YOLO系列目标检测模型演进与YOLOv13深度解析
YOLO系列目标检测模型演进与YOLOv13深度解析
1. 引言
YOLO (You Only Look Once) 系列自诞生以来,便以其卓越的速度与精度平衡,成为实时目标检测领域的标杆。从最初的开创性工作到如今的YOLOv13,该系列模型不断推陈出新,在架构设计、计算效率和检测性能上持续突破。本文将梳理YOLO系列的关键演进路径,并重点剖析最新成员YOLOv13所引入的革命性技术——超图增强的自适应视觉感知。
论文链接
代码链接
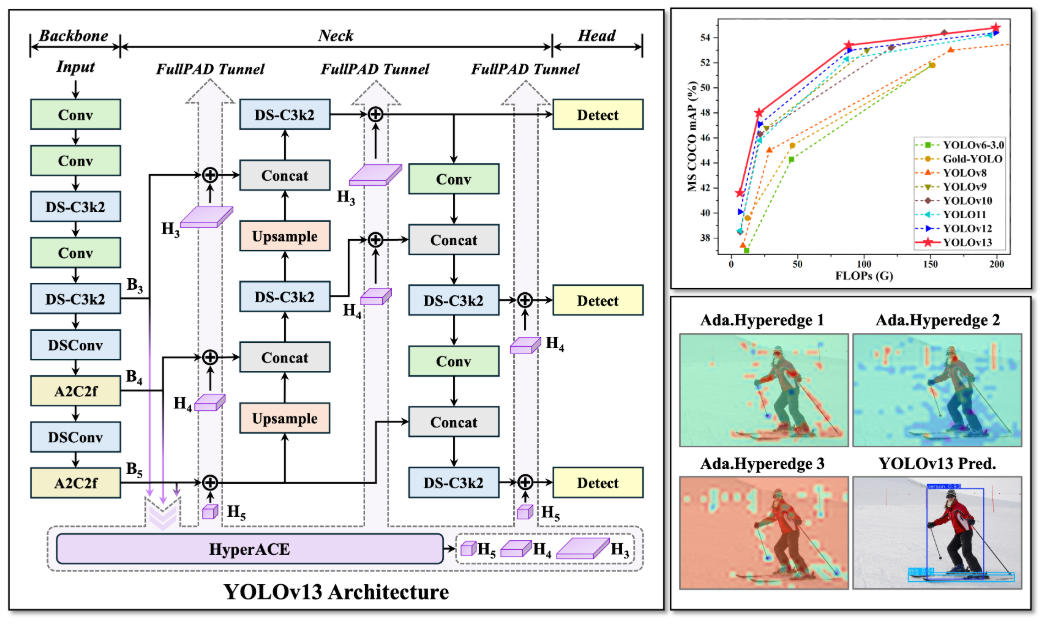
2. YOLO系列演进简史
YOLO系列的发展并非一蹴而就,而是经历了多个关键阶段的迭代优化:
- 早期阶段 (YOLOv1-v8):奠定了“One-Stage”检测器的基础,通过将检测任务视为单一的回归问题,实现了前所未有的推理速度。后续版本(如v3, v5, v8)主要在主干网络(Backbone)、特征金字塔网络(Neck)和检测头(Head)的设计上进行精细化改进,例如引入残差连接、CSP结构、Anchor-Free机制等,不断提升模型的精度和鲁棒性。
- 轻量化与部署优化 (YOLOv9 & YOLOv10):这一阶段的焦点转向了模型的轻量化和端到端部署的流畅性。研究者们致力于设计更精简、计算量更小的骨干网络,使得YOLO模型能够在资源受限的边缘设备(如手机、嵌入式设备)上高效运行,同时简化了从训练到部署的流程。
- 模块化与精细化 (YOLO11):YOLO11在保持经典“Backbone-Neck-Head”模块化设计的同时,进行了内部组件的升级。它用效率更高的
C3k2单元替换了原有的C2f模块,并创新性地引入了部分空间注意力卷积块 (C2PSA, Convolutional Block with Partial Spatial Attention)。这一改进显著增强了模型对小目标和被遮挡目标的检测能力,解决了目标检测中的两大经典难题。 - 注意力机制融合 (YOLOv12):作为YOLO11的继任者,YOLOv12标志着注意力机制在YOLO架构中的全面集成。通过引入更强大的注意力模块,模型能够更智能地聚焦于图像中的关键区域,进一步提升了检测精度,尤其是在复杂背景下的表现。
3. YOLOv13:超图增强的自适应视觉感知
YOLOv13代表了YOLO系列的最新前沿,其核心创新在于引入了超图增强的自适应视觉感知 (Hypergraph-Enhanced Adaptive Visual Perception)。这一理念旨在突破传统卷积神经网络在建模复杂、高阶视觉关系上的局限。
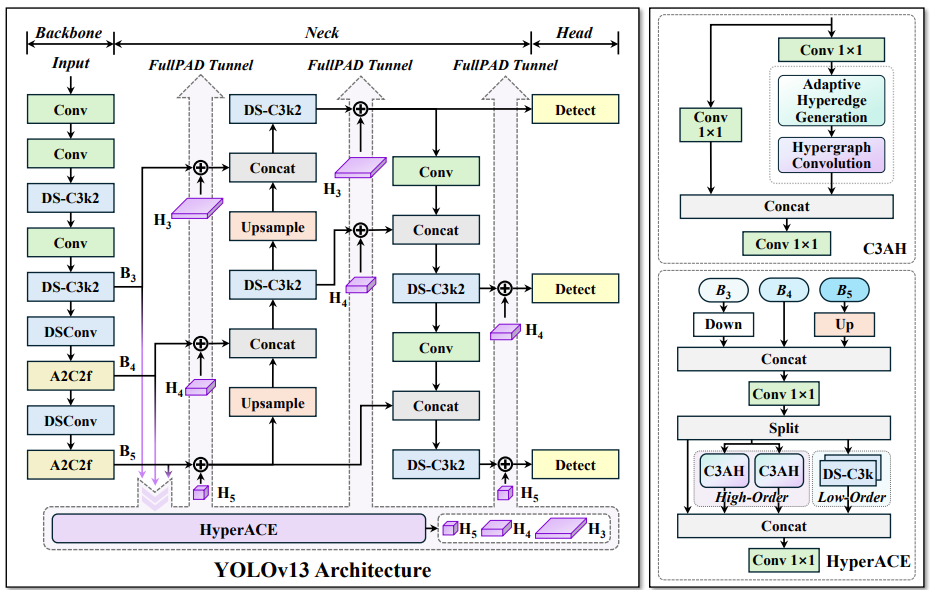
3.1 核心架构组件
根据提供的架构图,YOLOv13的架构在延续模块化设计的基础上,引入了多个关键新组件:
-
Backbone (骨干网络):
- DS-C3k2: 深度可分离(Depthwise Separable)版本的C3k2模块,旨在减少计算量和参数,同时保持特征提取能力。
- A2C2f: 一种新型的注意力增强模块,可能结合了自注意力(Self-Attention)或通道注意力机制,用于在骨干网络早期阶段就捕获重要的全局上下文信息。
-
Neck (颈部网络):
-
继续使用
DS-C3k2进行特征融合。 -
引入了FullPAD Tunnel结构。虽然具体实现细节未完全展示,但“Tunnel”一词暗示这是一种跨层级或跨尺度的信息传递通道,可能用于更有效地融合来自不同层级(B3, B4, B5)的特征。
-
核心创新: HyperACE模块 。这是YOLOv13的灵魂所在,全称为Hypergraph-Adaptive Convolutional Enhancement(超图自适应卷积增强)。它由以下几个子模块构成:
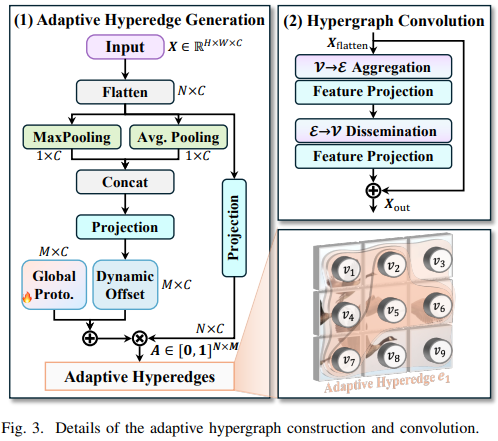
- Hyper Graph Generation (超图生成): 分析输入特征,构建一个超图(Hypergraph)结构。与普通图(Graph)中一条边只连接两个节点不同,超图的一条超边(Hyperedge)可以连接多个节点,从而能更自然地建模多个像素或特征点之间的高阶关系。
- Adaptive Hyper Convolution (自适应超图卷积): 在生成的超图结构上进行卷积操作。这种卷积不再是传统的网格状卷积,而是沿着超边进行,能够自适应地聚合具有复杂关联的特征。
- C3AH (C3 with Adaptive Hypergraph): 一个集成了自适应超图卷积的瓶颈模块,用于在网络中更深层次地应用超图感知能力。
- High-Order Local Perception (高阶局部感知): 强调模型不仅关注局部邻域,还能通过超图捕捉局部区域内的高阶交互。
-
-
Head (检测头):
- 采用多尺度检测头(Detect),分别处理来自不同层级的特征图(H3, H4, H5),以检测不同大小的目标。
- 检测头的输入特征经过了HyperACE模块的增强,包含了更丰富、更具判别力的上下文信息。
3.2 技术优势与意义
YOLOv13的核心价值在于其HyperACE模块所实现的“超图增强自适应视觉感知”:
- 建模高阶关系:传统的CNN擅长捕捉局部空间相关性,但在处理目标部件间、目标与背景间、多个目标间的复杂、非局部、高阶依赖关系时存在不足。超图提供了一种天然的数学工具来建模这种“一对多”或“多对多”的关系,使模型能理解更复杂的视觉场景。
- 自适应感知:模型能够根据输入内容动态地构建超图结构并进行卷积,这意味着它对不同场景、不同目标具有自适应的感知能力,而非依赖固定的卷积核。
- 提升复杂场景性能:这项技术有望在拥挤场景、严重遮挡、小目标群、不规则形状目标等极具挑战性的检测任务上取得显著性能提升,因为它能更好地理解目标的整体结构和上下文。
- 理论创新:将超图理论引入主流的目标检测框架,是一次重要的理论与实践结合的创新,为计算机视觉领域开辟了新的研究方向。
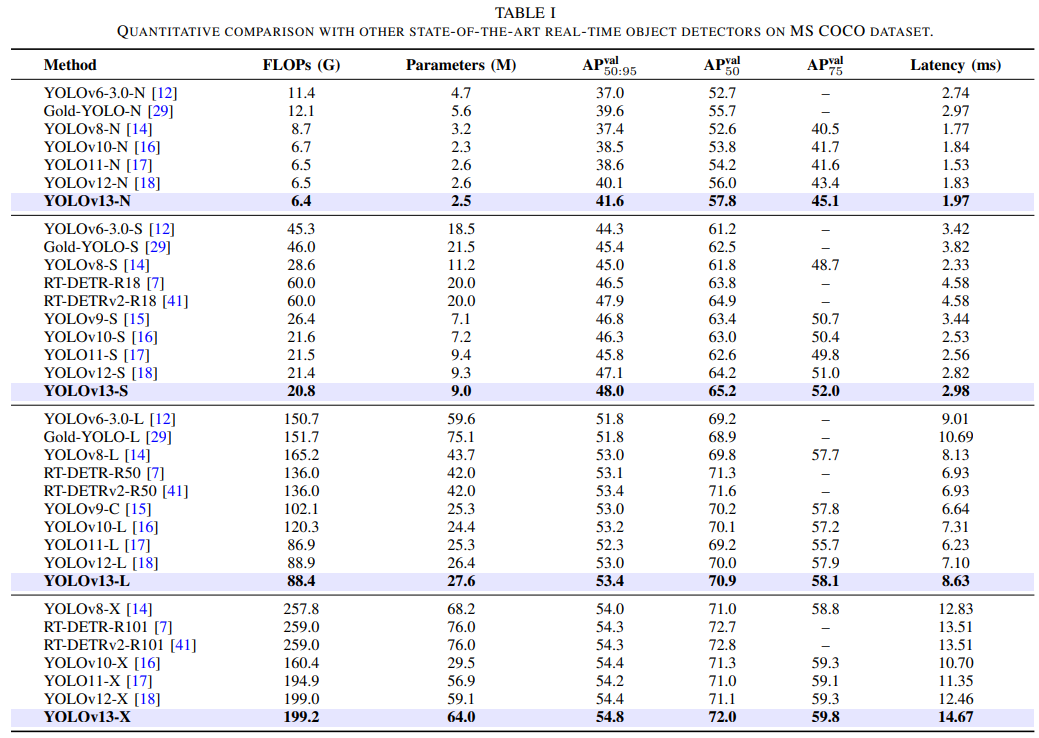
4. 总结
从YOLOv9/v10的轻量化,到YOLO11的精细化注意力,再到YOLOv12的全面注意力融合,YOLO系列始终站在技术前沿。而YOLOv13则迈出了更具颠覆性的一步,通过引入“超图增强的自适应视觉感知”,将目标检测的范式从传统的网格卷积,推向了能够理解和建模高阶视觉关系的新时代。尽管其具体实现细节和性能指标有待论文全文公布,但其架构设计理念已展现出巨大的潜力,预示着实时目标检测技术即将迎来新一轮的性能飞跃。

5.实现
1.安装依赖
【图像算法 - 01】保姆级深度学习环境搭建入门指南:硬件选型 + CUDA/cuDNN/Miniconda/PyTorch/Pycharm 安装全流程(附版本匹配秘籍+文末有视频讲解)
(有了上面环境的链接,下面的可不要)
wget https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.3/flash_attn-2.7.3+cu11torch2.2cxx11abiFALSE-cp311-cp311-linux_x86_64.whl
conda create -n yolov13 python=3.11
conda activate yolov13
pip install -r requirements.txt
pip install -e .
2.验证
YOLOv13-N、YOLOv13-S、 YOLOv13-L 、YOLOv13-X
from ultralytics import YOLO
model = YOLO('yolov13{n/s/l/x}.pt') # Replace with the desired model scale
3.训练
from ultralytics import YOLOmodel = YOLO('yolov13n.yaml')# Train the model
results = model.train(data='coco.yaml',epochs=600, batch=256, imgsz=640,scale=0.5, # S:0.9; L:0.9; X:0.9mosaic=1.0,mixup=0.0, # S:0.05; L:0.15; X:0.2copy_paste=0.1, # S:0.15; L:0.5; X:0.6device="0,1,2,3",
)# Evaluate model performance on the validation set
metrics = model.val('coco.yaml')# Perform object detection on an image
results = model("path/to/your/image.jpg")
results[0].show()4.预测
from ultralytics import YOLOmodel = YOLO('yolov13{n/s/l/x}.pt') # Replace with the desired model scale
model.predict()
多线程推理
from threading import Thread
from ultralytics import YOLOdef thread_safe_predict(model, image_path):"""Performs thread-safe prediction on an image using a locally instantiated YOLO model."""model = YOLO(model)results = model.predict(image_path)# Process results# Starting threads that each have their own model instance
Thread(target=thread_safe_predict, args=("yolov13n.pt", "image1.jpg")).start()
Thread(target=thread_safe_predict, args=("yolov13n.pt", "image2.jpg")).start()
视频推理
import cv2from ultralytics import YOLO# Load the YOLO model
model = YOLO("yolov13n.pt")# Open the video file
video_path = "20250727_035028.mp4"
cap = cv2.VideoCapture(video_path)# Loop through the video frames
while cap.isOpened():# Read a frame from the videosuccess, frame = cap.read()if success:# Run YOLO inference on the frameresults = model(frame)# Visualize the results on the frameannotated_frame = results[0].plot()# Display the annotated framecv2.imshow("YOLO Inference", annotated_frame)# Break the loop if 'q' is pressedif cv2.waitKey(1) & 0xFF == ord("q"):breakelse:# Break the loop if the end of the video is reachedbreak# Release the video capture object and close the display window
cap.release()
cv2.destroyAllWindows()
5.导出
from ultralytics import YOLO
model = YOLO('yolov13{n/s/l/x}.pt') # Replace with the desired model scale
model.export(format="engine", half=True) # or format="onnx"