通过语义AI管道检测文本数据中的潜在异常值
本文介绍了如何通过语义AI管道检测文本数据中的潜在异常值,结合嵌入技术、机器学习算法和可解释AI,构建一个完整的异常检测工作流。
Detecting Potential Outliers in Text Data Through a Semantic AI Pipeline
文章目录
- 1 嵌入、异常、可解释AI、聚类及更多
- 2 实战
- 2.1 理解和标准化我们的数据集
- 2.2 生成高维嵌入
- 2.3 为什么文本欧几里得距离方法永远行不通
- 2.4 基于马哈拉诺比斯距离的统计异常值
- 2.5 基于密度的局部异常因子(LOF)异常值
- 2.6 基于隔离的隔离森林异常值
- 2.7 比较分析
- 2.8 使用 LLM 进行语义解释
- 3 通过无监督聚类验证我们的嵌入
- 4 我们接下来可以做什么?
1 嵌入、异常、可解释AI、聚类及更多
我们知道现实世界的数据无法转化为完美的聚类。它充满了隐藏的异常值,这些异常值会悄无声息地破坏分析、扭曲机器学习模型,并导致错误的业务决策。
检测这些异常值曾纯粹是统计学上的游戏。但现在我们有了嵌入和大型语言模型(LLM),我们可以改变这个过程。通过将AI与传统机器学习相结合,我们可以构建的管道不仅能根据数字,还能根据语义含义来发现异常值。
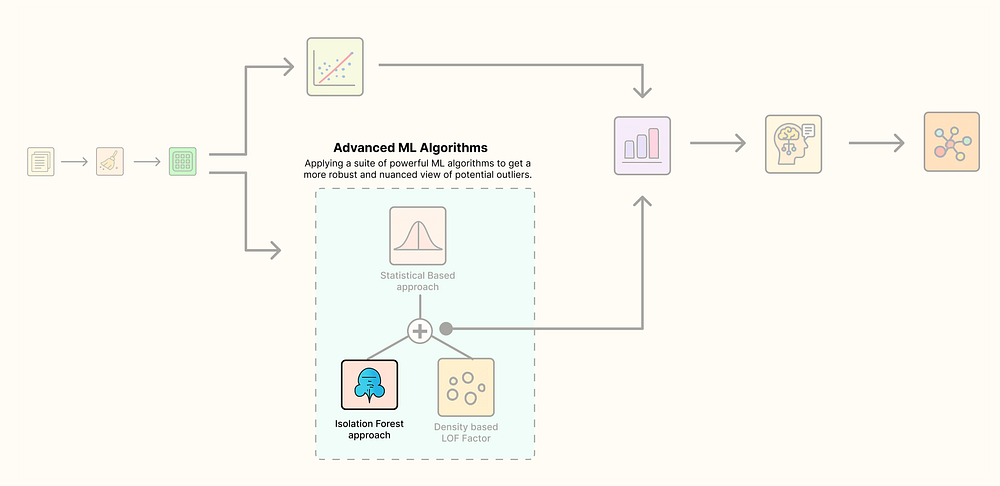
一个典型的集成AI的ML管道涉及许多传统组件以及新的基于AI的组件……
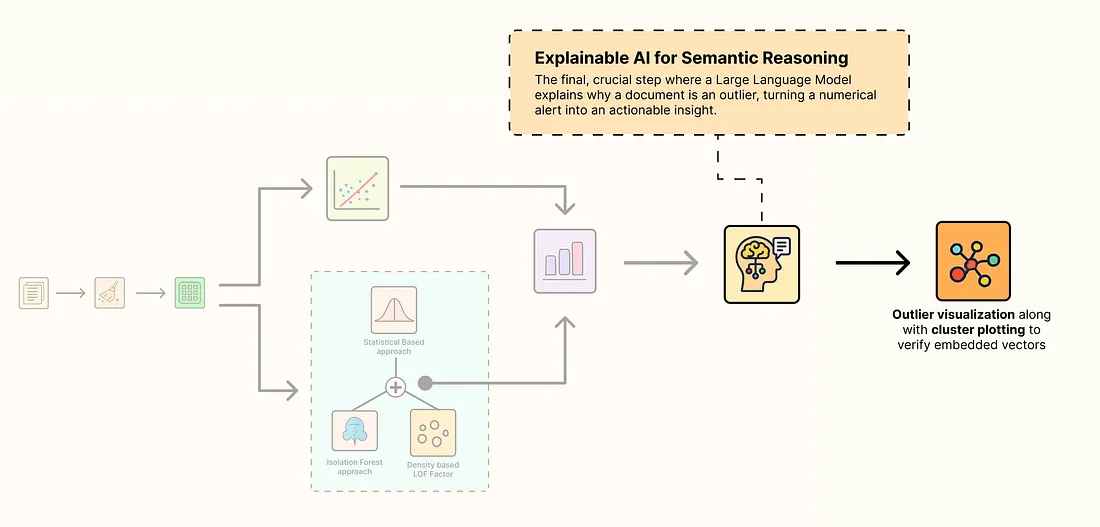
基于AI+ML的异常值检测管道
- 标准化数据集:我们将从原始的、非结构化文本开始,并应用清洗技术为我们的AI模型做准备。
- 生成高维嵌入:我们将使用强大的AI模型将清洗后的文本转换为捕获语义含义的丰富数值向量。
- 使用多种ML算法检测异常值:我们将运行一套经典和先进的算法,从不同角度识别潜在的异常值。
- 使用无监督聚类验证嵌入:我们将执行关键的健全性检查,以确认我们的嵌入已成功将数据组织成有意义的组。
- 使用LLM生成语义解释:最后,我们将使用LLM自动解释为什么一个文档是异常值,将简单的警报转化为可操作的洞察。
所有代码都可以在我的GitHub仓库中找到:AI-outlier-detection
2 实战
为了有效地检测数据管道中的异常,我们需要将AI与机器学习相结合。此工作流程中有三个关键组件:
- 嵌入模型:它将我们的文本数据转换为数值向量,使其适用于计算和分析。
- 机器学习算法:这些算法对嵌入进行聚类,并根据向量空间中的模式检测异常。
- 可解释AI / LLM:大型语言模型有助于验证检测到的异常并提供解释,从而增强我们对结果的信心。
在我们深入核心模块之前,让我们先导入一些将在整个项目中使用的基本库:
import re
import os
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from tqdm.auto import tqdm
这些库将支持诸如绘制聚类、处理数据帧和跟踪进度等任务。
对于机器学习部分,我们将使用scikit-learn,它是监督和无监督学习、聚类和异常检测的标准库:
from scipy.spatial.distance import mahalanobis
from scipy.stats import chi2
from sklearn.neighbors import LocalOutlierFactor
from sklearn.ensemble import IsolationForest
from sklearn.cluster import KMeans
通过向量化我们的数据,我们可以执行数值计算,例如距离计算、聚类和异常值检测。KMeans将帮助我们可视化异常值与主要聚类的关系。
对于AI组件,我们将通过Nebius API使用LLM和嵌入模型进行快速实验。您也可以换用其他提供商,例如Ollama,在本地运行LLM:
from openai import OpenAIapi_key = "API_KEY_HERE" client = OpenAI( base_url="https://api.studio.nebius.com/v1/", api_key=api_key
)
如果需要,只需将base_url替换为您选择的LLM提供商的端点即可。
2.1 理解和标准化我们的数据集
为了确定哪种算法最适合异常检测,我们需要在真实世界的数据集上测试它们。为此,我们将使用20 Newsgroups数据集,这是一个由scikit-learn提供的知名数据集。该数据集特别有趣,因为它包含固有的聚类挑战,这些挑战不容易检测,使其成为测试异常检测方法的理想选择。
理解我们的数据集
- 该数据集包含大约20,000篇新闻组帖子,分布在20个类别中,包括政治、体育、科学、宗教等主题。
- 它最初由Ken Lang于1995年编译,后来为机器学习实验进行了整理和标准化。
让我们首先加载此数据集并进行初步分析以了解其结构。
from sklearn.datasets import fetch_20newsgroupsnewsgroups_train = fetch_20newsgroups(subset="train")print("Newsgroups Categories:")
print(newsgroups_train.target_names)
Newsgroups Categories:
[ 'alt.atheism', 'comp.graphics', 'comp.os.ms-windows.misc', 'comp.sys.ibm.pc.hardware', 'comp.sys.mac.hardware', 'comp.windows.x', 'misc.forsale', 'rec.autos', 'rec.motorcycles', 'rec.sport.baseball', 'rec.sport.hockey', 'sci.crypt', 'sci.electronics', 'sci.med', 'sci.space', 'soc.religion.christian', 'talk.politics.guns', 'talk.politics.mideast', 'talk.politics.misc', 'talk.religion.misc'
]
到目前为止,我们数据集共有20个新闻类别。让我们看看第一个条目,了解其内容:
print(newsgroups_train.data[0])
"From: lerxst@wam.umd.edu (where is my thing)
Subject: WHAT car is this!?
Nntp-Posting-Host: rac3.wam.umd.edu
Organization: University of Maryland, College Park
Lines: 15I was wondering if anyone out there could enlighten me on this car I saw
the other day. I... ry, or whatever info you
have on this funky looking car, please e-mail.Thanks,
- IL ---- brought to you by your neighborhood Lerxst ----"
正如我们所看到的,数据集在传入嵌入模型之前需要进行一些清洗。清洗不仅对于减少嵌入中的噪声很重要,而且还可以节省计算资源,如果使用付费API,还可以降低成本。
查看第一个文档,我们注意到非字母字符、过多的空格和其他伪影占据了不必要的空间。
为了解决这个问题,我们创建一个函数来预处理和清洗文本。
def clean_and_structure_data(dataset): """Cleans the raw text data and structures it into a Pandas DataFrame."""data = [re.sub(r"[\w\.-]+@[\w\.-]+", "", d) for d in dataset.data]data = [re.sub(r"\([^()]*\)", "", d) for d in data]data = [d.replace("From: ", "") for d in data] data = [d.replace("\nSubject: ", "") for d in data] data = [d.replace("Subject: ", "") for d in data] data = [d.replace("Lines:", "") for d in data]data = [d[:2000] for d in data]df = pd.DataFrame(data, columns=["Text"])df["Label"] = dataset.target df["Class Name"] = df["Label"].map(dataset.target_names.__getitem__)return df
在我们的清洗过程中,我们执行了几个特定的步骤:
- 删除电子邮件地址以及括号内的任何内容,因为这些通常对理解主要主题没有用。
- 截断长文本输入,假设帖子的开头几行通常足以捕捉其主要主题。
- 将清洗后的文本转换为结构化DataFrame,使其更容易用于嵌入和下游处理。
让我们将此清洗函数应用于我们的原始数据集并查看结果:
df_full = clean_and_structure_data(newsgroups_train)df_full.head()
清洗后的数据帧如下所示。
太棒了!现在我们已经将数据转换为更干净、更结构化的格式,我们可以进一步缩小数据集。处理较小的子集将使我们更容易科学地可视化管道的每个步骤,并更好地理解从嵌入到异常检测的每个组件如何影响结果。
def filter_and_sample_data(df, sample_size=150): """Filters for specific categories and samples the data."""df_sci = df[df["Class Name"].str.contains("sci")]df_sampled = ( df_sci.groupby("Class Name", group_keys=False) .apply(lambda x: x.sample(sample_size, random_state=42)) .reset_index(drop=True) )return df_sampled
由于数据集包含近20个新闻组类别,因此有许多聚类需要考虑。为了简化我们的分析并更好地理解管道的工作原理,我们可以专注于特定的类别子集。在此示例中,我们将针对科学相关类别,使我们能够清楚地看到嵌入、聚类和异常检测在更易于管理的范围内如何表现。
让我们将此过滤函数应用于我们最近清洗过的数据集并检查结果:
df_train = filter_and_sample_data(df_full, sample_size=150)print(df_train.info())
print("\nClass distribution in the sampled dataset:")
print(df_train["Class Name"].value_counts())
RangeIndex: 600 entries, 0 to 599
Data columns (total 3 columns): --- ------ -------------- ----- 0 Text 600 non-null object 1 Label 600 non-null int64 2 Class Name 600 non-null object
dtypes: int64(1), object(2)
memory usage: 14.2+ KB
NoneClass distribution in the sampled dataset:
Class Name
sci.crypt 150
sci.electronics 150
sci.med 150
sci.space 150
Name: count, dtype: int64
我们现在有一个数据集子集,其中包含600个文档,分布在4个科学相关类别中:sci.crypt、sci.electronics、sci.med和sci.space。这个重点数据集将作为构建和测试我们异常检测管道的基础,使我们能够清楚地可视化和理解该过程的每个步骤。
有了准备好的数据,我们可以继续向量化文档、对它们进行聚类并使用我们的AI和机器学习组件检测异常。
2.2 生成高维嵌入
我们管道的第一步是生成嵌入。我们使用的是BAAI/bge-en-icl模型,该模型因其在涉及语义相似性的任务中的强大性能而被选中。该模型将文本映射到高维向量空间,其中向量之间的距离反映了它们含义的相似程度。
生成高维数据
为了简化此过程,我们可以创建一个函数,该函数获取所有清洗过的文档并将其转换为嵌入:
def embed_corpus_with_api(df, client, model_name, batch_size=50): """Generates embeddings for the 'Text' column using the specified API client."""all_embeddings = [] text_corpus = df["Text"].tolist()for i in tqdm(range(0, len(text_corpus), batch_size)): batch = text_corpus[i:i + batch_size]response = client.embeddings.create( model=model_name, input=batch )embeddings = [np.array(item.embedding) for item in response.data] all_embeddings.extend(embeddings)df["Embeddings"] = all_embeddings df.dropna(subset=["Embeddings"], inplace=True)return df
为了节省时间,我们正在将文本数据批量传递给我们的嵌入模型。但是,如果您在本地或GPU上运行开源LLM,这也会增加计算资源的使用。让我们在训练数据上运行此函数。
df_train = embed_corpus_with_api(df_train, client, model_name="BAAI/bge-en-icl")print(f"Shape of the first embedding vector: {df_train['Embeddings'].iloc[0].shape}")
Generating embeddings using 'BAAI/bge-en-icl'...
100%|██████████| 12/12 [00:31<00:00, 2.60s/it]
Embeddings generated and added to the DataFrame.
Shape of the first embedding vector: (4096,)
总共有600个条目通过我们的嵌入模型分12批处理。现在我们已经向量化了数据,600个文档中的每个都由一个4096维向量表示。这个高维空间捕获了我们文本的语义含义。
让我们看看我们更新后的数据帧。
df_train.head()
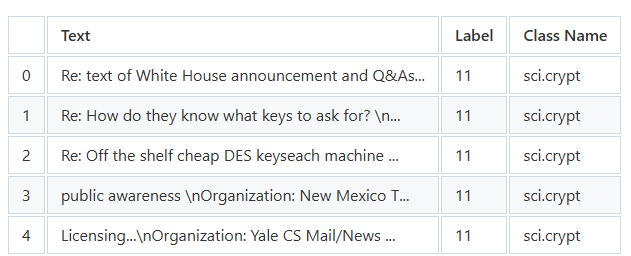
我们现在可以开始实现基线,以及其他聚类机器学习算法,并评估它们的性能。
2.3 为什么文本欧几里得距离方法永远行不通
在真实世界的数据中,我们很少能找到欧几里得方法适用的完美形状的聚类。
基线方法
为了证明这一点,我们正在实现一个简单的基线方法。在我们编写代码并探索实际问题之前,让我们首先理解并可视化它的工作原理。
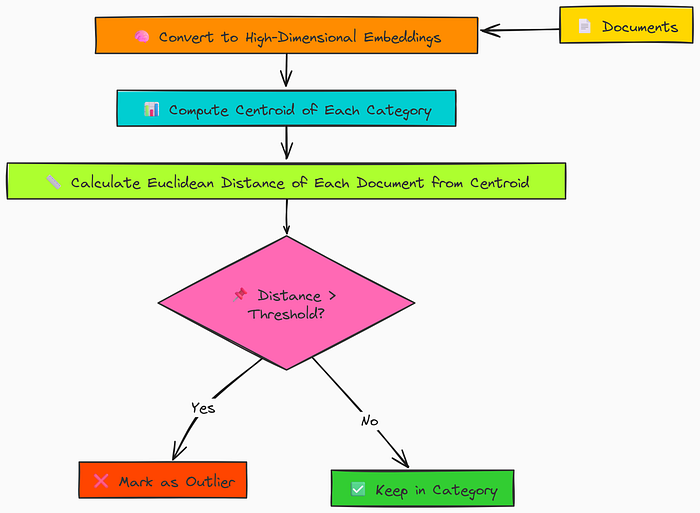
欧几里得距离的流程
- 首先,我们将每个文档转换为高维嵌入向量(在上一节中已完成)。
- 之后,我们通过平均其嵌入来计算每个类别的质心。
- 接下来,我们使用欧几里得距离确定每个文档与其类别质心的距离。
- 最后,我们设置一个距离阈值,并将任何超出该边界的文档标记为异常值。
我们需要编写一个函数,可以为我们的每个科学类别提供质心。
def get_embedding_centroids(df): """Calculates the centroid of the embeddings for each class.""" emb_centroids = {} grouped = df.groupby("Class Name") for class_name, group in grouped: emb_centroids[class_name] = np.mean(np.vstack(group['Embeddings']), axis=0) return emb_centroids
因此,在这个函数中,我们基本上是按类别对DataFrame进行分组,然后计算每个组的平均向量,以找到其在4096维空间中的**“重心”**。
接下来,我们需要应用欧几里得公式来测量文档与其类别中心之间的直线距离。

欧几里得公式
def calculate_euclidean_distance(p1, p2): """Calculates the Euclidean distance between two vectors.""" return np.sqrt(np.sum((p1 - p2) ** 2))
我们已经准备好两个主要组件。现在我们可以编写第三个组件的代码,该组件根据预定义的半径检测异常值。
def detect_outliers_euclidean(df, emb_centroids, radius): """Flags outliers based on Euclidean distance from the class centroid."""outlier_indices = []for idx, row in df.iterrows(): class_name = row["Class Name"] dist = calculate_euclidean_distance(row["Embeddings"], emb_centroids[class_name]) if dist > radius: outlier_indices.append(idx)df["Outlier_Euclidean"] = False df.loc[outlier_indices, "Outlier_Euclidean"] = Truereturn df
让我们运行这个基线方法。我们将设置一个任意半径0.55,这意味着任何超过55%的我们都称之为异常值。
RADIUS = 0.55baseline_centroids = get_embedding_centroids(df_train)df_train = detect_outliers_euclidean(df_train, baseline_centroids, RADIUS)num_outliers_baseline = df_train["Outlier_Euclidean"].sum()
print(f"Found {num_outliers_baseline} outliers with Euclidean method at radius {RADIUS}")
通过运行我们的欧几里得距离管道,我们得到以下输出。
######### OUTPUT ##########
Found 506 outliers with Euclidean method at radius 0.55
在我们的600个文档中,506个异常值,这种简单的方法将超过84%的文档标记为异常。这是我们第一个重要的线索,表明这种方法过于天真。
它失败的原因有两个:
- 任意半径:我们是如何选择0.55的?半径为0.6会找到更少的异常值,而0.5会找到更多。这个单一的、硬编码的值在统计上不够健壮。
- 球形假设:该方法假设每个类别都形成一个完美的数据点球体。实际上,文本嵌入会创建复杂的、细长的形状。单一半径根本无法捕捉这种细微差别。
为了直观地查看异常值如何在我们的聚类中表示,我们首先需要将高维数据映射到2D,这可以使用UMAP完成,所以让我们先编写该函数。
def project_with_umap(df, n_neighbors=15, min_dist=0.1, random_state=42): """Projects high-dimensional embeddings into 2D using UMAP."""print("Projecting embeddings to 2D using UMAP...")embeddings = np.vstack(df["Embeddings"])reducer = umap.UMAP( n_neighbors=n_neighbors, min_dist=min_dist, random_state=random_state, metric="cosine" )umap_results = reducer.fit_transform(embeddings)df_umap = pd.DataFrame(umap_results, columns=["UMAP1", "UMAP2"]) df_umap = pd.concat([df_umap, df.reset_index(drop=True)], axis=1)print("UMAP projection complete.") return df_umap
我们在UMAP中使用余弦相似度作为度量标准,以保留高维嵌入之间的角度关系,这对于文本数据比直线距离更有意义。
这有助于在投影到2D时保持文档的语义结构。让我们运行此函数并将数据转换为2D表示。
df_umap = project_with_umap(df_train)
现在,我们可以简单地编写一个绘图函数,该函数将生成聚类以及其上的异常值。
def plot_single_method_outliers(df_plot, outlier_col, method_name): """Plots UMAP projection highlighting outliers for one detection method."""fig, ax = plt.subplots(figsize=(12, 9))inliers = df_plot[df_plot[outlier_col] == False] sns.scatterplot( data=inliers, x="UMAP1", y="UMAP2", hue="Class Name", palette="viridis", ax=ax, alpha=0.6 )outliers = df_plot[df_plot[outlier_col] == True] sns.scatterplot( data=outliers, x="UMAP1", y="UMAP2", color="red", marker="X", s=150, label="Outlier", ax=ax )sns.move_legend(ax, "upper left", bbox_to_anchor=(1, 1)) plt.title(f"UMAP Projection with Outliers Detected by {method_name}") plt.xlabel("UMAP Dimension 1") plt.ylabel("UMAP Dimension 2")plt.show()
- UMAP维度1代表投影后高维嵌入空间中最大方差的方向,捕获数据中最显著的模式。
- UMAP维度2捕获次要显著方差,保留点之间的局部关系。
- 这两个维度共同使我们能够在2D中可视化嵌入的结构,同时保留全局和局部聚类信息。
现在我们可以简单地运行此函数并查看我们的图表。
plot_single_method_outliers(df_umap, "Outlier_Euclidean", "Euclidean Distance")
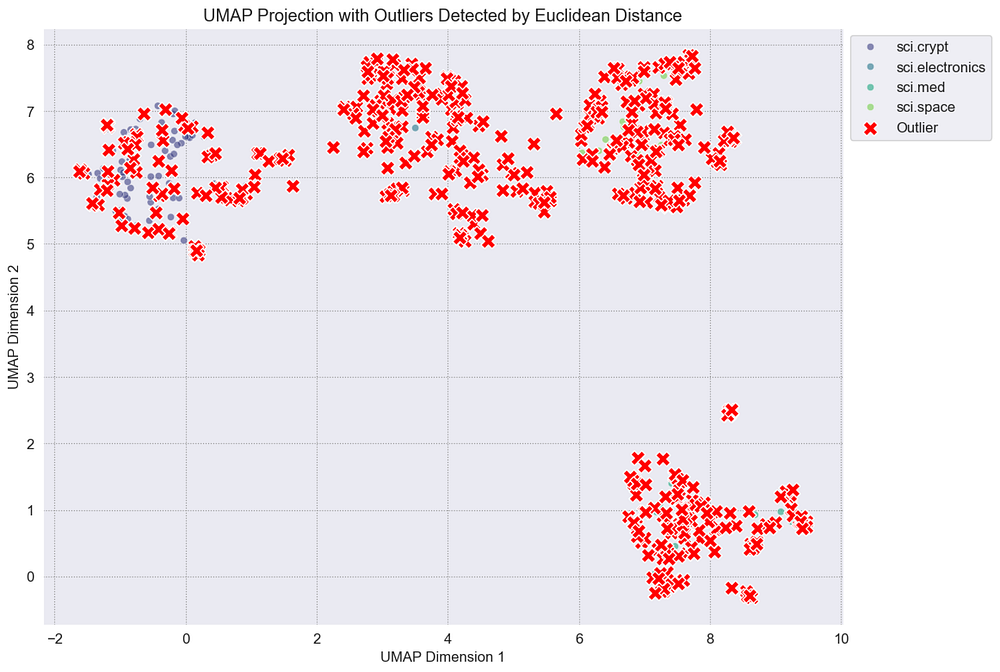
基线欧几里得聚类
那些红色的叉号代表我们几乎看不到的非异常值点,这是错误的。我们清楚地看到,即使使用一个好的嵌入模型来整合AI因素,我们的真实世界数据也没有太大变化,需要更合适的ML算法来改进我们的管道,所以让我们这样做。
欧几里得只适用于完美聚类的数据。
2.4 基于马哈拉诺比斯距离的统计异常值
欧几里得方法的失败告诉我们,真实世界的数据聚类很少是完美的球体。我们需要一种能够理解数据形状和分布的方法。这就是马哈拉诺比斯距离发挥作用的地方。
统计方法
马哈拉诺比斯方法不是画一个简单的圆(像欧几里得距离),而是在数据周围画一个定制的椭圆,考虑其独特的形状。它的工作原理如下:
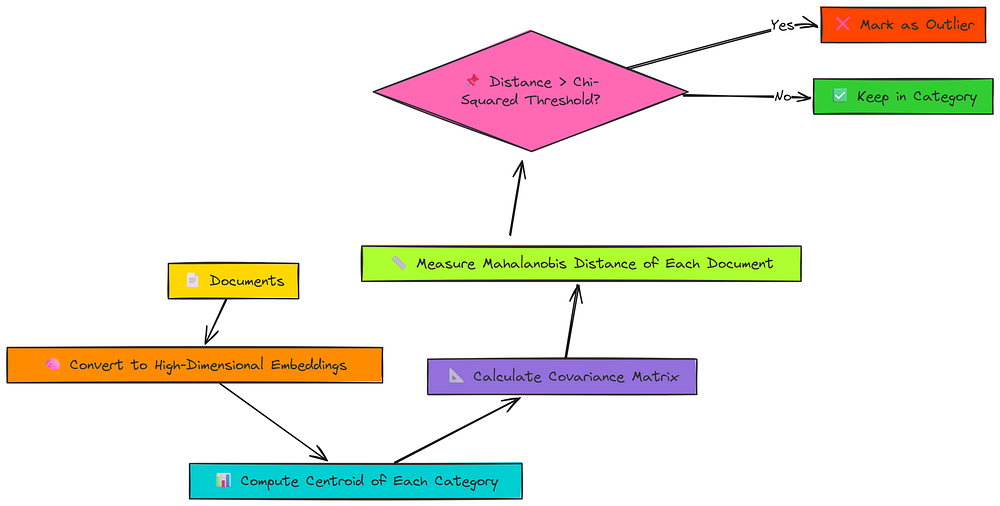
马哈拉诺比斯距离流程
- 首先,它找到每个类别数据云的中心(质心),就像欧几里得方法一样。
- 其次,它通过计算其协方差矩阵来分析该云的_形状_。这告诉我们数据的分布方式以及它是否在某些方向上比其他方向更分散。
- 第三,它测量每个点到质心的距离,相对于云的形状。一个在数据已经非常分散的方向上远离的点,比一个在数据通常非常紧密的方向上稍微偏离的点,被认为不那么异常。
- 最后,它不使用任意半径,而是将这个计算出的距离与从卡方分布导出的统计阈值进行比较。这使我们能够以特定的置信水平(例如99%)判断一个点是否是真正的异常值。
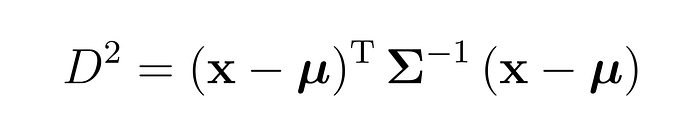
逆协方差矩阵
为了理解它的工作原理,我们需要查看核心公式,最重要的是,公式中每个符号的作用。
- D2D^2D2 是马哈拉诺比斯距离,它是一种在考虑聚类形状的同时测量点到中心距离的方法。
- xxx 是单个文档的嵌入,即我们正在测量的点。
- μ\muμ (mu)是平均嵌入,即聚类的中心。
- (x−μ)(x - \mu)(x−μ) 是差向量,显示文档与中心的距离。
- Σ\SigmaΣ (Sigma)是协方差矩阵,它描述了数据在不同方向上的分布方式。
- Σ−1\Sigma^{-1}Σ−1 (Sigma-Inverse)是逆协方差矩阵,它通过降低对分散方向的重视程度和提高对紧密方向的重视程度来重新加权距离。
- T^TT (转置)只是一个数学步骤,用于使乘法正确进行。
现在我们需要编写一个实现此逻辑的函数。我们将计算每个类别的质心和协方差,计算该类别中每个文档的马哈拉诺比斯距离,然后标记任何超出我们99%置信阈值的内容。
def detect_outliers_mahalanobis(df, confidence=0.99): """Flags outliers based on Mahalanobis distance for each class."""outlier_indices = [] grouped = df.groupby("Class Name")for class_name, group in grouped: embeddings = np.vstack(group["Embeddings"]) centroid = np.mean(embeddings, axis=0) cov = np.cov(embeddings.T) inv_cov = np.linalg.inv(cov + np.identity(cov.shape[0]) * 1e-6) distances = [mahalanobis(emb, centroid, inv_cov) for emb in embeddings]threshold = chi2.ppf(confidence, df=embeddings.shape[1]) print(f"Mahalanobis threshold for '{class_name}': {threshold:.2f}")group_outlier_indices = group.index[np.array(distances) > threshold].tolist() outlier_indices.extend(group_outlier_indices)df["Outlier_Mahalanobis"] = False df.loc[outlier_indices, "Outlier_Mahalanobis"] = Truereturn df
让我们在数据上运行这种更复杂的方法。
df_umap = detect_outliers_mahalanobis(df_umap, confidence=0.99)num_outliers = df_umap["Outlier_Mahalanobis"].sum()
print(f"Found {num_outliers} outliers with Mahalanobis Distance method.")
运行此代码会给我们一个非常不同,也许令人惊讶的结果。
Mahalanobis threshold for 'sci.crypt': 4309.49
Mahalanobis threshold for 'sci.electronics': 4309.49
Mahalanobis threshold for 'sci.med': 4309.49
Mahalanobis threshold for 'sci.space': 4309.49
Found 0 outliers with Mahalanobis Distance method.
零异常值!这个结果和我们之前发现的506个异常值一样具有信息量。它告诉我们,虽然聚类并非完美的球体,但它们在统计上非常一致。高维度(4096维)意味着真正统计异常的阈值非常高。没有一个文档偏离其类别的形状足够远,以至于被这个严格的测试标记。
让我们可视化这一点以确认。我们将使用与之前相同的绘图函数。
plot_single_method_outliers(df_umap, "Outlier_Mahalanobis", "Mahalanobis Distance")
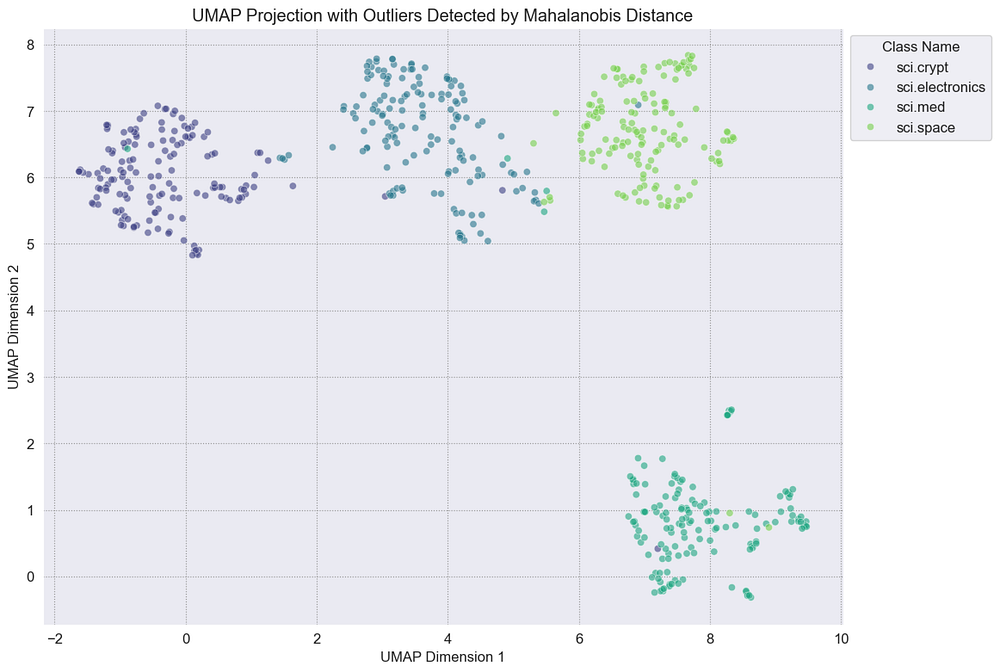
正如预期的那样,图表看起来很干净,没有出现红色的 X 标记。这表明统计方法认为所有数据点都落在其类别的正常分布内。我们可以降低置信参数,以使检测更加敏感,更容易捕捉潜在的异常,但现在我们专注于一种更严格、硬性的搜索方法。
但这正是数据科学领域的本质……这完全是关于试错,在我们的数据集中找到合适的组合。那么,我们接下来该怎么办呢?我们的第一种方法(欧几里得)太简单,几乎标记了所有内容。我们的第二种更先进的方法(马哈拉诺比斯)在统计上是稳健的,但没有找到任何东西,这可能是因为它观察的是整个簇的全局形状。
2.5 基于密度的局部异常因子(LOF)异常值
这引出了一个新问题……
如果异常值不是一个在统计上远离中心的点,而是一个……孤独的点呢?
如果它位于嵌入空间中稀疏、孤立的部分,远离其最近的邻居呢?
LOF检测
这是一个局部密度问题,而不是全局距离问题。为此,我们有一个完美的解决方案:**局部异常因子(LOF)**算法。
LOF的核心思想非常简单,可以用一个派对类比来解释:
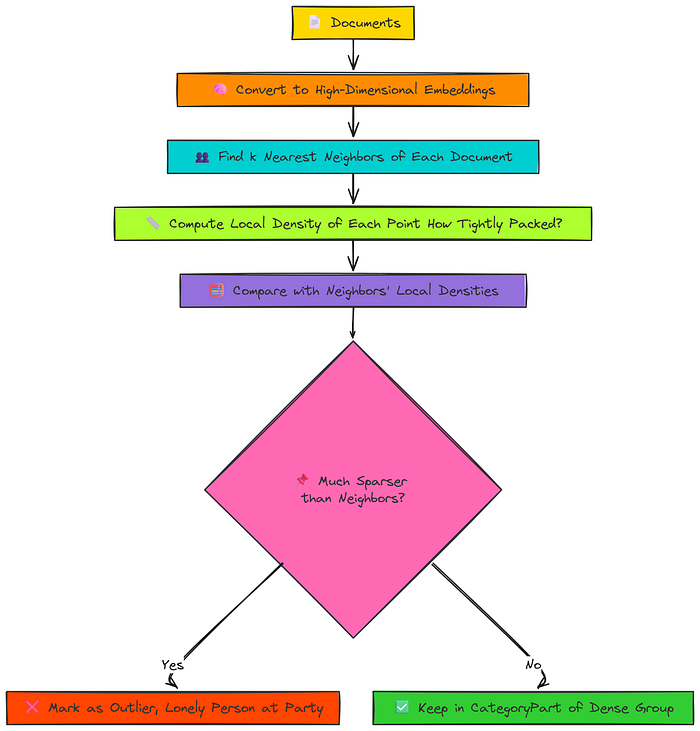
局部异常因子 (LOF)
- 首先,要检查某人是否是异常值,您会查看他们最亲密的朋友圈(他们的最近邻居)。
- 其次,您会测量该群体的紧密程度。他们是在进行亲密的交谈,还是分散开来?这就是这个人的_局部密度_。
- 第三,这是关键一步,您会询问他们的朋友关于_他们自己_的群体。您会找出每个邻居的局部密度。
- 最后,您进行比较。如果您正在检查的人所在的群体比他们的朋友所在的群体更分散、更稀疏,那么他们就是异常值。他们是那个尴尬地独自站着的人,而他们最近的“朋友”都在更紧密、更密集的交谈圈中。
LOF擅长发现这些其他方法可能遗漏的孤立点。让我们来编写代码。
def detect_outliers_lof(df, n_neighbors=20, contamination="auto"): """Flags outliers using the Local Outlier Factor algorithm."""embeddings = np.vstack(df["Embeddings"])lof = LocalOutlierFactor(n_neighbors=n_neighbors, contamination=contamination)predictions = lof.fit_predict(embeddings)df["Outlier_LOF"] = (predictions == -1)return df
我们将contamination设置为'auto',这是一种稳健的方式,让算法根据其内部评分来决定异常值的比例,而不是我们猜测一个固定的百分比。
让我们运行这个基于密度的检查。
df_umap = detect_outliers_lof(df_umap)num_outliers = df_umap["Outlier_LOF"].sum()
print(f"Found {num_outliers} outliers with Local Outlier Factor method.")
结果再次相同。
Found 0 outliers with Local Outlier Factor method.
再次零异常值!这告诉我们关于数据的一些非常重要的事情。聚类不仅在统计上一致(如马哈拉诺比斯所示),而且它们也相当均匀地密集。没有孤立的数据点位于稀疏区域。每个类别中的文档在语义上接近且分布良好。
让我们快速可视化以确保。
plot_single_method_outliers(df_umap, "Outlier_LOF", "Local Outlier Factor")
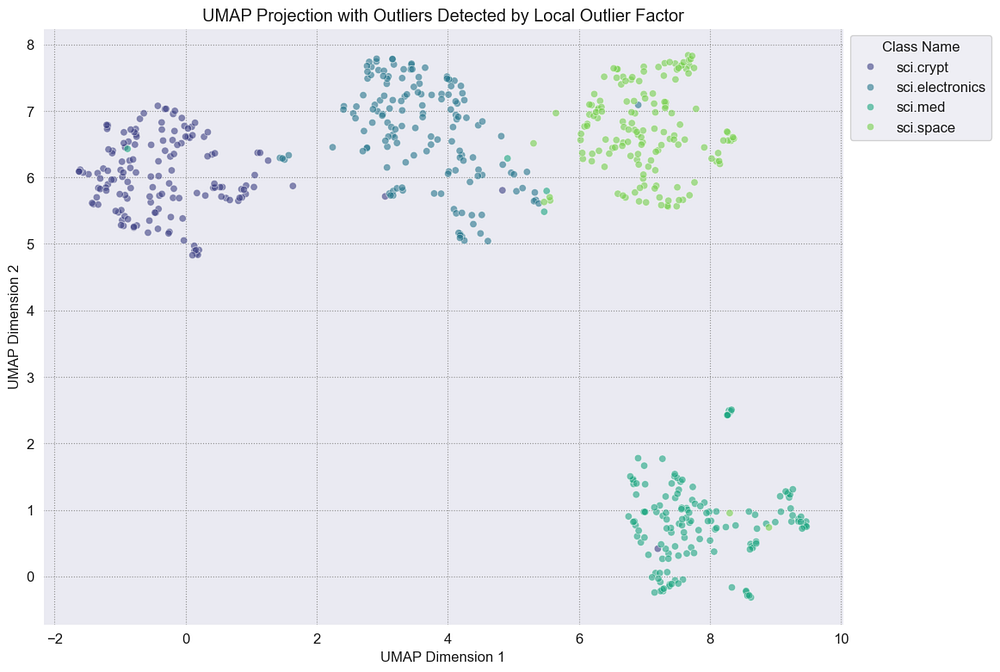
基于LOF的方法
就像马哈拉诺比斯图一样,可视化是干净的,没有标记异常值。我们现在尝试了一种基于距离的方法、一种基于统计形状的方法和一种基于局部密度的方法。它们都没有在严格应用时发现令人信服的异常。
这并不意味着我们的管道失败了,而是意味着我们的管道告诉我们数据比我们想象的要干净。但我们还有一个绝招。这使我们进入了第三个也是最后一个高级技术,它根本不依赖于距离或密度。相反,它试图_隔离_异常。
2.6 基于隔离的隔离森林异常值
到目前为止,我们的实现教会了我们以不同的方式看待事物。欧几里得方法到处都看到了异常值。马哈拉诺比斯和LOF方法,凭借其严格的统计和基于密度的规则,没有看到异常值。这告诉我们,我们的数据聚类是结构良好且均匀密集的。
隔离森林
但这使我们进入了第三个也是最后一个高级技术,它根本不依赖于距离或密度。相反,它基于一个根本不同且巧妙的原理:
异常值数量少且与众不同,这使得它们比正常点更容易_隔离_。
这是隔离森林算法的核心思想。让我们用另一个类比来理解它:
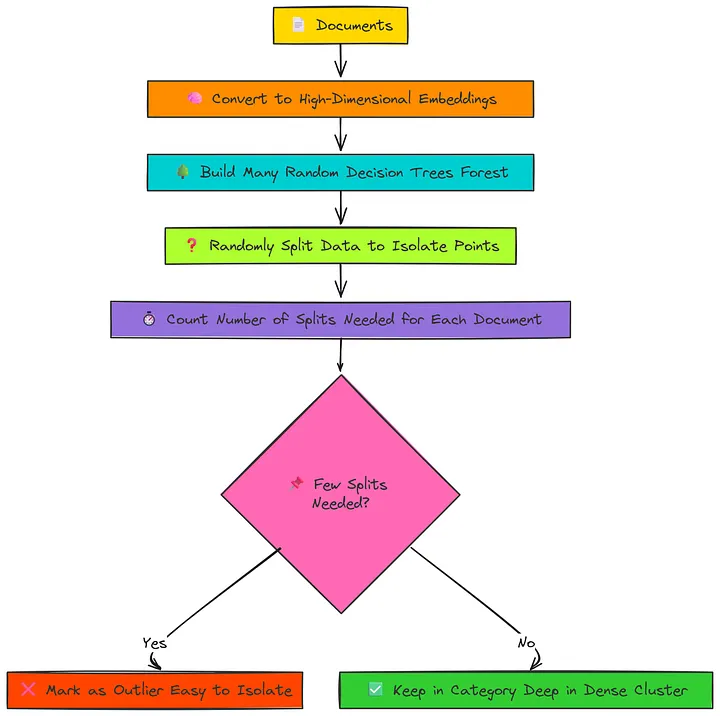
想象一下,您正在玩一个“猜猜我是谁?”的游戏,有我们的600个文档。您开始提出随机问题以找出特定文档。
- 要隔离一个正常文档,它位于密集聚类深处(例如,一篇关于航天飞机发射的典型“sci.space”文章),您需要很多问题:“它是关于太空的吗?”(是),“它是关于NASA的吗?”(是),“它是关于航天飞机的吗?”(是),“它是关于哥伦比亚号的吗?”(是)……需要很多次分割才能到达那个特定的正常点。
- 现在,想象一个异常文档。也许它是一篇“sci.space”文章,实际上是一首关于星星的长诗。要隔离它,您可能只需要一两个问题:“文本格式像诗歌吗?”(是)。砰。隔离。
隔离森林构建了数百个随机决策树(一个“森林”)来玩这个游戏。它计算隔离每个文档所需的平均问题数(分割)。那些始终以最少问题被隔离的文档被标记为异常。
至关重要的是,使用这种方法,我们必须给算法一个提示。我们使用一个名为contamination的参数,这是我们对数据中异常值百分比的最佳猜测。这与我们之前的方法不同;在这里,我们明确告诉模型,“我预计我的数据中大约有5%是异常的。请告诉我哪些点最符合这个描述。”
让我们编写这个强大的方法。
def detect_outliers_isoforest(df, contamination=0.05, random_state=42): """Flags outliers using the Isolation Forest algorithm."""embeddings = np.vstack(df['Embeddings'])iso_forest = IsolationForest(contamination=contamination, random_state=random_state)predictions = iso_forest.fit_predict(embeddings)df['Outlier_ISO'] = (predictions == -1)return df
我们将contamination设置为0.05,告诉模型找出最容易被隔离的前5%的点。现在,让我们看看它发现了什么。
df_umap = detect_outliers_isoforest(df_umap, contamination=0.05)num_outliers = df_umap["Outlier_ISO"].sum()
print(f"Found {num_outliers} outliers with Isolation Forest method.")
这一次,我们取得了突破。
Found 30 outliers with Isolation Forest method.
我们得到了一个合理且可操作的潜在异常值数量。我们的600个文档中有5%正好是30个,算法已成功识别出它们。这些文档在结构上**“不同”**,足以通过极少的决策分割始终与同类文档分离。
我们现在有了基线和三种高级方法的结果。下一步是结合这些结果,以识别最可疑的**“高置信度”**异常值,最重要的是,理解它们被标记的原因(可解释AI)。
2.7 比较分析
我们现在运行了四种不同的算法,每种算法都告诉我们一个不同的故事:
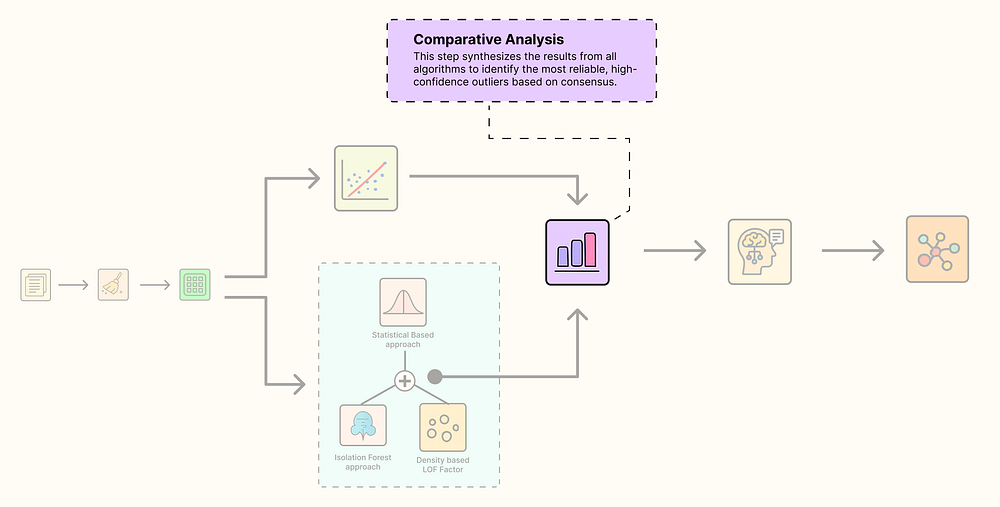
比较分析
- 欧几里得距离:将超过84%的数据标记为异常值。对于这类数据来说,显然过于敏感和天真。
- 马哈拉诺比斯距离:一种统计方法,没有发现异常值,告诉我们聚类形状良好,即使不完全是球形。
- 局部异常因子(LOF):一种基于密度的方法,也没有发现异常值,表明我们的聚类均匀密集,没有孤立点。
- 隔离森林:一种基于隔离的方法,成功识别出30个文档(占我们数据的5%)作为异常值。
单一算法的意见很有用,但真正的力量来自共识。在一个完美的世界中,我们会将**“高置信度异常值”**定义为被我们所有高级方法(马哈拉诺比斯、LOF和隔离森林)标记的任何文档。这将使我们对该点是真正异常值有极高的信心。
让我们总结一下我们的发现,看看是否存在这样的共识。
outlier_cols = ['Outlier_Euclidean', 'Outlier_Mahalanobis', 'Outlier_LOF', 'Outlier_ISO']
summary = df_umap[outlier_cols].sum().to_dict()advanced_cols = ['Outlier_Mahalanobis', 'Outlier_LOF', 'Outlier_ISO']
df_umap['Outlier_HighConfidence'] = df_umap[advanced_cols].all(axis=1)
summary['High-Confidence'] = df_umap['Outlier_HighConfidence'].sum()print("--- Final Outlier Detection Summary ---")
print(f"Euclidean Distance: {summary['Outlier_Euclidean']}")
print(f"Mahalanobis Distance: {summary['Outlier_Mahalanobis']}")
print(f"Local Outlier Factor: {summary['Outlier_LOF']}")
print(f"Isolation Forest: {summary['Outlier_ISO']}")
print("---------------------------------")
print(f"High-Confidence Outliers (Mahalanobis AND LOF AND ISO): {summary['High-Confidence']}")
这份总结清晰地阐明了我们迄今为止发现的一切。
--- Final Outlier Detection Summary ---
Euclidean Distance: 506
Mahalanobis Distance: 0
Local Outlier Factor: 0
Isolation Forest: 30
---------------------------------
High-Confidence Outliers (Mahalanobis AND LOF AND ISO): 0
结果很清楚,因为马哈拉诺比斯和LOF非常保守,根据我们严格的定义,我们有零个高置信度异常值。这是一个有价值的见解!它告诉我们,隔离森林发现的30个异常值是一种独特的异常类型,它们在结构上不同且易于隔离,但在统计上并不远离中心,也不在特别稀疏的区域。
对于我们的分析,隔离森林的结果是最有趣和可操作的。因此,我们将使用它们作为我们主要的异常集。
让我们可视化我们最终的聚类,并在其上检测到的异常。
def plot_outliers_final_comparison(df_plot): """Plots the UMAP projection, highlighting outliers from different methods with a focus on high-confidence ones."""fig, ax = plt.subplots(figsize=(12, 9))sns.scatterplot( data=df_plot, x="UMAP1", y="UMAP2", hue="Class Name", palette="viridis", alpha=0.4, ax=ax )iso_only = df_plot[(df_plot["Outlier_ISO"] == True) & (df_plot["Outlier_HighConfidence"] == False)] sns.scatterplot( data=iso_only, x="UMAP1", y="UMAP2", color="orange", marker="s", s=70, label="Isolation Forest Only", ax=ax, alpha=0.7 )lof_only = df_plot[(df_plot["Outlier_LOF"] == True) & (df_plot["Outlier_HighConfidence"] == False)] sns.scatterplot( data=lof_only, x="UMAP1", y="UMAP2", facecolors="none", edgecolors="cyan", marker="o", s=100, label="LOF Only", ax=ax, linewidth=1.5 )maha_only = df_plot[(df_plot["Outlier_Mahalanobis"] == True) & (df_plot["Outlier_HighConfidence"] == False)] sns.scatterplot( data=maha_only, x="UMAP1", y="UMAP2", color="magenta", marker="D", s=70, label="Mahalanobis Only", ax=ax, alpha=0.7 )high_conf_outliers = df_plot[df_plot["Outlier_HighConfidence"] == True] sns.scatterplot( data=high_conf_outliers, x="UMAP1", y="UMAP2", color="red", marker="X", s=250, label="High-Confidence Outlier (All 3)", ax=ax )sns.move_legend(ax, "upper left", bbox_to_anchor=(1, 1)) plt.title("UMAP Projection of Newsgroup Embeddings with Outlier Comparison") plt.xlabel("UMAP Dimension 1") plt.ylabel("UMAP Dimension 2")plt.show()
plot_outliers_final_comparison(df_umap)
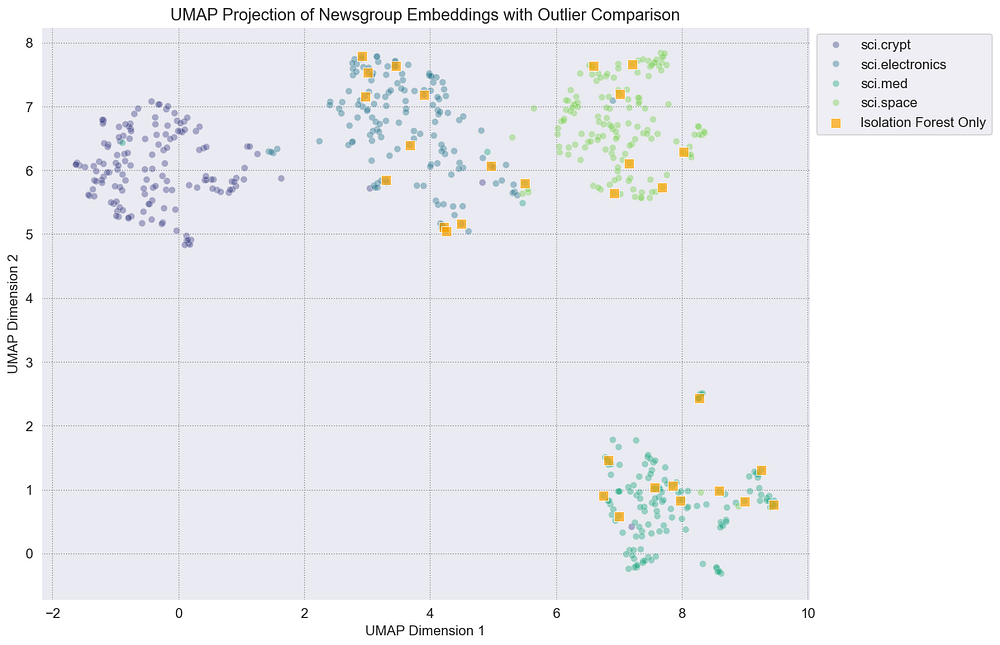
聚类内的异常
太棒了,现在我们已经能够找到数据中的一些异常,我们可以进入解释其原因的部分。
2.8 使用 LLM 进行语义解释
我们已经成功识别出潜在的异常值。但要使这个管道真正有用,我们需要理解为什么一个文档被认为是异常值。仅仅有一个标记项目的列表是不够的;我们需要上下文。
这就是我们完成AI和机器学习集成愿景的地方。我们现在将使用一个强大的指令调整大型语言模型(meta-llama/Meta-Llama-3.1-8B-Instruct)作为我们的数据分析师。
用于语义的可解释AI
过程如下:
- 我们选择隔离森林发现的30个异常值中的一个。
- 我们从_同一类别_中获取几个“正常”(inlier)文档作为比较的基线。
- 我们将所有这些信息打包成一个精心设计的提示,并将其发送给LLM。
- 我们要求LLM提供一个简洁、人类可读的解释,说明为什么该异常文档在语义上与正常文档不同。
让我们首先定义处理此交互的函数。
def explain_outlier_with_llm(client, outlier_doc, inlier_docs, category, model_name): """Uses a configured LLM to generate an explanation for an outlier."""inlier_text = "\n\n".join([f"--- Normal Document {i+1} ---\n{doc}" for i, doc in enumerate(inlier_docs)])system_prompt = "You are an expert data analyst. Your task is to explain why a document is a semantic outlier within its given category. Analyze the content and themes, and provide a concise, one-paragraph explanation highlighting the key differences."user_message = f""" Category: '{category}'--- Outlier Document --- {outlier_doc}{inlier_text}**Explanation of the Outlier:** """messages = [ {"role": "system", "content": system_prompt}, {"role": "user", "content": user_message} ]response = client.chat.completions.create( model=model_name, messages=messages, temperature=0.3, max_tokens=256 )return response.choices[0].message.content.strip()
现在,让我们从sci.electronics类别中选择一个被隔离森林模型标记的异常值,并请求LLM进行分析。
outlier_to_explain = df_umap[df_umap['Outlier_ISO'] == True].iloc[0]inliers = df_umap[ (df_umap['Class Name'] == outlier_to_explain['Class Name']) & (df_umap['Outlier_ISO'] == False)
]
inlier_examples = inliers.sample(3, random_state=42)['Text'].tolist()print("--- GENERATING EXPLANATION FOR OUTLIER ---\n")
print(f"Category: {outlier_to_explain['Class Name']}\n")
print(f"**Outlier Document Text:**\n{outlier_to_explain['Text']}")
print("\n----------------------------------------\n")explanation = explain_outlier_with_llm( client, outlier_to_explain['Text'], inlier_examples, outlier_to_explain['Class Name'], model_name="meta-llama/Meta-Llama-3.1-8B-Instruct"
)print(f"**LLM Explanation:**\n{explanation}")
输出正是我们所寻求的洞察。
--- GENERATING EXPLANATION FOR OUTLIER ---Category: sci.electronics**Outlier Document Text:** Re: Radar detector DETECTORS?
Organization: Kansas State University 23
NNTP-Posting-Host: matt.ksu.ksu.edu writes:
>It used to be that the only way the law could be enforced was for
>an officer to actually see the radar detector. Not any more! Many
>law enforcement agencies are now using radar detector detectors.
...
From what I understand about radar dectectors all they are is a passive
device much like the radio in your car... Therefore there would
be no way of detecting a radar detector...Neal Howland
----------------------------------------**LLM Explanation:**
The outlier document in the "sci.electronics" category is a discussion about
radar detector detectors, which are devices used by law enforcement to detect
the presence of radar detectors in vehicles. This document stands out from
the other documents in the category because it is the only one that does not
focus on a technical or engineering aspect of electronics. Instead,
it discusses a social and legal issue related to the use of radar detectors,
and how law enforcement agencies are using technology to ...
LLM智能地分类,尽管该文档与电子产品相关,但其主题是关于法律和社会政策,而不是sci.electronics组中典型的技术规范或维修问题。
它成功地弥合了数值异常分数与定性、人类可理解的原因之间的鸿沟。这使得我们的整个管道不仅仅是一个检测工具,而是一个可操作的洞察引擎。
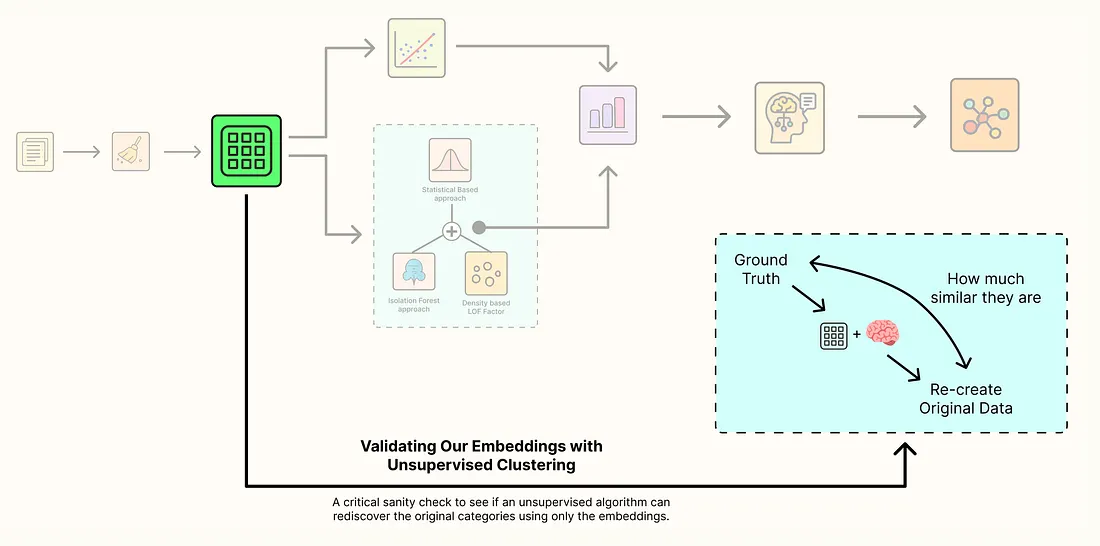
3 通过无监督聚类验证我们的嵌入
我们的主要目标是找到异常值,我们已经成功做到了。但我们的管道还有另一个重要组成部分,那就是所有600个文档的高质量、4096维嵌入。
这引出了一个有趣的问题……
这些嵌入是否足以让机器在没有任何标签的情况下,自行重新发现原始的四个科学类别?
嵌入验证
这是经典的无监督聚类任务。我们将假装不知道任何文档的Class Name,并要求算法根据它们的语义相似性将它们分组到四个聚类中。如果机器创建的聚类与原始的真实类别很好地吻合,这将极大地增强我们对整个管道质量的信心,从嵌入模型到我们的UMAP可视化。
验证流程
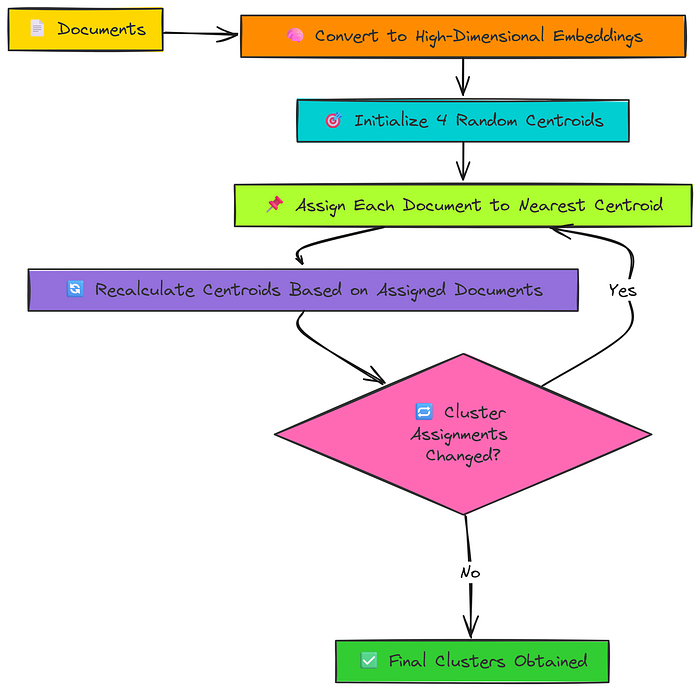
对于此任务,我们将使用最著名的聚类算法之一:K-Means。
K-Means背后的逻辑非常直观:
- 它首先在我们的高维嵌入空间中随机放置四个“质心”(聚类中心)。
- 然后,它将我们的600个文档中的每个文档分配给最近的质心。
- 接下来,它重新计算每个质心的位置,使其成为分配给它的所有文档的新中心。
- 它重复步骤2和3,直到聚类分配不再改变。
让我们编写一个函数来将K-Means应用于我们的嵌入。我们将设置n_clusters=4,因为我们从初始数据采样中知道有四个不同的科学类别我们正在尝试重新发现。
def apply_kmeans(df, n_clusters=4, random_state=42): """Applies K-Means clustering to the embeddings and adds cluster labels to the DataFrame."""embeddings = np.vstack(df['Embeddings'])kmeans = KMeans(n_clusters=n_clusters, random_state=random_state, n_init=10) df['KMeans_Cluster'] = kmeans.fit_predict(embeddings)print("K-Means clustering complete. Cluster labels added to the DataFrame.") return df
现在,让我们运行聚类并查看算法的性能。
df_umap = apply_kmeans(df_umap, n_clusters=4)
df_umap DataFrame现在有一个新列KMeans_Cluster,其中包含算法分配给每个文档的聚类ID(0、1、2或3)。
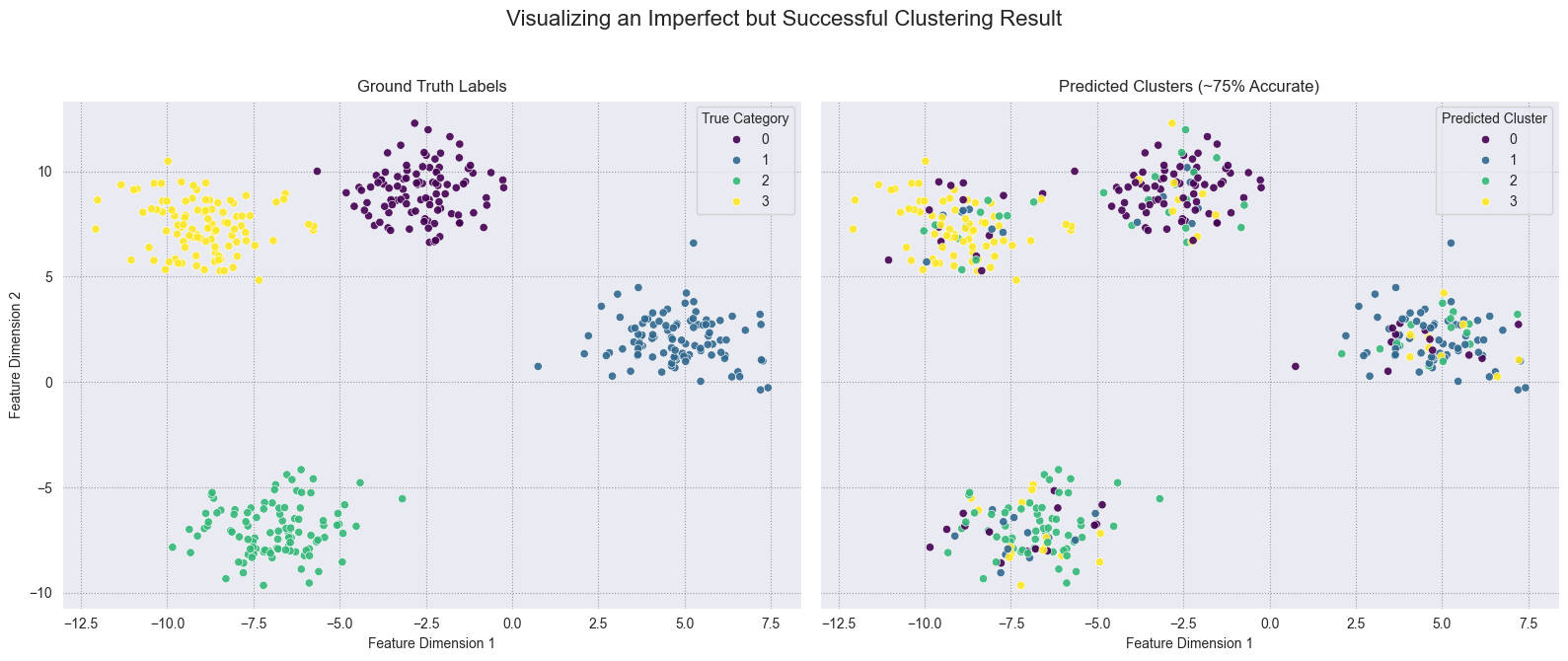
判断结果最有效的方法是将其可视化。我们将创建一个并排比较:
- 左侧,一个按原始真实标签(
sci.crypt、sci.med等)着色的图。 - 右侧,完全相同的图,但按K-Means预测的聚类标签着色。
如果我们的嵌入良好,这两个图应该看起来非常相似。
def plot_kmeans_vs_ground_truth(df_plot): """Creates a side-by-side plot comparing K-Means clusters to ground truth labels.""" fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(16, 7), sharey=True, sharex=True)sns.scatterplot(data=df_plot, x='UMAP1', y='UMAP2', hue='Class Name', palette='viridis', ax=ax1, alpha=0.8) ax1.set_title('Ground Truth Labels') ax1.legend(title='Category')sns.scatterplot(data=df_plot, x='UMAP1', y='UMAP2', hue='KMeans_Cluster', palette='viridis', ax=ax2, alpha=0.8) ax2.set_title('K-Means Predicted Clusters') ax2.legend(title='Cluster ID')fig.suptitle('UMAP Projection: Ground Truth vs. K-Means Clustering', fontsize=16) plt.tight_layout(rect=[0, 0, 1, 0.96]) plt.show()
plot_kmeans_vs_ground_truth(df_umap)
嵌入验证
右侧的图清楚地表明,K-Means在没有任何先验知识的情况下,重新发现了原始四个科学群体的基本结构。
它证明了我们的BAAI/bge-en-icl嵌入成功地以语义上有意义的方式组织了文档,其中不同的主题形成了大致不同的聚类。核心群体被清晰地识别出来。
请注意,错误主要发生在主题自然重叠的模糊边界处……
例如,一个文档可能同时讨论**“医学”和“电子”**主题。这并非算法的失败,而是数据复杂性的真实反映。
在混乱的文本上进行完全无监督的任务,达到约65%的准确率是一个很好的起点,可以深入研究,这使我们对嵌入的质量和我们之前识别的异常值的有效性充满信心。
4 我们接下来可以做什么?
我们的管道展示了一种在文本中发现有意义异常的现代方法。通过结合高质量的嵌入、机器学习算法和LLM驱动的解释,我们构建了一个有效且可操作的系统。
以下是我们已完成的工作以及这项工作可能带来的未来方向的总结:
- 建立了稳健的工作流程:我们证明了结合多种高级算法(如隔离森林)可以比任何单一方法提供更细致、更可靠的异常视图。
- 验证了我们的嵌入:我们成功的K-Means聚类实验证实,嵌入模型创建了一个高质量、语义上有意义的空间,这是整个管道的基础。
- 实现了真正的可解释性:我们超越了仅仅_发现_异常值,而是_理解_它们,使用LLM自动生成清晰、人类可读的解释,说明为什么一个文档是异常的。
- 未来工作1:领域特定微调:下一步是在专门数据集(例如,法律或医学文本)上微调嵌入模型,以实现更高的准确性并捕捉领域特定的细微差别。
- 未来工作2:完全自动化监控:整个管道可以自动化,以创建一个实时监控系统,该系统摄取新数据、标记异常并直接向分析师的收件箱提供LLM生成的解释。