【论文阅读】小模型是智能体的未来
引言
最新刷到了一篇Nvidia团队在六月发布的一篇论文,主要提出了一个观点:小模型是智能体的未来。
论文标题:Small Language Models are the Future of Agentic AI
论文地址:https://arxiv.org/abs/2506.02153
看了下原文,一来是想看看这种行业趋势预测类型的文章是如何论述的;二来是看到Nvidia这个行业巨头对未来的某些看法。
以下是该文章的内容总结概括。
1. 背景与问题
-
智能体 AI(Agentic AI) 的快速兴起:超过一半的大型 IT 企业已在使用 AI 智能体,市场规模预计到 2034 年将达 2000 亿美元。
-
目前的主流做法:几乎所有智能体系统都依赖 大型语言模型(LLMs),通过云端 API 统一调用。
-
存在的问题:
- LLM 部署和推理成本高昂(2024 年云基础设施投资达 570 亿美元,市场仅 56 亿)。
- 智能体的大多数任务是 重复、范围有限、非对话型的,用 LLM 处理显得过度。
2. 核心主张
作者提出:
-
小语言模型(SLMs,Small Language Models, 通常 <10B 参数)比 LLM 更适合大部分智能体应用。
-
具体理由:
- 能力足够(V1)
- 操作适配性更强(V2)
- 经济性更优(V3)
-
结论:SLM 是智能体 AI 的未来,LLM 将逐步退居辅助地位。
3. 具体论据
3.1. 能力足够(A1)
-
SLMs 已能媲美旧一代 LLM:
- Microsoft Phi-2 (2.7B):推理和代码生成 ≈ 30B 模型,速度快 15 倍。
- Phi-3 Small (7B):可对标 70B 同代模型。
- DeepSeek-R1-Distill (1.5–8B):部分任务超越 GPT-4o、Claude 3.5。
- RETRO-7.5B:外部知识库增强,性能 ≈ GPT-3(175B),参数量减少 25 倍。
-
推理增强:小模型可通过 自一致性、工具增强 在数学/代码推理上达到或超过大模型。
-
结论:智能体子任务大多是窄域的,SLM 已能胜任。
3.2. 经济性更佳(A2)
- 推理成本:7B 模型比 70–175B 模型便宜 10–30 倍。
- 微调成本:LoRA/DoRA 等 PEFT 方法让定制化仅需数小时 GPU 计算。
- 边缘部署:ChatRTX 等系统表明消费级 GPU 就能运行实时 SLM,离线可用,提升隐私。
- 参数利用率:LLM 的大部分参数在推理中并未激活,效率浪费更严重;SLM 更“紧凑”。
- 系统模块化:采用多个 SLM 专家模型(“乐高式”组合)比用单一 LLM 更灵活。
3.3. 灵活性更强(A3)
- 小模型训练和适配成本低,便于快速更新和迭代。
- 更符合本地合规和隐私要求。
- 民主化效应:降低门槛,让中小企业和个人也能开发智能体,推动多样化和创新。
3.4. 智能体任务的局限性(A4–A5)
- 智能体往往只用到语言模型的极小子集功能(如工具调用、结构化输出)。
- 这些任务对格式严格,不能容忍 LLM 的偶发“幻觉”。
- 定制化的 SLM 更容易保持稳定的行为和输出格式。
3.5. 智能体系统天然异构性(A6)
-
智能体架构允许多模型协作:
- 简单任务用 SLM。
- 高复杂度推理再调用 LLM。
-
未来趋势是 SLM 优先,LLM 辅助。
3.6. 智能体交互能生成高价值数据(A7)
- 智能体交互本身就是生成训练数据的来源。
- 可以逐步用这些数据训练专门的 SLM,替代原本依赖 LLM 的部分。
4. 反对意见与回应
1.LLM 在语言理解上始终更强(AV1)
- 反驳:SLM 可以通过 任务分解、微调、推理增强 达到所需水平。
2.集中化的 LLM 推理更便宜(AV2)
- 反驳:SLM 部署成本在下降,推理框架(如 NVIDIA Dynamo)提升了灵活性。
3.行业惯性(AV3)
- 现有投资和工具链都押注 LLM,导致生态惯性。
- 作者认为 SLM 的优势足以逐步改变格局。
5. 当前障碍
- B1:巨额资本投入 LLM 基础设施(570 亿美元)。
- B2:SLM 评估体系仍沿用 LLM 通用基准,不匹配实际智能体任务。
- B3:SLM 缺乏市场宣传,知名度低。
6. 解决方案:LLM → SLM 转换算法
1.数据收集:记录智能体的输入、输出、工具调用日志。
2.数据清洗:去除隐私和敏感信息。
3.任务聚类:识别常见任务模式。
4.SLM 选择:为不同任务选择合适的候选模型。
5.专门化微调:用收集的数据定制 SLM。
6.迭代优化:不断更新路由器和模型,提升性能。
我的看法
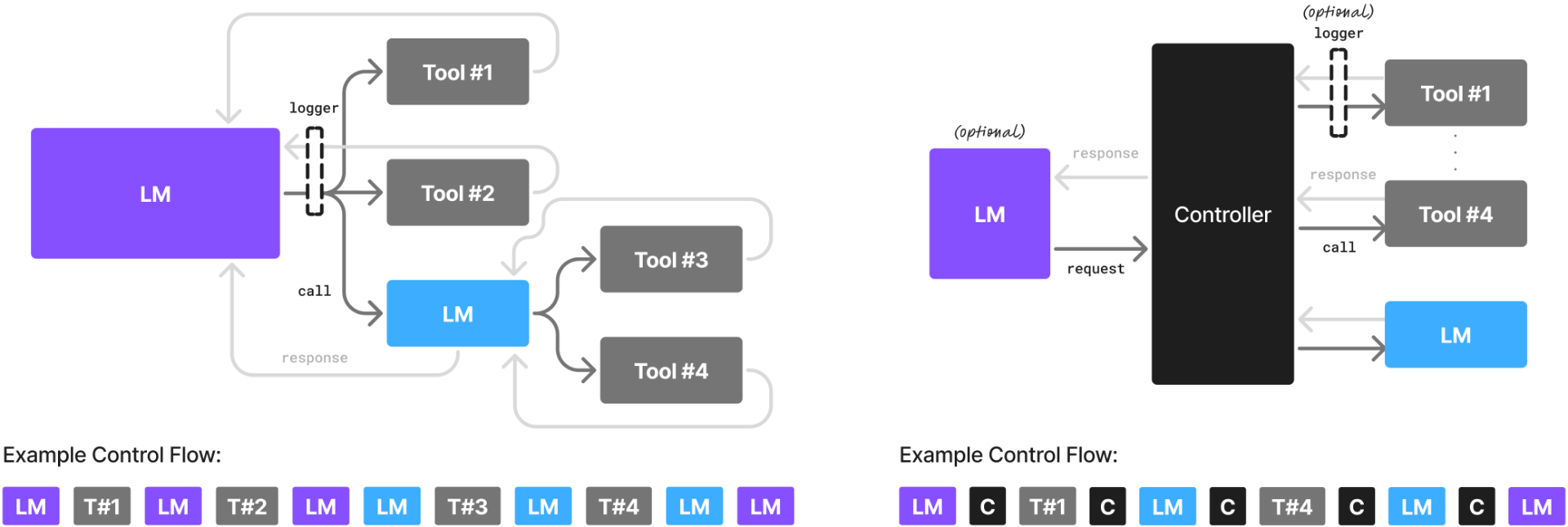
个人还是比较认同这篇工作提出的观点。该论文还绘制了一张图,比较了目前智能体的两种模式,图中左侧是目前更常见的模式,通过一个 LLM 进行任务驱动;右侧是一种更新的模式,类似(GPT-5),通过一个控制器(Controller)去负责调度所有交互,LLM 仅作为一个可选的接口。
在“scaling law”的指导下,模型参数量一直在scaling的方向狂奔,但回头可能会发现,<#include<bits/stdc++.h>不如拆分出来按需导入。