阿里FunASR语音转文字模型搭建
最近在做语音文件转换文字,FunASR正好可以在没有显卡的情况下运行起来,正适合练手。
1.环境要求
python+vscode(本文使用vscode)
python 需要 3.10.X 高于3.10X的版本不一定能用
注意vscode的右下方,选择运行环境要选本地安装的python环境。如果不用本地环境,则需要选择其他类似 conda创建的虚拟环境
2.安装funasr 库
pip install -U funasr
3.安装模型管理工具 ModelScope
pip install modelscope torchaudio
4.下载语音数据模型,我这里使用的是
modelscope download --model iic/speech_seaco_paraformer_large_asr_nat-zh-cn-16k-common-vocab8404-pytorch
模型介绍地址
https://modelscope.cn/models/iic/speech_paraformer_asr_nat-zh-cn-16k-common-vocab8404-online
下载好后,可以做一个简单的测试,使用官方例子:
from funasr import AutoModel# paraformer-zh is a multi-functional asr model# use vad, punc, spk or not as you needmodel = AutoModel(model="paraformer-zh", model_revision="v2.0.4",vad_model="fsmn-vad", vad_model_revision="v2.0.4",punc_model="ct-punc-c", punc_model_revision="v2.0.4",# spk_model="cam++", spk_model_revision="v2.0.2",)res = model.generate(input=f"{model.model_path}/example/asr_example.wav",batch_size_s=300,hotword='魔搭')print(res)运行后效果如下:
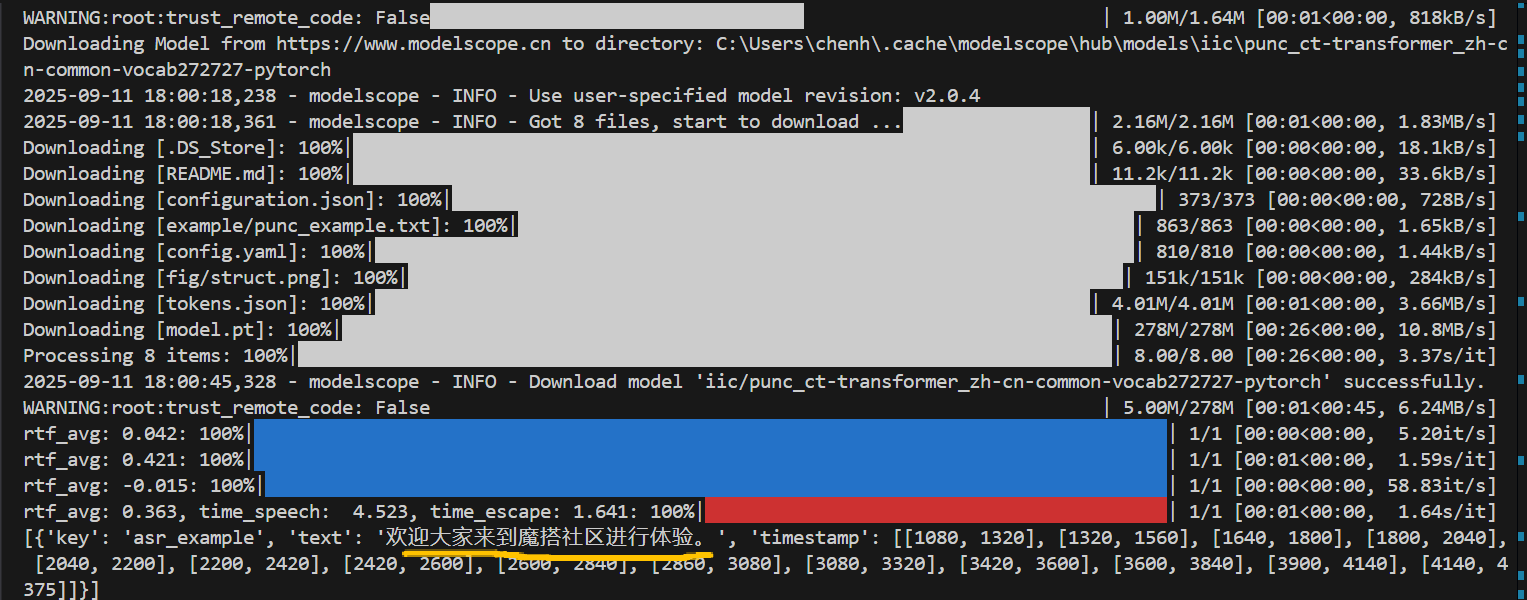
官网的这个代码首次运行他会去下载对应的语音模型库。和我们前面单独下载的语音模型库不是同一个库。没关系,我们继续用手动下载的库来做离线项目。
5.下载的模型
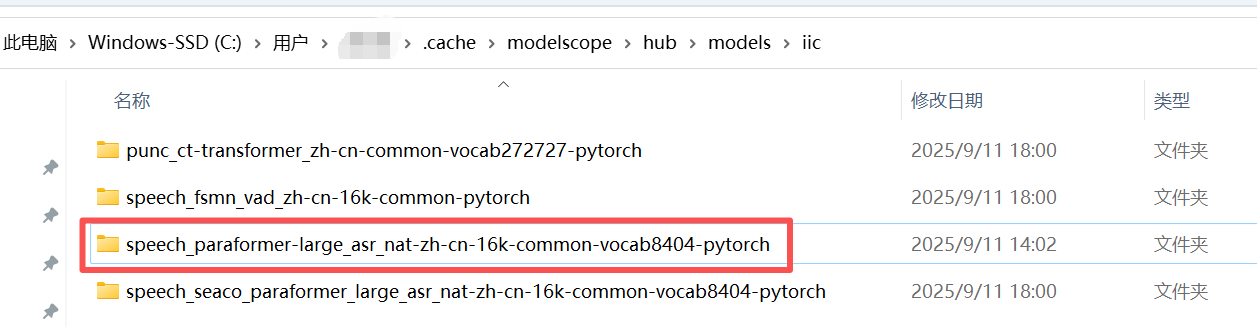
我们刚刚手动下载的模型如上图标红部分。其他3个是运行官网demo自动下载的。
为了项目管理方便,我把手动下载的语音模型拷贝到项目目录下,自己取个名字
下面把模型改成本地路径即可测试。注意音频文件需要16 kHz、单声道、PCM 16-bit。
from funasr import AutoModel
import os# 指定模型缓存路径
local_model_path = "./asr_nat-zh-pytorch"# 确保模型目录存在
if os.path.exists(local_model_path ):print("使用本地模型...")model = AutoModel( model=local_model_path ,disable_update=True, # 禁止更新,避免重复下载trust_remote_code=False)res = model.generate(input="./asr_example_zh.wav", batch_size_s=300)print(res)
else:print("没找到模型...")运行效果如下: