AI论文速读 | VisionTS++:基于持续预训练视觉主干网络的跨模态时间序列基础模型
论文标题: VisionTS++: Cross-Modal Time Series Foundation Model with Continual Pre-trained Visual Backbones
作者: Lefei Shen, Mouxiang Chen, Xu Liu(柳旭), Han Fu, Xiaoxue Ren(任晓雪), Jianling Sun, Zhuo Li, Chenghao Liu(刘成昊)
机构:浙江大学,新加坡国立大学(NUS),道富信息科技(浙江)有限公司,Salesforce
论文链接:https://arxiv.org/abs/2508.04379
Cool Paper:https://papers.cool/arxiv/2508.04379
代码:https://github.com/HALF111/VisionTSpp
TL;DR:针对视觉模型跨模态迁移到时间序列的三大鸿沟,提出持续预训练的VisionTS++,采用图像化多变量转换、视觉过滤与多分位数预测技术,实现多基准SOTA。
关键词:跨模态迁移、视觉基础模型、时间序列基础模型、时间序列预测、持续预训练、多分位数预测

🌟【紧跟前沿】“时空探索之旅”与你一起探索时空奥秘!🚀
欢迎大家关注时空探索之旅时空探索之旅
摘要
近期研究表明,在图像上预训练的视觉模型,通过将预测重构为图像重建任务,能够在时间序列预测中表现出色,这表明它们有可能成为通用的时间序列基础模型。然而,由于三个关键差异,从视觉到时间序列的有效跨模态迁移仍然具有挑战性:(1)结构化、有界的图像数据与无界、异构的时间序列之间的数据模态差距;(2)基于标准RGB三通道的视觉模型与对任意数量变量的时间序列进行建模的需求之间的多变量预测差距;(3)大多数视觉模型的确定性输出格式与对不确定性感知概率预测的需求之间的概率预测差距。为了弥合这些差距,我们提出了VisionTS++,这是一种基于视觉模型的时间序列基础模型(TSFM),它在大规模时间序列数据集上进行持续预训练,包括三项创新:(1)一种基于视觉模型的过滤机制,用于识别高质量的时间序列数据,从而减轻模态差距并提高预训练的稳定性;(2)一种彩色多变量转换方法,将多变量时间序列转换为多子图RGB图像,捕捉复杂的变量间依赖关系;(3)一种多分位数预测方法,使用并行重建头生成不同分位数水平的预测,从而在没有严格先验分布假设的情况下,更灵活地逼近任意输出分布。在分布内和分布外的时间序列预测基准上进行评估时,该模型取得了最先进的结果,均方误差(MSE)降低幅度比专门的时间序列基础模型高出6% - 44%,并且在12个概率预测设置中的9个中排名第一。我们的工作为跨模态知识转移建立了一种新范式,推动了通用时间序列基础模型的发展。
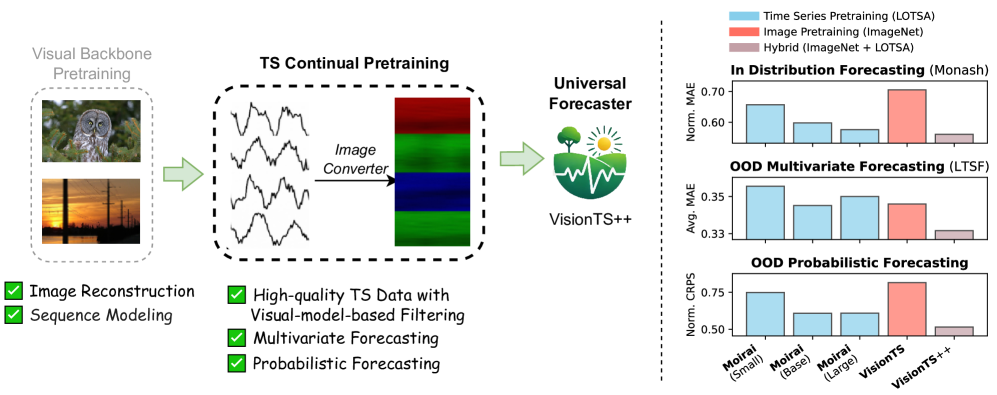
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决如何有效利用预训练的视觉模型进行时间序列预测(Time Series Forecasting, TSF)的问题。尽管已有研究表明,通过将时间序列预测任务重新表述为图像重建任务,预训练的视觉模型可以在时间序列预测中表现出色,但将视觉模型有效地迁移到时间序列领域仍面临挑战。这些挑战主要源于图像数据和时间序列数据之间的三个关键差异:
- 数据模态差距(Data-Modality Gap):图像数据是结构化且有界的,而时间序列数据是无界且异质的。
- 多变量预测差距(Multivariate-Forecasting Gap):标准的视觉模型是为具有三个颜色通道(RGB)的图像设计的,这与需要处理任意数量变量(多变量)的时间序列不匹配。
- 概率预测差距(Probabilistic-Forecasting Gap):大多数预训练的视觉模型主要关注图像像素的确定性重建或预测,而实际的时间序列预测通常需要提供预测的不确定性度量,即概率预测。
为了解决这些差距,论文提出了 VisionTS++,这是一个基于视觉模型的时间序列基础模型(Time Series Foundation Model, TSFM),通过在大规模时间序列数据集上进行持续预训练(continual pre-training),来提升视觉模型在时间序列预测任务中的性能。
Q: 有哪些相关研究?
A:
- 本文涉及的相关研究主要集中在以下几个领域:
时间序列基础模型(Time Series Foundation Models)
- Moirai [Woo et al., 2024]:一个基于编码器的时间序列基础模型,使用大规模时间序列数据进行预训练,展示了强大的零样本(zero-shot)预测能力。
- Chronos [Ansari et al., 2024]:通过将时间序列值进行缩放和量化,将其转换为固定词汇表中的标记,然后使用T5系列语言模型进行预训练。
- TimesFM [Das et al., 2024]:一个基于解码器的时间序列基础模型,使用大规模真实和合成时间序列数据进行预训练。
- Timer [Liu et al., 2024c]:一个基于解码器的时间序列基础模型,具有类似大型语言模型(LLM)的特性,如灵活的上下文长度和自回归生成能力。
视觉模型在时间序列分析中的应用
- VisionTS [Chen et al., 2024a]:将时间序列预测任务重新表述为图像重建任务,使用预训练的视觉掩码自编码器(MAE)作为骨干网络,展示了视觉模型在时间序列预测中的潜力。
- ViTime [Yang et al., 2024a]:通过将合成时间序列数据转换为折线图进行预训练,探索了视觉模型在时间序列生成、插值和外推任务中的应用。
- ImagenTime [Naiman et al., 2024]:通过将时间序列转换为图像(如通过延迟嵌入和STFT等可逆方法),利用先进的视觉扩散模型进行生成、插值和外推任务。
时间序列预测中的概率预测方法
- DeepAR [Salinas et al., 2020]:一个基于循环神经网络(RNN)的概率预测模型,能够为时间序列预测提供不确定性估计。
- Quantile Transformer [Park et al., 2022]:通过学习分位数函数来进行无分布的时间序列预测,避免了分位数交叉问题。
数据过滤与预训练
- Data Filtering Networks [Fang et al., 2023]:提出了一种数据过滤网络,用于在预训练过程中过滤低质量数据,提高模型性能。
- Vision-Language Models [Chen et al., 2024b]:在视觉-语言模型中,通过数据选择和过滤技术来提高模型的性能和泛化能力。
这些相关研究为本文提出的 VisionTS++ 模型提供了理论基础和技术支持,特别是在如何利用预训练的视觉模型进行时间序列预测以及如何处理图像和时间序列之间的模态差异方面。
Q: 论文如何解决这个问题?
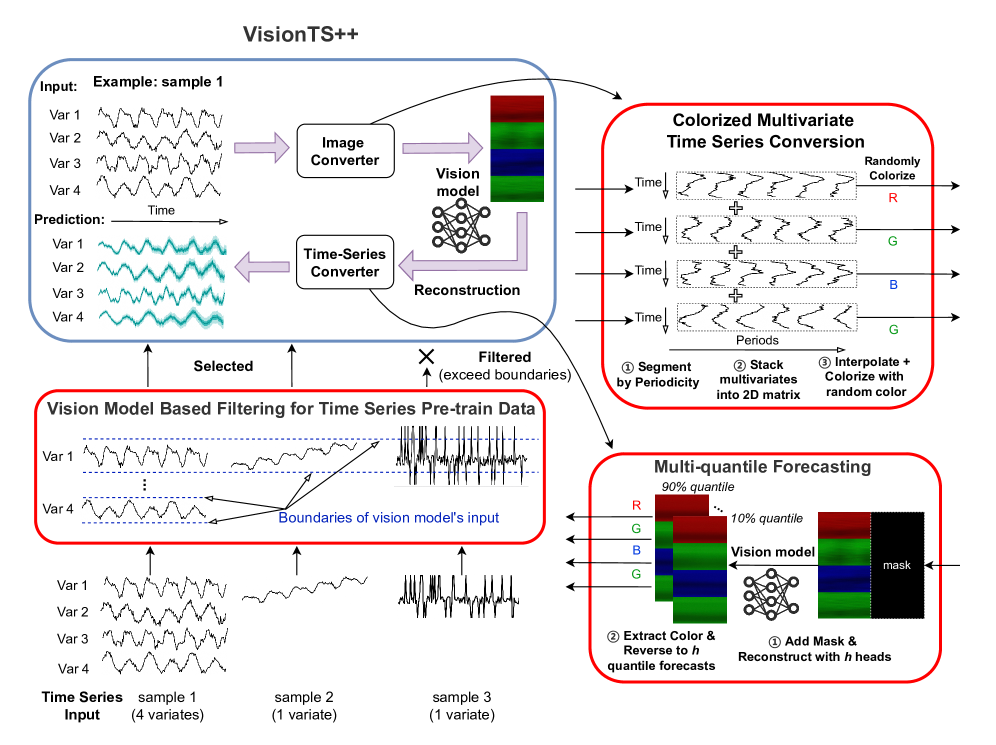
A: 论文通过提出 VisionTS++ 模型来解决如何有效利用预训练的视觉模型进行时间序列预测的问题。VisionTS++ 通过以下三个核心创新来弥合图像和时间序列之间的关键差异:
1. 视觉模型基础的过滤机制(Vision-Model-Based Filtering)
为了弥合数据模态差距,VisionTS++ 引入了一种基于视觉模型的过滤机制,用于从大规模预训练数据集中筛选出高质量的时间序列样本。具体来说,该机制利用视觉模型的输入约束来过滤掉那些转换为图像后可能超出视觉模型输入范围的时间序列样本。这一步骤显著降低了负迁移的风险,并使得持续预训练更加稳定。
2. 彩色多变量转换方法(Colorized Multivariate Conversion)
为了解决多变量预测差距,VisionTS++ 提出了一种将多变量时间序列转换为多子图 RGB 图像的方法。该方法将每个变量映射到图像的一个子图中,类似于图像中的一个对象。通过这种方式,模型可以将变量间的关系建模为子图之间的交互,这与 MAE 处理多对象图像的能力自然契合。此外,通过为每个子图随机分配不同的颜色通道,该方法还增强了变量间的分离度。
3. 多分位数预测方法(Multi-Quantile Forecasting)
为了弥合概率预测差距,VisionTS++ 采用了一种多头预测策略,通过并行重建头生成不同分位数水平的预测。这种方法将概率预测重新表述为一组点预测,更适合视觉模型处理。它充分利用了预训练的视觉知识,能够灵活地近似任意输出分布,而无需依赖于限制性的先验分布假设。
通过这些创新,VisionTS++ 在大规模时间序列数据集上进行持续预训练,有效地将视觉模型的知识迁移到时间序列预测任务中,同时保留了预训练的视觉知识。这使得 VisionTS++ 在多种时间序列预测基准测试中取得了最先进的性能。
Q: 论文做了哪些实验?
A: 论文进行了广泛的实验,以评估 VisionTS++ 在时间序列预测任务中的性能。实验涵盖了多种基准测试和与现有模型的比较。以下是实验的主要内容:
1. 实验设置
- 训练数据集:使用大规模开放时间序列存档(Large-scale Open Time Series Archive, LOTSA)数据集进行持续预训练,该数据集包含来自不同领域的超过2310亿个观测值。
- 模型架构:基于 MAE(Masked Autoencoder)架构,使用预训练的 ImageNet 权重初始化。实验中还评估了不同大小的模型变体(base、large 和 huge)。
- 训练过程:持续预训练过程运行100,000步,每步批量大小为512。使用 AdamW 优化器,学习率设置为1e-4,并采用线性预热和余弦退火的学习率调度策略。
- 评估协议:在三个关键基准测试上进行评估:Monash 时间序列预测基准、长期时间序列预测(LTSF)基准和概率预测(PF)基准。
2. 实验结果
a. 在分布内(In-distribution)预测
- Monash 时间序列预测基准:在29个数据集上进行评估,使用归一化平均绝对误差(normalized MAE)作为评估指标。VisionTS++ 在大多数情况下都取得了最佳性能,平均性能比其他基础模型和特定数据集的模型有显著提升。
[外链图片转存中…(img-WLJ2ekAw-1757744875268)]
b. 在分布外(Out-of-distribution)预测
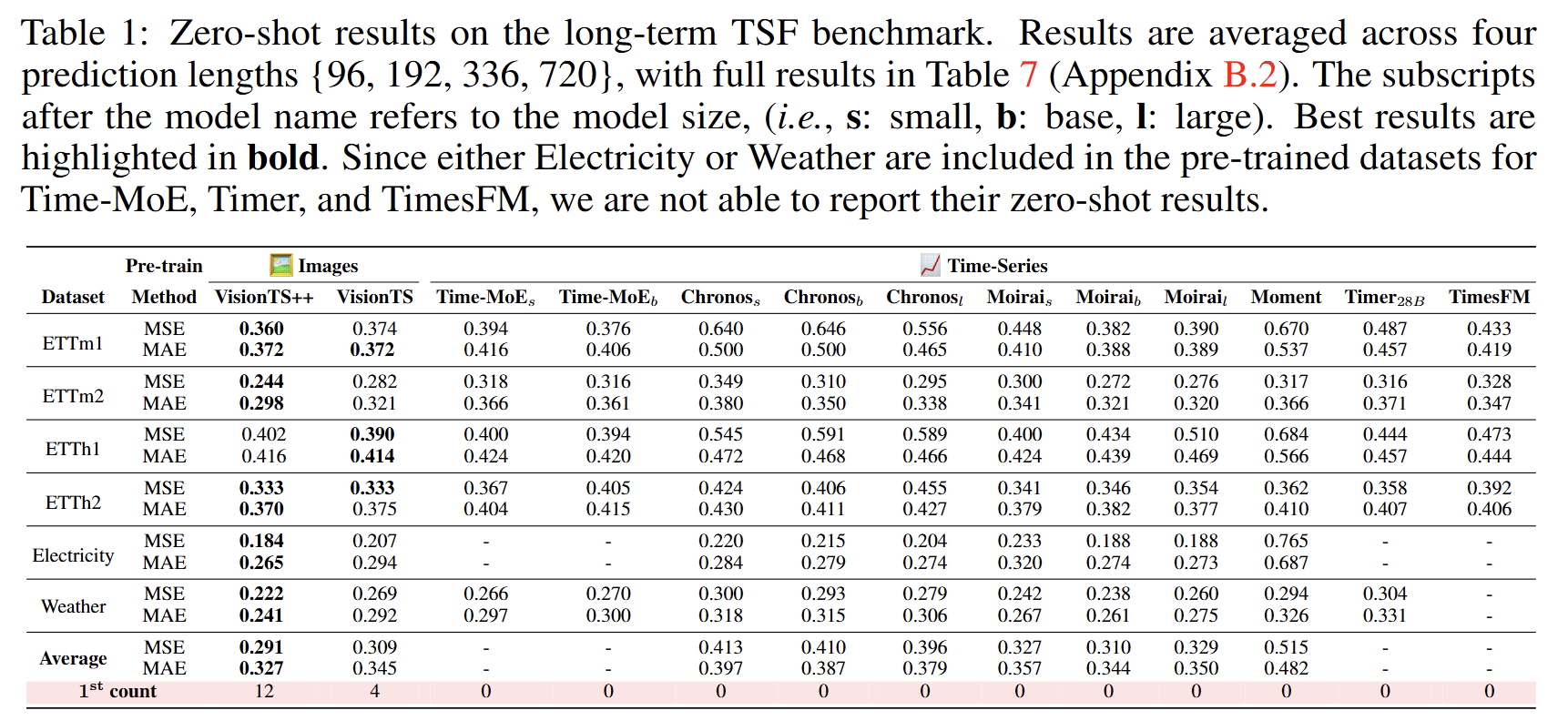
- 长期时间序列预测(LTSF)基准:在6个广泛使用的时间序列数据集上进行评估,使用均方误差(MSE)和平均绝对误差(MAE)作为评估指标。VisionTS++ 在大多数情况下都取得了最佳性能,平均性能比其他基础模型有显著提升。
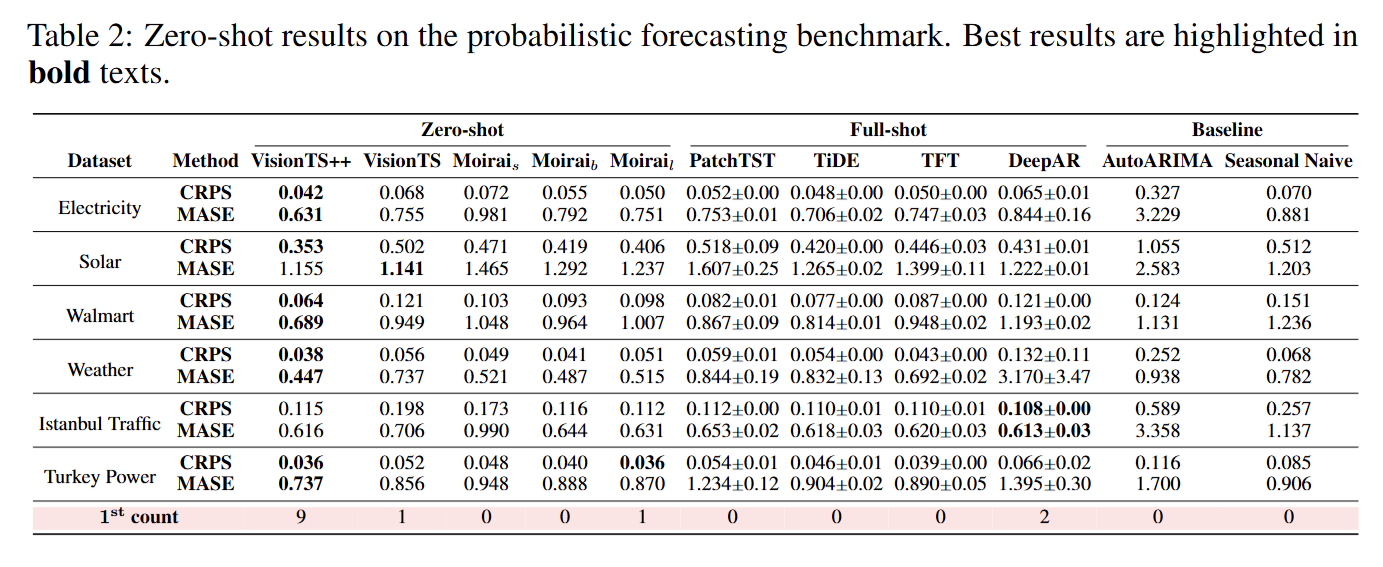
- 概率预测(PF)基准:在6个真实世界的数据集上进行评估,使用连续排序概率分数(CRPS)和平均绝对缩放误差(MASE)作为评估指标。VisionTS++ 在大多数情况下都取得了最佳性能,平均性能比其他基础模型有显著提升。
3. 进一步分析
- 随机初始化与预训练权重的比较:通过比较使用随机初始化的 MAE 骨干网络和使用预训练 ImageNet 权重的 VisionTS++ 的性能,验证了预训练权重对下游时间序列预测任务的重要性。
- 消融实验:通过移除 VisionTS++ 中的关键组件(如视觉模型基础的过滤机制、彩色多变量转换方法和多分位数预测方法),评估每个组件对模型性能的贡献。结果表明,这些组件都对模型性能有显著影响。
- 不同模型规模的比较:通过比较不同大小的 VisionTS++ 模型(base、large 和 huge)的性能,分析模型规模对时间序列预测任务的影响。结果显示,在持续预训练数据规模和训练周期保持不变的情况下,增加模型容量对下游时间序列预测任务的性能提升有限。
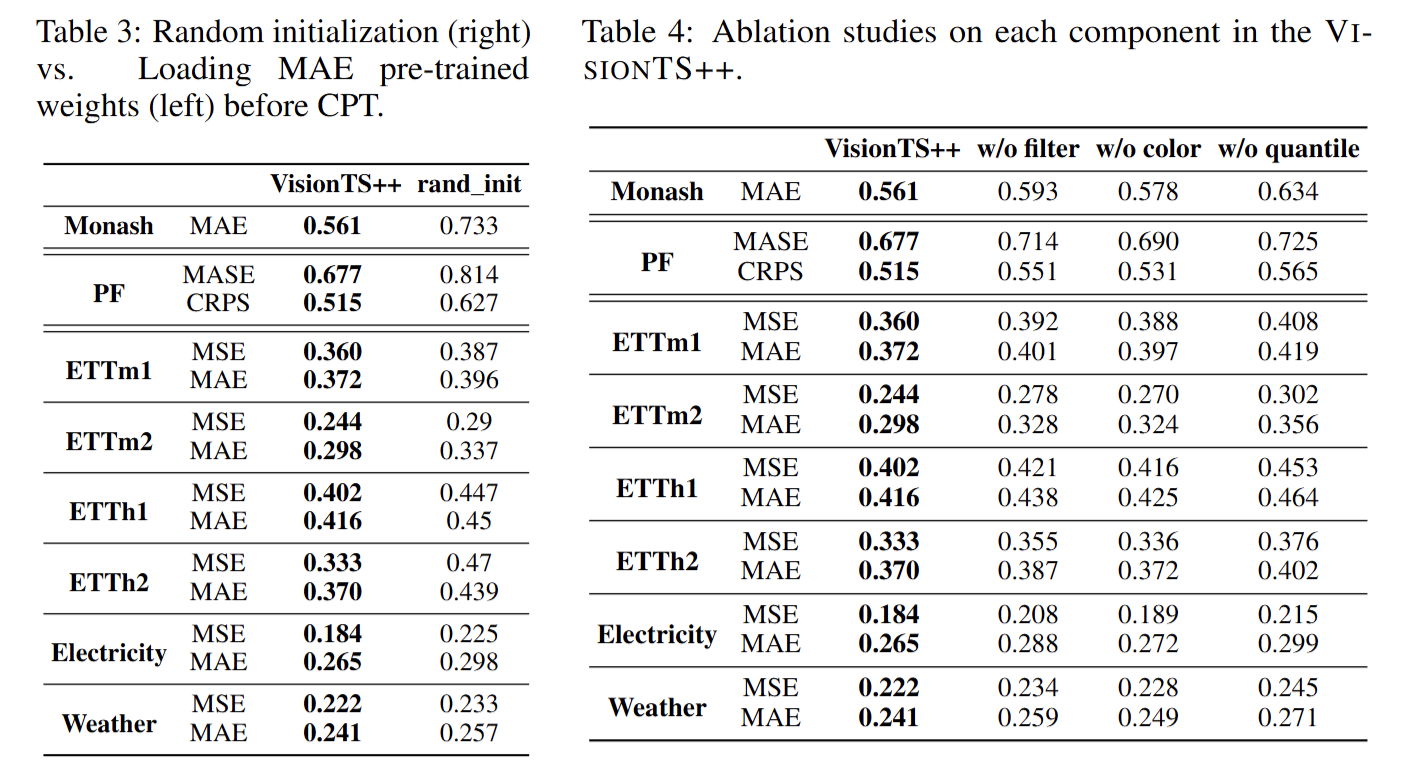

这些实验结果表明,VisionTS++ 在时间序列预测任务中具有强大的性能和泛化能力,能够有效地将视觉模型的知识迁移到时间序列领域。
附录中有更加详细的实验结果和分析,阅读原文获取详细的信息。
vUgU-1757744875269)]
这些实验结果表明,VisionTS++ 在时间序列预测任务中具有强大的性能和泛化能力,能够有效地将视觉模型的知识迁移到时间序列领域。
附录中有更加详细的实验结果和分析,阅读原文获取详细的信息。
🌟【紧跟前沿】“时空探索之旅”与你一起探索时空奥秘!🚀
欢迎大家关注时空探索之旅时空探索之旅