Kafka 入门指南:从 0 到 1 构建你的 Kafka 知识基础入门体系
系列文章
文章目录
- 系列文章
- 前言
- 一、Broker 和集群 (Broker and Cluster)
- 1. Broker(代理)
- 2. Cluster(集群)
- 3. 控制器(Controller)
- 4. Zookeeper / KRaft
- 二、主题和分区 (Topic and Partition)
- 1. 主题 (Topic)
- 2. 分区 (Partition)
- 3. 偏移量 (Offset)
- 4. 分区副本 (Replication) 和 Leader/Follower
- 三、 核心关系:Broker、主题与分区的协作模式
- 图示说明
- 四、生产者和消费者 (Producer and Consumer)
- 1. 生产者 (Producer)
- 消息和批次 (Messages and Batches)
- 2. 消费者 (Consumer) 和消费组 (Consumer Group)
- 四、整体工作流程回顾
- 总结
前言
在现代分布式系统中,例如大型电商平台,业务流程会持续产生海量的事件数据,如用户行为、订单状态变更、支付通知、库存更新及物流跟踪等。这些事件通常需要被多个下游系统(如推荐系统、库存服务、数据分析平台)进行消费和处理。
如果采用直接的点对点集成方式,会导致服务之间形成高度耦合的连接关系。这种架构不仅难以维护和扩展,而且任何一个服务的变更都可能对依赖它的其他服务产生直接影响,降低了系统的健壮性和灵活性。因此,在系统设计中引入一个中间层来实现服务间的解耦和异步通信,成为了一种必要的架构选择。
Apache Kafka 正是为应对此类大规模、实时的事件流处理需求而设计的分布式平台。本文旨在系统性地介绍构成 Kafka 的四个基本组件:集群(Broker)、主题(Topic)、生产者(Producer) 和 消费者(Consumer)。通过理解这些组件的定义及其协作方式,你将能清晰地掌握 Kafka 的核心工作原理,并了解它们如何共同构建起可靠、高效的数据管道。
一、Broker 和集群 (Broker and Cluster)
首先,我们从 Kafka 的物理基础——服务器和集群开始。
1. Broker(代理)
Broker 是 Kafka 集群中的一个独立服务器实例。你可以把它想象成一台运行着 Kafka 服务的计算机。它的核心职责是:
- 接收消息:从生产者那里接收消息。
- 存储消息:将消息持久化到磁盘上,以确保数据不会丢失。
- 提供消息:为消费者提供服务,让它们可以拉取(pull)所需的消息。
每个 Broker 都有一个唯一的整数 ID,例如 0, 1, 2。
2. Cluster(集群)
一个 Kafka 集群 由一个或多个 Broker 组成。将多个 Broker 组合成一个集群,主要带来两大好处:
- 高可用性 (High Availability):当集群中的某个 Broker 发生故障时,其他 Broker 可以接管它的工作,确保整个系统服务不中断。这种容错能力是通过**分区副本(Partition Replication)**机制实现的。
- 高扩展性 (High Scalability):当数据量或请求量增加时,你可以通过向集群中添加更多的 Broker 来水平扩展系统的存储能力和处理能力。
3. 控制器(Controller)
在 Kafka 集群中,有一个特殊的 Broker 会被选举为控制器(Controller)。控制器的角色至关重要,它负责管理整个集群的状态,包括:
- 分区管理:决定哪个 Broker 上的哪个副本成为分区的 Leader。
- Broker 监控:监听 Broker 的上线和下线,并在 Broker 发生变化时执行相应的管理任务。
- 状态维护:维护集群的元数据信息。
4. Zookeeper / KRaft
传统上,Kafka 使用 Apache ZooKeeper 来存储集群的元数据(如 Broker 列表、Topic 配置、ACLs 等)并协助进行控制器选举。然而,从 Kafka 2.8 版本开始,引入了基于 Raft 协议的 KRaft 模式,旨在逐步取代 ZooKeeper,将元数据管理的功能内置到 Kafka Broker 自身,从而简化部署和运维。
小结:Broker 是 Kafka 的单个服务器,多个 Broker 组成一个集群。集群通过控制器和分区副本机制,共同提供了高可用和高扩展性的分布式消息服务。
二、主题和分区 (Topic and Partition)
在了解了物理基础后,我们来看看数据在 Kafka 中是如何被逻辑组织的。
1. 主题 (Topic)
主题(Topic) 是 Kafka 中消息的逻辑分类。你可以把它看作是数据库中的一张表,或者是文件系统中的一个文件夹。所有相关的消息都应该被发布到同一个 Topic 中。例如,一个电商系统可以有 orders(订单)、payments(支付)、user-clicks(用户点击)等多个 Topic。
生产者将消息发送到指定的 Topic,消费者则订阅它们感兴趣的 Topic 来接收消息。
2. 分区 (Partition)
分区(Partition) 是 Kafka 实现并行处理和高吞吐量的核心机制。一个 Topic 可以被划分为一个或多个分区。每个分区都是一个有序的、不可变的、只能追加(append-only)的消息序列,也就是一个提交日志(Commit Log)。
分区的主要特点和作用:
- 有序性保证:在单个分区内部,消息是严格按照其被写入的顺序存储和读取的。但 Kafka 不保证 Topic 级别的全局消息顺序。
- 水平扩展:一个 Topic 的数据可以分布在集群的多个 Broker 上,每个 Broker 负责存储一部分分区。这使得 Topic 的存储容量可以超越单个服务器的限制。
- 并行消费:多个消费者可以同时从一个 Topic 的不同分区读取数据,极大地提高了消费端的处理能力。
3. 偏移量 (Offset)
分区中的每条消息都有一个唯一的、连续递增的整数 ID,称为偏移量(Offset)。Offset 精确地标识了消息在分区中的位置。消费者通过维护自己消费到的 Offset 来跟踪其读取进度。这使得消费者可以自由地控制其消费位置,例如重新消费已经处理过的消息。
4. 分区副本 (Replication) 和 Leader/Follower
为了实现高可用性,每个分区都可以配置多个副本(Replicas)。这些副本存储在集群的不同 Broker 上。
- Leader 副本:每个分区有且仅有一个 Leader 副本。所有来自生产者和消费者的读写请求都由 Leader 副本处理。
- Follower 副本:其他副本都是 Follower 副本。它们唯一的任务就是从 Leader 处异步地复制数据,保持与 Leader 的同步。
- ISR (In-Sync Replicas):与 Leader 保持同步的 Follower 副本集合(包括 Leader 自身)被称为 ISR。当 Leader 发生故障时,控制器会从 ISR 中选举一个新的 Leader,以确保数据的完整性。
小结:Topic 是消息的逻辑分类。它被划分为多个分区,分区是实现扩展性和并行性的基础。每个分区内的消息通过 Offset 保证有序,并通过副本机制保证高可用性。
三、 核心关系:Broker、主题与分区的协作模式
在理解了各个独立组件后,最关键的是要弄清楚它们是如何协同工作的。Broker、主题和分区之间的关系是 Kafka 分布式架构的基石。
让我们来详细解读这层关系:
-
主题(Topic)与分区(Partition)的关系:逻辑与物理的映射
- 一对多关系:一个主题(Topic)是消息的逻辑分类,但它在物理上被划分为一个或多个分区(Partition)。这就像将一个大文件拆分成多个小块,以便于管理和并行处理。
- 数据分片:主题中的所有消息被分散存储在这些分区中。每个分区只包含主题消息的一个子集。生产者发送消息时,通过分区策略(如基于 Key 的哈希或轮询)决定消息进入哪个分区。
- 顺序性保证:Kafka 只保证 在单个分区内部,消息是严格按照写入顺序存储和读取的。因为一个主题的消息被分散到不同分区,所以 Kafka 不保证主题级别的消息全局有序。这是一种为了获得极高吞吐量而做的设计权衡。
-
分区(Partition)与副本(Replica)的关系:高可用的保障
- 主从架构:为了防止数据丢失和保证服务的高可用性,每个分区都可以配置多个副本(通常建议为3个)。这些副本存储在集群中不同的 Broker 上。
- Leader 与 Follower:在分区的所有副本中,有且只有一个是 Leader 副本。它承担了该分区所有的读写请求。所有生产者和消费者的请求都直接与 Leader 交互。(
- 数据同步:其余的副本都是 Follower 副本。它们唯一的职责就是从 Leader 处被动地、异步地拉取数据,以保持与 Leader 的数据同步。如果 Leader 发生故障,控制器会从同步状态良好(ISR 集合内)的 Follower 中选举一个新的 Leader,整个过程对用户透明。
2.0版本后,写操作Leader,读操作Fellow)
-
分区/副本(Partition/Replica)与 Broker 的关系:分布式部署
- 物理承载:分区及其副本最终都需要存储在物理服务器上,也就是 Broker。
- 智能分布:Kafka 的控制器会尽可能地将一个主题的不同分区以及每个分区的不同副本均匀地分布到集群中的各个 Broker 上。
这种分布策略有两个核心目的:
- 负载均衡:将读写请求的压力分散到整个集群,避免单点性能瓶颈。
- 容错能力:即使某个 Broker 宕机,由于其上的分区副本在其他 Broker 上都有备份,服务依然可以继续,数据也不会丢失。
图示说明
假设我们有一个3个 Broker 的集群,一个名为 Topic-A 的主题,它有2个分区(P0, P1),每个分区的副本因子为3。Kafka 的分布可能如下所示:
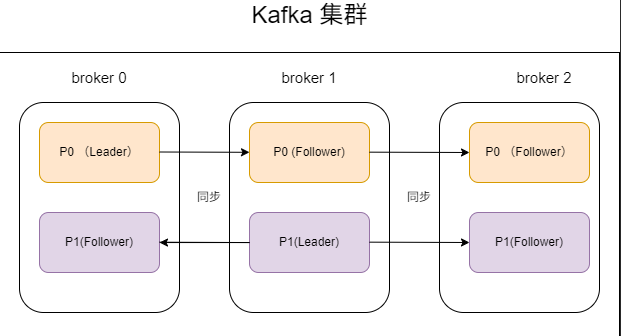
从图中可以看出:
- 分区0(P0)的 Leader 在 Broker 0 上,其 Follower 在 Broker 1 和 Broker 2 上。
- 分区1(P1)的 Leader 在 Broker 1 上,其 Follower 在 Broker 0 和 Broker 2 上。
- 读写负载被分散:对 P0 的请求由 Broker 1 处理,对 P1 的请求由 Broker 2 处理。
- 高可用:如果 Broker 1 宕机,P1 不受影响。对于 P0,Kafka 会在 Broker 2 和 Broker 3 之间选举一个新的 Leader,服务很快就能恢复。
四、生产者和消费者 (Producer and Consumer)
现在,我们来看看与 Kafka 系统交互的两个主要角色。
1. 生产者 (Producer)
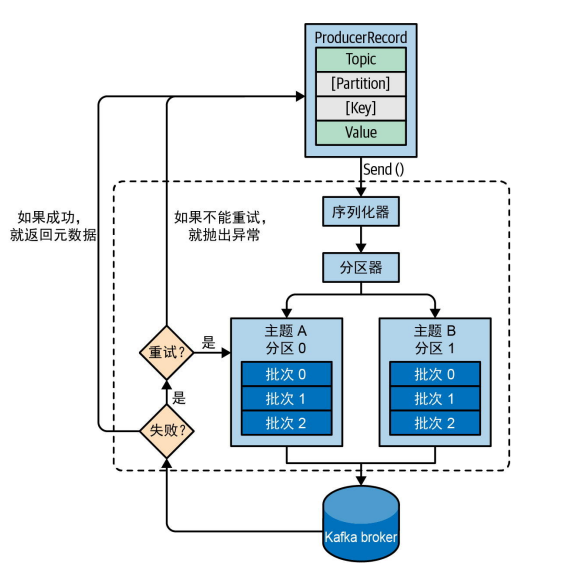
生产者是创建并向 Kafka Topic 发布消息的客户端应用程序。
核心工作流程:
- 创建消息:生产者创建一个
ProducerRecord对象,其中包含目标 Topic、可选的分区号、Key(键)和 Value(值)。 - 序列化:生产者将 Key 和 Value 序列化成字节数组,因为 Kafka 只处理字节流。
- 分区选择:生产者通过**分区器(Partitioner)**来决定消息该发送到哪个分区:
- 如果消息中指定了分区,则直接发送到该分区。
- 如果未指定分区但指定了 Key,则对 Key 进行哈希计算,并映射到一个分区。这保证了所有具有相同 Key 的消息都会被发送到同一个分区,从而保证了这些消息的相对顺序。
- 如果既未指定分区也未指定 Key,则以轮询(Round-robin)的方式将消息均匀地发送到各个分区。
- 发送消息:生产者将消息发送给目标分区的 Leader 副本所在的 Broker。
消息和批次 (Messages and Batches)
- 消息 (Message):Kafka 中数据传输的基本单位,由 Key、Value、时间戳和一些元数据头(Headers)组成。Key 和 Value 的内容对 Kafka 来说是透明的字节数组。
- 批次 (Batch):**为了提高效率,生产者并不会每条消息都单独发送。相反,它会将发往同一个分区的多条消息收集到一个批次(Batch)**中,然后一次性发送。这种批处理机制极大地减少了网络请求的开销,显著提高了吞吐量。生产者可以通过
batch.size和linger.ms参数来控制批次的大小和发送时机。
2. 消费者 (Consumer) 和消费组 (Consumer Group)
消费者是从 Kafka Topic 读取消息的客户端应用程序。Kafka 的消费模型非常强大和灵活,其核心是消费组(Consumer Group)。
-
消费组 (Consumer Group):一个消费组由一个或多个消费者实例组成,它们共同消费一个或多个 Topic 的数据。一个消费组有一个唯一的 Group ID。
-
分区所有权:在任何时刻,一个 Topic 的每个分区只能被同一个消费组内的一个消费者实例消费。这种设计确保了每个分区的数据只会被处理一次,从而实现了消费者之间的负载均衡。
-
负载均衡和再均衡 (Rebalance):
- 如果一个消费组内的消费者数量少于 Topic 的分区数,那么某些消费者将消费多个分区。
- 如果消费者数量等于分区数,则每个消费者将恰好消费一个分区。
- 如果消费者数量多于分区数,那么多余的消费者将会空闲。
- 当有新的消费者加入消费组,或有现有消费者离开(例如崩溃或正常关闭)时,会触发再均衡(Rebalance)。在再均衡过程中,分区的所有权会重新分配给组内的消费者,以达到新的平衡。
-
偏移量提交 (Offset Commit):消费者需要定期**提交(Commit)**它已经成功处理的消息的 Offset。这个信息会保存在 Kafka 一个名为
__consumer_offsets的内部 Topic 中。如果消费者崩溃并重启,它可以从上次提交的 Offset 处继续消费,避免了重复处理或丢失数据。
小结:生产者负责创建消息并将其高效地(通过批处理)发送到 Topic 的特定分区。消费者以消费组的形式工作,通过分区分配机制实现并行处理和负载均衡,并通过提交 Offset 来保证消息处理的可靠性。
四、整体工作流程回顾
让我们将这四个核心组件串联起来,看一个完整的事件流处理流程:
- 启动集群:首先,一个由多个 Broker 组成的 Kafka 集群 启动并运行。其中一个 Broker 被选举为控制器。
- 创建主题:管理员创建一个名为
user-activity的 Topic,并设定它有 3 个分区和 3 个副本。控制器负责将这些分区及其副本分配到不同的 Broker 上,并为每个分区选举一个 Leader。 - 生产者发送消息:一个 Web 服务器作为生产者,每当用户点击一个按钮时,它就会生成一条消息(例如,
key="user123", value="clicked_buy_button")。 - 分区定位:生产者使用
user123这个 Key 进行哈希计算,确定该消息应该发送到分区1。 - 发送与存储:生产者将消息发送给分区1的 Leader Broker。该 Broker 将消息写入其本地日志,并等待 ISR 中的 Follower 副本也完成同步。
- 消费者组消费:一个数据分析服务启动了两个消费者实例,它们都属于同一个消费组
analytics-group。 - 分区分配:Kafka 将
user-activityTopic 的 3 个分区分配给这两个消费者。例如,消费者A负责消费分区0和分区1,消费者B负责消费分区2。 - 拉取与处理:消费者A 从分区1的 Leader Broker 处拉取
user123这条消息,并更新其内部的统计数据。 - 提交偏移量:处理完一批消息后,消费者A 向 Kafka 提交它在分区1上消费到的最新偏移量,标记这条消息已经被成功处理。
这个流程周而复始,形成了一个解耦、异步、可靠且可扩展的数据管道,完美地解决了前言中提到的分布式系统集成问题。
总结
通过本文的介绍,我们系统地学习了构成 Apache Kafka 的四大核心组件:
- Broker 和集群:提供了 Kafka 服务的物理基础,通过分布式部署实现了高可用性和水平扩展能力。
- 主题和分区:构成了 Kafka 数据的逻辑组织结构。主题用于分类消息,而分区是实现并行处理和数据分发的核心。
- 生产者:作为数据的来源,负责高效、可靠地将消息发布到指定的主题分区中。
- 消费者和消费组:作为数据的终点,通过强大的消费组模型,实现了负载均衡、容错和可扩展的消息处理。
这四个组件环环相扣、协同工作,使得 Kafka 能够作为一个高性能、高吞吐量的分布式事件流平台,在现代数据架构中扮演着不可或缺的角色。希望通过这篇文章,你已经对 Kafka 的核心原理有了清晰的认识。