大数据电商流量分析项目实战:Hive 数据仓库(三)


✨博客主页: https://blog.csdn.net/m0_63815035?type=blog
💗《博客内容》:大数据、Java、测试开发、Python、Android、Go、Node、Android前端小程序等相关领域知识
📢博客专栏: https://blog.csdn.net/m0_63815035/category_11954877.html
📢欢迎点赞 👍 收藏 ⭐留言 📝
📢本文为学习笔记资料,如有侵权,请联系我删除,疏漏之处还请指正🙉
📢大厦之成,非一木之材也;大海之阔,非一流之归也✨

前言&课程重点
大家好,我是程序员小羊!接下来一周,咱们将用 “实战拆解 + 技术落地” 的方式,带大家吃透一个完整的大数据电商项目 ——不管你是想靠项目经验敲开大厂就业门,还是要做毕业设计、提升技术深度,这门课都能帮你 “从懂概念到能落地”。
毕竟大数据领域不缺 “会背理论” 的人,缺的是 “能把项目跑通、能跟业务结合” 的实战型选手。咱们这一周的内容,不搞虚的,全程围绕 “电商业务痛点→数据解决方案→技术栈落地” 展开,每天聚焦 1 个核心模块,最后还能输出可放进简历的项目成果。
进入正题:
本项目是一门实战导向的大数据课程,专为具备Java基础但对大数据生态系统不熟悉的同学量身打造。你将从零开始,逐步掌握大数据的基本概念、架构原理以及在电商流量分析中的实际应用,迅速融入当下热门的离线数据处理技术。
在这门课程中,你将学会如何搭建和优化Hadoop高可用环境,了解HDFS存储、YARN资源调度的核心原理,为数据处理打下坚实的基础。同时,你将掌握Hive数据仓库的构建和数仓建模方法,了解如何将海量原始数据经过层次化处理,转化为高质量的数据资产。
课程还将引领你深入Spark SQL的世界,通过实际案例学习如何利用Spark高效计算PV、UV以及各类衍生指标,提升数据分析效率。此外,你还将学习Flume的安装与配置,实现Web日志的实时采集和ETL入仓,确保数据传输的稳定与高效。
为了贴近企业实际运作,本项目还包括定时任务的设置和自动化数据管道构建,教你如何编写Shell脚本并利用crontab定时调度Spark作业,让数据处理过程实现自动化与智能化。最后,通过可视化展示模块,你将学会用FineBI等工具将数据分析结果直观呈现
总之,这是一门集大数据基础、系统搭建、数据处理与智能分析于一体的全链路实战课程。无论你是初入大数据领域的新手,还是希望提升数据处理能力的开发者,都将在这里收获满满,掌握最前沿的大数据技术。
课程计划:
| 天数 | 主题 | 主要内容 |
|---|---|---|
| Day 1 | 大数据基础+项目分组 (ZK补充) | 大数据概念、数仓建模、组件介绍、分组;简单介绍项目。 |
| Day 2 | Hadoop初认识+ HA环境搭建 | 初认识Hadoop,了解HDFS 基本操作,YARN 资源调度,数据存储测试等,并且完成Hadoop高可用的环境搭建。 |
| Day 3 | Hive 数据仓库 | Hive SQL 基础、表设计、加载数据,搭建Hive环境并融入Hadoop实现高可用 |
| Day 4 | Spark SQL 基础 | 讲解Spark基础,DataFrame & SQL 查询,Hive 集成和环境的搭建 |
| Day 5 | Flume 数据采集及ETL入仓 | 安装Flume高可用,学习基础的Flume知识并且使用Flume 采集 Web 日志,存入 HDFS;数据格式解析,数据传输优化 |
| Day 6 | 数据入仓 & 指标计算 | 解析 PV、UV 计算逻辑,Hive 数据清洗、分层存储(ODS → DWD) |
| Day 7 | Spark 计算 & 指标优化 | 使用 Spark SQL 计算 PV、UV 及衍生指标(如跳出率、人均访问时长等) |
| Day 8 | 定时任务 & 数据管道 | 编写 Shell 脚本,使用 crontab 实现定时任务,调度 Spark SQL |
| Day 9 | 可视化 & 数据分析 | 搭建一个简单的项目使用 FineBI 进行数据展示,分析趋势。 |
| Day 10 | 项目答辩 | 小组演示分析结果,可以后台联系程序员小羊点评 |
今日学习重点(Hive仓库):
Hive 的前生属于 Facebook,用于解决海量结构化数据的统计分析,现在属于 Apache 软件基金会。Hive 是一个构建在
Hadoop 之上的数据分析工具(Hive 没有存储数据的能力,只有使用数据的能力),底层由 HDFS 来提供数据存储,可以
将结构化的数据文件映射为一张数据库表,并且提供类似 SQL 的查询功能,本质就是将 HQL 转化成 MapReduce 程序。
说
白了 Hive 可以理解为一个将 SQL 转换为 MapReduce 程序的工具,甚至更近一步说 Hive 就是一个 MapReduce 客户端。
官网:https://hive.apache.org/
安装Hive
安装之前请先下载Hive的安装包 apache-hive-3.1.3-bin.tar.gz https://cloud.189.cn/web/share?code=NzuA3aiiYNFf(访问码:fad9)
目标环境:

- 将准备好的安装包上传至 node01,然后解压:
cd /opt/yjx
【上传文件】
[root@node01 ~]# tar -zxvf apache-hive-3.1.3-bin.tar.gz -C /opt/yjx/
[root@node01 ~]# rm apache-hive-3.1.3-bin.tar.gz -rf
- 修改配置文件 hive-env.sh:
[root@node01 ~]# cd /opt/yjx/apache-hive-3.1.3-bin/conf/
[root@node01 conf]# cp hive-env.sh.template hive-env.sh
[root@node01 conf]# vim hive-env.sh# 在最后一行添加下面的参数
HADOOP_HOME=/opt/yjx/hadoop-3.3.4/
export HIVE_CONF_DIR=/opt/yjx/apache-hive-3.1.3-bin/conf
export HIVE_AUX_JARS_PATH=/opt/yjx/apache-hive-3.1.3-bin/lib
export HADOOP_CLIENT_OPTS="-Xmx2048m $HADOOP_CLIENT_OPTS"
- 修改配置文件 hive-site.xml
[root@node01 conf]# cp hive-default.xml.template hive-site.xml
[root@node01 conf]# vim hive-site.xml#! 首先删除configuration标签里面的数据全部删掉
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://node01:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<property>
<name>datanucleus.schema.autoCreateAll</name>
<value>true</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/hive/warehouse</value>
</property>
<property>
<name>hive.server2.webui.host</name>
<value>node01</value>
</property>
<property>
<name>hive.server2.webui.port</name>
<value>10002</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://node01:9083</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>node01:2181,node02:2181,node03:2181</value>
</property>
</configuration>
懒人包,下面这个是老师的集群的配置后的conf的压缩包,如果修改后启动不成功hive,把这个里面的文件和你当前集群里面hive-conf文件替换【放在资源里面】。
- (忽略)配置hdfs和Hive的用户授信,这个我们默认配置过了 在 core-site.xml ,是这样配置的,如果没有添加。
<!-- 该参数表示可以通过 httpfs 接口访问 HDFS 的 IP 地址限制 -->
<!-- 配置 root(超级用户) 允许通过 httpfs 方式访问 HDFS 的主机名、域名 -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<!-- 通过 httpfs 接口访问的用户获得的群组身份 -->
<!-- 配置允许通过 httpfs 方式访问的客户端的用户组 -->
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
- 配置日志数据目录
[root@node01 conf]# mkdir /opt/yjx/apache-hive-3.1.3-bin/logs
[root@node01 conf]# cp hive-log4j2.properties.template hive-log4j2.properties
[root@node01 conf]# vim hive-log4j2.properties将 property.hive.log.dir = ${sys:java.io.tmpdir}/${sys:user.name} 替换为:property.hive.log.dir = /opt/yjx/apache-hive-3.1.3-bin/logs
- 在hive下的bin目录下的配置文件hive-config.sh中修改如下配置:
cd $HADOOP_HOME/etc/hadoopvim hadoop-env.sh
t添加到末尾:export HADOOP_CLIENT_OPTS="-Xmx2048m $HADOOP_CLIENT_OPTS"拷贝给其他集群
scp -r hadoop-env.sh node02:$PWDscp -r hadoop-env.sh node03:$PWD
cd $HIVE_HOME/bin vim hive-config.sh 找到 export HADOOP_HEAPSIZE 修改为 export HADOOP_HEAPSIZE=${HADOOP_HEAPSIZE:-2048}
- 添加Mysql连接驱动包【资源区有或者自己在Maven仓库下载】:
下载 mysql-connector-java-8.0.18.jar 文件 上传到/opt/yjx/apache-hive-3.1.3-bin/lib/目录下即可
- 拷贝刚刚修改好的文件
[root@node02 ~]# scp -r root@node01:/opt/yjx/apache-hive-3.1.3-bin /opt/yjx/
[root@node03 ~]# scp -r root@node01:/opt/yjx/apache-hive-3.1.3-bin /opt/yjx/
- (可忽略)分发后node02 服务器需要修改 hive-site.xml 配置文件中hive.server2.webui.host 属性的值为 node02。如果你修改了Hadoop 的 core-stie.xml 配置文件别忘了要同步一下
[root@node01 ~]# scp /opt/yjx/hadoop-3.3.4/etc/hadoop/core-site.xml root@node02:/opt/yjx/hadoop-3.3.4/etc/hadoop/
[root@node01 ~]# scp /opt/yjx/hadoop-3.3.4/etc/hadoop/core-site.xml root@node03:/opt/yjx/hadoop-3.3.4/etc/hadoop/
- 配置环境变量 三个节点下的 /etc/profile 文件下都添加下面的数据,你也可以配置一个然后剩下的两个节点分发。修改后所有的窗口运行
source /etc/profile重新加载环境。
export HIVE_HOME=/opt/yjx/apache-hive-3.1.3-bin
export PATH=$HIVE_HOME/bin:$PATH
- 启动hive
#!首先Mysql必须第一个启动 一般开机会自动启动
启动Zookpeer 三个机器都启动
zkServer.sh start使用 start-all.sh 启动hadoop进程
使用 start-yarn.sh 启动yarn进程启动JOBHistory
mapred --daemon start historyserver初始化hive数据库(第一次启动Hive运行)
cd /opt/yjx/apache-hive-3.1.3-bin/bin
./schematool -dbType mysql -initSchema连接node01 的数据库 看看是否有hive数据库后台启动hive / hiveserver2
[root@node01 ~]# nohup hive --service metastore > /dev/null 2>&1 &
[root@node02 ~]# nohup hive --service metastore > /dev/null 2>&1 &启动 HiveServer2 服务。
# 后台启动
[root@node01 ~]# nohup hiveserver2 > /dev/null 2>&1 &
[root@node02 ~]# nohup hiveserver2 > /dev/null 2>&1 &连接hive 两种方式
[root@node01 ~]# hive
[root@node01 ~]# beeline -u jdbc:hive2://node01:10000 -n root
注意:3.1.2 有遗留问题,连接 hive 服务需要启动服务接近 1~2 分钟后才可以连接成功
Hive的介绍
在HA中HIVE的元数据会存储到mysql中,计算引擎可以选 MR 和 Spark 。
当 Hive 连接到 MySQL 作为元数据存储(MetaStore)时,Hive 会在 MySQL 中初始化并创建一系列的元数据表。这些表用于存储 Hive 数据库、表、列、分区等的信息。
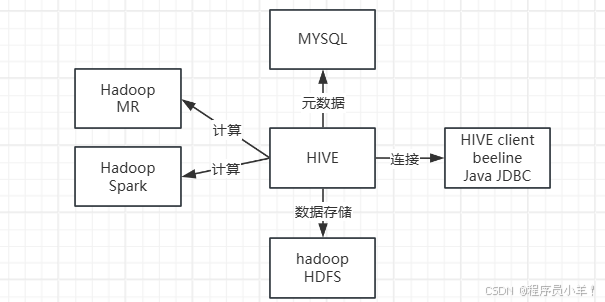
在海量数据场景下,传统的关系型数据库难以满足横向扩展与高吞吐的需求。Facebook 早期将海量日志数据存储于 Hadoop 分布式文件系统(HDFS)上,却发现编写 MapReduce 程序进行查询分析效率较低,于是基于 HDFS 开发了 Hive 来提供更简单的 SQL 式分析接口。
Hive 主要用于大规模数据的离线批处理分析,侧重于高吞吐量与扩展性,而非实时查询。它通过 SQL 风格的语言降低了 Hadoop 平台上大数据分析的门槛。
核心概念:
HiveQL:Hive 提供的类 SQL 查询语言,支持常见的 SQL 语法(如 SELECT、JOIN、GROUP BY 等),也允许用户编写自定义函数(UDF)。
元数据存储(Metastore):Hive 使用元数据存储来管理表结构、分区信息、数据位置等,常常采用 MySQL、PostgreSQL 等外部数据库来保存这些元数据。
表和分区:Hive 中的数据表本质上对应 HDFS 上的文件目录。分区是根据某个字段(例如日期、地区)将数据文件进一步划分,有助于缩小查询范围,提高查询效率。
执行引擎:Hive 最初的执行引擎是基于 MapReduce,后续也可在 Spark、Tez 等其他分布式计算框架上运行,以提升性能。
架构和流程
HIve的架构和工作原理
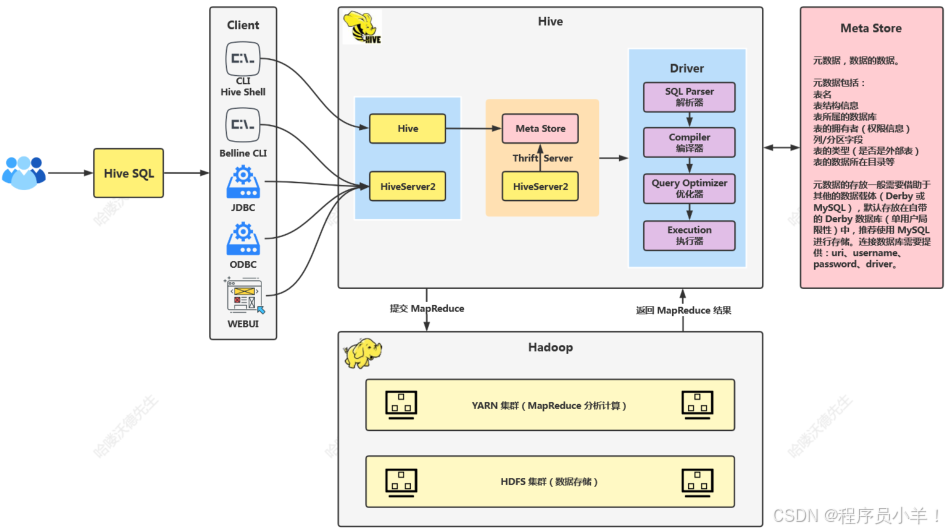
Client(客户端): Hive 提供了多种访问接口,包括 CLI、Beeline CLI、JDBC 等驱动类以及 Web UI 这些接口允许用户使用 HiveQL 与 Hive 进行交互。
Hive Core(核心): 其核心中包含两大组件 Hive 和 HiveServer2;Hive 用于接收用户的查询请求,并将其转换为 MapReduce 任务或其他执行引擎的任务;HiveServer2 是一个支持多用户并发操作的服务,提供更好的并发性和安全性。
Meta Store(元存储) :存储所有关于 Hive 表、分区、列的数据的元数据。元数据包括表名、列名及其类型、表的分区信息、表数据的位置等。这些信息通常存储在一个关系型数据库中,比如 MySQL 或者 Derby。Meta Store 是 Hive 查询优化器生成执行计划的重要数据来源。
Derby:当你没有配置 Hive 的 MetaStore 的数据库的时候内置的默认数据库,Hive 默认将元数据存储在 Derby 数据库中,但其仅支持单线程操作,若有一个用户在操作,其他用户则无法使用,造成效率不高;而且当在切换目录后,重新进入 Hive 会找不到原来已经创建的数据库和表。
Driver(驱动):驱动中主要有四大工具也是用户提交 HQL 的时候的执行流程。
- 解析器:解析用户的 SQL 查询,将其转换为语法树。
- 编译器:将解析后的查询转换为执行计划。具体地,它会生成一系列的 MapReduce 作业。
- 查询优化器:对执行计划进行优化,以减少数据处理的成本。
- 执行器:负责实际执行查询,将任务提交给 Hadoop 集群。
工作流程 (简述):用户通过各种客户端发送 Hive SQL 查询,Hive 接收到查询后,通过 HiveServer2 将查询转发给 Meta Store 查询数据后给 Driver,首先 Driver 中的 SQL Parser 解析查询,编译器编译查询并通过查询优化器进行优化,然后生成 MapReduce 作业让执行器执行提交给 Hadoop,作业提交给 YARN 集群进行调度,MR 执行执行,数据从 HDFS 读取,最终结果返回给用户。
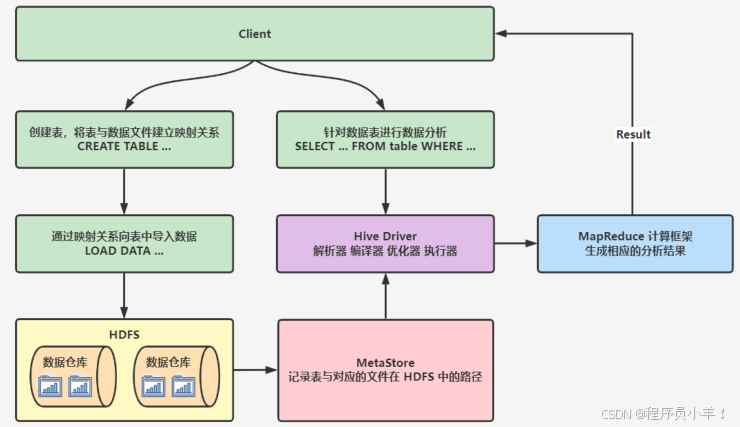
HIve的工作流程
① 创建表:用户通过 SQL 命令创建表时,需要指定数据在 HDFS 上的存储路径。表的元数据包括表的结构和 HDFS 路径被存储在 MetaStore 中,用于建立表和实际数据文件之间的映射关系。
② 加载数据:当数据被加载到表中时,Hive 会根据 MetaStore 中存储的映射关系,将数据导入到对应的 HDFS 路径。
③ 执行查询:用户输入 SQL 查询语句,Hive 将这些 SQL 语句解析、编译和优化,Hive 会将 SQL 语句转换成对应的 MapReduce 任务,这些任务被提交到 Hadoop 集群的 YARN 框架进行资源调度和执行。Hive 会自动匹配和使用这些模板来生成具体的 MapReduce 程序。
④ 返回结果:MapReduce 任务执行完毕后,计算结果被返回给 Hive,Hive 再将结果返回给用户。
分区分桶 内部表和外部表
在 Hive 中,分区和分桶是优化数据存储和查询性能的两种常见方法。这些技术旨在减少数据扫描的范围和查询时间,特别是在处理大规模数据集时非常有效。
分区:分区是根据表中的一个或多个字段的值,将数据划分为多个部分,每个部分称为一个分区。每个分区通常存储在一个独立的目录中。
分区将表的数据根据特定列(如日期、地域等)划分成多个部分,使用分区时,Hive 会根据分区列的值为每个分区创建一个单独的目录(文件夹)。这些目录用于存放属于该分区的数据文件。
这个结构有助于高效地组织和管理大数据集,同时优化查询性能在查询时,可以根据查询条件只扫描相关分区的数据,从而减少扫描的数据量。例如,如果按日期分区,只需要查询特定日期的数据。
分桶: 是将数据进一步细分为更小的部分,每个部分称为一个桶(bucket)。分桶是通过对某列进行哈希运算,然后将数据根据哈希值分配到不同的桶中。分桶 适用于数据分布均匀、需要 Join 或 采样查询 的场景
分桶在每个分区内部进一步将数据分配到固定数量的桶中。桶的数量在表创建时确定,且所有桶的大小尽量均匀,分桶可以与分区一起使用,有效减少数据扫描量。如果两个表按照相同的列分桶且桶的数量相同,可以减少数据的 shuffle 操作。
# 建表分区分桶的案例
假设我们有一个 sales 表,记录销售数据,我们希望按 year 和 month 进行分区:CREATE TABLE sales (order_id STRING,customer_name STRING,amount DECIMAL(10,2)
)
PARTITIONED BY (year INT, month INT)
STORED AS ORC;这意味着数据存储在 HDFS 目录结构中:
/user/hive/warehouse/sales/year=2023/month=01/
/user/hive/warehouse/sales/year=2023/month=02/
/user/hive/warehouse/sales/year=2024/month=01/插入数据时需要指定分区:
INSERT INTO sales PARTITION (year=2023, month=01) VALUES ('1001', 'Alice', 200.50);假设我们希望对 customer_id 进行分桶,以优化查询:
CREATE TABLE sales_bucketed (order_id STRING,customer_name STRING,amount DECIMAL(10,2)
)
PARTITIONED BY (year INT, month INT)
CLUSTERED BY (customer_name) INTO 4 BUCKETS
STORED AS ORC;插入数据(使用 INSERT 语句时需要 SORTED BY 并开启 bucketing 机制):
SET hive.enforce.bucketing = true;
INSERT INTO sales_bucketed PARTITION (year=2023, month=01)
| 对比项 | 分区(Partition) | 分桶(Bucket) |
|---|---|---|
| 目的 | 物理划分数据,减少扫描范围 | 逻辑划分数据,提高查询效率 |
| 存储方式 | 数据按目录存储 | 数据按文件存储 |
| 适用场景 | 查询时常带有分区字段过滤 | 适用于 Join 操作和均匀分布数据 |
| 创建方式 | PARTITIONED BY | CLUSTERED BY |
| 查询优化 | 通过 WHERE 过滤分区 | 通过 JOIN 和 SAMPLE 提高查询 |
内部表和外部表
在 Hive 中,表可以分为 内部表(管理表) 和 外部表,它们的主要区别在于 数据存储方式和生命周期管理。
通常来内部表数据存储在 Hive 的默认仓库目录(通常是 /user/hive/warehouse/)Hive 负责数据的管理,删除表时,数据文件也会一起删除,适用于数据临时存储,或者数据是 Hive 主要管理的情况。
在一般情况下内部表用的比较少,外部表用的比较多;外部表 允许 Hive 只管理表的元数据,而数据存储在用户指定的 HDFS 目录下。删除表时,数据仍然存在,不会被删除。也就是说外部表Hive存储的只是数据的源数据
1.需要手动指定数据存储路径 (LOCATION 关键字)。2.适用于外部存储的数据(如日志数据、共享数据集等)。3.删除表时,数据仍然保留,只删除元数据。
| 对比项 | 内部表(Managed Table) | 外部表(External Table) |
|---|---|---|
| 数据存储 | Hive 默认仓库 /user/hive/warehouse/ | 用户指定的 HDFS 目录 |
| 数据管理 | 由 Hive 管理 | 用户管理数据存储 |
| 删除表影响 | 删除表时,数据和元数据一起删除 | 删除表时,数据仍然存在 |
| 适用场景 | 适用于 Hive 主要管理的数据 | 适用于共享数据,或 Hive 仅作为查询工具 |
# 创建内部表
CREATE TABLE sales_managed (order_id STRING,customer_name STRING,amount DECIMAL(10,2)
)
PARTITIONED BY (year INT, month INT)
STORED AS ORC;STORED AS 指定 文件存储格式,表示文件是按照ORC格式存储的# 插入数据
INSERT INTO sales_managed PARTITION (year=2024, month=01)
VALUES ('1001', 'Alice', 200.50);
# 查看表路径
DESCRIBE FORMATTED sales_managed;
# 删除内部表
DROP TABLE sales_managed;# 创建外部表
CREATE EXTERNAL TABLE sales_external (order_id STRING,customer_name STRING,amount DECIMAL(10,2)
)
PARTITIONED BY (year INT, month INT)
STORED AS ORC
LOCATION '/yjx/data/sales/';# 插入数据
INSERT INTO sales_external PARTITION (year=2024, month=01)
VALUES ('2001', 'Bob', 150.75);
# 查看表存储路径
DESCRIBE FORMATTED sales_external;
# 删除表 你会发现数据还在,你要是手动创建表数据还在
DROP TABLE sales_external;# 内转外
ALTER TABLE sales_managed SET TBLPROPERTIES ('EXTERNAL'='TRUE');
数据倾斜
在 Hive 中,数据倾斜(Data Skew) 指的是某些任务处理的数据远远多于其他任务,导致执行时间严重不均衡,从而降低查询性能,甚至导致任务失败。
在 JOIN 过程中,Hive 通过 某个字段的哈希值 将数据分发到不同的 Reducer 处理。如果某个字段的某个值出现得特别多,Hive 就会将该值对应的数据全部发到 同一个 Reducer,导致该 Reducer 处理的数据量远超其他 Reducer,进而引发倾斜。
例如:JOIN因为单个id数据特别多产生的join数据倾斜。还有因为GROUP BY 造成的数据倾斜;Hive 需要根据分组字段 将相同的 key 分发到同一个 Reducer 进行聚合计算。如果某个 key 占比过大,就会造成 某个 Reducer 过载。
在 Hive 进行 DISTRIBUTE BY或者sort by它会根据字段的哈希值将数据分发到不同的 Reducer。如果某些值过于集中,则会造成部分 Reducer 处理的数据量过大。
解决方案
1.使用 MAP JOIN(小表广播) 如果 customers 表比较小,可以使用 MAP JOIN,让 Hive 在 Mapper 端直接加载小表到内存,避免 Reducer 计算。
SET hive.auto.convert.join=true;
SELECT /*+ MAPJOIN(c) */ *
FROM orders o
JOIN customers c
ON o.customer_id = c.customer_id;
2.SALTING(给热点 key 赋随机值) 如果某个 key(如 customer_id='10001')占比过大,可以人为在 key 上 添加随机数,让数据更均匀地分布到不同 Reducer。
1.修改前
SELECT *
FROM orders o
JOIN customers c
ON o.customer_id = c.customer_id;2.修改后
SELECT *
FROM orders o
JOIN (SELECT customer_id, RAND() as salt FROM customers) c
ON o.customer_id = c.customer_id AND o.salt = c.salt;
3.某些 key 数据过多时,让 GROUP BY 先打散数据,最后再合并。(groupby)类似方法一
4.增加reducer数量导致部分 Reducer 处理过多。SET mapreduce.job.reduces=20; 手动提高reduces数量。
5.对于 DISTRIBUTE BY 的数据倾斜,可以认为的添加一个DISTRIBUTE 的条件,添加一个随机数让数据在hash基础上更乱一些。
SELECT *
FROM transactions
DISTRIBUTE BY region, RAND();
数据的更新方式
在 Hive 中,数据的更新不像传统关系型数据库(如 MySQL、PostgreSQL)那样直接支持 UPDATE 和 DELETE 操作。因为 Hive 主要是为 大规模数据分析和批处理 设计的,最初并不支持事务和行级更新。
不过,在 Hive 2.0 及以上版本,ACID 事务被引入,使 Hive 具备了一定的 更新、删除和插入能力。但速度很慢基本不用。
| 方法 | 适用场景 | 是否适合大规模更新 | 是否保留历史数据 |
|---|---|---|---|
| 先插入后删除 | 分区表数据更新、大规模数据更新 | ✅ 适合 | ❌ 不保留 |
| SCD Type 1 | (用户、产品)、用户、产品等维度表 | ✅ 适合 | ❌ 不保留 |
| SCD Type 2 | 维度表,需保留历史 | ❌ 适量使用 | ✅ 保留 |
| ACID 事务(UPDATE/DELETE) | 行级更新、小规模行级更新,需要支持并且表开启事务 | ❌ 不适合 | ✅ 可保留 |
先插入后删除
这种方法的核心思想是:1. 先把新数据插入(可能是全量数据,也可能是增量数据)。 2. 再删除旧数据,保证数据的最新状态。
首先这样做肯定是为了保证性能和数据的完整性,适用于分区表可以直接覆盖某个分区的数据,而不影响其他分区。
如果是 大规模更新,可以直接用 INSERT OVERWRITE 覆盖分区。这样不会影响其他数据,并且不会产生 DELETE 开销,更新速度更快。
-- 1. 先插入新数据(假设 new_sales_data 是增量表)
INSERT INTO sales PARTITION (year=2024, month=03, day=01)
SELECT * FROM new_sales_data WHERE year=2024 AND month=03 AND day=01;-- 2. 删除旧数据
ALTER TABLE sales DROP PARTITION (year=2024, month=03, day=01);INSERT OVERWRITE TABLE sales PARTITION (year=2024, month=03, day=01)
SELECT * FROM new_sales_data WHERE year=2024 AND month=03 AND day=01;
缓慢变化维(SCD)
缓慢变化维(SCD)是一种 针对数据仓库的更新策略,用于处理 维度表(如用户、产品信息) 数据的变更。主要有 SCD Type 1 和 SCD Type 2 两种常见方式。
- SCD Type 1(覆盖旧数据,不保留历史)适用于 不关心历史数据 的场景,每次更新都是 直接覆盖旧数据。
例如:如果 users 维度表存储用户信息,每天都会有新的更新,我们可以直接整个替换,简单但是数据肯定没有体现出历史变化。
- SCD Type 2(保留历史数据,加版本或时间戳)
适用于 需要保留历史记录 的场景,每次数据更新时 不会覆盖旧数据,而是新增一条带时间戳的记录。给 users 维度表增加 start_date 和 end_date 来标记数据的有效时间
启动顺序 (Hadoop+HiVE+saprk)
# 先开启 Zookpeer (三台机器都要启动)
zkServer.sh start
zkServer.sh status# 启动Hadoop (只要node01即可)
start-all.sh
start-yarn.sh# 启动JobHistory Server (三个机器都要启动)
mapred --daemon start historyserver# 启动Hive MetaStore (node01,node02)
nohup hive --service metastore >> /dev/hive-runlog 2>&1 &
nohup hiveserver2 >> /dev/hive2-runlog 2>&1 &# 启动Spark
cd /opt/yjx/spark-3.3.2/
sbin/start-thriftserver.sh \
--hiveconf hive.server2.thrift.port=10015 \
--master yarn --deploy-mode client \
--queue default \
--driver-cores 1 --driver-memory 1024M \
--num-executors 1 --executor-cores 1 --executor-memory 2G
数据分析实操的简单案例
目标1:建表并导入外部数据
首先你在windows电脑上准备一个名为 employees.csv 模拟外面导入的数据。
1001, Alice, HR, 2024-01-01
1002, Bob, IT, 2024-02-15
1003, Charlie, Finance, 2024-03-10
保存然后通过Web页面上传文件到hdfs下的 /data/employees 下,当然如果没有文件夹需要自己手动创建
创建外部表并尝试查询数据。
CREATE EXTERNAL TABLE employees_ext (emp_id STRING,name STRING,department STRING,join_date STRING
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS textfile
LOCATION '/data/employees/';SELECT * FROM employees_ext;
目标2:WordCount 处理文本文件
1.下载下面的txt文件,我们要尝试分析文件并且输出,每个单词都出现了几次。这就是简单的数据分析案例 WordCount
2.通过网页或者其他方式上传文件到 /data/wordcount,现在创建表,但是我们现在有个问题是数据在表格我们应该怎么存储?其实很简单我们只要存一列 line 就行
CREATE EXTERNAL TABLE wordcount_raw (line STRING
)
STORED AS TEXTFILE
LOCATION '/data/wordcount/';
3.处理 WordCount 把每一列的数据都根据 split 切除 条件是空格,查询到的所有的数据单独输出为word,最后只需要根据word分组并且COUNT(*)就可以知道最后的情况了。
SELECT word, COUNT(*) AS count
FROM (SELECT explode(split(line, ' ')) AS word FROM wordcount_raw
) temp
GROUP BY word
ORDER BY count DESC;
目标3:拉链表(SCD Type 2)
拉链表保存了每条记录的生效日期和结束日期,可以用于跟踪数据的变化。
-
如果增量数据与已有的数据相匹配,并且发生了变化,更新历史记录的
end_dt为当前日期,并插入一条新的记录,表示新的数据状态。 -
如果增量数据是新数据,直接插入到拉链表中,
end_dt设为'9999-12-31'。
通过这样的操作,可以确保拉链表中保存了每条记录的完整历史信息,便于后续的分析和查询。
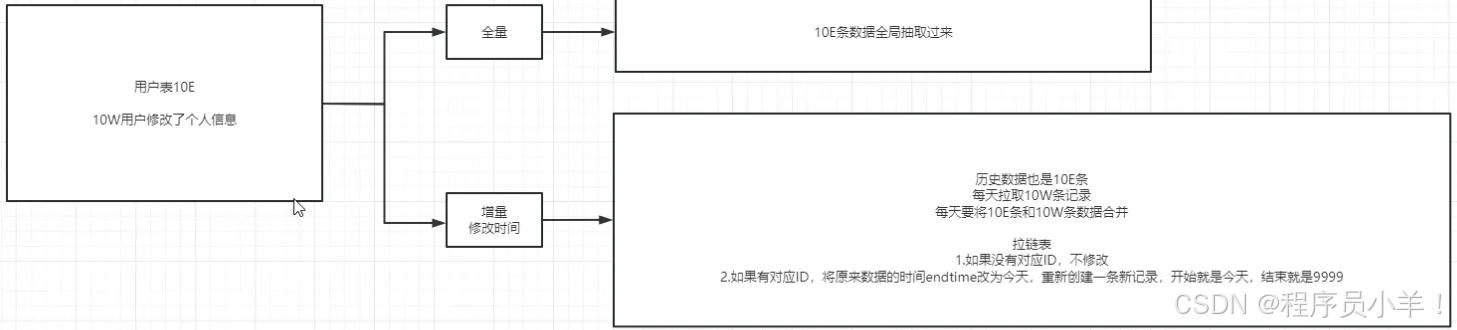
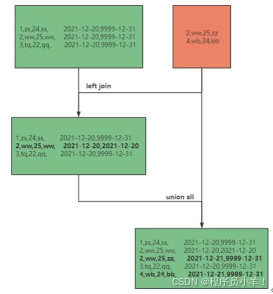
- 首先,需要创建一个拉链表
test.lalian,用于存储数据变化的历史信息。 拉链表中的每一条记录都会有 开始时间 和 结束时间 两个时间字段,分别表示该记录的生效和结束日期。结束时间 等于9999-12-31时,表示该记录目前仍然有效(即“开链”)。
create table test.lalian
(oid string,amount double,status int,start_dt string,end_dt string
)
partitioned by (dt string)
row format delimited fields terminated by ',';
- 我们将数据加载到
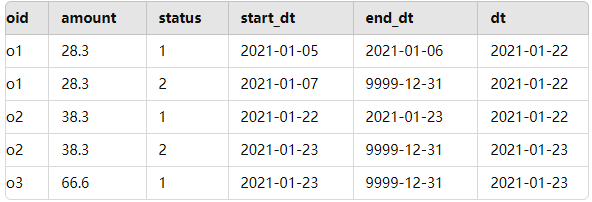
lalian表的分区中。创建一个 txt文本,数据如下所示,上传到Linux中加载数据到内部表中。
o1,28.3,1,2021-01-05,2021-01-06
o1,28.3,2,2021-01-07,9999-12-31
o2,38.3,1,2021-01-22,9999-12-31++++++++++++++++++ 下面是加载代码 ++++++++++++++++++
load data local inpath '/root/lalian.txt' into table test.lalian
partition(dt='2021-01-22');
- 创建 ODS 层的增量数据表
test.add,用于存储新数据,创建一个 txt文本,数据如下所示,上传到HDFS中加载数据到内部表中。
++++++++++++++++++ 下面是建表语句 ++++++++++++++++++
create table test.add(oid string,amount double,status int
)
partitioned by (dt string)
row format delimited fields terminated by ',';++++++++++++++++++ 下面是txt数据 ++++++++++++++++++
o2,38.3,2
o3,66.6,1++++++++++++++++++ 下面是加载代码 ++++++++++++++++++
load data local inpath '/root/add.txt' into table test.add
partition(dt='2021-01-23');
- 拉链表的更新 取出
2021-01-22的历史数据,并取出2021-01-23的增量数据
WITH a AS (SELECT * FROM test.lalian WHERE dt = '2021-01-22'
),
b AS (SELECT * FROM test.add WHERE dt = '2021-01-23'
)
- 更新历史数据中已经存在的记录
-- 如果新数据的 oid 已经在历史记录中存在,我们更新原始记录的 end_dt
-- 为新数据到来的 dt。 如果 end_dt 是 '9999-12-31',并且 b.oid 存在
-- 则更新 end_dt。INSERT INTO TABLE test.lalian PARTITION(dt='2021-01-23')
SELECT a.oid,a.amount,a.status,a.start_dt,IF(a.end_dt = '9999-12-31' AND b.oid IS NOT NULL, a.dt, a.end_dt) AS end_dt
FROM a
LEFT JOIN b
ON a.oid = b.oid
- 插入新数据
-- 对于不在历史数据中的新记录,直接插入 b 表中的数据,同时设定 start_dt 为当前 dt
UNION ALL
SELECTb.oid,b.amount,b.status,b.dt AS start_dt,'9999-12-31' AS end_dt
FROM b;
WITH a AS (SELECT *FROM test.lalianWHERE dt = '2021-01-22'
),
b AS (SELECT *FROM test.addWHERE dt = '2021-01-23'
)
INSERT INTO TABLE test.lalian PARTITION(dt='2021-01-23')
SELECTa.oid,a.amount,a.status,a.start_dt,IF(a.end_dt = '9999-12-31' AND b.oid IS NOT NULL, a.dt, a.end_dt) AS end_dt
FROM a
LEFT JOIN b
ON a.oid = b.oid
UNION ALL
SELECTb.oid,b.amount,b.status,b.dt AS start_dt,'9999-12-31' AS end_dt
FROM b;
结尾:
本课程是一门以电商流量数据分析为核心的大数据实战课程,旨在帮助你全面掌握大数据技术栈的核心组件及其在实际项目中的应用。从零开始,你将深入了解并实践Hadoop、Hive、Spark和Flume等主流技术,为企业级电商流量项目构建一个高可用、稳定高效的数据处理系统。
在课程中,你将学习如何搭建并优化Hadoop高可用环境,熟悉HDFS分布式存储和YARN资源调度机制,为大规模数据存储与计算奠定坚实基础。随后,通过Hive数据仓库的构建与数仓建模,你将掌握如何将原始日志数据进行分层处理,实现数据清洗与结构化存储,从而为后续数据分析做好准备。
借助Spark SQL的强大功能,你将通过实战案例学会快速计算和分析关键指标,如页面浏览量(PV)、独立访客数(UV),以及通过数据比较获得的环比、等比等衍生指标。这些指标将帮助企业准确洞察用户行为和流量趋势,为优化营销策略提供科学依据。
同时,本课程还包含Flume数据采集与ETL入仓的实战模块,教你如何采集实时Web日志数据,并利用ETL流程将数据自动导入HDFS和Hive,确保数据传输和处理的高效稳定。
总体来说,这门课程面向希望提升大数据应用能力的技术人员和企业项目团队,紧密围绕公司电商流量项目的实际需求展开。通过系统的理论讲解与动手实践,你不仅能够构建从数据采集、存储、处理到可视化展示的完整数据管道,还能利用PV、UV、环比、等比等关键指标,全面掌握电商流量数据分析的核心技能。
今天这篇文章就到这里了,大厦之成,非一木之材也;大海之阔,非一流之归也。感谢大家观看本文
