【数据结构】 ArrayList深入解析
AraayList
- 一、ArrayList的使用
- ArrayList的构造方法
- 二、ArrayList 基本操作与源码解析
- 2. 操作 1:添加元素(`add()` 与 `addAll()`)
- 2.(1) 按索引添加元素(`add(int index, E element)`)
- 2.(2) 源码解析:`add(int index, E element)`
- 2.2.3 批量添加元素(`addAll(Collection<? extends E> c)`)
- 2.3 操作 2:删除元素(`remove()` 重载)
- 2.3.1 按索引删除(`remove(int index)`)
- 2.3.2 按元素删除(`remove(Object o)`)
- 2.4 操作 3:查找元素(`indexOf()` 与 `lastIndexOf()`)
- 2.5 操作 4:截取子集合(`subList(int fromIndex, int toIndex)`)
- 2.5.1 坑点:修改子集合会影响原集合
- 三、ArrayList 常见问题与思考
- 四、ArrayList 四种遍历方式
- 4.1 遍历代码示例
- 方式 1:普通 for 循环(基于索引)
- 方式 2:增强 for 循环(for-each)
- 方式 3:Iterator 迭代器
- 方式 4:ListIterator 迭代器(扩展版)
- 4.2 遍历方式对比表
一、ArrayList的使用
在深入操作前,先明确 ArrayList 的关键特性,这是理解后续内容的基础:
- 泛型实现:采用泛型设计,使用前需实例化(指定元素类型,如
ArrayList<Integer>),避免类型转换异常。 - 接口实现:
- 实现
RandomAccess接口:支持高效随机访问(通过索引直接获取元素,时间复杂度 O(1))。 - 实现
Cloneable接口:支持克隆(clone()方法)。 - 实现
Serializable接口:支持序列化(可网络传输或持久化存储)。
- 实现
- 线程安全性:非线程安全,单线程环境直接使用;多线程需选择
Vector或CopyOnWriteArrayList。 - 底层结构:基于连续内存空间(
Object[] elementData数组),支持动态扩容,本质是“动态顺序表”。
ArrayList的一些基本操作,与我们自己手动实现的MyArrayList相似
ArrayList的构造方法
在讲解构造方法之前,我们先来看一下ArrayList的成员变量的源码:
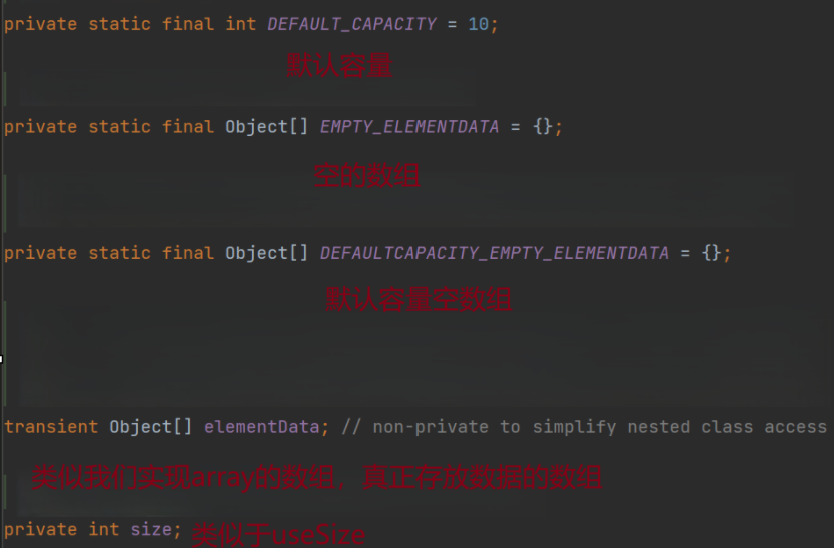
有三种构造方法:
1.第一种正常参数的方法:

当传递参数数为一个数值时,会按以下规则处理:
- 若该数值大于0,则创建一个长度为此数值的数组
- 若该数值等于0,则使用空数组来存储数据
- 若该数值小于0,则抛出异常
2.没有参数的构造方法:

public static void main(String[] args) {ArrayList<Integer> list = new ArrayList<>();list.add(10);list.add(11);list.add(12);list.add(1,13);System.out.println(list);list.clear();System.out.println(list);
}
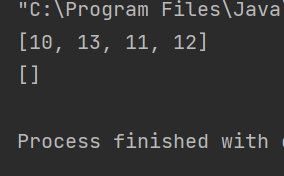
这个时候,我们可以观察没有传递任何参数,但是却能打印,我们可以看到这个构造方法是真正存放数据的数组等于默认容量置空数组
我们就会想要来了解这个时候的值都放在哪里了?
那么这个时候就要先看一下list的add的方法了;
//部分源码:博主用的是JDK17,17对于一些源码进行封装的处理public boolean add(E e) {modCount++;add(e, elementData, size);return true;}private void add(E e, Object[] elementData, int s) {if (s == elementData.length)elementData = grow();elementData[s] = e;size = s + 1;}private Object[] grow(int minCapacity) {int oldCapacity = elementData.length;if (oldCapacity > 0 || elementData != DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {int newCapacity = ArraysSupport.newLength(oldCapacity,minCapacity - oldCapacity, /* minimum growth */oldCapacity >> 1 /* preferred growth */);return elementData = Arrays.copyOf(elementData, newCapacity);} else {return elementData = new Object[Math.max(DEFAULT_CAPACITY, minCapacity)];}}private Object[] grow() {return grow(size + 1);}我们会发现,没有进行传递参数的构造方法时,那么真正存放数据的数组就等于默认置空数组,如果我们调用add方法时候,添加一个元素为10;
这个时候add传参的值就是e=10, elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA,size=0
所以我们看到真正的add方法,那么这个是s 等于数组的长度(0 == 0),那么就会扩容进入到grow方法中
由于size = 0,所以扩容方法首次传递的参数就是size +1(也就是1),所以那么参数minCapacity为1,而这个时候oldCapacity也就是0,所以就会判断oldCapacity和elementData是否成立,但是这种第一次无法成立,直接进入到else,所以最后通过取默认容量10(DEFAULT_CAPACITY)和 minCapacity的最大值
可以触发扩容的两种情况:
- 0 == 0
- size == elementData.length(放满了)
扩容的新容量是当前容量的1.5倍(通过oldCapacity + (oldCapacity >> 1)计算
如果如果用户所需大小超过预估1.5倍大小,则按照用户所需大小扩容
真正扩容之前检测是否能扩容成功,防止太大导致扩容失败
结论:这个方法可以在第一次add方法时候进行分配内存空间,第一次的大小是10
3.参数为集合的构造方法:
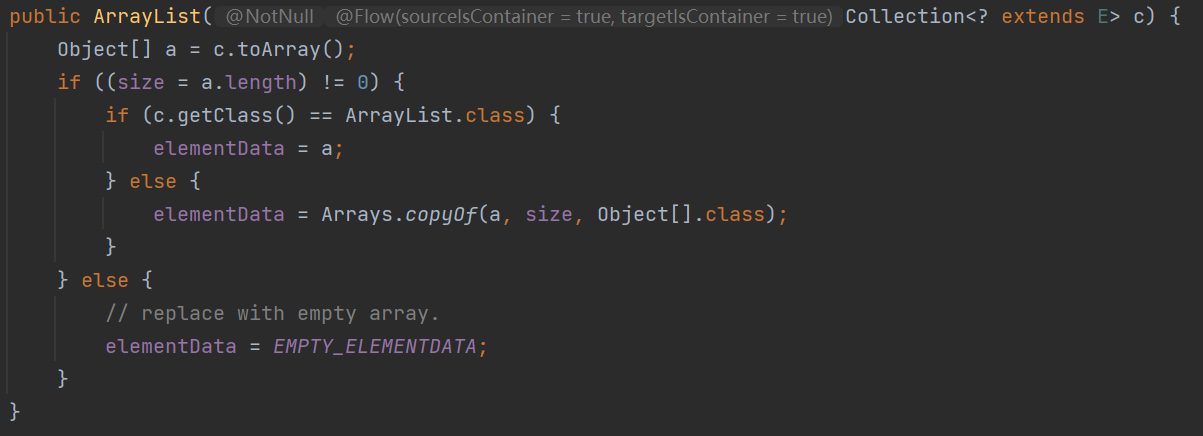
Collection<? extends E> c只要实现了
collection的接口,便都是可以进行传参
?指的是通配符
E表示通配符的上界
那么两者也就是表示?要么是E的子类,要么是E本身
ArrayList<Integer> list2 = new ArrayList<>(list);list2.add(999999999);System.out.println(list2);

由此可见,当传递的是类型化集合类时,若传递的是 List,则它实现了Collection接口。此时,代码中的泛型参数E对应Integer,因此该 List 集合的元素类型只能是Integer本身或其派生的子类。
二、ArrayList 基本操作与源码解析
2. 操作 1:添加元素(add() 与 addAll())
ArrayList 提供两种添加元素的核心方法:单个元素添加(add())和批量元素添加(addAll())。
2.(1) 按索引添加元素(add(int index, E element))
功能:在指定索引位置插入元素,后续元素需向后“搬移”,确保内存连续性。
ArrayList<Integer> list = new ArrayList<>();
// 在索引 0、1、2 分别插入元素
list.add(0, 23);
list.add(1, 5);
list.add(2, 2);
System.out.println(list);
2.(2) 源码解析:add(int index, E element)
底层通过数组拷贝实现元素“后移”,并处理扩容逻辑,关键步骤如下:
public void add(int index, E element) {// 1. 检查索引合法性(不能小于 0,也不能大于当前元素个数)rangeCheckForAdd(index);// 2. 记录集合修改次数(用于快速失败机制,如迭代器遍历中修改集合会抛异常)modCount++;final int s; // 当前集合元素个数Object[] elementData; // 底层存储数组// 3. 检查是否需要扩容(若当前元素个数 == 数组长度,触发扩容)if ((s = size) == (elementData = this.elementData).length)elementData = grow(); // 扩容方法(默认扩容为原容量的 1.5 倍,JDK 8+)// 4. 数组拷贝:将 index 及后续元素向后搬移 1 位System.arraycopy(elementData, index, // 原数组 + 原数组起始索引elementData, index + 1,// 目标数组 + 目标数组起始索引(后移 1 位)s - index // 拷贝长度(index 到末尾的元素个数));// 5. 在空出的 index 位置插入新元素elementData[index] = element;// 6. 元素个数 +1size = s + 1;
}
关键结论:
- 按索引添加元素的时间复杂度为 O(N)(需搬移后续元素),不适合频繁在头部插入。
- 扩容时会申请新内存、拷贝旧数据、释放旧内存,存在性能开销,建议初始化时预估容量(如
new ArrayList<>(100))。
2.2.3 批量添加元素(addAll(Collection<? extends E> c))
功能:将另一个集合的所有元素添加到当前 ArrayList 的末尾,无需指定索引。
// 新建一个待批量添加的集合
ArrayList<Integer> test = new ArrayList<>();
test.add(1);
test.add(2);
test.add(3);
// 批量添加 test 的所有元素到 arrayList 末尾
arrayList.addAll(test);
System.out.println(list); // 输出:[23, 5, 2, 1, 2, 3]
源码逻辑:
- 检查传入集合
c是否为空,为空则直接返回false。 - 将
c转换为数组,计算其长度numNew。 - 检查当前 ArrayList 容量是否足够(
size + numNew是否超过数组长度),不足则扩容。 - 通过
System.arraycopy()将c的数组拷贝到elementData的末尾。 - 更新
size(size += numNew)。
2.3 操作 2:删除元素(remove() 重载)
ArrayList 提供两种删除方式:按索引删除(remove(int index))和按元素删除(remove(Object o))。
2.3.1 按索引删除(remove(int index))
功能:删除指定索引的元素,后续元素向前“覆盖”,填补空位。
// 删除索引 0 的元素(值为 23)
arrayList.remove(0);
System.out.println(arrayList);
// 输出:[5, 2, 1, 2, 3]
2.3.2 按元素删除(remove(Object o))
功能:删除第一个匹配的元素(需通过 equals() 比较),若元素为 null 则匹配 null。
// 删除元素 1(注意:JDK 9+ 中 new Integer(1) 已过时,建议直接传值)
arrayList.remove(new Integer(1)); // 过时写法
arrayList.remove(1); // 推荐写法(自动装箱为 Integer)
System.out.println(arrayList);// 输出:[5, 2, 2, 3]
源码核心逻辑:
- 遍历
elementData数组,找到第一个与o匹配的元素(o == null则匹配null,否则调用o.equals(es[i]))。 - 若找到匹配元素,调用
fastRemove(i)进行删除(本质是数组拷贝,将i+1及后续元素向前搬移 1 位)。 - 未找到则返回
false。
关键结论:
- 两种删除方式的时间复杂度均为 O(N)(需搬移后续元素)。
- 按元素删除需遍历数组,若元素不存在则遍历全表,效率较低。
2.4 操作 3:查找元素(indexOf() 与 lastIndexOf())
功能:
indexOf(Object o):从头部开始遍历,返回第一个匹配元素的索引,无匹配则返回-1。lastIndexOf(Object o):从尾部开始遍历,返回第一个匹配元素的索引,无匹配则返回-1。
// 查找元素 2 的索引(从头部开始)
System.out.println(arrayList.indexOf(2)); // 输出:1(第一个 2 在索引 1)
// 查找元素 2 的索引(从尾部开始)
System.out.println(arrayList.lastIndexOf(2)); // 输出:2(最后一个 2 在索引 2)
源码解析(indexOfRange() 核心逻辑):
int indexOfRange(Object o, int start, int end) {Object[] es = elementData;if (o == null) {// 匹配 null 元素for (int i = start; i < end; i++) {if (es[i] == null) return i;}} else {// 匹配非 null 元素(调用 equals())for (int i = start; i < end; i++) {if (o.equals(es[i])) return i;}}return -1;
}
注意:若元素未重写 equals() 方法(如自定义对象),则默认使用 Object 的 equals()(比较地址),可能导致查找结果不符合预期,需手动重写 equals()。
**结论: lastIndexOf从后到前遍历,从而第一次返回了目标对象返回下标
IndexOf从前到后遍历,第一次返回目标对象的下标 **
2.5 操作 4:截取子集合(subList(int fromIndex, int toIndex))
功能:返回原集合中从 fromIndex(包含)到 toIndex(不包含)的子集合,注意子集合与原集合共享内存空间。
// 新建一个集合用于演示截取
ArrayList<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
list.add(4);
list.add(5);
// 截取索引 1~3 的元素(包含 1,不包含 3,即元素 2、3)
List<Integer> list1 = list.subList(1, 3);
System.out.println(list); // 原集合:[1, 2, 3, 4, 5]
System.out.println(list1); // 子集合:[2, 3]
2.5.1 坑点:修改子集合会影响原集合
由于子集合与原集合共享内存,修改子集合的元素会直接同步到原集合:
// 修改子集合 list1 的索引 0 元素为 99
list1.set(0, 99);
System.out.println(list); // 原集合变为:[1, 99, 3, 4, 5]
System.out.println(list1); // 子集合变为:[99, 3]
//list预期结果分别是:1,2,3,4,5 list1预期结果:99,3
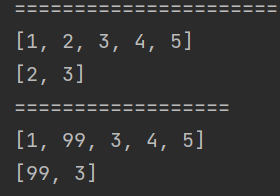
源码原因:
subList() 返回的是 ArrayList 的内部类 SubList,SubList 并未创建新数组,而是直接引用原集合的 elementData 数组,仅通过 offset(偏移量)和 size(子集合长度)限定访问范围。
建议:若需独立子集合,需手动创建新 ArrayList 并传入子集合:
List<Integer> independentList = new ArrayList<>(list.subList(1, 3));
三、ArrayList 常见问题与思考
ArrayList 虽易用,但在性能和空间上存在固有缺陷,需在实际开发中规避:
-
插入/删除效率低
底层为连续数组,任意位置插入/删除需搬移后续元素,时间复杂度 O(N),频繁在头部操作建议使用LinkedList。 -
扩容的性能开销
扩容时需申请新内存、拷贝旧数据、释放旧内存(默认扩容为原容量的 1.5 倍),频繁扩容会浪费资源。建议初始化时预估容量(如new ArrayList<>(1000))。 -
空间浪费
扩容后若元素未填满,会产生闲置空间。例如:容量 100 扩容到 200,仅插入 5 个元素,会浪费 95 个空间。
四、ArrayList 四种遍历方式
ArrayList 支持多种遍历方式,不同场景下效率和易用性不同,以下是详细对比:
4.1 遍历代码示例
先准备遍历所需的集合:
ArrayList<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
list.add(4);
list.add(5);
方式 1:普通 for 循环(基于索引)
原理:通过 size() 获取元素个数,遍历索引并调用 get(int index) 获取元素。
优点:支持随机访问,效率高(ArrayList 实现 RandomAccess,get() 时间复杂度 O(1));可修改索引(如跳过元素)。
缺点:代码稍繁琐,需手动管理索引。
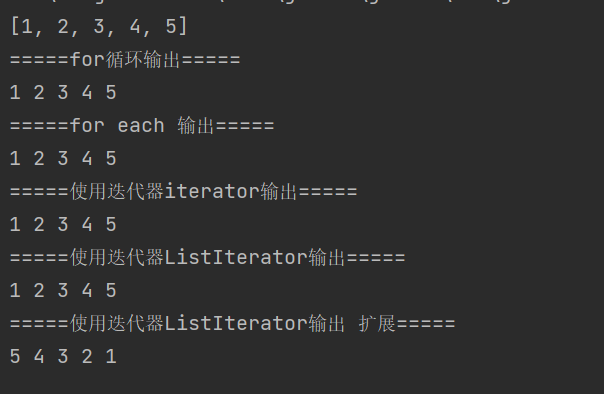
System.out.println("=====普通 for 循环=====");
int size = list.size(); // 提前获取 size,避免循环中多次调用(优化性能)
for (int i = 0; i < size; i++) {System.out.print(list.get(i) + " "); // 输出:1 2 3 4 5
}
方式 2:增强 for 循环(for-each)
原理:语法糖,底层通过 Iterator 实现,无需手动管理索引。
优点:代码简洁,不易出错,适合仅遍历不修改索引的场景。
缺点:无法获取当前索引(需手动计数);遍历中不能修改集合结构(如 add()/remove(),会抛 ConcurrentModificationException)。
System.out.println("=====for each 输出=====");
for (Integer num : list) {System.out.print(num + " "); // 输出:1 2 3 4 5
}
方式 3:Iterator 迭代器
原理:通过 list.iterator() 获取 Iterator 对象,调用 hasNext()(判断是否有下一个元素)和 next()(获取下一个元素)遍历。
优点:支持在遍历中安全删除元素(需调用 iterator.remove(),而非 list.remove())。
缺点:仅支持正向遍历,代码稍长。
System.out.println("=====使用迭代器iterator输出=====");
Iterator<Integer> iterator = list.iterator();
while (iterator.hasNext()) {Integer num = iterator.next();//意味着打印当前iterator的下一个,同时iterator往后走一步//就是在集合之外,如果判断这个迭代器的下一个存在,那么直接打印;//并且往下走一个位置(走到打印的那个位置),如果没有就不再打印System.out.print(num + " "); // 输出:1 2 3 4 5// 遍历中安全删除(示例:删除元素 2)if (num == 2) {iterator.remove(); // 需在 next() 后调用,否则抛异常}
}
System.out.println("\n删除后:" + list); // 输出:[1, 3, 4, 5]
方式 4:ListIterator 迭代器(扩展版)
原理:ListIterator 是 Iterator 的子接口,仅支持 List 集合,新增反向遍历、添加元素、修改元素等功能。 但是ListIterator比Iterator更具体,因为它可以专门打印list的内容了相当于扩展了Iterator。
优点:支持正向/反向遍历,可在遍历中修改集合(add()/set())。
缺点:仅适用于 List 集合,代码稍复杂。
System.out.println("=====使用迭代器ListIterator输出=====");
ListIterator<Integer> listIt = list.listIterator();
while (listIt.hasNext()) {System.out.print(listIt.next() + " "); // 输出:1 3 4 5
}System.out.println("=====使用迭代器ListIterator输出 扩展=====");
// 从集合末尾开始反向遍历(需先正向遍历到末尾,或传入初始索引为 list.size())
ListIterator<Integer> reverseIt = list.listIterator(list.size());
while (reverseIt.hasPrevious()) {//从后往前打印:previous表示先前的,逆序打印System.out.print(reverseIt.previous() + " "); // 输出:5 4 3 1
}
4.2 遍历方式对比表
| 遍历方式 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 普通 for 循环 | 效率高,支持索引操作 | 代码繁琐,需手动管理索引 | 需修改索引或频繁访问元素 |
| 增强 for 循环 | 代码简洁,不易出错 | 无法获取索引,遍历中不能修改集合结构 | 仅遍历,不修改集合 |
| Iterator | 支持遍历中安全删除 | 仅正向遍历 | 遍历中需删除元素 |
| ListIterator | 支持正向/反向遍历,可修改集合 | 仅适用于 List 集合,代码稍复杂 | 需反向遍历或修改元素 |