Qwen2.5-VL 实战:用 VLM 实现 “看图对话”,从目标检测到空间推理!【附源码】
《博主简介》
小伙伴们好,我是阿旭。
专注于计算机视觉领域,包括目标检测、图像分类、图像分割和目标跟踪等项目开发,提供模型对比实验、答疑辅导等。
《------往期经典推荐------》
一、AI应用软件开发实战专栏【链接】
| 项目名称 | 项目名称 |
|---|---|
| 1.【人脸识别与管理系统开发】 | 2.【车牌识别与自动收费管理系统开发】 |
| 3.【手势识别系统开发】 | 4.【人脸面部活体检测系统开发】 |
| 5.【图片风格快速迁移软件开发】 | 6.【人脸表表情识别系统】 |
| 7.【YOLOv8多目标识别与自动标注软件开发】 | 8.【基于深度学习的行人跌倒检测系统】 |
| 9.【基于深度学习的PCB板缺陷检测系统】 | 10.【基于深度学习的生活垃圾分类目标检测系统】 |
| 11.【基于深度学习的安全帽目标检测系统】 | 12.【基于深度学习的120种犬类检测与识别系统】 |
| 13.【基于深度学习的路面坑洞检测系统】 | 14.【基于深度学习的火焰烟雾检测系统】 |
| 15.【基于深度学习的钢材表面缺陷检测系统】 | 16.【基于深度学习的舰船目标分类检测系统】 |
| 17.【基于深度学习的西红柿成熟度检测系统】 | 18.【基于深度学习的血细胞检测与计数系统】 |
| 19.【基于深度学习的吸烟/抽烟行为检测系统】 | 20.【基于深度学习的水稻害虫检测与识别系统】 |
| 21.【基于深度学习的高精度车辆行人检测与计数系统】 | 22.【基于深度学习的路面标志线检测与识别系统】 |
| 23.【基于深度学习的智能小麦害虫检测识别系统】 | 24.【基于深度学习的智能玉米害虫检测识别系统】 |
| 25.【基于深度学习的200种鸟类智能检测与识别系统】 | 26.【基于深度学习的45种交通标志智能检测与识别系统】 |
| 27.【基于深度学习的人脸面部表情识别系统】 | 28.【基于深度学习的苹果叶片病害智能诊断系统】 |
| 29.【基于深度学习的智能肺炎诊断系统】 | 30.【基于深度学习的葡萄簇目标检测系统】 |
| 31.【基于深度学习的100种中草药智能识别系统】 | 32.【基于深度学习的102种花卉智能识别系统】 |
| 33.【基于深度学习的100种蝴蝶智能识别系统】 | 34.【基于深度学习的水稻叶片病害智能诊断系统】 |
| 35.【基于与ByteTrack的车辆行人多目标检测与追踪系统】 | 36.【基于深度学习的智能草莓病害检测与分割系统】 |
| 37.【基于深度学习的复杂场景下船舶目标检测系统】 | 38.【基于深度学习的农作物幼苗与杂草检测系统】 |
| 39.【基于深度学习的智能道路裂缝检测与分析系统】 | 40.【基于深度学习的葡萄病害智能诊断与防治系统】 |
| 41.【基于深度学习的遥感地理空间物体检测系统】 | 42.【基于深度学习的无人机视角地面物体检测系统】 |
| 43.【基于深度学习的木薯病害智能诊断与防治系统】 | 44.【基于深度学习的野外火焰烟雾检测系统】 |
| 45.【基于深度学习的脑肿瘤智能检测系统】 | 46.【基于深度学习的玉米叶片病害智能诊断与防治系统】 |
| 47.【基于深度学习的橙子病害智能诊断与防治系统】 | 48.【基于深度学习的车辆检测追踪与流量计数系统】 |
| 49.【基于深度学习的行人检测追踪与双向流量计数系统】 | 50.【基于深度学习的反光衣检测与预警系统】 |
| 51.【基于深度学习的危险区域人员闯入检测与报警系统】 | 52.【基于深度学习的高密度人脸智能检测与统计系统】 |
| 53.【基于深度学习的CT扫描图像肾结石智能检测系统】 | 54.【基于深度学习的水果智能检测系统】 |
| 55.【基于深度学习的水果质量好坏智能检测系统】 | 56.【基于深度学习的蔬菜目标检测与识别系统】 |
| 57.【基于深度学习的非机动车驾驶员头盔检测系统】 | 58.【太基于深度学习的阳能电池板检测与分析系统】 |
| 59.【基于深度学习的工业螺栓螺母检测】 | 60.【基于深度学习的金属焊缝缺陷检测系统】 |
| 61.【基于深度学习的链条缺陷检测与识别系统】 | 62.【基于深度学习的交通信号灯检测识别】 |
| 63.【基于深度学习的草莓成熟度检测与识别系统】 | 64.【基于深度学习的水下海生物检测识别系统】 |
| 65.【基于深度学习的道路交通事故检测识别系统】 | 66.【基于深度学习的安检X光危险品检测与识别系统】 |
| 67.【基于深度学习的农作物类别检测与识别系统】 | 68.【基于深度学习的危险驾驶行为检测识别系统】 |
| 69.【基于深度学习的维修工具检测识别系统】 | 70.【基于深度学习的维修工具检测识别系统】 |
| 71.【基于深度学习的建筑墙面损伤检测系统】 | 72.【基于深度学习的煤矿传送带异物检测系统】 |
| 73.【基于深度学习的老鼠智能检测系统】 | 74.【基于深度学习的水面垃圾智能检测识别系统】 |
| 75.【基于深度学习的遥感视角船只智能检测系统】 | 76.【基于深度学习的胃肠道息肉智能检测分割与诊断系统】 |
| 77.【基于深度学习的心脏超声图像间隔壁检测分割与分析系统】 | 78.【基于深度学习的心脏超声图像间隔壁检测分割与分析系统】 |
| 79.【基于深度学习的果园苹果检测与计数系统】 | 80.【基于深度学习的半导体芯片缺陷检测系统】 |
| 81.【基于深度学习的糖尿病视网膜病变检测与诊断系统】 | 82.【基于深度学习的运动鞋品牌检测与识别系统】 |
| 83.【基于深度学习的苹果叶片病害检测识别系统】 | 84.【基于深度学习的医学X光骨折检测与语音提示系统】 |
| 85.【基于深度学习的遥感视角农田检测与分割系统】 | 86.【基于深度学习的运动品牌LOGO检测与识别系统】 |
| 87.【基于深度学习的电瓶车进电梯检测与语音提示系统】 | 88.【基于深度学习的遥感视角地面房屋建筑检测分割与分析系统】 |
| 89.【基于深度学习的医学CT图像肺结节智能检测与语音提示系统】 | 90.【基于深度学习的舌苔舌象检测识别与诊断系统】 |
| 91.【基于深度学习的蛀牙智能检测与语音提示系统】 | 92.【基于深度学习的皮肤癌智能检测与语音提示系统】 |
| 93.【基于深度学习的工业压力表智能检测与读数系统】 |
二、机器学习实战专栏【链接】,已更新31期,欢迎关注,持续更新中~~
三、深度学习【Pytorch】专栏【链接】
四、【Stable Diffusion绘画系列】专栏【链接】
五、YOLOv8改进专栏【链接】,持续更新中~~
六、YOLO性能对比专栏【链接】,持续更新中~
《------正文------》
目录
- 一、核心主题与背景
- 二、Qwen2.5-VL 模型核心优势
- 三、VLMs 的视觉理解层级(以 Qwen2.5-VL 为例)
- 1. Level 1:基础级 —— 零样本目标检测(Zero-Shot Object Detection)
- 2. Level 2:进阶级 —— 精准视觉定位与计数(Visual Grounding & Object Counting)
- 3. Level 3:高阶 —— 关系与场景理解(Relationship & Context Understanding)
- 四、Qwen2.5-VL 代码实现流程
- 1. 环境搭建:加载模型与处理器
- 2. 核心推理函数(detect_qwen)
- 3. 结果可视化函数(create_annotated_image)
- 五、典型应用案例
- 六、核心结论与价值
一、核心主题与背景
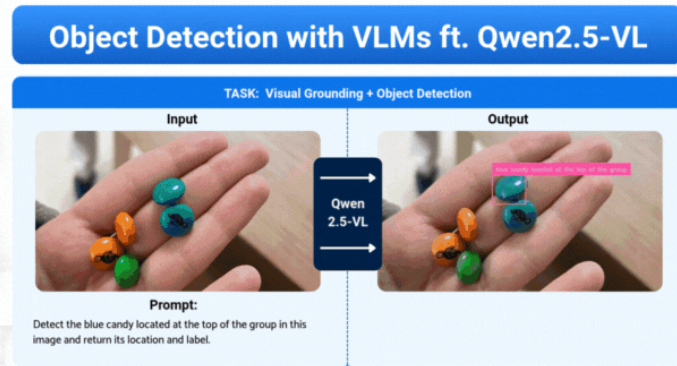
本文聚焦视觉语言模型(VLMs)在目标检测与空间理解领域的应用,以阿里巴巴团队开发的开源模型Qwen2.5-VL为核心案例,阐述其如何打破传统视觉模型(如 YOLO)依赖预训练类别、无法与人类 “对话式交互” 的局限,实现 “像素语言” 与 “文字语言” 的跨模态融合,推动计算机视觉从 “识别” 向 “理解” 升级。
二、Qwen2.5-VL 模型核心优势
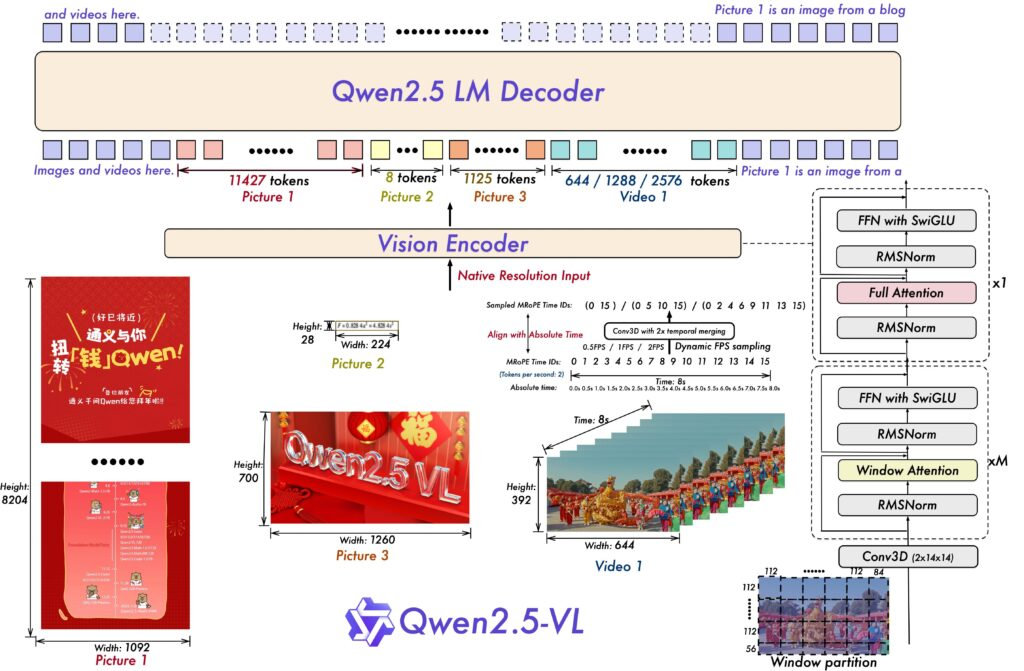
作为当前接近闭源模型(如 GPT-4o)性能的开源 VLMs,其核心竞争力体现在四大维度:
- 原生高清图像处理:无需将图像缩放到固定尺寸,可保留原始分辨率下的细节(如远处标牌文字、织物纹理),避免信息丢失。
- 精准空间感知能力:基于像素级坐标定位目标(类似 “图像 GPS”),而非模糊相对位置,为关键点检测等高精度任务提供支撑。
- 复杂文档解析能力:可处理含表格、图表、手写笔记、化学公式的 PDF 等文档,能理解文档结构而非仅识别文本。
- 视频时序理解能力:通过 “多模态旋转位置嵌入(MRoPE)” 技术,将内部 “时间 ID” 与视频绝对时间戳对齐,可区分快 / 慢动作,突破传统模型仅按帧序分析的局限。
此外,模型训练基于4.1 万亿个多样化 tokens(含图像描述、智能体交互等数据),为深度目标理解奠定基础。
三、VLMs 的视觉理解层级(以 Qwen2.5-VL 为例)
VLMs 的视觉理解呈 “阶梯式进阶”,对应不同应用场景需求:
1. Level 1:基础级 —— 零样本目标检测(Zero-Shot Object Detection)
- 定位:模型无需针对特定图像做预训练,可基于通用知识识别指定类别的所有目标并返回坐标。
- 案例:输入 “检测图像中所有摩托车手,以 JSON 格式返回坐标及是否戴头盔”,模型可在繁忙公路图像中框选所有摩托车手并标注状态。
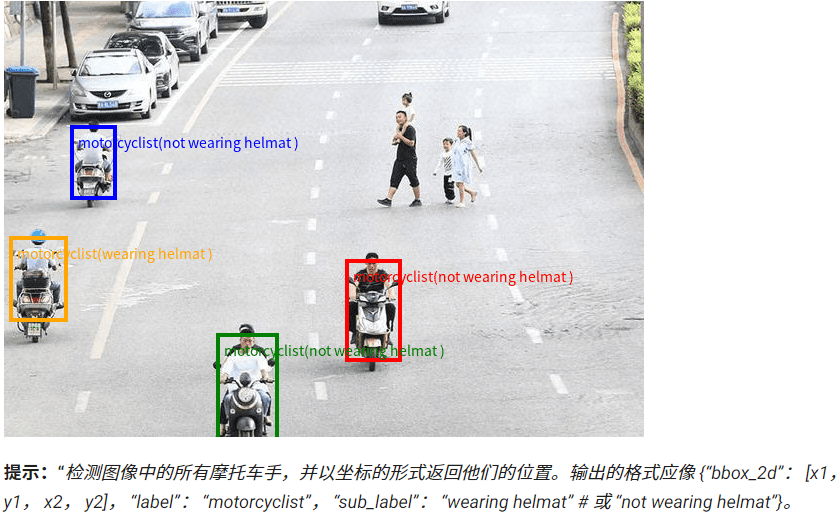
- 价值:无需定制数据集或微调模型,适用于通用目标检测场景。
2. Level 2:进阶级 —— 精准视觉定位与计数(Visual Grounding & Object Counting)
- 核心能力:将文本描述与图像中特定目标绑定,不仅识别类别,还能基于特征筛选目标;支持关键点检测(超越 bounding box 的精细定位)。
- 视觉定位案例:输入 “定位所有蛋糕并描述特征,返回坐标”,模型可识别 “带巧克力豆的纸杯蛋糕” 并排除其他款式。

- 关键点检测案例:输入 “识别篮球运动员并标记手部、头部关键点”,模型可在运动员身上标记像素级精准点位,适用于体育分析、AR 等场景。

3. Level 3:高阶 —— 关系与场景理解(Relationship & Context Understanding)
-
核心能力:超越单一目标识别,通过 “视觉观察 + 语言推理” 解读目标间关系与场景逻辑,处理抽象概念任务。
-
案例:输入 “定位表现勇敢的人,返回坐标”,模型需先识别图像中儿童与老人 / 掉落的杂货袋,再结合 “勇敢” 的语言定义,判断出帮助老人的儿童并定位。

-
价值:实现从 “看场景” 到 “懂场景” 的跨越,可用于复杂场景自动描述、智能机器人交互等。
四、Qwen2.5-VL 代码实现流程
现在,我们介绍一个 Python 脚本,该脚本为使用 VLM 进行对象检测的交互式应用程序提供支持。
核心分三部分:
1. 环境搭建:加载模型与处理器
from transformers import (AutoProcessor,Qwen2_5_VLForConditionalGeneration,
)
import supervision as sv# --- Config ---
model_qwen_id = "Qwen/Qwen2.5-VL-3B-Instruct"# Load the main model
model_qwen = Qwen2_5_VLForConditionalGeneration.from_pretrained(model_qwen_id, torch_dtype="auto", device_map="auto"
)# Load the processor
min_pixels = 224 * 224
max_pixels = 1024 * 1024
processor_qwen = AutoProcessor.from_pretrained("Qwen/Qwen2.5-VL-3B-Instruct", min_pixels=min_pixels, max_pixels=max_pixels
)
- 模型:Qwen2_5_VLForConditionalGeneration(核心推理模块);
- 处理器:AutoProcessor(将图像 / 文本转为模型可识别的张量,支持动态分辨率范围)。
2. 核心推理函数(detect_qwen)
实现 “输入图像 + 提示词→模型输出” 的核心流程,分 6 步:
def detect_qwen(image, prompt):# Step 1: Format the inputsmessages = [{"role": "user","content": [{"type": "image", "image": image},{"type": "text", "text": prompt},],}]# Step 2: Preprocess with the processortext = processor_qwen.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)image_inputs, video_inputs = process_vision_info(messages)inputs = processor_qwen(text=[text],images=image_inputs,# ...return_tensors="pt",).to(model_qwen.device)# Step 3: Run inferencegenerated_ids = model_qwen.generate(**inputs, max_new_tokens=1024)# Step 4: Decode the output# ... (trimming and decoding logic)output_text = processor_qwen.batch_decode(generated_ids_trimmed,# ...)[0]# Step 5: Get processed dimensions for scalinginput_height = inputs["image_grid_thw"][0][1] * 14input_width = inputs["image_grid_thw"][0][2] * 14# Step 6: Create the annotated imageannotated_image = create_annotated_image(image, output_text, input_height, input_width)return annotated_image, output_text, # ...
- 格式化输入:将图像与提示词封装为 “user-message” 结构;
- 预处理:处理器对文本应用聊天模板、对图像分块,生成张量;
- 推理:调用
model_qwen.generate()生成输出 tokens; - 解码:将 tokens 转为人类可读文本(如 JSON 格式);
- 获取处理后尺寸:基于模型的 14×14 像素补丁网格,计算模型 “看到” 的图像尺寸,用于后续坐标缩放;
- 生成标注图像:调用可视化函数处理结果。
3. 结果可视化函数(create_annotated_image)
该模型为我们提供了数据,下面将数据结果绘制在界面上。它解析模型的 JSON 响应,并将边界框和关键点直接绘制到我们的原始图像上。
def create_annotated_image(image, json_data, height, width):# Step 1: Parse the JSON responsetry:parsed_json_data = json_data.split("```json")[1].split("```")[0]bbox_data = json.loads(parsed_json_data)except Exception:return image # Return original image if parsing fails# Step 2: Handle both bounding boxes and keypoints using 'supervision'annotated_image = np.array(image.convert("RGB"))# For Bounding Boxesdetections = sv.Detections.from_vlm(vlm=sv.VLM.QWEN_2_5_VL,result=json_data,resolution_wh=(width, height), # Use the model's processed dimensions)bounding_box_annotator = sv.BoxAnnotator()label_annotator = sv.LabelAnnotator()annotated_image = bounding_box_annotator.annotate(scene=annotated_image, detections=detections)annotated_image = label_annotator.annotate(scene=annotated_image, detections=detections)# For Keypoints# ... (code to extract and annotate points) ...return Image.fromarray(annotated_image)
第 1 步:解析 JSON:该模型通常将其 JSON 输出包装在 Markdown 样式的代码块(json …)中。此代码首先清理它,然后使用 json.loads 将文本转换为可用的 Python 对象列表。try-except 块是防止应用在模型返回非 JSON 响应时崩溃的良好做法。
第 2 步:在supervision下可视化:手动绘制框和标签可能很乏味。supervision库是一个很棒的工具包,可以极大地简化这一点。
sv.Detections.from_vlm(…):该库内置了对解析 Qwen2.5-VL 输出的支持!我们只需将原始 JSON 响应(结果)和模型使用的维度(resolution_wh)传递给它。它会自动处理坐标缩放并创建 Detections 对象。
sv.BoxAnnotator and sv.LabelAnnotator:这些是获取 Detections 对象的帮助程序,并使用一行代码将框和标签绘制到我们的图像上。
五、典型应用案例
以下是 4 类核心应用展示:
-
特定目标定位:输入 “检测蓝色糖果中位于顶部的那个,返回坐标”,模型精准框选符合 “蓝色 + 顶部位置” 的糖果;


-
关键点检测:输入 “识别红色汽车并标记关键点”,模型在红色汽车上标记像素级点位(如车轮、车头);


-
目标计数推理:输入 “数猫头鹰的眼睛数量”,模型先识别 2 只猫头鹰,再结合 “猫头鹰有 2 只眼睛” 的常识,计算出总数 4 只并以自然语言回答;


-
抽象现象检测:输入 “定位纸狐狸的影子,返回坐标”,模型通过推理 “纸狐狸与光线的关系”,框选出无实体纹理的影子区域(传统检测器无法实现)。


六、核心结论与价值
- 技术突破:VLMs 实现 “与图像对话”,可通过自然语言提问获取精准结果,突破传统视觉模型的交互局限;
- 落地潜力:Qwen2.5-VL 的原生分辨率处理、文档解析、坐标精准性等能力,可应用于电商视觉搜索、视障辅助、资产分类等场景;
- 开发便捷性:借助 Hugging Face Transformers(加载模型)、Supervision(可视化)等库,无需从零构建,降低 VLMs 应用门槛;
好了,这篇文章就介绍到这里,喜欢的小伙伴感谢给点个赞和关注,更多精彩内容持续更新~~
关于本篇文章大家有任何建议或意见,欢迎在评论区留言交流!