redis 入门-1
1. redis 安装(ubantu 环境)
(注:以下均在 root 权限下操作,如果不是 root 用户,先使用 su 命令切换到 root 用户)
1.1 使用 apt 命令搜索并下载 redis
apt search redis 搜索 redis 相关软件包。
apt install redis 执行该命令,系统会自动安装合适的 redis。
在 continue 这里 点击 y(不区分大小写),确认安装。
netstat -anp | grep redis 看一下是否安装成功。
成功后长这样:

1.2 配置 redis
cd /etc/redis/ 进入该文件。
vim redis.conf 对 redis 文件下的 redis.conf 配置文件对照下图进行修改。
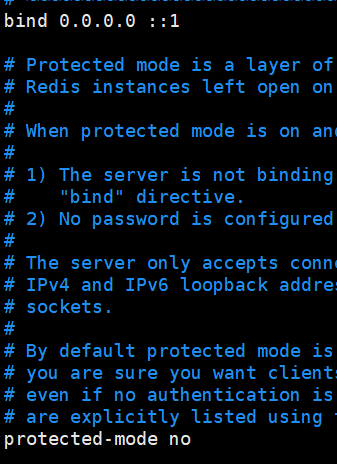
点击 i 进入编辑模式,Esc 键退出编辑,:wq 退出并保存(退出编辑后操作)
配置完成后,要重启服务。
service redis-server restart
然后,看一下服务是否正常运行:
service redis-server status
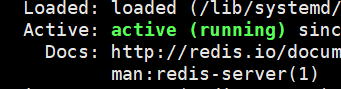
running 表示正常运行
2. 基础通用命令
注: redis 命令并不区分大小写。
1. get & set
用于设置 键值对 和 获取 key 对应的 value。如下图,所示
127.0.0.1:6379> set key hello
OK
127.0.0.1:6379> get key
"hello"
如果 key 不存在,那么get 的结果为 nil(和 null 含义相同) ,
2. keys
用于查询 符合某一特征的 key
redis> KEYS *name*
1) "firstname"
2) "lastname"
redis> KEYS a??
1) "age"
KEYS *
1) "age"
2) "firstname"
3) "lastname"
- ? 匹配单个任意字符
- * 匹配任意个任意字符
- h[ae]llo 匹配 hello 和 hallo 但不匹配 hillo
- h[^e]llo 匹配 hallo , hbllo , … 但不匹配 hello
- h[a-z]llo 匹配 hallo ,hbllo,hcllo,……,hzllo。
keys 命令的时间复杂度是 O(N)。
注意事项:在生产环境中,一般不使用 keys 命令,尤其是 keys * (查询 redis 中的所有 key)。
redis 经常用作 缓存,挡在 mysql 前,替 mysql 负重前行。你一个 keys * 操作,可能导致 redis 被阻塞,这时其他的查询 redis 的操作就超时了,转而这些请求就直接交给了 数据库。
突然来一大波请求,mysql 就有可能就挂了。整个系统就可能瘫痪了
3. exist
EXISTS key [key ...]
返回 key 存在的个数,针对 多个key 来说,是非常有用的。
这个操作的时间复杂度是 O(1) 因为 redis 使用键值对进行存储,类似于 哈希表。key 是唯一的。
辨析:一次查多个 和 一次一个分多次
EXISTS hello hallo
======================
EXISTS hello
EXISTS hallo
redis 是一个客户端,服务器 结构的程序。客户端和服务器之间通过网络进行通信。
分开的写法,会产生更多轮次的网络通信。而网络通信 效率比较低,成本比较高 (相较而言,如和直接操作内存比)
网络通信还要封装和分用。
进行网络通信的时候,发送方发送一个数据,这个数据就要从应用层,到物理层,层层封装。(每一层协议都要加上报头或者尾)=> 发一个快递,要包装一下,要包裹好几层。
接收方收到一个数据,这个数据就要从物理层,到应用层层层分用(把每一层协议中的报头或者尾给拆掉)=> 收到一个快递,要拆快递,要拆很多层。
网卡是 IO 设备。
更何况,你的客户端和服务器不一定在一个主机上,中间可能隔着很远。
redis 自身也非常清楚上述问题。redis 的很多命令都是支持一次就能操作多个 key 的多种操作。
4. del
del (即 delete) 删除指定的 key,可以一次删除一个或者多个。
127.0.0.1:6379> del hello
(integer) 1
127.0.0.1:6379> del hello hallo aaa
(integer) 2
返回值:删除掉的 key 的个数。
时间复杂度: O(1)
mysql 文章中,当时强调,删除类的操作。如:drop database、drop table、delete from… 都是非常危险的操作,一旦删除了之后,数据就没了。
redis 中 删除操作的风险,要是具体情况和用途而言。
① redis 主要的应用场景,就是作为缓存。此时 redis 里存的只是一个热点数据,全量数据是在 mysql 数据库中。
此时,如果把 redis 中的 key 删除了几个,一般来说,问题不大。
但是,当然如果把所有的数据或者一大半数据一下都干没,这种影响很大。
本来 redis 帮 mysql 负重前行,redis 没数据了,大部分的请求落到 mysql 然后就容易把 mysql 搞挂
相比之下,如果是 mysql 这样的数据,哪怕误删了一个数据,都可能是影响很大的。
② redis 作为数据库,此时误删就影响比较大了。
③ redis 作为消息队列(mq),该情况下误删数据影响大不大,就要据具体情况而言。
归根结底,还是不要乱删数据。
5. expire
expire 给指定的 key 设置过期时间。此处的设定过期时间,必须是 针对已经存在的 key 设置。
设置的时间单位是秒,key 存活时间超出这个指定的值,就会被自动删除。
很多业务场景,是有时间限制的。
如:手机验证码有时效;点外卖、优惠券在指定时间内有效、基于 redis 实现分布式锁(为了避免出现不能正确解锁的情况,通常都会在加锁的时候设置一下过期间。(所谓的使用 redis 作为分布式锁,就是给 redis 里写一个特殊的 key value))
语法:
EXPIRE key seconds
设置成功返回 1,设置失败返回 0。
时间复杂度,也是 O(1)。
对于计算机来说,秒是一个非常长的时间。所以还有以毫秒为单位的 pexpire。
6. ttl
ttl ,即 time to live。该命令用于查看当前 key 的过期时间还有多少,单位为 秒
-1 表⽰没有关联过期时间,-2 表⽰ key 不存在。
使用示例:
redis> SET mykey "Hello"
"OK"
redis> EXPIRE mykey 10
(integer) 1
redis> TTL mykey
(integer) 10
该命令同样有一个 毫秒 单位的版本:pttl。
网络原理,IP 协议。
IP 协议报头中,就有一个字段,TTL
IP 中的 TTL 不是用时间衡量过期的,而是用次数。
3. redis 过期策略
4. 常用数据结构
这里所说的数据结构,其实更类似于 我们编程中使用的 数据类型。redis 有如下几种数据类型。
 这几个最常用 String,Hash,List,Set,Sorted set。其余几个主要是一些特殊场景下的特殊数据类型/数据结构。
这几个最常用 String,Hash,List,Set,Sorted set。其余几个主要是一些特殊场景下的特殊数据类型/数据结构。
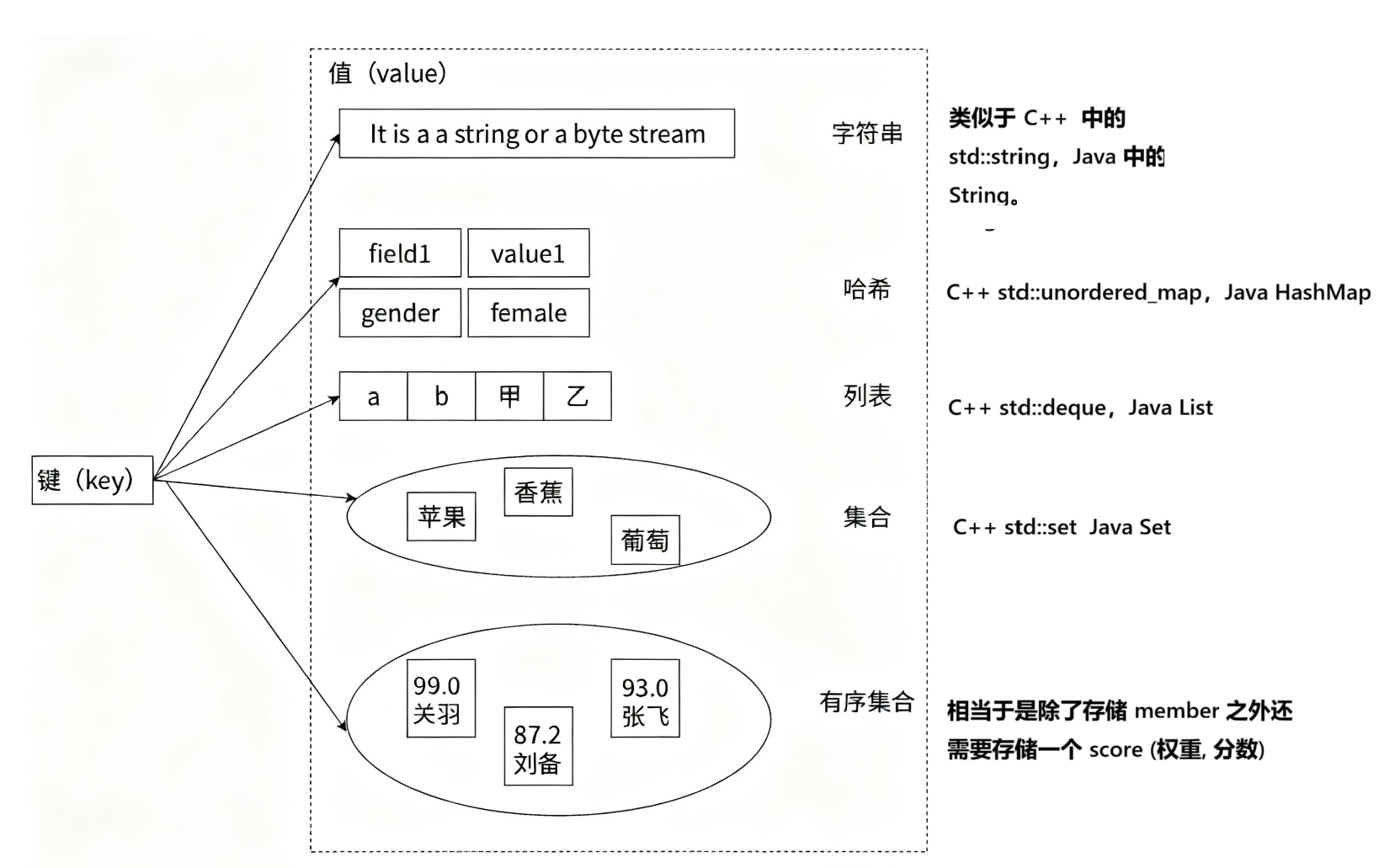
Redis 底层在实现上述数据结构的时候,会在源码层面,针对上述实现进行特定的优化 [ 即 内部的具体实现的数据结构(编码方式),还会有变化】,来达到节省时间/节省空间效果。
以 redis 中的 hash 表为例。相当于 redis 告诉你,它有个 hash 表,你进行查询、插入、删除操作,都是保证 O(1)。
但是,这个背后的实现,不一定就是一个标准的 hash 表。在特定场景下,可能使用别的数据结构实现,但是仍然保证时间复杂度符合 hash 表。
同一个数据类型, 背后可能的编码实现方式是不同的,会根据特定场景优化,redis 会自适应,我们在使用 redis 时,一般感受不到。
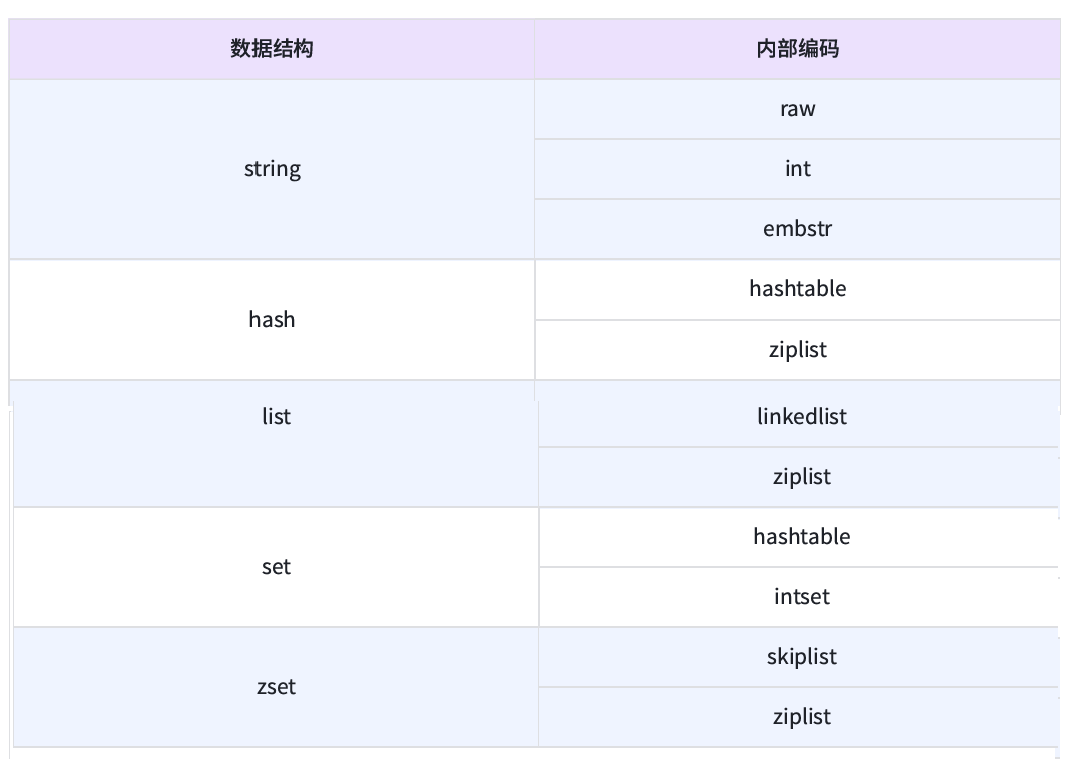
4.1. string
string 有三种内部编码。
raw: 最基本的字符串. (底层就是持有一个 char 数组(C++), 或者
byte 数组 (Java)) ,注:Java 的char 是两个字节的,而 C++ 里的 char 是 1 字节的,其 等价于 Java 的 byte。
int: redis 通常也可以用来实现一些 “计数” 这样的功能。当 value 就是一个整数的时候,此时可能 redis 会直接使用 int 来保存。
embstr: 针对短字符串进行的特殊优化
4.2. hash
hashtable: 最基本的哈希表。 redis 内部 哈希表 的实现。
学过 Java 的可能知道,在 Java 标准库中有一个东西也叫做 HashTable (JAVA 标准库中的 哈希表 的实现)。
二者实现方式可能不太一样,但是整体思想是和之前学过的一致的。
ziplist: zip 是常见的压缩包后缀。这里指 压缩列表。压缩列表中元素较少,获取 value 时,对其进行遍历,速度很快。
在哈希表里面元素比较少的时候,可能就优化成 ziplist 。
为什么要压缩? 答:redis 上有很多很多 key。可能是某些 key 的 value 是 hash,
此时, 如果 key 特别多,对应的 hash 也特别多,但是每个 hash 又不大的情况下,就尽量去压缩。 压缩之后就可以让整体占用的内存更小了。
4.3. list
linkedlist 链表,ziplist 压缩链表。
从 redis 3.2 开始, 引入了新的实现方式 (quicklist),其同时兼顾了 linkedlist 和 ziplist 的优点。
quicklist 就是一个链表,链表中的每个元素又是一个 ziplist,这样把空间和效率都折中的兼顾到。
quicklist 比较类似于 C++ 中的 std::deque。Java 标准库中, 不太清楚。
4.4. set
intset: 集合中存的都是整数。
hashtable
4.5. zset
skiplist: 跳表
链表笔试题, 有一个经典的题目 “复杂链表复制”,原理和它差不多。
跳表也是链表, 不同于普通的链表, 每个节点上有多个指针域。巧妙搭配这些指针域的指向,就可以做到,从跳表上查询元素的时间复杂度是 O(logN)。
ziplist
4.6 object encoding key
object encoding key 查看 key 对应的 value 的实际编码方式。
127.0.0.1:6379> type key1
string
127.0.0.1:6379> OBJECT encoding key1
"Int"
127.0.0.1:6379> get key1
"111"
127.0.0.1:6379> type key2
list
127.0.0.1:6379> OBJECT encoding key2
"quicklist"
4.7 常见思维误区
redis 会自动根据当前的实际情况选择内部的编码方式, 自动适应的。那就有人要问了 是否要记住, 啥时候使用啥编码方式呢?
我想说的是 只记思想, 不记数字。记数字,没什么意义。
数字都是可配置的,数字并不是完全不变。
重要的是知道数字是怎么来的? 这样就可以根据所处的实际场景,重新得到这样的数字。
举例:
HashMap 的相关数字:链表长度达到 多长 => 变成红黑树;负载因子达到多大=> 触发扩容。 同理, 类似的还有, 一个线程池, 线程数目设置成多少,类似于这样的一些 “参数” 非常常见的,都是 “可调” 的。
实际工作中遇到的一些场景,默认的数字就不一定合适了。正确的做法,是根据实际的测试结果,找出一个合适的数值
很多人都会陷入 “记忆数字” 的误区,虽然学校乐意考这种问题。
但是考试和面试, 和工作, 都差别很大。
考试的评价标准: 有标准答案, 看你做的对不对。
面试的评价标准: 有部分标准答案, 也有一部分没有标准答案,eg:看你解决问题的过程和思路以及面试官是否认可你这个人。
实际工作的评价标准: 低成本的解决问题。
5. 单线程模型
5.1 单线程模型工作过程
redis 是 单线程模型,即 redis 只使用一个线程,处理所有的命令请求。 但是这不是说一个 redis 服务器进程内部真的就只有一个线程,其实也有多个线程,只不过 多个线程是在处理 网络 IO。
假设, 有多个客户端, 同时操作一个 redis 服务器 对 某个数据进行自增操作。了解多线程的应该知道,由于一般的自增不具备原子性,多个线程同时自增同一个遍历,就存在线程安全问题。
有人就要问了,当前这两个客户端, 也相当于 “并发” 的发起了上述的请求。此时就意味着是否服务器这边也会存在类似的线程安全问题?
答: 并不会, redis 服务器实际上是单线程模型,这就使得当前收到的这多个请求
是串行执行的。多个请求同时到达 redis 服务器, 也是要现在队列中排队,再等待 redis 服务器一个个的取出里面的命令去执行。微观上讲,redis 服务器是串行顺序执行这多个命令的。
redis 使用 单线程模型,还能很好的工作, 原因主要在于 redis 的核心业务逻辑, 都是短平快的。不太消耗 cpu 资源也就不太吃多核了。
使用单线程模型也是有弊端的,redis 必须要特别小心, 某个操作占用时间长, 就会阻塞其他命令的执行
5.2 redis 单线程 为什么快
redis 虽然是单线程模型, 为啥效率这么高呢? 速度这么快呢?(这里的快是参照 Mysql 之类的数据库) [重要的面试题]
-
redis 访问内存, 数据库则是访问硬盘。
-
redis 核心功能, 比数据库的核心功能更简单。
数据库对于数据的插入删除查询…,都有更复杂的功能支持。这些功能,必然要花费更多的开销。比如, 针对插入删除, 数据库中的各种约束,都会使数据库做额外的工作。
redis 干的活少, 提供的功能相比于 mysql 也是少了不少。 -
单线程模型,避免了一些不必要的线程竞争开销。
redis 每个基本操作, 都是短平快的,就是简单操作一下内存数据, 不是什么特别消耗 cpu 的操作(就算搞多个线程, 也提升不大) -
处理网络 IO 的时候, 使用了 epoll 这样的 IO 多路复用机制。
即一个线程, 就可以管理多个 socket。
针对 TCP 来说, 服务器这边每次要服务一个客户端, 都需要给这个客户端安排一个 socket。一个服务器服务多个客户端, 同时就有多个 socket。
这些 socket 并非都是无事不刻的在传输数据,很多情况下, 每个客户端和服务器之间的通信也没那么频繁,此时这么多 socket 大部分时间都是静默的,没有数据需要传输的。同一时刻,只有少数 socket 是活跃的。
IO 多路复用
(操作系统,给程序员提供的机制, 提供了一套 API,内部的功能都是操作系统内核实现的)
Linux 上提供的 IO 多路复用, 主要是三套 API:
1.select、2.poll、3.epoll (2006 左右出现)运行效率最高的机制。
C++ 可以直接使用 Linux 原生的 epoll api,Java 可以使用 NIO (标准库提供的一组类,底层就是封装了 epoll)。