【PostgreSQL内核学习:表达式】
PostgreSQL内核学习:表达式
- ExecInitExpr
- 主要流程(以 SQL 为例)
- ExecCreateExprSetupSteps
- expr_setup_walker
- ExecPushExprSetupSteps
- 主要流程(以 SQL 为例)
- ExecInitExprRec
- 主要流程(以 SQL 为例)
- 表格:`ExecInitExprRec` 中 `case` 分支汇总
- 说明
- 为什么重要?
- ExprEvalPushStep
- 主要流程(以 SQL 为例)
- ExecReadyExpr
- ExecReadyInterpretedExpr
- ExecInterpExpr
- 表格:`ExecInterpExpr` 中 `case` 分支汇总
- 说明与重要性
- 总结
- 参考文档:
声明:本文的部分内容参考了他人的文章。在编写过程中,我们尊重他人的知识产权和学术成果,力求遵循合理使用原则,并在适用的情况下注明引用来源。
本文主要参考了 postgresql-18 beta2 的开源代码和《PostgresSQL数据库内核分析》一书
ExecInitExpr
ExecInitExpr 是 PostgreSQL 查询执行引擎中的一个核心函数,用于初始化一个表达式树(Expr),将其转换为可执行的状态(ExprState)。表达式树通常表示 SQL 查询中的条件、计算或聚合操作(如 WHERE 子句、计算列等)。
我将用一个简单的 SQL 查询示例,结合 ExecInitExpr 函数的每一步,通俗解释其作用。假设我们有一个 SQL 查询:
SELECT name, age + 10 AS new_age FROM users WHERE age > 30;
这个查询中的表达式是 age + 10 和 age > 30。ExecInitExpr 的任务是把这些表达式准备成可执行的状态。下面是每一步的通俗解释,结合这个 SQL 示例:
/** ExecInitExpr: 准备一个表达式树以供执行* 类似于把 SQL 表达式(如 age + 10 或 age > 30)翻译成计算机能执行的指令。*/
ExprState *
ExecInitExpr(Expr *node, PlanState *parent)
{ExprState *state; // 声明一个“执行计划书”,用来记录怎么执行表达式ExprEvalStep scratch = {0}; // 准备一个临时“指令卡”,用来写执行步骤/* 特殊情况:如果没有表达式(比如 SQL 没写 WHERE),直接返回空 */if (node == NULL)return NULL;// SQL 例子:如果没有 WHERE 子句,直接返回空,不需要处理表达式。/* 初始化“执行计划书”,分配空间并记录表达式和上下文 */state = makeNode(ExprState); // 创建一个空的“执行计划书”state->expr = node; // 记录表达式,比如“age + 10”或“age > 30”state->parent = parent; // 记录这是哪个查询计划的一部分state->ext_params = NULL; // 暂时没有外部参数// SQL 例子:为“age + 10”创建一个计划书,标记它属于 SELECT 查询。/* 根据需要添加初始化步骤,比如准备变量或函数 */ExecCreateExprSetupSteps(state, (Node *) node); // 准备执行环境,比如确保“age”列可以读取// SQL 例子:确保“age”列的数据可以从 users 表中取出来。/* 编译表达式,生成具体的执行步骤 */ExecInitExprRec(node, state, &state->resvalue, &state->resnull); // 把“age + 10”翻译成“取 age,加 10,存结果”// SQL 例子:为“age + 10”生成步骤:1. 取 age 值,2. 加 10,3. 保存结果到 new_age。/* 添加一个“完成”指令,表示表达式处理完了 */scratch.opcode = EEOP_DONE; // 写一张“结束”指令卡ExprEvalPushStep(state, &scratch); // 把“结束”指令加到计划书// SQL 例子:告诉计算机“age + 10”算完了,可以返回结果。/* 最后检查,确保计划书可以执行 */ExecReadyExpr(state); // 检查计划书,确保没问题,可以开始运行// SQL 例子:确认“age + 10”和“age > 30”的执行步骤都准备好了。/* 返回准备好的执行计划书 */return state;// SQL 例子:返回一个包含“age + 10”和“age > 30”执行步骤的计划书,供查询使用。
}
主要流程(以 SQL 为例)
- 检查空表达式:如果
SQL没有WHERE或计算列(比如SELECT * FROM users),直接返回空,不需要处理。 - 创建计划书:为表达式(如
age + 10或age > 30)创建一个“执行计划书”,记录表达式和查询的上下文。 - 准备环境:确保表达式用到的列(比如
age)可以从表中读取,可能还包括准备函数或聚合操作。 - 翻译表达式:把表达式翻译成计算机能懂的步骤,比如“取
age,加10,存结果”。 - 添加结束标志:在步骤最后加一个“完成”标志,告诉计算机表达式处理完了。
- 检查并返回:确认计划书没问题,返回给查询执行器,准备运行。
ExecCreateExprSetupSteps
该函数是表达式初始化的“总指挥”,负责为 SQL 表达式(如 age + 10 或 age > 30)生成执行前的准备步骤。它先通过 expr_setup_walker 检查表达式需要哪些数据(比如字段 age 或子查询),然后调用 ExecPushExprSetupSteps 把这些需求翻译成具体的初始化指令。就像在执行 SQL 前,先列一个清单,写好“要从 users 表取 age 字段”的准备工作。
/** ExecCreateExprSetupSteps: 为表达式添加执行前的初始化步骤* 类似于在执行 SQL 表达式(如 age + 10)前,检查需要准备哪些数据或环境。*/
static void
ExecCreateExprSetupSteps(ExprState *state, Node *node)
{ExprSetupInfo info = {0, 0, 0, NIL}; // 创建一个“准备清单”,记录需要哪些初始化工作// SQL 例子:为“age + 10”创建一个清单,记录需要从 users 表取 age。/* 扫描表达式,找出需要的初始化工作 */expr_setup_walker(node, &info); // 检查表达式树,标记需要的数据(如 age 字段)// SQL 例子:扫描“age + 10”,发现需要从 users 表取 age 字段。/* 根据清单生成初始化步骤 */ExecPushExprSetupSteps(state, &info); // 根据清单生成具体的准备步骤// SQL 例子:为读取 age 字段生成指令,确保执行时能找到 age 的值。
}
expr_setup_walker
该函数像一个“侦察员”,递归遍历 SQL 表达式的树结构,找出所有需要的数据或特殊操作。它会记录表达式中用到的字段(比如 age)来自哪里(普通表、内连接表或外连接表),以及是否有特殊的子查询(MULTIEXPR 类型)。它会忽略聚合函数(如 SUM)或窗口函数的参数,因为这些不在当前上下文执行。最终,它把这些信息存到“准备清单”中,供后续生成指令用。
/** expr_setup_walker: 检查表达式树,记录需要的初始化工作* 像是在 SQL 表达式中找需要用到的字段或子查询,记下来以便准备。*/
static bool
expr_setup_walker(Node *node, ExprSetupInfo *info)
{if (node == NULL) // 如果没有表达式节点,直接退出return false;// SQL 例子:如果没有 WHERE 或计算列,直接返回。if (IsA(node, Var)) // 如果节点是一个字段(变量){Var *variable = (Var *) node; // 获取字段信息AttrNumber attnum = variable->varattno; // 获取字段编号(如 age 的列号)switch (variable->varno) // 根据字段来源分类{case INNER_VAR: // 字段来自内表(比如内连接的表)info->last_inner = Max(info->last_inner, attnum); // 记录内表需要的最大字段编号break;// SQL 例子:如果 age 来自内连接的表,记录需要取 age。case OUTER_VAR: // 字段来自外表info->last_outer = Max(info->last_outer, attnum); // 记录外表需要的最大字段编号break;// SQL 例子:如果 age 来自外连接的表,记录需要取 age。default: // 字段来自普通表扫描info->last_scan = Max(info->last_scan, attnum); // 记录扫描表需要的最大字段编号break;// SQL 例子:age 来自 users 表,记录需要从 users 表取 age。}return false; // 字段处理完,不需要继续深入}/* 收集特殊的子查询(MULTIEXPR 类型) */if (IsA(node, SubPlan)) // 如果节点是一个子查询{SubPlan *subplan = (SubPlan *) node; // 获取子查询信息if (subplan->subLinkType == MULTIEXPR_SUBLINK) // 如果是 MULTIEXPR 子查询info->multiexpr_subplans = lappend(info->multiexpr_subplans, subplan); // 记录到清单// SQL 例子:如果有子查询(如 SELECT ... WHERE id IN (SELECT ...)),记录需要准备子查询。}/* 忽略聚合函数、窗口函数、分组函数的参数,因为它们不在当前上下文执行 */if (IsA(node, Aggref)) // 聚合函数(如 SUM)return false; // 不处理其参数// SQL 例子:如果有 SUM(age),忽略 SUM 内部的 age。if (IsA(node, WindowFunc)) // 窗口函数(如 ROW_NUMBER)return false; // 不处理其参数if (IsA(node, GroupingFunc)) // 分组函数return false; // 不处理其参数/* 递归检查表达式的子节点 */return expression_tree_walker(node, expr_setup_walker, info);// SQL 例子:继续检查“age + 10”中的 age 和 10,确保所有部分都记录。
}
ExecPushExprSetupSteps
这个函数是“执行计划的装配工”,根据 expr_setup_walker 提供的清单,生成具体的初始化指令。它为表达式中用到的字段(来自内表、外表或普通表)创建“读取数据”的指令,比如“从 users 表取 age”。如果有特殊的子查询(MULTIEXPR 类型),它还会生成执行子查询的指令。这些指令会被添加到 ExprState 的计划书中,确保 SQL 表达式执行时能顺利获取数据。
/** ExecPushExprSetupSteps: 根据清单生成初始化步骤* 像是在 SQL 执行前,生成具体的指令来准备字段或子查询。*/
static void
ExecPushExprSetupSteps(ExprState *state, ExprSetupInfo *info)
{ExprEvalStep scratch = {0}; // 创建一个临时“指令卡”ListCell *lc; // 用于遍历子查询列表scratch.resvalue = NULL; // 初始化结果值为空scratch.resnull = NULL; // 初始化结果是否为空的标志/* 为内表字段生成读取指令 */if (info->last_inner > 0) // 如果表达式用到内表字段{scratch.opcode = EEOP_INNER_FETCHSOME; // 设置指令为“从内表取字段”scratch.d.fetch.last_var = info->last_inner; // 设置需要的最大字段编号scratch.d.fetch.fixed = false; // 非固定格式scratch.d.fetch.kind = NULL; // 未知类型scratch.d.fetch.known_desc = NULL; // 未知描述if (ExecComputeSlotInfo(state, &scratch)) // 计算字段信息ExprEvalPushStep(state, &scratch); // 添加指令到计划书// SQL 例子:如果 age 来自内连接的表,生成指令从内表取 age。}/* 为外表字段生成读取指令 */if (info->last_outer > 0) // 如果表达式用到外表字段{scratch.opcode = EEOP_OUTER_FETCHSOME; // 设置指令为“从外表取字段”scratch.d.fetch.last_var = info->last_outer; // 设置需要的最大字段编号scratch.d.fetch.fixed = false; // 非固定格式scratch.d.fetch.kind = NULL; // 未知类型scratch.d.fetch.known_desc = NULL; // 未知描述if (ExecComputeSlotInfo(state, &scratch)) // 计算字段信息ExprEvalPushStep(state, &scratch); // 添加指令到计划书// SQL 例子:如果 age 来自外连接的表,生成指令从外表取 age。}/* 为扫描表字段生成读取指令 */if (info->last_scan > 0) // 如果表达式用到普通表字段{scratch.opcode = EEOP_SCAN_FETCHSOME; // 设置指令为“从扫描表取字段”scratch.d.fetch.last_var = info->last_scan; // 设置需要的最大字段编号scratch.d.fetch.fixed = false; // 非固定格式scratch.d.fetch.kind = NULL; // 未知类型scratch.d.fetch.known_desc = NULL; // 未知描述if (ExecComputeSlotInfo(state, &scratch)) // 计算字段信息ExprEvalPushStep(state, &scratch); // 添加指令到计划书// SQL 例子:age 来自 users 表,生成指令从 users 表取 age。}/* 为 MULTIEXPR 子查询生成执行步骤 */foreach(lc, info->multiexpr_subplans) // 遍历所有子查询{SubPlan *subplan = (SubPlan *) lfirst(lc); // 获取子查询Assert(subplan->subLinkType == MULTIEXPR_SUBLINK); // 确保是 MULTIEXPR 类型/* 执行子查询,忽略结果但存储到指定位置 */ExecInitSubPlanExpr(subplan, state, &state->resvalue, &state->resnull);// SQL 例子:如果有子查询(如 IN (SELECT ...)),生成执行子查询的指令。}
}
注:MULTIEXPR 是什么?
在 PostgreSQL 源码里,MULTIEXPR(对应枚举值 T_MultiExpr)代表 多值表达式(Multiple expressions placeholder)。
- 它主要用于多列子查询或多列
VALUES列表 等场景。- 一个
MULTIEXPR节点可以表示「一组表达式结果」,而不是单个Expr。
换句话说:普通的 Expr 节点返回一个值,而 MULTIEXPR 节点表示一组值(tuple-like)。
主要流程(以 SQL 为例)
ExecCreateExprSetupSteps:像在执行SELECT name, age + 10 FROM users WHERE age > 30前,先列出需要准备的工作(取age字段),然后生成准备指令。expr_setup_walker:检查age + 10和age > 30,发现需要从users表取age,记录下来;如果有子查询,也会记下来。ExecPushExprSetupSteps:根据记录,生成指令,比如“从users表取age字段”或“执行子查询”,确保表达式能顺利运行。
ExecInitExprRec
ExecInitExprRec 是 PostgreSQL 查询执行引擎中用于将 SQL 表达式(如 age + 10 或 age > 30)递归翻译成可执行指令的核心函数。
它遍历表达式树的每个节点(如字段 age、常量 10 或运算符 +),为每个节点生成具体的执行步骤(ExprEvalStep),并将这些步骤添加到 ExprState 的步骤列表中。这些步骤告诉计算机如何一步步计算表达式的结果,比如“从表中取 age 值”“加上 10”“比较是否大于 30”。最终,这些步骤会被 ExecEvalExpr 使用来执行表达式。
主要流程(以 SQL 为例)
对于 SELECT name, age + 10 AS new_age FROM users WHERE age > 30:
- 输入:表达式
age + 10和age > 30。 - 处理过程:
- 对于
age(Var节点):生成指令“从users表取age列”。 - 对于
10(Const节点):生成指令“使用常量10”。 - 对于
+(运算符):生成指令“将age和10相加”。 - 对于
age > 30:类似地,为age、30和>生成相应指令。
- 对于
- 输出:一组有序的执行步骤,存储在
ExprState->steps中,供后续执行age + 10和age > 30。
/** Append the steps necessary for the evaluation of node to ExprState->steps,* possibly recursing into sub-expressions of node.** node - expression to evaluate* state - ExprState to whose ->steps to append the necessary operations* resv / resnull - where to store the result of the node into*/
static void
ExecInitExprRec(Expr *node, ExprState *state,Datum *resv, bool *resnull)
{ExprEvalStep scratch = {0};/* Guard against stack overflow due to overly complex expressions */check_stack_depth();/* Step's output location is always what the caller gave us */Assert(resv != NULL && resnull != NULL);scratch.resvalue = resv;scratch.resnull = resnull;/* cases should be ordered as they are in enum NodeTag */switch (nodeTag(node)){case T_Var:{Var *variable = (Var *) node;if (variable->varattno == InvalidAttrNumber){/* whole-row Var */ExecInitWholeRowVar(&scratch, variable, state);}else if (variable->varattno <= 0){/* system column */scratch.d.var.attnum = variable->varattno;scratch.d.var.vartype = variable->vartype;switch (variable->varno){case INNER_VAR:scratch.opcode = EEOP_INNER_SYSVAR;break;case OUTER_VAR:scratch.opcode = EEOP_OUTER_SYSVAR;break;/* INDEX_VAR is handled by default case */default:scratch.opcode = EEOP_SCAN_SYSVAR;break;}}else{/* regular user column */scratch.d.var.attnum = variable->varattno - 1;scratch.d.var.vartype = variable->vartype;switch (variable->varno){case INNER_VAR:scratch.opcode = EEOP_INNER_VAR;break;case OUTER_VAR:scratch.opcode = EEOP_OUTER_VAR;break;/* INDEX_VAR is handled by default case */default:scratch.opcode = EEOP_SCAN_VAR;break;}}ExprEvalPushStep(state, &scratch);break;}case T_Const:{Const *con = (Const *) node;scratch.opcode = EEOP_CONST;scratch.d.constval.value = con->constvalue;scratch.d.constval.isnull = con->constisnull;ExprEvalPushStep(state, &scratch);break;}case T_Param:{Param *param = (Param *) node;ParamListInfo params;switch (param->paramkind){case PARAM_EXEC:scratch.opcode = EEOP_PARAM_EXEC;scratch.d.param.paramid = param->paramid;scratch.d.param.paramtype = param->paramtype;ExprEvalPushStep(state, &scratch);break;case PARAM_EXTERN:/** If we have a relevant ParamCompileHook, use it;* otherwise compile a standard EEOP_PARAM_EXTERN* step. ext_params, if supplied, takes precedence* over info from the parent node's EState (if any).*/if (state->ext_params)params = state->ext_params;else if (state->parent &&state->parent->state)params = state->parent->state->es_param_list_info;elseparams = NULL;if (params && params->paramCompile){params->paramCompile(params, param, state,resv, resnull);}else{scratch.opcode = EEOP_PARAM_EXTERN;scratch.d.param.paramid = param->paramid;scratch.d.param.paramtype = param->paramtype;ExprEvalPushStep(state, &scratch);}break;default:elog(ERROR, "unrecognized paramkind: %d",(int) param->paramkind);break;}break;}case T_Aggref:{Aggref *aggref = (Aggref *) node;scratch.opcode = EEOP_AGGREF;scratch.d.aggref.aggno = aggref->aggno;if (state->parent && IsA(state->parent, AggState)){AggState *aggstate = (AggState *) state->parent;aggstate->aggs = lappend(aggstate->aggs, aggref);}else{/* planner messed up */elog(ERROR, "Aggref found in non-Agg plan node");}ExprEvalPushStep(state, &scratch);break;}case T_GroupingFunc:{GroupingFunc *grp_node = (GroupingFunc *) node;Agg *agg;if (!state->parent || !IsA(state->parent, AggState) ||!IsA(state->parent->plan, Agg))elog(ERROR, "GroupingFunc found in non-Agg plan node");scratch.opcode = EEOP_GROUPING_FUNC;agg = (Agg *) (state->parent->plan);if (agg->groupingSets)scratch.d.grouping_func.clauses = grp_node->cols;elsescratch.d.grouping_func.clauses = NIL;ExprEvalPushStep(state, &scratch);break;}case T_WindowFunc:{WindowFunc *wfunc = (WindowFunc *) node;WindowFuncExprState *wfstate = makeNode(WindowFuncExprState);wfstate->wfunc = wfunc;if (state->parent && IsA(state->parent, WindowAggState)){WindowAggState *winstate = (WindowAggState *) state->parent;int nfuncs;winstate->funcs = lappend(winstate->funcs, wfstate);nfuncs = ++winstate->numfuncs;if (wfunc->winagg)winstate->numaggs++;/* for now initialize agg using old style expressions */wfstate->args = ExecInitExprList(wfunc->args,state->parent);wfstate->aggfilter = ExecInitExpr(wfunc->aggfilter,state->parent);/** Complain if the windowfunc's arguments contain any* windowfuncs; nested window functions are semantically* nonsensical. (This should have been caught earlier,* but we defend against it here anyway.)*/if (nfuncs != winstate->numfuncs)ereport(ERROR,(errcode(ERRCODE_WINDOWING_ERROR),errmsg("window function calls cannot be nested")));}else{/* planner messed up */elog(ERROR, "WindowFunc found in non-WindowAgg plan node");}scratch.opcode = EEOP_WINDOW_FUNC;scratch.d.window_func.wfstate = wfstate;ExprEvalPushStep(state, &scratch);break;}case T_MergeSupportFunc:{/* must be in a MERGE, else something messed up */if (!state->parent ||!IsA(state->parent, ModifyTableState) ||((ModifyTableState *) state->parent)->operation != CMD_MERGE)elog(ERROR, "MergeSupportFunc found in non-merge plan node");scratch.opcode = EEOP_MERGE_SUPPORT_FUNC;ExprEvalPushStep(state, &scratch);break;}case T_SubscriptingRef:{SubscriptingRef *sbsref = (SubscriptingRef *) node;ExecInitSubscriptingRef(&scratch, sbsref, state, resv, resnull);break;}case T_FuncExpr:{FuncExpr *func = (FuncExpr *) node;ExecInitFunc(&scratch, node,func->args, func->funcid, func->inputcollid,state);ExprEvalPushStep(state, &scratch);break;}case T_OpExpr:{OpExpr *op = (OpExpr *) node;ExecInitFunc(&scratch, node,op->args, op->opfuncid, op->inputcollid,state);ExprEvalPushStep(state, &scratch);break;}case T_DistinctExpr:{DistinctExpr *op = (DistinctExpr *) node;ExecInitFunc(&scratch, node,op->args, op->opfuncid, op->inputcollid,state);/** Change opcode of call instruction to EEOP_DISTINCT.** XXX: historically we've not called the function usage* pgstat infrastructure - that seems inconsistent given that* we do so for normal function *and* operator evaluation. If* we decided to do that here, we'd probably want separate* opcodes for FUSAGE or not.*/scratch.opcode = EEOP_DISTINCT;ExprEvalPushStep(state, &scratch);break;}case T_NullIfExpr:{NullIfExpr *op = (NullIfExpr *) node;ExecInitFunc(&scratch, node,op->args, op->opfuncid, op->inputcollid,state);/** If first argument is of varlena type, we'll need to ensure* that the value passed to the comparison function is a* read-only pointer.*/scratch.d.func.make_ro =(get_typlen(exprType((Node *) linitial(op->args))) == -1);/** Change opcode of call instruction to EEOP_NULLIF.** XXX: historically we've not called the function usage* pgstat infrastructure - that seems inconsistent given that* we do so for normal function *and* operator evaluation. If* we decided to do that here, we'd probably want separate* opcodes for FUSAGE or not.*/scratch.opcode = EEOP_NULLIF;ExprEvalPushStep(state, &scratch);break;}case T_ScalarArrayOpExpr:{ScalarArrayOpExpr *opexpr = (ScalarArrayOpExpr *) node;Expr *scalararg;Expr *arrayarg;FmgrInfo *finfo;FunctionCallInfo fcinfo;AclResult aclresult;Oid cmpfuncid;/** Select the correct comparison function. When we do hashed* NOT IN clauses, the opfuncid will be the inequality* comparison function and negfuncid will be set to equality.* We need to use the equality function for hash probes.*/if (OidIsValid(opexpr->negfuncid)){Assert(OidIsValid(opexpr->hashfuncid));cmpfuncid = opexpr->negfuncid;}elsecmpfuncid = opexpr->opfuncid;Assert(list_length(opexpr->args) == 2);scalararg = (Expr *) linitial(opexpr->args);arrayarg = (Expr *) lsecond(opexpr->args);/* Check permission to call function */aclresult = object_aclcheck(ProcedureRelationId, cmpfuncid,GetUserId(),ACL_EXECUTE);if (aclresult != ACLCHECK_OK)aclcheck_error(aclresult, OBJECT_FUNCTION,get_func_name(cmpfuncid));InvokeFunctionExecuteHook(cmpfuncid);if (OidIsValid(opexpr->hashfuncid)){aclresult = object_aclcheck(ProcedureRelationId, opexpr->hashfuncid,GetUserId(),ACL_EXECUTE);if (aclresult != ACLCHECK_OK)aclcheck_error(aclresult, OBJECT_FUNCTION,get_func_name(opexpr->hashfuncid));InvokeFunctionExecuteHook(opexpr->hashfuncid);}/* Set up the primary fmgr lookup information */finfo = palloc0(sizeof(FmgrInfo));fcinfo = palloc0(SizeForFunctionCallInfo(2));fmgr_info(cmpfuncid, finfo);fmgr_info_set_expr((Node *) node, finfo);InitFunctionCallInfoData(*fcinfo, finfo, 2,opexpr->inputcollid, NULL, NULL);/** If hashfuncid is set, we create a EEOP_HASHED_SCALARARRAYOP* step instead of a EEOP_SCALARARRAYOP. This provides much* faster lookup performance than the normal linear search* when the number of items in the array is anything but very* small.*/if (OidIsValid(opexpr->hashfuncid)){/* Evaluate scalar directly into left function argument */ExecInitExprRec(scalararg, state,&fcinfo->args[0].value, &fcinfo->args[0].isnull);/** Evaluate array argument into our return value. There's* no danger in that, because the return value is* guaranteed to be overwritten by* EEOP_HASHED_SCALARARRAYOP, and will not be passed to* any other expression.*/ExecInitExprRec(arrayarg, state, resv, resnull);/* And perform the operation */scratch.opcode = EEOP_HASHED_SCALARARRAYOP;scratch.d.hashedscalararrayop.inclause = opexpr->useOr;scratch.d.hashedscalararrayop.finfo = finfo;scratch.d.hashedscalararrayop.fcinfo_data = fcinfo;scratch.d.hashedscalararrayop.saop = opexpr;ExprEvalPushStep(state, &scratch);}else{/* Evaluate scalar directly into left function argument */ExecInitExprRec(scalararg, state,&fcinfo->args[0].value,&fcinfo->args[0].isnull);/** Evaluate array argument into our return value. There's* no danger in that, because the return value is* guaranteed to be overwritten by EEOP_SCALARARRAYOP, and* will not be passed to any other expression.*/ExecInitExprRec(arrayarg, state, resv, resnull);/* And perform the operation */scratch.opcode = EEOP_SCALARARRAYOP;scratch.d.scalararrayop.element_type = InvalidOid;scratch.d.scalararrayop.useOr = opexpr->useOr;scratch.d.scalararrayop.finfo = finfo;scratch.d.scalararrayop.fcinfo_data = fcinfo;scratch.d.scalararrayop.fn_addr = finfo->fn_addr;ExprEvalPushStep(state, &scratch);}break;}case T_BoolExpr:{BoolExpr *boolexpr = (BoolExpr *) node;int nargs = list_length(boolexpr->args);List *adjust_jumps = NIL;int off;ListCell *lc;/* allocate scratch memory used by all steps of AND/OR */if (boolexpr->boolop != NOT_EXPR)scratch.d.boolexpr.anynull = (bool *) palloc(sizeof(bool));/** For each argument evaluate the argument itself, then* perform the bool operation's appropriate handling.** We can evaluate each argument into our result area, since* the short-circuiting logic means we only need to remember* previous NULL values.** AND/OR is split into separate STEP_FIRST (one) / STEP (zero* or more) / STEP_LAST (one) steps, as each of those has to* perform different work. The FIRST/LAST split is valid* because AND/OR have at least two arguments.*/off = 0;foreach(lc, boolexpr->args){Expr *arg = (Expr *) lfirst(lc);/* Evaluate argument into our output variable */ExecInitExprRec(arg, state, resv, resnull);/* Perform the appropriate step type */switch (boolexpr->boolop){case AND_EXPR:Assert(nargs >= 2);if (off == 0)scratch.opcode = EEOP_BOOL_AND_STEP_FIRST;else if (off + 1 == nargs)scratch.opcode = EEOP_BOOL_AND_STEP_LAST;elsescratch.opcode = EEOP_BOOL_AND_STEP;break;case OR_EXPR:Assert(nargs >= 2);if (off == 0)scratch.opcode = EEOP_BOOL_OR_STEP_FIRST;else if (off + 1 == nargs)scratch.opcode = EEOP_BOOL_OR_STEP_LAST;elsescratch.opcode = EEOP_BOOL_OR_STEP;break;case NOT_EXPR:Assert(nargs == 1);scratch.opcode = EEOP_BOOL_NOT_STEP;break;default:elog(ERROR, "unrecognized boolop: %d",(int) boolexpr->boolop);break;}scratch.d.boolexpr.jumpdone = -1;ExprEvalPushStep(state, &scratch);adjust_jumps = lappend_int(adjust_jumps,state->steps_len - 1);off++;}/* adjust jump targets */foreach(lc, adjust_jumps){ExprEvalStep *as = &state->steps[lfirst_int(lc)];Assert(as->d.boolexpr.jumpdone == -1);as->d.boolexpr.jumpdone = state->steps_len;}break;}case T_SubPlan:{SubPlan *subplan = (SubPlan *) node;/** Real execution of a MULTIEXPR SubPlan has already been* done. What we have to do here is return a dummy NULL record* value in case this targetlist element is assigned* someplace.*/if (subplan->subLinkType == MULTIEXPR_SUBLINK){scratch.opcode = EEOP_CONST;scratch.d.constval.value = (Datum) 0;scratch.d.constval.isnull = true;ExprEvalPushStep(state, &scratch);break;}ExecInitSubPlanExpr(subplan, state, resv, resnull);break;}case T_FieldSelect:{FieldSelect *fselect = (FieldSelect *) node;/* evaluate row/record argument into result area */ExecInitExprRec(fselect->arg, state, resv, resnull);/* and extract field */scratch.opcode = EEOP_FIELDSELECT;scratch.d.fieldselect.fieldnum = fselect->fieldnum;scratch.d.fieldselect.resulttype = fselect->resulttype;scratch.d.fieldselect.rowcache.cacheptr = NULL;ExprEvalPushStep(state, &scratch);break;}case T_FieldStore:{FieldStore *fstore = (FieldStore *) node;TupleDesc tupDesc;ExprEvalRowtypeCache *rowcachep;Datum *values;bool *nulls;int ncolumns;ListCell *l1,*l2;/* find out the number of columns in the composite type */tupDesc = lookup_rowtype_tupdesc(fstore->resulttype, -1);ncolumns = tupDesc->natts;ReleaseTupleDesc(tupDesc);/* create workspace for column values */values = (Datum *) palloc(sizeof(Datum) * ncolumns);nulls = (bool *) palloc(sizeof(bool) * ncolumns);/* create shared composite-type-lookup cache struct */rowcachep = palloc(sizeof(ExprEvalRowtypeCache));rowcachep->cacheptr = NULL;/* emit code to evaluate the composite input value */ExecInitExprRec(fstore->arg, state, resv, resnull);/* next, deform the input tuple into our workspace */scratch.opcode = EEOP_FIELDSTORE_DEFORM;scratch.d.fieldstore.fstore = fstore;scratch.d.fieldstore.rowcache = rowcachep;scratch.d.fieldstore.values = values;scratch.d.fieldstore.nulls = nulls;scratch.d.fieldstore.ncolumns = ncolumns;ExprEvalPushStep(state, &scratch);/* evaluate new field values, store in workspace columns */forboth(l1, fstore->newvals, l2, fstore->fieldnums){Expr *e = (Expr *) lfirst(l1);AttrNumber fieldnum = lfirst_int(l2);Datum *save_innermost_caseval;bool *save_innermost_casenull;if (fieldnum <= 0 || fieldnum > ncolumns)elog(ERROR, "field number %d is out of range in FieldStore",fieldnum);/** Use the CaseTestExpr mechanism to pass down the old* value of the field being replaced; this is needed in* case the newval is itself a FieldStore or* SubscriptingRef that has to obtain and modify the old* value. It's safe to reuse the CASE mechanism because* there cannot be a CASE between here and where the value* would be needed, and a field assignment can't be within* a CASE either. (So saving and restoring* innermost_caseval is just paranoia, but let's do it* anyway.)** Another non-obvious point is that it's safe to use the* field's values[]/nulls[] entries as both the caseval* source and the result address for this subexpression.* That's okay only because (1) both FieldStore and* SubscriptingRef evaluate their arg or refexpr inputs* first, and (2) any such CaseTestExpr is directly the* arg or refexpr input. So any read of the caseval will* occur before there's a chance to overwrite it. Also,* if multiple entries in the newvals/fieldnums lists* target the same field, they'll effectively be applied* left-to-right which is what we want.*/save_innermost_caseval = state->innermost_caseval;save_innermost_casenull = state->innermost_casenull;state->innermost_caseval = &values[fieldnum - 1];state->innermost_casenull = &nulls[fieldnum - 1];ExecInitExprRec(e, state,&values[fieldnum - 1],&nulls[fieldnum - 1]);state->innermost_caseval = save_innermost_caseval;state->innermost_casenull = save_innermost_casenull;}/* finally, form result tuple */scratch.opcode = EEOP_FIELDSTORE_FORM;scratch.d.fieldstore.fstore = fstore;scratch.d.fieldstore.rowcache = rowcachep;scratch.d.fieldstore.values = values;scratch.d.fieldstore.nulls = nulls;scratch.d.fieldstore.ncolumns = ncolumns;ExprEvalPushStep(state, &scratch);break;}case T_RelabelType:{/* relabel doesn't need to do anything at runtime */RelabelType *relabel = (RelabelType *) node;ExecInitExprRec(relabel->arg, state, resv, resnull);break;}case T_CoerceViaIO:{CoerceViaIO *iocoerce = (CoerceViaIO *) node;Oid iofunc;bool typisvarlena;Oid typioparam;FunctionCallInfo fcinfo_in;/* evaluate argument into step's result area */ExecInitExprRec(iocoerce->arg, state, resv, resnull);/** Prepare both output and input function calls, to be* evaluated inside a single evaluation step for speed - this* can be a very common operation.** We don't check permissions here as a type's input/output* function are assumed to be executable by everyone.*/if (state->escontext == NULL)scratch.opcode = EEOP_IOCOERCE;elsescratch.opcode = EEOP_IOCOERCE_SAFE;/* lookup the source type's output function */scratch.d.iocoerce.finfo_out = palloc0(sizeof(FmgrInfo));scratch.d.iocoerce.fcinfo_data_out = palloc0(SizeForFunctionCallInfo(1));getTypeOutputInfo(exprType((Node *) iocoerce->arg),&iofunc, &typisvarlena);fmgr_info(iofunc, scratch.d.iocoerce.finfo_out);fmgr_info_set_expr((Node *) node, scratch.d.iocoerce.finfo_out);InitFunctionCallInfoData(*scratch.d.iocoerce.fcinfo_data_out,scratch.d.iocoerce.finfo_out,1, InvalidOid, NULL, NULL);/* lookup the result type's input function */scratch.d.iocoerce.finfo_in = palloc0(sizeof(FmgrInfo));scratch.d.iocoerce.fcinfo_data_in = palloc0(SizeForFunctionCallInfo(3));getTypeInputInfo(iocoerce->resulttype,&iofunc, &typioparam);fmgr_info(iofunc, scratch.d.iocoerce.finfo_in);fmgr_info_set_expr((Node *) node, scratch.d.iocoerce.finfo_in);InitFunctionCallInfoData(*scratch.d.iocoerce.fcinfo_data_in,scratch.d.iocoerce.finfo_in,3, InvalidOid, NULL, NULL);/** We can preload the second and third arguments for the input* function, since they're constants.*/fcinfo_in = scratch.d.iocoerce.fcinfo_data_in;fcinfo_in->args[1].value = ObjectIdGetDatum(typioparam);fcinfo_in->args[1].isnull = false;fcinfo_in->args[2].value = Int32GetDatum(-1);fcinfo_in->args[2].isnull = false;fcinfo_in->context = (Node *) state->escontext;ExprEvalPushStep(state, &scratch);break;}case T_ArrayCoerceExpr:{ArrayCoerceExpr *acoerce = (ArrayCoerceExpr *) node;Oid resultelemtype;ExprState *elemstate;/* evaluate argument into step's result area */ExecInitExprRec(acoerce->arg, state, resv, resnull);resultelemtype = get_element_type(acoerce->resulttype);if (!OidIsValid(resultelemtype))ereport(ERROR,(errcode(ERRCODE_INVALID_PARAMETER_VALUE),errmsg("target type is not an array")));/** Construct a sub-expression for the per-element expression;* but don't ready it until after we check it for triviality.* We assume it hasn't any Var references, but does have a* CaseTestExpr representing the source array element values.*/elemstate = makeNode(ExprState);elemstate->expr = acoerce->elemexpr;elemstate->parent = state->parent;elemstate->ext_params = state->ext_params;elemstate->innermost_caseval = (Datum *) palloc(sizeof(Datum));elemstate->innermost_casenull = (bool *) palloc(sizeof(bool));ExecInitExprRec(acoerce->elemexpr, elemstate,&elemstate->resvalue, &elemstate->resnull);if (elemstate->steps_len == 1 &&elemstate->steps[0].opcode == EEOP_CASE_TESTVAL){/* Trivial, so we need no per-element work at runtime */elemstate = NULL;}else{/* Not trivial, so append a DONE step */scratch.opcode = EEOP_DONE;ExprEvalPushStep(elemstate, &scratch);/* and ready the subexpression */ExecReadyExpr(elemstate);}scratch.opcode = EEOP_ARRAYCOERCE;scratch.d.arraycoerce.elemexprstate = elemstate;scratch.d.arraycoerce.resultelemtype = resultelemtype;if (elemstate){/* Set up workspace for array_map */scratch.d.arraycoerce.amstate =(ArrayMapState *) palloc0(sizeof(ArrayMapState));}else{/* Don't need workspace if there's no subexpression */scratch.d.arraycoerce.amstate = NULL;}ExprEvalPushStep(state, &scratch);break;}case T_ConvertRowtypeExpr:{ConvertRowtypeExpr *convert = (ConvertRowtypeExpr *) node;ExprEvalRowtypeCache *rowcachep;/* cache structs must be out-of-line for space reasons */rowcachep = palloc(2 * sizeof(ExprEvalRowtypeCache));rowcachep[0].cacheptr = NULL;rowcachep[1].cacheptr = NULL;/* evaluate argument into step's result area */ExecInitExprRec(convert->arg, state, resv, resnull);/* and push conversion step */scratch.opcode = EEOP_CONVERT_ROWTYPE;scratch.d.convert_rowtype.inputtype =exprType((Node *) convert->arg);scratch.d.convert_rowtype.outputtype = convert->resulttype;scratch.d.convert_rowtype.incache = &rowcachep[0];scratch.d.convert_rowtype.outcache = &rowcachep[1];scratch.d.convert_rowtype.map = NULL;ExprEvalPushStep(state, &scratch);break;}/* note that CaseWhen expressions are handled within this block */case T_CaseExpr:{CaseExpr *caseExpr = (CaseExpr *) node;List *adjust_jumps = NIL;Datum *caseval = NULL;bool *casenull = NULL;ListCell *lc;/** If there's a test expression, we have to evaluate it and* save the value where the CaseTestExpr placeholders can find* it.*/if (caseExpr->arg != NULL){/* Evaluate testexpr into caseval/casenull workspace */caseval = palloc(sizeof(Datum));casenull = palloc(sizeof(bool));ExecInitExprRec(caseExpr->arg, state,caseval, casenull);/** Since value might be read multiple times, force to R/O* - but only if it could be an expanded datum.*/if (get_typlen(exprType((Node *) caseExpr->arg)) == -1){/* change caseval in-place */scratch.opcode = EEOP_MAKE_READONLY;scratch.resvalue = caseval;scratch.resnull = casenull;scratch.d.make_readonly.value = caseval;scratch.d.make_readonly.isnull = casenull;ExprEvalPushStep(state, &scratch);/* restore normal settings of scratch fields */scratch.resvalue = resv;scratch.resnull = resnull;}}/** Prepare to evaluate each of the WHEN clauses in turn; as* soon as one is true we return the value of the* corresponding THEN clause. If none are true then we return* the value of the ELSE clause, or NULL if there is none.*/foreach(lc, caseExpr->args){CaseWhen *when = (CaseWhen *) lfirst(lc);Datum *save_innermost_caseval;bool *save_innermost_casenull;int whenstep;/** Make testexpr result available to CaseTestExpr nodes* within the condition. We must save and restore prior* setting of innermost_caseval fields, in case this node* is itself within a larger CASE.** If there's no test expression, we don't actually need* to save and restore these fields; but it's less code to* just do so unconditionally.*/save_innermost_caseval = state->innermost_caseval;save_innermost_casenull = state->innermost_casenull;state->innermost_caseval = caseval;state->innermost_casenull = casenull;/* evaluate condition into CASE's result variables */ExecInitExprRec(when->expr, state, resv, resnull);state->innermost_caseval = save_innermost_caseval;state->innermost_casenull = save_innermost_casenull;/* If WHEN result isn't true, jump to next CASE arm */scratch.opcode = EEOP_JUMP_IF_NOT_TRUE;scratch.d.jump.jumpdone = -1; /* computed later */ExprEvalPushStep(state, &scratch);whenstep = state->steps_len - 1;/** If WHEN result is true, evaluate THEN result, storing* it into the CASE's result variables.*/ExecInitExprRec(when->result, state, resv, resnull);/* Emit JUMP step to jump to end of CASE's code */scratch.opcode = EEOP_JUMP;scratch.d.jump.jumpdone = -1; /* computed later */ExprEvalPushStep(state, &scratch);/** Don't know address for that jump yet, compute once the* whole CASE expression is built.*/adjust_jumps = lappend_int(adjust_jumps,state->steps_len - 1);/** But we can set WHEN test's jump target now, to make it* jump to the next WHEN subexpression or the ELSE.*/state->steps[whenstep].d.jump.jumpdone = state->steps_len;}/* transformCaseExpr always adds a default */Assert(caseExpr->defresult);/* evaluate ELSE expr into CASE's result variables */ExecInitExprRec(caseExpr->defresult, state,resv, resnull);/* adjust jump targets */foreach(lc, adjust_jumps){ExprEvalStep *as = &state->steps[lfirst_int(lc)];Assert(as->opcode == EEOP_JUMP);Assert(as->d.jump.jumpdone == -1);as->d.jump.jumpdone = state->steps_len;}break;}case T_CaseTestExpr:{/** Read from location identified by innermost_caseval. Note* that innermost_caseval could be NULL, if this node isn't* actually within a CaseExpr, ArrayCoerceExpr, etc structure.* That can happen because some parts of the system abuse* CaseTestExpr to cause a read of a value externally supplied* in econtext->caseValue_datum. We'll take care of that* scenario at runtime.*/scratch.opcode = EEOP_CASE_TESTVAL;scratch.d.casetest.value = state->innermost_caseval;scratch.d.casetest.isnull = state->innermost_casenull;ExprEvalPushStep(state, &scratch);break;}case T_ArrayExpr:{ArrayExpr *arrayexpr = (ArrayExpr *) node;int nelems = list_length(arrayexpr->elements);ListCell *lc;int elemoff;/** Evaluate by computing each element, and then forming the* array. Elements are computed into scratch arrays* associated with the ARRAYEXPR step.*/scratch.opcode = EEOP_ARRAYEXPR;scratch.d.arrayexpr.elemvalues =(Datum *) palloc(sizeof(Datum) * nelems);scratch.d.arrayexpr.elemnulls =(bool *) palloc(sizeof(bool) * nelems);scratch.d.arrayexpr.nelems = nelems;/* fill remaining fields of step */scratch.d.arrayexpr.multidims = arrayexpr->multidims;scratch.d.arrayexpr.elemtype = arrayexpr->element_typeid;/* do one-time catalog lookup for type info */get_typlenbyvalalign(arrayexpr->element_typeid,&scratch.d.arrayexpr.elemlength,&scratch.d.arrayexpr.elembyval,&scratch.d.arrayexpr.elemalign);/* prepare to evaluate all arguments */elemoff = 0;foreach(lc, arrayexpr->elements){Expr *e = (Expr *) lfirst(lc);ExecInitExprRec(e, state,&scratch.d.arrayexpr.elemvalues[elemoff],&scratch.d.arrayexpr.elemnulls[elemoff]);elemoff++;}/* and then collect all into an array */ExprEvalPushStep(state, &scratch);break;}case T_RowExpr:{RowExpr *rowexpr = (RowExpr *) node;int nelems = list_length(rowexpr->args);TupleDesc tupdesc;int i;ListCell *l;/* Build tupdesc to describe result tuples */if (rowexpr->row_typeid == RECORDOID){/* generic record, use types of given expressions */tupdesc = ExecTypeFromExprList(rowexpr->args);/* ... but adopt RowExpr's column aliases */ExecTypeSetColNames(tupdesc, rowexpr->colnames);/* Bless the tupdesc so it can be looked up later */BlessTupleDesc(tupdesc);}else{/* it's been cast to a named type, use that */tupdesc = lookup_rowtype_tupdesc_copy(rowexpr->row_typeid, -1);}/** In the named-type case, the tupdesc could have more columns* than are in the args list, since the type might have had* columns added since the ROW() was parsed. We want those* extra columns to go to nulls, so we make sure that the* workspace arrays are large enough and then initialize any* extra columns to read as NULLs.*/Assert(nelems <= tupdesc->natts);nelems = Max(nelems, tupdesc->natts);/** Evaluate by first building datums for each field, and then* a final step forming the composite datum.*/scratch.opcode = EEOP_ROW;scratch.d.row.tupdesc = tupdesc;/* space for the individual field datums */scratch.d.row.elemvalues =(Datum *) palloc(sizeof(Datum) * nelems);scratch.d.row.elemnulls =(bool *) palloc(sizeof(bool) * nelems);/* as explained above, make sure any extra columns are null */memset(scratch.d.row.elemnulls, true, sizeof(bool) * nelems);/* Set up evaluation, skipping any deleted columns */i = 0;foreach(l, rowexpr->args){Form_pg_attribute att = TupleDescAttr(tupdesc, i);Expr *e = (Expr *) lfirst(l);if (!att->attisdropped){/** Guard against ALTER COLUMN TYPE on rowtype since* the RowExpr was created. XXX should we check* typmod too? Not sure we can be sure it'll be the* same.*/if (exprType((Node *) e) != att->atttypid)ereport(ERROR,(errcode(ERRCODE_DATATYPE_MISMATCH),errmsg("ROW() column has type %s instead of type %s",format_type_be(exprType((Node *) e)),format_type_be(att->atttypid))));}else{/** Ignore original expression and insert a NULL. We* don't really care what type of NULL it is, so* always make an int4 NULL.*/e = (Expr *) makeNullConst(INT4OID, -1, InvalidOid);}/* Evaluate column expr into appropriate workspace slot */ExecInitExprRec(e, state,&scratch.d.row.elemvalues[i],&scratch.d.row.elemnulls[i]);i++;}/* And finally build the row value */ExprEvalPushStep(state, &scratch);break;}case T_RowCompareExpr:{RowCompareExpr *rcexpr = (RowCompareExpr *) node;int nopers = list_length(rcexpr->opnos);List *adjust_jumps = NIL;ListCell *l_left_expr,*l_right_expr,*l_opno,*l_opfamily,*l_inputcollid;ListCell *lc;/** Iterate over each field, prepare comparisons. To handle* NULL results, prepare jumps to after the expression. If a* comparison yields a != 0 result, jump to the final step.*/Assert(list_length(rcexpr->largs) == nopers);Assert(list_length(rcexpr->rargs) == nopers);Assert(list_length(rcexpr->opfamilies) == nopers);Assert(list_length(rcexpr->inputcollids) == nopers);forfive(l_left_expr, rcexpr->largs,l_right_expr, rcexpr->rargs,l_opno, rcexpr->opnos,l_opfamily, rcexpr->opfamilies,l_inputcollid, rcexpr->inputcollids){Expr *left_expr = (Expr *) lfirst(l_left_expr);Expr *right_expr = (Expr *) lfirst(l_right_expr);Oid opno = lfirst_oid(l_opno);Oid opfamily = lfirst_oid(l_opfamily);Oid inputcollid = lfirst_oid(l_inputcollid);int strategy;Oid lefttype;Oid righttype;Oid proc;FmgrInfo *finfo;FunctionCallInfo fcinfo;get_op_opfamily_properties(opno, opfamily, false,&strategy,&lefttype,&righttype);proc = get_opfamily_proc(opfamily,lefttype,righttype,BTORDER_PROC);if (!OidIsValid(proc))elog(ERROR, "missing support function %d(%u,%u) in opfamily %u",BTORDER_PROC, lefttype, righttype, opfamily);/* Set up the primary fmgr lookup information */finfo = palloc0(sizeof(FmgrInfo));fcinfo = palloc0(SizeForFunctionCallInfo(2));fmgr_info(proc, finfo);fmgr_info_set_expr((Node *) node, finfo);InitFunctionCallInfoData(*fcinfo, finfo, 2,inputcollid, NULL, NULL);/** If we enforced permissions checks on index support* functions, we'd need to make a check here. But the* index support machinery doesn't do that, and thus* neither does this code.*//* evaluate left and right args directly into fcinfo */ExecInitExprRec(left_expr, state,&fcinfo->args[0].value, &fcinfo->args[0].isnull);ExecInitExprRec(right_expr, state,&fcinfo->args[1].value, &fcinfo->args[1].isnull);scratch.opcode = EEOP_ROWCOMPARE_STEP;scratch.d.rowcompare_step.finfo = finfo;scratch.d.rowcompare_step.fcinfo_data = fcinfo;scratch.d.rowcompare_step.fn_addr = finfo->fn_addr;/* jump targets filled below */scratch.d.rowcompare_step.jumpnull = -1;scratch.d.rowcompare_step.jumpdone = -1;ExprEvalPushStep(state, &scratch);adjust_jumps = lappend_int(adjust_jumps,state->steps_len - 1);}/** We could have a zero-column rowtype, in which case the rows* necessarily compare equal.*/if (nopers == 0){scratch.opcode = EEOP_CONST;scratch.d.constval.value = Int32GetDatum(0);scratch.d.constval.isnull = false;ExprEvalPushStep(state, &scratch);}/* Finally, examine the last comparison result */scratch.opcode = EEOP_ROWCOMPARE_FINAL;scratch.d.rowcompare_final.rctype = rcexpr->rctype;ExprEvalPushStep(state, &scratch);/* adjust jump targets */foreach(lc, adjust_jumps){ExprEvalStep *as = &state->steps[lfirst_int(lc)];Assert(as->opcode == EEOP_ROWCOMPARE_STEP);Assert(as->d.rowcompare_step.jumpdone == -1);Assert(as->d.rowcompare_step.jumpnull == -1);/* jump to comparison evaluation */as->d.rowcompare_step.jumpdone = state->steps_len - 1;/* jump to the following expression */as->d.rowcompare_step.jumpnull = state->steps_len;}break;}case T_CoalesceExpr:{CoalesceExpr *coalesce = (CoalesceExpr *) node;List *adjust_jumps = NIL;ListCell *lc;/* We assume there's at least one arg */Assert(coalesce->args != NIL);/** Prepare evaluation of all coalesced arguments, after each* one push a step that short-circuits if not null.*/foreach(lc, coalesce->args){Expr *e = (Expr *) lfirst(lc);/* evaluate argument, directly into result datum */ExecInitExprRec(e, state, resv, resnull);/* if it's not null, skip to end of COALESCE expr */scratch.opcode = EEOP_JUMP_IF_NOT_NULL;scratch.d.jump.jumpdone = -1; /* adjust later */ExprEvalPushStep(state, &scratch);adjust_jumps = lappend_int(adjust_jumps,state->steps_len - 1);}/** No need to add a constant NULL return - we only can get to* the end of the expression if a NULL already is being* returned.*//* adjust jump targets */foreach(lc, adjust_jumps){ExprEvalStep *as = &state->steps[lfirst_int(lc)];Assert(as->opcode == EEOP_JUMP_IF_NOT_NULL);Assert(as->d.jump.jumpdone == -1);as->d.jump.jumpdone = state->steps_len;}break;}case T_MinMaxExpr:{MinMaxExpr *minmaxexpr = (MinMaxExpr *) node;int nelems = list_length(minmaxexpr->args);TypeCacheEntry *typentry;FmgrInfo *finfo;FunctionCallInfo fcinfo;ListCell *lc;int off;/* Look up the btree comparison function for the datatype */typentry = lookup_type_cache(minmaxexpr->minmaxtype,TYPECACHE_CMP_PROC);if (!OidIsValid(typentry->cmp_proc))ereport(ERROR,(errcode(ERRCODE_UNDEFINED_FUNCTION),errmsg("could not identify a comparison function for type %s",format_type_be(minmaxexpr->minmaxtype))));/** If we enforced permissions checks on index support* functions, we'd need to make a check here. But the index* support machinery doesn't do that, and thus neither does* this code.*//* Perform function lookup */finfo = palloc0(sizeof(FmgrInfo));fcinfo = palloc0(SizeForFunctionCallInfo(2));fmgr_info(typentry->cmp_proc, finfo);fmgr_info_set_expr((Node *) node, finfo);InitFunctionCallInfoData(*fcinfo, finfo, 2,minmaxexpr->inputcollid, NULL, NULL);scratch.opcode = EEOP_MINMAX;/* allocate space to store arguments */scratch.d.minmax.values =(Datum *) palloc(sizeof(Datum) * nelems);scratch.d.minmax.nulls =(bool *) palloc(sizeof(bool) * nelems);scratch.d.minmax.nelems = nelems;scratch.d.minmax.op = minmaxexpr->op;scratch.d.minmax.finfo = finfo;scratch.d.minmax.fcinfo_data = fcinfo;/* evaluate expressions into minmax->values/nulls */off = 0;foreach(lc, minmaxexpr->args){Expr *e = (Expr *) lfirst(lc);ExecInitExprRec(e, state,&scratch.d.minmax.values[off],&scratch.d.minmax.nulls[off]);off++;}/* and push the final comparison */ExprEvalPushStep(state, &scratch);break;}case T_SQLValueFunction:{SQLValueFunction *svf = (SQLValueFunction *) node;scratch.opcode = EEOP_SQLVALUEFUNCTION;scratch.d.sqlvaluefunction.svf = svf;ExprEvalPushStep(state, &scratch);break;}case T_XmlExpr:{XmlExpr *xexpr = (XmlExpr *) node;int nnamed = list_length(xexpr->named_args);int nargs = list_length(xexpr->args);int off;ListCell *arg;scratch.opcode = EEOP_XMLEXPR;scratch.d.xmlexpr.xexpr = xexpr;/* allocate space for storing all the arguments */if (nnamed){scratch.d.xmlexpr.named_argvalue =(Datum *) palloc(sizeof(Datum) * nnamed);scratch.d.xmlexpr.named_argnull =(bool *) palloc(sizeof(bool) * nnamed);}else{scratch.d.xmlexpr.named_argvalue = NULL;scratch.d.xmlexpr.named_argnull = NULL;}if (nargs){scratch.d.xmlexpr.argvalue =(Datum *) palloc(sizeof(Datum) * nargs);scratch.d.xmlexpr.argnull =(bool *) palloc(sizeof(bool) * nargs);}else{scratch.d.xmlexpr.argvalue = NULL;scratch.d.xmlexpr.argnull = NULL;}/* prepare argument execution */off = 0;foreach(arg, xexpr->named_args){Expr *e = (Expr *) lfirst(arg);ExecInitExprRec(e, state,&scratch.d.xmlexpr.named_argvalue[off],&scratch.d.xmlexpr.named_argnull[off]);off++;}off = 0;foreach(arg, xexpr->args){Expr *e = (Expr *) lfirst(arg);ExecInitExprRec(e, state,&scratch.d.xmlexpr.argvalue[off],&scratch.d.xmlexpr.argnull[off]);off++;}/* and evaluate the actual XML expression */ExprEvalPushStep(state, &scratch);break;}case T_JsonValueExpr:{JsonValueExpr *jve = (JsonValueExpr *) node;Assert(jve->raw_expr != NULL);ExecInitExprRec(jve->raw_expr, state, resv, resnull);Assert(jve->formatted_expr != NULL);ExecInitExprRec(jve->formatted_expr, state, resv, resnull);break;}case T_JsonConstructorExpr:{JsonConstructorExpr *ctor = (JsonConstructorExpr *) node;List *args = ctor->args;ListCell *lc;int nargs = list_length(args);int argno = 0;if (ctor->func){ExecInitExprRec(ctor->func, state, resv, resnull);}else if ((ctor->type == JSCTOR_JSON_PARSE && !ctor->unique) ||ctor->type == JSCTOR_JSON_SERIALIZE){/* Use the value of the first argument as result */ExecInitExprRec(linitial(args), state, resv, resnull);}else{JsonConstructorExprState *jcstate;jcstate = palloc0(sizeof(JsonConstructorExprState));scratch.opcode = EEOP_JSON_CONSTRUCTOR;scratch.d.json_constructor.jcstate = jcstate;jcstate->constructor = ctor;jcstate->arg_values = (Datum *) palloc(sizeof(Datum) * nargs);jcstate->arg_nulls = (bool *) palloc(sizeof(bool) * nargs);jcstate->arg_types = (Oid *) palloc(sizeof(Oid) * nargs);jcstate->nargs = nargs;foreach(lc, args){Expr *arg = (Expr *) lfirst(lc);jcstate->arg_types[argno] = exprType((Node *) arg);if (IsA(arg, Const)){/* Don't evaluate const arguments every round */Const *con = (Const *) arg;jcstate->arg_values[argno] = con->constvalue;jcstate->arg_nulls[argno] = con->constisnull;}else{ExecInitExprRec(arg, state,&jcstate->arg_values[argno],&jcstate->arg_nulls[argno]);}argno++;}/* prepare type cache for datum_to_json[b]() */if (ctor->type == JSCTOR_JSON_SCALAR){bool is_jsonb =ctor->returning->format->format_type == JS_FORMAT_JSONB;jcstate->arg_type_cache =palloc(sizeof(*jcstate->arg_type_cache) * nargs);for (int i = 0; i < nargs; i++){JsonTypeCategory category;Oid outfuncid;Oid typid = jcstate->arg_types[i];json_categorize_type(typid, is_jsonb,&category, &outfuncid);jcstate->arg_type_cache[i].outfuncid = outfuncid;jcstate->arg_type_cache[i].category = (int) category;}}ExprEvalPushStep(state, &scratch);}if (ctor->coercion){Datum *innermost_caseval = state->innermost_caseval;bool *innermost_isnull = state->innermost_casenull;state->innermost_caseval = resv;state->innermost_casenull = resnull;ExecInitExprRec(ctor->coercion, state, resv, resnull);state->innermost_caseval = innermost_caseval;state->innermost_casenull = innermost_isnull;}}break;case T_JsonIsPredicate:{JsonIsPredicate *pred = (JsonIsPredicate *) node;ExecInitExprRec((Expr *) pred->expr, state, resv, resnull);scratch.opcode = EEOP_IS_JSON;scratch.d.is_json.pred = pred;ExprEvalPushStep(state, &scratch);break;}case T_JsonExpr:{JsonExpr *jsexpr = castNode(JsonExpr, node);/** No need to initialize a full JsonExprState For* JSON_TABLE(), because the upstream caller tfuncFetchRows()* is only interested in the value of formatted_expr.*/if (jsexpr->op == JSON_TABLE_OP)ExecInitExprRec((Expr *) jsexpr->formatted_expr, state,resv, resnull);elseExecInitJsonExpr(jsexpr, state, resv, resnull, &scratch);break;}case T_NullTest:{NullTest *ntest = (NullTest *) node;if (ntest->nulltesttype == IS_NULL){if (ntest->argisrow)scratch.opcode = EEOP_NULLTEST_ROWISNULL;elsescratch.opcode = EEOP_NULLTEST_ISNULL;}else if (ntest->nulltesttype == IS_NOT_NULL){if (ntest->argisrow)scratch.opcode = EEOP_NULLTEST_ROWISNOTNULL;elsescratch.opcode = EEOP_NULLTEST_ISNOTNULL;}else{elog(ERROR, "unrecognized nulltesttype: %d",(int) ntest->nulltesttype);}/* initialize cache in case it's a row test */scratch.d.nulltest_row.rowcache.cacheptr = NULL;/* first evaluate argument into result variable */ExecInitExprRec(ntest->arg, state,resv, resnull);/* then push the test of that argument */ExprEvalPushStep(state, &scratch);break;}case T_BooleanTest:{BooleanTest *btest = (BooleanTest *) node;/** Evaluate argument, directly into result datum. That's ok,* because resv/resnull is definitely not used anywhere else,* and will get overwritten by the below EEOP_BOOLTEST_IS_** step.*/ExecInitExprRec(btest->arg, state, resv, resnull);switch (btest->booltesttype){case IS_TRUE:scratch.opcode = EEOP_BOOLTEST_IS_TRUE;break;case IS_NOT_TRUE:scratch.opcode = EEOP_BOOLTEST_IS_NOT_TRUE;break;case IS_FALSE:scratch.opcode = EEOP_BOOLTEST_IS_FALSE;break;case IS_NOT_FALSE:scratch.opcode = EEOP_BOOLTEST_IS_NOT_FALSE;break;case IS_UNKNOWN:/* Same as scalar IS NULL test */scratch.opcode = EEOP_NULLTEST_ISNULL;break;case IS_NOT_UNKNOWN:/* Same as scalar IS NOT NULL test */scratch.opcode = EEOP_NULLTEST_ISNOTNULL;break;default:elog(ERROR, "unrecognized booltesttype: %d",(int) btest->booltesttype);}ExprEvalPushStep(state, &scratch);break;}case T_CoerceToDomain:{CoerceToDomain *ctest = (CoerceToDomain *) node;ExecInitCoerceToDomain(&scratch, ctest, state,resv, resnull);break;}case T_CoerceToDomainValue:{/** Read from location identified by innermost_domainval. Note* that innermost_domainval could be NULL, if we're compiling* a standalone domain check rather than one embedded in a* larger expression. In that case we must read from* econtext->domainValue_datum. We'll take care of that* scenario at runtime.*/scratch.opcode = EEOP_DOMAIN_TESTVAL;/* we share instruction union variant with case testval */scratch.d.casetest.value = state->innermost_domainval;scratch.d.casetest.isnull = state->innermost_domainnull;ExprEvalPushStep(state, &scratch);break;}case T_CurrentOfExpr:{scratch.opcode = EEOP_CURRENTOFEXPR;ExprEvalPushStep(state, &scratch);break;}case T_NextValueExpr:{NextValueExpr *nve = (NextValueExpr *) node;scratch.opcode = EEOP_NEXTVALUEEXPR;scratch.d.nextvalueexpr.seqid = nve->seqid;scratch.d.nextvalueexpr.seqtypid = nve->typeId;ExprEvalPushStep(state, &scratch);break;}default:elog(ERROR, "unrecognized node type: %d",(int) nodeTag(node));break;}
}
我将为 ExecInitExprRec 函数中的所有 case 分支创建一个表格,汇总每种节点类型(NodeTag)对应的处理情况,基于提供的代码片段。表格将列出每个 case 的节点类型、描述、操作码(opcode)或主要操作,以及通俗的解释,结合 SQL 查询 SELECT name, age + 10 AS new_age FROM users WHERE age > 30 或其他相关示例(如 SUM(age) 或 CASE 语句)来阐明其作用。表格将保持简介、易读,并以通俗的方式描述功能。
表格:ExecInitExprRec 中 case 分支汇总
| 节点类型 (NodeTag) | 描述 | 操作码 (opcode) 或主要操作 | 通俗解释(以 SQL 为例) |
|---|---|---|---|
| T_Var | 字段(变量),如表中的列 | EEOP_INNER_VAR, EEOP_OUTER_VAR, EEOP_SCAN_VAR, EEOP_INNER_SYSVAR, EEOP_OUTER_SYSVAR, EEOP_SCAN_SYSVAR, 或调用 ExecInitWholeRowVar | 处理 SQL 中的列,如 age。根据字段来源(普通表、内连接表、外连接表、系统列或整行引用),生成指令“从表中取 age 值”。例如,age + 10 中的 age 会生成读取列的指令。 |
| T_Const | 常量,如数字或字符串 | EEOP_CONST | 处理 SQL 中的常量,如 10 或 'John'。生成指令“直接使用值 10”并记录是否为 NULL。例如,age + 10 中的 10 会生成保存常量的指令。 |
| T_Param | 参数,如查询中的占位符 | EEOP_PARAM_EXEC, EEOP_PARAM_EXTERN, 或调用 paramCompile | 处理 SQL 中的参数,如 WHERE age > $1 中的 $1。生成指令从查询参数中取值,或者通过外部参数钩子处理。例如,$1 可能是用户输入的 30。 |
| T_Aggref | 聚合函数,如 SUM, COUNT | EEOP_AGGREF | 处理 SQL 中的聚合函数,如 SUM(age)。将聚合函数添加到父 AggState 并生成调用聚合的指令。确保在聚合计划中正确处理,例如 SELECT SUM(age) FROM users。 |
| T_GroupingFunc | 分组函数,如 GROUPING | EEOP_GROUPING_FUNC | 处理 SQL 中的 GROUPING 函数,用于 GROUP BY 中的分组集。生成指令计算分组标识,例如 GROUP BY CUBE(age, name) 中的 GROUPING(age)。 |
| T_WindowFunc | 窗口函数,如 ROW_NUMBER | EEOP_WINDOW_FUNC | 处理 SQL 中的窗口函数,如 ROW_NUMBER() OVER (PARTITION BY name)。初始化窗口函数状态并添加到父 WindowAggState,生成调用窗口函数的指令。 |
| T_MergeSupportFunc | MERGE 语句的支持函数 | EEOP_MERGE_SUPPORT_FUNC | 处理 SQL MERGE 语句中的支持函数。生成调用相关函数的指令,确保在 MERGE 计划中正确执行。 |
| T_SubscriptingRef | 数组或复合类型的下标引用 | 调用 ExecInitSubscriptingRef | 处理 SQL 中的数组或复合类型访问,如 array[1]。生成指令访问数组元素或复合类型字段。 |
| T_FuncExpr | 普通函数调用 | 调用 ExecInitFunc | 处理 SQL 中的函数,如 UPPER(name)。生成调用函数的指令,处理函数参数和结果。 |
| T_OpExpr | 运算符表达式,如 +, > | 调用 ExecInitFunc | 处理 SQL 中的运算符,如 age + 10 或 age > 30。生成调用运算符函数的指令,例如“加 10”或“比较大于 30”。 |
| T_DistinctExpr | DISTINCT ON 表达式 | EEOP_DISTINCT | 处理 SQL 中的 DISTINCT 比较,如 SELECT DISTINCT ON (name) ...。生成指令比较是否相等,类似 = 运算符。 |
| T_NullIfExpr | NULLIF 表达式 | EEOP_NULLIF | 处理 SQL 中的 NULLIF(name, 'John')。生成指令比较参数,如果相等返回 NULL,否则返回第一个参数。 |
| T_ScalarArrayOpExpr | 数组操作,如 IN | EEOP_SCALARARRAYOP, EEOP_HASHED_SCALARARRAYOP | 处理 SQL 中的数组操作,如 age IN (30, 40)。生成指令比较值是否在数组中,支持哈希优化以提高性能。 |
| T_BoolExpr | 布尔表达式,如 AND, OR, NOT | EEOP_BOOL_AND_STEP*, EEOP_BOOL_OR_STEP*, EEOP_BOOL_NOT_STEP | 处理 SQL 中的逻辑运算,如 age > 30 AND name = 'John'。生成短路求值的指令,例如“如果第一个条件为假,跳过后续”。 |
| T_SubPlan | 子查询 | EEOP_CONST (MULTIEXPR), 或调用 ExecInitSubPlanExpr | 处理 SQL 中的子查询,如 WHERE id IN (SELECT ...)。对于 MULTIEXPR 类型返回空值,其他类型生成执行子查询的指令。 |
| T_FieldSelect | 从复合类型选择字段 | EEOP_FIELDSELECT | 处理 SQL 中的复合类型字段访问,如 user.address.city。生成指令从复合类型中提取指定字段。 |
| T_FieldStore | 修改复合类型字段 | EEOP_FIELDSTORE_DEFORM, EEOP_FIELDSTORE_FORM | 处理 SQL 中的复合类型字段更新,如 user.address = ROW('New York', ...)。生成指令分解和重组复合类型。 |
| T_RelabelType | 类型转换(无运行时操作) | 无操作码,直接递归处理子表达式 | 处理 SQL 中的显式类型转换,如 CAST(age AS float)。仅递归处理子表达式,无需额外指令。 |
| T_CoerceViaIO | 通过输入/输出函数进行类型转换 | EEOP_IOCOERCE, EEOP_IOCOERCE_SAFE | 处理 SQL 中的类型转换,如 age::text。生成指令调用类型的输入/输出函数进行转换。 |
| T_ArrayCoerceExpr | 数组元素类型转换 | EEOP_ARRAYCOERCE | 处理 SQL 中的数组元素转换,如 ARRAY[1, 2]::text[]。生成指令对数组元素逐个转换。 |
| T_ConvertRowtypeExpr | 行类型转换 | EEOP_CONVERT_ROWTYPE | 处理 SQL 中的行类型转换,如 ROW(age, name)::new_type。生成指令将一种行类型转换为另一种。 |
| T_CaseExpr | CASE 表达式 | EEOP_JUMP_IF_NOT_TRUE, EEOP_JUMP, EEOP_MAKE_READONLY | 处理 SQL 中的 CASE WHEN age > 30 THEN 'Adult' ELSE 'Young' END。生成条件跳转和结果选择的指令。 |
| T_CaseTestExpr | CASE 测试值 | EEOP_CASE_TESTVAL | 处理 CASE 语句中的测试值,如 CASE age WHEN 30 THEN ...。生成指令读取 CASE 的测试值。 |
| T_ArrayExpr | 数组构造 | EEOP_ARRAYEXPR | 处理 SQL 中的数组构造,如 ARRAY[1, 2, 3]。生成指令计算数组元素并构造数组。 |
| T_RowExpr | 行构造 | EEOP_ROW | 处理 SQL 中的行构造,如 ROW(age, name)。生成指令计算各字段并构造行值。 |
| T_RowCompareExpr | 行比较 | EEOP_ROWCOMPARE_STEP, EEOP_ROWCOMPARE_FINAL | 处理 SQL 中的行比较,如 ROW(age, name) > ROW(30, 'John')。生成指令逐字段比较并得出结果。 |
| T_CoalesceExpr | COALESCE 表达式 | EEOP_JUMP_IF_NOT_NULL | 处理 SQL 中的 COALESCE(age, 0)。生成指令返回第一个非 NULL 值。 |
| T_MinMaxExpr | GREATEST, LEAST 表达式 | EEOP_MINMAX | 处理 SQL 中的 GREATEST(age, 18) 或 LEAST(age, 65)。生成指令比较参数并返回最大/最小值。 |
| T_SQLValueFunction | SQL 值函数,如 CURRENT_DATE | EEOP_SQLVALUEFUNCTION | 处理 SQL 中的值函数,如 CURRENT_DATE 或 CURRENT_USER。生成指令调用对应的值函数。 |
| T_XmlExpr | XML 表达式 | EEOP_XMLEXPR | 处理 SQL 中的 XML 操作,如 XMLELEMENT(name, 'data')。生成指令计算参数并构造 XML。 |
| T_JsonValueExpr | JSON 值表达式 | 递归处理 raw_expr 和 formatted_expr | 处理 SQL 中的 JSON 值表达式,如 JSON_VALUE(json_col, '$.path')。递归处理原始和格式化表达式。 |
| T_JsonConstructorExpr | JSON 构造表达式 | EEOP_JSON_CONSTRUCTOR, 或递归处理子表达式 | 处理 SQL 中的 JSON 构造,如 JSON_OBJECT('key': value)。生成指令构造 JSON 数据,或处理特定子表达式。 |
| T_JsonIsPredicate | JSON 谓词,如 IS JSON | EEOP_IS_JSON | 处理 SQL 中的 json_col IS JSON。生成指令检查值是否为 JSON。 |
| T_JsonExpr | JSON 表达式,如 JSON_TABLE | EEOP_JSON_CONSTRUCTOR, 或递归处理 formatted_expr | 处理 SQL 中的 JSON_TABLE 或其他 JSON 表达式。生成指令处理 JSON 数据或递归处理格式化表达式。 |
| T_NullTest | NULL 测试,如 IS NULL | EEOP_NULLTEST_ISNULL, EEOP_NULLTEST_ISNOTNULL, EEOP_NULLTEST_ROWISNULL, EEOP_NULLTEST_ROWISNOTNULL | 处理 SQL 中的 age IS NULL 或 age IS NOT NULL。生成指令检查值或行是否为 NULL。 |
| T_BooleanTest | 布尔测试,如 IS TRUE | EEOP_BOOLTEST_IS_TRUE, EEOP_BOOLTEST_IS_NOT_TRUE, EEOP_BOOLTEST_IS_FALSE, EEOP_BOOLTEST_IS_NOT_FALSE, 或重用 NULL 测试 | 处理 SQL 中的 condition IS TRUE 或 condition IS FALSE。生成指令检查布尔值状态。 |
| T_CoerceToDomain | 域类型约束 | 调用 ExecInitCoerceToDomain | 处理 SQL 中的域类型检查,如 age::mydomain。生成指令验证值是否符合域约束。 |
| T_CoerceToDomainValue | 域值引用 | EEOP_DOMAIN_TESTVAL | 处理域类型中的值引用。生成指令读取域值,类似 CASE 测试值。 |
| T_CurrentOfExpr | CURRENT OF 表达式 | EEOP_CURRENTOFEXPR | 处理 SQL 中的 WHERE CURRENT OF cursor。生成指令处理游标当前位置。 |
| T_NextValueExpr | 序列函数,如 nextval | EEOP_NEXTVALUEEXPR | 处理 SQL 中的 nextval('seq')。生成指令获取序列的下一个值。 |
| default | 未知节点类型 | 抛出错误 (elog(ERROR)) | 如果遇到无法识别的节点类型,抛出错误,表明计划有误。 |
说明
- 表格内容:每个
case对应一种表达式节点类型,描述其功能、生成的主要操作码(或调用的函数),并用SQL示例解释其作用。操作码(如EEOP_*)是PostgreSQL执行引擎的指令,告诉系统如何处理表达式。 - SQL 示例:基于
SELECT name, age + 10 AS new_age FROM users WHERE age > 30,并扩展到其他常见SQL构造(如SUM(age),CASE,JSON_OBJECT等),以便直观理解。 - 通俗解释:每个节点的处理都被简化为“生成什么指令”“做什么事”,例如“从表取值”“计算加法”“检查是否
NULL”等。 - 完整性:表格覆盖了代码中所有的
case分支,基于提供的代码片段。每个分支都专注于为特定表达式类型生成执行步骤,确保SQL查询高效执行。
为什么重要?
ExecInitExprRec 是 PostgreSQL 将 SQL 表达式的抽象树转换为可执行指令的核心函数。每个 case 处理一种表达式类型(如字段、常量、函数、逻辑运算等),生成对应的指令,确保查询引擎能正确计算结果。表格清晰展示了每种节点类型的处理逻辑,帮助理解 PostgreSQL 如何将复杂 SQL 翻译为可执行步骤。
ExprEvalPushStep
ExprEvalPushStep 是 PostgreSQL 查询执行引擎中用于将单个表达式执行步骤(ExprEvalStep)添加到 ExprState 的步骤列表(steps)的函数。它的作用就像把一条具体的执行指令(如“从表中取 age 值”或“计算 age + 10”)写入一个“执行计划笔记本”。
它会检查当前“笔记本”是否有空间,如果没有就初始化或扩展空间,然后将指令写入,确保表达式(如 age + 10 或 age > 30)的执行步骤按顺序保存,供后续查询执行使用。这个函数是 ExecInitExprRec 等函数的辅助工具,确保所有生成的指令都能被正确记录。
/** ExprEvalPushStep: 向 ExprState->steps 添加一个表达式执行步骤* 类似于把一条执行指令(如“从表取 age 值”)添加到 SQL 表达式的执行计划书中。* 注意:这个过程可能会重新分配 steps 数组的内存,所以在构建表达式时不能直接使用 steps 数组的指针。*/
void
ExprEvalPushStep(ExprState *es, const ExprEvalStep *s)
{/* 如果 steps 数组尚未分配,初始化它 */if (es->steps_alloc == 0){es->steps_alloc = 16; // 分配 16 个槽位给 steps 数组,像准备一个能存 16 条指令的笔记本es->steps = palloc(sizeof(ExprEvalStep) * es->steps_alloc); // 创建 steps 数组// SQL 例子:为“age + 10”的执行计划创建一个空的“指令笔记本”。}/* 如果 steps 数组已满,扩展它 */else if (es->steps_alloc == es->steps_len){es->steps_alloc *= 2; // 将槽位数翻倍,比如从 16 变成 32es->steps = repalloc(es->steps, sizeof(ExprEvalStep) * es->steps_alloc); // 重新分配更大的数组// SQL 例子:如果“age + 10”和“age > 30”的指令太多,笔记本满了,就换一个更大的笔记本。}/* 将新的执行步骤复制到 steps 数组 */memcpy(&es->steps[es->steps_len++], s, sizeof(ExprEvalStep)); // 把指令(如“取 age 值”)写入笔记本,并更新指令计数// SQL 例子:把“从 users 表取 age”或“加 10”的指令写入计划书,准备执行。
}
主要流程(以 SQL 为例)
假设我们处理 SQL 查询 SELECT name, age + 10 AS new_age FROM users WHERE age > 30,其中表达式 age + 10 和 age > 30 需要生成执行步骤:
- 检查是否需要初始化
steps数组:- 代码:
if (es->steps_alloc == 0) - 功能:如果
steps数组(存储指令的“笔记本”)还没创建,就分配一个能存16条指令的空间。 SQL例子:为age + 10的执行计划创建一个空的“指令笔记本”,准备记录如何计算age + 10。
- 代码:
-
检查
steps数组是否已满并扩展:- 代码:
else if (es->steps_alloc == es->steps_len) - 功能:如果“笔记本”满了(已有指令数等于分配的槽位数),将槽位数翻倍并重新分配更大的空间。
SQL例子:如果age + 10和age > 30的指令太多(比如超过16条),就把“笔记本”扩展到32条指令的容量。
- 代码:
-
添加新步骤到
steps数组:- 代码:
memcpy(&es->steps[es->steps_len++], s, sizeof(ExprEvalStep)) - 功能:将新的执行步骤(如“取
age值”或“加10”)复制到“笔记本”中,并增加指令计数。 SQL例子:把“从users表取age”或“加10”的指令写入“笔记本”,记录在age + 10的执行计划中。
- 代码:
ExecReadyExpr
ExecReadyExpr 是 PostgreSQL 查询执行引擎中为表达式状态(ExprState)做最终执行准备的函数。它的作用就像检查 SQL 表达式的“执行计划书”(如 age + 10 的计算步骤)是否准备好运行。它首先尝试使用 JIT(即时编译)来优化执行速度,如果 JIT 不可用或失败,则调用 ExecReadyInterpretedExpr 准备解释执行方式。
这个函数是执行表达式的最后一步,确保 ExprState 可以被 ExecEvalExpr 正确执行。它设计为可扩展,未来可能支持更多执行方式(如 JIT 或其他优化)。
/** ExecReadyExpr: 为已编译的表达式准备执行* 类似于检查 SQL 表达式的“执行计划书”是否准备好,确保可以运行。* 目前只调用解释执行的准备函数,但未来可能支持其他执行方式(如 JIT 编译)。* 因此,应使用此函数,而不是直接调用 ExecReadyInterpretedExpr。*/
static void
ExecReadyExpr(ExprState *state)
{/* 尝试使用 JIT 编译表达式,如果成功则直接返回 */if (jit_compile_expr(state))return;// SQL 例子:检查是否可以用 JIT(即时编译)加速“age + 10”的执行,如果可以就用更快的方式。/* 如果 JIT 不可用,准备解释执行 */ExecReadyInterpretedExpr(state);// SQL 例子:如果 JIT 不行,就按常规方式准备“age + 10”的执行计划。
}
ExecReadyInterpretedExpr
ExecReadyInterpretedExpr 是为解释执行方式准备 ExprState 的函数,类似于为 SQL 表达式的“执行计划书”做最后检查和优化。它确保解释器环境已初始化,验证计划书有效(有步骤且以 EEOP_DONE 结尾),并为简单表达式选择快速执行路径(如直接取字段或常量)。如果启用了直接线程化,它还会优化指令跳转地址以提高性能。对于复杂表达式,它设置标准的解释执行函数。这个函数确保 age + 10 或 age > 30 的执行计划可以高效、正确地运行。
/** ExecReadyInterpretedExpr: 为解释执行准备 ExprState* 类似于为 SQL 表达式的“执行计划书”做最后检查和优化,确保可以按步骤运行。*/
void
ExecReadyInterpretedExpr(ExprState *state)
{/* 确保解释器的初始化工作已完成 */ExecInitInterpreter();// SQL 例子:确保计算“age + 10”的解释器环境已设置好,比如内存和基本函数。/* 检查表达式是否有效 */Assert(state->steps_len >= 1); // 确保计划书至少有一条指令Assert(state->steps[state->steps_len - 1].opcode == EEOP_DONE); // 确保最后一条指令是“结束”// SQL 例子:检查“age + 10”的计划书不为空,且以“完成”指令结尾。/* 如果已初始化,跳过重复工作 */if (state->flags & EEO_FLAG_INTERPRETER_INITIALIZED)return;// SQL 例子:如果“age + 10”的计划书已经准备好,就不重复处理。/* 设置初始执行函数,用于验证属性和变量是否匹配 */state->evalfunc = ExecInterpExprStillValid;// SQL 例子:设置一个检查函数,确保“age”列在执行时仍然有效(比如表结构没变)。/* 确保未启用直接线程化 */Assert((state->flags & EEO_FLAG_DIRECT_THREADED) == 0);// SQL 例子:确认“age + 10”的计划书还没用高级优化(直接线程化)。/* 标记已初始化,简化后续处理 */state->flags |= EEO_FLAG_INTERPRETER_INITIALIZED;// SQL 例子:标记“age + 10”的计划书已准备好,避免重复初始化。/* 为简单表达式选择快速执行路径 */if (state->steps_len == 5){ExprEvalOp step0 = state->steps[0].opcode;ExprEvalOp step1 = state->steps[1].opcode;ExprEvalOp step2 = state->steps[2].opcode;ExprEvalOp step3 = state->steps[3].opcode;if (step0 == EEOP_INNER_FETCHSOME &&step1 == EEOP_HASHDATUM_SET_INITVAL &&step2 == EEOP_INNER_VAR &&step3 == EEOP_HASHDATUM_NEXT32){state->evalfunc_private = (void *) ExecJustHashInnerVarWithIV;return;}}else if (state->steps_len == 4){/* 类似处理,检查特定步骤模式,设置快速函数 */// SQL 例子:如果“age”是简单内表字段,选择快速函数直接取值。}else if (state->steps_len == 3){/* 检查简单模式,如取字段或赋值 */// SQL 例子:如果只是“从 users 表取 age”,用快速函数直接处理。}else if (state->steps_len == 2){ExprEvalOp step0 = state->steps[0].opcode;if (step0 == EEOP_CONST){state->evalfunc_private = ExecJustConst;return;}// SQL 例子:如果表达式只是常量“10”,直接用快速函数返回常量值。}// SQL 例子:检查“age + 10”的指令数,如果是简单模式(如只取 age),用快速函数加速。/* 如果启用了直接线程化,优化指令跳转地址 */
#if defined(EEO_USE_COMPUTED_GOTO)for (int off = 0; off < state->steps_len; off++){ExprEvalStep *op = &state->steps[off];op->opcode = EEO_OPCODE(op->opcode); // 将操作码替换为跳转地址}state->flags |= EEO_FLAG_DIRECT_THREADED; // 标记已启用直接线程化// SQL 例子:将“age + 10”的指令优化为直接跳转,提高执行速度。
#endif/* 设置默认解释执行函数 */state->evalfunc_private = ExecInterpExpr;// SQL 例子:如果没有快速路径,就用标准函数逐条执行“age + 10”的指令。
}
我将为 ExecInterpExpr 函数中的所有 case 分支创建一个表格,汇总每种操作码(ExprEvalOp)对应的处理情况,基于提供的代码片段。表格将列出每个 case 的操作码、描述、主要操作,以及通俗的解释,结合 SQL 查询 SELECT name, age + 10 AS new_age FROM users WHERE age > 30 或其他相关示例(如 SUM(age)、CASE 语句)来阐明其作用。表格将保持简介、易读,并以通俗的方式描述功能。之后,我会用一段话描述该函数的主要功能。
ExecInterpExpr
ExecInterpExpr 是 PostgreSQL 查询执行引擎中负责解释执行表达式的核心函数。它通过逐条处理 ExprState 中的操作码(ExprEvalOp),执行 SQL 表达式的每一步计算(如 age + 10 或 age > 30)。函数使用一个跳转表(dispatch_table)支持高效的指令分派,处理从简单字段获取(如 age)到复杂操作(如 SUM(age)、逻辑运算 AND、JSON 处理)的各种表达式。它支持短路求值(如 AND/OR 逻辑)、NULL 处理、类型转换等,确保表达式结果正确返回,同时通过内联简单操作和外联复杂操作优化性能。这个函数是查询执行的“执行者”,将 ExecInitExprRec 和 ExecReadyInterpretedExpr 准备的计划书转化为实际结果。
/** Evaluate expression identified by "state" in the execution context* given by "econtext". *isnull is set to the is-null flag for the result,* and the Datum value is the function result.** As a special case, return the dispatch table's address if state is NULL.* This is used by ExecInitInterpreter to set up the dispatch_table global.* (Only applies when EEO_USE_COMPUTED_GOTO is defined.)*/
static Datum
ExecInterpExpr(ExprState *state, ExprContext *econtext, bool *isnull)
{ExprEvalStep *op;TupleTableSlot *resultslot;TupleTableSlot *innerslot;TupleTableSlot *outerslot;TupleTableSlot *scanslot;/** This array has to be in the same order as enum ExprEvalOp.*/
#if defined(EEO_USE_COMPUTED_GOTO)static const void *const dispatch_table[] = {&&CASE_EEOP_DONE,&&CASE_EEOP_INNER_FETCHSOME,&&CASE_EEOP_OUTER_FETCHSOME,&&CASE_EEOP_SCAN_FETCHSOME,&&CASE_EEOP_INNER_VAR,&&CASE_EEOP_OUTER_VAR,&&CASE_EEOP_SCAN_VAR,&&CASE_EEOP_INNER_SYSVAR,&&CASE_EEOP_OUTER_SYSVAR,&&CASE_EEOP_SCAN_SYSVAR,&&CASE_EEOP_WHOLEROW,&&CASE_EEOP_ASSIGN_INNER_VAR,&&CASE_EEOP_ASSIGN_OUTER_VAR,&&CASE_EEOP_ASSIGN_SCAN_VAR,&&CASE_EEOP_ASSIGN_TMP,&&CASE_EEOP_ASSIGN_TMP_MAKE_RO,&&CASE_EEOP_CONST,&&CASE_EEOP_FUNCEXPR,&&CASE_EEOP_FUNCEXPR_STRICT,&&CASE_EEOP_FUNCEXPR_FUSAGE,&&CASE_EEOP_FUNCEXPR_STRICT_FUSAGE,&&CASE_EEOP_BOOL_AND_STEP_FIRST,&&CASE_EEOP_BOOL_AND_STEP,&&CASE_EEOP_BOOL_AND_STEP_LAST,&&CASE_EEOP_BOOL_OR_STEP_FIRST,&&CASE_EEOP_BOOL_OR_STEP,&&CASE_EEOP_BOOL_OR_STEP_LAST,&&CASE_EEOP_BOOL_NOT_STEP,&&CASE_EEOP_QUAL,&&CASE_EEOP_JUMP,&&CASE_EEOP_JUMP_IF_NULL,&&CASE_EEOP_JUMP_IF_NOT_NULL,&&CASE_EEOP_JUMP_IF_NOT_TRUE,&&CASE_EEOP_NULLTEST_ISNULL,&&CASE_EEOP_NULLTEST_ISNOTNULL,&&CASE_EEOP_NULLTEST_ROWISNULL,&&CASE_EEOP_NULLTEST_ROWISNOTNULL,&&CASE_EEOP_BOOLTEST_IS_TRUE,&&CASE_EEOP_BOOLTEST_IS_NOT_TRUE,&&CASE_EEOP_BOOLTEST_IS_FALSE,&&CASE_EEOP_BOOLTEST_IS_NOT_FALSE,&&CASE_EEOP_PARAM_EXEC,&&CASE_EEOP_PARAM_EXTERN,&&CASE_EEOP_PARAM_CALLBACK,&&CASE_EEOP_PARAM_SET,&&CASE_EEOP_CASE_TESTVAL,&&CASE_EEOP_MAKE_READONLY,&&CASE_EEOP_IOCOERCE,&&CASE_EEOP_IOCOERCE_SAFE,&&CASE_EEOP_DISTINCT,&&CASE_EEOP_NOT_DISTINCT,&&CASE_EEOP_NULLIF,&&CASE_EEOP_SQLVALUEFUNCTION,&&CASE_EEOP_CURRENTOFEXPR,&&CASE_EEOP_NEXTVALUEEXPR,&&CASE_EEOP_ARRAYEXPR,&&CASE_EEOP_ARRAYCOERCE,&&CASE_EEOP_ROW,&&CASE_EEOP_ROWCOMPARE_STEP,&&CASE_EEOP_ROWCOMPARE_FINAL,&&CASE_EEOP_MINMAX,&&CASE_EEOP_FIELDSELECT,&&CASE_EEOP_FIELDSTORE_DEFORM,&&CASE_EEOP_FIELDSTORE_FORM,&&CASE_EEOP_SBSREF_SUBSCRIPTS,&&CASE_EEOP_SBSREF_OLD,&&CASE_EEOP_SBSREF_ASSIGN,&&CASE_EEOP_SBSREF_FETCH,&&CASE_EEOP_DOMAIN_TESTVAL,&&CASE_EEOP_DOMAIN_NOTNULL,&&CASE_EEOP_DOMAIN_CHECK,&&CASE_EEOP_HASHDATUM_SET_INITVAL,&&CASE_EEOP_HASHDATUM_FIRST,&&CASE_EEOP_HASHDATUM_FIRST_STRICT,&&CASE_EEOP_HASHDATUM_NEXT32,&&CASE_EEOP_HASHDATUM_NEXT32_STRICT,&&CASE_EEOP_CONVERT_ROWTYPE,&&CASE_EEOP_SCALARARRAYOP,&&CASE_EEOP_HASHED_SCALARARRAYOP,&&CASE_EEOP_XMLEXPR,&&CASE_EEOP_JSON_CONSTRUCTOR,&&CASE_EEOP_IS_JSON,&&CASE_EEOP_JSONEXPR_PATH,&&CASE_EEOP_JSONEXPR_COERCION,&&CASE_EEOP_JSONEXPR_COERCION_FINISH,&&CASE_EEOP_AGGREF,&&CASE_EEOP_GROUPING_FUNC,&&CASE_EEOP_WINDOW_FUNC,&&CASE_EEOP_MERGE_SUPPORT_FUNC,&&CASE_EEOP_SUBPLAN,&&CASE_EEOP_AGG_STRICT_DESERIALIZE,&&CASE_EEOP_AGG_DESERIALIZE,&&CASE_EEOP_AGG_STRICT_INPUT_CHECK_ARGS,&&CASE_EEOP_AGG_STRICT_INPUT_CHECK_NULLS,&&CASE_EEOP_AGG_PLAIN_PERGROUP_NULLCHECK,&&CASE_EEOP_AGG_PLAIN_TRANS_INIT_STRICT_BYVAL,&&CASE_EEOP_AGG_PLAIN_TRANS_STRICT_BYVAL,&&CASE_EEOP_AGG_PLAIN_TRANS_BYVAL,&&CASE_EEOP_AGG_PLAIN_TRANS_INIT_STRICT_BYREF,&&CASE_EEOP_AGG_PLAIN_TRANS_STRICT_BYREF,&&CASE_EEOP_AGG_PLAIN_TRANS_BYREF,&&CASE_EEOP_AGG_PRESORTED_DISTINCT_SINGLE,&&CASE_EEOP_AGG_PRESORTED_DISTINCT_MULTI,&&CASE_EEOP_AGG_ORDERED_TRANS_DATUM,&&CASE_EEOP_AGG_ORDERED_TRANS_TUPLE,&&CASE_EEOP_LAST};StaticAssertDecl(lengthof(dispatch_table) == EEOP_LAST + 1,"dispatch_table out of whack with ExprEvalOp");if (unlikely(state == NULL))return PointerGetDatum(dispatch_table);
#elseAssert(state != NULL);
#endif /* EEO_USE_COMPUTED_GOTO *//* setup state */op = state->steps;resultslot = state->resultslot;innerslot = econtext->ecxt_innertuple;outerslot = econtext->ecxt_outertuple;scanslot = econtext->ecxt_scantuple;#if defined(EEO_USE_COMPUTED_GOTO)EEO_DISPATCH();
#endifEEO_SWITCH(){EEO_CASE(EEOP_DONE){goto out;}EEO_CASE(EEOP_INNER_FETCHSOME){CheckOpSlotCompatibility(op, innerslot);slot_getsomeattrs(innerslot, op->d.fetch.last_var);EEO_NEXT();}EEO_CASE(EEOP_OUTER_FETCHSOME){CheckOpSlotCompatibility(op, outerslot);slot_getsomeattrs(outerslot, op->d.fetch.last_var);EEO_NEXT();}EEO_CASE(EEOP_SCAN_FETCHSOME){CheckOpSlotCompatibility(op, scanslot);slot_getsomeattrs(scanslot, op->d.fetch.last_var);EEO_NEXT();}EEO_CASE(EEOP_INNER_VAR){int attnum = op->d.var.attnum;/** Since we already extracted all referenced columns from the* tuple with a FETCHSOME step, we can just grab the value* directly out of the slot's decomposed-data arrays. But let's* have an Assert to check that that did happen.*/Assert(attnum >= 0 && attnum < innerslot->tts_nvalid);*op->resvalue = innerslot->tts_values[attnum];*op->resnull = innerslot->tts_isnull[attnum];EEO_NEXT();}EEO_CASE(EEOP_OUTER_VAR){int attnum = op->d.var.attnum;/* See EEOP_INNER_VAR comments */Assert(attnum >= 0 && attnum < outerslot->tts_nvalid);*op->resvalue = outerslot->tts_values[attnum];*op->resnull = outerslot->tts_isnull[attnum];EEO_NEXT();}EEO_CASE(EEOP_SCAN_VAR){int attnum = op->d.var.attnum;/* See EEOP_INNER_VAR comments */Assert(attnum >= 0 && attnum < scanslot->tts_nvalid);*op->resvalue = scanslot->tts_values[attnum];*op->resnull = scanslot->tts_isnull[attnum];EEO_NEXT();}EEO_CASE(EEOP_INNER_SYSVAR){ExecEvalSysVar(state, op, econtext, innerslot);EEO_NEXT();}EEO_CASE(EEOP_OUTER_SYSVAR){ExecEvalSysVar(state, op, econtext, outerslot);EEO_NEXT();}EEO_CASE(EEOP_SCAN_SYSVAR){ExecEvalSysVar(state, op, econtext, scanslot);EEO_NEXT();}EEO_CASE(EEOP_WHOLEROW){/* too complex for an inline implementation */ExecEvalWholeRowVar(state, op, econtext);EEO_NEXT();}EEO_CASE(EEOP_ASSIGN_INNER_VAR){int resultnum = op->d.assign_var.resultnum;int attnum = op->d.assign_var.attnum;/** We do not need CheckVarSlotCompatibility here; that was taken* care of at compilation time. But see EEOP_INNER_VAR comments.*/Assert(attnum >= 0 && attnum < innerslot->tts_nvalid);Assert(resultnum >= 0 && resultnum < resultslot->tts_tupleDescriptor->natts);resultslot->tts_values[resultnum] = innerslot->tts_values[attnum];resultslot->tts_isnull[resultnum] = innerslot->tts_isnull[attnum];EEO_NEXT();}EEO_CASE(EEOP_ASSIGN_OUTER_VAR){int resultnum = op->d.assign_var.resultnum;int attnum = op->d.assign_var.attnum;/** We do not need CheckVarSlotCompatibility here; that was taken* care of at compilation time. But see EEOP_INNER_VAR comments.*/Assert(attnum >= 0 && attnum < outerslot->tts_nvalid);Assert(resultnum >= 0 && resultnum < resultslot->tts_tupleDescriptor->natts);resultslot->tts_values[resultnum] = outerslot->tts_values[attnum];resultslot->tts_isnull[resultnum] = outerslot->tts_isnull[attnum];EEO_NEXT();}EEO_CASE(EEOP_ASSIGN_SCAN_VAR){int resultnum = op->d.assign_var.resultnum;int attnum = op->d.assign_var.attnum;/** We do not need CheckVarSlotCompatibility here; that was taken* care of at compilation time. But see EEOP_INNER_VAR comments.*/Assert(attnum >= 0 && attnum < scanslot->tts_nvalid);Assert(resultnum >= 0 && resultnum < resultslot->tts_tupleDescriptor->natts);resultslot->tts_values[resultnum] = scanslot->tts_values[attnum];resultslot->tts_isnull[resultnum] = scanslot->tts_isnull[attnum];EEO_NEXT();}EEO_CASE(EEOP_ASSIGN_TMP){int resultnum = op->d.assign_tmp.resultnum;Assert(resultnum >= 0 && resultnum < resultslot->tts_tupleDescriptor->natts);resultslot->tts_values[resultnum] = state->resvalue;resultslot->tts_isnull[resultnum] = state->resnull;EEO_NEXT();}EEO_CASE(EEOP_ASSIGN_TMP_MAKE_RO){int resultnum = op->d.assign_tmp.resultnum;Assert(resultnum >= 0 && resultnum < resultslot->tts_tupleDescriptor->natts);resultslot->tts_isnull[resultnum] = state->resnull;if (!resultslot->tts_isnull[resultnum])resultslot->tts_values[resultnum] =MakeExpandedObjectReadOnlyInternal(state->resvalue);elseresultslot->tts_values[resultnum] = state->resvalue;EEO_NEXT();}EEO_CASE(EEOP_CONST){*op->resnull = op->d.constval.isnull;*op->resvalue = op->d.constval.value;EEO_NEXT();}/** Function-call implementations. Arguments have previously been* evaluated directly into fcinfo->args.** As both STRICT checks and function-usage are noticeable performance* wise, and function calls are a very hot-path (they also back* operators!), it's worth having so many separate opcodes.** Note: the reason for using a temporary variable "d", here and in* other places, is that some compilers think "*op->resvalue = f();"* requires them to evaluate op->resvalue into a register before* calling f(), just in case f() is able to modify op->resvalue* somehow. The extra line of code can save a useless register spill* and reload across the function call.*/EEO_CASE(EEOP_FUNCEXPR){FunctionCallInfo fcinfo = op->d.func.fcinfo_data;Datum d;fcinfo->isnull = false;d = op->d.func.fn_addr(fcinfo);*op->resvalue = d;*op->resnull = fcinfo->isnull;EEO_NEXT();}EEO_CASE(EEOP_FUNCEXPR_STRICT){FunctionCallInfo fcinfo = op->d.func.fcinfo_data;NullableDatum *args = fcinfo->args;int nargs = op->d.func.nargs;Datum d;/* strict function, so check for NULL args */for (int argno = 0; argno < nargs; argno++){if (args[argno].isnull){*op->resnull = true;goto strictfail;}}fcinfo->isnull = false;d = op->d.func.fn_addr(fcinfo);*op->resvalue = d;*op->resnull = fcinfo->isnull;strictfail:EEO_NEXT();}EEO_CASE(EEOP_FUNCEXPR_FUSAGE){/* not common enough to inline */ExecEvalFuncExprFusage(state, op, econtext);EEO_NEXT();}EEO_CASE(EEOP_FUNCEXPR_STRICT_FUSAGE){/* not common enough to inline */ExecEvalFuncExprStrictFusage(state, op, econtext);EEO_NEXT();}/** If any of its clauses is FALSE, an AND's result is FALSE regardless* of the states of the rest of the clauses, so we can stop evaluating* and return FALSE immediately. If none are FALSE and one or more is* NULL, we return NULL; otherwise we return TRUE. This makes sense* when you interpret NULL as "don't know": perhaps one of the "don't* knows" would have been FALSE if we'd known its value. Only when* all the inputs are known to be TRUE can we state confidently that* the AND's result is TRUE.*/EEO_CASE(EEOP_BOOL_AND_STEP_FIRST){*op->d.boolexpr.anynull = false;/** EEOP_BOOL_AND_STEP_FIRST resets anynull, otherwise it's the* same as EEOP_BOOL_AND_STEP - so fall through to that.*//* FALL THROUGH */}EEO_CASE(EEOP_BOOL_AND_STEP){if (*op->resnull){*op->d.boolexpr.anynull = true;}else if (!DatumGetBool(*op->resvalue)){/* result is already set to FALSE, need not change it *//* bail out early */EEO_JUMP(op->d.boolexpr.jumpdone);}EEO_NEXT();}EEO_CASE(EEOP_BOOL_AND_STEP_LAST){if (*op->resnull){/* result is already set to NULL, need not change it */}else if (!DatumGetBool(*op->resvalue)){/* result is already set to FALSE, need not change it *//** No point jumping early to jumpdone - would be same target* (as this is the last argument to the AND expression),* except more expensive.*/}else if (*op->d.boolexpr.anynull){*op->resvalue = (Datum) 0;*op->resnull = true;}else{/* result is already set to TRUE, need not change it */}EEO_NEXT();}/** If any of its clauses is TRUE, an OR's result is TRUE regardless of* the states of the rest of the clauses, so we can stop evaluating* and return TRUE immediately. If none are TRUE and one or more is* NULL, we return NULL; otherwise we return FALSE. This makes sense* when you interpret NULL as "don't know": perhaps one of the "don't* knows" would have been TRUE if we'd known its value. Only when all* the inputs are known to be FALSE can we state confidently that the* OR's result is FALSE.*/EEO_CASE(EEOP_BOOL_OR_STEP_FIRST){*op->d.boolexpr.anynull = false;/** EEOP_BOOL_OR_STEP_FIRST resets anynull, otherwise it's the same* as EEOP_BOOL_OR_STEP - so fall through to that.*//* FALL THROUGH */}EEO_CASE(EEOP_BOOL_OR_STEP){if (*op->resnull){*op->d.boolexpr.anynull = true;}else if (DatumGetBool(*op->resvalue)){/* result is already set to TRUE, need not change it *//* bail out early */EEO_JUMP(op->d.boolexpr.jumpdone);}EEO_NEXT();}EEO_CASE(EEOP_BOOL_OR_STEP_LAST){if (*op->resnull){/* result is already set to NULL, need not change it */}else if (DatumGetBool(*op->resvalue)){/* result is already set to TRUE, need not change it *//** No point jumping to jumpdone - would be same target (as* this is the last argument to the AND expression), except* more expensive.*/}else if (*op->d.boolexpr.anynull){*op->resvalue = (Datum) 0;*op->resnull = true;}else{/* result is already set to FALSE, need not change it */}EEO_NEXT();}EEO_CASE(EEOP_BOOL_NOT_STEP){/** Evaluation of 'not' is simple... if expr is false, then return* 'true' and vice versa. It's safe to do this even on a* nominally null value, so we ignore resnull; that means that* NULL in produces NULL out, which is what we want.*/*op->resvalue = BoolGetDatum(!DatumGetBool(*op->resvalue));EEO_NEXT();}EEO_CASE(EEOP_QUAL){/* simplified version of BOOL_AND_STEP for use by ExecQual() *//* If argument (also result) is false or null ... */if (*op->resnull ||!DatumGetBool(*op->resvalue)){/* ... bail out early, returning FALSE */*op->resnull = false;*op->resvalue = BoolGetDatum(false);EEO_JUMP(op->d.qualexpr.jumpdone);}/** Otherwise, leave the TRUE value in place, in case this is the* last qual. Then, TRUE is the correct answer.*/EEO_NEXT();}EEO_CASE(EEOP_JUMP){/* Unconditionally jump to target step */EEO_JUMP(op->d.jump.jumpdone);}EEO_CASE(EEOP_JUMP_IF_NULL){/* Transfer control if current result is null */if (*op->resnull)EEO_JUMP(op->d.jump.jumpdone);EEO_NEXT();}EEO_CASE(EEOP_JUMP_IF_NOT_NULL){/* Transfer control if current result is non-null */if (!*op->resnull)EEO_JUMP(op->d.jump.jumpdone);EEO_NEXT();}EEO_CASE(EEOP_JUMP_IF_NOT_TRUE){/* Transfer control if current result is null or false */if (*op->resnull || !DatumGetBool(*op->resvalue))EEO_JUMP(op->d.jump.jumpdone);EEO_NEXT();}EEO_CASE(EEOP_NULLTEST_ISNULL){*op->resvalue = BoolGetDatum(*op->resnull);*op->resnull = false;EEO_NEXT();}EEO_CASE(EEOP_NULLTEST_ISNOTNULL){*op->resvalue = BoolGetDatum(!*op->resnull);*op->resnull = false;EEO_NEXT();}EEO_CASE(EEOP_NULLTEST_ROWISNULL){/* out of line implementation: too large */ExecEvalRowNull(state, op, econtext);EEO_NEXT();}EEO_CASE(EEOP_NULLTEST_ROWISNOTNULL){/* out of line implementation: too large */ExecEvalRowNotNull(state, op, econtext);EEO_NEXT();}/* BooleanTest implementations for all booltesttypes */EEO_CASE(EEOP_BOOLTEST_IS_TRUE){if (*op->resnull){*op->resvalue = BoolGetDatum(false);*op->resnull = false;}/* else, input value is the correct output as well */EEO_NEXT();}EEO_CASE(EEOP_BOOLTEST_IS_NOT_TRUE){if (*op->resnull){*op->resvalue = BoolGetDatum(true);*op->resnull = false;}else*op->resvalue = BoolGetDatum(!DatumGetBool(*op->resvalue));EEO_NEXT();}EEO_CASE(EEOP_BOOLTEST_IS_FALSE){if (*op->resnull){*op->resvalue = BoolGetDatum(false);*op->resnull = false;}else*op->resvalue = BoolGetDatum(!DatumGetBool(*op->resvalue));EEO_NEXT();}EEO_CASE(EEOP_BOOLTEST_IS_NOT_FALSE){if (*op->resnull){*op->resvalue = BoolGetDatum(true);*op->resnull = false;}/* else, input value is the correct output as well */EEO_NEXT();}EEO_CASE(EEOP_PARAM_EXEC){/* out of line implementation: too large */ExecEvalParamExec(state, op, econtext);EEO_NEXT();}EEO_CASE(EEOP_PARAM_EXTERN){/* out of line implementation: too large */ExecEvalParamExtern(state, op, econtext);EEO_NEXT();}EEO_CASE(EEOP_PARAM_CALLBACK){/* allow an extension module to supply a PARAM_EXTERN value */op->d.cparam.paramfunc(state, op, econtext);EEO_NEXT();}EEO_CASE(EEOP_PARAM_SET){/* out of line, unlikely to matter performance-wise */ExecEvalParamSet(state, op, econtext);EEO_NEXT();}EEO_CASE(EEOP_CASE_TESTVAL){/** Normally upper parts of the expression tree have setup the* values to be returned here, but some parts of the system* currently misuse {caseValue,domainValue}_{datum,isNull} to set* run-time data. So if no values have been set-up, use* ExprContext's. This isn't pretty, but also not *that* ugly,* and this is unlikely to be performance sensitive enough to* worry about an extra branch.*/if (op->d.casetest.value){*op->resvalue = *op->d.casetest.value;*op->resnull = *op->d.casetest.isnull;}else{*op->resvalue = econtext->caseValue_datum;*op->resnull = econtext->caseValue_isNull;}EEO_NEXT();}EEO_CASE(EEOP_DOMAIN_TESTVAL){/** See EEOP_CASE_TESTVAL comment.*/if (op->d.casetest.value){*op->resvalue = *op->d.casetest.value;*op->resnull = *op->d.casetest.isnull;}else{*op->resvalue = econtext->domainValue_datum;*op->resnull = econtext->domainValue_isNull;}EEO_NEXT();}EEO_CASE(EEOP_MAKE_READONLY){/** Force a varlena value that might be read multiple times to R/O*/if (!*op->d.make_readonly.isnull)*op->resvalue =MakeExpandedObjectReadOnlyInternal(*op->d.make_readonly.value);*op->resnull = *op->d.make_readonly.isnull;EEO_NEXT();}EEO_CASE(EEOP_IOCOERCE){/** Evaluate a CoerceViaIO node. This can be quite a hot path, so* inline as much work as possible. The source value is in our* result variable.** Also look at ExecEvalCoerceViaIOSafe() if you change anything* here.*/char *str;/* call output function (similar to OutputFunctionCall) */if (*op->resnull){/* output functions are not called on nulls */str = NULL;}else{FunctionCallInfo fcinfo_out;fcinfo_out = op->d.iocoerce.fcinfo_data_out;fcinfo_out->args[0].value = *op->resvalue;fcinfo_out->args[0].isnull = false;fcinfo_out->isnull = false;str = DatumGetCString(FunctionCallInvoke(fcinfo_out));/* OutputFunctionCall assumes result isn't null */Assert(!fcinfo_out->isnull);}/* call input function (similar to InputFunctionCall) */if (!op->d.iocoerce.finfo_in->fn_strict || str != NULL){FunctionCallInfo fcinfo_in;Datum d;fcinfo_in = op->d.iocoerce.fcinfo_data_in;fcinfo_in->args[0].value = PointerGetDatum(str);fcinfo_in->args[0].isnull = *op->resnull;/* second and third arguments are already set up */fcinfo_in->isnull = false;d = FunctionCallInvoke(fcinfo_in);*op->resvalue = d;/* Should get null result if and only if str is NULL */if (str == NULL){Assert(*op->resnull);Assert(fcinfo_in->isnull);}else{Assert(!*op->resnull);Assert(!fcinfo_in->isnull);}}EEO_NEXT();}EEO_CASE(EEOP_IOCOERCE_SAFE){ExecEvalCoerceViaIOSafe(state, op);EEO_NEXT();}EEO_CASE(EEOP_DISTINCT){/** IS DISTINCT FROM must evaluate arguments (already done into* fcinfo->args) to determine whether they are NULL; if either is* NULL then the result is determined. If neither is NULL, then* proceed to evaluate the comparison function, which is just the* type's standard equality operator. We need not care whether* that function is strict. Because the handling of nulls is* different, we can't just reuse EEOP_FUNCEXPR.*/FunctionCallInfo fcinfo = op->d.func.fcinfo_data;/* check function arguments for NULLness */if (fcinfo->args[0].isnull && fcinfo->args[1].isnull){/* Both NULL? Then is not distinct... */*op->resvalue = BoolGetDatum(false);*op->resnull = false;}else if (fcinfo->args[0].isnull || fcinfo->args[1].isnull){/* Only one is NULL? Then is distinct... */*op->resvalue = BoolGetDatum(true);*op->resnull = false;}else{/* Neither null, so apply the equality function */Datum eqresult;fcinfo->isnull = false;eqresult = op->d.func.fn_addr(fcinfo);/* Must invert result of "="; safe to do even if null */*op->resvalue = BoolGetDatum(!DatumGetBool(eqresult));*op->resnull = fcinfo->isnull;}EEO_NEXT();}/* see EEOP_DISTINCT for comments, this is just inverted */EEO_CASE(EEOP_NOT_DISTINCT){FunctionCallInfo fcinfo = op->d.func.fcinfo_data;if (fcinfo->args[0].isnull && fcinfo->args[1].isnull){*op->resvalue = BoolGetDatum(true);*op->resnull = false;}else if (fcinfo->args[0].isnull || fcinfo->args[1].isnull){*op->resvalue = BoolGetDatum(false);*op->resnull = false;}else{Datum eqresult;fcinfo->isnull = false;eqresult = op->d.func.fn_addr(fcinfo);*op->resvalue = eqresult;*op->resnull = fcinfo->isnull;}EEO_NEXT();}EEO_CASE(EEOP_NULLIF){/** The arguments are already evaluated into fcinfo->args.*/FunctionCallInfo fcinfo = op->d.func.fcinfo_data;Datum save_arg0 = fcinfo->args[0].value;/* if either argument is NULL they can't be equal */if (!fcinfo->args[0].isnull && !fcinfo->args[1].isnull){Datum result;/** If first argument is of varlena type, it might be an* expanded datum. We need to ensure that the value passed to* the comparison function is a read-only pointer. However,* if we end by returning the first argument, that will be the* original read-write pointer if it was read-write.*/if (op->d.func.make_ro)fcinfo->args[0].value =MakeExpandedObjectReadOnlyInternal(save_arg0);fcinfo->isnull = false;result = op->d.func.fn_addr(fcinfo);/* if the arguments are equal return null */if (!fcinfo->isnull && DatumGetBool(result)){*op->resvalue = (Datum) 0;*op->resnull = true;EEO_NEXT();}}/* Arguments aren't equal, so return the first one */*op->resvalue = save_arg0;*op->resnull = fcinfo->args[0].isnull;EEO_NEXT();}EEO_CASE(EEOP_SQLVALUEFUNCTION){/** Doesn't seem worthwhile to have an inline implementation* efficiency-wise.*/ExecEvalSQLValueFunction(state, op);EEO_NEXT();}EEO_CASE(EEOP_CURRENTOFEXPR){/* error invocation uses space, and shouldn't ever occur */ExecEvalCurrentOfExpr(state, op);EEO_NEXT();}EEO_CASE(EEOP_NEXTVALUEEXPR){/** Doesn't seem worthwhile to have an inline implementation* efficiency-wise.*/ExecEvalNextValueExpr(state, op);EEO_NEXT();}EEO_CASE(EEOP_ARRAYEXPR){/* too complex for an inline implementation */ExecEvalArrayExpr(state, op);EEO_NEXT();}EEO_CASE(EEOP_ARRAYCOERCE){/* too complex for an inline implementation */ExecEvalArrayCoerce(state, op, econtext);EEO_NEXT();}EEO_CASE(EEOP_ROW){/* too complex for an inline implementation */ExecEvalRow(state, op);EEO_NEXT();}EEO_CASE(EEOP_ROWCOMPARE_STEP){FunctionCallInfo fcinfo = op->d.rowcompare_step.fcinfo_data;Datum d;/* force NULL result if strict fn and NULL input */if (op->d.rowcompare_step.finfo->fn_strict &&(fcinfo->args[0].isnull || fcinfo->args[1].isnull)){*op->resnull = true;EEO_JUMP(op->d.rowcompare_step.jumpnull);}/* Apply comparison function */fcinfo->isnull = false;d = op->d.rowcompare_step.fn_addr(fcinfo);*op->resvalue = d;/* force NULL result if NULL function result */if (fcinfo->isnull){*op->resnull = true;EEO_JUMP(op->d.rowcompare_step.jumpnull);}*op->resnull = false;/* If unequal, no need to compare remaining columns */if (DatumGetInt32(*op->resvalue) != 0){EEO_JUMP(op->d.rowcompare_step.jumpdone);}EEO_NEXT();}EEO_CASE(EEOP_ROWCOMPARE_FINAL){int32 cmpresult = DatumGetInt32(*op->resvalue);RowCompareType rctype = op->d.rowcompare_final.rctype;*op->resnull = false;switch (rctype){/* EQ and NE cases aren't allowed here */case ROWCOMPARE_LT:*op->resvalue = BoolGetDatum(cmpresult < 0);break;case ROWCOMPARE_LE:*op->resvalue = BoolGetDatum(cmpresult <= 0);break;case ROWCOMPARE_GE:*op->resvalue = BoolGetDatum(cmpresult >= 0);break;case ROWCOMPARE_GT:*op->resvalue = BoolGetDatum(cmpresult > 0);break;default:Assert(false);break;}EEO_NEXT();}EEO_CASE(EEOP_MINMAX){/* too complex for an inline implementation */ExecEvalMinMax(state, op);EEO_NEXT();}EEO_CASE(EEOP_FIELDSELECT){/* too complex for an inline implementation */ExecEvalFieldSelect(state, op, econtext);EEO_NEXT();}EEO_CASE(EEOP_FIELDSTORE_DEFORM){/* too complex for an inline implementation */ExecEvalFieldStoreDeForm(state, op, econtext);EEO_NEXT();}EEO_CASE(EEOP_FIELDSTORE_FORM){/* too complex for an inline implementation */ExecEvalFieldStoreForm(state, op, econtext);EEO_NEXT();}EEO_CASE(EEOP_SBSREF_SUBSCRIPTS){/* Precheck SubscriptingRef subscript(s) */if (op->d.sbsref_subscript.subscriptfunc(state, op, econtext)){EEO_NEXT();}else{/* Subscript is null, short-circuit SubscriptingRef to NULL */EEO_JUMP(op->d.sbsref_subscript.jumpdone);}}EEO_CASE(EEOP_SBSREF_OLD)EEO_CASE(EEOP_SBSREF_ASSIGN)EEO_CASE(EEOP_SBSREF_FETCH){/* Perform a SubscriptingRef fetch or assignment */op->d.sbsref.subscriptfunc(state, op, econtext);EEO_NEXT();}EEO_CASE(EEOP_CONVERT_ROWTYPE){/* too complex for an inline implementation */ExecEvalConvertRowtype(state, op, econtext);EEO_NEXT();}EEO_CASE(EEOP_SCALARARRAYOP){/* too complex for an inline implementation */ExecEvalScalarArrayOp(state, op);EEO_NEXT();}EEO_CASE(EEOP_HASHED_SCALARARRAYOP){/* too complex for an inline implementation */ExecEvalHashedScalarArrayOp(state, op, econtext);EEO_NEXT();}EEO_CASE(EEOP_DOMAIN_NOTNULL){/* too complex for an inline implementation */ExecEvalConstraintNotNull(state, op);EEO_NEXT();}EEO_CASE(EEOP_DOMAIN_CHECK){/* too complex for an inline implementation */ExecEvalConstraintCheck(state, op);EEO_NEXT();}EEO_CASE(EEOP_HASHDATUM_SET_INITVAL){*op->resvalue = op->d.hashdatum_initvalue.init_value;*op->resnull = false;EEO_NEXT();}EEO_CASE(EEOP_HASHDATUM_FIRST){FunctionCallInfo fcinfo = op->d.hashdatum.fcinfo_data;/** Save the Datum on non-null inputs, otherwise store 0 so that* subsequent NEXT32 operations combine with an initialized value.*/if (!fcinfo->args[0].isnull)*op->resvalue = op->d.hashdatum.fn_addr(fcinfo);else*op->resvalue = (Datum) 0;*op->resnull = false;EEO_NEXT();}EEO_CASE(EEOP_HASHDATUM_FIRST_STRICT){FunctionCallInfo fcinfo = op->d.hashdatum.fcinfo_data;if (fcinfo->args[0].isnull){/** With strict we have the expression return NULL instead of* ignoring NULL input values. We've nothing more to do after* finding a NULL.*/*op->resnull = true;*op->resvalue = (Datum) 0;EEO_JUMP(op->d.hashdatum.jumpdone);}/* execute the hash function and save the resulting value */*op->resvalue = op->d.hashdatum.fn_addr(fcinfo);*op->resnull = false;EEO_NEXT();}EEO_CASE(EEOP_HASHDATUM_NEXT32){FunctionCallInfo fcinfo = op->d.hashdatum.fcinfo_data;uint32 existinghash;existinghash = DatumGetUInt32(op->d.hashdatum.iresult->value);/* combine successive hash values by rotating */existinghash = pg_rotate_left32(existinghash, 1);/* leave the hash value alone on NULL inputs */if (!fcinfo->args[0].isnull){uint32 hashvalue;/* execute hash func and combine with previous hash value */hashvalue = DatumGetUInt32(op->d.hashdatum.fn_addr(fcinfo));existinghash = existinghash ^ hashvalue;}*op->resvalue = UInt32GetDatum(existinghash);*op->resnull = false;EEO_NEXT();}EEO_CASE(EEOP_HASHDATUM_NEXT32_STRICT){FunctionCallInfo fcinfo = op->d.hashdatum.fcinfo_data;if (fcinfo->args[0].isnull){/** With strict we have the expression return NULL instead of* ignoring NULL input values. We've nothing more to do after* finding a NULL.*/*op->resnull = true;*op->resvalue = (Datum) 0;EEO_JUMP(op->d.hashdatum.jumpdone);}else{uint32 existinghash;uint32 hashvalue;existinghash = DatumGetUInt32(op->d.hashdatum.iresult->value);/* combine successive hash values by rotating */existinghash = pg_rotate_left32(existinghash, 1);/* execute hash func and combine with previous hash value */hashvalue = DatumGetUInt32(op->d.hashdatum.fn_addr(fcinfo));*op->resvalue = UInt32GetDatum(existinghash ^ hashvalue);*op->resnull = false;}EEO_NEXT();}EEO_CASE(EEOP_XMLEXPR){/* too complex for an inline implementation */ExecEvalXmlExpr(state, op);EEO_NEXT();}EEO_CASE(EEOP_JSON_CONSTRUCTOR){/* too complex for an inline implementation */ExecEvalJsonConstructor(state, op, econtext);EEO_NEXT();}EEO_CASE(EEOP_IS_JSON){/* too complex for an inline implementation */ExecEvalJsonIsPredicate(state, op);EEO_NEXT();}EEO_CASE(EEOP_JSONEXPR_PATH){/* too complex for an inline implementation */EEO_JUMP(ExecEvalJsonExprPath(state, op, econtext));}EEO_CASE(EEOP_JSONEXPR_COERCION){/* too complex for an inline implementation */ExecEvalJsonCoercion(state, op, econtext);EEO_NEXT();}EEO_CASE(EEOP_JSONEXPR_COERCION_FINISH){/* too complex for an inline implementation */ExecEvalJsonCoercionFinish(state, op);EEO_NEXT();}EEO_CASE(EEOP_AGGREF){/** Returns a Datum whose value is the precomputed aggregate value* found in the given expression context.*/int aggno = op->d.aggref.aggno;Assert(econtext->ecxt_aggvalues != NULL);*op->resvalue = econtext->ecxt_aggvalues[aggno];*op->resnull = econtext->ecxt_aggnulls[aggno];EEO_NEXT();}EEO_CASE(EEOP_GROUPING_FUNC){/* too complex/uncommon for an inline implementation */ExecEvalGroupingFunc(state, op);EEO_NEXT();}EEO_CASE(EEOP_WINDOW_FUNC){/** Like Aggref, just return a precomputed value from the econtext.*/WindowFuncExprState *wfunc = op->d.window_func.wfstate;Assert(econtext->ecxt_aggvalues != NULL);*op->resvalue = econtext->ecxt_aggvalues[wfunc->wfuncno];*op->resnull = econtext->ecxt_aggnulls[wfunc->wfuncno];EEO_NEXT();}EEO_CASE(EEOP_MERGE_SUPPORT_FUNC){/* too complex/uncommon for an inline implementation */ExecEvalMergeSupportFunc(state, op, econtext);EEO_NEXT();}EEO_CASE(EEOP_SUBPLAN){/* too complex for an inline implementation */ExecEvalSubPlan(state, op, econtext);EEO_NEXT();}/* evaluate a strict aggregate deserialization function */EEO_CASE(EEOP_AGG_STRICT_DESERIALIZE){/* Don't call a strict deserialization function with NULL input */if (op->d.agg_deserialize.fcinfo_data->args[0].isnull)EEO_JUMP(op->d.agg_deserialize.jumpnull);/* fallthrough */}/* evaluate aggregate deserialization function (non-strict portion) */EEO_CASE(EEOP_AGG_DESERIALIZE){FunctionCallInfo fcinfo = op->d.agg_deserialize.fcinfo_data;AggState *aggstate = castNode(AggState, state->parent);MemoryContext oldContext;/** We run the deserialization functions in per-input-tuple memory* context.*/oldContext = MemoryContextSwitchTo(aggstate->tmpcontext->ecxt_per_tuple_memory);fcinfo->isnull = false;*op->resvalue = FunctionCallInvoke(fcinfo);*op->resnull = fcinfo->isnull;MemoryContextSwitchTo(oldContext);EEO_NEXT();}/** Check that a strict aggregate transition / combination function's* input is not NULL.*/EEO_CASE(EEOP_AGG_STRICT_INPUT_CHECK_ARGS){NullableDatum *args = op->d.agg_strict_input_check.args;int nargs = op->d.agg_strict_input_check.nargs;for (int argno = 0; argno < nargs; argno++){if (args[argno].isnull)EEO_JUMP(op->d.agg_strict_input_check.jumpnull);}EEO_NEXT();}EEO_CASE(EEOP_AGG_STRICT_INPUT_CHECK_NULLS){bool *nulls = op->d.agg_strict_input_check.nulls;int nargs = op->d.agg_strict_input_check.nargs;for (int argno = 0; argno < nargs; argno++){if (nulls[argno])EEO_JUMP(op->d.agg_strict_input_check.jumpnull);}EEO_NEXT();}/** Check for a NULL pointer to the per-group states.*/EEO_CASE(EEOP_AGG_PLAIN_PERGROUP_NULLCHECK){AggState *aggstate = castNode(AggState, state->parent);AggStatePerGroup pergroup_allaggs =aggstate->all_pergroups[op->d.agg_plain_pergroup_nullcheck.setoff];if (pergroup_allaggs == NULL)EEO_JUMP(op->d.agg_plain_pergroup_nullcheck.jumpnull);EEO_NEXT();}/** Different types of aggregate transition functions are implemented* as different types of steps, to avoid incurring unnecessary* overhead. There's a step type for each valid combination of having* a by value / by reference transition type, [not] needing to the* initialize the transition value for the first row in a group from* input, and [not] strict transition function.** Could optimize further by splitting off by-reference for* fixed-length types, but currently that doesn't seem worth it.*/EEO_CASE(EEOP_AGG_PLAIN_TRANS_INIT_STRICT_BYVAL){AggState *aggstate = castNode(AggState, state->parent);AggStatePerTrans pertrans = op->d.agg_trans.pertrans;AggStatePerGroup pergroup =&aggstate->all_pergroups[op->d.agg_trans.setoff][op->d.agg_trans.transno];Assert(pertrans->transtypeByVal);if (pergroup->noTransValue){/* If transValue has not yet been initialized, do so now. */ExecAggInitGroup(aggstate, pertrans, pergroup,op->d.agg_trans.aggcontext);/* copied trans value from input, done this round */}else if (likely(!pergroup->transValueIsNull)){/* invoke transition function, unless prevented by strictness */ExecAggPlainTransByVal(aggstate, pertrans, pergroup,op->d.agg_trans.aggcontext,op->d.agg_trans.setno);}EEO_NEXT();}/* see comments above EEOP_AGG_PLAIN_TRANS_INIT_STRICT_BYVAL */EEO_CASE(EEOP_AGG_PLAIN_TRANS_STRICT_BYVAL){AggState *aggstate = castNode(AggState, state->parent);AggStatePerTrans pertrans = op->d.agg_trans.pertrans;AggStatePerGroup pergroup =&aggstate->all_pergroups[op->d.agg_trans.setoff][op->d.agg_trans.transno];Assert(pertrans->transtypeByVal);if (likely(!pergroup->transValueIsNull))ExecAggPlainTransByVal(aggstate, pertrans, pergroup,op->d.agg_trans.aggcontext,op->d.agg_trans.setno);EEO_NEXT();}/* see comments above EEOP_AGG_PLAIN_TRANS_INIT_STRICT_BYVAL */EEO_CASE(EEOP_AGG_PLAIN_TRANS_BYVAL){AggState *aggstate = castNode(AggState, state->parent);AggStatePerTrans pertrans = op->d.agg_trans.pertrans;AggStatePerGroup pergroup =&aggstate->all_pergroups[op->d.agg_trans.setoff][op->d.agg_trans.transno];Assert(pertrans->transtypeByVal);ExecAggPlainTransByVal(aggstate, pertrans, pergroup,op->d.agg_trans.aggcontext,op->d.agg_trans.setno);EEO_NEXT();}/* see comments above EEOP_AGG_PLAIN_TRANS_INIT_STRICT_BYVAL */EEO_CASE(EEOP_AGG_PLAIN_TRANS_INIT_STRICT_BYREF){AggState *aggstate = castNode(AggState, state->parent);AggStatePerTrans pertrans = op->d.agg_trans.pertrans;AggStatePerGroup pergroup =&aggstate->all_pergroups[op->d.agg_trans.setoff][op->d.agg_trans.transno];Assert(!pertrans->transtypeByVal);if (pergroup->noTransValue)ExecAggInitGroup(aggstate, pertrans, pergroup,op->d.agg_trans.aggcontext);else if (likely(!pergroup->transValueIsNull))ExecAggPlainTransByRef(aggstate, pertrans, pergroup,op->d.agg_trans.aggcontext,op->d.agg_trans.setno);EEO_NEXT();}/* see comments above EEOP_AGG_PLAIN_TRANS_INIT_STRICT_BYVAL */EEO_CASE(EEOP_AGG_PLAIN_TRANS_STRICT_BYREF){AggState *aggstate = castNode(AggState, state->parent);AggStatePerTrans pertrans = op->d.agg_trans.pertrans;AggStatePerGroup pergroup =&aggstate->all_pergroups[op->d.agg_trans.setoff][op->d.agg_trans.transno];Assert(!pertrans->transtypeByVal);if (likely(!pergroup->transValueIsNull))ExecAggPlainTransByRef(aggstate, pertrans, pergroup,op->d.agg_trans.aggcontext,op->d.agg_trans.setno);EEO_NEXT();}/* see comments above EEOP_AGG_PLAIN_TRANS_INIT_STRICT_BYVAL */EEO_CASE(EEOP_AGG_PLAIN_TRANS_BYREF){AggState *aggstate = castNode(AggState, state->parent);AggStatePerTrans pertrans = op->d.agg_trans.pertrans;AggStatePerGroup pergroup =&aggstate->all_pergroups[op->d.agg_trans.setoff][op->d.agg_trans.transno];Assert(!pertrans->transtypeByVal);ExecAggPlainTransByRef(aggstate, pertrans, pergroup,op->d.agg_trans.aggcontext,op->d.agg_trans.setno);EEO_NEXT();}EEO_CASE(EEOP_AGG_PRESORTED_DISTINCT_SINGLE){AggStatePerTrans pertrans = op->d.agg_presorted_distinctcheck.pertrans;AggState *aggstate = castNode(AggState, state->parent);if (ExecEvalPreOrderedDistinctSingle(aggstate, pertrans))EEO_NEXT();elseEEO_JUMP(op->d.agg_presorted_distinctcheck.jumpdistinct);}EEO_CASE(EEOP_AGG_PRESORTED_DISTINCT_MULTI){AggState *aggstate = castNode(AggState, state->parent);AggStatePerTrans pertrans = op->d.agg_presorted_distinctcheck.pertrans;if (ExecEvalPreOrderedDistinctMulti(aggstate, pertrans))EEO_NEXT();elseEEO_JUMP(op->d.agg_presorted_distinctcheck.jumpdistinct);}/* process single-column ordered aggregate datum */EEO_CASE(EEOP_AGG_ORDERED_TRANS_DATUM){/* too complex for an inline implementation */ExecEvalAggOrderedTransDatum(state, op, econtext);EEO_NEXT();}/* process multi-column ordered aggregate tuple */EEO_CASE(EEOP_AGG_ORDERED_TRANS_TUPLE){/* too complex for an inline implementation */ExecEvalAggOrderedTransTuple(state, op, econtext);EEO_NEXT();}EEO_CASE(EEOP_LAST){/* unreachable */Assert(false);goto out;}}out:*isnull = state->resnull;return state->resvalue;
}
表格:ExecInterpExpr 中 case 分支汇总
| 操作码 (ExprEvalOp) | 描述 | 主要操作 | 通俗解释(以 SQL 为例) |
|---|---|---|---|
| EEOP_DONE | 结束表达式执行 | 跳转到 out,返回结果 | 表示“age + 10”计算完成,返回结果(如 40)。 |
| EEOP_INNER_FETCHSOME | 从内表获取属性 | slot_getsomeattrs 获取指定字段 | 从内表(如 JOIN 的左表)取 age 值,确保字段可用。 |
| EEOP_OUTER_FETCHSOME | 从外表获取属性 | slot_getsomeattrs 获取指定字段 | 从外表(如 JOIN 的右表)取 age 值,确保字段可用。 |
| EEOP_SCAN_FETCHSOME | 从扫描表获取属性 | slot_getsomeattrs 获取指定字段 | 从当前扫描表(如 users)取 age 值。 |
| EEOP_INNER_VAR | 获取内表字段值 | 从 innerslot 取值 | 直接取内表 age 列的值(如 30)。 |
| EEOP_OUTER_VAR | 获取外表字段值 | 从 outerslot 取值 | 直接取外表 age 列的值。 |
| EEOP_SCAN_VAR | 获取扫描表字段值 | 从 scanslot 取值 | 直接取 users 表 age 列的值。 |
| EEOP_INNER_SYSVAR | 获取内表系统列 | 调用 ExecEvalSysVar | 取内表的系统列(如 ctid),用于元数据操作。 |
| EEOP_OUTER_SYSVAR | 获取外表系统列 | 调用 ExecEvalSysVar | 取外表的系统列(如 oid)。 |
| EEOP_SCAN_SYSVAR | 获取扫描表系统列 | 调用 ExecEvalSysVar | 取 users 表的系统列。 |
| EEOP_WHOLEROW | 获取整行引用 | 调用 ExecEvalWholeRowVar | 取整行(如 users.*),用于 ROW 构造。 |
| EEOP_ASSIGN_INNER_VAR | 赋值内表字段到结果 | 复制 innerslot 值到 resultslot | 将内表 age 值赋给结果列(如 new_age)。 |
| EEOP_ASSIGN_OUTER_VAR | 赋值外表字段到结果 | 复制 outerslot 值到 resultslot | 将外表 age 值赋给结果列。 |
| EEOP_ASSIGN_SCAN_VAR | 赋值扫描表字段到结果 | 复制 scanslot 值到 resultslot | 将 users 表 age 值赋给结果列。 |
| EEOP_ASSIGN_TMP | 赋值临时值到结果 | 复制 state->resvalue 到 resultslot | 将临时计算结果(如 age + 10)存入结果列。 |
| EEOP_ASSIGN_TMP_MAKE_RO | 赋值临时值并设为只读 | 复制并调用 MakeExpandedObjectReadOnlyInternal | 将 age + 10 结果存为只读值,避免修改。 |
| EEOP_CONST | 获取常量值 | 设置 resvalue 和 resnull | 直接返回常量(如 10)用于 age + 10。 |
| EEOP_FUNCEXPR | 调用普通函数 | 调用函数并存储结果 | 执行 UPPER(name),返回大写 name。 |
| EEOP_FUNCEXPR_STRICT | 调用严格函数 | 检查参数非 NULL 后调用 | 执行 SUBSTRING(name, 1, 3),若参数 NULL 则返回 NULL。 |
| EEOP_FUNCEXPR_FUSAGE | 调用带外键函数 | 调用 ExecEvalFuncExprFusage | 处理带外键的函数(如触发器相关)。 |
| EEOP_FUNCEXPR_STRICT_FUSAGE | 调用严格带外键函数 | 调用 ExecEvalFuncExprStrictFusage | 处理严格模式的带外键函数。 |
| EEOP_BOOL_AND_STEP_FIRST | 开始 AND 逻辑 | 重置 anynull | 开始处理 age > 30 AND name = 'John',初始化 NULL 跟踪。 |
| EEOP_BOOL_AND_STEP | AND 逻辑步骤 | 检查 FALSE 或 NULL,短路跳转 | 检查 age > 30,若 FALSE 则跳到结束,返回 FALSE。 |
| EEOP_BOOL_AND_STEP_LAST | 结束 AND 逻辑 | 确定最终结果(TRUE、FALSE、NULL) | 完成 age > 30 AND name = 'John',根据 NULL 返回结果。 |
| EEOP_BOOL_OR_STEP_FIRST | 开始 OR 逻辑 | 重置 anynull | 开始处理 age > 30 OR name = 'John',初始化 NULL 跟踪。 |
| EEOP_BOOL_OR_STEP | OR 逻辑步骤 | 检查 TRUE 或 NULL,短路跳转 | 检查 age > 30,若 TRUE 则跳到结束,返回 TRUE。 |
| EEOP_BOOL_OR_STEP_LAST | 结束 OR 逻辑 | 确定最终结果(TRUE、FALSE、NULL) | 完成 age > 30 OR name = 'John',根据 NULL 返回结果。 |
| EEOP_BOOL_NOT_STEP | NOT 逻辑 | 反转布尔值 | 处理 NOT (age > 30),将 TRUE 变 FALSE 或反之。 |
| EEOP_QUAL | 条件检查 | 检查 FALSE 或 NULL,短路返回 FALSE | 检查 age > 30,若 FALSE 或 NULL 则返回 FALSE。 |
| EEOP_JUMP | 无条件跳转 | 跳转到指定步骤 | 跳到 CASE 语句的下一个分支。 |
| EEOP_JUMP_IF_NULL | NULL 时跳转 | 若结果 NULL 则跳转 | 若 age 为 NULL,跳过 age + 10 的计算。 |
| EEOP_JUMP_IF_NOT_NULL | 非 NULL 时跳转 | 若结果非 NULL 则跳转 | 若 age 非 NULL,继续计算 age + 10。 |
| EEOP_JUMP_IF_NOT_TRUE | 非 TRUE 时跳转 | 若结果 NULL 或 FALSE 则跳转 | 若 age > 30 为 FALSE,跳到 CASE 的 ELSE 分支。 |
| EEOP_NULLTEST_ISNULL | 检查是否 NULL | 返回是否为 NULL | 处理 age IS NULL,返回 TRUE 或 FALSE。 |
| EEOP_NULLTEST_ISNOTNULL | 检查是否非 NULL | 返回是否非 NULL | 处理 age IS NOT NULL,返回 TRUE 或 FALSE。 |
| EEOP_NULLTEST_ROWISNULL | 检查行是否 NULL | 调用 ExecEvalRowNull | 检查 ROW(age, name) 是否全 NULL。 |
| EEOP_NULLTEST_ROWISNOTNULL | 检查行是否非 NULL | 调用 ExecEvalRowNotNull | 检查 ROW(age, name) 是否有非 NULL 值。 |
| EEOP_BOOLTEST_IS_TRUE | 检查是否 TRUE | 返回 TRUE 或 FALSE | 处理 age > 30 IS TRUE,若 NULL 则返回 FALSE。 |
| EEOP_BOOLTEST_IS_NOT_TRUE | 检查是否非 TRUE | 返回非 TRUE 结果 | 处理 age > 30 IS NOT TRUE,若 NULL 则返回 TRUE。 |
| EEOP_BOOLTEST_IS_FALSE | 检查是否 FALSE | 返回 FALSE 或 TRUE | 处理 age > 30 IS FALSE,若 NULL 则返回 FALSE。 |
| EEOP_BOOLTEST_IS_NOT_FALSE | 检查是否非 FALSE | 返回非 FALSE 结果 | 处理 age > 30 IS NOT FALSE,若 NULL 则返回 TRUE。 |
| EEOP_PARAM_EXEC | 获取执行参数 | 调用 ExecEvalParamExec | 取子查询参数,如 (SELECT id FROM t WHERE x = age)。 |
| EEOP_PARAM_EXTERN | 获取外部参数 | 调用 ExecEvalParamExtern | 取查询参数,如 $1 在 age > $1。 |
| EEOP_PARAM_CALLBACK | 获取扩展参数 | 调用扩展模块的 paramfunc | 允许扩展模块提供参数值。 |
| EEOP_PARAM_SET | 设置参数值 | 调用 ExecEvalParamSet | 设置动态参数值。 |
| EEOP_CASE_TESTVAL | 获取 CASE 测试值 | 从 op 或 econtext 取值 | 取 CASE age WHEN 30 THEN ... 的 age 值。 |
| EEOP_DOMAIN_TESTVAL | 获取域测试值 | 从 op 或 econtext 取值 | 取域类型的值,类似 CASE 测试值。 |
| EEOP_MAKE_READONLY | 设置只读值 | 调用 MakeExpandedObjectReadOnlyInternal | 将 name 值设为只读,防止修改。 |
| EEOP_IOCOERCE | 类型转换(I/O) | 调用输入/输出函数 | 处理 age::text,将 age 转为字符串。 |
| EEOP_IOCOERCE_SAFE | 安全类型转换 | 调用 ExecEvalCoerceViaIOSafe | 安全处理 age::text,避免错误。 |
| EEOP_DISTINCT | IS DISTINCT FROM | 检查 NULL 或调用比较函数 | 处理 age IS DISTINCT FROM 30,比较是否不同。 |
| EEOP_NOT_DISTINCT | IS NOT DISTINCT FROM | 检查 NULL 或调用比较函数 | 处理 age IS NOT DISTINCT FROM 30,比较是否相等。 |
| EEOP_NULLIF | NULLIF 表达式 | 检查相等返回 NULL 或第一个值 | 处理 NULLIF(name, 'John'),若相等返回 NULL。 |
| EEOP_SQLVALUEFUNCTION | SQL 值函数 | 调用 ExecEvalSQLValueFunction | 处理 CURRENT_DATE,返回当前日期。 |
| EEOP_CURRENTOFEXPR | CURRENT OF 表达式 | 调用 ExecEvalCurrentOfExpr | 处理 WHERE CURRENT OF cursor,取游标位置。 |
| EEOP_NEXTVALUEEXPR | 序列函数 | 调用 ExecEvalNextValueExpr | 处理 nextval('seq'),获取序列值。 |
| EEOP_ARRAYEXPR | 数组构造 | 调用 ExecEvalArrayExpr | 处理 ARRAY[1, 2, 3],构造数组。 |
| EEOP_ARRAYCOERCE | 数组类型转换 | 调用 ExecEvalArrayCoerce | 处理 ARRAY[1, 2]::text[],转换数组元素类型。 |
| EEOP_ROW | 行构造 | 调用 ExecEvalRow | 处理 ROW(age, name),构造行值。 |
| EEOP_ROWCOMPARE_STEP | 行比较步骤 | 调用比较函数,检查相等 | 处理 ROW(age, name) > ROW(30, 'John'),逐字段比较。 |
| EEOP_ROWCOMPARE_FINAL | 行比较最终结果 | 根据比较类型返回结果 | 完成 ROW(age, name) > ROW(30, 'John'),返回 TRUE/FALSE。 |
| EEOP_MINMAX | GREATEST/LEAST | 调用 ExecEvalMinMax | 处理 GREATEST(age, 18),返回最大值。 |
| EEOP_FIELDSELECT | 字段选择 | 调用 ExecEvalFieldSelect | 处理 user.address.city,取复合类型字段。 |
| EEOP_FIELDSTORE_DEFORM | 分解字段存储 | 调用 ExecEvalFieldStoreDeForm | 分解复合类型字段以更新。 |
| EEOP_FIELDSTORE_FORM | 构造字段存储 | 调用 ExecEvalFieldStoreForm | 构造复合类型字段。 |
| EEOP_SBSREF_SUBSCRIPTS | 下标预检查 | 检查下标是否 NULL | 处理 array[1],检查下标有效性。 |
| EEOP_SBSREF_OLD, EEOP_SBSREF_ASSIGN, EEOP_SBSREF_FETCH | 数组下标操作 | 调用 subscriptfunc | 处理 array[1] 的获取或赋值。 |
| EEOP_CONVERT_ROWTYPE | 行类型转换 | 调用 ExecEvalConvertRowtype | 处理 ROW(age, name)::new_type,转换行类型。 |
| EEOP_SCALARARRAYOP | 数组操作 | 调用 ExecEvalScalarArrayOp | 处理 age IN (30, 40),检查值是否在数组中。 |
| EEOP_HASHED_SCALARARRAYOP | 哈希数组操作 | 调用 ExecEvalHashedScalarArrayOp | 优化 age IN (30, 40),用哈希加速。 |
| EEOP_DOMAIN_NOTNULL | 域非 NULL 检查 | 调用 ExecEvalConstraintNotNull | 检查域类型值是否非 NULL。 |
| EEOP_DOMAIN_CHECK | 域约束检查 | 调用 ExecEvalConstraintCheck | 检查域类型值是否符合约束。 |
| EEOP_HASHDATUM_SET_INITVAL | 设置哈希初始值 | 设置初始哈希值 | 为哈希计算(如 hash_agg)设置初始值。 |
| EEOP_HASHDATUM_FIRST | 首次哈希计算 | 调用哈希函数 | 计算 age 的首次哈希值,用于分组。 |
| EEOP_HASHDATUM_FIRST_STRICT | 严格首次哈希 | 检查 NULL 后计算哈希 | 若 age 为 NULL,返回 NULL,否则计算哈希。 |
| EEOP_HASHDATUM_NEXT32 | 后续哈希计算 | 旋转并组合哈希值 | 继续计算哈希,合并多个值(如多列分组)。 |
| EEOP_HASHDATUM_NEXT32_STRICT | 严格后续哈希 | 检查 NULL 后组合哈希 | 若输入 NULL,返回 NULL,否则合并哈希。 |
| EEOP_XMLEXPR | XML 表达式 | 调用 ExecEvalXmlExpr | 处理 XMLELEMENT(name, 'data'),构造 XML。 |
| EEOP_JSON_CONSTRUCTOR | JSON 构造 | 调用 ExecEvalJsonConstructor | 处理 JSON_OBJECT('key': age),构造 JSON。 |
| EEOP_IS_JSON | JSON 谓词 | 调用 ExecEvalJsonIsPredicate | 处理 json_col IS JSON,检查是否为 JSON。 |
| EEOP_JSONEXPR_PATH | JSON 路径表达式 | 调用 ExecEvalJsonExprPath | 处理 JSON_VALUE(json_col, '$.path'),提取 JSON 值。 |
| EEOP_JSONEXPR_COERCION | JSON 类型转换 | 调用 ExecEvalJsonCoercion | 处理 JSON 值的类型转换。 |
| EEOP_JSONEXPR_COERCION_FINISH | 完成 JSON 类型转换 | 调用 ExecEvalJsonCoercionFinish | 完成 JSON 类型转换的收尾工作。 |
| EEOP_AGGREF | 聚合函数引用 | 从 econtext 取预计算聚合值 | 处理 SUM(age),返回预计算的和。 |
| EEOP_GROUPING_FUNC | 分组函数 | 调用 ExecEvalGroupingFunc | 处理 GROUPING(age),返回分组标识。 |
| EEOP_WINDOW_FUNC | 窗口函数 | 从 econtext 取预计算值 | 处理 ROW_NUMBER() OVER (...),返回窗口函数结果。 |
| EEOP_MERGE_SUPPORT_FUNC | MERGE 支持函数 | 调用 ExecEvalMergeSupportFunc | 处理 MERGE 语句中的支持函数。 |
| EEOP_SUBPLAN | 子查询 | 调用 ExecEvalSubPlan | 处理 WHERE id IN (SELECT ...),执行子查询。 |
| EEOP_AGG_STRICT_DESERIALIZE | 严格聚合反序列化 | 检查 NULL 后调用反序列化 | 处理严格聚合的反序列化,若输入 NULL 则跳转。 |
| EEOP_AGG_DESERIALIZE | 聚合反序列化 | 调用反序列化函数 | 处理聚合状态的反序列化。 |
| EEOP_AGG_STRICT_INPUT_CHECK_ARGS | 严格聚合输入检查(参数) | 检查参数非 NULL | 检查 SUM(age) 的输入参数是否 NULL。 |
| EEOP_AGG_STRICT_INPUT_CHECK_NULLS | 严格聚合输入检查(NULL 数组) | 检查 NULL 数组 | 检查 SUM(age) 的输入是否 NULL。 |
| EEOP_AGG_PLAIN_PERGROUP_NULLCHECK | 聚合组状态检查 | 检查组状态是否 NULL | 检查 SUM(age) 的组状态是否存在。 |
| EEOP_AGG_PLAIN_TRANS_INIT_STRICT_BYVAL | 严格值传递聚合初始化 | 初始化或调用值传递转换 | 初始化 SUM(age) 的严格值传递状态。 |
| EEOP_AGG_PLAIN_TRANS_STRICT_BYVAL | 严格值传递聚合 | 调用值传递转换 | 处理 SUM(age) 的严格值传递转换。 |
| EEOP_AGG_PLAIN_TRANS_BYVAL | 值传递聚合 | 调用值传递转换 | 处理 SUM(age) 的值传递转换。 |
| EEOP_AGG_PLAIN_TRANS_INIT_STRICT_BYREF | 严格引用传递聚合初始化 | 初始化或调用引用传递转换 | 初始化 SUM(age) 的严格引用传递状态。 |
| EEOP_AGG_PLAIN_TRANS_STRICT_BYREF | 严格引用传递聚合 | 调用引用传递转换 | 处理 SUM(age) 的严格引用传递转换。 |
| EEOP_AGG_PLAIN_TRANS_BYREF | 引用传递聚合 | 调用引用传递转换 | 处理 SUM(age) 的引用传递转换。 |
| EEOP_AGG_PRESORTED_DISTINCT_SINGLE | 单列预排序去重 | 调用 ExecEvalPreOrderedDistinctSingle | 处理 SELECT DISTINCT age,检查单列去重。 |
| EEOP_AGG_PRESORTED_DISTINCT_MULTI | 多列预排序去重 | 调用 ExecEvalPreOrderedDistinctMulti | 处理 SELECT DISTINCT age, name,检查多列去重。 |
| EEOP_AGG_ORDERED_TRANS_DATUM | 单列有序聚合 | 调用 ExecEvalAggOrderedTransDatum | 处理单列有序聚合转换。 |
| EEOP_AGG_ORDERED_TRANS_TUPLE | 多列有序聚合 | 调用 ExecEvalAggOrderedTransTuple | 处理多列有序聚合转换。 |
| EEOP_LAST | 不可达 | 抛出错误 | 表示代码错误,正常情况下不会到达。 |
说明与重要性
- 表格内容:表格覆盖了
ExecInterpExpr中的所有case分支,列出操作码、功能描述、主要操作,以及基于SQL示例(如age + 10、SUM(age))的通俗解释。每个操作码对应一种执行步骤,支持从简单常量到复杂聚合的处理。 - SQL 示例:以
SELECT name, age + 10 AS new_age FROM users WHERE age > 30为基础,扩展到其他场景(如SUM(age)、CASE、JSON_OBJECT),直观展示每步的作用。 - 通俗解释:用“取值”“计算”“检查”等简单语言描述,确保易于理解。例如,
EEOP_CONST就是“直接返回10”,EEOP_FUNCEXPR是“执行加法age + 10”。 - 重要性:
ExecInterpExpr是PostgreSQL执行SQL表达式的核心,直接决定了查询结果的计算效率和正确性。它通过跳转表和优化路径(如短路求值)提高性能,同时支持复杂表达式的灵活处理,是连接计划准备和结果输出的关键环节。
总结
PostgreSQL 的表达式执行过程通过 ExecInitExprRec、ExprEvalPushStep、ExecReadyExpr、ExecReadyInterpretedExpr、ExecInterpExprStillValid 和 ExecInterpExpr 协同完成,从解析 SQL 表达式到生成并执行指令序列。ExecInitExprRec 将表达式(如 age + 10)分解为操作码序列,ExprEvalPushStep 将这些指令存入 ExprState。ExecReadyExpr 决定执行方式(JIT 或解释执行),并调用 ExecReadyInterpretedExpr 准备解释执行环境,优化简单表达式并设置初始检查函数 ExecInterpExprStillValid。ExecInterpExprStillValid 验证表达式有效性后调用 ExecInterpExpr,后者逐条执行指令,计算最终结果。这些函数共同确保 SQL 表达式的正确、高效执行,贯穿从计划生成到结果返回的整个流程。
[SQL 查询解析]|| (解析 SQL: SELECT name, age + 10 AS new_age FROM users WHERE age > 30)v
[ExecInitExprRec]| (生成执行步骤: 为 age + 10 创建指令,如“取 age”“加 10”)|----> [ExprEvalPushStep]| (添加步骤到 ExprState: 将“取 age”“加 10”写入“计划书”)| || v| [ExprState.steps] (存储指令序列)|v
[ExecReadyExpr]| (决定执行方式: 尝试 JIT 或解释执行)|----> [jit_compile_expr] (尝试 JIT 编译 age + 10,若成功直接执行)|----> [ExecReadyInterpretedExpr]| (准备解释执行: 检查计划书,优化简单表达式)| || v| [ExecInitInterpreter] (初始化解释器环境)| [Set evalfunc to ExecInterpExprStillValid] (设置首次检查函数)| [Optimize simple cases] (为简单表达式如 age 设置快速路径)| [Enable direct threading] (若启用,优化跳转地址)| [Set evalfunc_private to ExecInterpExpr] (默认解释执行函数)|v
[ExecInterpExprStillValid]| (首次执行检查: 验证 age 列有效性)|----> [CheckExprStillValid] (检查表结构是否匹配)|----> [Set evalfunc to evalfunc_private] (设置实际执行函数)|----> [Call evalfunc]| || v| [ExecInterpExpr]| (执行表达式: 逐条处理指令,计算 age + 10)| || v| [dispatch_table] (跳转表,分派指令如 EEOP_CONST、EEOP_FUNCEXPR)| [Process steps] (执行“取 age”“加 10”,返回 40)|v
[Return Result] (返回 age + 10 的结果,如 40)
graph TDA[SQL 查询解析<br>解析 `SELECT name, age + 10 AS new_age FROM users WHERE age > 30`] --> B[ExecInitExpr<br>初始化 ExprState,为 `age + 10` 创建执行计划书]B -->|检查 node 是否为 NULL| C{node == NULL?}C -->|是| D[Return NULL<br>返回空,无需处理表达式]C -->|否| E[makeNode ExprState<br>创建空的 ExprState,记录表达式和上下文]E --> F[ExecCreateExprSetupSteps<br>准备执行环境,确保 `age` 列可读取]E --> G[ExecInitExprRec<br>生成操作码序列,如 `取 age`、`加 10`]G --> H[ExprEvalPushStep<br>将指令 `取 age`、`加 10` 存入 ExprState.steps]H --> I[ExprState.steps<br>存储指令序列,如 EEOP_INNER_VAR、EEOP_CONST]E --> J[ExprEvalPushStep<br>添加 EEOP_DONE 指令,表示表达式完成]J --> IE --> K[ExecReadyExpr<br>决定执行方式,尝试 JIT 或解释执行]K -->|尝试 JIT| L[jit_compile_expr<br>编译 `age + 10` 为机器代码,若成功直接执行]K -->|解释执行| M[ExecReadyInterpretedExpr<br>准备解释执行,检查计划书并优化]M --> N[ExecInitInterpreter<br>初始化解释器环境,准备内存和函数]M --> O[Check steps validity<br>验证 ExprState.steps 不为空且以 EEOP_DONE 结束]M --> P[Set evalfunc to ExecInterpExprStillValid<br>设置首次检查函数]M --> Q[Optimize simple expressions<br>为简单表达式如 `age` 设置快速路径]M --> R[Enable direct threading<br>若启用,优化指令跳转地址]M --> S[Set evalfunc_private to ExecInterpExpr<br>设置默认解释执行函数]M --> T[ExecInterpExprStillValid<br>检查 `age` 列有效性并执行表达式]T --> U[CheckExprStillValid<br>验证 `age` 列与表结构匹配]T --> V[Set evalfunc to evalfunc_private<br>设置实际执行函数,如 ExecInterpExpr]T --> W[ExecInterpExpr<br>逐条执行指令,计算 `age + 10`]W --> X[dispatch_table<br>分派指令,如 EEOP_CONST、EEOP_FUNCEXPR]W --> Y[Process steps<br>执行 `取 age=30`、`加 10`,得到 40]W --> Z[Return Result<br>返回 `age + 10` 的结果,如 40]L --> Z
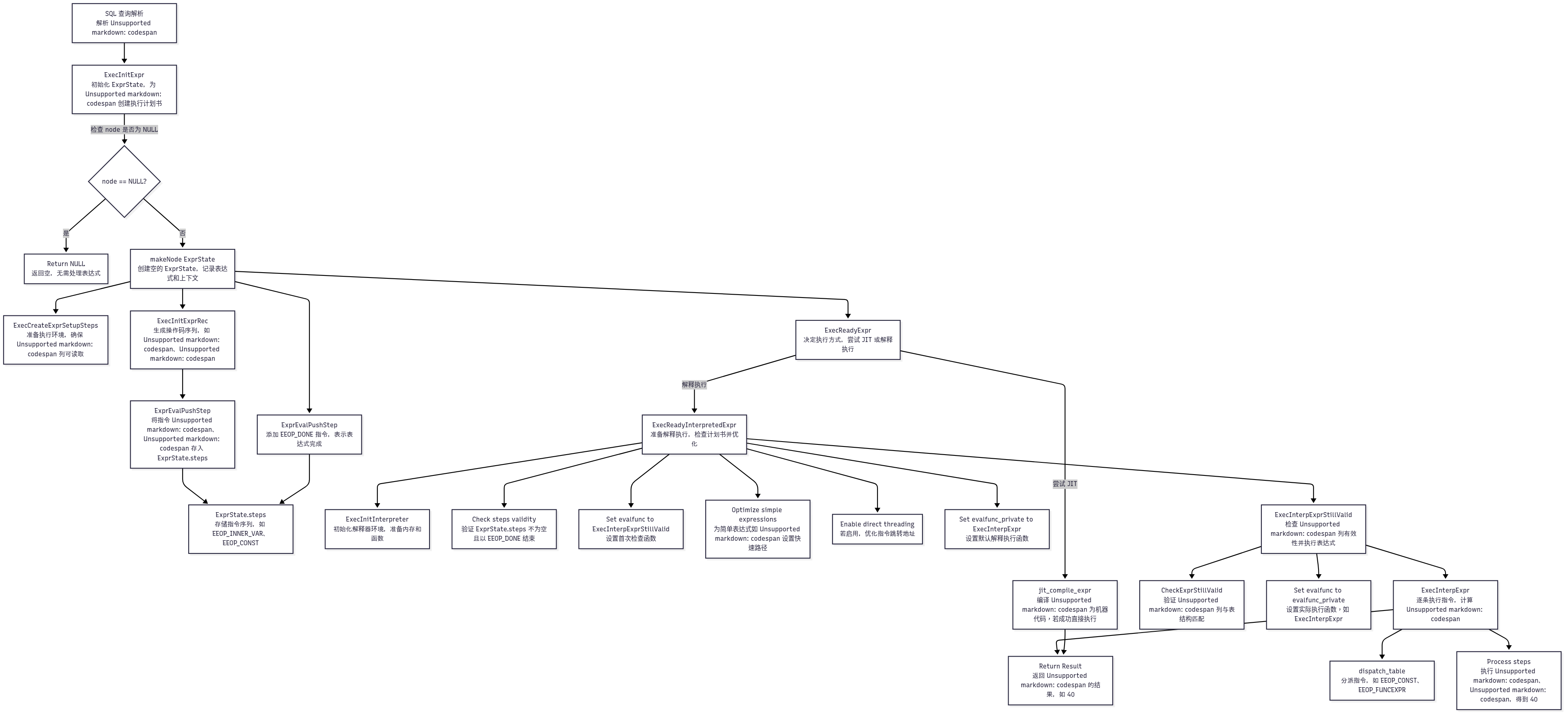
参考文档:
- Postgresql源码(85)查询执行——表达式解析器分析(select 1+1如何执行)
- Postgresql源码(130)ExecInterpExpr转换为IR的流程