智能推荐新纪元:快手生成式技术对系统边界的消融与重建
一、前言
老周这次受邀作为嘉宾参加了AICon全球人工智能开发与应用大会,本文将基于快手科技副总裁、基础大模型及推荐模型负责人周国睿老师在AICon大会的演讲内容,基于我自己的思考总结分享给大家。
二、传统推荐级联架构的规模化瓶颈与范式局限
我们知道,快手是一家视频公司,推荐系统对它们是至关重要的。传统推荐级联架构是当前工业界广泛采用的多阶段推荐框架,其核心设计通过分阶段处理实现效率与精度的平衡,但同时也面临规模化瓶颈与范式局限。
规模化瓶颈与范式局限:
1、规模化瓶颈与范式局限
- 级联架构中,各阶段独立优化,上一阶段输出成为下一阶段上限,导致整体性能受限
- 传统MFU(模型利用率)普遍低于10%,算力浪费严重
2、目标冲突与协同不足
- 多阶段目标不一致(如召回追求覆盖率,精排追求CTR),需人工设计对齐策略
- 特征工程复杂,跨阶段特征传递效率低
3、生成式推荐的挑战
- 传统架构难以适应大模型时代需求,如端到端生成式推荐(如OneRec)通过统一序列生成任务实现效果跃升
推荐的服务场景决定了不适合做大模型?
| 对比维度 | LLM Chat场景 | 推荐系统 |
|---|---|---|
| QPS | >10K | >400K |
| 时延要求 | 10-15 tokens/秒 | 单次请求<500ms |
| 激活参数规模 | 1B~1T | <250M |
推荐模型大模型化的三大“忽悠点”
1、规模论
推荐模型参数量已相当庞大,计入Sparse参数后,总参数规模甚至超过LLM(大语言模型)。这意味着模型在“Scale Up(规模升级)”方向上已无充足拓展空间。
2、延迟论
推荐系统属于实时响应型系统,需在极低延迟(Low Latency)场景下完成服务。而大模型的推理计算耗时较长,推荐系统无法为大模型预留足够时间完成计算,导致性能与需求不匹配。
3、成本论
推荐系统的QPS(每秒查询请求数)极高,但单次服务的商业价值(如广告点击、商品转化等)相对“薄”;大模型的计算资源消耗极大,若应用于推荐场景,单次服务的成本会显著超出其商业价值,导致成本不可控。
其中延迟论也是符合我的之前的认知的,推荐系统要实时响应,而推理计算耗时,你看DeepSeek那个思考就知道了,一点点输出响应的值,放在推荐系统的话肯定不合适。但后面周国睿老师后面的分享颠覆了我的认知。
接下来的信息流平台大模型计算成本分析框架

传统推荐系统中,MFU(模型使用效率)过低是导致计算成本与常规印象差异的核心原因。因其直接导致硬件资源浪费、能耗增加,且受限于高QPS和稀疏性难以通过常规手段优化。通过优化算力、成本结构与模型效率,可实现大模型在推荐场景下的成本可控性,为技术落地提供可行性支撑。
三、OneRec:端到端生成式推荐的系统验证
3.1 OneRec:端到端生成式推荐的整体架构
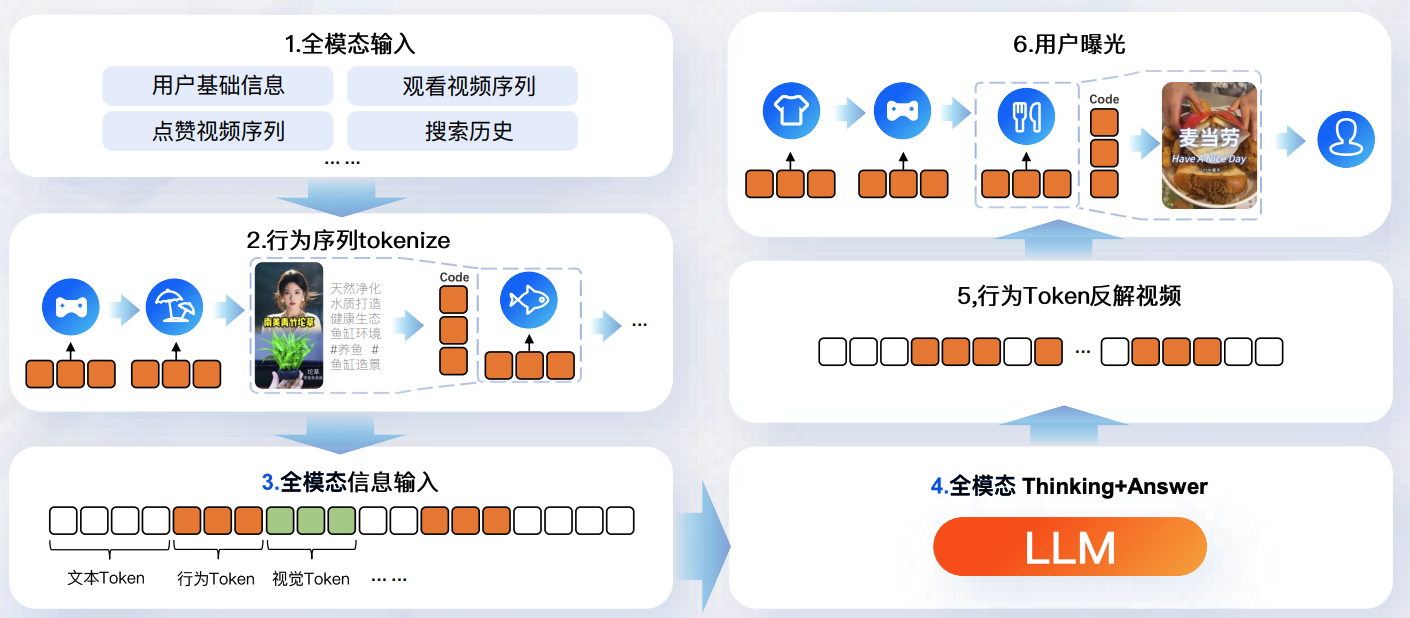
3.1.1 核心组件与流程
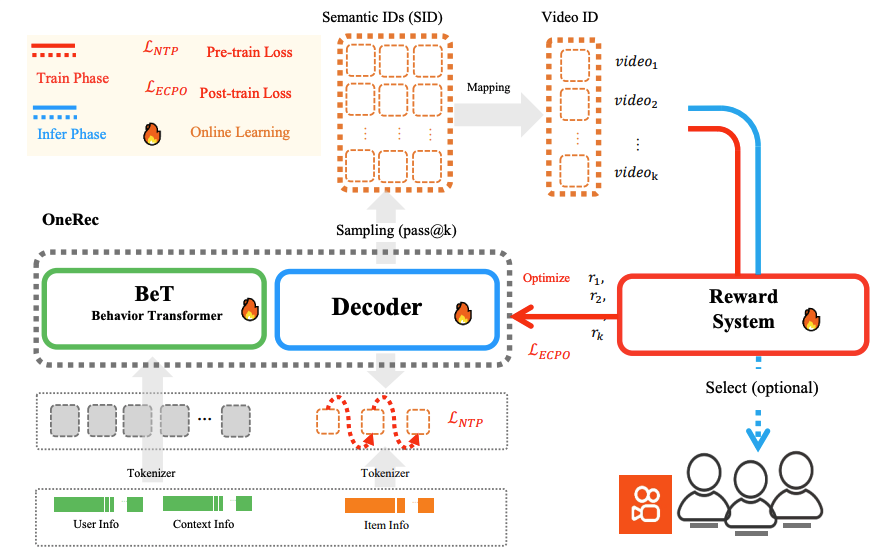
OneRec 是端到端推荐系统,通过“行为建模 + 解码生成 + 奖励优化”的闭环,实现推荐效果与成本的协同优化。架构分为 训练阶段(Train Phase) 和 推理阶段(Infer Phase),各组件功能如下:
- Behavior Transformer(BeT)
负责行为建模,将用户信息(User Info)、上下文信息(Context Info)、物品信息(Item Info)通过 Tokenizer 转换为 Token 后,学习用户行为模式,为解码器提供行为特征。 - Decoder
基于 BeT 的行为特征,生成推荐物品的候选列表(Candidate Items),是推荐结果的直接输出层。 - Reward System
评估推荐结果的业务价值(如点击率、留存率等),输出奖励信号(𝑟1,𝑟2,…𝑟𝑘),用于优化系统性能。
3.1.2 损失函数与学习机制
架构通过多阶段损失函数驱动模型学习,覆盖“预训练 - 后训练 - 在线学习”全流程:
- Pre-train Loss
预训练阶段的损失函数,用于初始化模型参数,让模型在大规模数据上学习基础特征。 - Post-train Loss
后训练阶段的损失函数,结合奖励系统输出的业务价值信号,优化模型在真实业务场景下的表现。 - Online Learning(实时学习)
推理阶段同步进行模型更新,通过用户实时反馈(如点击、停留时长)持续优化推荐效果,实现“边推边学”。
3.1.3 数据流与交互逻辑
-
训练阶段
用户、上下文、物品信息经 Tokenizer 转换后,输入 BeT 学习行为特征;BeT 输出的行为特征驱动 Decoder 生成候选物品,同时驱动预训练。 -
推理阶段
通过“采样(Sampling, pass@k)”从候选物品中选择推荐列表,映射为视频 ID(Video ID)后推送给用户;用户反馈通过 Reward System 转化为奖励信号,驱动优化模型;同时支持“可选选择(Select, optional)”策略,灵活调整推荐策略。
OneRec 通过端到端闭环打破传统推荐系统“模块化割裂”的局限,实现“行为理解 - 推荐生成 - 价值反馈”的一体化优化,同时支持在线学习实时响应用户偏好,为推荐效果与成本的平衡提供技术支撑。
3.2 OneRec:视频表征及Tokenizer
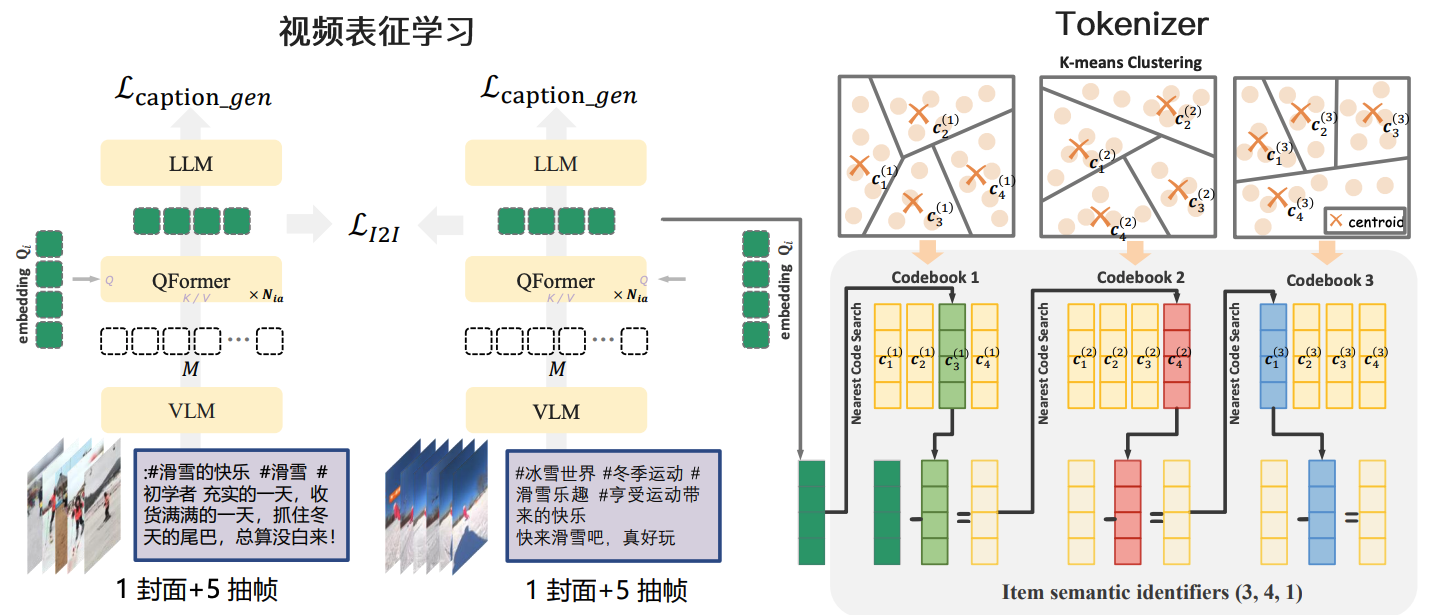
| 模块 | 功能描述 |
|---|---|
| VLM | 视觉语言模型,负责视频与文本的跨模态对齐,将特征映射到统一语义空间 |
| QFormer | 通过多头注意力机制(K/V路径)增强视频特征,输出多模态特征Q_i |
| LLM | 基于多模态特征生成视频描述文本(Lcaptiongen\mathcal{L}_{caption_gen}Lcaptiongen优化) |
| LI2I\mathcal{L}_{I2I}LI2I | 对比学习损失函数,强化视频与文本特征的交互一致性 |
Tokenizer 通过K-means 聚类和近邻码本搜索,将视频多模态特征转化为语义标识符,实现特征的离散化与语义压缩。
OneRec 架构通过视频表征学习实现“视频→文本”的语义关联,再通过Tokenizer将多模态特征转化为可理解的语义标识符,形成“视频→多模态特征→文本生成→语义标识符”的完整流程,为视频内容理解与推荐等下游任务提供高效表征与语义支持。
3.3 OneRec:基于Reward System 的偏好对齐
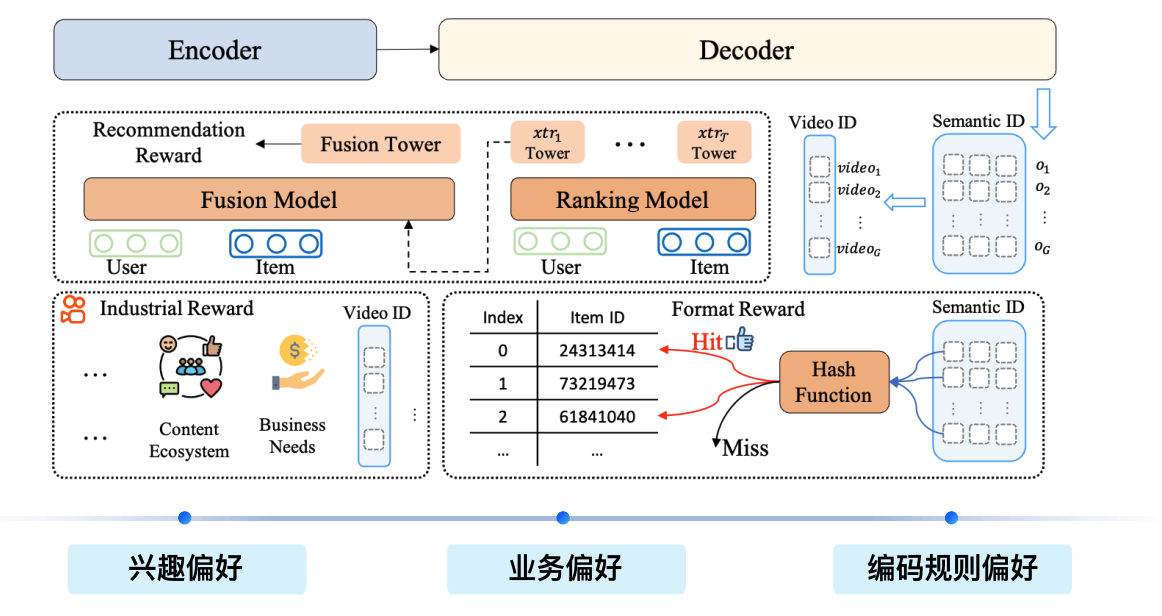
该推荐系统采用端到端训练架构,整合“兴趣偏好、业务偏好、编码规则偏好”三类偏好,核心模块包括:
- Encoder:负责对用户(User)、物品(Item)等特征进行编码,为后续模块提供特征表示。
- Decoder:接收编码后特征,输出最终推荐结果。
- Fusion Model:融合用户与物品特征,通过Fusion Tower与Reward交互,实现兴趣偏好建模。
- Ranking Model:包含多个Tower(如 xtr1 Tower、xtrT Tower),结合用户、物品特征,完成推荐排序。
系统从三类偏好维度驱动推荐:
- 兴趣偏好:由用户行为、内容生态(如互动、社交、内容偏好)等驱动,反映用户对物品的主观兴趣。
- 业务偏好:由商业需求(如营收、用户增长、内容生态健康度等)驱动,体现平台运营目标。
- 编码规则偏好:通过Hash Function对物品(如Video ID)进行编码映射,结合Format Reward(如“Hit”“Miss”反馈)优化推荐,属于技术规则层面的偏好。
模块交互逻辑:Fusion Model通过Tower整合用户-物品特征并与Reward形成闭环,强化兴趣偏好建模;Ranking Model利用多Tower实现多维排序,输出候选列表;Hash Function结合Hit/Miss反馈优化编码规则,提升推荐效率。
端到端训练优势:通过联合优化效果(点击率/转化率)与成本(计算资源/训练效率),突破传统系统效果与成本割裂的局限,实现用户体验、商业目标与技术效率的多目标平衡。
3.3.1 兴趣偏好对齐
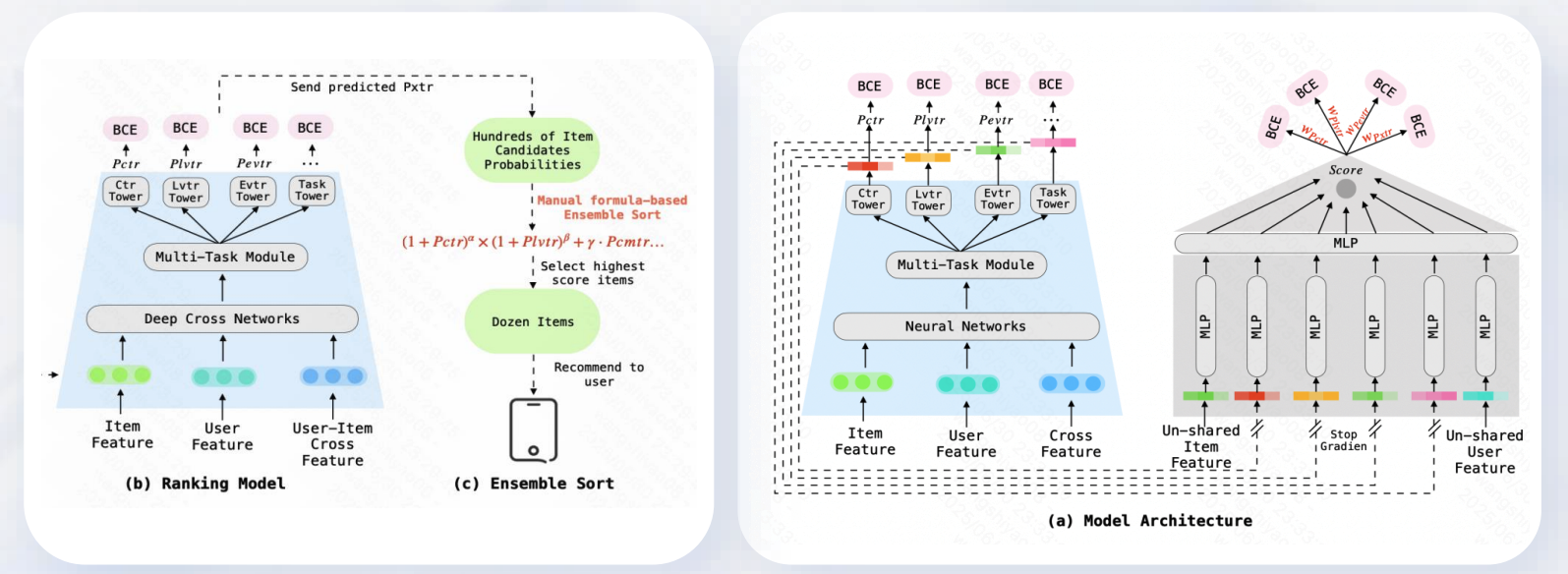
模型核心架构包含共享特征提取层与多任务模块:
- 共享特征提取层:整合Item Feature(物品特征)、User Feature(用户特征)、Cross Feature(交叉特征),通过多层MLP(多层感知机)提取共享特征,同时对Item Feature、User Feature做“不共享”处理(通过Stop Gradient机制),保留个性化特征。
- 多任务模块:基于共享特征,构建多任务学习框架,涵盖CTR Tower(点击率预测)、Lvttr Tower(长期价值预测)、Evr Tower(曝光价值预测)、Task Tower(任务相关预测)等子任务,各任务通过BCE(二元交叉熵)损失函数优化。
在Ranking Model中,通过Deep Cross Networks融合Item Feature、User Feature、User-Item Cross Feature(用户-物品交叉特征),生成多维度候选物品概率;再经手动公式化集成排序,筛选出高分物品推荐给用户。
Ensemble Sort环节中,先通过“手动公式化集成排序”从“数百个物品候选概率”中筛选出“数十个高分物品”,再将这些物品传递至用户端完成推荐。
3.3.2 业务偏好对齐
3.3.3 规则对齐
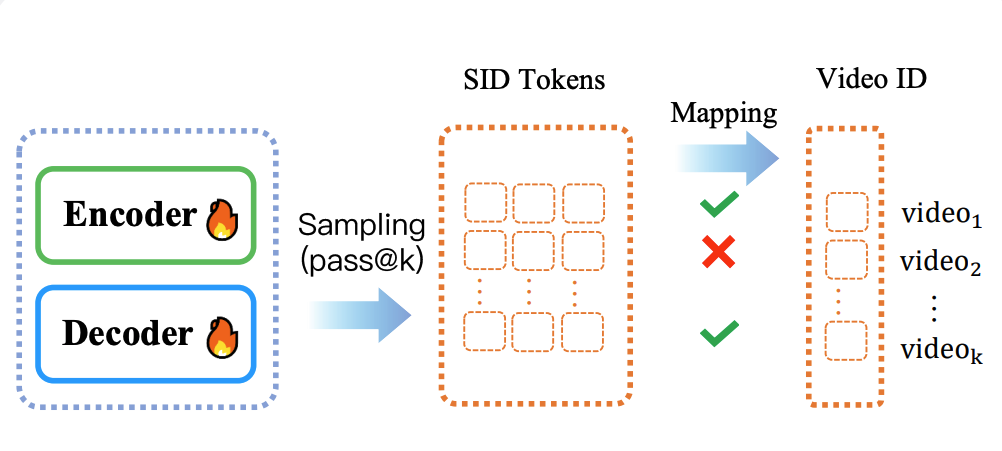
Encoder与Decoder间标注“Sampling(pass@k)”,表示模型通过采样机制(pass@k策略)生成中间结果。
模型生成语义ID(SID)后,需通过“反解”步骤得到确切的视频ID(Video ID)。但该反解过程存在风险:SID组合可能“不合法”,导致映射失败或结果错误。
3.4 性能优化

四、Lazy Decoder Only:推荐Scaling的定制优化
4.1 样本组织形式
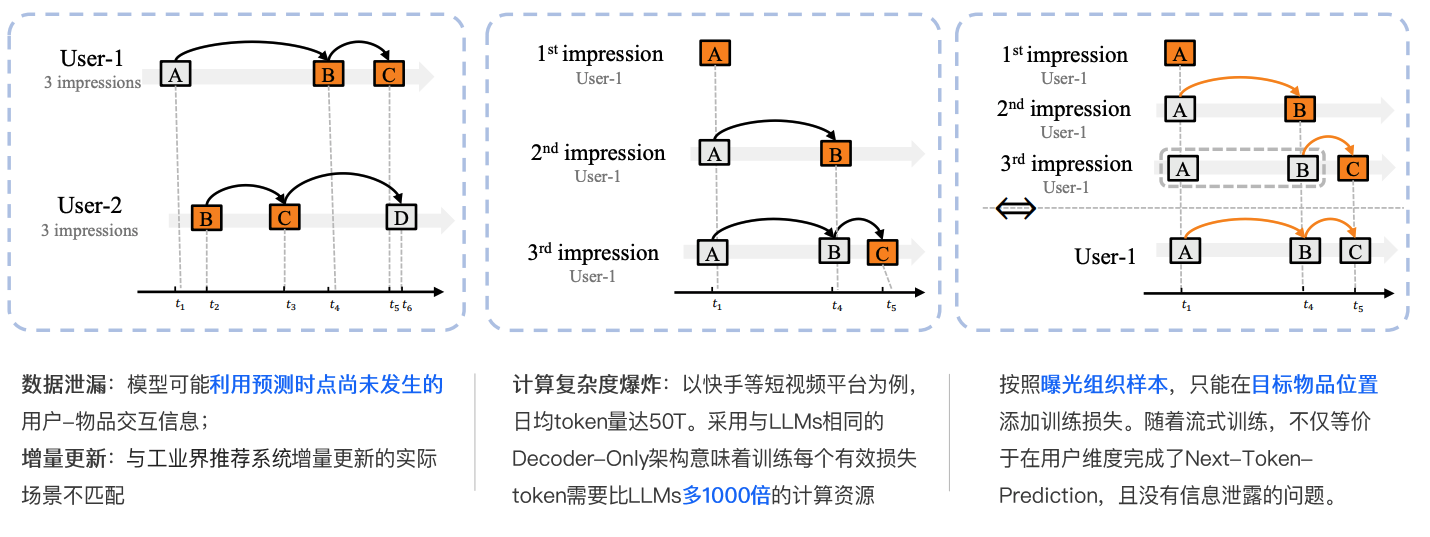
以下从数据泄漏风险、计算复杂度挑战、曝光组织方案优势三方面拆解样本组织形式的核心问题:
4.1.1 数据泄漏风险
传统样本组织方式存在数据泄漏隐患:模型可能在预测时“提前”利用未来交互信息(即预测时点尚未发生的用户 - 物品交互行为)。这种信息泄露会干扰模型对“当前交互逻辑”的学习,导致训练与实际场景(如推荐系统实时预测)的匹配度下降。
4.1.2 计算复杂度挑战
以短视频平台(如快手)为例,日均处理的token量级达50T。若采用与大语言模型(LLMs)一致的Decoder - Only架构,训练每个有效损失token所需的计算资源,是LLMs的1000倍。这种“计算复杂度爆炸”直接制约了模型在工业级场景的落地效率。
4.1.3 曝光组织方案优势
通过按曝光组织样本的方式,可解决核心痛点:
- 数据泄漏规避:仅在目标物品位置添加训练损失,严格限制模型对“未来交互”的依赖,确保训练逻辑与实际预测场景一致;
- 计算资源优化:等价于在用户维度完成“Next - Token - Prediction”任务,且无信息泄露问题,大幅降低计算复杂度,匹配工业界“增量更新”等实际场景需求。
4.2 Encoder-Decoder 的训练瓶颈
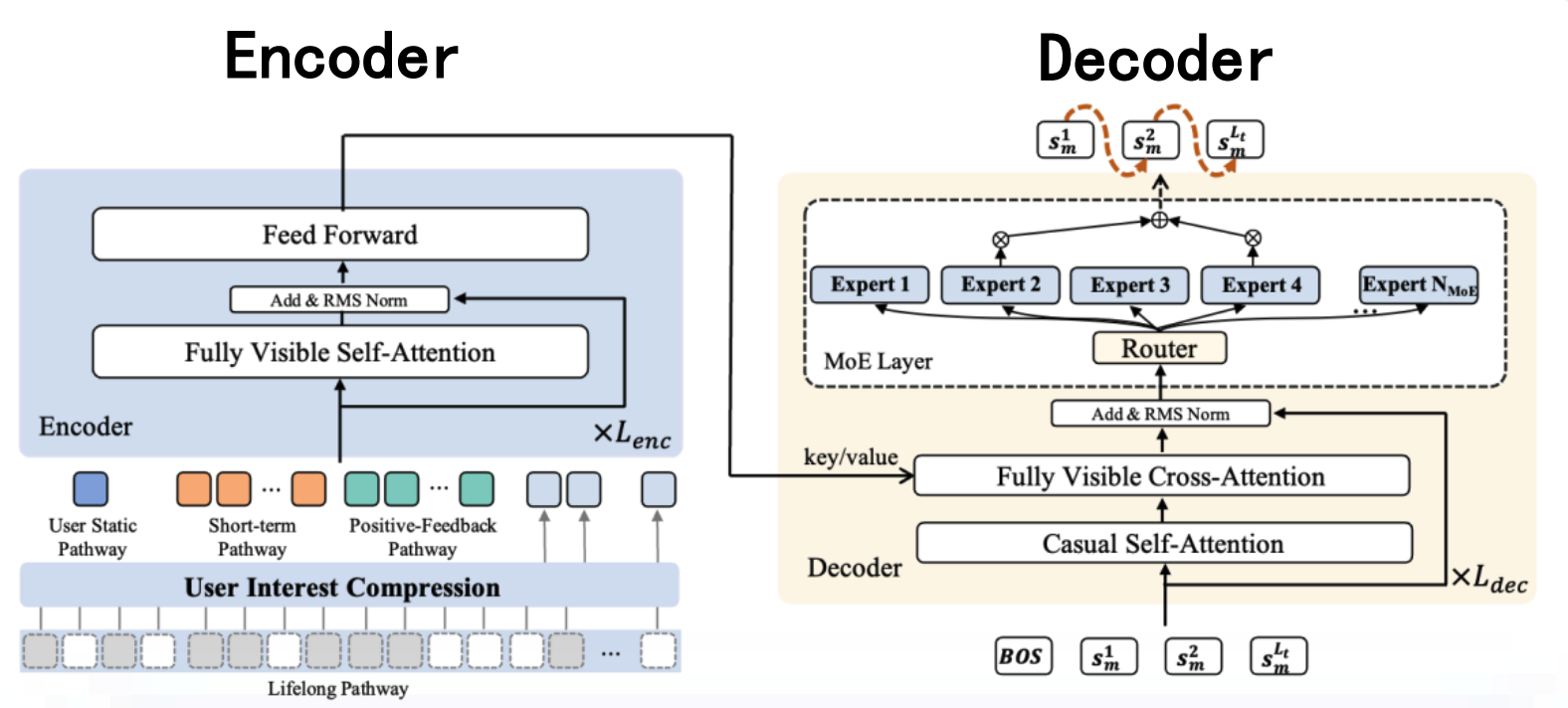
4.2.1 核心结构拆解
Encoder - Decoder 是序列到序列任务的经典架构,图中左侧为 Encoder、右侧为 Decoder,二者通过注意力机制协同完成信息编码与解码。
- Encoder(编码器):
以用户特征(如用户静态路径、短期路径、正反馈路径、终身路径)为输入,通过多层堆叠的「Fully Visible Self - Attention(全可见自注意力)」与「Feed Forward(前馈层)」,结合「Add & RMS Norm(残差连接 + 标准化)」模块,对输入特征进行深度编码,输出压缩后的用户兴趣表示。 - Decoder(解码器):
接收 Encoder 的输出作为 Key/Value,通过「Fully Visible Cross - Attention(全可见交叉注意力)」与「Casual Self - Attention(因果自注意力)」模块,结合「MoE Layer(专家混合层)」与「Router(路由模块)」,逐步生成目标序列(如文本生成、序列预测等任务的输出)。
4.2.2 训练瓶颈问题
- 监督信息量与计算量失衡:
Encoder 接触的监督信息量(用于指导训练的标注信息)远少于其承担的计算量,导致模型难以高效利用计算资源学习任务特征。 - 计算 - 效果转换率低:
训练过程中,模型消耗的计算资源(如 GPU 时间、浮点运算量)与最终任务性能(如生成质量、预测精度)的提升幅度不成正比,资源利用率低。 - 模型尺寸天花板限制:
传统 Encoder - Decoder 架构在模型参数量、计算复杂度等方面存在天然上限,难以通过简单扩大规模突破性能瓶颈。
4.2.3 小结
Encoder - Decoder 架构在序列任务中兼具灵活性与表达力,但训练阶段的「监督信息 - 计算量失衡」「资源利用率低」「规模天花板」等问题,限制了其性能上限。需结合模型设计(如引入专家混合层、优化注意力机制)与训练策略(如强化监督信号、提升计算 - 效果转换效率)针对性解决。
4.3 快手的解法——Lazy Decoder Only
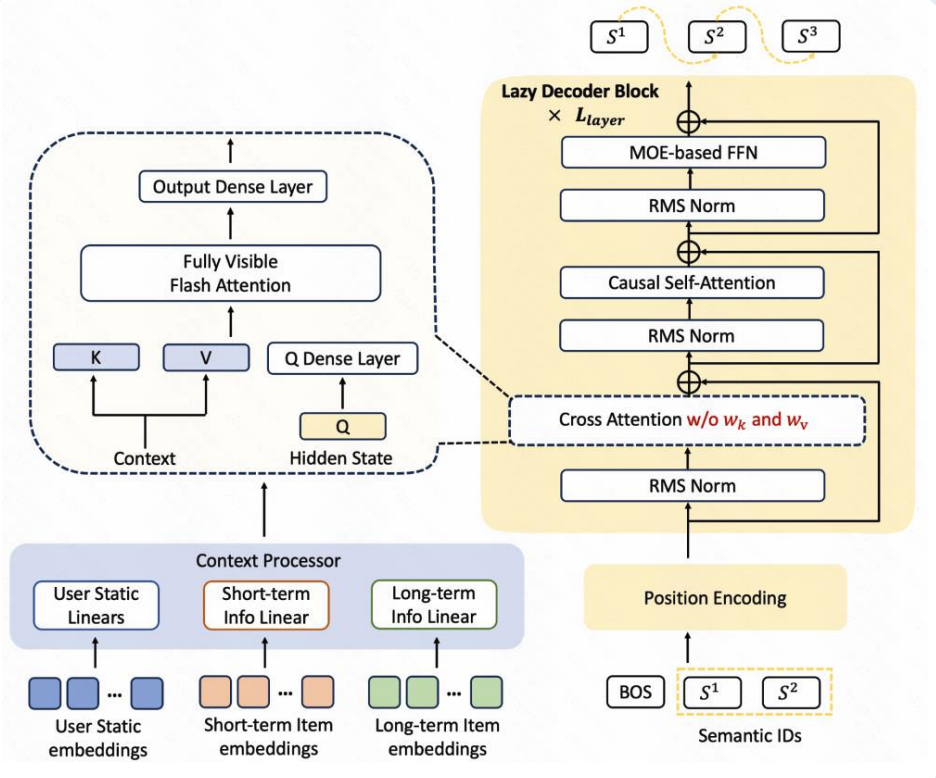
为提升效率与性能,架构在Encoder、Cross Attention、Decoder三方面进行针对性优化:
- 极简 Encoder
采用“小FC”(小规模全连接层)实现特征对齐,大幅降低Encoder计算量,简化模型结构。 - 简化 Cross Attention
去除 K/V 的全连接层(FC),减少交叉注意力模块的计算开销,提升解码速度。 - 强化 Decoder
通过懒惰解码策略集中算力于解码 Token 位置,优化计算资源分配,提升解码效率。
该架构通过模块化设计与针对性优化,实现高效序列处理与资源利用,适用于推荐、对话等需快速生成的场景。
五、OneRec-Think:全模态生成理解统一基座
大语言模型的深度推理能力源自token - by - token的深度语义搜索,而推荐系统OneRec目前缺乏自然语言领域的通用知识表征,导致其难以自主产生认知推理过程。
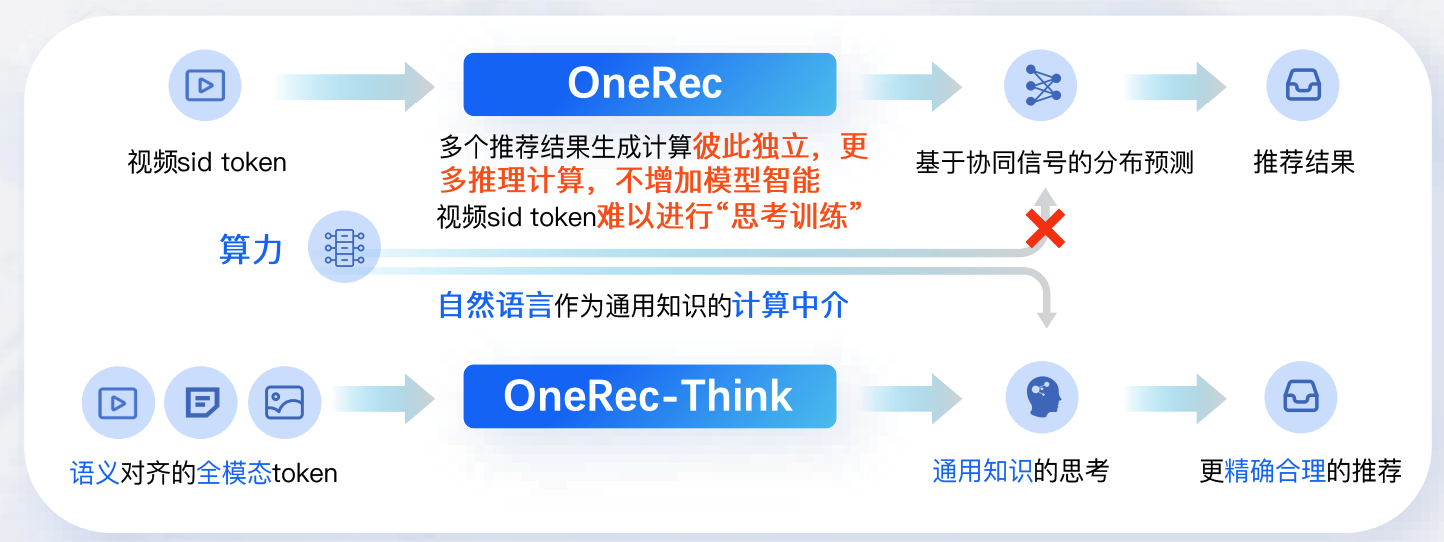
OneRec的推荐逻辑以“视频sid token”为输入,经“算力”环节后,通过“多个推荐结果生成计算(彼此独立、更多推理计算、不增加模型智能)”、“视频sid token难以进行‘思考训练’”、“自然语言作为通用知识的计算中介”等环节,最终输出“推荐结果”。
OneRec-Think的推荐逻辑以“语义对齐的全模态token”为输入,经“通用知识的思考”环节后,输出“更精确合理的推荐”。