MLLM学习~M3-Agent Prompt学习
Prompt
“输入→处理→输出→评估” 全流程
Prompt 并非孤立存在,形成了完整的视频理解链路:
视频原始数据(语音 / 图像)→ 模块 1(提取语音 + 绑定人物 ID)→ 模块 2(生成情景记忆描述)→ 模块 3(生成语义记忆推理)→ 模块 4(基于记忆问答 / 检索)→ 模块 5(评估结果质量)→ 模块 6(优化结果格式)
第一个模块原文
# Copyright (2025) Bytedance Ltd. and/or its affiliates# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at# http://www.apache.org/licenses/LICENSE-2.0# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.prompt_audio_segmentation = """You are given a video. Your task is to perform Automatic Speech Recognition (ASR) and audio diarization on the provided video. Extract all speech segments with accurate timestamps and segment them by speaker turns (i.e., different speakers should have separate segments), but without assigning speaker identifiers.Return a JSON list where each entry represents a speech segment with the following fields:• start_time: Start timestamp in MM:SS format.• end_time: End timestamp in MM:SS format.• asr: The transcribed text for that segment.Example Output:[{"start_time": "00:05", "end_time": "00:08", "asr": "Hello, everyone."},{"start_time": "00:09", "end_time": "00:12", "asr": "Welcome to the meeting."}
]Strict Requirements:• Ensure precise speech segmentation with accurate timestamps.• Segment based on speaker turns (i.e., different speakers' utterances should be separated).• Preserve punctuation and capitalization in the ASR output.• Skip the speeches that can hardly be clearly recognized.• Return only the valid JSON list (which starts with "[" and ends with "]") without additional explanations.• If the video contains no speech, return an empty list ("[]").Now generate the JSON list based on the given video:"""
prompt_audio_segmentation(音频分割提示词)
Automatic Speech Recognition (ASR) 自动语音识别
punctuation ˌpʌŋktʃuˈeɪʃn ˌpʌŋktʃuˈeɪʃ(ə)n 标点符号
capitalization ˌkæpɪtəlaɪˈzeɪʃn ˌkæpɪtələˈzeɪʃn 资本化;资本总额;用大写
utterance ˈʌtərəns ˈʌtərəns 言论,言辞;发声,表达;(语言学)话语
preserve prɪˈzɜːv prɪˈzɜːrv
保护,维护;保持,维持;腌制,保存(食物);禁止他人捕猎
果酱,腌菜;(某人或某个团体的)专属领域,独有活动;动物保护区,外人禁入的猎地
diarization
说话人识别:一种自动识别和标记音频或视频中不同说话人的过程。通常用于语音识别、会议记录和电话会议等场景
accurate / ˈækjərət / / ˈækjərət /
准确的,精确的;(工具,方法)精密的;正确无误的;(武器、投掷)精准的
你会获得一个视频。你的任务是对该视频执行自动语音识别(ASR)和音频角色分离。提取所有带有准确时间戳的语音片段(accurate timestamps),并按说话人轮次分割(segment them by speaker turns,即不同说话人的语音应分为不同片段),但无需为说话人分配标识。
返回一个 JSON 列表,其中每个条目代表一个语音片段,包含以下字段:
・ start_time:开始时间戳,格式为 MM:SS(分:秒)
・ end_time:结束时间戳,格式为 MM:SS(分:秒)
・ asr:该片段的转录文本
示例输出:
[
{"start_time": "00:05", "end_time": "00:08", "asr": "Hello, everyone."},
{"start_time": "00:09", "end_time": "00:12", "asr": "Welcome to the meeting."}
]
严格要求:
・ 确保语音分割精准,时间戳准确
・ 按说话人轮次分割(即不同说话人的语音需分开)
・ 保留 ASR 输出中的标点符号和大小写格式
・ 跳过难以清晰识别的语音内容
・ 仅返回有效的 JSON 列表(以 “[” 开头、以 “]” 结尾),无需附加说明
・ 若视频中无语音,返回空列表(“[]”)
现在根据给定的视频生成 JSON 列表:
第二个模块原文
enclosed ɪnˈkləʊzd ɪnˈkloʊzd
围住的,封闭的;随函附上的;与世隔绝的
包围,围住;随信附上,随信装入(enclose 的过去式和过去分词)
cohesive kəʊˈhiːsɪv koʊˈhiːsɪv 团结的,有凝聚力的;使团结的,使凝聚的
angle bracket 尖括号
inferable ɪnˈfɜːrəb(ə)l ɪnˈfɜːrəb(ə)l 能推论的;能推理的
incorporate ɪnˈkɔːpəreɪt ɪnˈkɔːrpəreɪt
包含,合并;组成公司;掺和,混合(成分);使具体化,体现
合成一体的,合并的;具体化的;组成公司(或社团)的
distinguishing dɪˈstɪŋɡwɪʃɪŋ dɪˈstɪŋɡwɪʃɪŋ 有区别的(有辨识度的)
clarity ˈklærəti ˈklærəti 清晰易懂;思路清晰;(画面或声音的)清晰,清楚;清澈,明净
approaches əˈprəʊtʃɪz əˈproʊtʃɪz
靠近,临近;接洽,交谈;对付,处理(approach 的第三人称单数)
方法,态度;接洽,要求;通道,路径(approach 的复数)
wherever weərˈevə(r) werˈevər
无论在哪里,在任何地方;在任何情况下;不知在哪里,不知在什么地方
究竟在哪儿(用在疑问句句首,表示惊讶);无论在哪里,无论去哪里;随便什么地方
dialogue 对话
prompt_generate_captions_with_ids = """You are given a video, a set of character features. Each feature (some of them may belong to the same character) can be a face image represented by a video frame with a bounding box, or can be a voice feature represented by several speech segments, each with a start time, an end time (both in MM:SS format), and the corresponding content. Each face and voice feature is identified by a unique ID enclosed in angle brackets (< >).Your Task:Using the provided feature IDs, generate a detailed and cohesive description of the current video clip. The description should capture the complete set of observable and inferable events in the clip. Your output should incorporate the following categories (but is not limited to them):1. Characters' Appearance: Describe the characters' appearance, such as their clothing, facial features, or any distinguishing characteristics.2. Characters' Actions & Movements: Describe specific gesture, movement, or interaction performed by the characters.3. Characters' Spoken Dialogue: Transcribe or summarize what are spoken by the characters.4. Characters' Contextual Behavior: Describe the characters' roles in the scene or their interaction with other characters, focusing on their behavior, emotional state, or relationships.Strict Requirements:• If a character has an associated feature ID in the input context (either face or voice), refer to them **only** using that feature ID (e.g., <face_1>, <voice_2>).• If a character **does not** have an associated feature ID in the input context, use a short descriptive phrase (e.g., "a man in a blue shirt," "a young woman standing near the door") to refer to them.• Ensure accurate and consistent mapping between characters and their corresponding feature IDs when provided.• Each description must represent a **single atomic event or detail**. Avoid combining multiple unrelated aspects (e.g., appearance and dialogue) into one line. If a sentence can be split without losing clarity, it must be split.• Do not use pronouns (e.g., "he," "she," "they") or inferred names to refer to any character.• Include natural time expressions and physical location cues wherever inferable from the context (e.g., "in the evening at the dinner table," "early morning outside the building").• The generated descriptions must not invent events or characteristics not grounded in the video.• The final output must be a list of strings, with each string representing exactly one atomic event or description.Example Input:
<input_video>,
"<face_1>": <img>,
"<face_2>": <img>,
"<face_3>": <img>,
"<voice_1>": [{"start_time": "00:05", "end_time": "00:08", "asr": "Hello, everyone."},{"start_time": "00:09", "end_time": "00:12", "asr": "Let's get started with today's agenda."}
],
"<voice_2>": [{"start_time": "00:15", "end_time": "00:18", "asr": "Thank you for having me here."},{"start_time": "00:19", "end_time": "00:22", "asr": "I'm excited to share my presentation."}
]Example Output:
["In the bright conference room, <face_1> enters confidently, giving a professional appearance as he approaches <face_2> to shake hands.","<face_1> wears a black suit with a white shirt and tie. He has short black hair and wears glasses.","<face_2>, dressed in a striking red dress with long brown hair.","<face_2> smiles warmly and greets <face_1>. She then sits down at the table beside him, glancing at her phone briefly while occasionally looking up.","<voice_1> speaks to the group, 'Good afternoon, everyone. Let's begin the meeting.' His voice commands attention as the room quiets, and all eyes turn to him.","<face_2> listens attentively to <voice_1>'s words, nodding in agreement while still occasionally checking her phone. The atmosphere is professional, with the participants settling into their roles for the meeting.","<face_1> adjusts his tie and begins discussing the agenda, engaging the participants in a productive conversation."
]Please only return the valid string list (which starts with "[" and ends with "]"), without any additional explanation or formatting."""
prompt_generate_captions_with_ids(生成带标识字幕提示词)
生成带标识字幕提示词
你会获得一个视频和一组角色特征。每个特征(部分特征可能属于同一角色)可以是:由带边界框的视频帧表示的面部图像(a face image represented by a video frame with a bounding box),或由多个语音片段表示的语音特征(每个语音片段均包含开始时间、结束时间(均为 “分:秒” 格式)及对应内容)。每个面部特征和语音特征都有一个唯一标识,该标识用尖括号(< >)包裹。
你的任务
利用提供的特征标识,生成对当前视频片段的详细且连贯的描述。描述需涵盖片段中所有可观察到的事件以及可推断出的事件。
输出内容需包含以下类别(但不限于这些类别):
角色外貌:描述角色的外貌特征,例如衣着、面部特点或其他具有辨识度的特征。
角色动作与移动:描述角色做出的具体手势、移动轨迹或与他人的互动动作。
角色对话内容:转录或总结角色所说的话。
角色情境行为:描述角色在场景中的角色定位或与其他角色的互动情况,重点关注其行为表现、情绪状态或人物关系。
严格要求
若某角色在输入情境中有关联的特征标识(无论是面部标识还是语音标识),则仅使用该特征标识指代该角色(例如 <face_1>、<voice_2>)
若某角色在输入情境中没有关联的特征标识,则使用简短的描述性短语指代(例如 “穿蓝色衬衫的男士”“站在门口附近的年轻女士”)
当提供特征标识时,需确保角色与其对应的特征标识之间的映射准确且一致
每个描述必须代表一个独立的事件或细节。避免将多个不相关的方面(如外貌和对话)合并到同一句话中。若一句话可拆分且拆分后不影响清晰度,则必须拆分。
不得使用代词(如 “he”“she”“they”)或推断出的名字指代任何角色
凡能从情境中推断出时间表述和实际位置线索的,均需在描述中包含(例如 “晚上在餐桌旁”“清晨在大楼外”)。
生成的描述不得虚构视频中不存在的事件或特征
最终输出必须是一个字符串列表,列表中的每个字符串恰好代表一个独立的事件或描述。
示例输入
<input_video>,
"<face_1>": <img>,
"<face_2>": <img>,
"<face_3>": <img>,
"<voice_1>": [
{"start_time": "00:05", "end_time": "00:08", "asr": "Hello, everyone."},
{"start_time": "00:09", "end_time": "00:12", "asr": "Let's get started with today's agenda."}
],
"<voice_2>": [
{"start_time": "00:15", "end_time": "00:18", "asr": "Thank you for having me here."},
{"start_time": "00:19", "end_time": "00:22", "asr": "I'm excited to share my presentation."}
]
示例输出
[
"在明亮的会议室里,<face_1> 自信地走进来,面带专业的神情走向 < face_2 > 并与其握手。",
"<face_1 > 穿着黑色西装,内搭白色衬衫并系着领带,留着黑色短发,戴着眼镜。",
"<face_2 > 身着醒目的红色连衣裙,留着棕色长发。",
"<face_2 > 热情地微笑并向 < face_1 > 打招呼,随后在 < face_1 > 身旁的椅子上坐下,偶尔低头看手机,偶尔抬头环顾四周。",
"<voice_1 > 向众人说道:“下午好,各位。我们开始开会吧。” 其声音吸引了所有人的注意力,会议室逐渐安静下来,所有人的目光都投向了 < voice_1 > 的方向。",
"<face_2 > 专注地聆听 < voice_1 > 的讲话,不时点头表示赞同,同时仍会偶尔查看手机。现场氛围十分专业,参会人员均已进入会议状态。",
"<face_1 > 整理了一下领带,随后开始讲解会议议程,与参会人员展开富有成效的讨论。"
]
请仅返回有效的字符串列表(列表以 “[” 开头、以 “]” 结尾),无需附加任何说明或格式调整
第三个模块原文
prompt_generate_thinkings_with_ids = """You are given a video and a set of character features. Each feature is either a face (represented by a video frame with a bounding box) or a voice (represented by speech segments with MM:SS timestamps and transcripts). Each feature has a unique ID in angle brackets (e.g., <face_1>, <voice_2>). You are also given a list of video descriptions.Your Task:Using the provided feature IDs, generate a list of high-level reasoning-based conclusions about the video across the following five categories, going beyond surface-level observations:1. Equivalence IdentificationIdentify which face and voice features refer to the same character.
• Use the exact format: Equivalence: <face_x>, <voice_y>.
• Include as many confident matches as possible.2. Character-Level AttributesInfer abstract attributes for each character, such as:
• Name (if explicitly stated),
• Personality (e.g., confident, nervous),
• Role/profession (e.g., host, newcomer),
• Interests or background (when inferable),
• Distinctive behaviors or traits (e.g., speaks formally, fidgets).
Avoid restating visual facts—focus on identity construction.3. Interpersonal Relationships & DynamicsDescribe the relationships and interactions between characters:
• Roles (e.g., host-guest, leader-subordinate),
• Emotions or tone (e.g., respect, tension),
• Power dynamics (e.g., who leads),
• Evidence of cooperation, exclusion, conflict, etc.4. Video-Level Plot UnderstandingSummarize the scene-level narrative, such as:
• Main event or theme,
• Narrative arc or sequence (e.g., intro → discussion → reaction),
• Overall tone (e.g., formal, tense),
• Cause-effect or group dynamics.5. Contextual & General KnowledgeInclude general knowledge that can be learned from the video, such as:
• Likely setting or genre (e.g., corporate meeting, game show),
• Cultural/procedural norms,
• Real-world knowledge (e.g., "Alice market is pet-friendly"),
• Common-sense or format conventions.Output Format:• A Python list of concise English sentences, each expressing one high-level conclusion.
• Do not include reasoning steps or restate input observations. Only output the final conclusions.Strict Requirements:• If a character has an associated feature ID in the input context (either face or voice), refer to them **only** using that feature ID (e.g., <face_1>, <voice_2>).• If a character **does not** have an associated feature ID in the input context, use a short descriptive phrase (e.g., "a man in a blue shirt," "a young woman standing near the door") to refer to them.• Ensure accurate and consistent mapping between characters and their corresponding feature IDs when provided. • Do not use pronouns (e.g., "he," "she," "they") or inferred names to refer to any character.• Provide only the final high-level thinking conclusions, without detailing the reasoning process or restating simple observations from the video.• Pay more attention to features that are most likely to be the same person, using the format: "Equivalence: <face_x>, <voice_y>".• Your output should be a Python list of well-formed, concise English sentences (one per item).Example Input:<input_video>,
"<face_1>": <img>,
"<face_2>": <img>,
"<face_3>": <img>,
"<voice_1>": [{"start_time": "00:05", "end_time": "00:08", "asr": "Hello, everyone."},{"start_time": "00:09", "end_time": "00:12", "asr": "Let's get started with today's agenda."}
],
"<voice_2>": [{"start_time": "00:15", "end_time": "00:18", "asr": "Thank you for having me here."},{"start_time": "00:19", "end_time": "00:22", "asr": "I'm excited to share my presentation."}
]
"video descriptions": ["<face_1> wears a black suit with a white shirt and tie and has short black hair and wears glasses.","<face_1> enters the conference room and shakes hands with <face_2>.","<face_2> sits down at the table next to <face_1> after briefly greeting <face_1>.","<face_2> waves at <face_1> while sitting at the table and checks her phone.","<face_2> listens attentively to <face_1>'s speech and nods in agreement.",
]Example Output:["Equivalence: <face_1>, <voice_1>","<face_1>'s name is David.","<face_1> holds a position of authority, likely as the meeting's organizer or a senior executive.","<face_2> shows social awareness and diplomacy, possibly indicating experience in public or client-facing roles.","<face_1> demonstrates control and composure, suggesting a high level of professionalism and confidence under pressure.","The interaction between <face_1> and <face_2> suggests a working relationship built on mutual respect.","The overall tone of the meeting is structured and goal-oriented, indicating it is part of a larger organizational workflow."
]Please only return the valid string list (which starts with "[" and ends with "]"), without any additional explanation or formatting."""
第四个模块原文
prompt_generate_full_memory = """
You are given a video along with a set of character features. Each feature is either:
• Face: a single video frame with a bounding box, or
• Voice: one or more speech segments, each containing start_time (MM:SS), end_time (MM:SS) and asr (transcript).
Every feature has a unique ID enclosed in angle brackets (e.g. <face_1>, <voice_2>).Your Tasks (produce both in the same response) :1. **Episodic Memory** (the ordered list of atomic captions)
• Using the provided feature IDs, generate a detailed and cohesive description of the current video clip. The description should capture the complete set of observable and inferable events in the clip. Your output should incorporate the following categories (but is not limited to them):(a) Characters' Appearance: Describe the characters' appearance, such as their clothing, facial features, or any distinguishing characteristics.(b) Characters' Actions & Movements: Describe specific gesture, movement, or interaction performed by the characters.(c) Characters' Spoken Dialogue: Quote—or, if necessary, summarize—what are spoken by the characters.(d) Characters' Contextual Behavior: Describe the characters' roles in the scene or their interaction with other characters, focusing on their behavior, emotional state, or relationships.2. **Semantic Memory** (the ordered list of high-level thinking conclusions)
• Produce concise, high-level reasoning-based conclusions across five categories:(a) Equivalence Identification – Identify which face and voice features refer to the same character. Use the exact format: Equivalence: <face_x>, <voice_y>. Include as many confident matches as possible.(b) Character-level Attributes – Infer abstract attributes for each character, such as: Name (if explicitly stated), Personality (e.g., confident, nervous), Role/profession (e.g., host, newcomer), Interests or background (when inferable), istinctive behaviors or traits (e.g., speaks formally, fidgets). Avoid restating visual facts—focus on identity construction.(c) Interpersonal Relationships & Dynamics – Describe the relationships and interactions between characters: Roles (e.g., host-guest, leader-subordinate), Emotions or tone (e.g., respect, tension), Power dynamics (e.g., who leads), Evidence of cooperation, exclusion, conflict, etc.(d) Video-level Plot Understanding – Summarize the scene-level narrative, such as: Main event or theme, Narrative arc or sequence (e.g., intro → discussion → reaction), Overall tone (e.g., formal, tense), Cause-effect or group dynamics.(e) Contextual & General Knowledge – Include general knowledge that can be learned from the video, such as: Likely setting or genre (e.g., corporate meeting, game show), Cultural/procedural norms, Real-world knowledge (e.g., "Alice market is pet-friendly"), Common-sense or format conventions.Strict Requirements (apply to both sections unless noted)1. If a character has a provided feature ID, refer to that character only with the ID (e.g. <face_1>, <voice_2>).
2. If no ID exists, use a short descriptive phrase (e.g. “a man in a blue shirt”).
3. Do not use “he,” “she,” “they,” pronouns, or invented Names.
4. Keep face/voice IDs consistent throughout.
5. Describe only what is grounded in the video or obviously inferable.
6. Include natural Time & Location cues and setting hints when inferable.
7. Each Episodic Memory line must express one event/detail; split sentences if needed.
8. Output English only.
9. Output a Python list of sentences for each memory type.Additional Rules for Episodic Memory1. Do not mix unrelated aspects in one memory sentence.
2. Focus on appearance, actions/movements, spoken dialogue (quote or summary), contextual behavior.Additional Rules for Semantic Memory1. For Equivalence lines, use the exact format: Equivalence: <face_x>, <voice_y>.
2. Do not repeat simple surface observations already in the captions.
3. Provide only final conclusions, not reasoning steps.Expected Output FormatReturn the result as a single Python dict containing exactly two keys:{"episodic_memory": ["In the bright conference room, <face_1> enters confidently, giving a professional appearance as he approaches <face_2> to shake hands.","<face_1> wears a black suit with a white shirt and tie. He has short black hair and wears glasses.","<face_2>, dressed in a striking red dress with long brown hair.","<face_2> smiles warmly and greets <face_1>. She then sits down at the table beside him, glancing at her phone briefly while occasionally looking up.","<voice_1> speaks to the group, 'Good afternoon, everyone. Let's begin the meeting.' His voice commands attention as the room quiets, and all eyes turn to him.","<face_2> listens attentively to <voice_1>'s words, nodding in agreement while still occasionally checking her phone. The atmosphere is professional, with the participants settling into their roles for the meeting.","<face_1> adjusts his tie and begins discussing the agenda, engaging the participants in a productive conversation."],"semantic_memory": ["Equivalence: <face_1>, <voice_1>","<face_1>'s name is David.","<face_1> holds a position of authority, likely as the meeting's organizer or a senior executive.","<face_2> shows social awareness and diplomacy, possibly indicating experience in public or client-facing roles.","<face_1> demonstrates control and composure, suggesting a high level of professionalism and confidence under pressure.","The interaction between <face_1> and <face_2> suggests a working relationship built on mutual respect.","The overall tone of the meeting is structured and goal-oriented, indicating it is part of a larger organizational workflow."]
}Please only return the valid python dict (which starts with "{" and ends with "}") containing two string lists in "episodic_memory" and "semantic_memory", without any additional explanation or formatting.
"""
第五个模块原文
prompt_generate_captions_with_ids_sft = """You will be given a video and a set of character features. Each feature (some of them may belong to the same character) can be a face image represented by a video frame with a bounding box, or can be a voice feature represented by several speech segments, each with a start time, an end time (both in MM:SS format), and the corresponding content. Each face and voice feature is identified by a unique ID enclosed in angle brackets (< >).Your task is using the provided feature IDs as the reference to characters (if available) in the video and generating a detailed and cohesive description of the current video clip. The description should capture the complete set of observable and inferable events in the clip. Your output should be a list of strings, with each string representing exactly one atomic event or description."""
第六个模块原文
prompt_generate_thinkings_with_ids_sft = """You will be given a video and a set of character features. Each feature is either a face (represented by a video frame with a bounding box) or a voice (represented by speech segments with MM:SS timestamps and transcripts). Each feature has a unique ID in angle brackets. You will also be given a list of video descriptions.Your task is using the provided feature IDs as the reference to characters (if available) in the video and generating a list of high-level reasoning-based conclusions about the video, going beyond surface-level observations. Particularly, in your output, you should identify which face and voice features refer to the same character, using the exact format: Equivalence: <face_x>, <voice_y>.Your output should be a list of strings, with each string representing exactly one high-level conclusion."""
第七个模块原文
prompt_generate_semantic_memory_with_ids_sft_equivalence = """You will be given a video and a set of character features. Each feature is either a face (represented by a video frame with a bounding box) or a voice (represented by speech segments with MM:SS timestamps and transcripts). Each feature has a unique ID in angle brackets. You will also be given a list of video descriptions.Your task is to identify which face and voice features refer to the same character. Use high-level reasoning based on timing alignment, contextual cues, and audiovisual consistency.Your output should be a list of exact matches in the following format:
["Equivalence: <face_x>, <voice_y>","Equivalence: <face_a>, <voice_b>",...
]"""第八个模块原文
prompt_generate_semantic_memory_with_ids_sft_character = """You will be given a video and a set of character features. Each feature is either a face (represented by a video frame with a bounding box) or a voice (represented by speech segments with MM:SS timestamps and transcripts). Each feature has a unique ID in angle brackets. You will also be given a list of video descriptions.Your task is to infer high-level character names, traits, intentions, emotional states, and behavioral patterns from the available features. Go beyond surface-level observations to draw psychologically meaningful conclusions.Refer to each character by their feature ID."""第九个模块原文
prompt_generate_semantic_memory_with_ids_sft_relation = """You will be given a video and a set of character features. Each feature is either a face (represented by a video frame with a bounding box) or a voice (represented by speech segments with MM:SS timestamps and transcripts). Each feature has a unique ID in angle brackets. You will also be given a list of video descriptions.Your task is to analyze the social relationships between characters based on the features and any video descriptions. Infer dynamics such as cooperation, conflict, status hierarchy, trust, or emotional connection.Use feature IDs to refer to the characters involved in each relationship."""第十个模块原文
prompt_generate_semantic_memory_with_ids_sft_plot = """You will be given a video and a set of character features. Each feature is either a face (represented by a video frame with a bounding box) or a voice (represented by speech segments with MM:SS timestamps and transcripts). Each feature has a unique ID in angle brackets. You will also be given a list of video descriptions.Your task is to infer high-level conclusions about the narrative or events in the video. Go beyond descriptive content and identify key developments, cause-effect patterns, and narrative structure.Present each reasoning-based conclusion as a separate statement. Use feature IDs to refer to the characters involved."""
第十一个模块原文
prompt_generate_semantic_memory_with_ids_sft_general_knowledge = """You will be given a video and a set of character features. Each feature is either a face (represented by a video frame with a bounding box) or a voice (represented by speech segments with MM:SS timestamps and transcripts). Each feature has a unique ID in angle brackets. You will also be given a list of video descriptions.Your task is to generate high-level, abstract conclusions that demonstrate deep understanding of the video. This may include inferred themes, implications, non-obvious insights, or some general knowledge that can be learned from the video.Output a list of such reasoning-based insights, using feature IDs to refer to the characters involved."""
第十二个模块原文
prompt_generate_memory_with_ids_sft = """You will be given a video and a set of character features. Each feature is either a face (represented by a video frame with a bounding box) or a voice (represented by one or more speech segments, each with MM:SS start and end times, and transcript content). Each feature has a unique ID enclosed in angle brackets. Some features may belong to the same character.Your task consists of two parts:
1. Video Description:
Generate a detailed and cohesive description of the current video clip. Use the provided feature IDs as references to characters (when applicable). Your description should cover all observable and inferable events. Each description should focus on a single atomic event or fact.
2. High-Level Conclusions:
Generate high-level reasoning-based conclusions that go beyond surface-level observations. Use logical inference to identify character intentions, relationships, and identities. If a face and a voice feature refer to the same character, indicate it using this exact format: Equivalence: <face_x>, <voice_y>Output Format:
Your output must be a JSON object with the following structure:{"video_description": ["...", // each string is one atomic event description"..."],"high_level_conclusions": ["...", // each string is one high-level inference or identity resolution"Equivalence: <face_1>, <voice_2>"]
}Please only return the valid JSON object, without any additional explanation or formatting."""第十三个模块原文
prompt_baseline_answer_clipwise_extract = """You are given a video and a question related to that video. You will be shown a specific clip from the video. Your task is to extract any relevant information from this clip that can help answer the question. If the clip does not contain any relevant or helpful information, simply respond with "none"."""第十四个模块原文
prompt_baseline_answer_clipwise_summarize = """You have reviewed all segments of a video and extracted relevant information in response to a given question. The extracted information is provided in chronological order, following the sequence of the video.Your task is to distill the most essential core idea from all extracted information and formulate a final answer that is as concise and to the point as possible, while fully addressing the question.Only provide the direct answer without any explanation, elaboration, or additional commentary."""第十五个模块原文
prompt_benchmark_verify_answer = """You are provided with a question, the ground truth answer, and a baseline answer. Your task is to assess whether the baseline answer is semantically consistent with the ground truth answer. If the meaning of the baseline answer aligns with the ground truth answer, regardless of exact wording, return "Yes". If the baseline answer is semantically incorrect, return "No".Input Example:{"question": "What is the capital of France?","answer": "Paris","baseline_answer": "Paris"
}Output Example:YesPlease only return "Yes" or "No", without any additional explanation or formatting."""
第十六个模块原文
prompt_generate_action = """You are given a question and some relevant knowledge about a specific video. Your task is to reason about whether the provided knowledge is sufficient to answer the question. If it is sufficient, output [ANSWER] followed by the answer. If it is not sufficient, output [SEARCH] and generate a query that will be encoded into embeddings for a vector similarity search. The query will help retrieve additional information from a memory bank that consists of detailed descriptions and high-level abstractions of the video, considering both the question and the provided knowledge.Specifically, your response should contain the following two parts:1. Reasoning: First, consider the question and existing knowledge. Think about whether the current information can answer the question. If not, do some reasoning about what is the exact information that is still missing and the reason why it is important to answer the question.2. Answer or Search:• Answer: If you can answer the question based on the provided knowledge, output [ANSWER] and provide the answer.• Search: If you cannot answer the question based on the provided knowledge, output [SEARCH] and generate a query. For the query:• Identify broad topics or themes that may help answer the question. These themes should cover aspects that provide useful context or background to the question, such as character names, behaviors, relationships, personality traits, actions, and key events.• Make the query concise and focused on a specific piece of information that could help answer the question. • The query should target information outside of the existing knowledge that might help answer the question.• For time-sensitive or chronological information (e.g., events occurring in sequence, changes over time, or specific moments in a timeline), you can generate clip-based queries that reference specific clips or moments in time. These queries should include a reference to the clip number, indicating the index of the clip in the video (a number from 1 to N, where a smaller number indicates an earlier clip). Format these queries as "CLIP_x", where x should be an integer that indicated the clip index. Note only generate clip-based queries if the question is about a specific moment in time or a sequence of events.• You can also generate queries that focus on specific characters or characters' attributes using the id shown in the knowledge.• Make sure your generated query focus on some aspects that are not retrieved or asked yet. Do not repeatedly generate queries that have high semantic similarity with those generated before.Example 1:Input:Question: How did the argument between Alice and Bob influence their relationship in the story?
Knowledge:
[{{"query": "What happened during the argument between Alice and Bob?","related memories": {{"CLIP_2": ["<face_1> and <face_2> are seen arguing in the living room.""<face_1> raises her voice, and <face_2> looks upset.""<face_1> accuses <face_2> of not listening to her."],}}}}
]Output:It seems that <face_1> and <face_2> are arguing about their relationship. I need to figure out the names of <face_1> and <face_2>.
[SEARCH] What are the names of <face_1> and <face_2>?Example 2:Input:Question: How did the argument between Alice and Bob influence their relationship in the story?
Knowledge:
[{{"query": "What happened during the argument between Alice and Bob?","related memories": {{"CLIP_2": ["<face_1> and <face_2> are seen arguing in the living room.""<face_1> raises her voice, and <face_2> looks upset.""<face_1> accuses <face_2> of not listening to her."],}}}},{{"query": "What are the names of <face_1> and <face_2>?","related memories": {{"CLIP_1": ["<face_1> says to <face_2>: 'I am done with you Bob!'","<face_2> says to <face_1>: 'What about now, Alice?'"],}}}}
]Output:It seems that content in CLIP_2 shows exactly the argument between Alice and Bob. To figure out how did the argument between Alice and Bob influence their relationship, I need to see what happened next in CLIP_3.
[SEARCH] CLIP_3Now, generate your response for the following input:Question: {question}Knowledge: {knowledge}Output:"""第十七个模块原文
prompt_generate_plan = """You are given a clip from a specific video and a question about the video. There exists a memory bank that contains information about this video, but you will not be shown its contents.The memory bank is structured as a temporally ordered sequence of entries. Each entry contains either:• a fine-grained description of a specific moment in the video, or• a high-level summary or abstraction of events.Your task is to create a detailed and robust retrieval plan: a step-by-step outline describing what kinds of information should be retrieved from the memory bank to answer the question effectively.Requirements:• Do not answer the question.• Instead, output a string list, where each item describes one retrieval step.• Each step should specify a type of content, topic, or temporal segment to retrieve (e.g., "find entries describing character motivations" or "look for summaries of the climax").Your plan must:1. Ensure completeness:The plan must guide the retrieval process in such a way that all essential pieces of information required to answer the question will be retrieved — including context, reasoning chains, motivations, consequences, and temporal links, as relevant.Do not stop at partial evidence. Design the plan so that it systematically explores and gathers all necessary supporting elements.2. Include contingency strategies:Anticipa what might go wrong or be missing during retrieval. For example:• What if direct mentions of an event are not available?• What if the memory bank contains conflicting interpretations?• What if characters' intentions or relationships are implied but not explicitly stated?Your plan should include fallback options and indirect paths to cover these cases (e.g., using emotion cues, related scenes, earlier summaries, or surrounding context).3. Follow a logical order:The steps should be ordered in a way that reflects effective reasoning — e.g., from specific to general, or from earlier scenes to later consequences.Output format:
A list of strings. Example:["Step 1: Retrieve entries describing the initial context and setting of the video.","Step 2: Look for interactions between the main characters relevant to the question.","Step 3: Find summaries that explain the consequences of the key events."
]Please response with only the string list of the plan (wrapped by "[]"), without any additional explanation or formatting.Now start generating the plan.Questions: {question}"""第十八个模块原文
prompt_generate_action_with_plan = """You are given a question and some relevant knowledge about a specific video. You are also provided with a retrieval plan, which outlines the types of information that should be retrieved from a memory bank in order to answer the question. Your task is to reason about whether the provided knowledge is sufficient to answer the question. If it is sufficient, output [ANSWER] followed by the answer. If it is not sufficient, output [SEARCH] and generate a query that will be encoded into embeddings for a vector similarity search. The query will help retrieve additional information from a memory bank that contains detailed descriptions and high-level abstractions of the video, considering the question, the provided knowledge, and the retrieval plan.Your response should contain two parts:
1. Reasoning• Analyze the question, the knowledge, and the retrieval plan.• If the current information is sufficient, explain why and what conclusions you can draw.• If not, clearly identify what is missing and why it is important.
2. Answer or Search• [ANSWER]: If the answer can be derived from the provided knowledge, output [ANSWER] followed by a short, clear, and direct answer.• When referring to a character, always use their specific name if available.• Do not use ID tags like <character_1> or <face_1>.• [SEARCH]: If the answer cannot be derived yet, output [SEARCH] followed by a single search query that would help retrieve the missing information.Instructions for [SEARCH] queries:• Use the retrieval plan to inform what type of content should be searched for next. These contents should cover aspects that provide useful context or background to the question, such as character names, behaviors, relationships, personality traits, actions, and key events.• Use keyword-based queries, not command sentences. Queries should be written as compact keyword phrases, not as full sentences or instructions. Avoid using directive language like "Retrieve", "Describe", or question forms such as "What", "When", "How".• Keep each query short and focused on one point. Each query should target one specific type of information, without combining multiple ideas or aspects.• Avoid over-complexity and unnecessary detail. Do not include too many qualifiers or conditions. Strip down to the most essential keywords needed to retrieve valuable content.• The query should target information outside of the existing knowledge that might help answer the question.• For time-sensitive or chronological information (e.g., events occurring in sequence, changes over time, or specific moments in a timeline), you can generate clip-based queries that reference specific clips or moments in time. These queries should include a reference to the clip number, indicating the index of the clip in the video (a number from 1 to N, where a smaller number indicates an earlier clip). Format these queries as "CLIP_x", where x should be an integer that indicates the clip index. Note only generate clip-based queries if the question is about a specific moment in time or a sequence of events.• You can also generate queries that focus on specific characters or characters' attributes using the id shown in the knowledge.• Make sure your generated query focus on some aspects that are not retrieved or asked yet. Do not repeatedly generate queries that have high semantic similarity with those generated before.Example 1:Input:Question: How did the argument between Alice and Bob influence their relationship in the story?Knowledge:
[{{"query": "What happened during the argument between Alice and Bob?","related memories": {{"CLIP_2": ["<face_1> and <face_2> are seen arguing in the living room.""<face_1> raises her voice, and <face_2> looks upset.""<face_1> accuses <face_2> of not listening to her."],}}}}
]Output:It seems that <face_1> and <face_2> are arguing about their relationship. I need to figure out the names of <face_1> and <face_2>.
[SEARCH] What are the names of <face_1> and <face_2>?Example 2:Input:Question: How did the argument between Alice and Bob influence their relationship in the story?Knowledge:
[{{"query": "What happened during the argument between Alice and Bob?","related memories": {{"CLIP_2": ["<face_1> and <face_2> are seen arguing in the living room.""<face_1> raises her voice, and <face_2> looks upset.""<face_1> accuses <face_2> of not listening to her."],}}}},{{"query": "What are the names of <face_1> and <face_2>?","related memories": {{"CLIP_1": ["<face_1> says to <face_2>: 'I am done with you Bob!'","<face_2> says to <face_1>: 'What about now, Alice?'"],}}}}
]Output:It seems that content in CLIP_2 shows exactly the argument between Alice and Bob. To figure out how did the argument between Alice and Bob influence their relationship, I need to see what happened next in CLIP_3.
[SEARCH] What happened in CLIP_3?Now, generate your response for the following input:Question: {question}Retrieval Plan: {retrieval_plan}Knowledge: {knowledge}Output:"""第十九个模块原文
prompt_generate_action_with_plan_new_direction = """You are given a question and some relevant knowledge about a specific video. You are also provided with a retrieval plan, which outlines the types of information that should be retrieved from a memory bank in order to answer the question. Your task is to reason about whether the provided knowledge is sufficient to answer the question.Important Context:
The previous retrieval attempt did not return any useful new information. Therefore, you must now shift your approach and think differently. Specifically, you must identify new angles or unexplored directions based on the retrieval plan that have not yet been considered. Your goal is to create search queries that are distinct from the ones used before, aiming to retrieve different types of content that could lead to an answer.Your response must include two parts:
1. Reasoning:• Analyze the question, the provided knowledge, and the retrieval plan.• Evaluate why the previous queries may have failed and what new avenues should be explored now.• Identify what specific types of information are still missing and why they matter.• Suggest alternative directions that have not been fully explored yet, based on the retrieval plan.
2. Answer or Search:• [ANSWER]: If the answer can now be derived from the current knowledge, output [ANSWER] followed by a short, clear, and direct answer.• Use specific character names if available.• Do not use generic tags like <character_1> or <face_1>.• [SEARCH]: If more information is needed, output [SEARCH] followed by a new search query that are different from those used in the previous retrieval attempt.• The new query must reflect a change in strategy, targeting unexplored or less obvious aspects.• Use the retrieval plan to guide what different types of content should be searched for (e.g., overlooked characters, background events, personality traits, contextual clues).• Include CLIP-based queries only if the question relates to specific moments or sequences in time, formatted as "CLIP_x" (noting that the clip ids are ordered chronologically).• Avoid repeating previous query patterns or focusing on the same semantic areas.• Use keyword-based queries, not command sentences. Queries should be written as compact keyword phrases, not as full sentences or instructions. Avoid using directive language like "Retrieve", "Describe", or question forms such as "What", "When", "How".• Keep each query short and focused on one point. Each query should target one specific type of information, without combining multiple ideas or aspects.• Avoid over-complexity and unnecessary detail. Do not include too many qualifiers or conditions. Strip down to the most essential keywords needed to retrieve valuable content.Instructions for [SEARCH] queries:• Reflect on what was not captured by previous queries, and pivot towards different aspects (e.g., from actions to motivations, from individuals to relationships, from events to consequences).• Think about what has not yet been considered: Are there minor characters, secondary events, or hidden dynamics that might now be worth retrieving?• Aim for maximum diversity and originality in your search suggestions.Example 1:Input:Question: How did the argument between Alice and Bob influence their relationship in the story?Knowledge:
[{{"query": "What happened during the argument between Alice and Bob?","related memories": {{"CLIP_2": ["<face_1> and <face_2> are seen arguing in the living room.""<face_1> raises her voice, and <face_2> looks upset.""<face_1> accuses <face_2> of not listening to her."],}}}}
]Output:It seems that <face_1> and <face_2> are arguing about their relationship. I need to figure out the names of <face_1> and <face_2>.
[SEARCH] What are the names of <face_1> and <face_2>?Example 2:Input:Question: How did the argument between Alice and Bob influence their relationship in the story?Knowledge:
[{{"query": "What happened during the argument between Alice and Bob?","related memories": {{"CLIP_2": ["<face_1> and <face_2> are seen arguing in the living room.""<face_1> raises her voice, and <face_2> looks upset.""<face_1> accuses <face_2> of not listening to her."],}}}},{{"query": "What are the names of <face_1> and <face_2>?","related memories": {{"CLIP_1": ["<face_1> says to <face_2>: 'I am done with you Bob!'","<face_2> says to <face_1>: 'What about now, Alice?'"],}}}}
]Output:It seems that content in CLIP_2 shows exactly the argument between Alice and Bob. To figure out how did the argument between Alice and Bob influence their relationship, I need to see what happened next in CLIP_3.
[SEARCH] What happened in CLIP_3?Now, generate your response for the following input:Question: {question}Retrieval Plan: {retrieval_plan}Knowledge: {knowledge}Output:"""第二十个模块原文
prompt_generate_action_with_plan_multiple_queries = """You are given a question and some relevant knowledge about a specific video. You are also provided with a retrieval plan, which outlines the types of information that should be retrieved from a memory bank in order to answer the question. Your task is to reason about whether the provided knowledge is sufficient to answer the question.If the knowledge is sufficient, output [ANSWER] followed by the answer. If it is not sufficient, output [SEARCH] and generate five diverse queries (in the form of string list wrapped by "[]") that can be used to retrieve more information from the memory bank. The memory bank contains detailed descriptions and high-level abstractions of the video. Your queries should take into account the question, the provided knowledge, and the retrieval plan.Your response should contain two parts:1. Reasoning• Analyze the question, the knowledge, and the retrieval plan.• If the current information is sufficient, explain why and what conclusions you can draw.• If not, clearly identify what is missing and why it is important.2. Answer or Search• [ANSWER]: If the answer can be derived from the provided knowledge, output [ANSWER] followed by a short, clear, and direct answer.• When referring to a character, always use their specific name if available.• Do not use ID tags like <character_1> or <face_1>.• [SEARCH]: If the answer cannot be derived yet, output [SEARCH] followed by a list of 5 diverse search queries that would help retrieve the missing information.Instructions for [SEARCH] queries:• Use the retrieval plan to inform what type of content should be searched for next. These contents should cover aspects that provide useful context or background to the question, such as character names, behaviors, relationships, personality traits, actions, and key events.• Use keyword-based queries, not command sentences. Queries should be written as compact keyword phrases, not as full sentences or instructions. Avoid using directive language like "Retrieve", "Describe", or question forms such as "What", "When", "How".• Keep each query short and focused on one point. Each query should target one specific type of information, without combining multiple ideas or aspects.• Avoid over-complexity and unnecessary detail. Do not include too many qualifiers or conditions. Strip down to the most essential keywords needed to retrieve valuable content.• The query should target information outside of the existing knowledge that might help answer the question.• For time-sensitive or chronological information (e.g., events occurring in sequence, changes over time, or specific moments in a timeline), you can generate clip-based queries that reference specific clips or moments in time. These queries should include a reference to the clip number, indicating the index of the clip in the video (a number from 1 to N, where a smaller number indicates an earlier clip). Format these queries as "CLIP_x", where x should be an integer that indicates the clip index. Note only generate clip-based queries if the question is about a specific moment in time or a sequence of events.• You can also generate queries that focus on specific characters or characters' attributes using the id shown in the knowledge.• Make sure your generated query focus on some aspects that are not retrieved or asked yet. Do not repeatedly generate queries that have high semantic similarity with those generated before.• Ensure diversity: the five queries must not be semantically redundant. Each query should explore a distinct direction toward answering the question.• Format the queries as a **Python-style string list wrapped by "[]"**: [SEARCH] ["What does Bob do after the argument?", "How does Alice react in CLIP_3?", "What is the emotional state of Alice after CLIP_2?", "What conclusions are drawn in high-level summaries about Alice and Bob's relationship?", "Does CLIP_4 show any reconciliation or continued conflict?"]Example 1:Input:Question: How did the argument between Alice and Bob influence their relationship in the story?Knowledge:
[{{"query": "What happened during the argument between Alice and Bob?","related memories": {{"CLIP_2": ["<face_1> and <face_2> are seen arguing in the living room.""<face_1> raises her voice, and <face_2> looks upset.""<face_1> accuses <face_2> of not listening to her."],}}}}
]Output:It seems that <face_1> and <face_2> are engaged in an argument, but their identities are not yet known, and there is no information about the consequences of the argument. To understand how it influenced their relationship, I need more contextual information about their identities, reactions, and what happened after.
[SEARCH] ["What are the names of <face_1> and <face_2>?", "What is the emotional state of <face_1> and <face_2> after the argument?", "What happens immediately after CLIP_2?", "Is there a summary indicating a change in the relationship between these two characters?", "Do any later clips show reconciliation or continued conflict between <face_1> and <face_2>?"]Example 2:Input:Question: How did the argument between Alice and Bob influence their relationship in the story?Knowledge:
[{{"query": "What happened during the argument between Alice and Bob?","related memories": {{"CLIP_2": ["<face_1> and <face_2> are seen arguing in the living room.""<face_1> raises her voice, and <face_2> looks upset.""<face_1> accuses <face_2> of not listening to her."],}}}},{{"query": "What are the names of <face_1> and <face_2>?","related memories": {{"CLIP_1": ["<face_1> says to <face_2>: 'I am done with you Bob!'","<face_2> says to <face_1>: 'What about now, Alice?'"],}}}}
]Output:CLIP_1 identifies <face_1> as Alice and <face_2> as Bob. CLIP_2 shows the argument between them. However, the influence of this argument on their relationship is not yet clear — we need to know what happened afterward and whether their interaction changed.
[SEARCH] ["What happens in CLIP_3 after the argument?", "How does Alice behave toward Bob after the argument?", "Are there any summaries indicating a shift in Alice and Bob's relationship?", "Do Alice and Bob interact again in later clips?", "Is there any indication that their relationship improves or deteriorates after CLIP_2?"]Now, generate your response for the following input:Question: {question}Retrieval Plan: {retrieval_plan}Knowledge: {knowledge}Output:"""第二十一个模块原文
prompt_generate_action_with_plan_multiple_queries_new_direction = """You are given a question and some relevant knowledge about a specific video. You are also provided with a retrieval plan, which outlines the types of information that should be retrieved from a memory bank in order to answer the question. Your task is to reason about whether the provided knowledge is sufficient to answer the question.Important Note:
The previous retrieval attempt did not return any useful new information. Therefore, you must now change your approach.
You need to think differently and generate new types of queries that explore alternative directions based on the retrieval plan. Your new queries must be distinct from the ones used before, targeting different aspects or underexplored areas in order to uncover useful content.If the knowledge is sufficient, output [ANSWER] followed by the answer. If it is not sufficient, output [SEARCH] and generate five diverse and novel queries (in the form of a string list wrapped by "[]") that can be used to retrieve more information from the memory bank. The memory bank contains detailed descriptions and high-level abstractions of the video. Your queries should take into account the question, the provided knowledge, and the retrieval plan.Your response must contain two parts:
1. Reasoning:• Analyze the question, the knowledge, and the retrieval plan.• Evaluate why the previous queries might have failed, and identify what new areas or different perspectives can be explored now.• Clearly explain what information is still missing, and why it matters.• Suggest what alternative retrieval directions could be valuable, based on the retrieval plan but not yet fully explored.
2. Answer or Search:• [ANSWER]: If the answer can now be derived from the current knowledge, output [ANSWER] followed by a short, clear, and direct answer.• Always use specific character names if available.• Do not use ID tags like <character_1> or <face_1>.• [SEARCH]: If more information is needed, output [SEARCH] followed by a list of 5 new, diverse, and exploratory search queries that reflect a shift in strategy.• These queries must be different in nature from those used in previous retrievals.• Use the retrieval plan to focus on alternative types of content, such as:• Less obvious character relationships or dynamics.• Emotional states, motivations, background context.• Events not directly related but potentially influential.• Include clip-based queries (formatted as "CLIP_x") only if the question relates to specific moments or sequences in time.• Use keyword-based queries, not command sentences. Queries should be written as compact keyword phrases, not as full sentences or instructions. Avoid using directive language like "Retrieve", "Describe", or question forms such as "What", "When", "How".• Keep each query short and focused on one point. Each query should target one specific type of information, without combining multiple ideas or aspects.• Avoid over-complexity and unnecessary detail. Do not include too many qualifiers or conditions. Strip down to the most essential keywords needed to retrieve valuable content.• Ensure the five queries are semantically diverse, each probing a unique angle.• Avoid repetition or slight variations of past queries.Formatting for Search Queries:• Output in Python-style string list, e.g.[SEARCH] ["What are Alice's intentions during CLIP_5?", "How does the group react to the decision in CLIP_2?", "What traits define Bob's personality throughout the video?", "What tension exists between secondary characters?", "What themes are highlighted in the summary of CLIP_7?"]Guidance for New Search Angles:• Think: What have I not asked about yet?• Focus on secondary factors, overlooked characters, indirect causes, or high-level themes.• Consider shifts from actions to intentions, from events to emotions, or from individuals to group dynamics.Example 1:Input:Question: How did the argument between Alice and Bob influence their relationship in the story?Knowledge:
[{{"query": "What happened during the argument between Alice and Bob?","related memories": {{"CLIP_2": ["<face_1> and <face_2> are seen arguing in the living room.""<face_1> raises her voice, and <face_2> looks upset.""<face_1> accuses <face_2> of not listening to her."],}}}}
]Output:It seems that <face_1> and <face_2> are engaged in an argument, but their identities are not yet known, and there is no information about the consequences of the argument. To understand how it influenced their relationship, I need more contextual information about their identities, reactions, and what happened after.
[SEARCH] ["What are the names of <face_1> and <face_2>?", "What is the emotional state of <face_1> and <face_2> after the argument?", "What happens immediately after CLIP_2?", "Is there a summary indicating a change in the relationship between these two characters?", "Do any later clips show reconciliation or continued conflict between <face_1> and <face_2>?"]Example 2:Input:Question: How did the argument between Alice and Bob influence their relationship in the story?Knowledge:
[{{"query": "What happened during the argument between Alice and Bob?","related memories": {{"CLIP_2": ["<face_1> and <face_2> are seen arguing in the living room.""<face_1> raises her voice, and <face_2> looks upset.""<face_1> accuses <face_2> of not listening to her."],}}}},{{"query": "What are the names of <face_1> and <face_2>?","related memories": {{"CLIP_1": ["<face_1> says to <face_2>: 'I am done with you Bob!'","<face_2> says to <face_1>: 'What about now, Alice?'"],}}}}
]Output:CLIP_1 identifies <face_1> as Alice and <face_2> as Bob. CLIP_2 shows the argument between them. However, the influence of this argument on their relationship is not yet clear — we need to know what happened afterward and whether their interaction changed.
[SEARCH] ["What happens in CLIP_3 after the argument?", "How does Alice behave toward Bob after the argument?", "Are there any summaries indicating a shift in Alice and Bob's relationship?", "Do Alice and Bob interact again in later clips?", "Is there any indication that their relationship improves or deteriorates after CLIP_2?"]Now, generate your response for the following input:Question: {question}Retrieval Plan: {retrieval_plan}Knowledge: {knowledge}Output:"""第二十二个模块原文
prompt_extract_entities = """You are given a set of semantic memory, which contains various descriptions of characters, actions, interactions, and events. Each description may refer to characters, speakers, or actions and includes unique IDs enclosed in angle brackets (< >). Your task is to identify equivalent nodes that refer to the same character across different descriptions.For each group of descriptions that refer to the same character, extract and represent them as equivalence relationships using strings in the following format: "Equivalence: <node_1>, <node_2>".Strict Requirements:• Identify all equivalent nodes, ensuring they refer to the same character or entity across different descriptions.• Use the exact IDs in angle brackets (e.g., <char_1>, <speaker_2>) in your equivalence statements.• Provide the output as a list of strings, each string in the form of "Equivalence: <node_1>, <node_2>".• Focus on finding relationships that represent the same individual, ignoring irrelevant information or assumptions.Example Input:["<char_1> wears a black suit and glasses.","<char_1> shakes hands with <char_2>.","<speaker_1> says: 'Hello, everyone.'","<char_2> wears a red dress and has long brown hair.","<char_2> listens attentively to <char_1>.","<speaker_2> says: 'Welcome to the meeting.'","<char_1> is the host of the meeting.","<char_2> is a colleague of <char_1>.""Equivalence: <char_3>, <speaker_3>."
]Example Output:["Equivalence: <char_1>, <speaker_1>.","Equivalence: <char_2>, <speaker_2>.","Equivalence: <char_3>, <speaker_3>."
]Please only return the valid string list (which starts with "[" and ends with "]"), without any additional explanation or formatting.Input:
{semantic_memory}Output:"""第二十三个模块原文
prompt_answer_with_retrieval_final = """You are given a question about a specific video and a dictionary of some related information about the video. Each key in the dictionary is a clip ID (an integer), representing the index of a video clip. The corresponding value is a list of video descriptions from that clip.Your task is to analyze the provided information, reason over it, and produce the most reasonable and well-supported answer to the question.Output Requirements:• Your response must begin with a brief reasoning process that explains how you arrive at the answer.• Then, output [ANSWER] followed by your final answer.• The format must be: Here is the reasoning... [ANSWER] Your final answer here.• Your final answer must be definite and specific — even if the information is partial or ambiguous, you must infer and provide the most reasonable answer based on the given evidence.• Do not refuse to answer or say that the answer is unknowable. Use reasoning to reach the best possible conclusion.Additional Guidelines:• When referring to a character, always use their specific name if it appears in the video information.• Do not use placeholder tags like <character_1> or <face_1>.• Avoid summarizing or repeating the video information. Focus on reasoning and answering.• The final answer should be short, clear, and directly address the question.Input:• Question: {question}• Video Information: {information}Output:"""第二十四个模块原文
prompt_refine_qa_list = """You are given a list of question-answer (QA) pairs based on specific videos, along with corresponding reasoning processes written in Chinese. Your task is to:1. Translate the reasoning processes into concise and fluent English, without changing their original meaning.2. Refine the reasoning to make it clearer and more precise, especially in terms of how the answer is logically derived from the video content.3. Revise the question and answer to ensure they are:• Natural and grammatically correct in English• Logically consistent with the reasoning• Expressed in a clear, specific, and rigorous wayAdditional Constraints:• Question:• Do not oversimplify or generalize the original question.• Preserve important contextual details or conditions from the original input.• The revised question should be more specific and tightly scoped, such that the video provides a unique and unambiguous answer.• Avoid vagueness or ambiguity; the revised question should not allow multiple valid answers.• Answer:• Ensure the answer is concise, grammatically correct, and semantically precise.• It should be directly supported by the reasoning and the video.• The answer should be unambiguous and standardized, suitable for use as ground truth in evaluation tasks.Output Format:Return a valid JSON list where each item contains:• "question": the revised English question• "answer": the revised English answer (refined for clarity and evaluability)• "reasoning": the translated and refined English reasoning explaining how the answer is derived from the videoExample Input:[{{"question": "what's the man doing?", "answer": "he fixing the car.", "reasoning": "需要从视频中找到男人正在修理汽车的场景。"}},{{"question": "why she looks angry?", "answer": "because someone take her bag.", "reasoning": "需要从视频中找到女人生气的原因。"}}
]Expected Output:[{{"question": "What is the man doing to the vehicle in the garage?", "answer": "He is repairing the car.", "reasoning": "There is a clip showing the man repairing a car in the garage."}},{{"question": "Why does the woman appear upset after walking into the hallway?", "answer": "Because someone took her bag.", "reasoning": "The video shows the woman appearing upset in the hallway after someone takes her bag."}}
]Now, apply the same logic to the following input:Input:{qa_list}Output:
(Only return the translated JSON list.)"""第二十五个模块原文
prompt_agent_verify_answer = """You are provided with a question, the ground truth answer, and the answer from an agent model. Your task is to assess whether the agent answer is semantically consistent with the ground truth answer, in the context of the question.If the meaning expressed by the agent answer aligns with the meaning of the ground truth answer — even if the wording or format is different — return "Yes". If the agent answer expresses a different or incorrect meaning, return "No".Do not require exact wording or surface form match. Semantic equivalence, given the context of the question, is sufficient.Please only return "Yes" or "No", with no additional explanation or formatting."""第二十六个模块原文
prompt_agent_verify_answer_referencing = """You are provided with a question, a ground truth answer, and an answer from an agent model. Your task is to determine whether the ground truth answer can be logically inferred from the agent's answer, in the context of the question.Do not directly compare the surface forms of the agent answer and the ground truth answer. Instead, assess whether the meaning expressed by the agent answer supports or implies the ground truth answer. If the ground truth can be reasonably derived from the agent answer, return "Yes". If it cannot, return "No".Important notes:• Do not require exact wording or matching structure.• Semantic inference is sufficient, as long as the agent answer entails or implies the meaning of the ground truth answer, given the question.• Only return "Yes" or "No", with no additional explanation or formatting.Input fields:• question: the question asked• ground_truth_answer: the correct answer• agent_answer: the model's answer to be evaluatedNow evaluate the following input:Input:• question: {question}• ground_truth_answer: {ground_truth_answer}• agent_answer: {agent_answer}Output ('Yes' or 'No'):"""第二十七个模块原文
prompt_agent_verify_answer_with_reasoning = """You are provided with a question, a ground truth answer, a reasoning that supports the ground truth answer (based on video content), and an answer from an agent model.Your task is to assess whether the agent answer is semantically valid, based on the question and the provided reasoning.Specifically:• If the agent answer expresses a meaning that is consistent with what can be reasonably inferred from the reasoning, return "Yes", even if it differs slightly from the ground truth answer in wording or phrasing.• If the agent answer conveys a different or incorrect meaning that is not supported by the reasoning, return "No".Do not require exact match between the agent answer and the ground truth answer. Use the reasoning as the primary source of truth — if the agent answer can be plausibly derived from the reasoning in the context of the question, it should be accepted as correct.Only return "Yes" or "No", with no additional explanation or formatting.Input fields:• question: the question asked about the video• ground_truth_answer: the correct answer• reasoning: explanation of how the answer is derived from the video• agent_answer: the answer generated by the model"""第二十八个模块原文
prompt_refine_answer = """You are given a question and its corresponding answer. Your task is to rewrite the answer to make it more concise, direct, and focused, so that it can be more easily and reliably evaluated for correctness.The revised answer should:• Clearly and explicitly address the question• Remove vague, redundant, or indirect phrasing• Preserve the original meaning, but express it in a shorter and more precise way• Be grammatically correct and unambiguous• Be suitable for use as a ground truth reference when evaluating other model outputsInput Format Example:{{"question": "What did the woman do after entering the room?","answer": "After she entered the room, she looked around and seemed confused."
}}Expected Output:She looked around and seemed confused.Now apply the same logic to the following input:Input:{qa_pair}Output:
(Directly return the revised answer.)"""第二十九个模块原文
prompt_refine_final_reasoning = """You are given a reasoning statement generated by the model in the final round of retrieval and analysis. Now, imagine that the model has already attempted multiple retrievals from the memory bank, but can no longer retrieve any new useful information.Your task is to:• Rephrase the beginning of this reasoning to reflect that the model has decided to stop retrieving and is now focusing on summarizing and analyzing the information it already has.• Keep the original logic and content of the reasoning unchanged, except for this addition.• Add a natural introduction such as:• "It seems no more useful information can be retrieved from memory, so now I will…"• "I can no longer retrieve helpful details, so I will analyze what I have gathered…"• "Further retrieval attempts have failed, so I will proceed with reasoning based on the available knowledge…"• Make sure the modified reasoning smoothly transitions into the original content.Example:Original Reasoning:
Bob's reaction in CLIP_3 shows clear frustration. Given his previous behavior and the group's dynamics, it is likely he disagreed with the decision made.Modified Reasoning:
It seems no more useful information can be retrieved from memory, so now I will analyze what I have. Bob's reaction in CLIP_3 shows clear frustration. Given his previous behavior and the group's dynamics, it is likely he disagreed with the decision made.Now, apply the same logic to the following reasoning:Original Reasoning:
{reasoning}Modified Reasoning:"""第二十九个模块原文
prompt_autodq = """Given a video description and a list of events. For each event, classify the relationship between the video description and the event into three classes: entailment, neutral, contradiction.- "entailment" means that the video description entails the event.
- "contradiction" means that some detail in the video description contradicts with the event.
- "neutral" means that the relationship is neither "entailment" or "contradiction".Output a list in Json format:
[ {{"event": "copy an event here", "relationship": "put class name here", "reason": "give a reason"}}, ... ]Video description:
{video_description}Events:
{events}DO NOT PROVIDE ANY OTHER OUTPUT TEXT OR EXPLANATION. Only output the JSON list in a **vliad format**.Output:"""第三十个模块原文
prompt_vdcscore_generate_qas = """You are an intelligent chatbot designed for generating 10 question-answer pairs given a detailed description of a video or image. You are describing the video.Here's how you can accomplish the task: INSTRUCTIONS:
- Cover the main objects and actions in the video or image.
- The questions should be open-ended and start with 'What', 'Who', 'Where', 'When', 'Why', 'How', etc.
- The answer should be a short sentence or phrase.
- Generate 10 question-answer pairs.Please generate 10 question-answer pairs given a detailed description of a video or image: Detailed description: {video_description}Please generate the response in the form of a Python list of tuple with the question and the corresponding answer. DO NOT PROVIDE ANY OTHER OUTPUT TEXT OR EXPLANATION. Only provide the Python list of tuple. For example, your response should look like this: [(the question 1, the answer 1), (the question 2, the answer 2), . . . ].QA pairs:"""第三十一个模块原文
prompt_vdcscore_answer = """You are an intelligent chatbot designed for providing accurate answers to questions related to the content based on a detailed description of a video or image.Here's how you can accomplish the task:INSTRUCTIONS:
- Read the detailed description carefully.
- Answer the question only based on the detailed description.
- The answer should be a short sentence or phrase.Please provide accurate answers to questions related to the content based on a detailed description of a video or image:Detailed description: {video_description}Question: {question}DO NOT PROVIDE ANY OTHER OUTPUT TEXT OR EXPLANATION. Only provide short but accurate answer.Answer:"""第三十二个模块原文
prompt_vdcscore_verify = """You are an intelligent chatbot designed for evaluating the correctness of generative outputs for questionanswer pairs. Your task is to compare the predicted answer with the correct answer and determine if they match meaningfully.Here's how you can accomplish the task:INSTRUCTIONS:
- Focus on the meaningful match between the predicted answer and the correct answer.
- Consider synonyms or paraphrases as valid matches.
- Evaluate the correctness of the prediction compared to the answer.Please evaluate the following video-based question-answer pair:Question: {question}
Correct Answer: {correct_answer}
Predicted Answer: {predicted_answer}Provide your evaluation only as a yes/no and score where the score is an integer value between 0 and 5, with 5 indicating the highest meaningful match.Please generate the response in the form of a Python dictionary string with keys 'pred' and 'score', where value of 'pred' is a string of 'yes' or 'no' and value of 'score' is in INTEGER, not STRING.DO NOT PROVIDE ANY OTHER OUTPUT TEXT OR EXPLANATION. Only provide the Python dictionary string. For example, your response should look like this: {{'pred': 'yes', 'score': 4.8}}.Evaluation:"""第三十三个模块原文
prompt_generate_action_qwen3 = """You are given a question and some relevant knowledge. Your task is to reason about whether the provided knowledge is sufficient to answer the question. If it is sufficient, output [Answer] followed by the answer. If it is not sufficient, output [Search] and generate a query that will be encoded into embeddings for a vector similarity search. The query will help retrieve additional information from a memory bank.Output the answer in the format:
Action: [Answer] or [Search]
Content: {{content}}If the answer can be derived from the provided knowledge, the {{content}} is the specific answer to the question, do not use ID tags like <character_0>.
If the answer cannot be derived yet, the {{content}} should be a single search query that would help retrieve the missing information.
You can get the mapping relationship between character ID and name by using search query such as: "What is the name of <character_0>" or "What is David's character".
You need to provide an answer within 5 rounds.Question: {question}"""第三十四个模块原文
prompt_mlvu_multiple_choice = """Carefully watch this video and pay attention to every detail. Based on your observations, select the best option that accurately addresses the question.Question: {question}Options:
{options}Only return the number of the best option, not the option text.Answer:"""第三十五个模块原文
prompt_mlvu_generation_sum = """Carefully watch this video and pay attention to every detail. Based on your observations, answer the given questions.Question: Please summarize the main content of this video.Answer:"""第三十六个模块原文
prompt_mlvu_generation_subscene = """Carefully watch this video and pay attention to every detail. Based on your observations, answer the given questions.Question: {question}Answer:"""第三十七个模块原文
prompt_mlvu_evaluation_subscene = """##TASK DESCRIPTION: You are required to evaluate a respondent's answer based on a provided question, some scoring points, and the respondent's answer. You should provide two scores. The first is the accuracy score, which should range from 1 to 5. The second is the relevance score, which should also range from 1 to 5. Below are the criteria for each scoring category.##ACCURACY Scoring Criteria:
Evaluate the respondent's answer against specific scoring points as follows:
Score 1: The response completely misses the scoring point.
Score 3: The response mentions content related to the scoring point but is not entirely correct.
Score 5: The response accurately addresses the scoring point.
Calculate the average score across all scoring points to determine the final accuracy score.##RELEVANCE Scoring Criteria:
Assess how the respondent's answer relates to the original question:
Score 1: The response is completely off-topic from the question.
Score 2: The response is partially related to the question but contains a significant amount of irrelevant content.
Score 3: The response primarily addresses the question, but the respondent seems uncertain about their own answer.
Score 4: The response mostly addresses the question and the respondent appears confident in their answer.
Score 5: The response is fully focused on addressing the question with no irrelevant content and demonstrates complete certainty.##INSTRUCTION:
1. Evaluate ACCURACY: First, assess and score each scoring point based on the respondent's answer. Calculate the average of these
scores to establish the final accuracy score. Provide a detailed rationale before assigning your score.
2. Evaluate RELEVANCE: Assess the relevance of the respondent’s answer to the question. Note that when evaluating relevance, the
correctness of the answer is not considered; focus solely on how relevant the answer is to the question. Provide a comprehensive
rationale before assigning your score.
3. Output Scores in JSON Format: Present the scores in JSON format as follows:{{"accuracy": 3,"relevance": 4
}}DO NOT PROVIDE ANY OTHER OUTPUT TEXT OR EXPLANATION. Only output the JSON.Question: {question}Scoring points:
{scoring_points}Respondent's answer:
{respondent_answer}Evaluation:"""第三十八个模块原文
prompt_mlvu_evaluation_sum = """##TASK DESCRIPTION:
You are required to evaluate the performance of the respondent in the video summarization task based on the standard answer and the respondent's answer. You should provide two scores. The first is the COMPLETENESS score, which should range from 1 to 5. The second is the RELIABILITY score, which should also range from 1 to 5. Below are the criteria for each scoring category:##COMPLETENESS Scoring Criteria:
The completeness score focuses on whether the summary covers all key points and main information from the video.
Score 1: The summary hardly covers any of the main content or key points of the video.
Score 2: The summary covers some of the main content and key points but misses many.
Score 3: The summary covers most of the main content and key points.
Score 4: The summary is very comprehensive, covering most to nearly all of the main content and key points.
Score 5: The summary completely covers all the main content and key points of the video.##CORRECTNESS Scoring Criteria:
The correctness score evaluates the correctness and clarity of the video summary. It checks for factual errors, misleading statements,
and contradictions with the video content. If the respondent's answer includes details that are not present in the standard answer, as
long as these details do not conflict with the correct answer and are reasonable, points should not be deducted.
Score 1: Contains multiple factual errors and contradictions; presentation is confusing.
Score 2: Includes several errors and some contradictions; needs clearer presentation.
Score 3: Generally accurate with minor errors; minimal contradictions; reasonably clear presentation.
Score 4: Very accurate with negligible inaccuracies; no contradictions; clear and fluent presentation.
Score 5: Completely accurate with no errors or contradictions; presentation is clear and easy to understand.##INSTRUCTION:
1. Evaluate COMPLETENESS: First, analyze the respondent's answer according to the scoring criteria, then provide an integer score
between 1 and 5 based on sufficient evidence.
2. Evaluate CORRECTNESS : First, analyze the respondent's answer according to the scoring criteria, then provide an integer score
between 1 and 5 based on sufficient evidence.
3. Output Scores in JSON Format: Present the scores in JSON format as follows:{{"completeness": 3,"correctness": 4
}}DO NOT PROVIDE ANY OTHER OUTPUT TEXT OR EXPLANATION. Only output the JSON.Question: {question}Standard answer:
{standard_answer}Respondent's answer:
{respondent_answer}Evaluation:"""第三十九个模块原文
prompt_videomme_multiple_choice = """Carefully watch this video and pay attention to every detail. Based on your observations, select the best option that accurately addresses the question.Question: {question}Options:
{options}Only return the number of the best option, not the option text.Answer:"""第四十个模块原文
prompt_generate_qa_from_route = """You are given a list of events extracted from a video. Each event is associated with a unique integer ID. Your task is to generate a single question-answer (QA) pair that reflects as much relevant information from the events as possible, while adhering to the following strict requirements:1. Do not use character identifiers like <character_1>, <character_2>, etc.2. Refer to individuals using specific and contextually meaningful descriptions (e.g., their names or appearance), rather than vague terms like "the man" or "someone".3. Refer to actions, locations, and events with enough specificity that your question remains unambiguous even within the broader context of the entire video. Avoid vague phrases like "that event" or "what happened there".4. The question must be atomic — focused on a single clear, answerable point, not a mixture of sub-questions.5. The answer must be concise, factually accurate, and easy to verify based on the provided events.6. Include as much relevant information from the events as possible, as long as it fits naturally into a single atomic question and concise answer.7. Additionally, return a field called related_ids — a list of the integer IDs of all events necessary to answer the question accurately.Return your result in the following JSON format:{{"question": "Your generated question here.","answer": "Your concise and verifiable answer here.","related_ids": [list of relevant event IDs]
}}Here is the list of events:{events}Make sure the QA pair is informative, natural-sounding, and grounded in the content of the events. The related_ids field must reflect exactly the subset of events needed to understand and answer the question. Do not include any explanation or other text except the JSON.Answer:"""Prompt模块
视频基础信息提取(语音 + 人物特征)
目标:从视频中提取结构化的语音片段、人物特征(人脸 / 语音 ID),为后续分析打基础

视频内容描述(情景记忆 / Episodic Memory)
目标:将视频中的 “可观察事件” 转化为结构化、原子化的文字描述,覆盖人物外观、动作、对话、互动等维度。
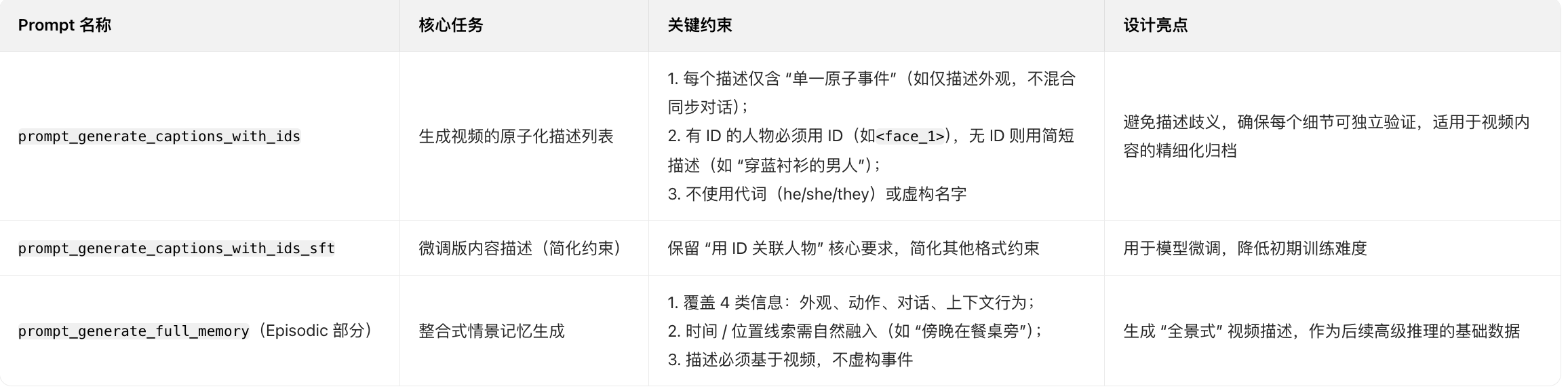
视频高级推理(语义记忆 / Semantic Memory)
目标:从 “表面描述” 中提炼 “深层结论”,覆盖人物关联、人物属性、人际关系、剧情理解、常识推断 5 大维度,属于 “超越观察的思考”。

视频问答与检索规划(动态决策)
目标:基于 “已有知识” 判断是否需进一步检索信息,若需检索则生成精准查询,最终完成问答任务。属于 “动态推理流程” 设计,覆盖 “检索规划→查询生成→结果整合” 全链路。
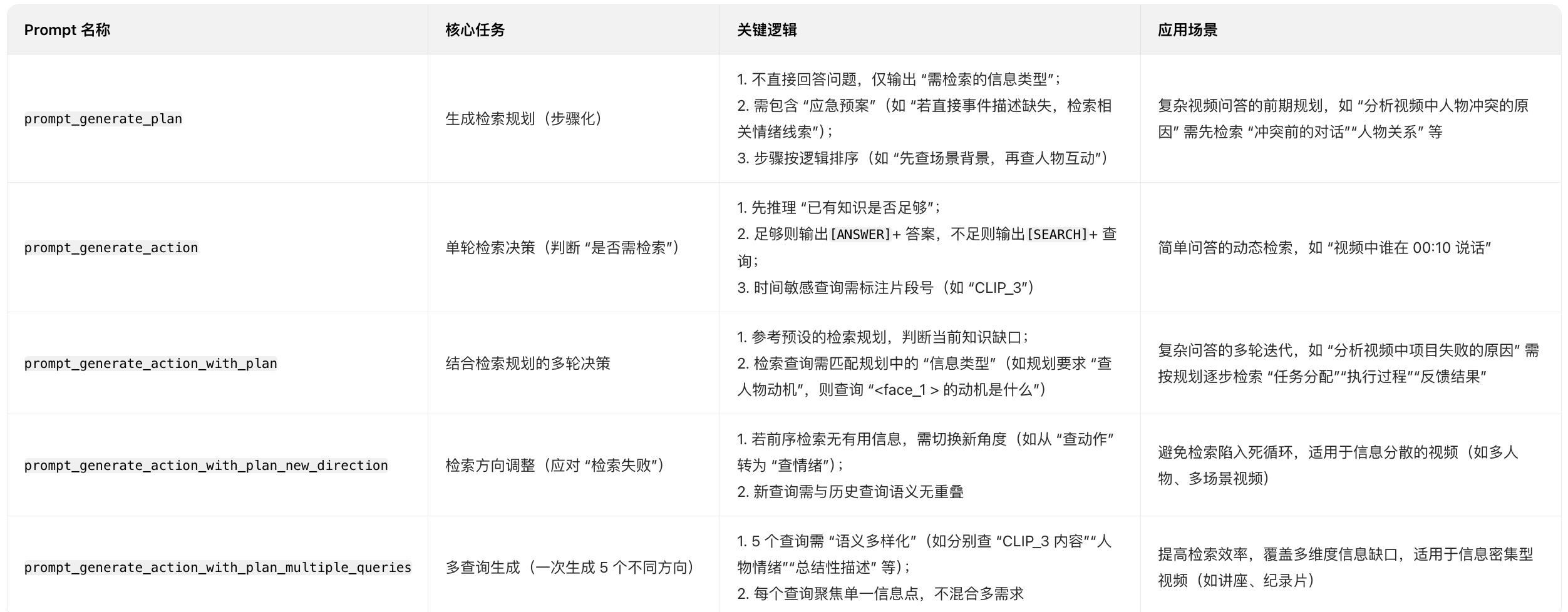
结果评估与验证
目标:对 “视频分析结果”(如问答答案、描述一致性、推理结论)进行客观评估,判断其正确性、一致性或完整性,构建评估体系。
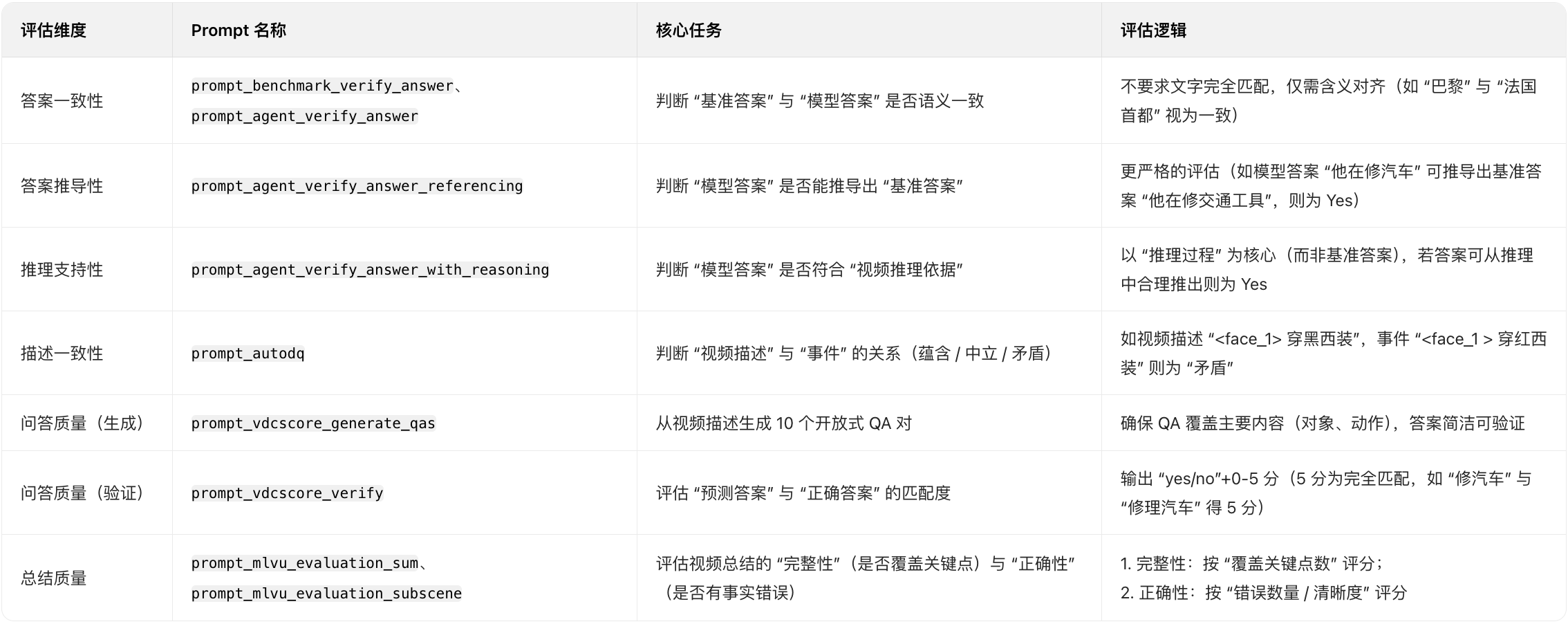
结果优化与格式规整
目标:对 “初步分析结果”(如 QA 对、推理过程)进行格式优化或语义精炼,提升结果的可读性、可评估性。

关键术语

核心应用场景
视频内容结构化:如会议视频的 “语音 - 人物 - 动作” 关联归档,方便后续检索(如 “查 00:30 谁在讨论项目进度”)
人物行为分析:如访谈视频中 “说话人身份识别”、“人物情绪变化推断”
视频问答系统:如用户提问 “视频中为什么两人会争吵”,系统通过多轮检索 + 推理输出答案
模型微调与评估:为视频理解模型(如多模态 LLM)提供标准化的 “输入 - 输出” 训练数据,以及客观的评估指标
其他
所有 Prompt 均强调 “无歧义” 和 “可验证”:
- 人物用唯一 ID 关联,避免 “他 / 她” 指代混乱
- 描述按 “原子事件” 拆分,每个细节可独立核对
- 推理结论需基于视频证据,不引入主观臆断
- 评估标准量化(如 0-5 分、Yes/No),避免模糊判断