03.【Linux系统编程】基础开发工具1(yum软件安装、vim编辑器、编辑器gcc/g++)
目录
1. 软件包管理器
1.1 什么是软件包
1.2 Linux软件生态
1.3 yum具体操作
1.3.1 查看软件包
1.3.2 安装软件
1.3.3 卸载软件
1.3.4 注意事项(测试网络)
1.3.5 yum指令集总结
1.4 yum源目录、安装源
2. Vim编辑器的使用
2.1 Linux编辑器-vim使用
2.2 vim的基本概念
2.3 vim基本操作
2.3.1 模式切换
2.3.2 正常模式命令集
2.3.3 末行模式命令集
2.3.4 其他模式命令集(批量添加/删除)
2.3.5 补充命令
3. 编译器gcc/g++
3.1 gcc编译
3.1.1 预处理(进行宏替换)
3.1.2 编译(生成汇编)
3.1.3 汇编(生成机器可识别代码)
3.1.4 链接(生成可执行文件或库文件)
3.2 动态链接和静态链接
3.3 静态库和动态库
3.4 条件编译用途,为什么C/C++编译时要转汇编
3.5 gcc其他常用选项(了解)
1. 软件包管理器
1.1 什么是软件包
Linux安装软件的三种方式:
1. 下载到程序的源代码, 并进行编译, 得到可执行程序.
2. ".rpm"文件,一种软件包格式,这种格式的文件扩展名通常是 .rpm。它包含了编译好的软件二进制文件、配置文件、文档以及安装/卸载脚本。(不包含软件依赖)
3. 包管理器(推荐),会分析软件依赖关系,并自动从软件仓库下载并安装所有必需的依赖包。
•Centos: yum(Yellow dog Updater, Modified)是Linux下非常常用的一种包管理器. 主要应用在Fedora,RedHat, Centos等发行版上.
• Ubuntu:主要使用apt(Advanced Package Tool)作为其包管理器。apt同样提供了自动解决依赖关系、下载和安装软件包的功能。
注意:安装软件需要root权限。
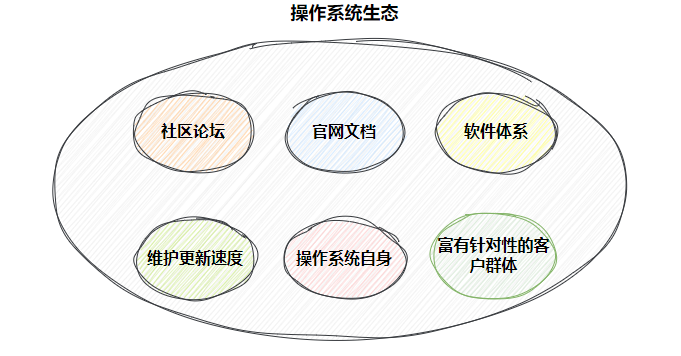
1.2 Linux软件生态
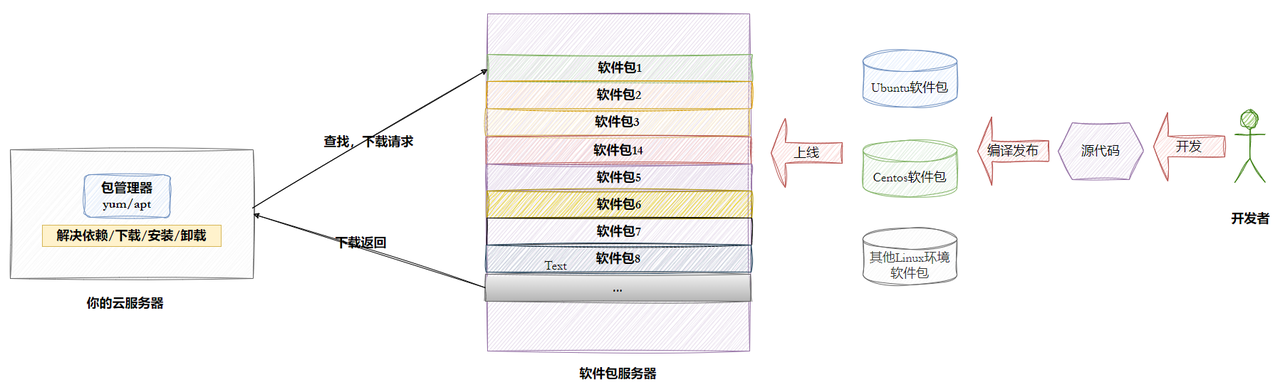
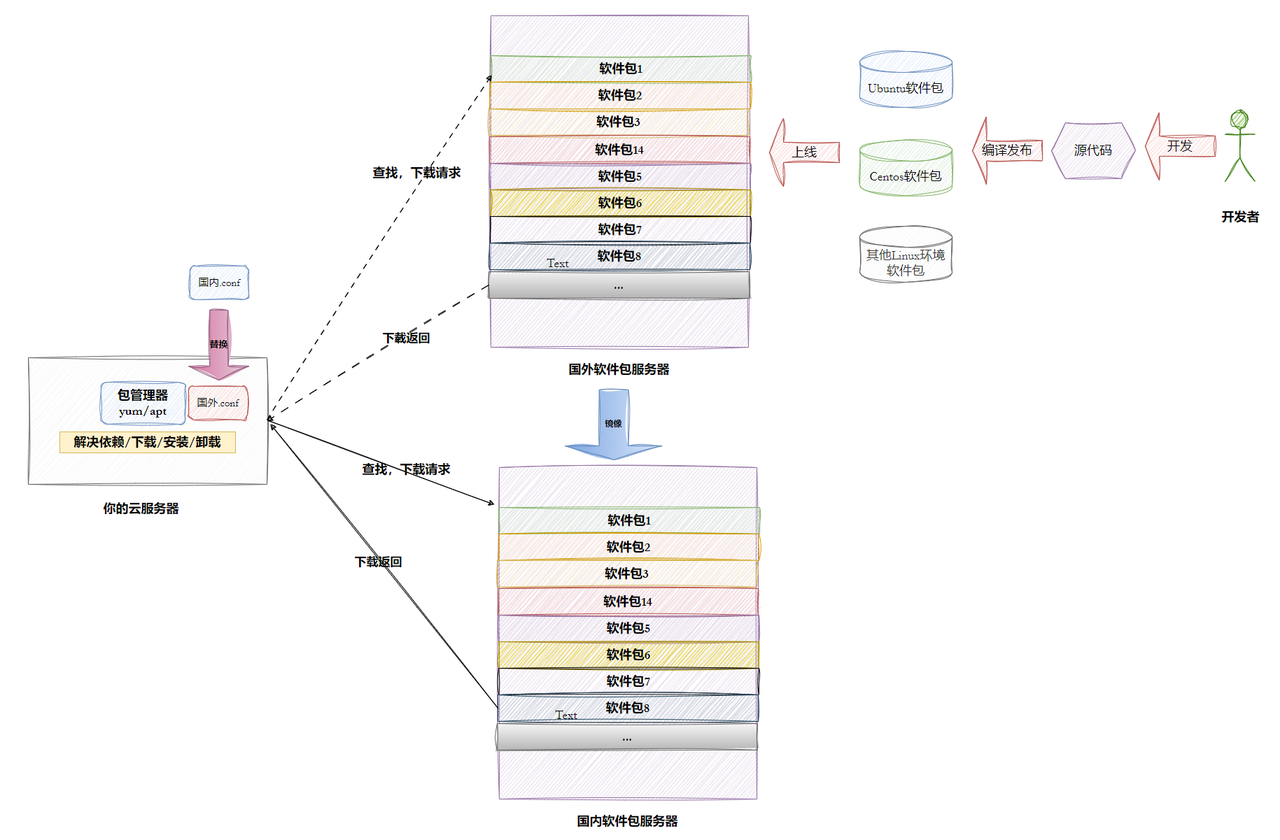
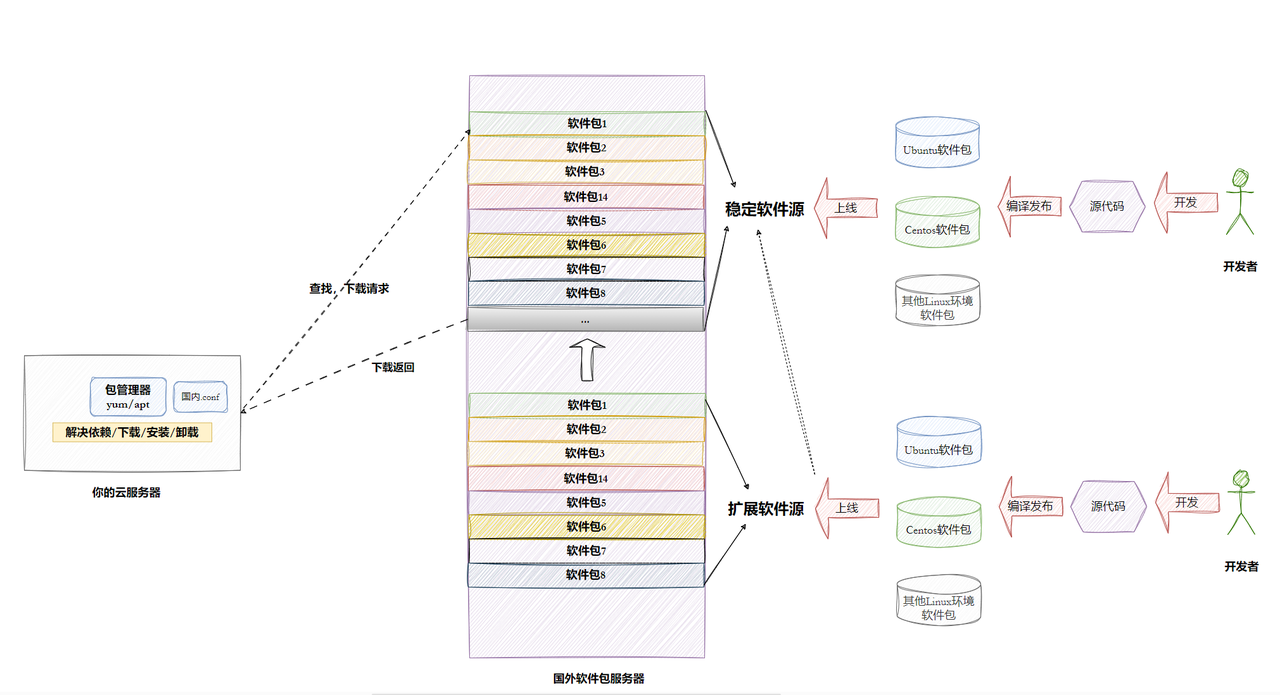
1. Linux下载软件的过程(Ubuntu、Centos、other)
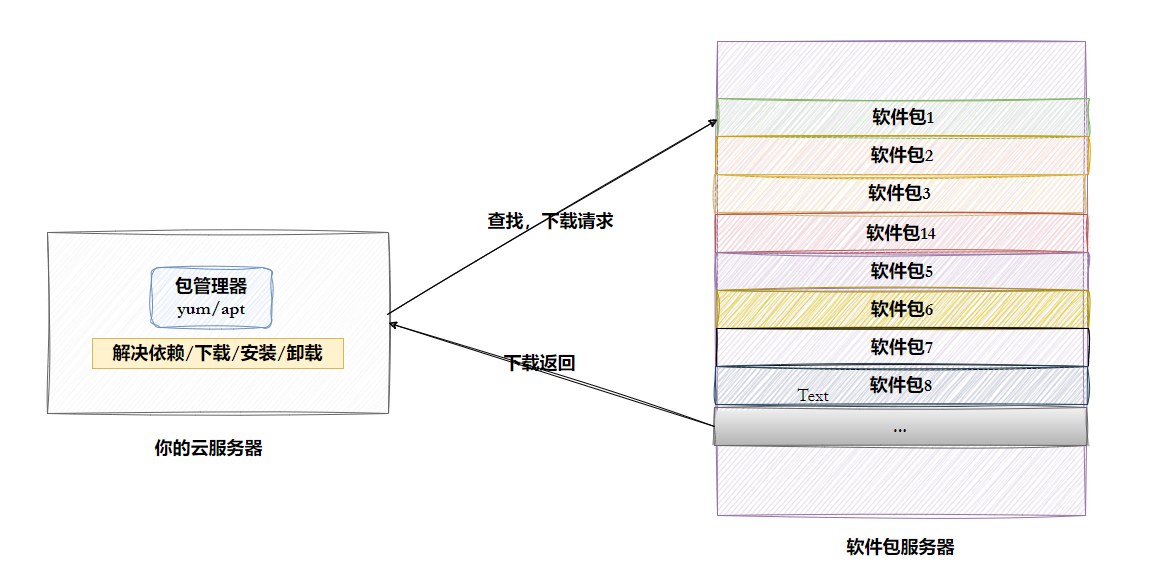
2. 操作系统的好坏评估--- 生态问题
3. 为什么会有人免费特定社区提供软件,还发布?还提供云服务器让你下载?
| 驱动方 | 主要动机 | 获得回报 |
| 个人开发者 | 理想主义、解决自身需求、获得声誉 | 名誉、技术提升、更好的就业机会 |
| 开源社区 | 协作精神、互利共赢 | 更好的软件、强大的生态 |
| 商业公司 | 构建生态、降低行业成本、制定标准 | 销售增值服务、支持服务、托管服务 |
| 云服务商 | 吸引用户使用其高利润的云平台 | 丰厚的云服务收入(远超带宽成本) |
所以,这并非纯粹的利他主义。这是一个精心设计的、多方共赢的生态系统:个人获得名誉,企业获得人才和创新,公司获得利润,社会获得技术进步。 免费提供软件和下载,只是这个庞大生态系统得以运转的“入门成本”和“流量入口”。
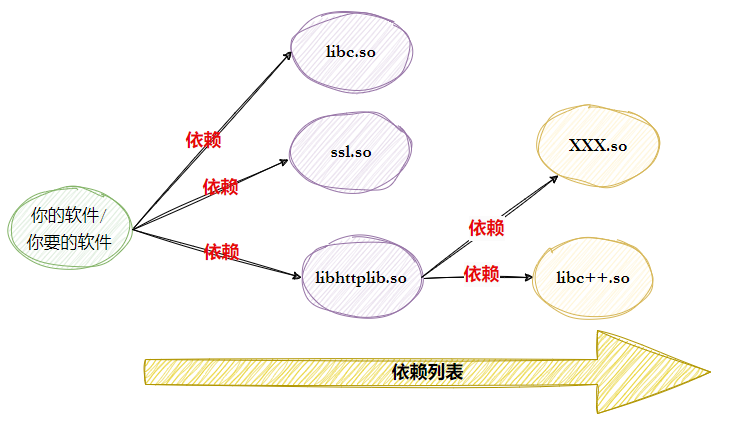
4. 软件包依赖的问题
5. 国内镜像源
1.3 yum具体操作
1.3.1 查看软件包
通过 yum list 命令可以罗列出当前一共有哪些软件包. 由于包的数目可能非常之多, 这里我们需要使用grep 命令只筛选出我们关注的包. 例如:
# Centos,yum list加grep寻找lrzsz
yum list | grep lrzsz
# lrzsz.x86_64 0.12.20-36.el7 @base# 注意事项:
# 软件包名称: 主版本号.次版本号.源程序发行号-软件包的发行号.主机平台.cpu架构.
# "x86_64" 后缀表示64位系统的安装包, "i686" 后缀表示32位系统安装包. 选择包时要和系统匹配.
# "el7" 表示操作系统发行版的版本. "el7" 表示的是 centos7/redhat7. "el6" 表示 centos6/redhat6.
# 最后一列, base 表示的是 "软件源" 的名称, 类似于 "小米应用商店", "华为应用商店" 这样的概念.1.3.2 安装软件
通过 yum, 我们可以通过很简单的一条命令完成 lrzsz的安装.
# Centos
# sudo yum install -y [软件名]
$ sudo yum install -y lrzsz# Ubuntu
$ sudo apt install -y lrzsz# yum/apt 会自动找到都有哪些软件包需要下载, 这时候敲 "y" 确认安装.
# 出现 "complete" 字样或者中间未出现报错, 说明安装完成.
# 注意事项:
# 安装软件时由于需要向系统目录中写入内容, 一般需要 sudo 或者切到 root 账户下才能完成.
# yum/apt安装软件只能一个装完了再装另一个. 正在yum/apt安装一个软件的过程中, 如果再尝试用yum/apt安装另外一个软件, yum/apt会报错.
1.3.3 卸载软件
# Centos
sudo yum remove [-y] lrzsz# Ubuntu
sudo apt remove [-y] lrzsz1.3.4 注意事项(测试网络)
关于 yum / apt 的所有操作必须保证主机(虚拟机)网络畅通!!!
可以通过 ping 指令验证
ping www.baidu.com1.3.5 yum指令集总结
| 指令 | 功能 |
| yum install | 安装软件包 |
| yum list | 列出所有可供安装的软件包 |
| yum search | 搜索包含指定关键字的软件包 |
| yum remove | 写在指定的软件包 |
| yum makecache | 将软件包信息缓存到本地 |
| yum search | 用于在搜索包含有指定关键字的软件包 |
| yum clean all | 清理老旧的缓存信息 |
| yum update | 升级所有包同时,也升级软件和系统内核 |
| yum upgrade | 只升级所有包,不升级软件和系统内核,软件和内核保持原样 |
1.4 yum源目录、安装源
Cetnos 安装源路径:
# /etc/yum.repos.d/ 目录下存放的.reps文件就是是各种应用下载源
$ ll /etc/yum.repos.d/
total 16
-rw-r--r-- 1 root root 676 Oct 8 20:47 CentOS-Base.repo # 标准源
-rw-r--r-- 1 root root 230 Aug 27 10:31 epel.repo # 扩展源# 安装扩展源,方便课堂演示
# $ sudo yum install -y epel-release
2. Vim编辑器的使用
2.1 Linux编辑器-vim使用
vi/vim的区别简单点来说,它们都是多模式编辑器,不同的是vim是vi的升级版本,它不仅兼容vi的所有指令,而且还有一些新的特性在里面。例如语法加亮,可视化操作不仅可以在终端运行,也可以运行于x window、 mac os、 windows。我们课堂上,统一按照vim来进行讲解。
2.2 vim的基本概念
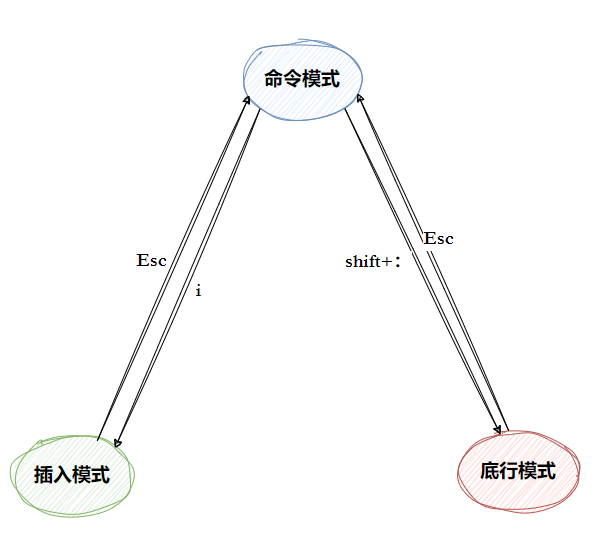
vim三种基础的模式分别是普通模式(Normal mode)、插入模式(Insert mode)和底行模式(last line mode),各模式的功能区分如下:
• 正常/普通/命令模式(Normal mode)
控制屏幕光标的移动,字符、字或行的删除,移动复制某区段及进入Insert mode下,或者到 lastline mode
• 插入模式(Insert mode)
只有在Insert mode下,才可以做文字输入,按「ESC」键可回到命令行模式。该模式是我们后面用的最频繁的编辑模式。
• 末行/底行模式(last line mode)
文件保存或退出,也可以进行文件替换,找字符串,列出行号等操作。
在命令模式下,*shift+:* 即可进入该模式。要查看你的所有模式:打开 vim,底行模式直接输入:help vim-modes(应该一共有12种模式:six BASIC modes和six ADDITIONAL modes.)
2.3 vim基本操作
2.3.1 模式切换
| 功能 | 指令 |
| 进入vim(默认正常模式) | vim test.c |
| 正常模式→插入模式 | a 或 i 或 o |
| 插入模式→正常模式 | Esc |
| 正常模式→末行模式 | shift+; |
| 末行模式退出/保存文件指令 | |
| 保存 | w |
| 保存并退出 | wq |
| 不存强制退出 | q! |
2.3.2 正常模式命令集
| 功能 | 命令 | 具体功能 |
| 正常→插入模式 | i | 从光标当前位置开始输入文件; |
| a | 从目前光标所在位置的下一个位置开始输入文字; | |
| o | 插入新的一行,从行首开始输入文字。 | |
| 移动光标 | h\j\k\l | 「h」「j」「k」「l」,分别控制光标左、下、上、右移一格。(光标移动可以带数字#[n]) |
| G | 移动到文章的最后 | |
| $ | 移动到光标所在行的“行尾” | |
| ^ | 移动到光标所在行的“行首” | |
| w | 光标跳到下个单词的开头(可带数字) | |
| e | 光标跳到下个单词的字尾(可带数字) | |
| b | 光标回到上个单词的开头(可带数字) | |
| #l | 光标移到该行的第#个位置,如:5l,56l | |
| gg | 进入到文本开始 | |
| shift+g | 进入文本末端 | |
| Ctrl+b | 屏幕往“后”移动一页 | |
| Ctrl+f | 屏幕往“前”移动一页 | |
| Ctrl+u | 屏幕往“后”移动半页 | |
| Ctrl+d | 屏幕往“前”移动半页 | |
| 删除/剪切 | x | 每按一次,删除光标所在位置的一个字符 |
| #x | 例如,「6x」表示删除光标所在位置的“后面(包含自己在内)”6个字符 | |
| X | 大写的X,每按一次,删除光标所在位置的“前面”一个字符 | |
| #X | 例如,「20X」表示删除光标所在位置的“前面”20个字符 | |
| dd | 删除光标所在行 | |
| #dd | 从光标所在行开始删除#行 | |
| 复制 | yw | 将光标所在之处到字尾的字符复制到缓冲区中。 |
| #yw | 复制#个字符到缓冲区 | |
| yy | 复制光标所在行到缓冲区。 | |
| #yy | 例如,「6yy」表示拷贝从光标所在的该行“往下数”6行文字。 | |
| p | 将缓冲区内的字符贴到光标所在位置。注意:所有与“y”有关的复制命令都必须与“p”配合才能完成复制与粘贴功能。(可带数字,粘贴n次) | |
| 替换模式 | r | 替换光标所在处的字符。 |
| R | 替换光标所到之处的字符,直到按下「ESC」键为止。 | |
| 更改 | cw | 更改光标所在处的字到字尾处 |
| c#w | 例如,「c3w」表示更改3个字 | |
| 查找 | shift+3=# | 选中单词 |
| n | 逆向查找,N正向查找 | |
| 跳至指定的行 | Ctrl+g | 列出光标所在行的行号。 |
| #G | 例如,「15G」,表示移动光标至文章的第15行首。(也可使以小写模式的shift+g) | |
| 大小写切换 | shift+~ | 大小写切换 |
| 撤销上一次操作 | u | 如果您误执行一个命令,可以马上按下「u」,回到上一个操作。按多次“u”可以执行多次回复。 |
| Ctrl+r | 撤销的恢复 |
2.3.3 末行模式命令集
| 功能 | 命令 | 具体功能 |
| 正常→末行模式 | Esc→: | 先Esc进入正常模式,shift+; 进入末行模式 |
| 列出行号 | set nu | 输入「set nu」后,会在文件中的每一行前面列出行号。 |
| 取消行号 | set nonu | 取消行号 |
| 按行号跳转 | # | 「#」号表示一个数字,在冒号后输入一个数字,再按回车键就会跳到该行了,如输入数字15,再回车,就会跳到文章的第15行。 |
| 查找 | /关键字 | 先按「/」键,再输入您想寻找的字符,如果第一次找的关键字不是您想要的,可以一直按「n」会往后寻找到您要的关键字为止。 |
| 保存文件 | w | 在冒号后输入字母「w」就可以将文件保存起来 |
| 离开vim(在wq、w、q后面跟!可以强制执行。) | q | 按「q」就是退出,如果无法离开vim,可以在「q」后跟一个「!」强制离开vim。 |
| wq | 一般建议离开时,搭配「w」一起使用,这样在退出的时候还可以保存文件。 | |
| 命令行模式 | ! | 在 ! 后面直接输入命令,可以在vim中执行命令行操作。 |
| 批量替换 | %s/src/dst/g | 将src字串替换为dst;s是substitute的缩写;%是指整个文件,不加%默认当前行;/g全局替换(一行内所有匹配项)不加 g 则只换每行的第一个 。 |
| 分屏操作 | vs new_src | 分屏给new_src |
| Ctrl+ww | 切换分屏(正常模式下执行) |
2.3.4 其他模式命令集(批量添加/删除)
1. 视图模式(批量添加/删除)
| 1. 正常模式→视图模式 | Ctrl+v |
| 2. 移动光标,选中区域 | 同正常模式 |
| 3.1 批量添加 | |
| 视图模式→(特殊)插入模式 | shift+i=I |
| 在光标所在行添加内容 | |
| 按下Esc键退出,则在光标选中的所有区域添加相同内容 | |
| 3.2 批量删除 | |
| 按d删除选中区域内容 |
2. 替换模式
| 替换模式 | r | 替换光标所在处的字符。 |
| R | 替换光标所到之处的字符,直到按下「ESC」键为止。(也可用小写的shift+r) |
2.3.5 补充命令
1. 打开时指定光标位置
# 打开文件并让光标跳转到15行
vim test.c +152.执行上一次带#的操作
!v
#执行上一次vim test.c +15的操作,直接打开3. 编译器gcc/g++
编译流程的四个步骤:
1. 预处理(进行宏替换/去注释/条件编译/头文件展开等)
2. 编译(生成汇编)
3. 汇编(生成机器可识别代码)
4. 链接(生成可执行文件或库文件)
3.1 gcc编译
gcc编译格式
gcc [选项] 要编译的文件 [选项] [目标文件]单文件编译
# 两种格式都可以
gcc code.c -o codegcc -o code code.c多文件编译
gcc main.c code1.c code2.c -o code
# 将main.c code1.c code2.c编译生成一个code文件# 两种写法都可以
gcc -o code main.c code1.c code2.c3.1.1 预处理(进行宏替换)
预处理功能主要包括宏定义,文件包含,条件编译,去注释等。
预处理指令是以#号开头的代码行。
#实例:
gcc –E hello.c –o hello.i
# •选项“-E”,该选项的作用是让 gcc 在预处理结束后停止编译过程。
# •选项“-o”是指目标文件,“.i”文件为已经过预处理的C原始程序。
3.1.2 编译(生成汇编)
• 在这个阶段中,gcc 首先要检查代码的规范性、是否有语法错误等,以确定代码的实际要做的工作,在检查无误后,gcc 把代码翻译成汇编语言。
#实例:
gcc –S hello.i –o hello.s# 用户可以使用“-S”选项来进行查看,该选项只进行编译而不进行汇编,生成汇编代码。3.1.3 汇编(生成机器可识别代码)
• 汇编阶段是把编译阶段生成的“.s”文件转成目标文件
# 实例:
gcc –c hello.s –o hello.o
# •读者在此可使用选项“-c”就可看到汇编代码已转化为“.o”的二进制目标代码了# 补:不指定目标文件,会生成同名.o文件
gcc -c code.c3.1.4 链接(生成可执行文件或库文件)
# 实例
gcc hello.o –o hello3.2 动态链接和静态链接
简单来讲:静态链接是将库中实现好的方法拷贝到我们的程序中执行。动态链接是找到库中方法的地址,跳转到库中执行方法,之后跳转回来。静态链接实际是拷贝,动态链接实际是寻址。
1. 静态链接
实际开发中,程序由多个源文件(.c)组成,它们相互调用,存在依赖关系。每个 .c 文件都会独立编译成目标文件(.o),静态链接负责把这些 .o 文件“打包”成一个完整的可执行程序。(注意:1.打包的是编译好的二进制目标代码.o文件;2.按需打包,只提取使用了的函数所在的目标文件;3.静态库只有在链接的时候有用,一旦形成可执行程序,静态库可以不再需要)
缺点:
1. 浪费空间:如果多个程序都用了同一个函数(如 printf),那么每个程序里都会有一份这个函数的完整代码副本,导致磁盘和内存中存在多份重复内容。
2. 更新困难:一旦库代码有更新,所有依赖它的程序都必须重新编译链接才能生效。
优点:
部署简单,运行快:因为可执行程序自成一体,无需外部依赖,直接就能运行。
2. 动态链接
动态链接的出现解决了静态链接中提到问题。动态链接的基本思想是把程序按照模块拆分成各个相对独立部分,在程序运行时才将它们链接在一起形成一个完整的程序,而不是像静态链接一样把所有程序模块都打包,形成一个单独的可执行文件。(动态链接在编译阶段向对应位置写入需要执行的方法的地址,运行时根据地址跳转到动态库对应位置执行对应的方法)
动态链接其实远比静态链接要常用得多。比如我们查看下hello 这个可执行程序依赖的动态库,会发现它就用到了一个c动态链接库
$ ldd hellolinux-vdso.so.1 => (0x00007fffeb1ab000)libc.so.6 => /lib64/libc.so.6 (0x00007ff776af5000)/lib64/ld-linux-x86-64.so.2 (0x00007ff776ec3000)# ldd 用来查看程序或者库文件所依赖的共享库列表。3. 动静态链接对比:
1. 动态库形成的可执行程序体积一定很小
2. 可执行程序对静态库的依赖度小,而动态库不能缺失
3. 程序运行,需要加载到内存,静态链接的,会在内存中出现大量的重复代码
4. 动态链接,比较节省内存和磁盘资源。
4. 为什么要汇编生成.o文件
动静态库的本质是打包起来的.o文件。所以在整个编译过程要进行汇编生成.o文件,然后使我的.o文件和动静态库中的.o文件链接生成可执行程序。
3.3 静态库和动态库
库是一套方法或者数据集,为我们开发提供最基本的保证(基本接口,功能,加速我们二次开发)
动静态库的本质是打包起来的.o文件。
• 静态库是指编译链接时,把库文件的代码全部加入到可执行文件中,因此生成的文件比较大,但在运行时也就不再需要库文件了。静态库后缀名一般为“.a”
• 动态库与之相反,在编译链接时并没有把库文件的代码加入到可执行文件中,而是在程序执行时由运行时链接文件加载库,这样可以节省系统的开销。动态库一般后缀名为“.so”,如前面所述的libc.so.6 就是动态库。gcc 在编译时默认使用动态库。完成了链接之后,gcc 就可以生成可执行文件,如下所示。gcc hello.o –o hello
• gcc默认生成的二进制程序,是动态链接的,这点可以通过file 命令验证。
# file可以查看文件是动态链接还是静态链接
$ file code
#code: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), dynamically linked (uses shared libs), for GNU/Linux 2.6.32, BuildID[sha1]=e8625d13488f2780664671d6e3802e4c0e08abe3, not stripped
# dynamically linked (uses shared libs)
# 动态链接(使用共享库)
补:一般我们的云服务器,C/C++的静态库并没有安装,可以采用如下方法安装
# Centos
# 安装C静态库
sudo yum install glibc-static# 安装C++静态库
sudo yum install libstdc++-static3.4 条件编译用途,为什么C/C++编译时要转汇编
1. 条件编译的用途
1. 软件进行专业度,收费情况进行区分(业务),使用条件编译,可以进行代码动态裁剪
2. 内核源代码也是采用条件编译进行代码裁剪
3. 开发工具,应用软件。
2. 为什么C/C++编译,要先变成汇编。
没出现C之前:汇编语言 → 二进制
出现了C之后:C语言 → 汇编语言 → 二进制(复用之前汇编转二进制,使得C只需要完成C转汇编,实现更简单)
3.5 gcc其他常用选项(了解)
| 选项 | 功能 |
| -E | 只激活预处理,这个不生成文件,你需要把它重定向到一个输出文件里面 |
| -S | 编译到汇编语言不进行汇编和链接 |
| -c | 编译到目标代码 |
| -o | 文件输出到 文件 |
| -static | 此选项对生成的文件采用静态链接 |
| -g | 生成调试信息。GNU 调试器可利用该信息。 |
| -shared | 此选项将尽量使用动态库,所以生成文件比较小,但是需要系统由动态库. |
| -O0、-O1、 -O2、-O3 | 编译器的优化选项的4个级别,-O0表示没有优化,-O1为缺省值,-O3优化级别最高 |
| -w | 不生成任何警告信息。 |
| -Wall | 生成所有警告信息。 |