每天五分钟深度学习:神经网络的权重参数如何初始化
本文重点
在逻辑回归的时候,我们可以将神经网络的权重参数初始化为0(或者同样的值),但是如果我们将神经网络的权重参数初始化为0就会出问题,上节课程我们已经进行了简单的解释,那么既然初始化为0不行,神经网络该如何进行参数初始化呢?神经网络的权重参数初始化是模型训练的关键步骤,直接影响收敛速度和最终性能。
权重W过大和过小
为权重W赋值比较小的数值
W=np.random.randn(input,output)*0.01
np.random.randn会随机生成标准正态分布,也就是说均值为0,方差为1,乘以0.01,那么此时的均值为0,方差为0.01。
这种情况下,训练的时候,我们会发现,神经网络层数比较多的时候,神经网络后面的层的权重参数均值和方差会逐渐变为0,那么这种情况就和前面的权重初始化为一样的值是一样的效果,此时神经网络是没有办法训练的了。
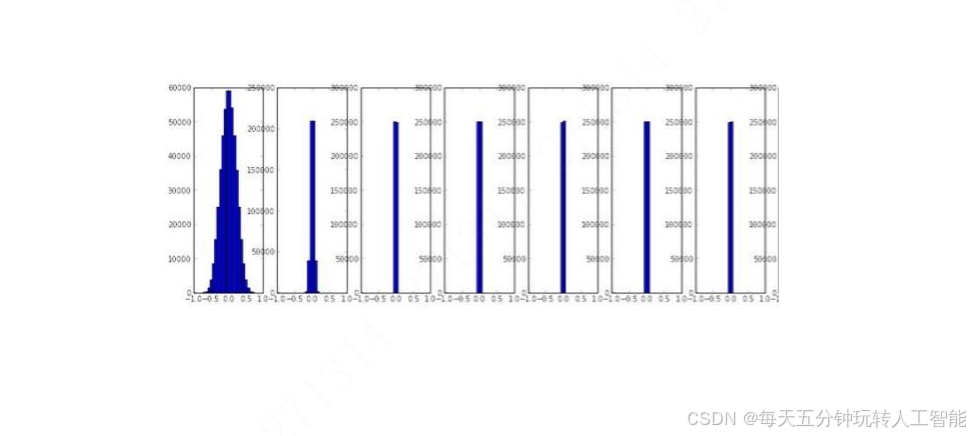
为权重W赋值比较大的数值
W=np.random.randn(input,output)*1.0因为当权重过大的时候,sigmoid就会出现饱和的情况,也就是说sigmoid(wx)=1或者-1,无论是1还是-1,此时的sigmoid的梯度都是0,那么此时反向传播是没有办法训