MySQL中InnoDB索引使用与底层原理
MySQL Server端的缓存(查询缓存)是MySQL Server层的特性,而InnoDB的缓存(缓冲池)是InnoDB存储引擎层的特性。两者是完全独立的。
下面我们来深入探讨这两者以及InnoDB索引的原理。
1. MySQL Server层的缓存 - 查询缓存 (Query Cache)
归属:MySQL Server特性。它是一个全局性的组件,理论上对所有存储引擎(如InnoDB, MyISAM)的查询都可能生效。
工作原理:
当执行一个SELECT语句时,MySQL会先计算这个语句的哈希值,然后去查询缓存中查找是否有完全匹配(字节对字节完全相同)的查询结果。
如果找到(缓存命中),则直接返回结果,完全跳过解析、优化和执行阶段,效率极高。
如果未找到(缓存未命中),则继续执行查询,获取结果后,会将结果存储到查询缓存中,以备下次使用。
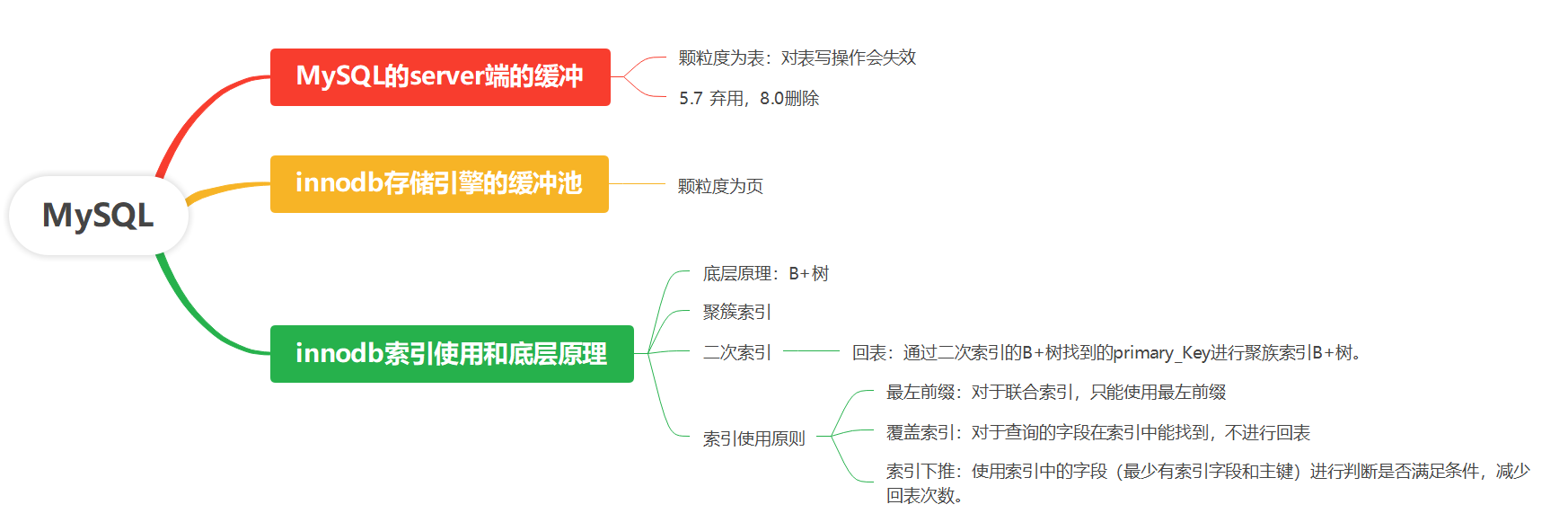
失效机制:非常粗粒度。只要对某张表进行了任何写操作(INSERT, UPDATE, DELETE, TRUNCATE, ALTER TABLE等),那么所有与这张表相关的查询缓存都会全部失效并被清除。这对于写操作频繁的数据库来说,缓存命中率会非常低,维护缓存反而带来了巨大的性能开销。
现状:在MySQL 5.7中开始弃用,在MySQL 8.0中已被彻底移除。主要原因就是其弊大于利,在高并发读写场景下,缓存失效带来的争用甚至会导致性能下降。现在通常建议使用应用层缓存(如Redis, Memcached)来替代它。
2. InnoDB存储引擎的缓存 - 缓冲池 (Buffer Pool)
归属:InnoDB存储引擎的特性。这是InnoDB自身实现的核心组件。
工作原理:
缓冲池是主内存中的一片区域,用于缓存表和索引数据。当需要读取数据时,InnoDB会先检查数据页是否在缓冲池中。如果在(缓存命中),则直接读取内存,速度极快。
如果不在(缓存未命中),则从磁盘读取相应的数据页,并将其放入缓冲池中,然后再进行读取。
对于写操作,修改的也是缓冲池中的数据页。这些被修改但尚未刷新到磁盘的页称为脏页 (Dirty Page)。InnoDB有后台线程定期将脏页刷新到磁盘,这个过程称为刷脏 (Checkpointing)。
重要性:这是InnoDB性能的核心。通过缓冲池,InnoDB将磁盘I/O操作最小化,将最多的操作在内存中完成。缓冲池的大小(通过
innodb_buffer_pool_size参数设置)是MySQL性能调优最重要的参数,通常建议设置为服务器物理内存的50%-80%。与索引的关系:B+树索引的非叶子节点和频繁访问的叶子节点都会常驻在缓冲池中,这使得基于索引的查询速度非常快。
3. InnoDB索引使用与底层原理
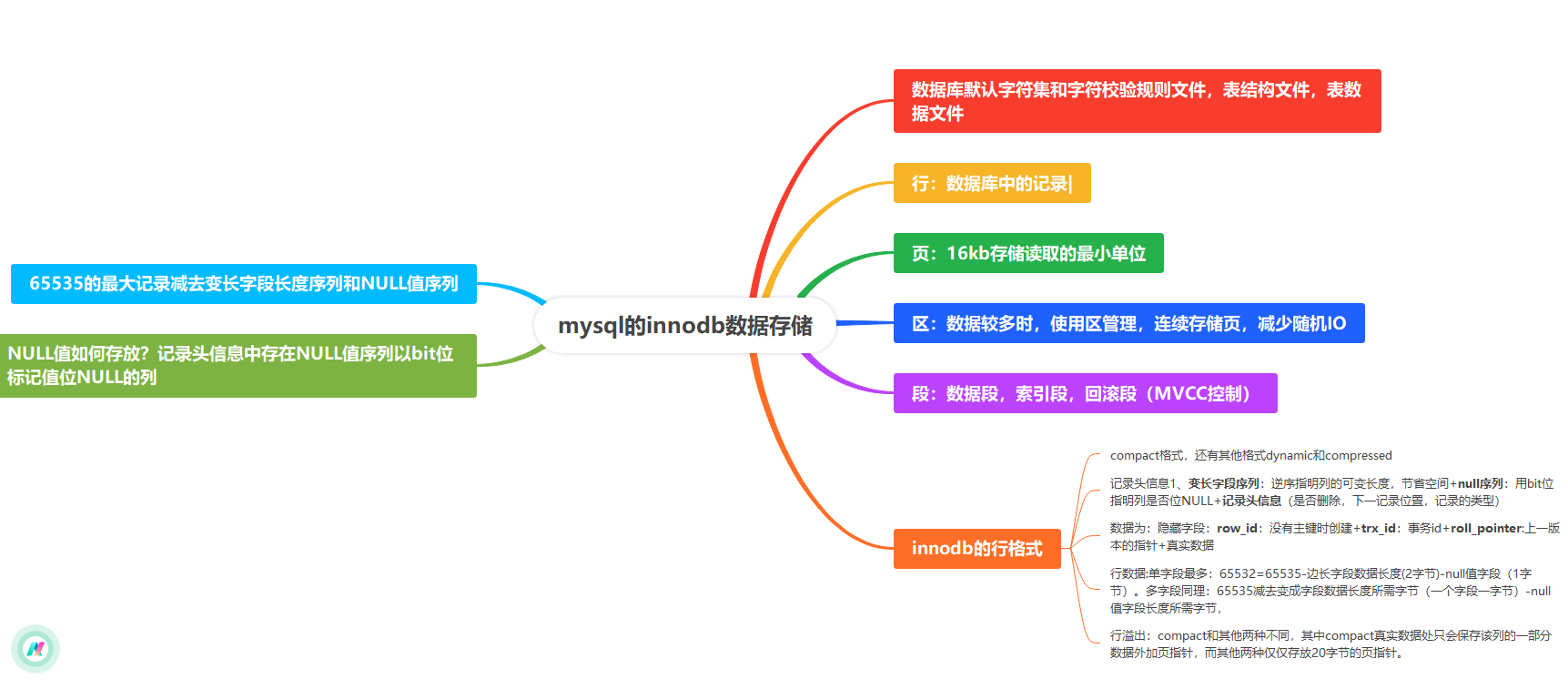
索引数据结构:B+树
InnoDB使用B+树作为其索引的数据结构。B+树是为磁盘存储而优化的,它具有以下特点:
矮胖树:层级很少,通常只需2-4次I/O就能在亿万级数据中找到目标。
所有数据都存储在叶子节点:非叶子节点只存储键值(索引列的值)和指向子节点的指针,这使得非叶子节点可以存储大量键值,让树更“矮胖”。
叶子节点形成有序链表:范围查询效率极高,只需找到范围的起始点,然后沿着链表遍历即可。
聚集索引 (Clustered Index)
InnoDB的表必须有一个聚集索引。
数据行本身就直接存储在聚集索引的叶子节点上。因此,表数据本身就是按聚集索引的顺序物理存储的。
通常,聚集索引就是主键(PRIMARY KEY)。如果没有定义主键,InnoDB会选择一个唯一的非空索引代替。如果也没有,则会隐式创建一个 rowid 作为聚集索引。
二级索引 (Secondary Index)
也叫非聚集索引或辅助索引。
二级索引的叶子节点存储的不是完整的数据行,而是该行的主键值。
当通过二级索引查询时,需要先找到对应的主键值,然后再回到聚集索引中根据主键查找完整的行数据。这个过程称为回表 (Bookmark Lookup)。
索引使用原则
最左前缀原则:对于联合索引
(a, b, c),它可以用于查询a,(a, b),(a, b, c)的条件,但不能用于跳过a直接查询b或c。覆盖索引 (Covering Index):如果查询的字段都包含在某个索引中(例如在索引
(a, b)上查询a, b),则引擎可以直接从索引中获取数据,而无需回表,极大提升性能。索引下推 (Index Condition Pushdown, ICP):MySQL 5.6引入。在索引遍历过程中,提前对索引中包含的字段进行WHERE条件过滤,减少回表的次数。
ps:如果没有索引下推优化(或称ICP优化),当进行索引查询时,首先根据索引来查找记录,然后再根据where条件来过滤记录;在支持ICP优化后,MySQL会在取出索引的同时,判断是否可以进行where条件过滤再进行索引查询。
总结与对比
| 特性 | MySQL Server查询缓存 | InnoDB缓冲池 (Buffer Pool) |
|---|---|---|
| 归属层面 | MySQL Server层 | InnoDB存储引擎层 |
| 缓存内容 | 完整的查询结果集 | 表和索引的数据页 |
| 粒度 | 粗(表级) | 细(页级,通常16KB) |
| 失效机制 | 对表的任何写操作导致所有相关缓存失效 | 基于LRU算法和刷脏机制,精细管理 |
| 现状 | MySQL 8.0中已移除 | InnoDB核心组件,至关重要 |
| 目的 | 避免重复执行相同的SQL查询 | 减少磁盘I/O,加速数据访问 |
因此,在现代MySQL(尤其是8.0+)的架构讨论和性能优化中,我们关注的重点几乎完全在 InnoDB缓冲池 上,而早已不再考虑已被废弃的Server层查询缓存。理解缓冲池的工作原理和大小设置,是优化数据库性能的第一步,也是最关键的一步。