使用 LMCache + vLLM 提升 AI 速度并降低 GPU 成本
原文:https://zhuanlan.zhihu.com/p/1936172655175796340
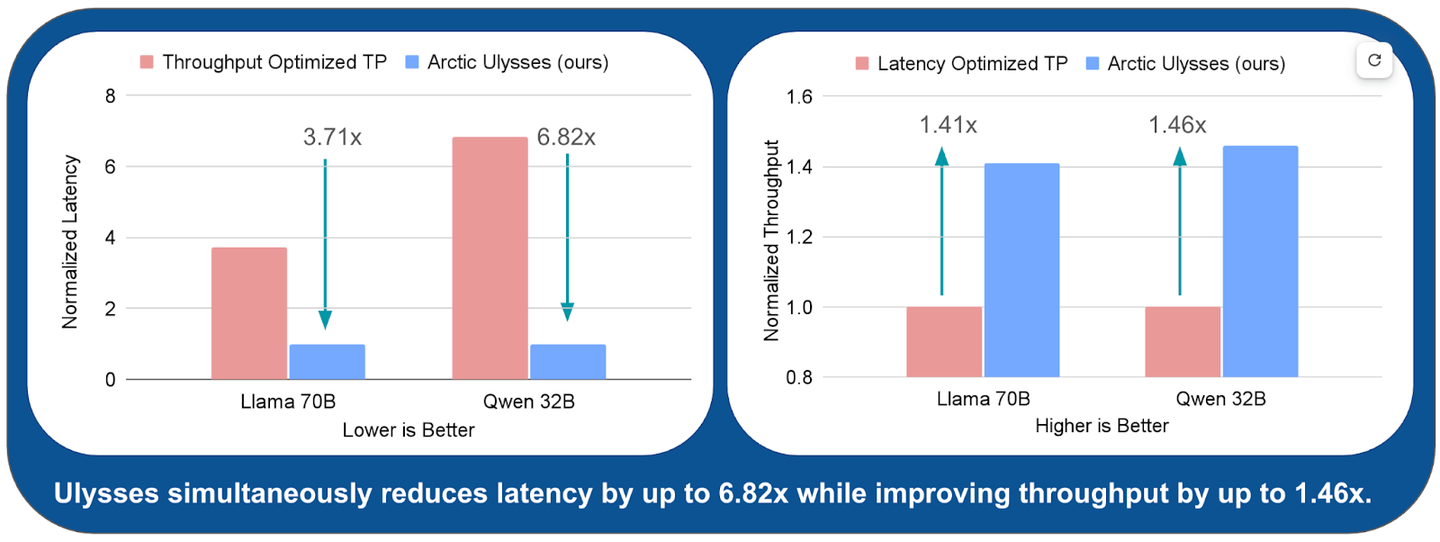
前面介绍了,使用序列并行实现长上下文的低延迟和高吞吐量推理(又名 Arctic Ulysses)
编辑大模型推理性能如何优化?37 赞同 · 2 评论 回答
低延迟和高吞吐量对于在企业AI中部署大语言模型(LLMs)至关重要。低延迟能够支持聊天等交互式体验,并在复杂的智能工作流程中实现及时响应。另一方面,高吞吐量可以降低运营成本 - 使LLMs的大规模部署更加经济实惠,也更容易被客户所接受。
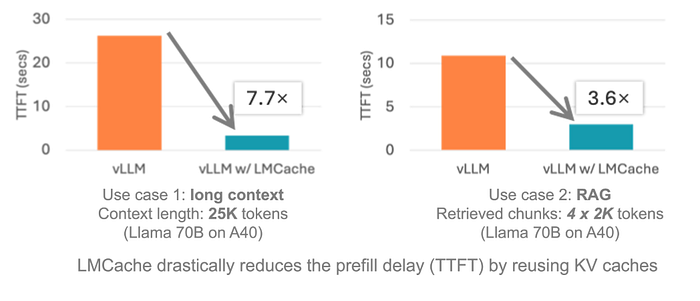
然而,同时实现低延迟和高吞吐量仍然是一个核心挑战 - 特别是对于长上下文推理任务,如检索增强生成(RAG)、摘要生成或代码生成。更长的输入需要更多的计算量,导致首个token生成时间(TTFT)增加和用户体验下降(见图2)。
从系统角度来看,减少长序列的TTFT通常需要积极使用张量并行(TP),这在vLLM和TensorRT-LLM等推理库中都有实现。TP将模型的计算分散到多个GPU上以减少延迟 - 但这需要付出很大代价。TP通过all-reduce集合通信引入了大量的GPU间通信,限制了其在多个GPU上的可扩展性。因此,虽然TP可以减少延迟,但可能会导致每个GPU的吞吐量显著下降(见图2),从而增加成本。
今天我们学习介绍的是LMCache,它是一个免费工具,可以让你的 AI(那些大型、精巧的语言模型)运行得更快。

什么是 LMCache?
LMCache 是 vLLM 等运行大型 AI 模型的系统的小助手。它保存这些被称为 KV 缓存的东西——基本上是 AI 阅读文本后的便利贴。LMCache 不会每次都涂写新的笔记,而是将它们放在手边,这样你的 AI 就不会浪费时间或消耗昂贵的 GPU 算力。
为什么这很酷:
- 你的 AI 开始以惊人的速度回答问题——有时快七倍,不开玩笑。
- 它使用更少的 GPU 资源,所以你不会因为云账单而哭泣。
- 它非常适合聊天机器人或应用程序,在这些应用中,你会一直看到相同的文本,比如搜索结果或冗长的设置消息。
所以,当你的 AI 阅读东西时,它会创建这些 KV 缓存来记住发生了什么。它们位于 GPU 内存中,这就像一个超级小、超级昂贵的背包。如果相同的文本再次出现——比如,聊天机器人的“嘿,有什么事吗?”——AI 通常会像个傻瓜一样重新开始。LMCache 就像是,“等等,让我们聪明一点。”
- 将这些笔记藏在其他地方,比如 CPU 甚至你的硬盘驱动器。
- 当文本重复时,将它们拉出来,不需要额外的工作。
- 与其他 AI 共享它们,就像在课堂上传递小抄。
对于大型任务来说,这是一个救星,比如聊天机器人处理长时间的聊天,或者应用程序挖掘文档寻找答案。节省时间,节省金钱。
LMCache 的三个亮点
LMCache 有一些巧妙的招数。以下是它的亮点。
1. 将东西缓存到其他地方
如果你的 GPU 背包满了,LMCache 会将这些缓存移动到 CPU 或磁盘。这就像把额外的衣服扔进抽屉里来清理你的桌子。这在以下情况下非常有用:
- 你有一个每个人都会看到的很长的介绍消息,比如聊天机器人的“嗨,我在这里!”
- 你的 GPU 抱怨空间不足。
我曾经有一个机器人,它一直被一个巨大的设置文件噎住。将缓存存储到 CPU 本可以使它像没人管一样飞速运行。
2. 与其它AI服务分享
有大量 AI 正在运行?LMCache 允许它们共享缓存,就像一个厨房里所有的厨师都使用相同的切碎蔬菜。这在以下情况下非常完美:
- 你在一个设置上运行多个 AI。
- 人们向不同的 AI 提出相同的问题。
我曾经在一个支持机器人上工作,每个人都像,“嘿,我的包裹在哪里?”共享缓存意味着一个 AI 的工作帮助了其他的 AI,没有人等待太久。
3. 分配工作
AI 做两件事:读取输入(即预填充)和编写答案(解码)。LMCache 可以将这些工作分配到不同的机器上,就像一个人切洋葱,另一个人烤汉堡。这:
- 使你的设备工作更智能,而不是更努力。
- 当你有大量用户时,保持快速。
在一个拥有无数用户的项目上,这个技巧使我们的成本保持在较低水平,并使答案快速。不需要额外的服务器。
如何开始
想让你的 AI 加快速度吗?如果你在 Linux 上使用 NVIDIA GPU,LMCache 可以非常简单地与 vLLM 一起设置。以下是详细介绍。
Step 1:
Pop open your terminal and type:
pip install lmcacheIf you’ve got vLLM, you’re mostly set. Hit a snag? The LMCache docs are your friend.
Step 2:
Here’s a quick script to mess around with LMCache and vLLM, using CPU to store extra stuff:
import lmcache
import vllm
# Get vLLM going with LMCache
model = vllm.LLM(model="meta-llama/Llama-3-8b", enable_lmcache=True)
# Tell LMCache to use CPU for extra room
lmcache_config = {"offload_to": "cpu", # Or try "disk" if you're feeling wild"cache_prefixes": True # Keeps repeated stuff ready
}
lmcache.configure(**lmcache_config)
# Throw in a prompt
prompt = "Hey, cool AI, what's the capital of France?"
response = model.generate(prompt)
print(response)This fires up an AI, tells LMCache to park caches on CPU, and tries a prompt. Use that prompt again, and LMCache grabs the old notes, making things quick.
为什么选择LMCache
LMCache 不只是说说而已。它:
- 使答案显示速度提高 3-10 倍,尤其是在具有大量文档的聊天或应用程序中。
- 减少 GPU 使用——我做的一个项目节省了大约一半的云预算。
- 处理大量人群而不会崩溃。
我曾经有一个 AI,它为每个问题爬取相同的 PDF。LMCache 的缓存技巧把它变成了一台速度机器,就像把自行车换成摩托车一样。
我已经见过很多技术工具,但 LMCache 是一颗宝石。它是免费的,它很容易,而且它解决了实际问题。它不仅仅是关于快速 AI——它使 AI 成为像我这样的普通人可以负担得起的东西。它可以与 vLLM、KServe 和其他东西很好地配合使用,因此它可以融入到项目中。