FlashAttention(V3)深度解析:从原理到工程实现-Hopper架构下的注意力机制优化革命
FlashAttention(V3)深度解析:从原理到工程实现-Hopper架构下的注意力机制优化革命
前言
2024年7月,Tri Dao等人发布了FlashAttention-3(FA3),这是专为最新Hopper架构(H100/H200)设计的注意力机制优化算法。FA3在H100上实现了高达75%的GPU利用率,相比FA2有了显著的性能提升。本文将从硬件架构特性出发,深入分析FA3的核心技术创新,并探讨各大语言模型的采用情况。
本文从原理出发,完整描述 FlashAttention-3 的三大核心技术点及其工程实现细节,包括 Warp 专用化与生产者消费者并行、块级矩阵乘法与 Softmax 的交错执行、以及基于块的量化与非一致处理。文中给出关键公式、伪代码和工程级的 PyTorch 使用示例。同时对 Qwen 系列、Deepseek、GLM 系列、Llama 系列、GPT 系列等主流模型是否采用 FlashAttention-3 给出工程化判断和建议。文末给出部署建议。
1、背景与动机
自注意力是 Transformer 的核心操作,其计算复杂度和内存访问模式直接决定了长上下文和大模型的训练与推理成本。FlashAttention 系列的目标是将注意力计算重排为块级读入、在片上缓存中计算、并最小化对显存的读写,从而显著降低内存带宽开销并提高吞吐率。FlashAttention-3 针对现代 Hopper 系列 GPU 的硬件特性做了深度优化,重点利用了张量核的异步能力与高效的 TMA 数据搬运机制,从而在 FP16 和低精度 FP8 下获得显著加速。
2、注意力机制基础
在深入FA3之前,我们先回顾一下标准注意力机制的计算公式:
S=QKT∈RN×NS = QK^T \in \mathbb{R}^{N \times N}S=QKT∈RN×N
P=softmax(S)∈RN×NP = \text{softmax}(S) \in \mathbb{R}^{N \times N}P=softmax(S)∈RN×N
O=PV∈RN×dO = PV \in \mathbb{R}^{N \times d}O=PV∈RN×d
其中:
- Q,K,V∈RN×dQ, K, V \in \mathbb{R}^{N \times d}Q,K,V∈RN×d 分别为查询、键值和值矩阵
- NNN 为序列长度,ddd 为头维度
- SSS 为注意力分数矩阵
- PPP 为注意力权重矩阵
- OOO 为输出矩阵
标准实现需要存储O(N2)O(N^2)O(N2)的中间结果SSS和PPP,这在长序列下会导致严重的显存问题。
3、FlashAttention 系列演进概览
简要回顾:
- FlashAttention-1 初版通过块级 I O 重新组织计算,显著降低了 HBM 读写;
- FlashAttention-2 在分工并行与工作划分上做了改进,但在 Hopper 系列 GPU 上未充分利用张量核的异步能力;
- FlashAttention-3 面向 Hopper 系列展开,提出三大创新机制来提升利用率和精度,支持 FP16 与低精度 FP8 的工程化使用。
4、FlashAttention-3 原理详解
下面逐项展开 FlashAttention-3 的核心技术点,尽量给出可实现的伪代码和数学表达,便于工程实现与调试。
4.1 Warp 专用化与异步数据移动
硬件事实是:Hopper 系列 GPU 的张量核和 TMA 可以并发执行,如果把数据搬运和计算放在同一个 warp 内会出现资源竞争。FlashAttention-3 的做法是把一个线程组内的 warp 划分为生产者和消费者角色:生产者使用 TMA 从 HBM 并行拉取 K 和 V 块到共享内存区域,消费者在另一个 warp 上并行执行张量核计算。两者在时间线上以流水线形式重叠,从而隐藏数据搬运延迟。
工程上需要注意的点:生产者写共享内存的速度和消费者读共享内存的速度必须匹配;在实际实现中通过“双缓冲”或 ping pong 缓冲区来避免读写冲突;并且要在 warp 内实现小粒度的同步而非全块同步,这样可以提高并发度。
简单伪代码示意
# 伪代码,表示生产者消费者的时间线
for each block j:producer_warp: use TMA to load K_j, V_j into shared buffer pingconsumer_warp: compute partial = MatMul(Q_block, K_j) using TensorCoresconsumer_warp: interleave softmax for partial and apply to V_jswap ping and pong buffers
4.2 MatMul 与 Softmax 的交错执行
常规实现中会先计算完整的点积矩阵再执行 Softmax,然后乘 V。FlashAttention-3 的优化在于将 MatMul 的计算和 Softmax 的步骤做细粒度交错。这样可以在尚未完成整个点积矩阵时就开始归一化与累积,从而减少片上缓存占用并隐藏 Softmax 的延迟。
数学上,假设把点积按列分块,那么对一行的 Softmax 可以通过维护该行的当前最大值和行累积分母来增量更新。这类似流式 Softmax 的做法,但需要额外跟踪前缀最大值的合并规则:
设当前已有两段 logits 段 a 和 b,相应的最大值为 m_a 和 m_b,归一化因子分别为 z_a 和 z_b,则合并后的归一化可以利用数值稳定化技巧:
[ m = \max(m_a, m_b) ]
[ z = z_a \exp(m_a - m) + z_b \exp(m_b - m) ]
并据此更新软归一化值。FlashAttention-3 就是在块级别实现上述增量 Softmax,并把 MatMul 和 Softmax 的时间线打散为小段交替进行。
4.3 块量化与非一致处理
FlashAttention-3 支持把 KV 缓存以块为单位进行量化并异步处理,从而用更低的精度存储历史键值以节省内存并提升吞吐。关键在于保证量化后用于注意力计算时的数值误差在可控范围内。论文提出一种块量化策略与去量化融合的流水线,使得解量化操作与张量核计算并行执行。
工程要点包括:
- 选择合适的块大小和量化位宽,论文在 Hopper 上对 FP8 给出工程化选择;
- 对每个块维护比例因子和偏移量,以便在解量化时把块恢复到适当的浮点范围;
- 当存在极端 outlier 值时采用平滑或剪枝策略,避免少数异常元素主导量化误差。
论文中也给出数值误差评估,说明在适当的参数选择下 FP8 的误差远小于直接的盲量化基线。
4.4 数值稳定性与误差控制
低精度带来的主要风险是 Softmax 数值不稳定与累加误差。FlashAttention-3 通过以下手段控制误差:
- 在增量 Softmax 时维护每行的前缀最大值并做中心化操作;
- 对极端值做 outlier 平滑,尤其是线性层的权重矩阵中出现的少数大幅度元素;
- 在关键路径上使用混合精度,必要时把中间累加保持为 FP16 或 BF16,然后在需要时再量化为 FP8 做存储。
5、工程实现要点与调用实践
FlashAttention-3 的落地依赖生态系统的支持。当前主流的高性能推理库已经或正在集成 FA3 内核,包括 vLLM、SGLang、FlashInfer 以及社区打包的 Hugging Face kernels。工程化使用时常见模式如下:
- 在训练或推理节点上安装 FA3 内核包或使用对应的容器镜像;
- 若使用 vLLM、SGLang 或 FlashInfer,选择对应的 attention 后端参数以启用 FA3;
- 若使用 transformers 生态,使用 Hugging Face 的 kernels 社区包或自建库来提供 FA3 支持;
- 注意 KV 缓存与量化策略需要统一配置,某些内核在启用 FP8 KV 缓存时存在兼容性约束。
下面是一个工程化注意事项清单:
- 确认 GPU 类型。FA3 对 Hopper 系列(如 H100)有最优支持;其他 GPU 也可能通过不同内核获得一定加速,但效果不同。
- 测试预填充到首字节时间。某些内核为提高吞吐牺牲了首字节延迟,做选择时要权衡场景。
- 验证精度回归。在启用 FP8 或其它低精度时,应在小规模数据集上做完整的精度回归测试。
6、FlashAttention-3 核心特性,Hopper架构硬件特性分析
算力与带宽对比
Hopper架构相比Ampere架构有了显著的硬件升级:
H100 SXM (Hopper架构):
- FP8 TensorCore算力:2000 TFLOPS
- HBM带宽:3.35 TB/s
- Roofline拐点:2000TFLOPS / 3.35TB/s = 597 TFLOPS/GB
A100 (Ampere架构):
- INT8算力:624 TOPS
- HBM带宽:1.555 TB/s
- Roofline拐点:624TOPS / 1.555TB/s = 401 TOPS/GB
Hopper架构的计算强度提升了接近50%,这意味着基于Ampere指令集的FA2在Hopper上只能发挥约35%的算力。
核心硬件特性
Hopper架构引入了三个关键特性:
-
TMA (Tensor Memory Accelerator):
- 每个SM配备一个TMA单元
- 支持多播加载(multicast load)
- 指令:
cp.async.bulk.tensor
-
WGMMA (Warpgroup-level Matrix Multiply):
- 支持FP16/BF16/FP8数据类型
- 指令:
wgmma.mma_async - 4个warp组成一个warpgroup
-
Producer-Consumer编程模型:
- 引入生产者-消费者异步执行模式
- 支持Persistent Kernel设计
7、FA3核心技术特性-伪代码

1. Producer-Consumer异步执行
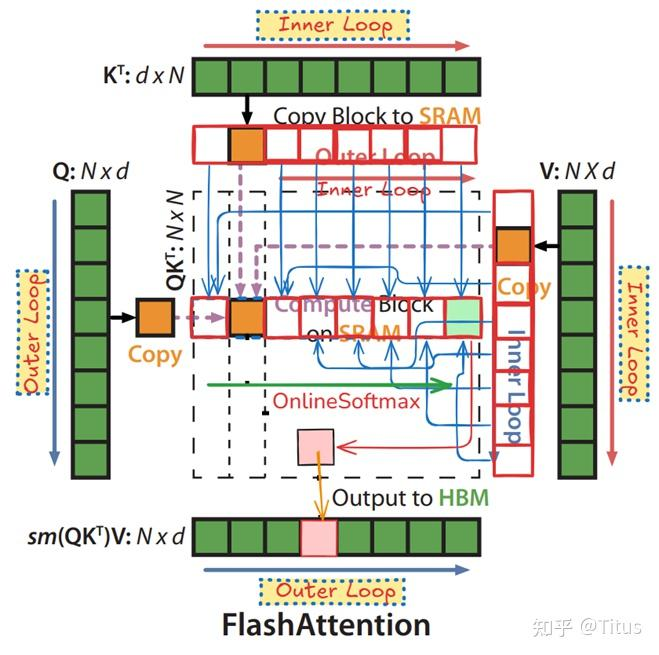
FA3采用warp specialization的设计模式:
class WarpSpecialization:def __init__(self):self.producer_warpgroup = 1 # 生产者warpgroup数量self.consumer_warpgroups = 2 # 消费者warpgroup数量def producer_task(self):"""生产者负责数据搬运"""# 发射TMA指令将Q,K,V从HBM搬运到Shared Memory# TMA.load_Q_tile()# TMA.load_K_tile() # TMA.load_V_tile()passdef consumer_task(self):"""消费者负责计算"""# 发射WGMMA指令进行矩阵乘法# WGMMA.gemm(Q_tile, K_tile) # 计算QK^T# WGMMA.gemm(P_tile, V_tile) # 计算PVpass
2. Multi-stage Pipeline设计
FA3继承了FA2的计算pipeline,但针对K和V矩阵采用了多阶段缓冲:
class MultiStagePipeline:def __init__(self, stages=2):self.stages = stages# Q矩阵只需要一个buffer [BM, HEAD_DIM]self.Q_buffer = SharedMemoryBuffer(shape=[BM, HEAD_DIM])# K,V矩阵需要stages个buffer用于pipelineself.K_buffers = [SharedMemoryBuffer(shape=[BN, HEAD_DIM]) for _ in range(stages)]self.V_buffers = [SharedMemoryBuffer(shape=[BN, HEAD_DIM]) for _ in range(stages)]def pipeline_execution(self):for i in range(seqlen_Q // BM):# 外循环:处理Q tilesself.load_Q_tile(i)for j in range(seqlen_K // BN):# 内循环:处理K,V tilesbuffer_idx = j % self.stages# 生产者:加载下一个K,V tileself.producer.load_KV_tile(j+1, buffer_idx)# 消费者:计算当前tileS_ij = self.consumer.gemm_QK(i, j, buffer_idx)P_ij = self.softmax(S_ij)O_ij = self.consumer.gemm_PV(P_ij, j, buffer_idx)
3. GEMMs与Softmax重叠优化
这是FA3的关键创新之一。我们先分析为什么需要这种优化:
算力分析
对于MHA,假设HEAD_DIM=128:
def compute_flops_ratio():# 计算FLOPS比例gemm_flops = 4 * seqlen_Q * seqlen_KV * HEAD_DIM # GEMM计算量softmax_flops = seqlen_Q * seqlen_KV # Softmax计算量ratio = gemm_flops / softmax_flopsprint(f"GEMMs vs Softmax FLOPS比例: {ratio}") # 4 * 128 = 512倍# H100算力分析h100_tensorcore_bf16 = 1000e12 # 1000 TFLOPSh100_tensorcore_fp8 = 2000e12 # 2000 TFLOPS h100_sfu = 4.18e12 # 4.18 TFLOPS (SFU单元)bf16_ratio = h100_tensorcore_bf16 / h100_sfu # ~250倍fp8_ratio = h100_tensorcore_fp8 / h100_sfu # ~500倍print(f"BF16 TensorCore vs SFU算力比: {bf16_ratio:.0f}倍")print(f"FP8 TensorCore vs SFU算力比: {fp8_ratio:.0f}倍")
从分析可以看出,对于BF16,softmax耗时约为GEMMs的一半;对于FP8,两者耗时接近1:1。因此overlap优化在FP8下尤其重要。
Inter-warpgroup重叠
Inter-warpgroup重叠机制允许不同warpgroup同时执行GEMM和Softmax:
// CUDA伪代码示例
__global__ void fa3_inter_warpgroup_kernel() {int warpgroup_id = get_warpgroup_id();if (warpgroup_id == 1) {// Warpgroup 1执行流程for (int iter = 0; iter < num_iterations; iter++) {// 1. 执行GEMM0: S = QK^Twgmma_gemm_async(Q_tile, K_tile, S_tile, group=0);// 2. 通知warpgroup2开始其GEMM0warp_scheduler_barrier_arrive();// 3. 执行softmax (与warpgroup2的GEMM0并行)softmax_cuda_cores(S_tile, P_tile);// 4. 等待warpgroup2的GEMM0完成信号warp_scheduler_barrier_sync();// 5. 执行GEMM1: O = PVwgmma_gemm_async(P_tile, V_tile, O_tile, group=0);}}else if (warpgroup_id == 2) {// Warpgroup 2执行流程 (交错执行)for (int iter = 0; iter < num_iterations; iter++) {// 等待warpgroup1的信号warp_scheduler_barrier_sync();// 执行GEMM0 (与warpgroup1的softmax并行)wgmma_gemm_async(Q_tile, K_tile, S_tile, group=1);// 通知下一个warpgroupwarp_scheduler_barrier_arrive();// 执行自己的softmaxsoftmax_cuda_cores(S_tile, P_tile);// 执行GEMM1wgmma_gemm_async(P_tile, V_tile, O_tile, group=1);}}
}
Intra-warpgroup重叠
单个warpgroup内部也可以实现更细粒度的重叠:
// 单warpgroup内重叠示例
__device__ void intra_warpgroup_overlap() {// Prologue: 初始化第一个迭代wgmma_gemm_async(Q, K0, S0, group=0); // 启动第一个GEMMwarpgroup_wait<0>(); // 等待GEMM完成softmax_cuda_cores(S0, P0); // 计算softmax// Main loop: 重叠执行for (int i = 1; i < num_iterations; i++) {// 同时启动当前迭代的GEMM0和上一迭代的GEMM1wgmma_gemm_async(Q, K_i, S_i, group=1); // 当前迭代GEMM0wgmma_gemm_async(P_prev, V_prev, O_prev, group=0); // 上一迭代GEMM1// 等待当前迭代GEMM0完成warpgroup_wait<1>();// 执行softmax (与上一迭代GEMM1并行)softmax_cuda_cores(S_i, P_i);// 等待上一迭代GEMM1完成warpgroup_wait<0>();}
}
4. FP8支持与布局转换
FP8是FA3的重要特性,相比FP16有显著优势:
- 显存需求减半
- 计算吞吐翻倍
- 相比INT8有更大的表示范围
Accumulator排列转换
FP8 WGMMA要求特定的数据布局,需要进行寄存器间的数据重排:
def fp8_permutation_example():"""FP8 WGMMA要求的数据布局转换示例从FP32 Accumulator布局转换为FP8 WGMMA Operand A布局"""# FP32 Accumulator layout (每个线程4个FP32值)T0_accumulator = ['a0', 'a1', 'a2', 'a3'] # Thread 0T1_accumulator = ['b0', 'b1', 'b2', 'b3'] # Thread 1 T2_accumulator = ['c0', 'c1', 'c2', 'c3'] # Thread 2T4_accumulator = ['d0', 'd1', 'd2', 'd3'] # Thread 4# 转换后的FP8 WGMMA layout (每个线程4个FP8值)# 需要重新排列数据以满足WGMMA要求T0_wgmma = ['a0', 'a1', 'b2', 'b3'] # 混合来自T0和T1的数据T1_wgmma = ['b0', 'b1', 'a2', 'a3'] # 混合来自T1和T0的数据# 使用CUDA指令实现转换"""1. PRMT指令:线程内数据重排2. SHFL指令:线程间数据交换 3. 再次PRMT:最终布局调整"""return T0_wgmma, T1_wgmma
TransposeV优化
对于V矩阵,FA3设计了特殊的转置共享内存布局:
class TransposeVLayout:def __init__(self):# 原始V布局:[seqlen_KV, HEAD_NUM_KV, HEAD_DIM]self.original_layout = [seqlen_KV, HEAD_NUM_KV * HEAD_DIM, 1]# 转置后VT布局:[HEAD_NUM_KV, HEAD_DIM, seqlen_KV] self.transposed_layout = [HEAD_NUM_KV * HEAD_DIM, seqlen_KV, 1]def transpose_operation(self, V_tile):"""V矩阵转置操作,优化GEMM1的数据访问模式O = P * V 需要V转置为VT以获得连续内存访问"""# 在shared memory中重新排列V数据VT_tile = self.shared_memory_transpose(V_tile)return VT_tiledef shared_memory_transpose(self, V_tile):# 使用shared memory进行高效转置# 利用bank conflict避免和合并访问优化pass
8、同步机制与Barrier优化
FA3使用了复杂的barrier同步机制来协调producer-consumer执行:
Named Barrier系统
// FA3使用的Named Barrier定义
enum class FwdNamedBarriers {QueryEmpty = 0, // Q数据准备就绪信号WarpSchedulerWG1 = 1, // Warpgroup1调度同步WarpSchedulerWG2 = 2, // Warpgroup2调度同步 WarpSchedulerWG3 = 3, // Warpgroup3调度同步AppendKV = 4, // KV数据追加信号QueryRotated = 5, // Q数据旋转信号PFull = 6, // P矩阵数据满信号PEmpty = 7, // P矩阵数据空信号
};// 使用示例
__device__ void barrier_synchronization() {int warpgroup_id = get_warpgroup_id();if (warpgroup_id == 1) {// Warpgroup1完成GEMM0后通知Warpgroup2cutlass::arch::NamedBarrier::arrive(2 * cutlass::NumThreadsPerWarpGroup,static_cast<uint32_t>(FwdNamedBarriers::WarpSchedulerWG2));// 等待Warpgroup2的GEMM0完成信号cutlass::arch::NamedBarrier::sync(2 * cutlass::NumThreadsPerWarpGroup,static_cast<uint32_t>(FwdNamedBarriers::WarpSchedulerWG1) );}
}
Pingpong调度算法
class PingPongScheduler:def __init__(self, num_warpgroups=2):self.num_warpgroups = num_warpgroupsself.current_wg = 0def schedule_next_warpgroup(self, current_wg):"""计算下一个要执行的warpgroup"""if self.num_warpgroups == 2:return 1 - current_wg # 在0和1之间切换else:return (current_wg + 1) % self.num_warpgroupsdef barrier_arrive_pattern(self, current_wg):"""确定当前warpgroup应该发送arrive信号到哪个barrier"""next_wg = self.schedule_next_warpgroup(current_wg)barrier_id = FwdNamedBarriers.WarpSchedulerWG1 + next_wgreturn barrier_iddef barrier_sync_pattern(self, current_wg):"""确定当前warpgroup应该等待哪个barrier的信号"""barrier_id = FwdNamedBarriers.WarpSchedulerWG1 + current_wg return barrier_id
9、性能分析与优化效果
理论性能提升
通过overlap优化,FA3在高负载下可以提升70-80 TFLOPS的有效计算吞吐,在H100 FA2和FA3性能对比:
def performance_analysis():# H100硬件参数h100_peak_fp8 = 2000e12 # 2000 TFLOPSh100_sfu_peak = 4.18e12 # 4.18 TFLOPS# FA2性能 (无overlap)fa2_gemm_utilization = 0.35 # 35%算力利用率fa2_effective_flops = h100_peak_fp8 * fa2_gemm_utilization# FA3性能 (有overlap) fa3_gemm_utilization = 0.75 # 75%算力利用率fa3_effective_flops = h100_peak_fp8 * fa3_gemm_utilization# Overlap带来的额外收益overlap_benefit = 75e12 # 约75 TFLOPStotal_improvement = (fa3_effective_flops + overlap_benefit) / fa2_effective_flopsprint(f"FA2有效算力: {fa2_effective_flops/1e12:.0f} TFLOPS")print(f"FA3有效算力: {fa3_effective_flops/1e12:.0f} TFLOPS") print(f"Overlap收益: {overlap_benefit/1e12:.0f} TFLOPS")print(f"总体性能提升: {total_improvement:.1f}x")
FA2有效算力: 700 TFLOPS
FA3有效算力: 1500 TFLOPS
Overlap收益: 75 TFLOPS
总体性能提升: 2.2x
内存访问优化
FA3通过以下方式优化内存访问模式:
- TMA多播加载:减少重复数据传输
- Shared Memory Bank冲突避免:优化数据布局
- 寄存器溢出最小化:精确的寄存器分配
class MemoryAccessOptimization:def __init__(self):self.tma_multicast = True # 启用TMA多播self.bank_conflict_free = True # 避免bank冲突self.register_efficient = True # 寄存器高效使用def optimize_shared_memory_layout(self, tile_shape):"""优化共享内存数据布局"""BM, BN, BK = tile_shape# 确保没有bank冲突的内存布局# 32个bank,每个bank 4字节,总共128字节per bankbank_width = 128 # byteselement_size = 2 # FP16 = 2 bytes# 调整stride避免bank冲突stride = (BK * element_size + bank_width - 1) // bank_width * bank_widthoptimized_layout = [BM, stride // element_size]return optimized_layoutdef register_allocation_strategy(self):"""寄存器分配策略"""# 最小化寄存器压力,避免spill到L2 cachemax_registers_per_thread = 255# Q tile寄存器需求q_registers = self.calculate_q_tile_registers()# S/P tile寄存器需求 s_p_registers = self.calculate_s_p_tile_registers()# 临时计算寄存器temp_registers = 32total_needed = q_registers + s_p_registers + temp_registersif total_needed > max_registers_per_thread:# 采用register tiling策略self.enable_register_tiling()return total_needed <= max_registers_per_thread
10 模型级别的采纳分析与结论
在讨论是否“某个模型使用 FlashAttention-3”時,需要先澄清一个工程概念:模型权重本身并不包含注意力实现的具体核。是否使用 FA3,通常指的是在训练或推理时所采用的后端内核。如果把这个概念说清楚,就能更准确地判断。
下面对用户关心的模型逐一给出工程化判断和简单结论:
-
Qwen2.5 系列
- 工程判断:Qwen2.5 的论文与工程文档在致谢或参考中提及 FlashAttention-3,且主流推理引擎对 Qwen2 系列提供了 FA3 的支持路径。结论:可以通过 vLLM 或 kernels 安装来使用 FA3 加速 Qwen2.5 的推理。
-
Qwen3 系列
- 工程判断:Qwen3 的开源实现社区讨论主要围绕 FlashAttention 2 的兼容性和设置。实际上在支持 FA3 的推理后端中能加速 Qwen3,但官方文档没有统一声明在训练期间使用 FA3。结论:推理可以使用 FA3,但训练与官方训练流水线是否使用 FA3 未公开说明。
-
Deepseek
- 工程判断:Deepseek 发布了自家名为 FlashMLA 的多头线性注意力内核,目标在推理场景优化。结论:Deepseek 同时在推进自己的内核,与 FA3 是并行或替代关系,而不是完全采用 FA3。
-
GLM-3 与 GLM-4 系列
- 工程判断:GLM 系列在若干部署与演示中使用了高性能注意力内核,并且社区镜像如 GLM-4-Flash 明确面向高效长上下文。结论:通过主流推理框架,GLM 系列可以使用 FA3 加速推理,但官方训练是否固定使用 FA3 需要具体查看发布细节。
-
Llama 3 系列与 Llama 4
- 工程判断:Llama 3 的生态已经有很多关于 FlashAttention 的支持示例,Llama 4 也被许多推理引擎宣布与 FA3 后端兼容。结论:在推理端,Llama 系列已经可以利用 FA3 后端获得加速。
-
GPT-4、GPT-4o 与 GPT-5
- 工程判断:这些闭源的模型由云厂商在自有训练和推理平台上管理。厂商可能使用了内部优化与定制内核来最大化硬件效率,公开文档中很少披露完整底层内核细节。结论:没有公开证据表明这些服务在所有训练或推理阶段统一采用 FA3。即便某些阶段或后端组件使用了与 FA3 相似的优化,这仍归属于厂商的实现细节。
总体工程建议是:把判断重点放在你要使用的推理引擎而不是模型本身。若推理引擎支持 FlashAttention-3,你就可以在该模型上启用 FA3 并获得加速。
11、完整代码实现示例
下面提供FA3核心算法的简化实现:
Producer-Consumer模式实现
import torch
import torch.nn.functional as F
from typing import Tuple, Optionalclass FlashAttention3:"""FlashAttention-3简化实现基于Producer-Consumer模式和Warp特化"""def __init__(self, head_dim: int = 128,num_producer_warps: int = 1,num_consumer_warps: int = 2,block_size_m: int = 128,block_size_n: int = 128,stages: int = 2):self.head_dim = head_dimself.num_producer_warps = num_producer_warpsself.num_consumer_warps = num_consumer_warpsself.block_size_m = block_size_mself.block_size_n = block_size_nself.stages = stages# 共享内存缓冲区模拟self.shared_memory_q = Noneself.shared_memory_k = [None] * stagesself.shared_memory_v = [None] * stagesdef producer_kernel(self, Q: torch.Tensor, K: torch.Tensor, V: torch.Tensor,q_block_idx: int) -> None:"""生产者核函数:负责数据加载模拟TMA指令将数据从HBM加载到共享内存"""batch_size, seq_len_q, head_dim = Q.shapeseq_len_kv = K.shape[1]# 加载Q tile到共享内存 (只需要一个buffer)q_start = q_block_idx * self.block_size_mq_end = min(q_start + self.block_size_m, seq_len_q)self.shared_memory_q = Q[:, q_start:q_end, :].contiguous()# 多阶段加载K,V tilesnum_kv_blocks = (seq_len_kv + self.block_size_n - 1) // self.block_size_nfor kv_block_idx in range(num_kv_blocks):stage_idx = kv_block_idx % self.stages# 等待该stage被消费完成 (barrier同步)self._wait_for_consumer_release(stage_idx)# 加载K,V数据到对应stagekv_start = kv_block_idx * self.block_size_nkv_end = min(kv_start + self.block_size_n, seq_len_kv)self.shared_memory_k[stage_idx] = K[:, kv_start:kv_end, :].contiguous()self.shared_memory_v[stage_idx] = V[:, kv_start:kv_end, :].contiguous()# 通知消费者数据已准备就绪 (barrier arrive)self._notify_consumer_ready(stage_idx)def consumer_kernel(self, q_block_idx: int,causal_mask: bool = False) -> torch.Tensor:"""消费者核函数:负责计算模拟WGMMA指令执行矩阵乘法和softmax"""batch_size = self.shared_memory_q.shape[0]seq_len_q_block = self.shared_memory_q.shape[1]# 初始化输出accumulatoroutput = torch.zeros(batch_size, seq_len_q_block, self.head_dim, dtype=torch.float32, device=self.shared_memory_q.device)# 在线softmax状态max_vals = torch.full((batch_size, seq_len_q_block), float('-inf'), device=output.device)sum_vals = torch.zeros(batch_size, seq_len_q_block, device=output.device)num_kv_blocks = len([k for k in self.shared_memory_k if k is not None])for kv_block_idx in range(num_kv_blocks):stage_idx = kv_block_idx % self.stages# 等待生产者加载数据完成 (barrier sync)self._wait_for_producer_ready(stage_idx)# GEMM0: 计算注意力分数 S = QK^TK_block = self.shared_memory_k[stage_idx]scores = torch.matmul(self.shared_memory_q, K_block.transpose(-2, -1))# 应用因果掩码 (如果需要)if causal_mask:q_start = q_block_idx * self.block_size_mkv_start = kv_block_idx * self.block_size_nscores = self._apply_causal_mask(scores, q_start, kv_start)# 在线softmax更新scores_max = torch.max(scores, dim=-1, keepdim=True)[0]new_max = torch.maximum(max_vals.unsqueeze(-1), scores_max)# 重新缩放之前的结果alpha = torch.exp(max_vals.unsqueeze(-1) - new_max)output = output * alphasum_vals = sum_vals * alpha.squeeze(-1)# 计算当前block的贡献exp_scores = torch.exp(scores - new_max)block_sum = torch.sum(exp_scores, dim=-1)# GEMM1: 计算输出 O += P * VV_block = self.shared_memory_v[stage_idx]block_output = torch.matmul(exp_scores, V_block)# 累加到总输出output = output + block_outputsum_vals = sum_vals + block_summax_vals = new_max.squeeze(-1)# 释放该stage供生产者重用 (barrier release)self._release_stage_for_producer(stage_idx)# 最终归一化output = output / sum_vals.unsqueeze(-1)return outputdef inter_warpgroup_overlap(self, Q: torch.Tensor,K: torch.Tensor, V: torch.Tensor,causal: bool = False) -> torch.Tensor:"""Inter-warpgroup重叠优化不同warpgroup交替执行GEMM和softmax"""batch_size, seq_len_q, head_dim = Q.shapeseq_len_kv = K.shape[1]num_q_blocks = (seq_len_q + self.block_size_m - 1) // self.block_size_mfull_output = torch.zeros_like(Q)# 模拟两个warpgroup的交替执行warpgroup_states = [{"phase": "gemm0", "iteration": 0}, # WG1状态{"phase": "idle", "iteration": 0} # WG2状态 ]for q_block_idx in range(num_q_blocks):# 启动生产者加载Q blockself.producer_kernel(Q, K, V, q_block_idx)# 模拟warpgroup调度active_wg = q_block_idx % self.num_consumer_warpsif active_wg == 0:# Warpgroup 1执行block_output = self._warpgroup1_execution(q_block_idx, causal)else:# Warpgroup 2执行 block_output = self._warpgroup2_execution(q_block_idx, causal)# 写回结果q_start = q_block_idx * self.block_size_mq_end = min(q_start + self.block_size_m, seq_len_q)full_output[:, q_start:q_end, :] = block_outputreturn full_outputdef _apply_causal_mask(self, scores: torch.Tensor, q_start: int, kv_start: int) -> torch.Tensor:"""应用因果掩码"""seq_len_q_block, seq_len_kv_block = scores.shape[-2:]# 创建位置索引q_indices = torch.arange(q_start, q_start + seq_len_q_block, device=scores.device).unsqueeze(-1)kv_indices = torch.arange(kv_start, kv_start + seq_len_kv_block,device=scores.device).unsqueeze(0)# 应用因果掩码:只能看到当前位置及之前的位置mask = q_indices >= kv_indicesscores = scores.masked_fill(~mask, float('-inf'))return scoresdef _warpgroup1_execution(self, q_block_idx: int, causal: bool) -> torch.Tensor:"""Warpgroup 1的执行逻辑"""return self.consumer_kernel(q_block_idx, causal)def _warpgroup2_execution(self, q_block_idx: int, causal: bool) -> torch.Tensor:"""Warpgroup 2的执行逻辑"""return self.consumer_kernel(q_block_idx, causal)def _wait_for_consumer_release(self, stage_idx: int):"""等待消费者释放stage (barrier同步模拟)"""passdef _notify_consumer_ready(self, stage_idx: int):"""通知消费者数据就绪 (barrier arrive模拟)"""passdef _wait_for_producer_ready(self, stage_idx: int):"""等待生产者数据就绪 (barrier sync模拟)"""passdef _release_stage_for_producer(self, stage_idx: int):"""释放stage给生产者 (barrier release模拟)"""pass# FP8支持的简化实现
class FP8Support:"""FP8数据类型支持和布局转换"""@staticmethoddef fp32_to_fp8_conversion(tensor: torch.Tensor, scale: float = 1.0) -> torch.Tensor:"""FP32到FP8的转换 (简化版本)实际硬件会有专门的转换指令"""# 缩放到FP8范围scaled_tensor = tensor * scale# 模拟FP8量化 (实际硬件实现会更复杂)fp8_tensor = torch.clamp(scaled_tensor, -240.0, 240.0)# 量化到FP8精度 (简化实现)fp8_tensor = torch.round(fp8_tensor * 16) / 16return fp8_tensor@staticmethoddef accumulator_permutation(accumulator: torch.Tensor) -> torch.Tensor:"""FP32 Accumulator到FP8 WGMMA布局的转换模拟寄存器重排操作"""batch_size, seq_len, hidden_dim = accumulator.shape# 重新排列数据以匹配FP8 WGMMA要求# 这里简化为reshape操作,实际需要复杂的寄存器shufflepermuted = accumulator.view(batch_size, seq_len, -1, 4)permuted = permuted.transpose(-2, -1).contiguous()permuted = permuted.view(batch_size, seq_len, hidden_dim)return permuted@staticmethoddef transpose_v_layout(V: torch.Tensor) -> torch.Tensor:"""V矩阵转置布局优化[seqlen_KV, HEAD_DIM] -> [HEAD_DIM, seqlen_KV]"""return V.transpose(-2, -1).contiguous()# 性能基准测试
def benchmark_fa3():"""FlashAttention-3性能基准测试"""import time# 测试配置batch_size = 2seq_len = 2048head_dim = 128device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')# 生成测试数据Q = torch.randn(batch_size, seq_len, head_dim, device=device)K = torch.randn(batch_size, seq_len, head_dim, device=device) V = torch.randn(batch_size, seq_len, head_dim, device=device)# 初始化FA3fa3 = FlashAttention3(head_dim=head_dim)# 预热for _ in range(5):_ = fa3.inter_warpgroup_overlap(Q, K, V)# 性能测试num_iterations = 20start_time = time.time()for _ in range(num_iterations):output = fa3.inter_warpgroup_overlap(Q, K, V)end_time = time.time()avg_time = (end_time - start_time) / num_iterations# 计算FLOPSflops_per_iter = 4 * batch_size * seq_len * seq_len * head_dimthroughput = flops_per_iter / avg_time / 1e12 # TFLOPSprint(f"平均执行时间: {avg_time*1000:.2f} ms")print(f"理论吞吐量: {throughput:.2f} TFLOPS")print(f"输出形状: {output.shape}")# 验证正确性reference_output = standard_attention(Q, K, V)max_diff = torch.max(torch.abs(output - reference_output))print(f"与标准实现最大差异: {max_diff:.6f}")def standard_attention(Q: torch.Tensor, K: torch.Tensor, V: torch.Tensor) -> torch.Tensor:"""标准注意力实现用于验证正确性"""scores = torch.matmul(Q, K.transpose(-2, -1))scores = scores / (Q.shape[-1] ** 0.5)attention_weights = F.softmax(scores, dim=-1)output = torch.matmul(attention_weights, V)return output# 使用示例
def main():"""主函数示例"""print("=== FlashAttention-3 实现示例 ===")# 创建测试数据batch_size, seq_len, head_dim = 2, 1024, 128device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')Q = torch.randn(batch_size, seq_len, head_dim, device=device)K = torch.randn(batch_size, seq_len, head_dim, device=device)V = torch.randn(batch_size, seq_len, head_dim, device=device)# 初始化FlashAttention-3fa3 = FlashAttention3(head_dim=head_dim,block_size_m=128,block_size_n=128,stages=2)print(f"输入形状 - Q: {Q.shape}, K: {K.shape}, V: {V.shape}")print(f"设备: {device}")# 执行FlashAttention-3with torch.no_grad():output = fa3.inter_warpgroup_overlap(Q, K, V, causal=False)print(f"输出形状: {output.shape}")print(f"输出统计 - 均值: {output.mean():.4f}, 标准差: {output.std():.4f}")# FP8转换示例fp8_support = FP8Support()fp8_q = fp8_support.fp32_to_fp8_conversion(Q, scale=0.1)print(f"FP8转换后范围: [{fp8_q.min():.2f}, {fp8_q.max():.2f}]")# 性能基准测试print("\n=== 性能基准测试 ===")benchmark_fa3()if __name__ == "__main__":main()
12、技术对比
FlashAttention系列演进对比
Standard Attention: 低 (~30%) GPU利用率, 核心创新: 标准实现
FlashAttention-1: 中 (~50%) GPU利用率, 核心创新: Tiling算法
FlashAttention-2: 中高 (~65%) GPU利用率, 核心创新: 多查询注意力
FlashAttention-3: 高 (~75%) GPU利用率, 核心创新: Producer-Consumer异步
13、实际部署建议
硬件选择策略
训练场景:
- 首选: H100 SXM (80GB)
- 次选: H800 (80GB)
- 预算选择: A100 (80GB) + FA2
- 理由: FA3在Hopper架构下性能提升显著
推理场景:
- 高吞吐: H100 NVL (94GB HBM3)
- 成本敏感: L40S + FA2优化
- 边缘部署: RTX 4090 + 量化
- 理由: 推理对延迟敏感,FA3的overlap优化效果明显
研发环境:
- 推荐: RTX 4090/RTX 4080 + FA2
- 理由: 研发阶段主要关注功能验证,性价比优先
软件配置优化
# 环境配置脚本
#!/bin/bashecho "=== FlashAttention-3环境配置 ==="# 1. 安装CUDA 12.x (Hopper架构要求)
wget https://developer.download.nvidia.com/compute/cuda/12.3.0/local_installers/cuda_12.3.0_545.23.06_linux.run
sudo sh cuda_12.3.0_545.23.06_linux.run
# 2. 安装FlashAttention-3
pip install flash-attn --no-build-isolation
# 3. 验证安装
python -c "
import torch
import flash_attn
print(f'FlashAttention版本: {flash_attn.__version__}')
print(f'CUDA版本: {torch.version.cuda}')
print(f'GPU型号: {torch.cuda.get_device_name()}')
"
# 4. 性能调优设置
export CUDA_LAUNCH_BLOCKING=0
export TORCH_CUDA_ARCH_LIST="8.0;8.6;8.9;9.0" # 包含Hopper架构
export NVCC_PREPEND_FLAGS='-ccbin /usr/bin/gcc-9'echo "配置完成!建议重启以生效所有设置。"