SciKit-Learn 全面分析 20newsgroups 新闻组文本数据集(文本分类)
文章目录
- 背景
- 数据概览
- 分析方法
- 分析步骤
- 分析结果
- 词云图
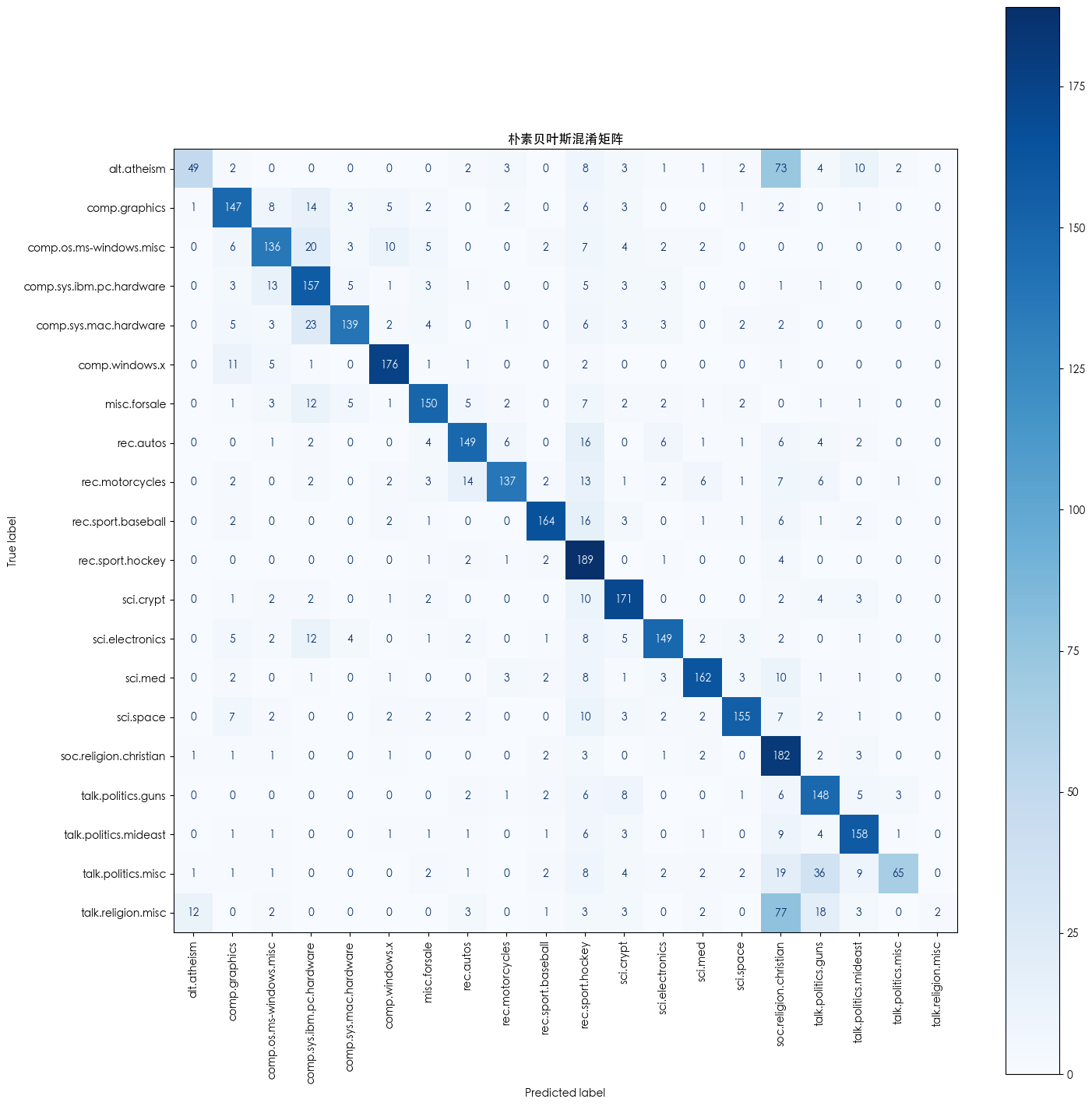
- 不同模型的混淆矩阵
- 超参数调优后的 SVM 混淆矩阵
- 不同模型的 ROC 及 AUC 对比
- t-SNE 降维及可视化
- 不同模型评估明细
- 代码
背景
fetch_20newsgroups 20个新闻组文本数据集,用于文本分类
| 计算机相关 (Computer) | 娱乐相关 (Recreation) | 科学相关 (Science) | Society & Politics | Religion |
|---|---|---|---|---|
| comp.graphics | rec.autos | sci.crypt | misc.forsale | alt.atheism |
| comp.os.ms-windows.misc | rec.motorcycles | sci.electronics | talk.politics.misc | soc.religion.christian |
| comp.sys.ibm.pc.hardware | rec.sport.baseball | sci.med | talk.politics.guns | talk.religion.misc |
| comp.sys.mac.hardware | rec.sport.hockey | sci.space | talk.politics.mideast | |
| comp.windows.x |
数据概览
from sklearn.datasets import fetch_20newsgroupsnewsgroups_data = fetch_20newsgroups(subset='all', shuffle=True, random_state=42)newsgroups_data.keys()
"""
dict_keys(['data', 'filenames', 'target_names', 'target', 'DESCR'])
"""# 查看类别
print(newsgroups_data.target_names)
"""
['alt.atheism','comp.graphics','comp.os.ms-windows.misc','comp.sys.ibm.pc.hardware','comp.sys.mac.hardware','comp.windows.x','misc.forsale','rec.autos','rec.motorcycles','rec.sport.baseball','rec.sport.hockey','sci.crypt','sci.electronics','sci.med','sci.space','soc.religion.christian','talk.politics.guns','talk.politics.mideast','talk.politics.misc','talk.religion.misc']
"""newsgroups_data.target.shape
"""
(18846,)
"""# 随机返回一条数据
import random
random_int = random.randint(0, 18845)
print(newsgroups_data.data[random_int])
"""
From: messina@netcom.com (Tony Porczyk)
Subject: Re: (Some info) The DOS/MSW meltdown is progressing nicely
Organization: Messina Software
Lines: 18ajayshah@almaak.usc.edu (Ajay Shah) writes:>"The Preferred Applications Development Platform"
>according to 432 of the Fortune 1000 corporations
>Survey by Sentry Market Research Survey
> 1992 1993
>Unix 18 28
>Mainframe 35 22
>DOS & MSW 24 18Development of what? In-house apps? Maybe, but certainly not apps
to be sold on an open market. Statistics like that are laughable,
because they may simply mean that there are not enough shrink-wrapped
usable apps for UNIX and they have to be developed disproportionately
often as compared to the installed UNIX base.
"""
分析方法
- SVM
- 朴素贝叶斯
- 随机森林
- 逻辑回归
分析步骤
- 加载数据集
- 拆分数据集(训练集、测试集)
- 数据预处理(TF-IDF)
- 选择模型
- 训练模型(拟合)
- 评估模型及可视化(准确率、ROC、AUC、混淆矩阵,词云、t-SNE)
- 优化模型(针对 SVM 进行超参数调优)
分析结果
词云图
不同模型的混淆矩阵
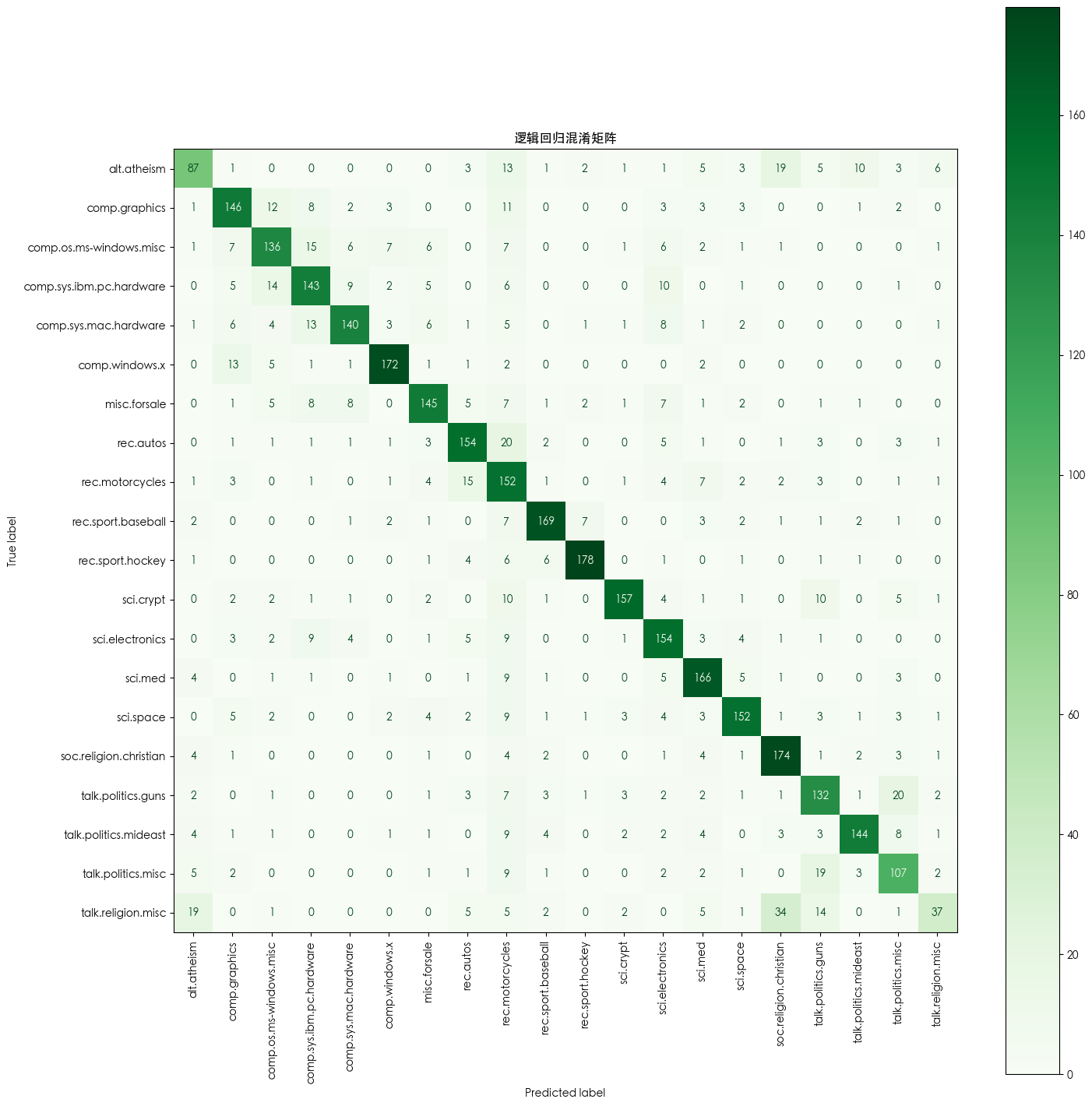
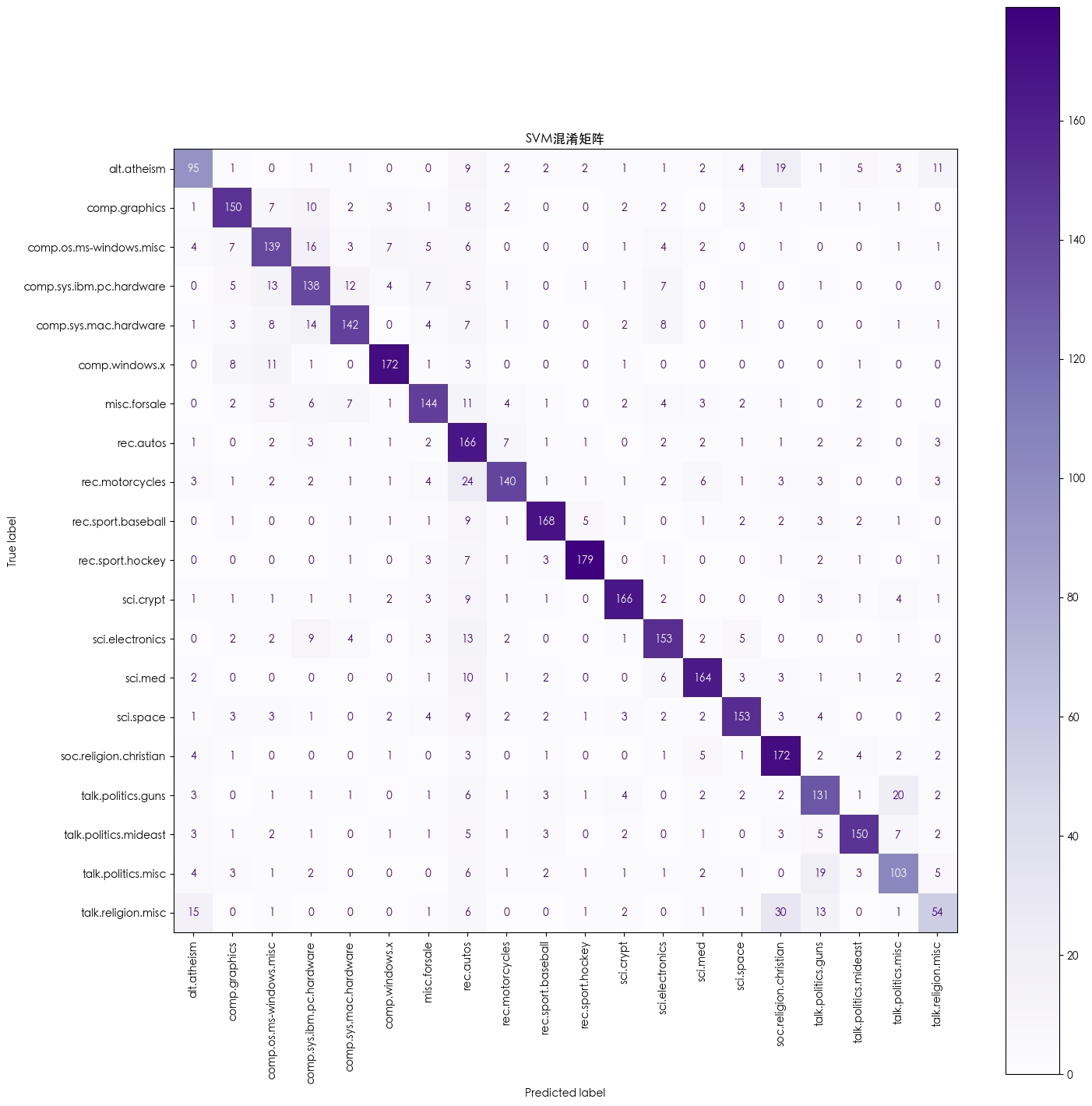
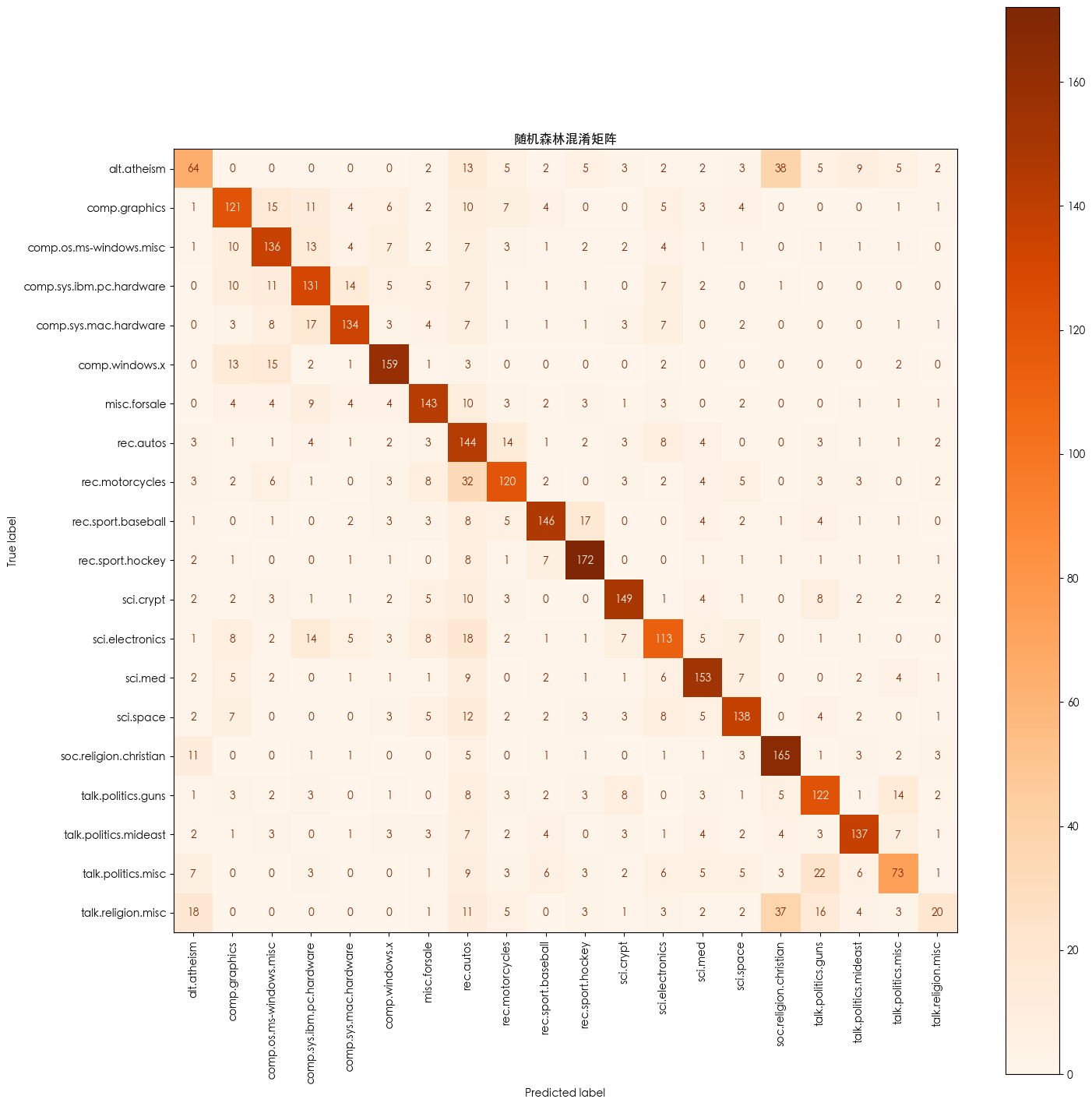
超参数调优后的 SVM 混淆矩阵
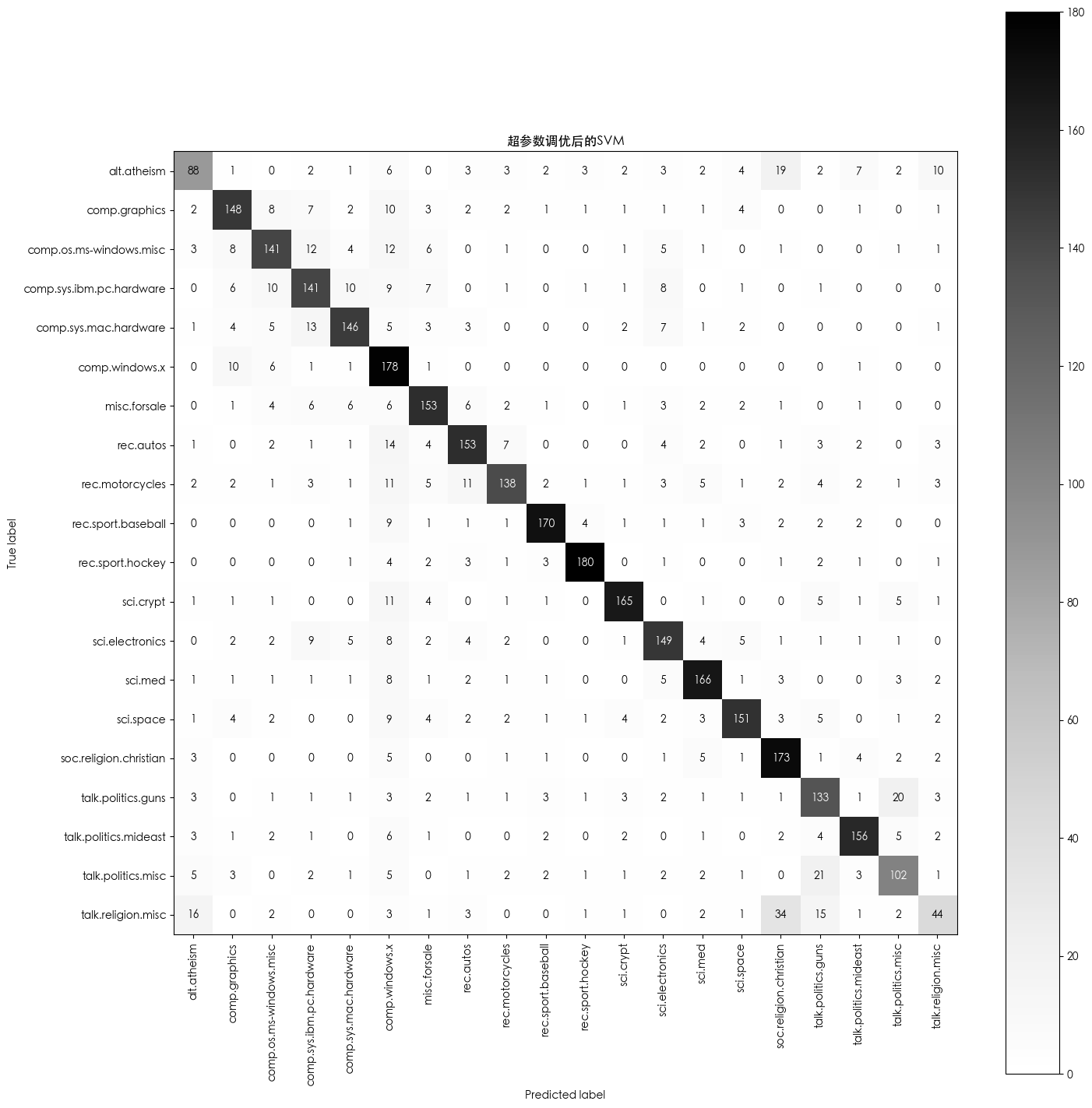
不同模型的 ROC 及 AUC 对比
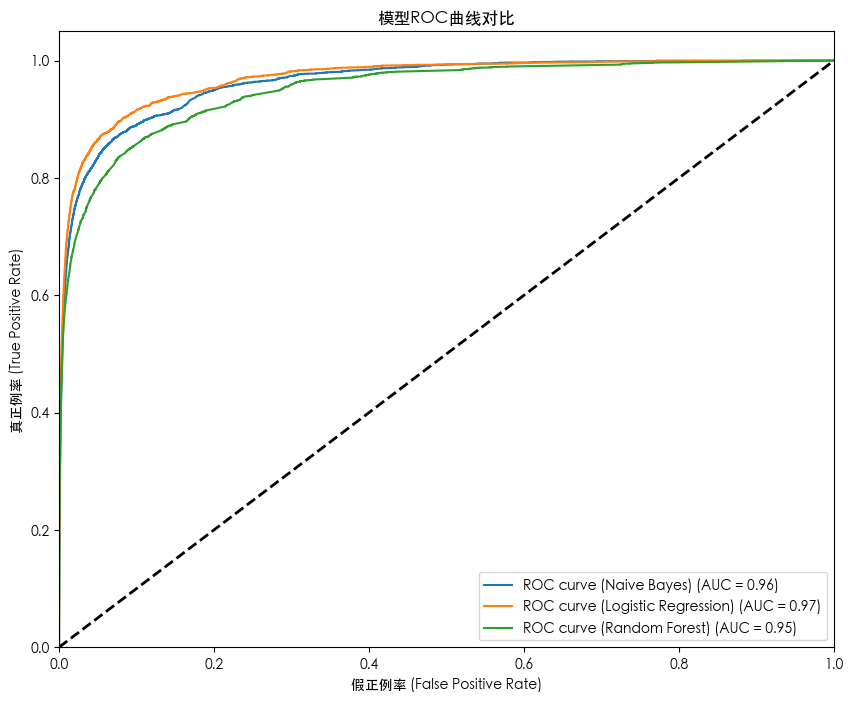
t-SNE 降维及可视化
不同模型评估明细
正在加载所有 20 个新闻组数据集...
数据集加载成功!
总共 18846 个文档,共 20 个类别。--- 正在划分数据集并转换为TF-IDF特征... ---
训练集大小: 15076,测试集大小: 3770--- 正在训练朴素贝叶斯模型... ---
朴素贝叶斯模型训练完成!
训练耗时: 0.02 秒precision recall f1-score supportalt.atheism 0.77 0.31 0.44 160comp.graphics 0.75 0.75 0.75 195comp.os.ms-windows.misc 0.76 0.69 0.72 197
comp.sys.ibm.pc.hardware 0.64 0.80 0.71 196comp.sys.mac.hardware 0.87 0.72 0.79 193comp.windows.x 0.86 0.89 0.87 198misc.forsale 0.82 0.77 0.80 195rec.autos 0.81 0.75 0.78 198rec.motorcycles 0.88 0.69 0.77 199rec.sport.baseball 0.91 0.82 0.86 199rec.sport.hockey 0.56 0.94 0.70 200sci.crypt 0.78 0.86 0.82 198sci.electronics 0.84 0.76 0.80 197sci.med 0.88 0.82 0.85 198sci.space 0.89 0.79 0.84 197soc.religion.christian 0.44 0.91 0.59 199talk.politics.guns 0.64 0.81 0.71 182talk.politics.mideast 0.79 0.84 0.81 188talk.politics.misc 0.90 0.42 0.57 155talk.religion.misc 1.00 0.02 0.03 126accuracy 0.74 3770macro avg 0.79 0.72 0.71 3770weighted avg 0.78 0.74 0.73 3770--- 正在训练逻辑回归模型... ---
逻辑回归模型训练完成!
训练耗时: 7.33 秒precision recall f1-score supportalt.atheism 0.66 0.54 0.60 160comp.graphics 0.74 0.75 0.74 195comp.os.ms-windows.misc 0.73 0.69 0.71 197
comp.sys.ibm.pc.hardware 0.71 0.73 0.72 196comp.sys.mac.hardware 0.81 0.73 0.77 193comp.windows.x 0.88 0.87 0.88 198misc.forsale 0.79 0.74 0.77 195rec.autos 0.77 0.78 0.77 198rec.motorcycles 0.50 0.76 0.60 199rec.sport.baseball 0.87 0.85 0.86 199rec.sport.hockey 0.93 0.89 0.91 200sci.crypt 0.91 0.79 0.85 198sci.electronics 0.70 0.78 0.74 197sci.med 0.77 0.84 0.80 198sci.space 0.83 0.77 0.80 197soc.religion.christian 0.73 0.87 0.79 199talk.politics.guns 0.67 0.73 0.70 182talk.politics.mideast 0.87 0.77 0.81 188talk.politics.misc 0.66 0.69 0.68 155talk.religion.misc 0.67 0.29 0.41 126accuracy 0.75 3770macro avg 0.76 0.74 0.74 3770weighted avg 0.76 0.75 0.75 3770--- 正在训练SVM模型... ---
SVM模型训练完成!
训练耗时: 0.79 秒precision recall f1-score supportalt.atheism 0.69 0.59 0.64 160comp.graphics 0.79 0.77 0.78 195comp.os.ms-windows.misc 0.70 0.71 0.70 197
comp.sys.ibm.pc.hardware 0.67 0.70 0.69 196comp.sys.mac.hardware 0.80 0.74 0.77 193comp.windows.x 0.88 0.87 0.87 198misc.forsale 0.77 0.74 0.76 195rec.autos 0.52 0.84 0.64 198rec.motorcycles 0.83 0.70 0.76 199rec.sport.baseball 0.88 0.84 0.86 199rec.sport.hockey 0.93 0.90 0.91 200sci.crypt 0.87 0.84 0.85 198sci.electronics 0.78 0.78 0.78 197sci.med 0.84 0.83 0.83 198sci.space 0.85 0.78 0.81 197soc.religion.christian 0.71 0.86 0.78 199talk.politics.guns 0.69 0.72 0.70 182talk.politics.mideast 0.86 0.80 0.83 188talk.politics.misc 0.70 0.66 0.68 155talk.religion.misc 0.60 0.43 0.50 126accuracy 0.76 3770macro avg 0.77 0.75 0.76 3770weighted avg 0.77 0.76 0.76 3770--- 正在训练随机森林模型... ---
随机森林模型训练完成!
训练耗时: 3.60 秒precision recall f1-score supportalt.atheism 0.53 0.40 0.46 160comp.graphics 0.63 0.62 0.63 195comp.os.ms-windows.misc 0.65 0.69 0.67 197
comp.sys.ibm.pc.hardware 0.62 0.67 0.65 196comp.sys.mac.hardware 0.77 0.69 0.73 193comp.windows.x 0.77 0.80 0.79 198misc.forsale 0.73 0.73 0.73 195rec.autos 0.43 0.73 0.54 198rec.motorcycles 0.67 0.60 0.63 199rec.sport.baseball 0.79 0.73 0.76 199rec.sport.hockey 0.79 0.86 0.82 200sci.crypt 0.79 0.75 0.77 198sci.electronics 0.63 0.57 0.60 197sci.med 0.75 0.77 0.76 198sci.space 0.74 0.70 0.72 197soc.religion.christian 0.65 0.83 0.73 199talk.politics.guns 0.63 0.67 0.65 182talk.politics.mideast 0.78 0.73 0.75 188talk.politics.misc 0.61 0.47 0.53 155talk.religion.misc 0.49 0.16 0.24 126accuracy 0.67 3770macro avg 0.67 0.66 0.66 3770weighted avg 0.68 0.67 0.67 3770--- 正在使用网格搜索调优SVM模型... ---
Fitting 5 folds for each of 6 candidates, totalling 30 fits
网格搜索完成!
网格搜索耗时: 27.06 秒
最佳参数: {'C': 1, 'loss': 'hinge'}
最佳交叉验证分数: 0.7526--- 超参数调优后SVM模型的评估报告 ---precision recall f1-score supportalt.atheism 0.68 0.55 0.61 160comp.graphics 0.77 0.76 0.76 195comp.os.ms-windows.misc 0.75 0.72 0.73 197
comp.sys.ibm.pc.hardware 0.70 0.72 0.71 196comp.sys.mac.hardware 0.80 0.76 0.78 193comp.windows.x 0.55 0.90 0.68 198misc.forsale 0.77 0.78 0.77 195rec.autos 0.78 0.77 0.78 198rec.motorcycles 0.83 0.69 0.76 199rec.sport.baseball 0.89 0.85 0.87 199rec.sport.hockey 0.93 0.90 0.91 200sci.crypt 0.88 0.83 0.86 198sci.electronics 0.76 0.76 0.76 197sci.med 0.83 0.84 0.83 198sci.space 0.85 0.77 0.81 197soc.religion.christian 0.71 0.87 0.78 199talk.politics.guns 0.67 0.73 0.70 182talk.politics.mideast 0.85 0.83 0.84 188talk.politics.misc 0.70 0.66 0.68 155talk.religion.misc 0.57 0.35 0.43 126accuracy 0.76 3770macro avg 0.76 0.75 0.75 3770weighted avg 0.77 0.76 0.76 3770
代码
import numpy as np
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.naive_bayes import MultinomialNB
from sklearn.linear_model import LogisticRegression
from sklearn.svm import LinearSVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, ConfusionMatrixDisplay, RocCurveDisplay, roc_curve, auc, RocCurveDisplay
from sklearn.preprocessing import label_binarize
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
from wordcloud import WordCloud
from sklearn.feature_extraction.text import CountVectorizer
import matplotlib.font_manager as fm
import warnings
import time# --- 解决中文显示问题(更健壮的方法) ---
# 检查系统中是否存在支持中文的字体。
# 设置 Matplotlib 字体以正确显示中文
plt.rcParams['font.sans-serif'] = ['SimHei', 'WenQuanYi Zen Hei', 'STHeiti', 'Arial Unicode MS']
plt.rcParams['axes.unicode_minus'] = False
wordcloud_title = "所有类别词云图"
matrix_title_nb = "朴素贝叶斯混淆矩阵"
matrix_title_lr = "逻辑回归混淆矩阵"
matrix_title_svm = "SVM混淆矩阵"
matrix_title_rf = "随机森林混淆矩阵"
roc_title = "模型ROC曲线对比"
tsne_title = "t-SNE降维可视化"
gs_title = "超参数调优后的SVM"# --- 加载数据集 ---
print("正在加载所有 20 个新闻组数据集...")
newsgroups_data = fetch_20newsgroups(subset='all',categories=None,remove=('headers', 'footers', 'quotes'),shuffle=True,random_state=42
)
print("数据集加载成功!")
print(f"总共 {len(newsgroups_data.data)} 个文档,共 {len(newsgroups_data.target_names)} 个类别。")# --- 数据集划分与特征提取 ---
print("\n--- 正在划分数据集并转换为TF-IDF特征... ---")
X = newsgroups_data.data
y = newsgroups_data.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)
tfidf_vectorizer = TfidfVectorizer(stop_words='english', max_df=0.95, min_df=2)
X_train_tfidf = tfidf_vectorizer.fit_transform(X_train)
X_test_tfidf = tfidf_vectorizer.transform(X_test)
print(f"训练集大小: {len(X_train)},测试集大小: {len(X_test)}")# --- 模型训练与评估 ---
print("\n--- 正在训练朴素贝叶斯模型... ---")
start_time = time.time()
classifier_nb = MultinomialNB()
classifier_nb.fit(X_train_tfidf, y_train)
end_time = time.time()
print("朴素贝叶斯模型训练完成!")
print(f"训练耗时: {end_time - start_time:.2f} 秒")
y_pred_nb = classifier_nb.predict(X_test_tfidf)
print(classification_report(y_test, y_pred_nb, target_names=newsgroups_data.target_names))print("\n--- 正在训练逻辑回归模型... ---")
start_time = time.time()
classifier_lr = LogisticRegression(max_iter=1000)
classifier_lr.fit(X_train_tfidf, y_train)
end_time = time.time()
print("逻辑回归模型训练完成!")
print(f"训练耗时: {end_time - start_time:.2f} 秒")
y_pred_lr = classifier_lr.predict(X_test_tfidf)
print(classification_report(y_test, y_pred_lr, target_names=newsgroups_data.target_names))print("\n--- 正在训练SVM模型... ---")
start_time = time.time()
classifier_svm = LinearSVC(max_iter=5000)
classifier_svm.fit(X_train_tfidf, y_train)
end_time = time.time()
print("SVM模型训练完成!")
print(f"训练耗时: {end_time - start_time:.2f} 秒")
y_pred_svm = classifier_svm.predict(X_test_tfidf)
print(classification_report(y_test, y_pred_svm, target_names=newsgroups_data.target_names))print("\n--- 正在训练随机森林模型... ---")
start_time = time.time()
classifier_rf = RandomForestClassifier(n_estimators=100, random_state=42, n_jobs=-1)
classifier_rf.fit(X_train_tfidf, y_train)
end_time = time.time()
print("随机森林模型训练完成!")
print(f"训练耗时: {end_time - start_time:.2f} 秒")
y_pred_rf = classifier_rf.predict(X_test_tfidf)
print(classification_report(y_test, y_pred_rf, target_names=newsgroups_data.target_names))# --- 超参数调优: 使用GridSearchCV优化SVM模型 ---
print("\n--- 正在使用网格搜索调优SVM模型... ---")
start_time = time.time()
param_grid = {'C': [0.1, 1, 10],'loss': ['hinge', 'squared_hinge']
}
grid_search = GridSearchCV(LinearSVC(max_iter=5000), param_grid, cv=5, n_jobs=-1, verbose=1)
grid_search.fit(X_train_tfidf, y_train)
end_time = time.time()
print("网格搜索完成!")
print(f"网格搜索耗时: {end_time - start_time:.2f} 秒")
print(f"最佳参数: {grid_search.best_params_}")
print(f"最佳交叉验证分数: {grid_search.best_score_:.4f}")# 使用最佳参数训练最终模型并评估
best_svm = grid_search.best_estimator_
y_pred_best_svm = best_svm.predict(X_test_tfidf)
print("\n--- 超参数调优后SVM模型的评估报告 ---")
print(classification_report(y_test, y_pred_best_svm, target_names=newsgroups_data.target_names))# --- 可视化 ---# 1. 词云图
print("\n--- 正在生成词云图... ---")
count_vectorizer = CountVectorizer(stop_words='english', max_df=0.95, min_df=2)
word_counts = count_vectorizer.fit_transform(newsgroups_data.data)
word_freq = dict(zip(count_vectorizer.get_feature_names_out(), np.ravel(word_counts.sum(axis=0))))
wordcloud = WordCloud(width=800, height=400, background_color='white').generate_from_frequencies(word_freq)plt.figure(figsize=(10, 5))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plt.title(wordcloud_title)
plt.show()# 2. 混淆矩阵
print("\n--- 正在生成所有模型的混淆矩阵... ---")
models = {'Naive Bayes': (y_pred_nb, matrix_title_nb, plt.cm.Blues),'Logistic Regression': (y_pred_lr, matrix_title_lr, plt.cm.Greens),'SVM': (y_pred_svm, matrix_title_svm, plt.cm.Purples),'Random Forest': (y_pred_rf, matrix_title_rf, plt.cm.Oranges),'Tuned SVM': (y_pred_best_svm, gs_title, plt.cm.Greys)
}
for name, (y_pred, title, cmap) in models.items():fig, ax = plt.subplots(figsize=(15, 15))ConfusionMatrixDisplay.from_predictions(y_test, y_pred, ax=ax,display_labels=newsgroups_data.target_names,xticks_rotation='vertical', cmap=cmap)plt.title(title)plt.tight_layout()plt.show()# 3. ROC曲线和AUC分数
print("\n--- 正在生成ROC曲线... ---")
# 绘制所有模型的微平均(Micro-average)ROC曲线。
plt.figure(figsize=(10, 8))
y_test_binarized = label_binarize(y_test, classes=range(newsgroups_data.target.max() + 1))
models_for_roc = {'Naive Bayes': classifier_nb,'Logistic Regression': classifier_lr,'Random Forest': classifier_rf
}for name, model in models_for_roc.items():if hasattr(model, "predict_proba"):y_score = model.predict_proba(X_test_tfidf)fpr, tpr, _ = roc_curve(y_test_binarized.ravel(), y_score.ravel())roc_auc = auc(fpr, tpr)plt.plot(fpr, tpr, label=f'ROC curve ({name}) (AUC = {roc_auc:.2f})')plt.plot([0, 1], [0, 1], 'k--', lw=2)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('假正例率 (False Positive Rate)')
plt.ylabel('真正例率 (True Positive Rate)')
plt.title(roc_title)
plt.legend(loc="lower right")
plt.show()# --- 4. t-SNE 降维与可视化 ---
print("\n--- 正在进行 t-SNE 降维与可视化... ---")
print("注意: t-SNE 计算时间较长,且结果随机性较大。")# 为了提高效率,我们只对训练集进行 t-SNE
X_tsne = X_train_tfidf.toarray()
y_tsne = y_train# 进一步采样以减少计算量,选择5000个样本
indices = np.random.choice(range(X_tsne.shape[0]), size=5000, replace=False)
X_tsne_subset = X_tsne[indices]
y_tsne_subset = y_tsne[indices]# 使用t-SNE将数据降维到2维
tsne = TSNE(n_components=2, random_state=42, perplexity=30)
X_tsne_2d = tsne.fit_transform(X_tsne_subset)# 绘制散点图
plt.figure(figsize=(15, 12))
# 使用新的、非弃用的方法来获取颜色映射
cmap = plt.colormaps['Spectral']# 将所有点一次性绘制,并使用y_tsne_subset作为颜色映射
scatter = plt.scatter(X_tsne_2d[:, 0], X_tsne_2d[:, 1],c=y_tsne_subset, cmap=cmap, s=10)plt.title(tsne_title)
plt.xlabel("t-SNE Component 1")
plt.ylabel("t-SNE Component 2")
plt.grid(True)# 创建并添加图例
legend_elements = []
num_classes = newsgroups_data.target.max() + 1
for i, target_name in enumerate(newsgroups_data.target_names):legend_elements.append(plt.Line2D([0], [0], marker='o', color='w',label=target_name,markerfacecolor=cmap(i / (num_classes - 1)),markersize=10))plt.legend(handles=legend_elements, title="类别", loc="best", bbox_to_anchor=(1.05, 1))
plt.tight_layout()
plt.show()