Java 的即时编译器(JIT)优化编译探测技术
我们来深入解析 Java 的即时编译器(JIT)优化。这是 Java 能从“解释执行”的慢语言演变为高性能语言的关键所在。
一、核心概念:解释执行 vs. 编译执行
Java 程序最初是通过 解释器 (Interpreter) 来执行的。解释器逐条读取字节码,逐条翻译成机器码执行。优点是启动快,但缺点是执行慢。
即时编译 (Just-In-Time Compilation, JIT) 是为了解决解释器效率低下而诞生的技术。它的核心思想是:将频繁执行的代码(称为“热点代码”)编译成本地机器码,并进行了深度优化,然后缓存起来。下次执行时直接运行机器码,效率得到极大提升。
二、分层编译 (Tiered Compilation)
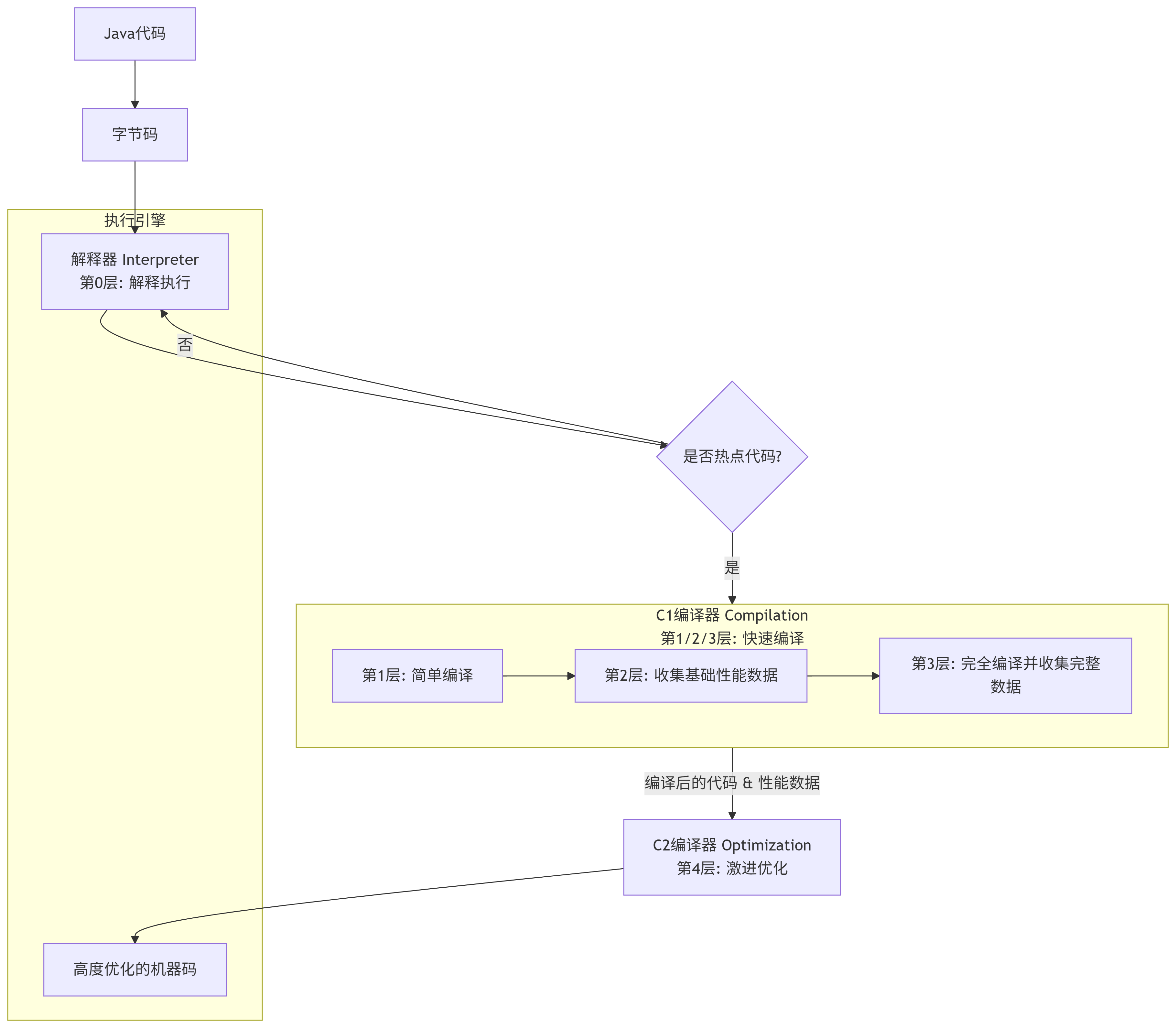
现代 JVM(如 HotSpot)采用了一种分层编译的策略,结合了不同编译器的优点,以实现启动速度和峰值性能的最佳平衡。它包含了多个编译层级:
| 层级 | 描述 | 目的 | 编译器 |
|---|---|---|---|
| 第0层:解释执行 | 所有代码最初都由此开始。 | 最快的启动速度。 | 解释器 |
| 第1层:C1 简单编译 | 开启少量优化(如方法内联的基础版),不收集性能监控数据。 | 以最小代价提升执行速度。 | C1 (Client Compiler) |
| 第2层:C1 受限编译 | 开启更多优化,收集简单的性能监控数据(如方法调用次数、循环回边次数)。 | 为C2编译收集数据,同时提供更好的性能。 | C1 |
| 第3层:C1 完全编译 | 开启所有优化,收集所有性能监控数据。 | 提供良好的性能,并收集完整数据供C2使用。 | C1 |
| 第4层:C2 编译 | 使用第2层和第3层收集的数据,进行激进的全方位优化。 | 提供最高的峰值性能。 | C2 (Server Compiler) |
工作流程如下图所示,代码会沿着解释器 -> C1 -> C2 的路径逐步优化:
图表
C1 与 C2 编译器的区别:
| 特性 | C1 编译器 (Client Compiler) | C2 编译器 (Server Compiler) |
|---|---|---|
| 编译速度 | 快 | 慢 |
| 优化程度 | 低,简单可靠的优化 | 高,激进的全方位优化 |
| 性能分析 | 收集少量数据 | 依赖 C1 收集的丰富数据 |
| 目标 | 优化启动速度,适用于 GUI 客户端 | 优化峰值性能,适用于服务器端 |
现代默认策略:在 JDK 8 及以后,64位服务端模式下,分层编译默认是开启的(-XX:+TieredCompilation)。这种策略使得程序在启动阶段能快速通过C1编译获得性能提升,随后在后台利用C2编译进行极致优化,完美兼顾了启动速度和长期运行的性能。
三、热点代码探测 (Hot Spot Code Detection)
JIT 并不会编译所有代码,只会编译那些“热点”代码。如何判定一段代码是不是热点呢?
HotSpot 虚拟机采用了基于计数器的热点探测。它为每个方法甚至每个代码块建立计数器,统计执行次数。
方法调用计数器 (Invocation Counter):
统计方法被调用的次数。
默认阈值在 Client 模式下是 1500 次,在 Server 模式下是 10000 次(
-XX:CompileThreshold)。超过这个阈值,就会触发 JIT 编译。
回边计数器 (Back Edge Counter):
统计循环体的循环次数(“回边”指字节码中跳回循环起始位置的指令)。
它的存在是为了识别循环密集的热点代码。
触发编译的阈值由
-XX:OnStackReplacePercentage等参数间接控制。
热度衰减 (Counter Decay):如果一段时间内方法的调用次数仍未达到阈值,方法的计数器值会减少一半。这个过程称为方法调用的热度衰减。这确保了“热点”是那些持续被调用的代码,而非只是曾经被频繁调用过的代码。
四、核心优化技术
JIT 编译器在编译热点代码时,会进行大量优化。以下是几个最关键的技术:
1. 方法内联 (Method Inlining)
这是最重要、最基础的优化。它将被调用方法的代码直接“复制”到调用者方法中,从而避免了一次真实的方法调用(创建新的栈帧、参数传递、跳转等)。
优点:
消除了方法调用的开销。
为其他优化创造了条件。因为代码在一个方法内了,编译器可以在此基础上做更多的优化,如死代码消除。
例子:
java
// 内联前 int a = Math.max(10, 20); // 需要调用方法// 内联后(效果等同于) int a = 10 > 20 ? 10 : 20; // 直接使用逻辑,无方法调用
限制:主要由方法体积决定。默认情况下,小于 35 字节(
-XX:MaxInlineSize)的方法会被直接内联,更大的方法则可能根据其“热度”和“成本”来决定是否内联。
2. 逃逸分析 (Escape Analysis)
这是 JIT 编译器进行其他高级优化的基础。它通过分析对象的作用域,来判断一个对象是否会在方法之外被访问到(即是否“逃逸”)。
三种逃逸状态:
不逃逸 (NoEscape):对象仅在当前方法中使用。
方法逃逸 (ArgEscape):对象作为参数传递给其他方法。
线程逃逸 (GlobalEscape):对象被赋值给类变量或可以被其他线程访问到(如赋值给
static字段)。
基于逃逸分析,JIT 可以做以下三种优化:
栈上分配 (Stack Allocation):
如果确定一个对象不会逃逸出方法,那么这个对象就可以直接在栈上分配内存,而不是在堆上。
好处:对象随栈帧出栈而自动销毁,极大减轻了 GC 的压力。
标量替换 (Scalar Replacement):
“标量”是指无法再分解的数据,如基本数据类型(
int,long等)。如果一個对象不会逃逸,并且可以被进一步分解,那么 JIT 不会创建这个对象,而是直接创建它的成员变量。
例子:
java
// 原始代码 Point point = new Point(10, 20); System.out.println(point.x + point.y);// 经过标量替换后(效果等同于) int x = 10, y = 20; // 直接在栈上分配两个int,没有创建Point对象 System.out.println(x + y);
同步消除 (Lock Elision):
如果一个对象被确定不会线程逃逸,即不会被其他线程访问到,那么对这个对象施加的同步措施(如
synchronized)就可以被安全地消除掉。
注意:逃逸分析本身是一个相对耗时的过程,但它的收益(尤其是标量替换和同步消除)是巨大的。
总结与启示
| 技术 | 核心思想 | 带来的好处 |
|---|---|---|
| 分层编译 | C1 保启动,C2 保性能,分工协作 | 兼顾应用的启动速度和峰值性能 |
| 热点探测 | 谁热我就优化谁 | 将有限的编译资源用在刀刃上,效率最大化 |
| 方法内联 | 用空间换时间,消除方法调用 | 消除了调用开销,是后续更多优化的基础 |
| 逃逸分析 | 分析对象作用域 | 栈上分配(减GC压力)、标量替换(减内存占用)、同步消除(提并发性能) |
对开发者的启示:
不要过早优化:JIT 已经非常智能,很多我们手动的“优化”(如循环展开)可能编译器做得更好。
编写“JIT友好”的代码:
保持方法小巧:有助于方法内联。
尽量限制变量的作用域(如使用局部变量而非成员变量):有助于逃逸分析进行优化。
避免不必要的同步:万一逃逸分析失败,同步就会成为真正的性能开销。
理解原理:理解这些优化原理,有助于我们诊断性能问题。例如,通过
-XX:+PrintCompilation查看哪些方法被编译了,通过-XX:+PrintInlining查看内联情况。