(综述)视觉任务的视觉语言模型
论文题目:Vision-Language Models for Vision Tasks: A Survey(视觉任务的视觉语言模型:综述)
期刊:IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE(TPAMI)
摘要:大多数视觉识别研究严重依赖于深度神经网络(DNN)训练中的众标数据,并且他们通常为每个单独的视觉识别任务训练一个DNN,这导致了一个费力且耗时的视觉识别范式。为了解决这两个挑战,视觉语言模型(VLM)最近得到了深入的研究,它从互联网上几乎无限可用的网络规模的图像-文本对中学习丰富的视觉语言相关性,并使用单个VLM对各种视觉识别任务进行零样本学习预测。本文对各种视觉识别任务的视觉语言模型进行了系统的综述,包括:(1)介绍了视觉识别范式发展的背景;(2) VLM的基础,总结了广泛采用的网络架构、预训练目标和下游任务;(3) VLM预训练和评估中广泛采用的数据集;(4)对现有VLM预训练方法、VLM迁移学习方法和VLM知识蒸馏方法进行了回顾和分类;(5)对审查的方法进行对标、分析和讨论;(6)未来视觉识别领域VLM研究面临的几个研究挑战和可能的研究方向。
引言
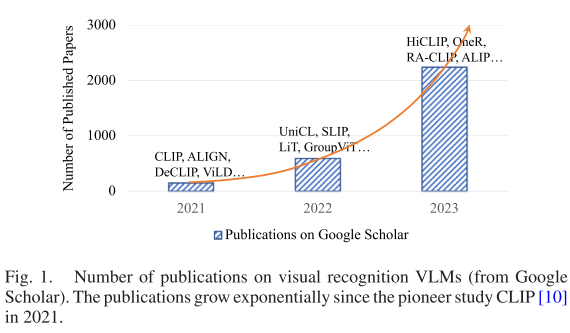
在人工智能快速发展的今天,一个革命性的技术范式正在重塑计算机视觉领域——视觉语言模型(Vision-Language Models, VLMs)。近日,一篇发表在IEEE顶级期刊TPAMI上的综述论文《Vision-Language Models for Vision Tasks: A Survey》为我们全面梳理了这一前沿领域的发展脉络和未来方向。从2021年CLIP的开创性工作开始,VLM相关发表论文数量呈指数级增长,这一趋势清晰地表明了该领域的重要性和活跃程度。
传统视觉识别方法的演进与困境
五个发展阶段的历史脉络
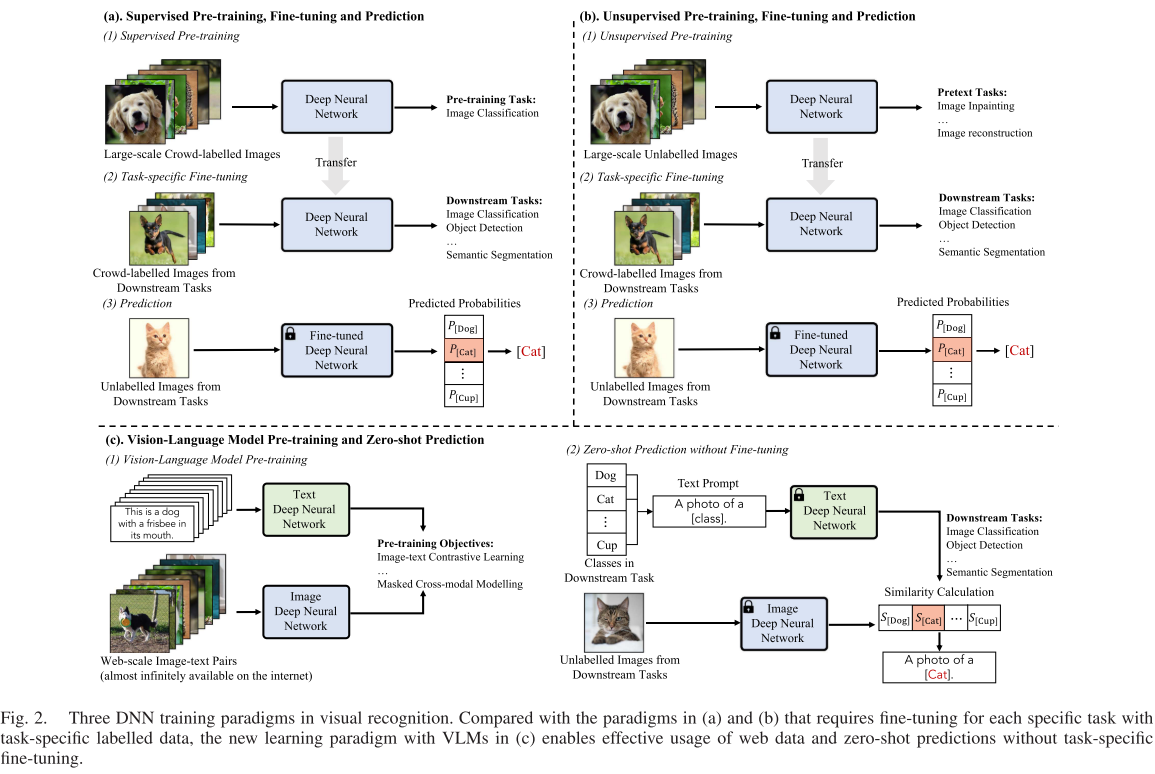
论文系统梳理了视觉识别训练范式的发展历程,将其划分为五个关键阶段:
1. 传统机器学习与预测阶段
在深度学习时代之前,视觉识别研究严重依赖手工特征工程,如SIFT、HOG等特征描述子,配合轻量级学习模型如SVM、随机森林等进行分类。这种方法的局限性显而易见:需要领域专家为特定任务精心设计特征,难以处理复杂任务且可扩展性差。
2. 深度学习从头训练阶段
深度学习的兴起彻底改变了特征学习方式。以ResNet为代表的端到端可训练深度神经网络通过跳跃连接解决了梯度消失问题,使得在ImageNet等大规模数据集上训练非常深的网络成为可能。然而,这种方法面临两个根本挑战:DNN训练收敛缓慢,以及对大规模标注数据的严重依赖。
3. 有监督预训练-微调-预测阶段
为了缓解从头训练的问题,研究者发现在大规模标注数据集(如ImageNet)上预训练的特征可以有效迁移到下游任务。这种范式通过预训练学习通用视觉知识,然后在特定任务数据上微调,显著加速了网络收敛并提升了性能。
4. 无监督预训练-微调-预测阶段
为了进一步减少对标注数据的依赖,自监督学习方法如对比学习(SimCLR、MoCo)和掩码图像建模(MAE)应运而生。这些方法通过设计预训练任务从无标注数据中学习有用的表征,然后在下游任务上进行微调。
5. 视觉语言模型预训练与零样本预测阶段
这是当前最前沿的范式,VLM通过学习大规模图像-文本对的关联性,获得了在无需任务特定微调情况下直接进行零样本预测的能力。这种范式的革命性在于它彻底摆脱了微调阶段的束缚。
传统方法面临的核心挑战
数据标注的重负担
传统深度学习方法对大规模人工标注数据的严重依赖构成了巨大挑战。ImageNet数据集虽然只包含100万张图像,但其标注工作却耗费了数年时间。更为严重的是,每个新的视觉任务都需要重新收集和标注大量数据,这种成本在实际应用中往往是不可承受的。
任务特定的孤岛效应
每个视觉识别任务(图像分类、目标检测、语义分割等)都需要单独训练专门的模型,导致严重的资源浪费和知识割裂。这种现象被称为"任务孤岛",它不仅增加了训练成本,还阻碍了跨任务知识的有效利用。
计算资源的巨大消耗
从零开始训练深度神经网络不仅收敛缓慢,还需要消耗大量计算资源。即使采用预训练-微调的策略,仍然需要为每个下游任务进行专门的微调过程,这在面对众多下游应用时会导致计算成本的线性增长。
视觉语言模型的技术革命
核心理念的根本性转变
VLM代表了从"任务特定学习"到"通用表征学习"的根本性转变。这种转变的核心在于三个关键要素:
大数据的有效利用:VLM充分利用了互联网上几乎无限的图像-文本对数据。与传统的人工标注数据不同,这些数据天然存在于网络上,成本极低且规模巨大。例如,LAION-5B数据集包含58亿个图像-文本对,规模是ImageNet的5800倍。
大模型的表征能力:VLM通常采用比传统视觉模型更大的网络架构。例如,COCA中的ViT-G模型包含20亿参数,为有效学习大规模数据提供了充足的模型容量。
任务无关的学习目标:与传统的任务特定监督信号不同,VLM采用通用的视觉-语言关联学习目标,使得单一模型能够处理多种下游任务。
VLM发展的三个维度
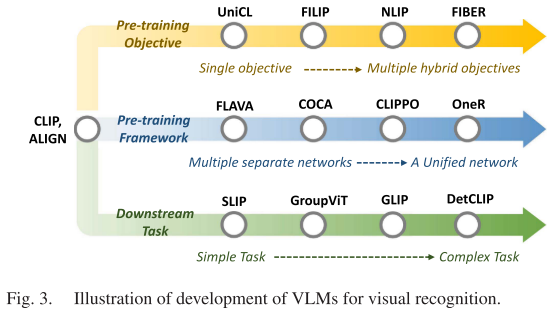
论文深入分析了VLM的技术演进轨迹,主要体现在三个维度:
预训练目标的多样化演进
- 早期阶段:以CLIP为代表,主要采用单一的图像-文本对比学习目标
- 中期发展:引入多种目标的组合,如FLAVA同时采用对比学习、掩码图像建模和掩码语言建模
- 当前趋势:探索对比、生成和对齐目标的协同作用,追求更鲁棒的多模态表征
网络架构的统一化趋势
- 双塔架构时代:CLIP、ALIGN等采用独立的图像编码器和文本编码器
- 双腿架构探索:FLAVA、FIBER等引入跨模态融合层,增强模态间交互
- 单塔架构展望:PaLI、PIXEL等尝试统一的多模态编码器,追求更高效的跨模态通信
下游任务的复杂化拓展
- 图像级任务起步:早期VLM主要关注图像分类、图像-文本检索等图像级任务
- 区域级任务探索:GLIP、DetCLIP等开始处理目标检测等需要区域定位的任务
- 像素级任务突破:SegCLIP、GroupViT等实现了语义分割等密集预测任务
技术架构的深度解析
网络架构设计
图像特征学习架构
CNN架构的持续演进:
- ResNet变体:CLIP采用了改进版ResNet,引入ResNet-D设计、反混叠池化和注意力池化机制
- EfficientNet适配:部分VLM采用EfficientNet作为图像编码器,通过复合缩放实现效率和性能的平衡
Transformer架构的主导地位:
- 标准ViT:将图像切分为固定大小的patch,通过线性投影和位置编码后输入Transformer编码器
- 改进版本:CLIP等在ViT基础上增加了归一化层,提升训练稳定性
文本特征学习架构
VLM中的文本编码器主要基于Transformer架构及其变体:
- 标准Transformer:采用6层编码器-解码器结构,每层包含多头自注意力和前馈网络
- GPT风格适配:大多数VLM采用类似GPT的单向语言模型结构,支持从头训练
- BERT风格集成:部分方法集成双向编码器,增强文本理解能力
预训练目标的技术细节
对比学习目标家族
图像对比学习: VLM中的图像对比学习旨在学习判别性的图像特征表示。以InfoNCE损失为核心:
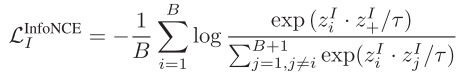
其中z_i^I表示查询图像嵌入,z_+^I表示正样本嵌入,τ为温度超参数。
图像-文本对比学习: 这是VLM的核心学习目标,通过对称的InfoNCE损失建模图像-文本关联:
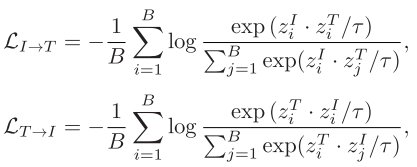
最终损失为L_IT = L_I→T + L_T→I。
图像-文本-标签对比学习: UniCL提出的三元对比学习将分类标签引入对比框架:
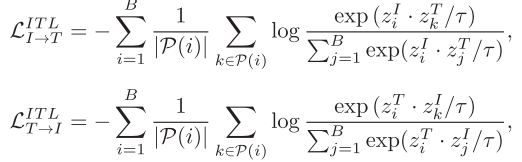
其中P(i) = {k | k ∈ B, y_k = y_i}表示与样本i同类的样本集合。
生成式目标设计
掩码图像建模: 借鉴NLP中掩码语言建模的思想,随机遮挡图像块并训练模型重建:
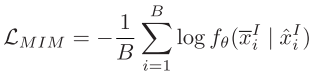
其中x_i^I和x̂_i^I分别表示被遮挡和未遮挡的图像块。
掩码语言建模:
在文本模态应用类似策略,随机遮挡15%的词汇并预测:
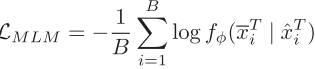
掩码跨模态建模: FLAVA提出的联合掩码策略,同时遮挡图像块和文本词汇:
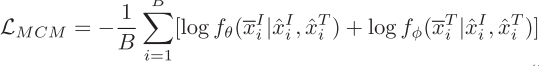
图像到文本生成: 训练模型基于图像自回归生成描述文本:
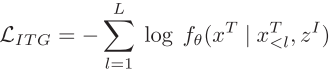
其中L为文本序列长度,z^I为图像嵌入。
对齐目标机制
全局图像-文本匹配: 通过二分类任务判断图像-文本对是否匹配:
![]()
其中p∈{0,1}表示匹配标签,S(·)为相似性度量函数。
局部区域-词汇匹配: 对于密集预测任务,建模图像区域与文本词汇的细粒度对应:
![]()
其中r^I表示图像区域,w^T表示文本词汇。
预训练框架比较
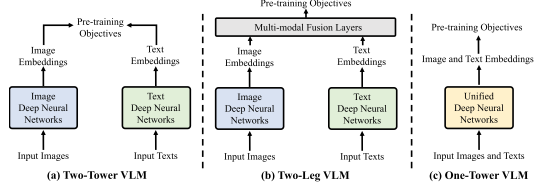
双塔框架的设计哲学
双塔框架采用两个独立的编码器分别处理图像和文本,具有以下特点:
- 并行处理:图像和文本可以并行编码,计算效率高
- 模态独立:每个模态保持相对独立的表征空间
- 易于扩展:可以方便地替换单模态编码器
双腿框架的融合策略
双腿框架在双塔基础上增加多模态融合层:
- 渐进融合:通过多层跨注意力机制逐步融合多模态信息
- 计算权衡:在表征能力和计算复杂度间寻求平衡
- 灵活设计:可以选择性地在不同层次进行模态交互
单塔框架的统一愿景
单塔框架使用统一编码器处理多模态输入:
- 统一表征:在同一表征空间中处理不同模态
- 高效通信:模态间交互更加直接和高效
- 内存优化:相比双塔框架显著减少GPU内存使用
数据资源的全景分析
预训练数据集概览
论文详细分析了VLM预训练中使用的大规模图像-文本数据集,这些数据集的规模和质量直接影响VLM的性能:
Web规模数据集:
- LAION-400M:包含4亿个图像-文本对,通过CLIP过滤确保质量
- LAION-5B:规模扩展至58亿对,是目前最大的开放数据集
- CC3M/CC12M:Conceptual Captions系列,提供高质量的图像描述
- YFCC100M:从Flickr收集的1亿个多媒体文件
- RedCaps:1200万个Reddit图像-文本对,注重多样性和包容性
专业数据集:
- Visual Genome:提供密集的视觉场景图标注
- Localized Narratives:包含详细的空间定位描述
- Objects365:用于区域级特征学习的辅助数据
评估数据集体系
论文总结了VLM评估中使用的40个数据集,涵盖多种视觉任务:
图像分类数据集(27个):
- 通用分类:ImageNet、CIFAR-10/100等经典基准
- 细粒度分类:Stanford Cars(汽车识别)、Oxford-IIIT Pet(宠物分类)、FGVCAircraft(飞机分类)
- 场景理解:SUN397(场景分类)、EuroSAT(遥感场景)
- 特殊领域:Hateful Memes(有害内容检测)、PatchCamelyon(医学图像)
目标检测数据集(4个):
- COCO:通用目标检测的标准基准
- LVIS:大词汇量实例分割数据集
- OpenImages:开放域目标检测
- Objects365:365类目标检测
语义分割数据集(4个):
- PASCAL VOC:经典分割基准
- PASCAL Context:包含丰富上下文信息
- Cityscapes:城市街景分割
- ADE20K:场景解析数据集
其他任务数据集:
- 图像-文本检索:Flickr30K、MSCOCO
- 动作识别:UCF101、Kinetics、RareAct
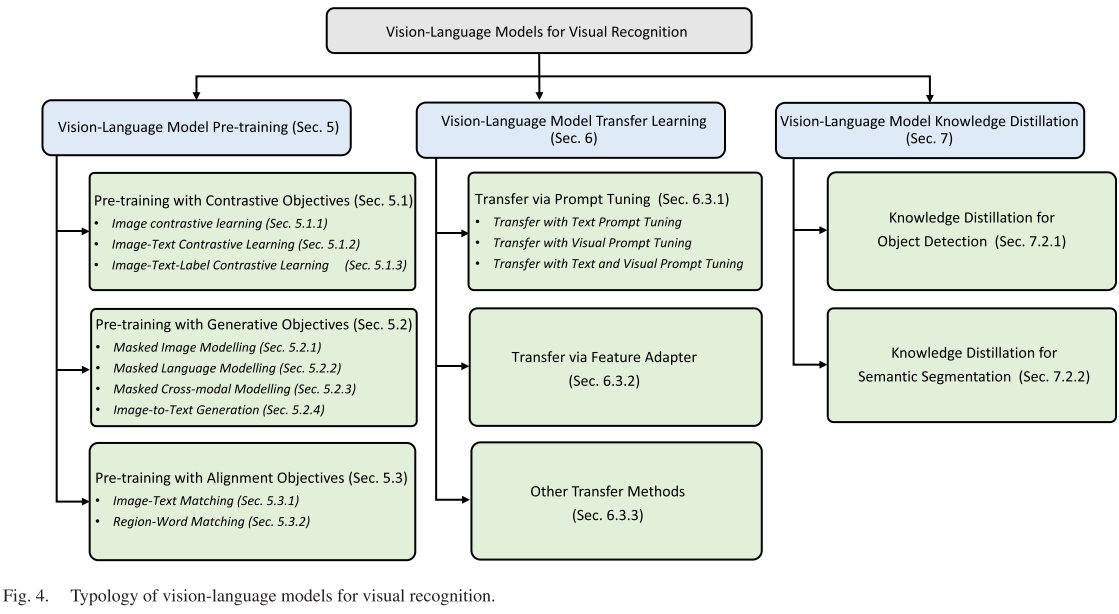
VLM预训练方法的系统分类
基于对比学习的方法族
CLIP及其影响
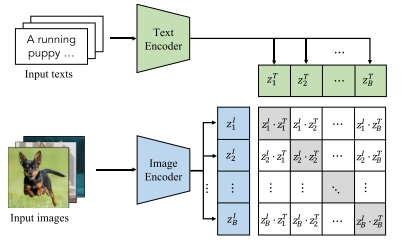
CLIP作为开创性工作,确立了图像-文本对比学习的基本范式。其核心创新在于:
- 大规模训练:在4亿图像-文本对上训练
- 零样本泛化:无需微调即可应用于多种下游任务
- 提示工程:通过"a photo of a [class]"等模板实现零样本分类
规模化改进方向
ALIGN的规模突破:
- 数据规模:使用18亿嘈杂图像-文本对
- 噪声鲁棒性:设计噪声鲁棒的对比学习策略
- 性能提升:在多个基准上超越CLIP
数据高效方法:
- DeCLIP:通过最近邻监督减少所需训练数据
- OTTER:使用最优传输理论进行伪配对,大幅减少数据需求
- ZeroVL:通过去偏数据采样和数据增强实现高效训练
细粒度对应建模
FILIP的创新:
- 细粒度对齐:建模图像patch与文本token的对应关系
- 跨级别对比:在全局和局部层面同时进行对比学习
- 性能一致性:在多个任务上展现稳定的性能表现
PyramidCLIP的层次化方法:
- 多语义层次:构建多个语义抽象级别
- 跨层对比:在不同抽象层次间进行对比学习
- 层次一致性:确保不同层次表征的一致性
基于生成的方法族
掩码建模方法
图像掩码建模的应用:
- FLAVA:采用BeiT风格的块掩码策略
- KELIP和SegCLIP:遵循MAE的高比例掩码(75%)
- 掩码策略:从随机掩码到结构化掩码的演进
语言掩码建模的集成:
- BERT风格应用:掩码15%的文本token
- 跨词关系建模:学习词汇间的语义依赖
- 多模态一致性:与图像表征保持语义一致
跨模态生成方法
COCA的生成式框架:
- 编码器-解码器架构:结合对比学习和生成学习
- 自回归生成:训练模型生成图像描述
- 双重优化:同时优化判别和生成目标
其他生成方法:
- NLIP:噪声鲁棒的语言-图像预训练
- PaLI:大规模多语言语言-图像模型
基于对齐的方法族
全局对齐策略
- 二分类框架:将图像-文本匹配建模为二分类任务
- 相似性函数设计:从点积到复杂的神经网络
- 负样本挖掘:FIBER采用困难负样本挖掘策略
局部对齐机制
GLIP的区域-词汇对齐:
- 检测预训练:将目标检测融入VLM预训练
- 区域提取:使用区域提议网络提取候选区域
- 细粒度匹配:建模图像区域与文本词汇的精确对应
DetCLIP的字典增强:
- 概念并行化:引入视觉概念字典
- 开放词汇检测:支持任意类别的目标检测
- 知识蒸馏:从预训练VLM向检测器传递知识
迁移学习策略的深度剖析

提示学习方法论
文本提示调优的技术细节
CoOp的上下文优化:
- 可学习上下文:将类别名嵌入可学习的上下文向量中
- 优化目标:最小化分类损失来学习最优提示
- 模板设计:从"[V₁] [V₂] ... [Vₘ] [CLASS]"学习上下文
CoCoOp的条件化改进:
- 实例特定提示:为每个输入图像生成特定的提示
- 元网络设计:使用轻量级网络生成条件化上下文
- 泛化性提升:缓解固定提示的过拟合问题
SubPT的子空间约束:
- 子空间投影:将提示学习约束在低维子空间中
- 正则化机制:防止提示向量偏离预训练表征流形
- 稳定性增强:提高少样本设置下的学习稳定性
视觉提示调优的探索
VP的像素级扰动:
- 可学习扰动:在输入图像上添加可学习的像素级扰动
- 优化策略:通过梯度下降直接优化扰动参数
- 适应机制:实现像素级别的任务特定适应
RePrompt的检索增强:
- 检索机制:从训练集中检索相似样本
- 提示生成:基于检索结果生成任务特定提示
- 知识利用:充分利用训练样本中的任务知识
多模态提示调优
UPT的统一框架:
- 联合优化:同时优化文本和视觉提示
- 互补性:发挥两种模态提示的互补作用
- 协同效应:通过多模态提示实现更好的任务适应
MVLPT的多任务扩展:
- 跨任务知识:在多个任务间共享和传递提示知识
- 任务特定性:为每个任务保留特定的提示参数
- 知识整合:有效整合多任务学习收益
特征适配器方法
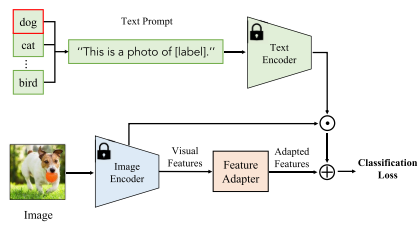
Clip-Adapter的设计理念
- 轻量级适配:在CLIP编码器后插入简单的线性层
- 参数冻结:保持原始CLIP参数不变
- 高效训练:只需训练少量适配器参数
Tip-Adapter的免训练策略
- 零训练成本:直接使用少样本标注图像作为适配器权重
- 缓存机制:构建特征缓存进行快速推理
- 即插即用:无需额外训练即可提升性能
SVL-Adapter的自监督增强
- 双重编码器:结合监督编码器和自监督编码器
- 表征融合:整合多种表征信息
- 鲁棒性提升:通过自监督学习增强表征鲁棒性
其他迁移方法
WiseFT的权重插值
- 模型平均:在微调模型和原始模型间进行权重插值
- 知识保持:避免微调过程中的灾难性遗忘
- 性能平衡:在新任务适应和原有能力保持间取得平衡
MaskCLIP的架构修改
- 密集特征提取:修改CLIP图像编码器以提取密集特征
- 分割适配:专门针对语义分割任务的架构调整
- 像素级预测:实现从图像级到像素级的能力扩展
知识蒸馏技术的应用深化
目标检测中的知识传递
ViLD的开创性工作
ViLD首次系统性地将VLM知识蒸馏到目标检测任务:
- 特征对齐:强制检测器的嵌入空间与CLIP图像编码器一致
- 开放词汇能力:利用CLIP的丰富词汇知识扩展检测器类别
- 两阶段框架:基于Faster R-CNN的区域提议和分类
层次化知识蒸馏方法
HierKD的多级策略:
- 全局-局部对应:在图像级和区域级同时进行知识蒸馏
- 层次一致性:确保不同粒度特征的语义一致性
- 渐进优化:从粗粒度到细粒度的渐进式优化策略
RKD的区域基础方法:
- 区域级对齐:专注于图像区域与整体图像的特征对齐
- 上下文建模:考虑区域间的空间关系和上下文信息
- 检测性能:在多个检测基准上显著提升性能
提示学习与检测结合
DetPro的检测提示技术:
- 连续提示表征:学习用于开放词汇检测的连续提示
- 区域-文本对齐:建立检测区域与文本描述的精确对应
- 端到端优化:在检测框架内直接优化提示参数
PromptDet的区域提示学习:
- 区域特定提示:为不同检测区域生成特定的提示表征
- 词嵌入对齐:将区域特征与词嵌入空间对齐
- 零样本检测:实现真正的零样本目标检测能力
语义分割中的知识应用
开放词汇分割方法
LSeg的像素-文本对齐:
- 像素级嵌入:将每个像素映射到语言嵌入空间
- CLIP文本编码器:利用CLIP强大的文本理解能力
- 相关性最大化:最大化像素嵌入与对应文本嵌入的相关性
CLIPSeg的轻量化设计:
- Transformer解码器:在CLIP基础上添加轻量级解码器
- 文本条件分割:根据文本描述进行条件化分割
- 计算效率:在保持性能的同时显著降低计算复杂度
弱监督分割应用
CLIP-ES的激活图细化:
- 类激活图:利用CLIP生成高质量的类激活图
- Softmax归一化:设计专门的softmax函数处理多类别
- 注意力机制:引入类感知注意力模块缓解类别混淆
CLIMS的跨语言匹配:
- 跨语言监督:利用不同语言的描述进行弱监督学习
- 多语言一致性:确保不同语言描述的语义一致性
- 知识增强:通过跨语言信息增强分割质量
伪标签生成策略
VLM引导的伪标签
PB-OVD的伪边界框生成:
- VLM预测边界框:使用VLM为图像生成伪标注边界框
- 质量过滤:设计置信度阈值过滤低质量预测
- 迭代改进:通过迭代训练逐步提升伪标签质量
XPM的跨模态伪标签:
- 鲁棒性策略:设计鲁棒的跨模态伪标签生成策略
- 掩码预测:生成实例分割的伪掩码标注
- 开放词汇实例分割:扩展到开放词汇实例分割任务
性能评估与基准分析
零样本性能的全面评估
图像分类任务表现
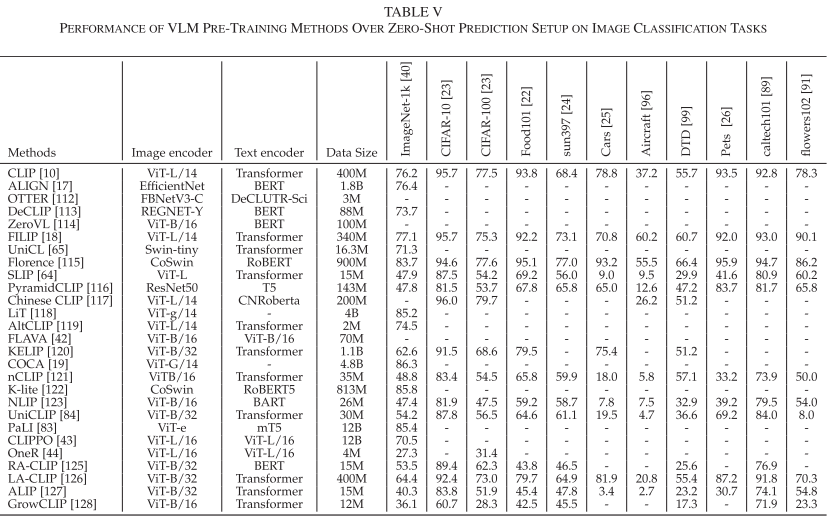
根据论文提供的详细实验结果,VLM在图像分类任务上展现出强大的零样本能力:
ImageNet基准表现:
- CLIP ViT-L/14:达到76.2%的top-1准确率
- ALIGN EfficientNet-L2:实现76.4%的性能
- COCA ViT-G:在使用更大模型后达到更优性能
- FILIP:通过细粒度对齐实现一致的高性能
细粒度分类任务: 在Stanford Cars、Oxford-IIIT Pet等细粒度分类任务上,VLM展现出比传统方法更强的泛化能力:
- Stanford Cars:从传统方法的约60%提升到CLIP的77.5%
- Oxford-IIIT Pet:达到93.5%的高准确率
- FGVCAircraft:在飞机分类任务上实现36.9%的性能
特殊域任务适应:
- EuroSAT:在遥感图像分类上达到69.2%
- PatchCamelyon:医学图像分类任务表现出色
- Hateful Memes:多模态有害内容检测展现潜力
目标检测任务分析
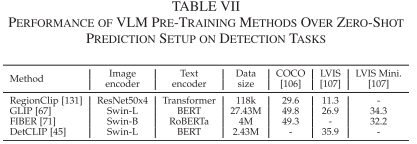
VLM在目标检测任务上的表现相对有限,但仍显示出显著的开放词汇能力:
COCO数据集表现:
- GLIP-T:在COCO上实现49.8 mAP的零样本性能
- DetCLIP:通过字典增强达到竞争性能
- FIBER:在多个检测基准上展现一致性
LVIS长尾检测:
- 开放词汇优势:VLM在长尾类别检测上显著优于传统方法
- 词汇扩展能力:能够检测训练时未见过的类别
- 实用价值:在实际应用中具有重要意义
语义分割任务评估
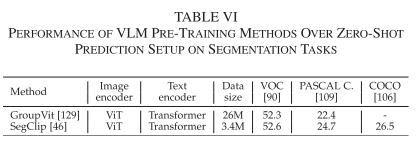
PASCAL VOC表现:
- GroupViT:实现52.3%的零样本mIoU
- SegCLIP:通过聚合学习达到更好性能
- 像素级理解:展现了像素级语义理解能力
城市场景分割:
- Cityscapes:在城市街景分割上展现实用潜力
- 语义一致性:保持语义类别的一致性理解
- 复杂场景处理:能够处理复杂的城市场景
规模法则的深入验证
数据规模效应分析
论文通过大量实验验证了VLM性能随数据规模的变化规律:
线性对数关系:
- 400M到5B:性能随数据规模呈现对数线性增长
- 收益递减:当数据规模达到一定程度后,性能提升放缓
- 质量重要性:高质量数据比单纯的数量更加重要
不同任务的敏感性:
- 图像分类:对数据规模最为敏感
- 细粒度任务:需要更大规模的数据支持
- 域特定任务:受领域相关数据比例影响
模型规模效应研究
参数量与性能关系:
- ViT-B vs ViT-L:从8600万参数到3.07亿参数,性能显著提升
- ViT-L vs ViT-G:继续扩大到20亿参数,性能持续改善
- 计算效率权衡:需要在性能和计算成本间取得平衡
架构设计的影响:
- 深度vs宽度:深度和宽度对性能的影响存在差异
- 注意力机制:多头注意力的头数对性能有重要影响
- 激活函数:不同激活函数对大规模模型的影响
迁移学习性能深度分析
有监督迁移学习效果
全量数据微调: 在有完整标注数据的情况下,VLM迁移学习表现出色:
- ImageNet:WiseFT达到87.1%,超越零样本10.9%
- CIFAR-100:迁移学习实现显著性能提升
- 域适应:在跨域任务上展现强大的适应能力
计算成本分析:
- 微调时间:相比从头训练减少60-80%的训练时间
- GPU资源:显著降低GPU小时消耗
- 收敛稳定性:具有更好的训练稳定性
少样本学习表现
Few-shot设置分析: 在1-shot到16-shot的设置下:
- CoOp方法:16-shot设置下平均提升1.7%
- CoCoOp改进:进一步提升泛化性能
- 跨任务一致性:在多个任务上保持一致的改进
样本效率比较:
- 传统方法:需要大量样本才能达到可接受性能
- VLM方法:仅需少量样本即可实现显著提升
- 实际应用价值:在标注数据稀缺场景下具有重要价值
无监督迁移探索
测试时适应:
- TPT方法:在测试时进行提示调优,提升0.8%
- 单样本适应:能够基于单个测试样本进行适应
- 无标注优势:完全不需要下游任务的标注数据
自训练策略:
- UPL方法:通过伪标签进行无监督提示学习
- 置信度过滤:设计策略过滤低质量伪标签
- 迭代改进:通过多轮迭代提升性能
知识蒸馏效果评估
目标检测蒸馏性能
开放词汇检测提升:
- ViLD:在LVIS数据集上实现显著的AP提升
- HierKD:通过层次化蒸馏进一步改进
- 实用性验证:在实际检测任务中展现价值
计算效率分析:
- 推理速度:相比直接使用VLM显著提升推理速度
- 内存占用:大幅降低内存需求
- 部署友好:更适合实际部署应用
语义分割蒸馏效果
像素级知识传递:
- LSeg:在ADE20K上实现competitive的性能
- 分割质量:在保持速度的同时提升分割质量
- 类别扩展:支持更广泛的分割类别
弱监督分割应用:
- CLIP-ES:仅使用图像级标注实现像素级分割
- 标注效率:大幅减少分割标注工作量
- 实际应用:在标注成本敏感的场景中具有价值
面临的挑战与技术瓶颈
当前方法的固有局限
性能饱和问题
随着模型和数据规模的持续增长,VLM面临明显的性能饱和现象:
- 收益递减规律:当训练数据超过一定规模后,性能提升显著放缓
- 计算成本激增:为了获得边际性能提升,需要付出指数级的计算成本
- 架构瓶颈:现有架构设计可能已接近其理论上限
密集预测任务发展滞后
相比图像分类的巨大成功,VLM在密集预测任务上的表现仍显不足:
- 空间定位能力:缺乏精确的空间定位和边界识别能力
- 细粒度理解:难以建模像素级别的语义关联
- 上下文建模:在复杂场景理解中存在明显短板
计算资源需求巨大
大规模VLM的训练和部署面临严峻的资源挑战:
- 训练成本:CLIP ViT-L需要256个V100 GPU训练288小时
- 碳排放:大规模训练产生巨量碳排放,环境影响显著
- 资源门槛:高昂的计算成本限制了研究参与者范围
技术挑战的深层分析
多模态对齐的复杂性
视觉和语言模态间的本质差异带来对齐挑战:
- 表征空间差异:视觉特征的连续性与文本特征的离散性
- 语义粒度不匹配:图像的像素级信息与文本的概念级信息
- 时序关系建模:难以处理复杂的时空关系
知识表示的局限性
当前VLM的知识表示方式存在根本性局限:
- 隐式知识存储:知识以隐式方式存储在参数中,难以解释和调试
- 知识冲突:不同来源的知识可能存在冲突,缺乏有效解决机制
- 知识更新困难:难以增量式更新和修正已学习的知识
泛化能力的边界
尽管VLM展现出强大的泛化能力,但仍存在明确边界:
- 域外泛化:在与训练分布差异较大的域上性能下降明显
- 长尾类别:对低频类别的识别能力仍然不足
- 组合理解:难以理解训练时未见过的概念组合
数据与标注挑战
数据质量问题
网络规模数据的质量问题严重影响VLM性能:
- 噪声标注:网络爬取的图像-文本对存在大量噪声
- 偏见传播:数据中的社会偏见会被模型学习和放大
- 版权争议:使用网络数据面临版权和伦理问题
评估基准限制
现有评估基准的局限性阻碍了技术进步:
- 基准过时:部分基准数据集已被大规模预训练数据污染
- 任务局限:现有基准主要关注传统视觉任务,缺乏新兴应用评估
- 评估指标:现有指标可能无法全面反映模型的真实能力
未来发展的九大方向
1. 细粒度视觉语言关联建模
技术发展需求
当前VLM主要建模图像-文本的全局对应关系,但实际应用中需要更精细的局部对应能力:
- 区域-词汇对应:建立图像区域与文本词汇的精确映射关系
- 属性-视觉特征匹配:将文本中的属性描述与视觉特征关联
- 关系建模:理解和表示对象间的空间和语义关系
潜在研究方向
- 注意力机制改进:设计更精细的跨模态注意力机制
- 图结构建模:利用图神经网络建模复杂的视觉语言关系
- 层次化表征:在多个语义层次上建模视觉语言对应
2. 视觉语言学习统一化
统一架构的愿景
利用Transformer的统一性,在单一网络中处理多模态信息:
- Token化策略:将图像patch和文本token统一为序列
- 位置编码统一:设计支持多模态的位置编码机制
- 注意力机制融合:在统一框架中处理模态内和跨模态注意力
技术实现挑战
- 计算效率:如何在统一架构中保持计算效率
- 模态特异性:如何在统一框架中保留模态特有信息
- 扩展性:统一架构的可扩展性和灵活性
3. 多语言VLM研究
文化包容性需求
现有VLM主要基于英语训练,存在明显的语言和文化偏见:
- 多语言数据收集:构建涵盖多语言的大规模图像-文本数据集
- 跨语言一致性:确保不同语言描述的语义一致性
- 文化适应性:适应不同文化背景下的视觉理解差异
技术发展路径
- 多语言预训练:设计支持多语言的预训练目标
- 跨语言对齐:建立不同语言间的语义对齐机制
- 文化偏见消除:开发减少文化偏见的技术方法
4. 数据高效的VLM
可持续发展需求
降低VLM对大规模数据和计算资源的依赖:
- 小样本学习:在有限数据下训练有效的VLM
- 数据增强策略:通过智能数据增强提升数据利用效率
- 知识蒸馏:从大模型向小模型传递知识
技术创新方向
- 元学习应用:利用元学习实现快速适应
- 数据合成技术:通过生成模型创建高质量训练数据
- 主动学习:智能选择最有价值的训练样本
5. 与大语言模型的深度融合
协同发展趋势
VLM与大语言模型(LLM)的结合呈现巨大潜力:
- 语言能力增强:利用LLM的强大语言理解和生成能力
- 知识注入:将LLM中的知识有效注入到VLM中
- 推理能力提升:结合LLM的推理能力处理复杂视觉语言任务
融合技术路径
- 架构融合:设计统一的多模态大模型架构
- 知识迁移:开发有效的跨模态知识迁移方法
- 联合训练:探索视觉语言联合训练策略
6. 无监督VLM迁移
实用化需求
减少对标注数据的依赖,提升VLM的实际应用价值:
- 零样本域适应:在无标注目标域数据上实现有效适应
- 自监督适应:利用目标域的内在结构进行适应
- 持续学习:在新任务上持续学习而不遗忘原有能力
技术发展方向
- 伪标签技术:开发高质量伪标签生成方法
- 一致性正则化:通过一致性约束提升无监督适应效果
- 对抗训练:利用域对抗训练缓解域间差异
7. 视觉提示与适配器技术
参数高效微调需求
发展更加参数高效和计算友好的迁移学习方法:
- 视觉提示学习:在视觉输入上添加可学习的提示
- 多模态适配器:设计同时处理视觉和文本的适配器
- 动态适配:根据任务特性动态调整适配策略
技术创新空间
- 提示设计:探索更有效的视觉提示设计方法
- 适配器架构:开发新型适配器架构
- 参数共享:在多任务间有效共享适配器参数
8. 测试时VLM适应
实时适应能力需求
开发能够在推理过程中动态适应的VLM系统:
- 在线学习:在测试时根据新样本更新模型
- 快速适应:实现对新场景的快速适应
- 稳定性保证:确保适应过程中的模型稳定性
技术实现挑战
- 计算效率:在推理时进行高效的模型更新
- 灾难性遗忘:避免适应过程中的性能退化
- 安全性考虑:防止恶意样本对模型的攻击
9. 多VLM知识协同与蒸馏
模型集成需求
充分利用多个VLM的互补优势:
- 知识融合:有效融合多个VLM的知识
- 集成学习:开发VLM集成学习方法
- 分布式推理:实现多VLM的分布式协同推理
技术发展路径
- 知识对齐:在不同VLM间建立知识对齐机制
- 动态集成:根据输入动态选择和组合VLM
- 效率优化:在保持性能的同时优化集成效率
产业影响与应用前景
技术产业化的深远影响
AI产业生态重构
VLM作为基础技术设施,正在重新定义AI产业生态:
- 从专用到通用:从任务特定模型向通用智能模型转变
- 从数据驱动到知识驱动:利用网络规模知识而非专门标注数据
- 从技术门槛到服务门槛:降低AI应用的技术门槛,提升服务质量要求
商业模式创新
VLM催生了全新的商业模式和应用场景:
- API经济:通过API服务提供VLM能力
- 定制化服务:基于通用VLM开发行业特定解决方案
- 内容智能化:推动内容产业的智能化转型
重点应用领域分析
内容理解与生产
- 自动内容审核:识别和过滤不当内容
- 智能内容标注:自动生成图像和视频标签
- 创意内容生成:辅助创意工作者进行内容创作
智能搜索与推荐
- 多模态搜索:支持图像、文本混合的复杂查询
- 个性化推荐:基于多模态理解的精准推荐
- 商品搜索:通过图像搜索商品和获取信息
教育与辅助技术
- 智能教学助手:提供个性化的视觉学习辅导
- 无障碍技术:为视觉障碍者提供图像描述服务
- 语言学习:通过视觉语言关联辅助语言学习
医疗健康应用
- 医学图像分析:辅助医学图像的诊断和分析
- 健康监测:通过图像分析进行健康状态评估
- 医学教育:提供智能化的医学教育工具
技术普及的社会意义
数字鸿沟缩小
VLM的零样本能力显著降低了AI应用的技术门槛:
- 中小企业赋能:使中小企业能够快速部署AI系统
- 发展中国家机遇:为资源受限的地区提供先进AI能力
- 个人开发者支持:个人开发者也能构建复杂的AI应用
创新创业促进
- 降低创业门槛:减少AI创业的技术和资金门槛
- 加速原型开发:快速验证和迭代AI产品概念
- 跨界融合:促进AI与传统行业的深度融合
研究方法论与标准化建议
基准测试标准化
评估框架统一
当前VLM研究缺乏统一的评估标准,亟需建立:
- 标准化基准:建立涵盖多任务的标准化评估基准
- 公平比较机制:确保不同方法间的公平比较
- 动态评估体系:建立能够适应技术发展的动态评估体系
性能度量完善
- 多维度评估:从准确性、效率、鲁棒性等多维度评估模型
- 实际应用导向:设计贴近实际应用场景的评估指标
- 可解释性量化:建立量化模型可解释性的评估方法
开放科学推进
资源共享机制
- 开源模型库:建立大规模VLM的开源共享平台
- 数据集开放:推动高质量数据集的开放共享
- 计算资源共享:建立面向学术研究的计算资源共享平台
研究透明度提升
- 实验可复现:提高实验的可复现性和透明度
- 负面结果报告:鼓励报告和分享负面实验结果
- 方法局限性讨论:诚实讨论方法的局限性和适用范围
结语与展望
技术发展的历史性意义
视觉语言模型的兴起标志着人工智能发展进入了一个全新的历史阶段。从传统的"数据+算法"范式到现在的"大数据+大模型+通用智能"范式,VLM不仅解决了计算机视觉领域长期面临的核心挑战,更为通用人工智能的实现提供了可能的技术路径。
这一技术革命的深远意义在于:它将AI从"专用工具"转变为"通用智能基础设施",从"技术专家的专利"转变为"普通开发者的工具",从"实验室的研究成果"转变为"产业界的核心驱动力"。
面向未来的技术愿景
展望未来,VLM技术的发展将朝着更加智能、高效、普惠的方向演进:
技术维度:模型将变得更加高效和强大,能够在更少的计算资源下实现更好的性能;理解能力将更加深入和精细,能够处理更复杂的视觉语言任务;知识整合将更加全面和准确,能够有效结合多源异构信息。
应用维度:VLM将深度融入到各行各业的核心业务流程中,成为数字化转型的重要驱动力;新的应用模式和商业模式将不断涌现,创造前所未有的价值;人机协作将更加自然和高效,真正实现人工智能的"智能增强"愿景。
社会维度:AI技术的民主化将进一步加速,让更多的人能够享受到AI带来的便利;数字鸿沟将逐步缩小,促进全球范围内的数字包容性;新的伦理和治理挑战将出现,需要社会各界的共同应对。