机器学习-数据清理、数据变换
数据清理
数据处理流程
- 是否有足够的数据
- 改善数据还是模型
- 若要提升数据质量,数据是否noisy–若是,则要进行数据清理
- 若数据比较干净,数据格式是否是模型想要的格式–若不是,则要进行数据变换
- 若数据格式正确,模型训练是否困难–若是,则要对数据进行特征提取
数据错误类型:
- outliers:数据偏离了正常的数据分布区间
- rule violations:超出了数值的限制,如“不能为空”或“必须是独有的”
- pattern violations:违反了语法语义上的一些限制
基于规则的检测
- functional dependencies(功能性依赖):x->y,若y依赖于x,则两者之间的关系要正确
- denial constraints:更灵活的一阶逻辑表达式,基于制定规则的检测
基于模式的检测
- 基于语法的:eng->English
- 基于语义的:通过知识图谱添加规则
数据变换
真实数据的四种normalization手段:
- 将最小、最大值限制在某一区间:
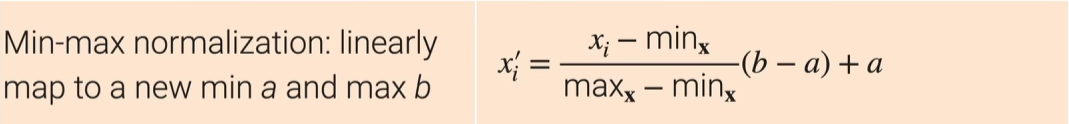
- 把所有元素的均值变为0,方差变成1(标准正态分布化):

- 小数化(将所有数限制在-1和+1之间):

- 对数化:

图片变换
一般采用降维的方法减少图片像素(剪裁、下采样)
视频变换
通常使用短视频片段作为一个单独的event
文本变换
- 词根化、语法化
am,is,are->be
car,cars,car’s,cars’->car - 词元化(tokenization)
text.split(’ ‘):把每个单词做一个词元
text.split(’'):把每个字母做一个词元