B到8B | 具有Large(80亿个参数)、Large Turbo(提取自SD 3.5)和Medium (25亿个参数)的模型家族。 |
2.SDXL最佳实践
SDXL 基础检查点可以像ComfyUI中的任何常规检查点一样使用。唯一需要注意的是,为了获得最佳性能,分辨率应设置为 1024x1024 或其他像素数量相同但宽高比不同的分辨率。例如:896x1152 或 1536x640 都是不错的分辨率。推荐分辨率如下:
- 1024 x 1024
- 1152 x 896
- 896 x 1152
- 1216 x 832
- 832 x 1216
- 1344 x 768
- 768 x 1344
- 1536 x 640
- 640 x 1536
3.SDXL模型下载
安装aria2快速下载模型,几乎能将我家1000M的宽带跑满,每秒80~90M,接下来的介绍模型都会给出安装命令。
apt install aria2
aria2c https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/resolve/main/sd_xl_base_1.0.safetensors?download=true -o SourceCode/ComfyUI/models/checkpoints/sd_xl_base_1.0.safetensors --auto-file-renaming=false --allow-overwrite=falsearia2c https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-1.0/resolve/main/sd_xl_refiner_1.0.safetensors?download=true -o SourceCode/ComfyUI/models/checkpoints/sd_xl_refiner_1.0.safetensors --auto-file-renaming=false --allow-overwrite=falsearia2c https://huggingface.co/comfyanonymous/clip_vision_g/resolve/main/clip_vision_g.safetensors?download=true -o SourceCode/ComfyUI/models/clip_vision/clip_vision_g.safetensors --auto-file-renaming=false --allow-overwrite=falsearia2c https://huggingface.co/stabilityai/sdxl-turbo/resolve/main/sd_xl_turbo_1.0_fp16.safetensors -o SourceCode/ComfyUI/models/checkpoints/sd_xl_turbo_1.0_fp16.safetensors --auto-file-renaming=false --allow-overwrite=false
二、SDXL工作流介绍
要将基础功能与精炼器结合使用,您可以使用此工作流程。您可以下载此图像并加载,或将其拖到 ComfyUI 上获取。
1.SDXL简单版本
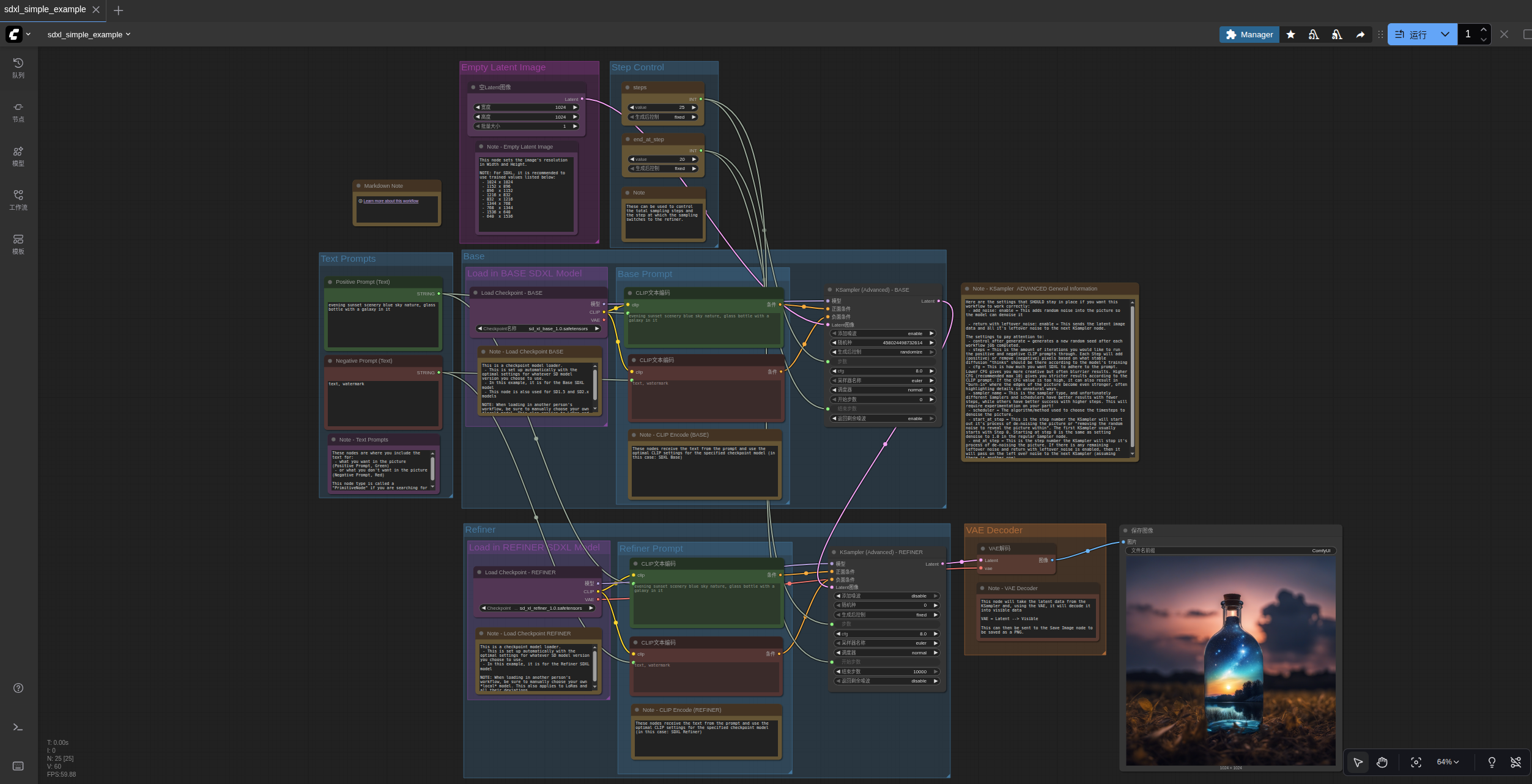
运行结果:

2.SDXL Refiner提示
您还可以像此工作流程一样为基础和refiner提供不同的提示。
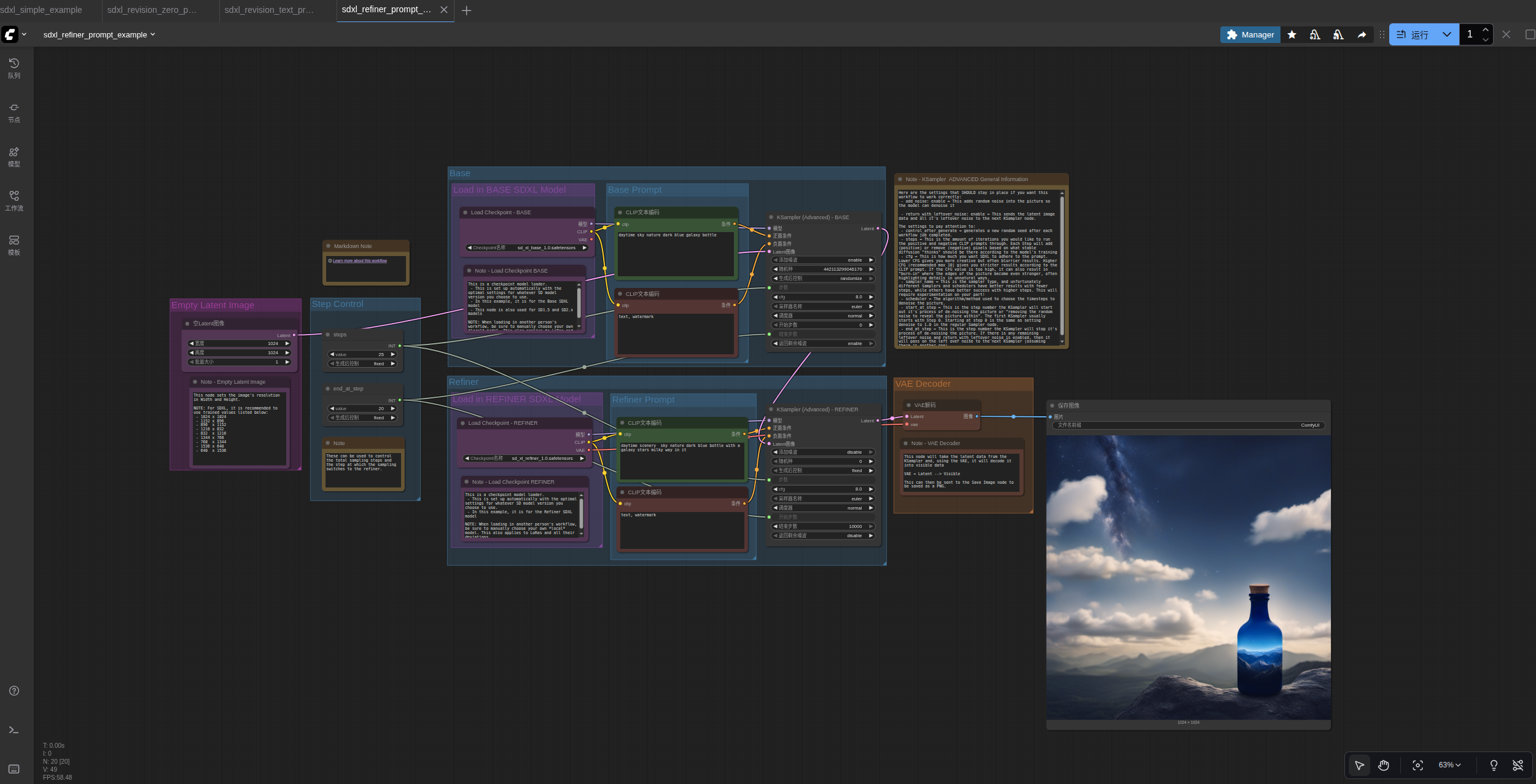
运行结果:

3.SDXL修订零正
ReVision 与unCLIP非常相似,但其行为更侧重于概念层面。你可以将一张或多张图片传递给它,它会从这些图片中提取概念,并以此为灵感创建新的图片。
首先下载CLIP-G Vision并将其放入您的 ComfyUI/models/clip_vision/ 目录中。
以下是一个可拖拽或加载到 ComfyUI 的示例工作流。在此示例中,正向文本提示被清零,以便最终输出更贴近输入图像。
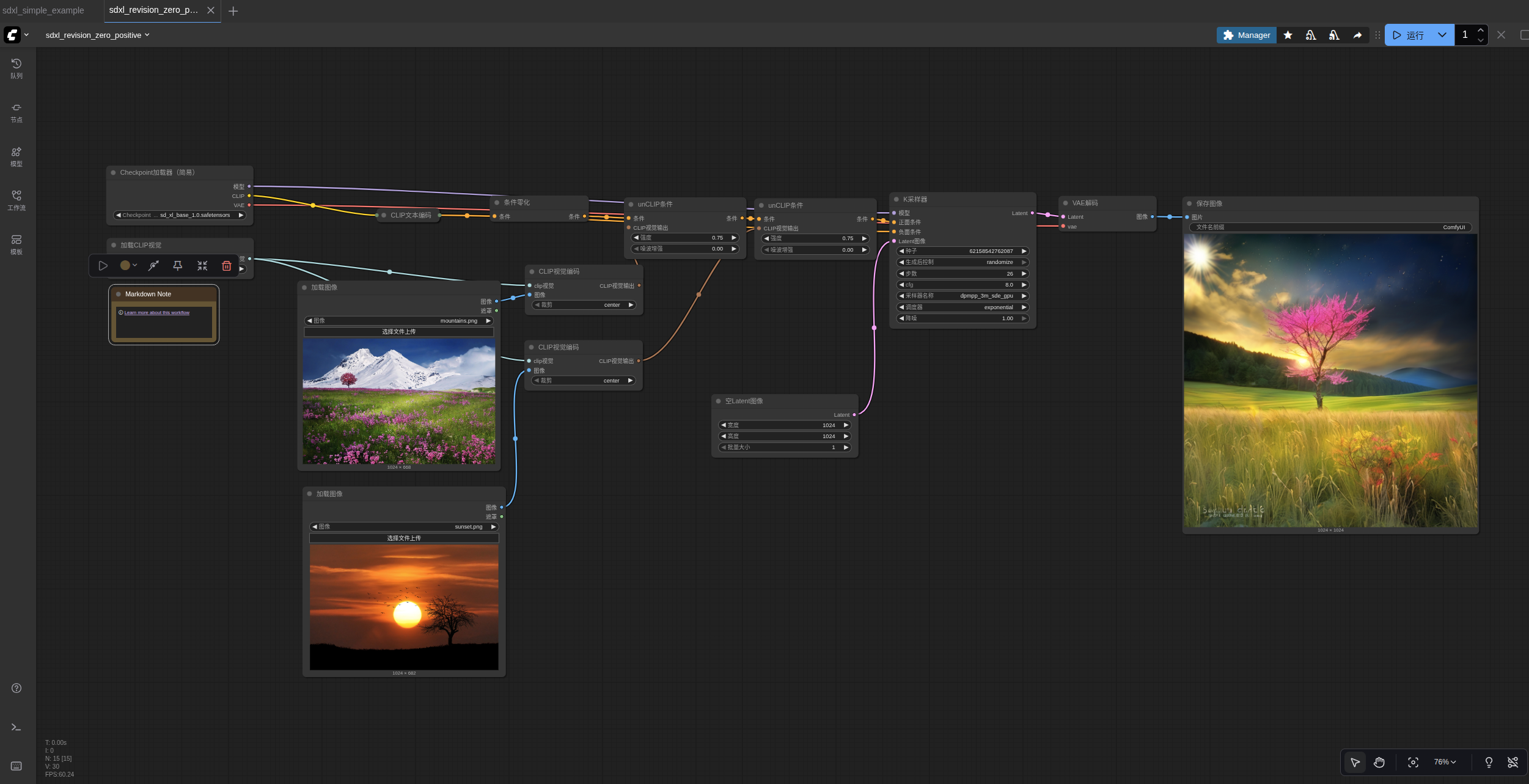
运行结果:

4.SDXL修订文本提示
如果您想使用文本提示,您可以使用这个示例:
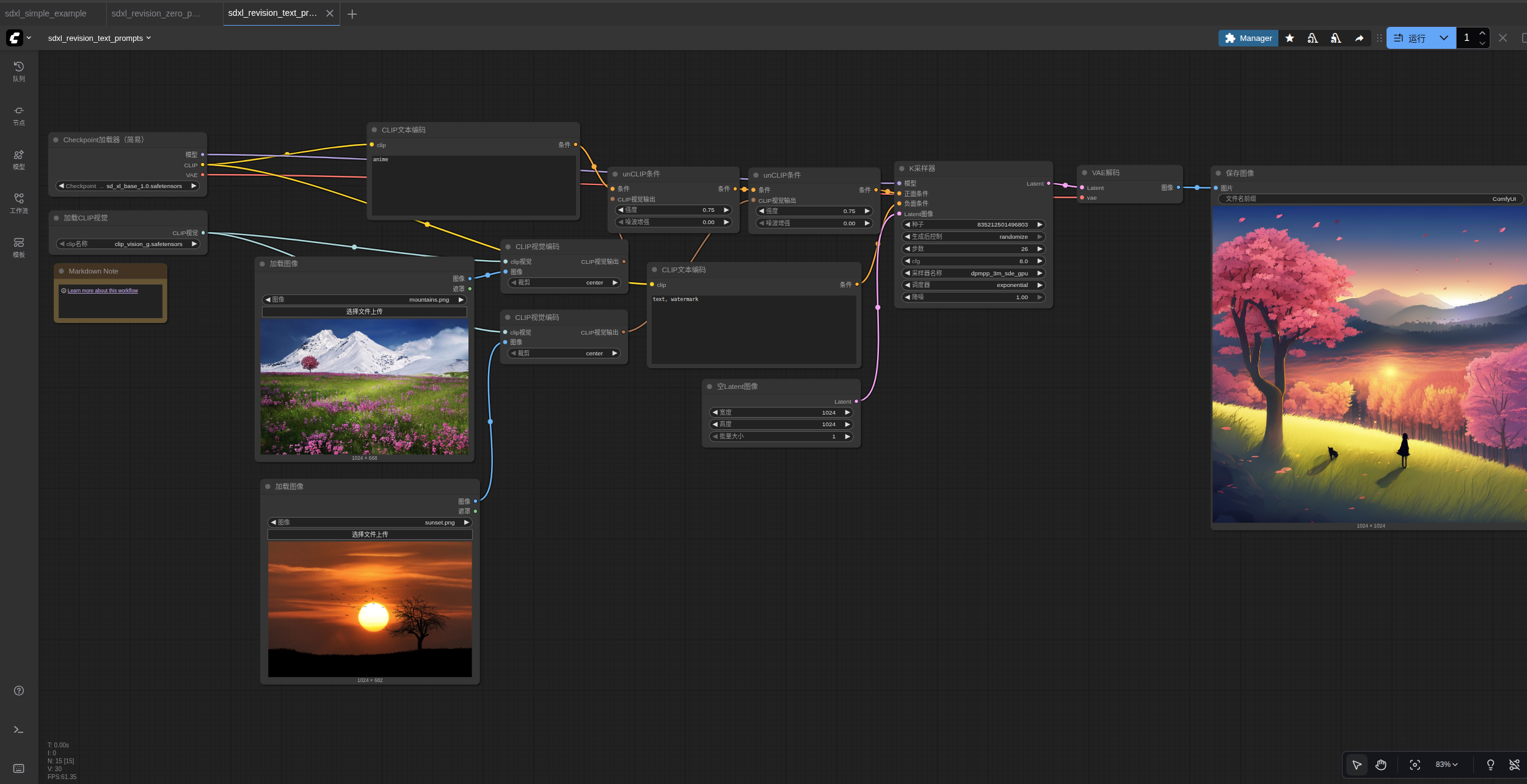
运行结果:

5.SDXL Turbo
SDXL Turbo 是一个 SDXL 模型,可以一步生成一致的图像。您可以使用更多步骤来提高质量。正确的使用方法是使用新的 SDTurboScheduler 节点,但它也可以与常规调度程序配合使用。
这是下载官方 SDXL turbo 检查点的链接
以下是使用它的工作流程:
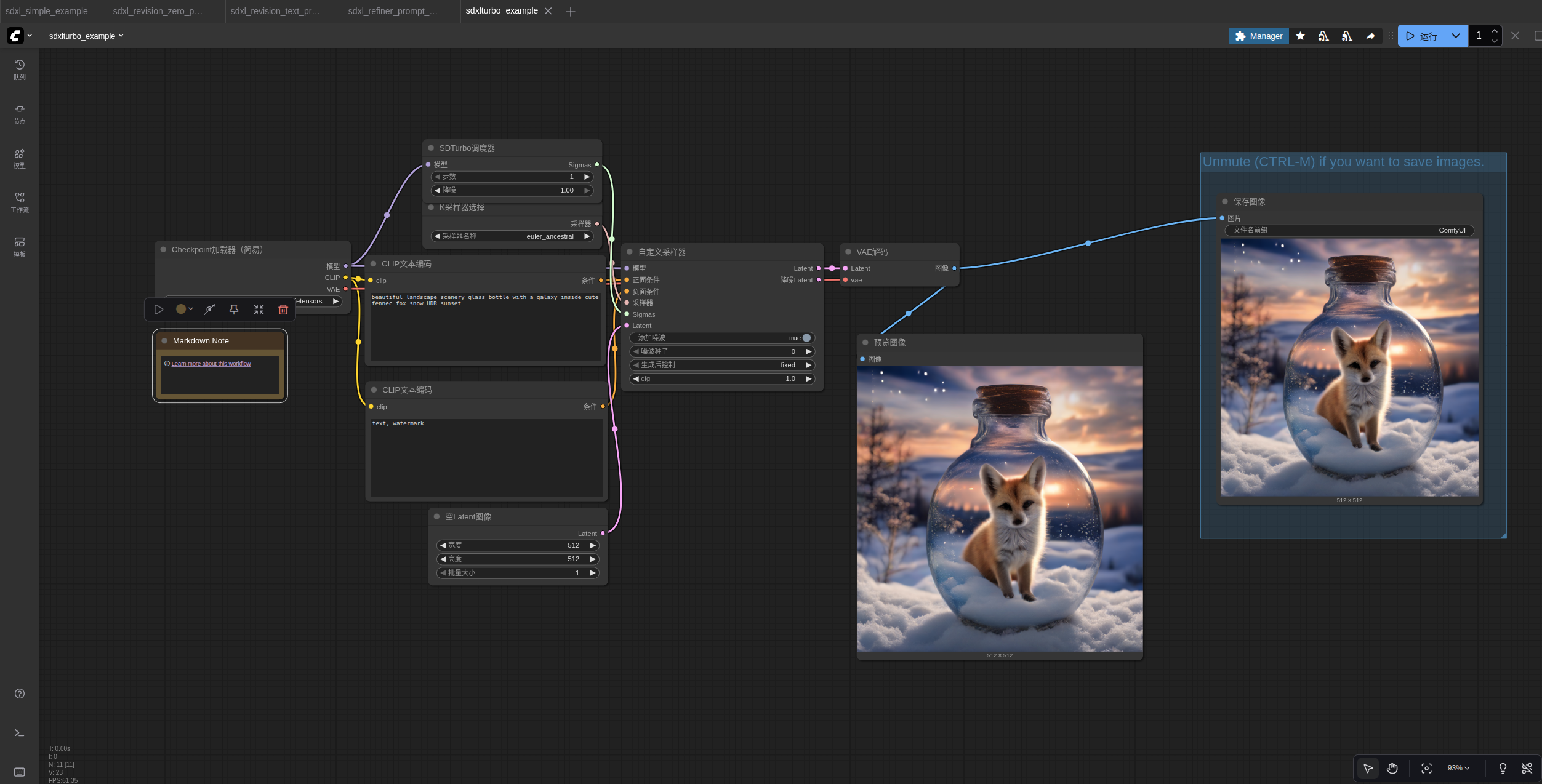
保存此图像,然后将其加载或拖放到 ComfyUI 上以获取工作流程。然后,我建议在界面中启用“额外选项”->“自动排队”。然后按一次“排队提示”,开始编写提示。
