ICCV 2025 | 首次引入Flash Attention,轻量SR窗口扩至32×32还不卡!
本文针对 Transformer 在高效图像**超分辨率(Super-Resolution, SR)**应用中的高计算开销问题,提出了一种创新的解决方案。研究发现,self-attention 机制在不同层之间存在特征提取的重复性,这为优化提供了契机。
基于此,论文设计了一个名为卷积注意力(Convolutional Attention, ConvAttn)的模块,它通过一个共享的大核(large kernel, LK)卷积和动态生成的卷积核,来模拟 self-attention 的长距离依赖建模和实例依赖加权能力。这种设计显著减少了对内存密集型 self-attention 的依赖。此外,本文首次成功地将Flash Attention技术引入轻量级SR领域,解决了扩大注意力窗口带来的内存瓶颈,使得窗口尺寸能扩展至32×32,从而在大幅降低延迟和内存消耗的同时,显著提升了模型性能。最终构建的网络(ESC)在保持 Transformer 强大表征能力和数据扩展性的同时,实现了卓越的效率与性能平衡。
另外,我整理了ICCV 2025计算机视觉相关论文+源码,感兴趣的可以自取,希望能帮到你!
一、论文基本信息

基本信息
- 论文标题:Emulating Self-attention with Convolution for Efficient Image Super-Resolution
- 作者:Dongheon Lee, Seokju Yun, Youngmin Ro
- 作者单位:Machine Intelligence Laboratory, University of Seoul, Korea
- 代码链接:https://github.com/dslisleedh/ESC
- 论文链接:https://arxiv.org/pdf/2503.06671
摘要精炼
本文旨在解决 Transformer 在图像超分辨率任务中因 self-attention 机制导致的高计算开销和内存瓶颈。核心技术贡献是提出了一个名为 Convolutional Attention (ConvAttn) 的模块,该模块通过一个共享的13x13大核卷积和动态生成的3x3**深度可分离卷积(depth-wise convolution, DWC)**核,高效地模拟了 self-attention 的长距离建模与实例依赖加权能力。同时,论文创新性地集成了 Flash Attention 技术,以克服在轻量级SR模型中扩大注意力窗口尺寸的内存限制,成功将窗口扩展至32×32。基于这些创新,所提出的 ESC 网络在 Urban100 (×4) 数据集上,相较于 HiT-SRF 模型,PSNR 提升了0.27 dB,同时延迟和内存使用分别降低了3.7倍和6.2倍。
这表明,即便大部分 self-attention 被替换,模型依然能保持 Transformer 的核心优势,实现了性能与效率的显著提升。
二、研究背景与相关工作
研究背景
图像超分辨率(SR)技术在高清多媒体内容消费和生成模型领域的需求日益增长,其实际部署效果成为研究焦点。Transformer 模型因其出色的长距离依赖捕获能力,在SR任务上展现了超越 CNN 的性能优势。然而,Transformer 的核心组件 self-attention 存在严重的内存访问开销,尤其是在需要处理大尺寸特征图的SR架构中。
例如,轻量级模型 SwinIR-light 虽然浮点运算(FLOPs)和参数量远低于CNN,但实际推理延迟和内存占用却高出数倍,这极大地阻碍了其在资源受限设备上的应用。本文的初步分析发现,self-attention 在相邻层中提取的特征和注意力图高度相似,表明其计算存在冗余。这启发了本研究的核心思路:用更高效的模块替代部分 self-attention,以在不牺牲性能的前提下解决效率瓶颈。
相关工作
相关工作主要分为三类。第一类是传统的 CNN 方法,它们通过堆叠卷积层提取局部特征,但通常受限于感受野大小,且容易过参数化。第二类是基于 Transformer 的方法,它们通过窗口化或通道化 self-attention 来降低计算量,但在处理大分辨率图像时,内存访问问题依然严峻。一些工作尝试通过跨层共享注意力图来提升效率,但仍需计算完整的注意力矩阵。第三类是新兴的替代方案,如大核 CNN 和状态空间模型(State-Space Models, SSM)。
这些方法旨在模仿 Transformer 的优势,但前者在注入实例依赖性方面不够高效,后者在适应二维图像时需要引入额外的复杂机制。本文工作旨在结合 self-attention 和卷积的优点,并通过 Flash Attention 从根本上解决内存瓶颈,提供一个更简洁高效的方案。
三、主要贡献与创新
- 提出高效模拟机制:证明了精心设计的卷积模块 (ConvAttn) 可以有效替代大部分 self-attention 层,在显著提升模型效率(降低延迟和内存)的同时,保留了 Transformer 的长距离建模能力、数据可扩展性等核心优势。
- 首次集成 Flash Attention:首次将 Flash Attention 成功应用于轻量级SR任务,解决了 self-attention 内存开销的瓶颈,使得在不增加过多内存占用的情况下,能将注意力窗口尺寸扩大至32×32,从而显著提升了模型性能。
- 构建高效且强大的SR网络:基于上述创新,提出的 ESC 网络在多个基准测试中超越了现有的轻量级 Transformer 和 CNN 模型,实现了更优的性能-效率权衡,充分发掘了 Transformer 在轻量级SR任务中的潜力。
四、研究方法与原理
总体框架与核心思想
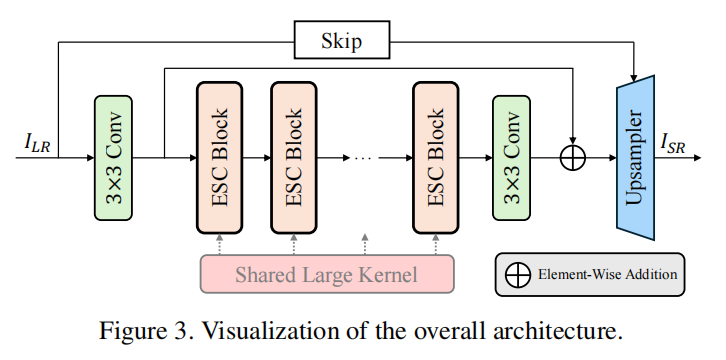
本文提出的网络 ESC 整体架构如图3所示,其核心思想是**“以卷积模拟自注意力,实现性能与效率的权衡”**。它并未完全抛弃 self-attention,而是采用一种混合策略:在每个 ESC Block 的起始位置保留一个标准的 self-attention 层以捕捉复杂的上下文信息,而在后续层级则用更轻量的 ConvAttn 模块来替代。
这种设计基于“self-attention在深层网络中存在功能冗余”的观察,通过用高效的卷积操作来“模拟”和“延续”初始 self-attention 提取的长距离依赖,从而在大幅降低计算成本的同时,维持网络的强大表征能力。全局共享的大核(LK)保证了长距离信息的持续交互,而逐层动态生成的卷积核(DK)则保留了对输入内容的适应性。
关键实现与评估原理
关键实现细节
-
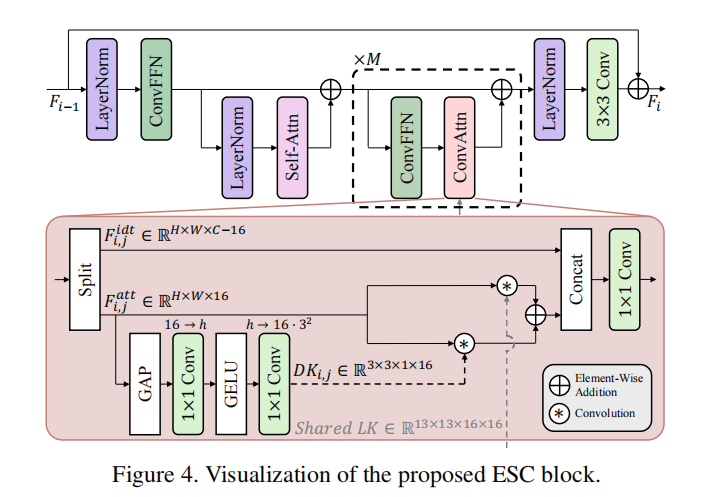
ESC Block 结构: 如图4所示,每个 ESC Block 首先通过一个窗口大小为32×32的 self-attention 层处理输入特征。为了应对大窗口带来的高内存消耗,该层采用了 Flash Attention 进行优化,这是将大窗口 self-attention 应用于轻量SR的关键。随后,Block 内会堆叠 M 个 ConvAttn 模块,用于高效地延续和提炼特征。
-
Convolutional Attention (ConvAttn) 模块: 这是方法的核心。对于输入特征,它首先在通道维度上进行分割,仅将一小部分通道(本文为16个)用于注意力计算。其工作机制可概括为以下公式:
Fatti,j,Fidti,j=Split16:C−16(FCFi,j),DKi,j=Convup1×1(ϕ(Convdown1×1(GAP(Fatti,j)))),Fresi,j=(Fatti,j⊛DKi,j)+(Fatti,j⊛LK),Ffusei,j=Convfuse1×1(Concat(Fresi,j,Fidti,j)) \begin{aligned} F_{\text{att}_{i,j}}, F_{\text{idt}_{i,j}} &= \text{Split}_{16:C-16}(F_{\text{CF}_{i,j}}), \\ DK_{i,j} &= \text{Conv}_{\text{up}}^{1\times1}(\phi(\text{Conv}_{\text{down}}^{1\times1}(\text{GAP}(F_{\text{att}_{i,j}})))), \\ F_{\text{res}_{i,j}} &= (F_{\text{att}_{i,j}} \circledast DK_{i,j}) + (F_{\text{att}_{i,j}} \circledast LK), \\ F_{\text{fuse}_{i,j}} &= \text{Conv}_{\text{fuse}}^{1\times1}(\text{Concat}(F_{\text{res}_{i,j}}, F_{\text{idt}_{i,j}})) \end{aligned} Fatti,j,Fidti,jDKi,jFresi,jFfusei,j=Split16:C−16(FCFi,j),=Convup1×1(ϕ(Convdown1×1(GAP(Fatti,j)))),=(Fatti,j⊛DKi,j)+(Fatti,j⊛LK),=Convfuse1×1(Concat(Fresi,j,Fidti,j))- 长距离依赖: 通过一个在整个网络中共享的13×13大核(LK)卷积实现,有效降低了参数量和优化难度。
- 实例依赖加权: 通过一个轻量级的网络动态生成一个3×3的深度可分离卷积核(DK),模拟 self-attention 的输入自适应性。
- 参数高效变体 (ESC-FP): 对于需要极致压缩FLOPs和参数的场景,论文提出了LK的分解形式,进一步降低了计算成本:
Fresi,j=(Fatti,j⊛LKc)⊛(ZP(DKi,j)+LKs) F_{\text{res}_{i,j}} = (F_{\text{att}_{i,j}} \circledast LK_c) \circledast (\text{ZP}(DK_{i,j}) + LK_s) Fresi,j=(Fatti,j⊛LKc)⊛(ZP(DKi,j)+LKs)
核心评估原理与指标
- 核心评估指标:
- 性能指标: PSNR (峰值信噪比) 和 SSIM (结构相似性指数),这是图像复原任务中最常用的客观评价标准。
- 效率指标: Latency (ms)、Memory Usage (mb)、FLOPs (G) 和 #Params (K),用于全面衡量模型的实际部署效率和资源消耗。
- 评估原理: 通过在多个标准数据集上与主流的 CNN、Transformer 及 SSM 模型进行全面的性能和效率对比,验证所提方法 ESC 的优越性。此外,通过消融实验验证各组件(LK, DK, Flash Attention)的有效性。
五、实验结果与分析
实验设置
- 数据集:
- 训练: 主要使用 DIV2K 数据集。在数据扩展性实验中,使用了 DFLIP (DIV2K+Flickr2K+LSDIR+DiverSeg-IP) 数据集。
- 评测: Set5, Set14, B100, Urban100, Manga109。
- 评估指标: PSNR, SSIM, Latency, Memory Usage, #FLOPs, #Params。
- 对比基线: 涵盖了 CNN (RCAN, RDN), Transformer (SwinIR-lt, ELAN-lt, ATD-lt, HiT-SRF) 和 SSM (MambaIR-lt, MambaIRV2-lt) 等多种代表性轻量级SR模型。
- 关键超参:
- ESC-light: 3个ESC Block,每个Block包含5个ConvAttn模块。
- Self-attention窗口大小: 32×32。
- ConvAttn中共享大核大小: 13×13。
核心实验与结论
【核心实验】:经典SR任务在DIV2K数据集上的性能与效率对比(如表2所示)
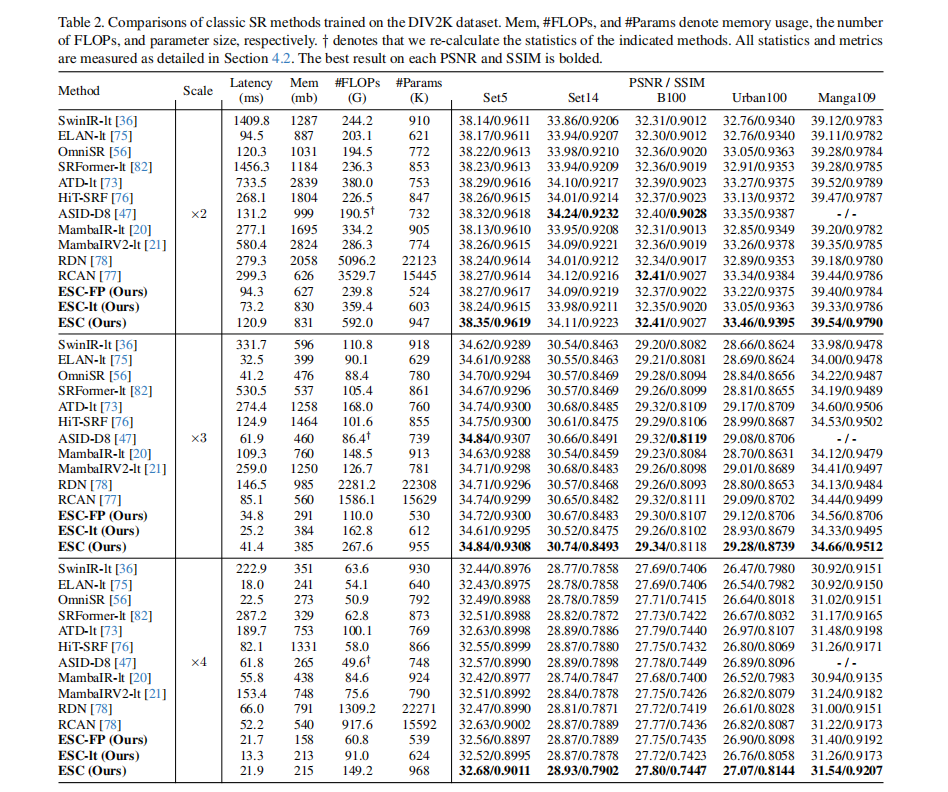
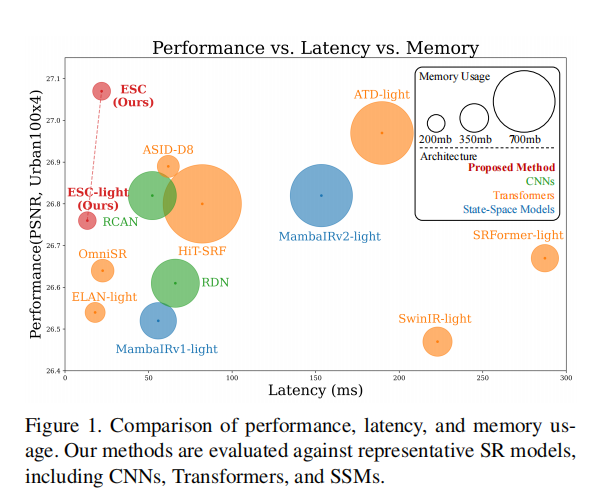
- 实验目的: 该实验旨在验证所提出的ESC模型及其变体(ESC-light, ESC-FP)相较于当前最先进的轻量级SR方法,是否能在性能和效率(尤其是延迟和内存)方面取得更优的平衡。
- 关键结果:
- ESC vs. 高性能Transformer: 在Urban100×4数据集上,ESC模型比ATD-light模型PSNR高出0.1dB,而推理速度快8.7倍。
- ESC vs. 高效率Transformer: 在Urban100×4数据集上,ESC模型比HiT-SRF模型PSNR高出0.27 dB,同时延迟和内存使用分别降低了3.7倍和6.2倍。
- ESC-light vs. ELAN-light: 在Manga109×4数据集上,ESC-light模型比ELAN-light快1.4倍,同时PSNR提升了0.34dB。
- 作者结论: 实验结果有力地证明,通过用精心设计的ConvAttn模块替代大部分self-attention,模型不仅没有损失,反而获得了更强的表征能力,同时显著降低了实际部署中的延迟和内存开销。这验证了本文方法在实现SOTA性能和高效率之间取得了卓越的平衡。
六、论文结论与启示
总结
本文成功地解决了 Transformer 在轻量级图像超分辨率任务中面临的严重内存开销问题。通过观察到 self-attention 机制在层间的计算冗余,论文提出了一种名为 ESC 的高效网络架构。其核心是 ConvAttn 模块,该模块巧妙地利用共享大核卷积与动态卷积来模拟 self-attention 的关键特性,从而在保留 Transformer 长距离建模能力的同时大幅提升了效率。
此外,论文开创性地将 Flash Attention 技术引入轻量级SR,使得采用32×32的大注意力窗口成为可能,进一步提升了模型性能。大量的实验证明,ESC 在性能、速度和内存占用上均优于现有的多种轻量级SR模型,展现了其作为新一代高效SR架构的巨大潜力。
展望
论文的结论部分主要聚焦于对本文工作的总结与成果陈述,未明确指出未来的具体研究方向。然而,从其成功实践中可以得到启示:
- 混合架构的潜力: 结合不同类型算子(如self-attention与卷积)的优势,根据其在网络不同深度的功能特性进行差异化设计,是构建高效模型的有效途径。
- 系统级优化: 将底层计算库(如Flash Attention)的优化与网络结构设计相结合,能够突破传统模型设计的瓶颈,实现之前难以达到的性能-效率权衡。