简单了解一下GraphRAG
传统RAG的缺点
当我们将一段文本信息以句子分割后,存入到向量数据库中。用户提问“老王喜欢吃什么”,这个问题会与向量数据库中的许多句子关联性比较强,能返回准确且具体的信息。
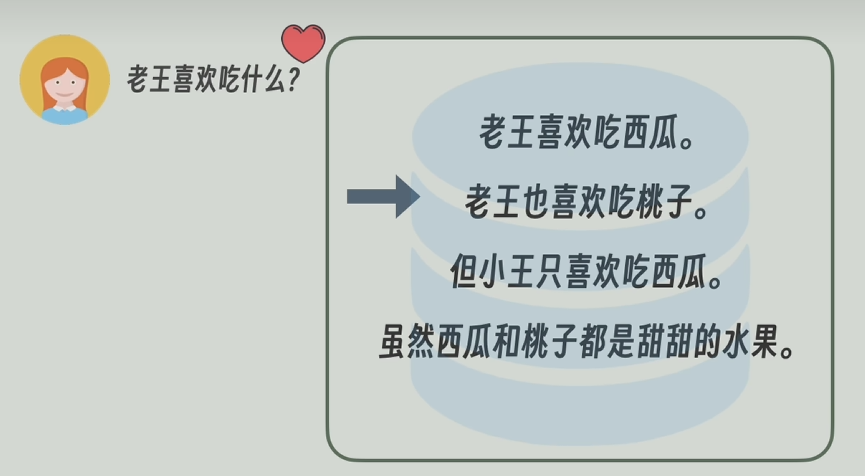
但是,若是问题换成“出现了几次西瓜”,西瓜是一个比较具体的名词/物品,它容易出现在很多句子中,但是在出现的句子中占比又不是很大。

用户的问题中的“西瓜”,在“老王喜欢吃西瓜”这句话中出现,但是这句话的只有一小部分信息是“西瓜”,所以,在提问这种比较细节性的问题时,在做问题与句子之间的相似度计算,相似度可能并不是很大,这就导致最后的查询结果会漏掉一些句子,甚至匹配错误。

那么如果划分的颗粒度再细一点,将“老王喜欢吃瓜”,切成“老王”,“喜欢吃”,‘西瓜’,又分成了三段,那么问题“西瓜出现几次”这个问题可能会比较好解决了(因为“西瓜”单独出现了),但是回到原问题“老王喜欢吃什么”又难以解决了,因为“老王喜欢吃什么”,只会匹配到“老王”和“喜欢吃”,匹配不到‘西瓜’,所以原问题又难以得到解决。

所以当划分段落的颗粒度比较粗,容易丢失细节,若划分颗粒度太细,语义之间的联系(老王--->喜欢吃---->西瓜)又被消除。这就是传统RAG的缺点之一。

1. 检索层面的缺点
-
语义召回不稳定:依赖向量召回(如基于 embedding),可能出现召回不相关或遗漏关键信息的情况。
-
知识碎片化:检索出的文档片段往往是局部的,缺乏整体结构,模型容易“拼凑”出不连贯的回答。
-
依赖索引质量:如果文本清洗、切分、embedding 表达不佳,检索效果会大幅下降。
2. 生成层面的缺点
-
上下文窗口限制:检索到的内容需要塞进模型上下文,受限于窗口大小,导致长文档场景容易丢失重要信息。
-
幻觉问题仍存在:虽然 RAG 能缓解模型“胡编乱造”,但如果检索不准,模型仍可能基于错误内容生成回答。
-
信息融合困难:模型可能无法很好地整合多个检索片段的信息,尤其是在需要推理、对比或跨段整合时。
3. 系统架构层面的缺点
-
延迟较高:RAG 需要两步(检索 + 生成),相比纯生成模型响应更慢。
-
维护复杂:需要单独维护知识库、向量索引和更新流程,工程成本高。
-
难以动态更新:传统 RAG 对知识更新通常需要重新向量化和索引,实时性不足。
4. 应用层面的缺点
-
鲁棒性不足:对用户提问方式敏感,表达不同可能导致检索结果差异显著。
-
领域依赖强:在知识高度专业、语义微妙的领域(如法律、医疗),检索误差对结果影响极大。
-
可解释性有限:虽然能返回检索片段,但生成结果和检索片段之间的逻辑联系往往不透明。
知识图谱
为了解决传统RAG的缺点,人们就应用知识图谱。下面这张就是一个典型的图谱,有实体节点“老王”和“习惯”,也有关系节点“爱吃”。

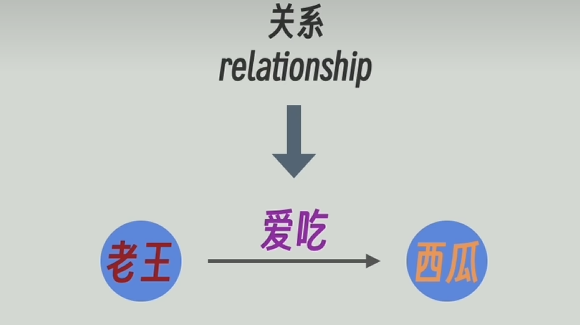
我们还可以赋予实体节点和关系节点属性和描述,比如实体节点“老王”,他的标签/属性可以是“人”,可以附带描述“爱吃西瓜”,关系节点“爱吃”,可以有描述“老王爱吃的东西”等等。比如,在neo4j图知识库中可以轻松做到这些。

在传统知识图谱构建中,我们需要从这一段文字中找出实体,抽取出实体之间的关系,算法十分复杂而且性能也一般。但是,再出现大模型之后,这些步骤就相对容易许多,而且性能也很好。做法就是,写好一段示例,并加上数据传给大模型,让大模型来抽取出实体和关系。需要注意的是里面的实体类型,需要我们自己定义,你可以认为“人”是实体,可以认为“水果”是实体,还可以认为“味道”是实体。
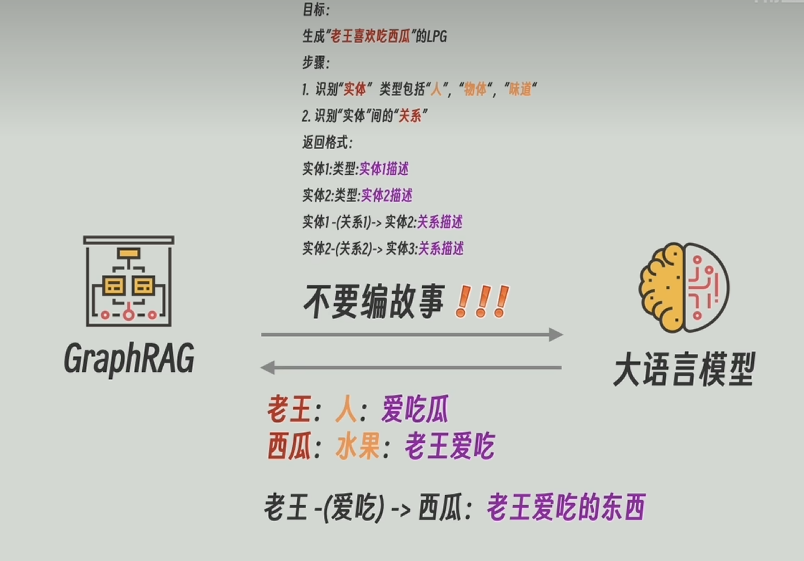
并且当大模型返回解析后的知识图谱之后,通常来说我们会将知识图谱和原文再发送给大模型,再让他解析,循环往复直到大模型任务这个原文的实体和关系都已经以最细的粒度抽取完毕了。

这样我们就借助大模型生成了某一文本段落的知识图谱。
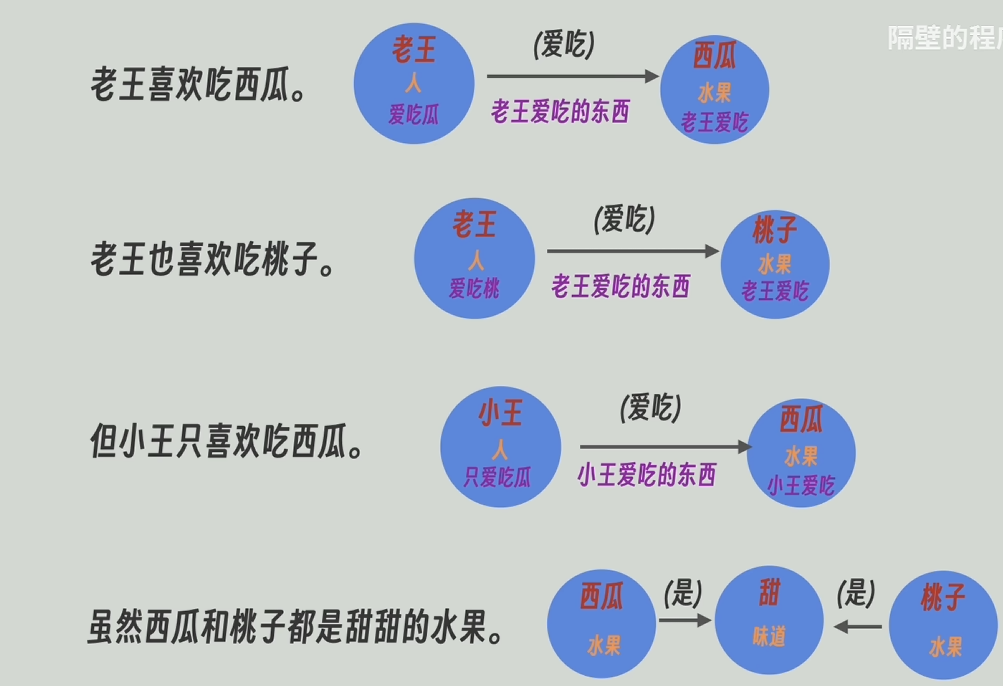
GraphRAG
合并图谱
将拆分后的每个段落生成的知识图谱合并,节点和关系合并的时候,其所带的描述信息也会一同合并。
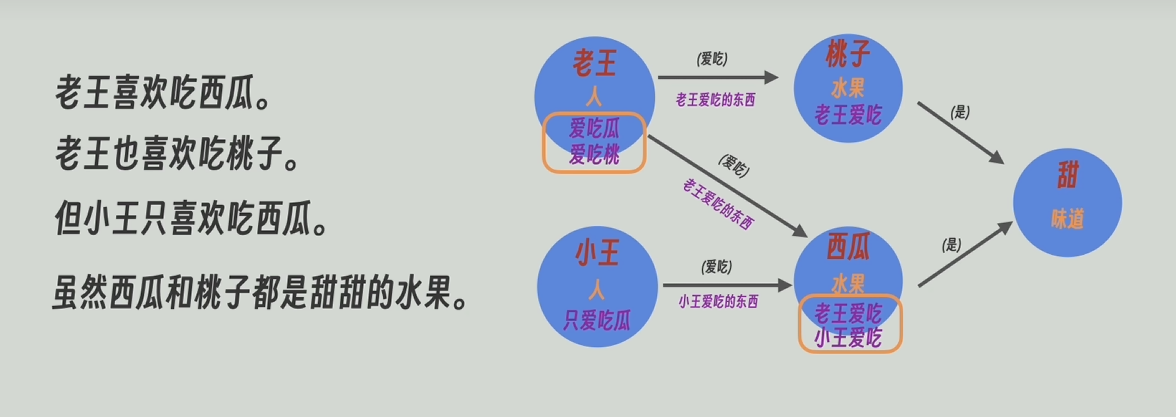
之后,把每个节点和关系(边)的合并后的描述信息再发送给大模型,让他对这些信息再总结一下,高度概括一下。
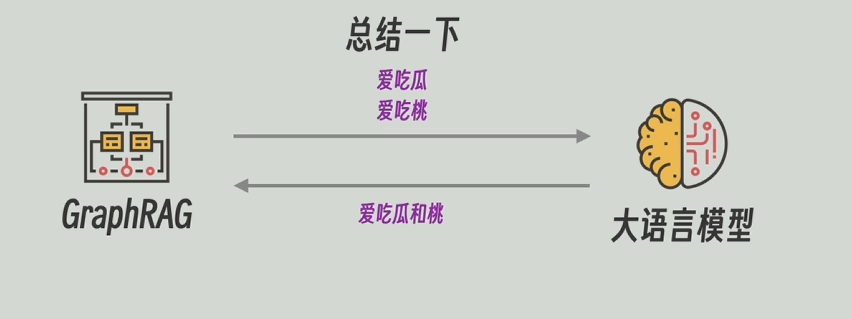
用大模型高度总结后的描述信息代替原本合并后的描述信息。此外GraphRAG还会一直维护着图谱和原文的关联信息。比如实体节点“老王”是由哪几段生成。
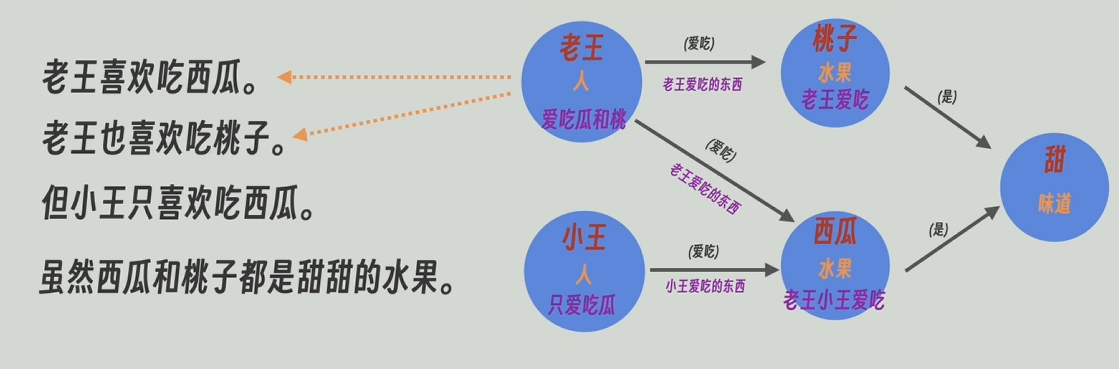
同理,一段原文也会对应着知识图谱中的哪些实体节点和关系节点

简化图谱
现在的知识图谱太大了,GraphRAG会通过算法合并部分图谱作为一个整体,比如将现在的知识图谱合并成了两个整体。
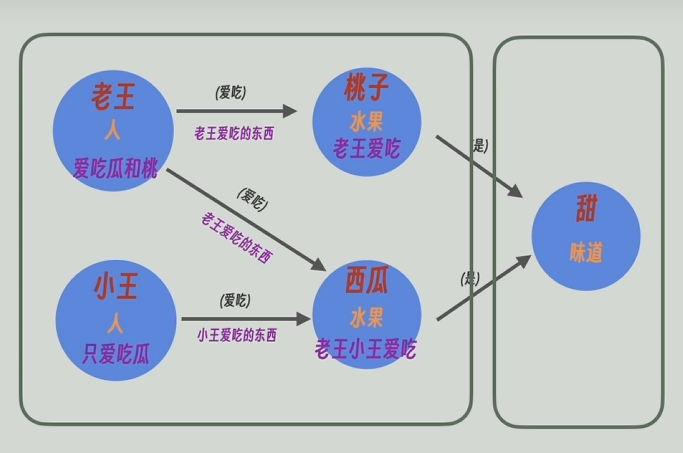
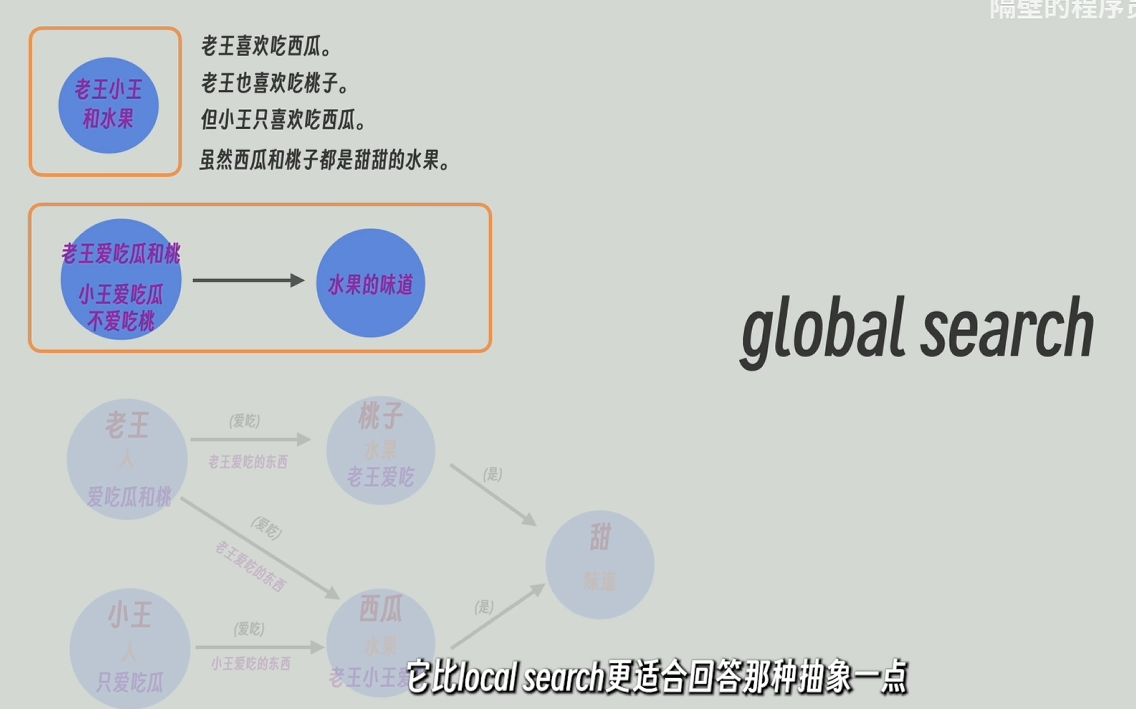
再把每个整体中的所有节点和关系的描述信息发送给大模型,再让大模型进行高度总结,甚至还能推理。比如通过“老王爱吃瓜和桃”和“小王只爱吃瓜”能总结/推理出“小王不爱吃桃”,再将高度总结后的更宽泛更高维的信息返回。
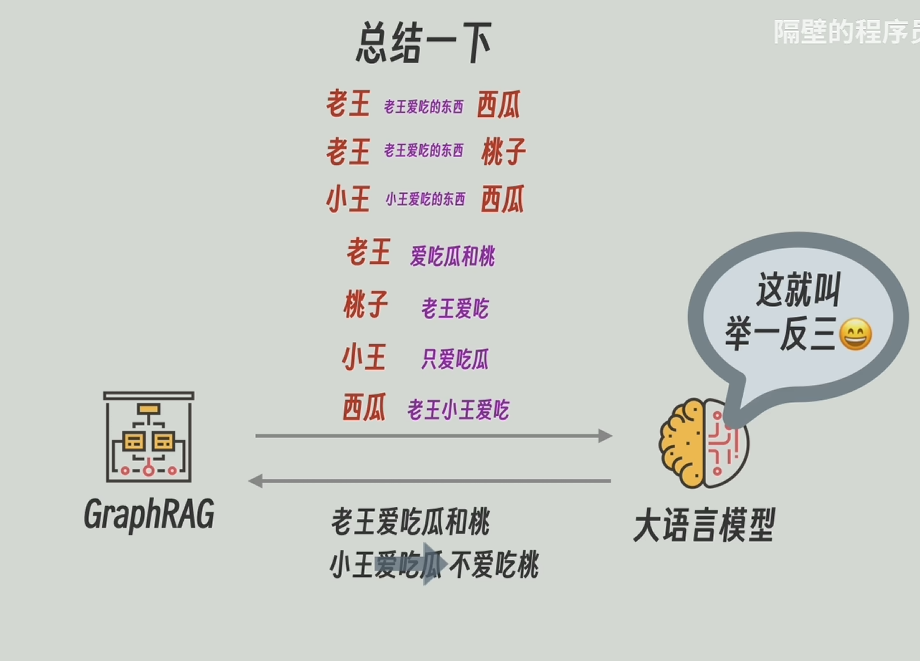
循环此操作,就可以得到一个层级结构的知识图谱,越往上,信息越凝练高度概括,越往下信息越详细
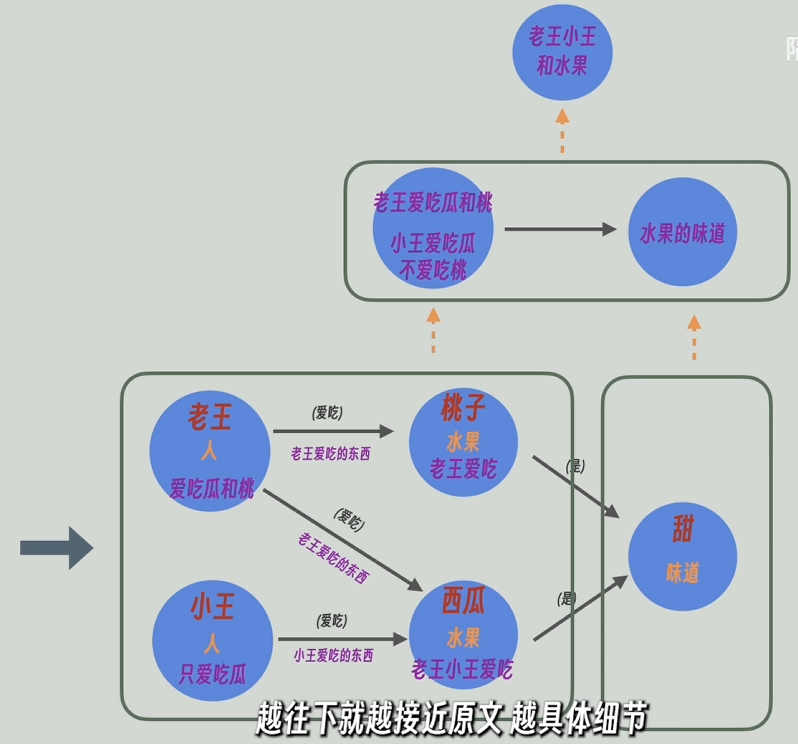
查询
把这个层级结构的知识图谱中的每条边每个节点的实体信息和描述都当做文本片段embedding后存入向量数据库中

同时,将原文的每个切片也都存入向量数据库中
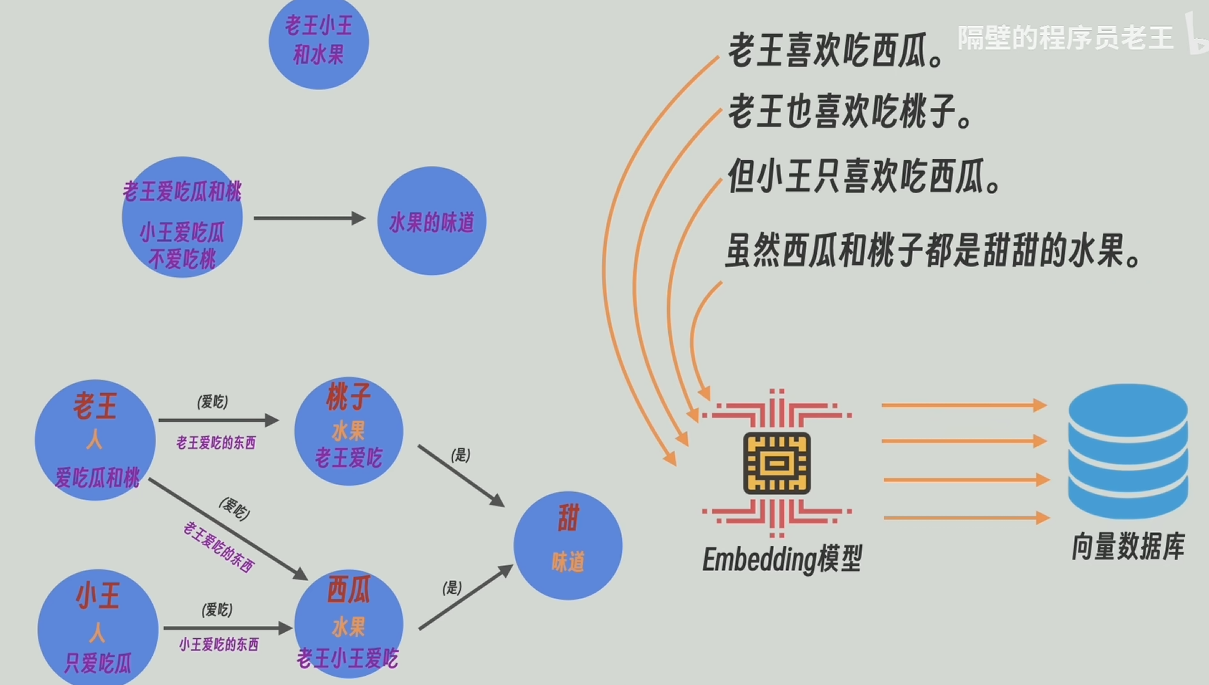
接下来就是把用户的提问转为embedding之后,可以和知识图谱某基层也可以和原文片段进行匹配,也可以全部查一遍
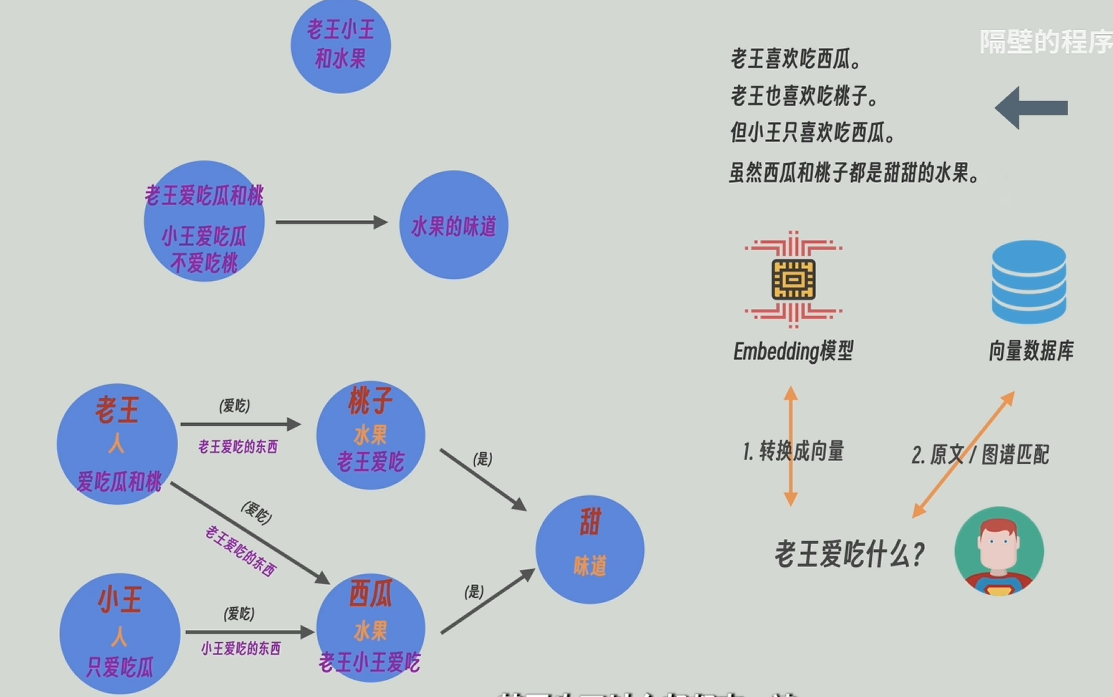
local_search策略:先从最底层(详细接近原文)的知识图谱中找出和问题最近的实体,再反向查询这个底层的知识图谱是由原文中哪些片段组成的,这个底层的知识图普相关的上层(有高层次的抽象问题)或相邻的节点(低层次的细节问题)和关系也会被找到,最后将这些节点和边的信息和原文片段和问题一起发给大模型。local_search从最底层,所以适应细节问题

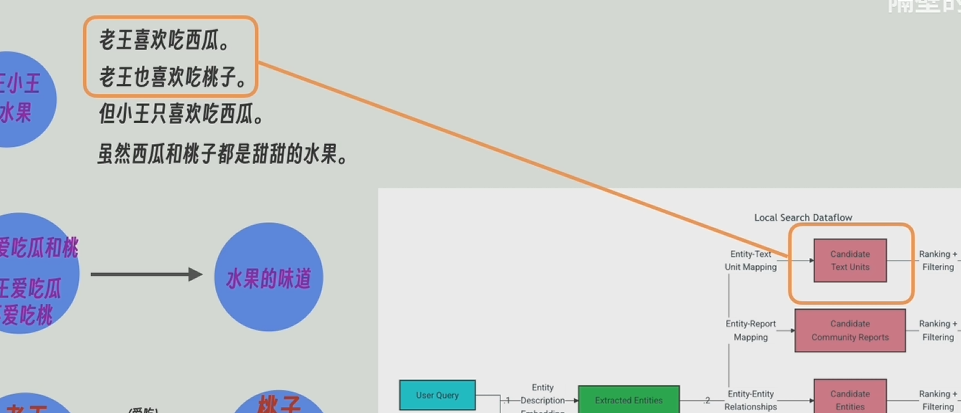

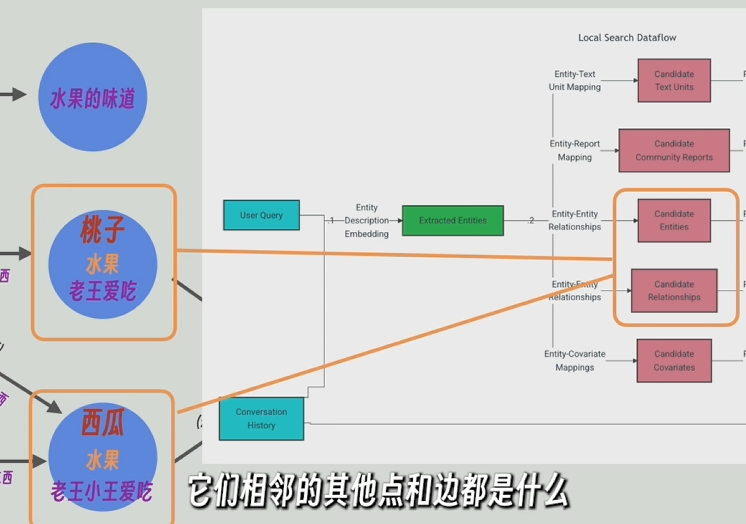

global_serch从知识图谱的顶层开始查起,所以比较适用于高层次抽象问题,比如“这篇文章的主旨是什么”
补充
莱顿社区检测算法








b站:AI知识图谱 GraphRAG 是怎么回事?_哔哩哔哩_bilibili