云轴科技ZStack AI多语种翻译平台建设实践
(一)前言
在《圣经·创世纪》中,记载着一个关于巴别塔(Tower of Babel)的传说故事。最初人类使用统一语言,他们期望建设一座通天高塔,以彰显人类团结的力量。上帝认为这是僭越之举,变乱了人类语言。因彼此无法沟通,人类被迫停止建塔工程。文明间筑起无形高墙。
数千年来,面对“失落的统一”,人类从未放弃互相理解的渴望。在AI技术迅猛发展的今天,在巴别塔的废墟上,我们正用代码重新架起连接世界的桥梁,AI驱动的智能翻译生态系统正在崛起。然而,这座数字通天塔的建造之路充满荆棘。如何在复杂的工程实践中实现语种间的完美转换,其间每一个难题都是对建塔工程师们的技术考验。
本文主要聚焦多语种场景,从ZStack文档实践出发,围绕本地模型部署与精调、一站式AI翻译平台设计思路、实际建设难题与攻克等要点,向大家全面深入介绍ZStack AI多语种翻译平台建设的成功实践。关于中英场景的解读,可关注此前推送文章《云轴科技ZStack AI中英翻译平台建设实践》。
(二)本地模型部署与精调
同中英场景一样,构建AI多语种翻译平台,本地模型部署与精调是基石。当下,大语言模型(LLM)在通用翻译领域表现强劲,但面对企业级专业场景(如云计算软件文档),通用LLM在产品术语、技术语境、风格规范等处理上明显局限。为此,ZStack基于开源模型,通过系统化精调,打造高度契合产品特点和实际业务需求的本地翻译模型。
本地模型部署与精调涵盖以下五个关键环节:
1、数据准备
面对企业级多语种翻译对质量和成本的双重要求,ZStack设计了一套人机协同的语料构建流程:“源语确立-语料选择-规则制定-AI初翻-人工审核”,在保证语料高质量的同时,显著提升生产效率。
1)源语确立
基于自身成熟的简中和英文基础,ZStack为不同语种定制了差异化转换路径,实现效率与准确性的最优平衡:
- 主流路径(英→X):以英语作为核心源语,覆盖除繁中外的全语种翻译。该路径无缝对接国际通用术语体系,从源头保障科技术语的准确性与全球一致性。
- 特例路径(简中→繁中):单独设计以简体中文为源语的直达路径,利用两种字符近乎一对一的映射关系,实现高效转换。
2)语料选择
为实现对各类翻译场景的全面覆盖,ZStack对语料来源进行了系统性筛选和配比,主要包括:
- 产品UI界面文字:占比不低于50%。包括UI参数、提示信息、菜单导航等文字。
- 产品技术文档:占比约40%。包括用户手册、技术白皮书、实践教程等。
- 其他辅助材料:占比约10%。包括市场材料、内部资料等。
3)规则制定+AI初翻
面对海量语料制备需求,ZStack采用“规则约束、AI生成”的协同模式,在人工制定核心术语表和风格指南的基础上,使用开源大模型进行批量初翻,在提升语料制备效率的同时,保障质量基线。
4)人工审核
基于AI初翻结果,进行人工审核,将符合标准的翻译结果正式加入语料库。对不符合标准的翻译结果进行修正或剔除,确保最终语料库具备高度准确性和可用性。
2.模型选择
选用Qwen2.5-7B-Instruct作为基础模型,该模型计算资源需求适中,且表现出良好的多语言处理能力和架构扩展性,符合本地部署企业级翻译模型对成本和性能的双重要求。
3.模型精调
本地部署Qwen2.5-7B-Instruct,并使用已准备的语料数据,结合LoRA(Low-Rank Adaptation)技术对模型进行针对性训练。
4.模型评估
通过量化指标与人工质检相结合的方式对模型翻译结果进行综合评估。
在量化评估方面,采用BLEU、TER、COMET等自动评估指标和模型,从文本相似度和语义一致性角度衡量翻译质量。在人工质检方面,组织专业团队,从术语一致性、风格规范、逻辑性、流畅性等角度评估模型翻译结果是否符合预期。
5.模型迭代
为紧跟最新业务逻辑,快速迭代模型能力,ZStack采用“实时语料收集+定期模型调优”方式,即在模型投入生产后,持续关注推理结果,择优入选语料库,定期使用最新语料库进行模型精调和评估。
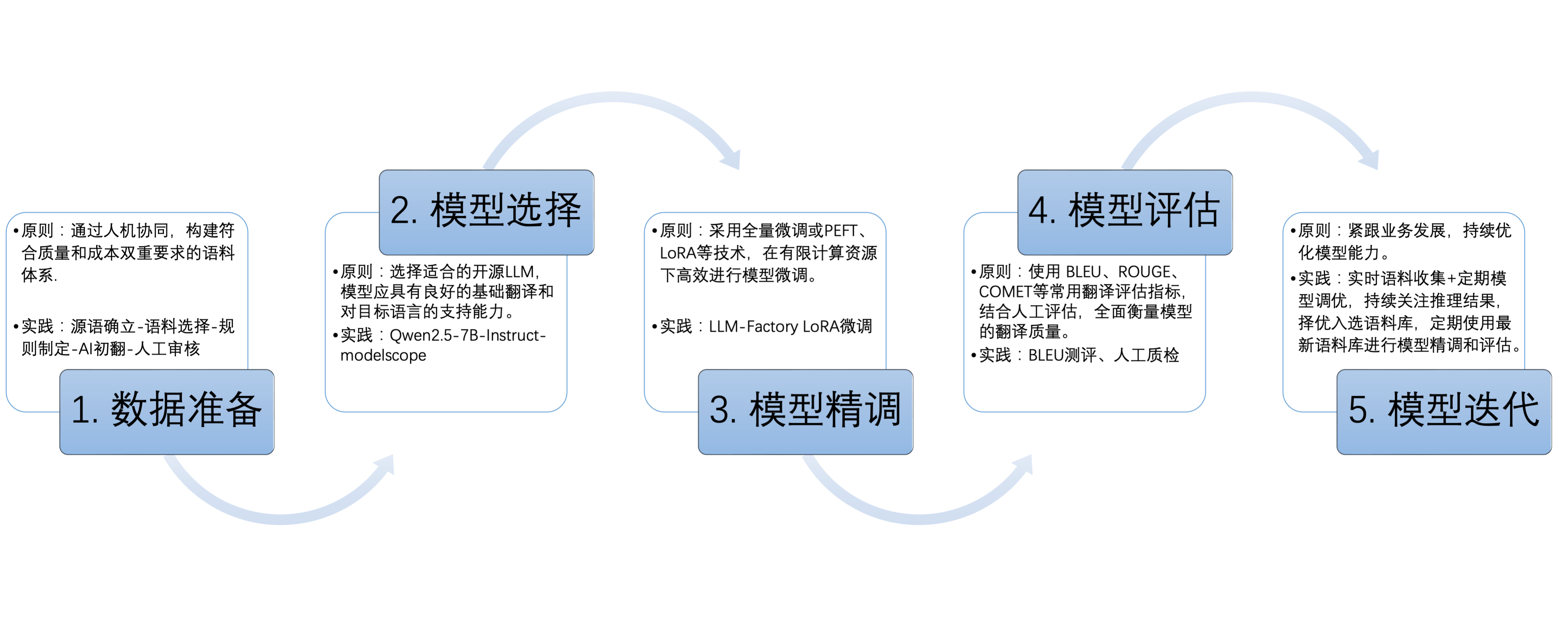
图1. 精调LLM的五个关键环节
(三)平台整体设计思路
ZStack AI多语种翻译平台基于ZStack AIOS智塔平台构建,深度融合模型部署与精调等AI基础设施管理能力,提供一站式翻译管理服务,包括:产品UI翻译、文件翻译、术语表/语料管理、日志与审计、系统管理等。此外,支持标准化API对接拓展应用,提供翻译赋能。
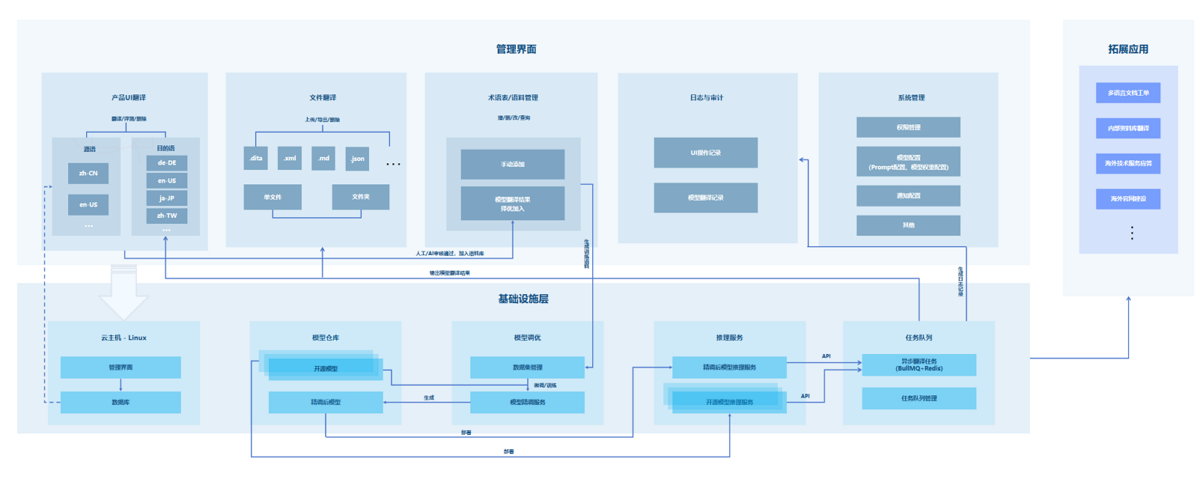
图2. 整体设计框架
1、基础设施层
1)模型管理:依托ZStack AIOS模型仓库、模型调优、推理服务等功能模块,实现从模型部署、精调到评估的一体化能力。
2)数据库层:采用PostgreSQL+Redis双引擎。通过PostgreSQL持久化存储核心数据,保证翻译数据精准可靠;通过Redis缓存翻译结果,提升翻译效率。
3)服务框架:后端采用NestJS+TypeORM+GraphQL框架,提供高性能API服务,支持分页、过滤、批量操作。前端采用React19+Zustand状态管理+ Tailwind CSS组件,提供Key管理、术语表、快照、队列、统计等管理页面。
4)异步任务:通过BullMQ队列实现翻译任务高可用、自动化调度与执行。
5)Hash计算:主要用于产品UI翻译场景。使用MurmurHash(32位)算法,通过UI词条Key+源语Value,结合不同盐值(Salt)生成64位Hash。在PostgreSQL中,通过触发器跟踪Hash值变更,精准识别源语变动,并针对变动部分触发翻译流程。
2、核心功能层
1)核心功能
- 产品UI翻译:实现“源语变动识别-翻译-结果导入代码”的全流程、自动化的UI文字翻译。
- 文件翻译:支持多种格式文件的单个/批量翻译,提供翻译进程管理与结果在线预览。
- 术语表/语料管理:支持核心术语和语料的增、删、改、查。
- 日志与审计:提供全平台操作日志与审计。
- 系统管理:支持权限管理、模型配置(Prompt配置、权重配置等)、通知配置等系统设置。
2)关键实现
- 自动化翻译工作流
-
- 任务入队:通过Hash识别源语变更,触发BullMQ任务,生成任务ID,结合Redis去重Key确保幂等,避免任务重复。
- 翻译执行:从BullMQ获取翻译任务,检查Redis和PostgreSQL中是否存在可用译文:如存在,直接使用已有译文;如不存在,自动调用模型API进行翻译,并将结果存入Redis和PostgreSQL。
- 译后处理:对翻译结果进行占位符保护、强制术语替换、标点校验、自动评分,评分较低的翻译结果将转由人工审核/修订,确保最终译文质量。
- Key & 翻译管理:使用KeyEntry表和Translation表分别管理源语和目的语数据。支持批量源语导入、翻译、结果导出,并提供保留/覆盖/合并等冲突解析策略。
- 翻译记忆:使用Redis缓存翻译和语言包,通过版本控制避免缓存失效风暴,有效提高重复内容翻译效率、降低翻译成本。
- 队列监控&审计:通过BullMQ UI面板展示翻译任务状态;通过JobAudit表记录翻译耗时、成本,用于成本统计和优化。
3、应用接口层
通过标准化API对接企业内外部业务系统,为拓展应用提供翻译赋能,例如:多语种文档工单、内部资料库翻译、海外技术服务应答、海外官网建设等。
(四)实际建设难题与攻克
1、翻译准确性
如前所述,当下通用LLM处理复杂语言任务时面临显著挑战。歧义词汇处理、上下文信息缺失、简体中文转换繁体中文的文化差异适配等,均对翻译质量造成影响。尤其专业领域翻译,术语不一致或语义偏差问题更为突显。
为此,建立完善的术语表十分必要。为专业术语提供标准翻译对照,并提供丰富的上下文信息,包括:文件路径、使用示例等。通过上下文注入,可显著提升AI翻译的准确性和一致性。在技术实现上,预处理阶段需保护占位符,避免翻译过程中的格式破坏;后处理阶段进行格式校验和术语命中率检查,确保翻译结果的技术完整性。
质量控制方面,实施自动评分机制是关键环节。采用BLEU分数和自定义规则评估翻译质量,建立质量阈值,将低于标准的翻译自动转入人工审核流程,形成AI翻译与人工审核的良性循环,持续提升整体翻译质量。
2、成本控制
大规模源语变更会触发海量AI翻译任务,导致API调用成本急剧上升。AI按Token计费,造成巨大成本压力。同时,Redis和BullMQ等基础设施在高并发场景下可能成为系统瓶颈,影响整体性能和用户体验。
成本控制核心在于智能缓存与去重机制。基于Redis实现高效缓存机制,通过BullMQ去重策略,可有效减少重复翻译任务,大幅降低不必要的API调用。该设计不仅节省成本,还提升响应速度。
服务可靠性方面,构建多LLM提供商回退链是必要措施。通过智能限流,在保证服务可用性的同时控制API调用频率。支持自建NLLM(如Llama)部署,减少外部API依赖,实现成本可控的可持续发展。
3、任务管理
BullMQ任务积压和Worker进程崩溃会导致翻译任务重复执行,不仅浪费资源,还可能结果不一致。死信队列(DLQ)的处理机制复杂,需要精心设计才能确保系统稳定性。在高并发场景下,任务调度的复杂性进一步增加系统维护难度。
幂等性保障是解决这一问题的关键。采用Redis分布式锁(RedLock)确保Worker执行的幂等性,设置任务重试上限(最多5次),避免无限重试。失败任务自动转入死信队列,便于后续分析和处理。该设计确保系统在异常情况下仍可保持数据一致性。
智能限流与监控体系同样重要。利用BullMQ的Group和Rate Limiting功能,按业务项目维度和LLM提供商维度实施精细化限流。建立队列长度监控机制,队列长度超过100时触发告警,实时监控队列健康状态,建立完善的告警机制,支持快速故障定位和恢复。
4、Hash冲突
在大规模翻译系统中,如何生成唯一且高效的缓存键是一个关键技术难题。简单的字符串拼接或基础哈希算法容易产生冲突,导致缓存失效或翻译任务误判,严重影响系统性能和准确性。尤其处理海量翻译请求时,Hash冲突概率显著增加,可能导致错误的缓存命中或重复的翻译任务。
为解决这一问题,系统采用MurmurHash(32位)算法处理Key和Value的组合。该算法相比MD5或SHA系列,计算速度更快,更适合高频缓存场景,且在大数据集上表现优异,可有效避免常见的Hash冲突问题。
进一步优化设计则是双重Hash。使用不同盐值(Salt)分别生成两个32位Hash值,将高32位和低32位拼接形成64位Hash,显著降低Hash冲突概率,提升缓存命中准确性。这种64位Hash空间可容纳庞大的取值规模,冲突概率降至几乎可忽略的水平。
通过数据库触发器配合智能变更检测机制,实时检测Hash是否变更,从而判定源语内容更新。当且仅当源语内容真正变更时才触发AI翻译任务。该设计避免因格式调整等无意义变更导致重复翻译,不仅节省计算资源,还提升整体效率。在实际应用中,该Hash同时用于Redis缓存键生成、BullMQ任务去重判断和翻译任务的唯一性标识。
5、实践心得
通过系统性解决翻译准确性、成本控制、任务管理和Hash冲突四大核心难题,ZStack成功构建一个高效、稳定、经济的AI多语种翻译平台。上述解决方案不仅适用于当前技术栈,更为未来系统发展奠定坚实基础。
在实践过程中,建议采用渐进式优化策略,优先解决最影响用户体验的问题,再逐步完善系统各个方面。通过持续打磨,最终实现系统的最佳性能与表现。事实上,每个技术难题的解决方案相互关联,形成一个完整技术生态,从而确保整个系统能在复杂生产环境中稳定运行。
(五)平台价值
1、统一管理,直观便捷
ZStack AI多语种翻译平台提供统一的可视化管理界面。支持一站式维护训练语料、工程化生产交付产品UI、多格式文件翻译管理、全平台操作日志与审计查阅、以及权限管理、模型配置、通知配置等系统设置。
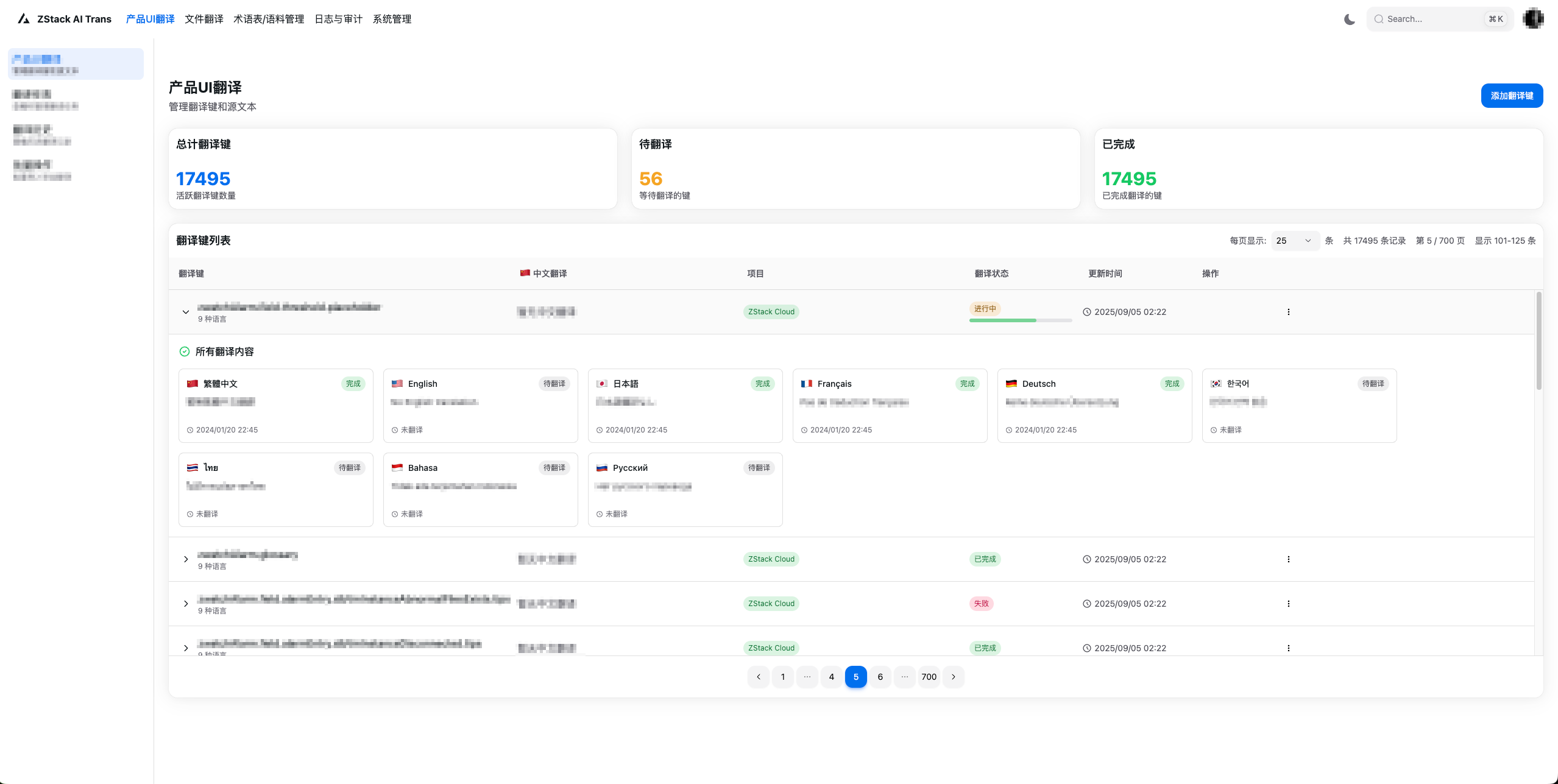
图3. 产品UI翻译界面
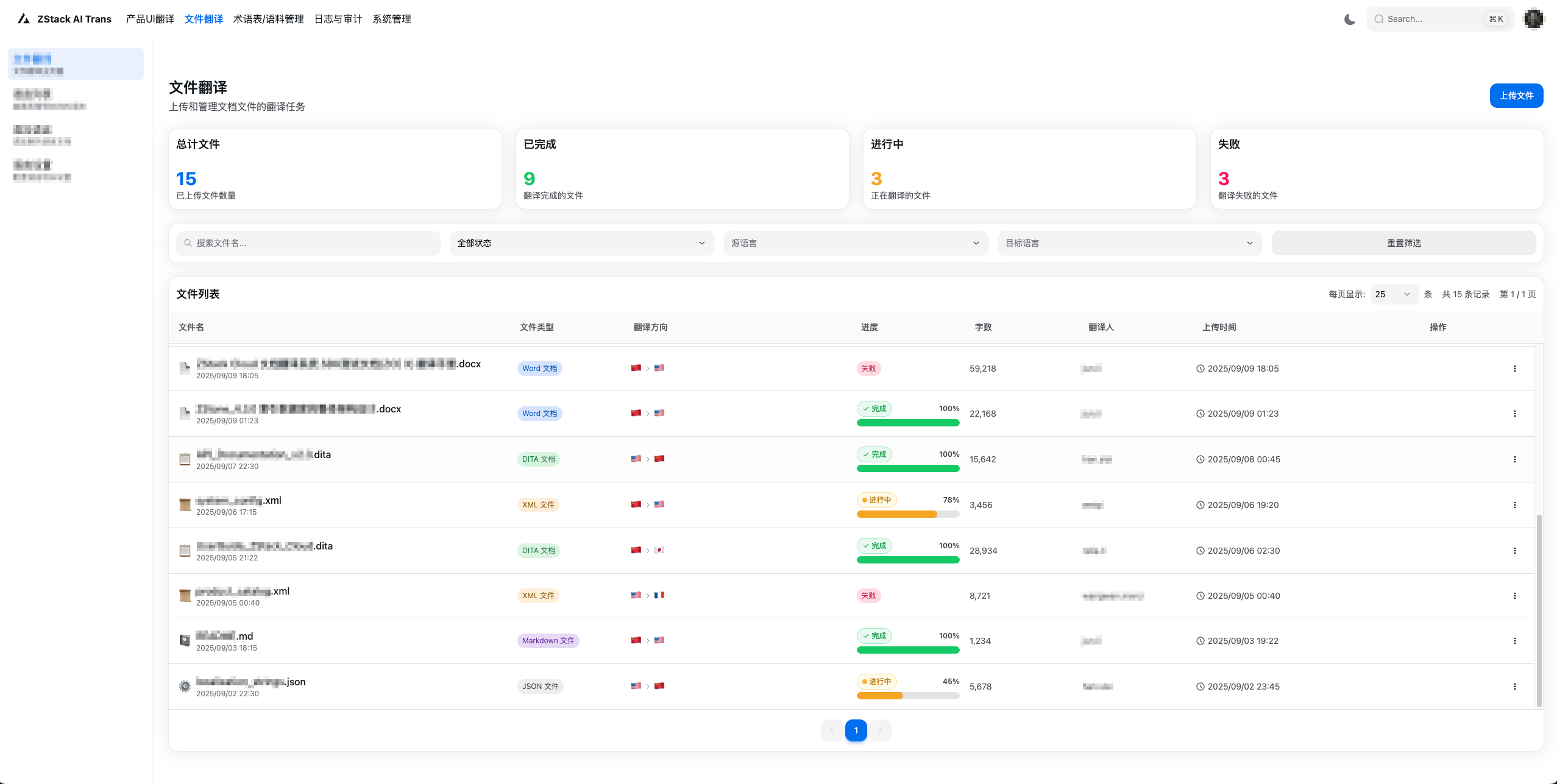
图4. 文件翻译界面
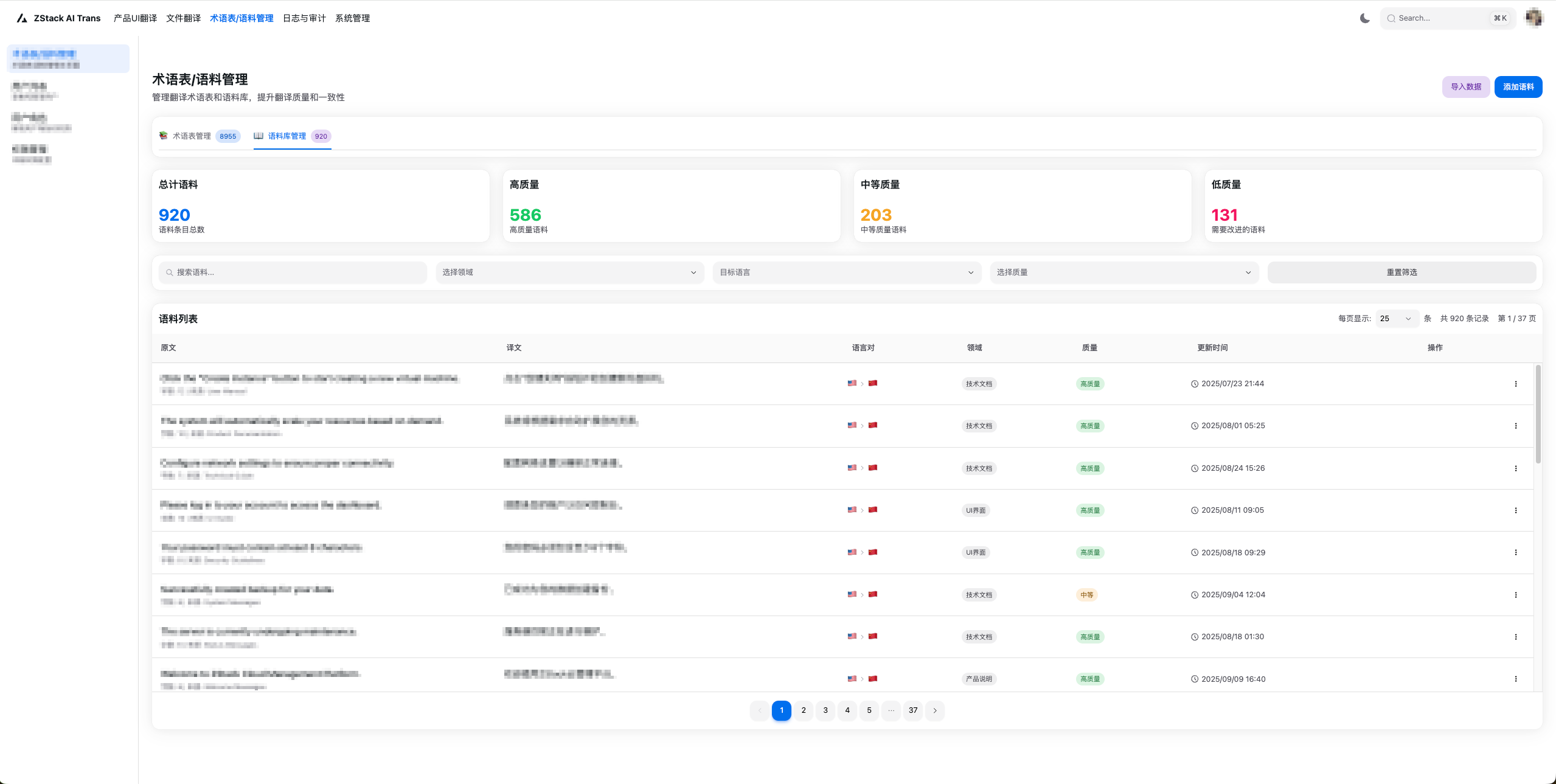
图5. 语料管理界面
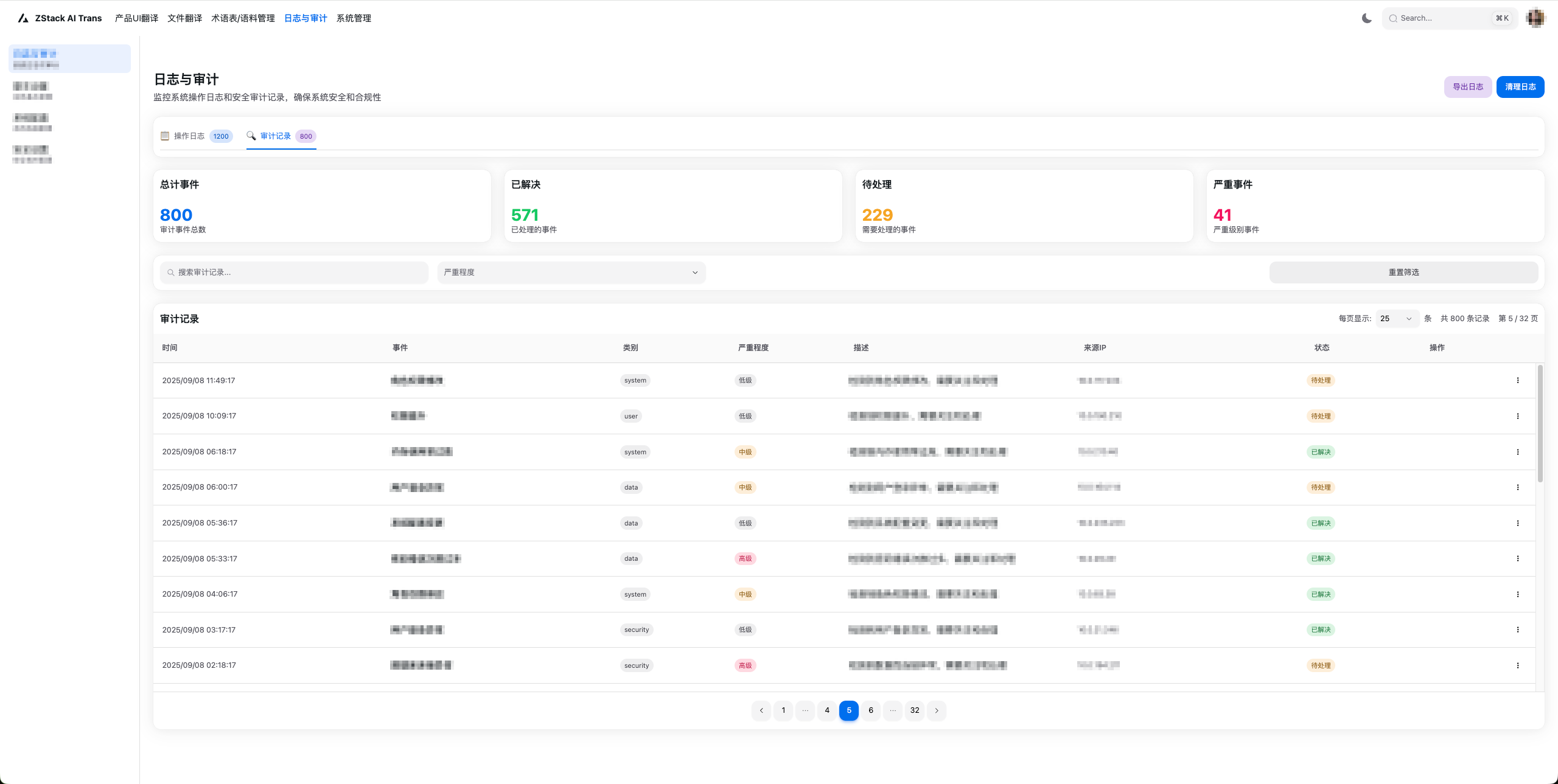
图6. 日志与审计界面
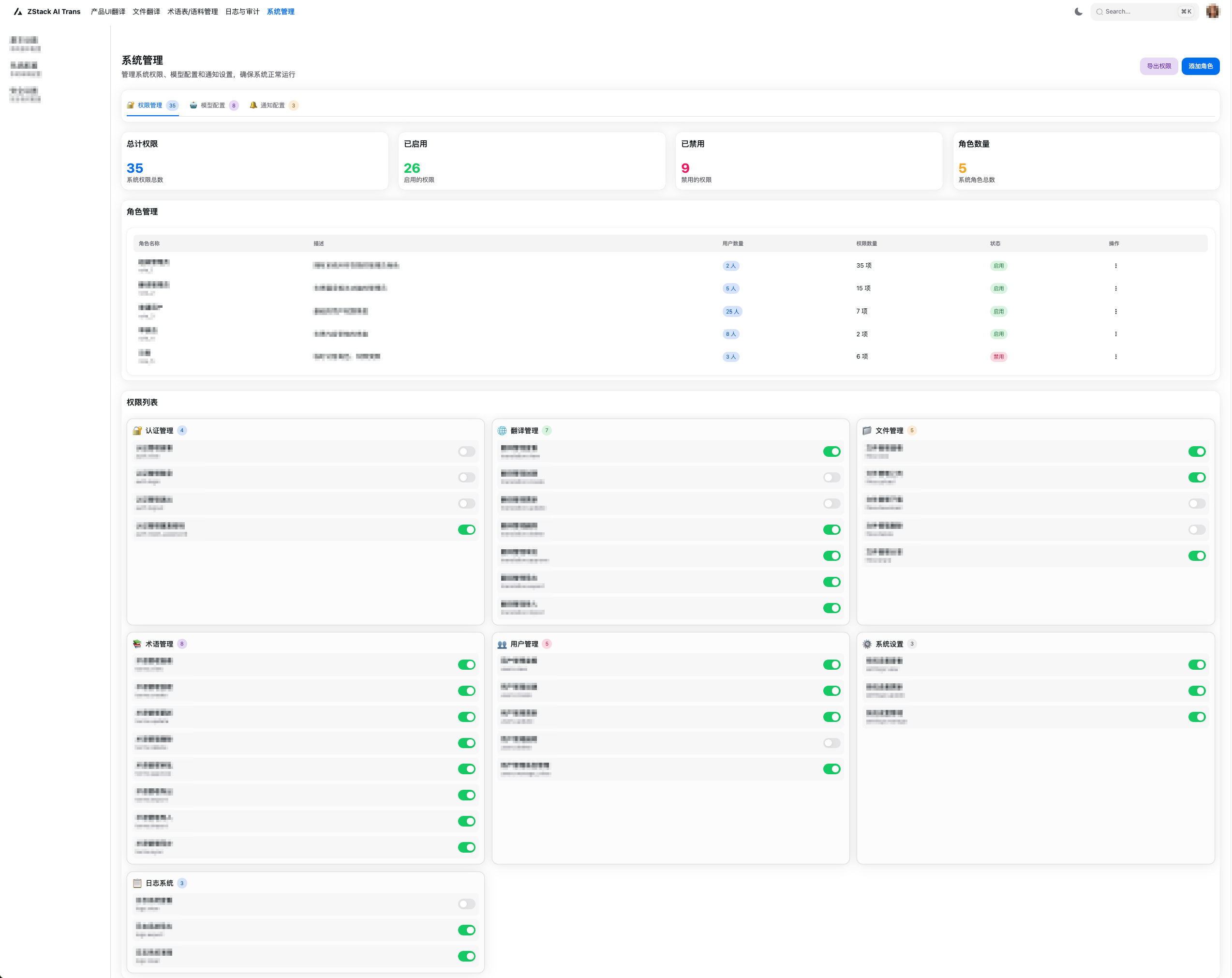
图7. 权限管理界面
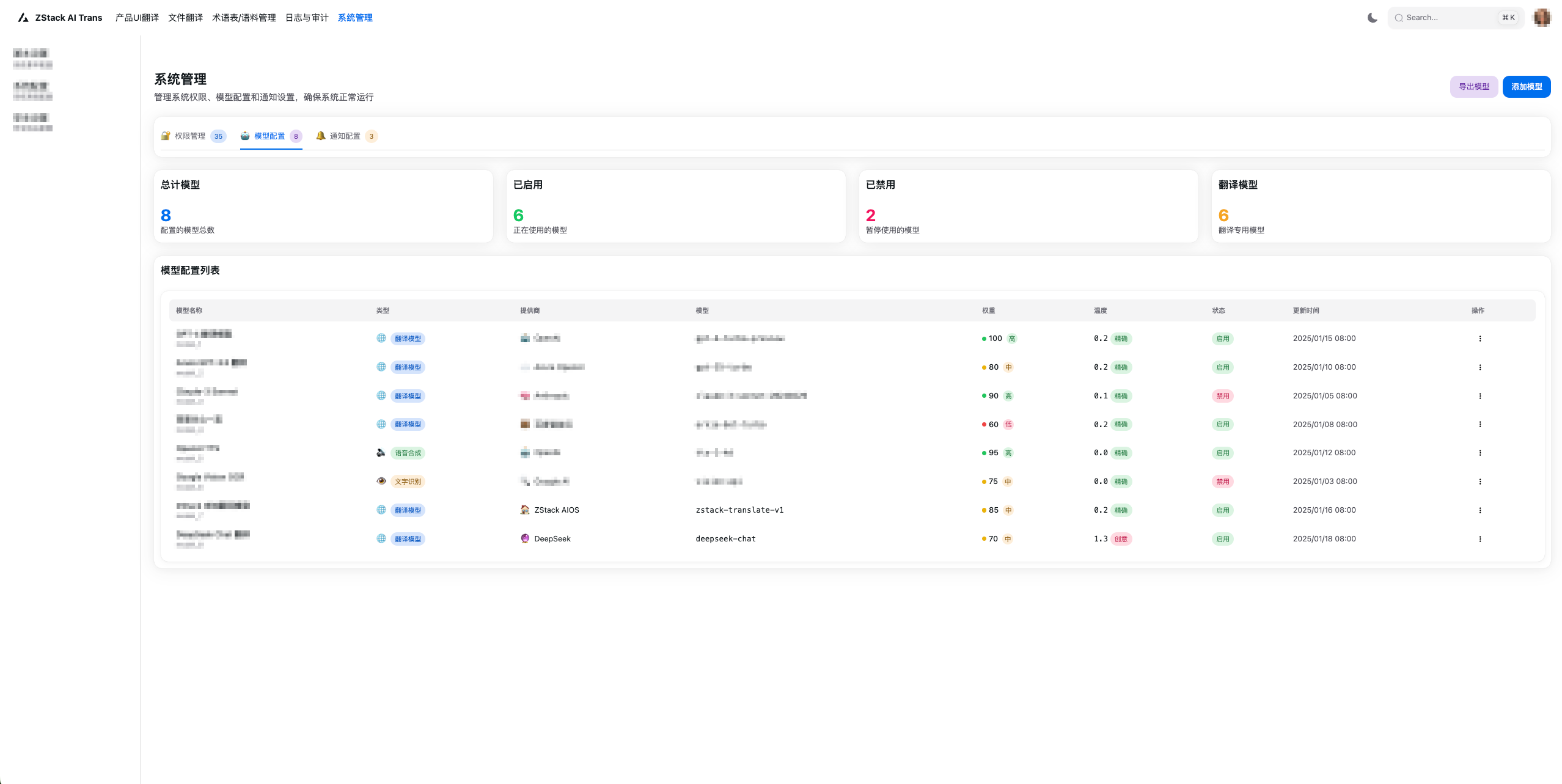
图8. 模型配置界面
图9. 通知配置界面
2、灵活扩展,赋能提效
ZStack AI多语种翻译平台提供标准化API接口,支持对接各种业务系统,例如内部资料库、海外技术服务系统、海外官网等,提供翻译赋能。
(六)结束语
为应对全球化挑战,ZStack文档一直致力于专业领域翻译技术的创新与实践。未来我们期待与更多同行者一起探索,共同推进AI驱动的智能翻译生态系统向前发展。巴别塔的奇迹正在继续。