【VLMs篇】07:Open-Qwen2VL:在学术资源上对完全开放的多模态大语言模型进行计算高效的预训练
1. 论文摘要介绍表格
| 项目 | 详细介绍 |
|---|---|
| 论文标题 | Open-Qwen2VL:在学术资源上对完全开放的多模态大语言模型进行计算高效的预训练 |
| 研究目标 | 解决SOTA多模态大语言模型(MLLM)复现困难、计算成本高昂、流程不透明的问题,为学术界提供一个低成本、完全开放的高性能MLLM训练方案。 |
| 核心问题 | 如何在有限的学术计算资源下,高效地预训练一个性能可与工业界模型媲美的多模态大语言模型? |
| 创新点 | 1. 完全开放(Redefining “Fully Open”): 首次将训练代码、数据过滤技术、所有预训练和微调数据完全开源,极大提升了研究的可复现性。 2. 极致的计算效率: 结合多种优化技术,仅用220个A100 GPU小时和50亿令牌就完成了预训练,远低于同类模型(如Qwen2-VL的1.4万亿令牌)。 3. 高效的数据策略: 创新性地结合了传统CLIP过滤和先进的MLLM-Filter数据过滤方法,并验证了高质量小规模数据(5M)能显著提升模型性能。 4. 训练流程优化: 采用多模态序列打包技术,减少了计算资源浪费;并使用从低到高动态图像分辨率策略,在保证性能的同时提升了预训练效率。 |
| 方法论 | 1. 数据: 精心筛选并混合了CC3M-CC12M-SBU、DataComp等数据集,最终形成约2900万的高质量图文对。 2. 架构: 基于Qwen2.5-1.5B LLM,结合SigLIP视觉编码器和自适应平均池化视觉投影器。 3. 训练: 分为预训练和监督微调(SFT)两个阶段。预训练采用序列打包和低分辨率,SFT阶段则使用高分辨率并扩展微调数据至1000万条。 |
| 主要成果 | 最终模型Open-Qwen2VL在多个多模态基准测试(如MMBench, SEEDBench)上,性能优于参数量相近的、部分开源的Qwen2-VL-2B模型,证明了该计算高效方案的有效性。 |
2. 论文具体实现流程
该论文的实现流程可以分解为数据准备、模型训练和评估三个核心阶段。
输入 (Input):
- 预训练数据:
- 原始数据集: CC3M-CC12M-SBU (CCS), LAION-400M, DataComp-Medium-128M。这些是包含海量图文对的公开数据集。
- 数据总量: 最终用于预训练的精选图文对约为2900万(包括去重)。
- 监督微调 (SFT) 数据:
- 初始微调: LLaVA-665k指令数据集。
- 扩展微调: MAmmoTH-VL-10M数据集(单图像子集)。
流转逻辑和数据流程 (Processing Logic & Data Flow):
阶段一:数据准备与预处理
- 高质量数据过滤: 这是流程的起点,也是关键。
- 对CCS和LAION数据集,使用传统的CLIP模型进行过滤,筛选出图文相关性高的样本。
- 对DataComp数据集,采用两种方法:
- DFN (Data-Filtering-Network): 使用一个强大的预训练模型筛选出Top 15%的高质量数据。
- MLM-Filter: 创新地使用一个高效的MLLM(本文中的
qwen2.5-1.5b-gpt4o)作为过滤器,根据语义理解(SU)指标打分,筛选出分数高于85的样本。
- 数据混合与去重: 将来自不同过滤器和源的数据(CCS-CLIP, DataComp-DFN, DataComp-MLM-Filter)混合在一起,形成最终的预训练数据集(约28.4M)。
- 多模态序列打包 (Sequence Packing):
- 计算每个图文对(图像转换为令牌+文本令牌)的总长度。
- 使用FFD装箱算法,将多个短的图文对“打包”成一个接近最大上下文长度(4096)的长序列。
- 这样做可以消除批处理中的填充(padding)部分,将原本会被浪费的计算资源用于处理有效数据,极大提升训练效率。
- 打包后的数据(包含图像对象和文本ID)以pickle文件格式存储。
阶段二:模型训练
-
预训练 (Pre-training):
- 模型架构: Qwen2.5-1.5B (LLM) + SigLIP (Vision Encoder) + 自适应池化投影器。
- 训练设置: 冻结视觉编码器,只训练LLM和投影器。
- 核心技术:
- 输入打包好的序列数据进行训练。
- 采用低分辨率图像策略:将图像的视觉令牌从729个压缩到144个,进一步减少计算量。
- 计算资源: 在8卡A100-40G GPU上训练1个epoch,总耗时约220 GPU小时。
- 产出: 基础的Open-Qwen2VL模型。
-
监督微调 (Supervised Fine-Tuning, SFT):
- 目标: 让模型学会遵循指令,以对话形式进行交互。
- 训练设置:
- 输入SFT指令数据(如“描述这幅画”)。
- 切换到高分辨率图像策略:使用完整的729个视觉令牌,以增强模型对图像细节的理解。
- 扩展微调: 将微调数据从66.5万条逐步扩展到1000万条,并观察模型性能的提升。
- 产出: 经过指令微调、可直接用于对话和任务的最终Open-Qwen2VL模型。
阶段三:评估
- 基准测试: 在多个公开的多模态基准测试集上(如MMBench, SEEDBench, MMStar, MathVista, POPE等)对模型进行全面评估。
- 性能对比: 将Open-Qwen2VL的评估结果与InternVL、DeepSeekVL、Qwen2-VL等同参数量级的SOTA模型进行比较。
输出 (Output):
- 基础模型检查点: 经过预训练但未进行指令微调的模型。
- 指令微调模型检查点: 最终可供用户使用的模型。
- 全套开源资料: 包括训练代码、数据过滤脚本、预处理后的数据、模型权重等,全部公开发布在GitHub和Hugging Face上。
3. 有趣的白话版详细解说
标题:我们只用一台“学术级”小超算,教出了一个比“部分天才”还聪明的“全能看图说话AI”
大家好!今天我们来聊一个超级酷的项目:Open-Qwen2VL。你可以把它想象成一个既能看懂图片又能和你聊天的AI。
这个故事的起点:一个“富人游戏”的烦恼
在AI的世界里,训练那些最顶尖的“看图说话”模型(我们叫它“多模态大语言模型”,简称MLLM),一直像是个只有科技巨头才能玩的“富人游戏”。为什么呢?
- 超级耗钱:训练它们需要用到成千上万块顶级显卡(GPU),烧掉的电费可能比一个小城市一年用的还多。这对于大学实验室这种“平民玩家”来说,简直是天方夜谭。
- 秘方不公开:那些大公司训练出厉害的AI后,通常只会把AI本身给你用,但怎么训练的“独家秘方”——比如用了哪些“食材”(数据)、“菜谱”(代码)、“烹饪技巧”(训练方法)——全都藏着掖着。这让其他研究者想学习和改进都摸不着门道。
我们的团队就想打破这个局面。我们想证明:“平民玩家”用有限的资源,只要方法得当,也能做出一个顶尖的AI!
我们的“省钱妙计”:四招炼成高效AI
我们是怎么做到的呢?主要靠这四个“省钱又高效”的妙计:
第一招:精挑细选“学习资料”,不搞题海战术
传统方法是让AI去看海量的图片和文字,觉得看得越多越好。但我们发现,很多资料质量很差,就像给学生看一堆模糊不清、内容错误的教科书,效果很差还浪费时间。
我们的做法是当一个“金牌图书管理员”:
- 我们用一个已经很聪明的AI(叫MLM-Filter)去当“质检员”,帮我们从海量图文资料里,挑出那些描述最精准、信息最丰富、质量最高的“五星好评”学习资料。
- 结果惊人!我们发现,只给AI看一小部分(大约2900万份)精挑细选的“顶级教材”,学习效率比看几万亿份“大杂烩”资料还要高!这就是“数据在精不在多”的道理。
第二招:把“小练习册”打包成“综合试卷”
想象一下,AI每次学习都是做一个“填空题”(一个图片配一小段文字)。如果这个填空题很短,那么试卷(计算单元)的大部分都是空白,这就浪费了AI的“学习时间”。
我们的“打包术”(多模态序列打包)就是:
- 把好几个短的“图文填空题”拼在一起,组成一张满满当当的“综合大试卷”。
- 这样一来,AI的每一次学习都“干货满满”,计算资源一点儿也不浪费。这个小技巧让我们的训练速度提升了一大截!
第三招:“先看大概,再看细节”的学习法
在AI刚开始学习(预训练阶段)的时候,我们没必要让它一上来就死抠图片的所有细节。
- 我们先让它看“低清版”的图片,只用144个“像素点”(视觉令牌)来代表一张图。这样它就能快速掌握图片的整体意思,学习速度飞快。
- 等到它基础打好了,需要进行“精装修”(微调阶段)时,我们再给它看“高清原图”(729个视觉令牌),让它学习细节。
这种“先粗后精”的方法,大大节省了早期训练的成本。
第四招:彻底的“开放共享”
我们不像其他团队那样藏着掖着。我们把我们的“全套秘方”都公开了:
- 训练代码:我们的“菜谱”是什么,一清二楚。
- 数据和过滤方法:我们用了哪些“食材”,怎么挑的,全部告诉你。
- 模型本身:最终做好的“大餐”也免费分享。
我们重新定义了什么叫“完全开放”。我们希望任何人,只要有一点点计算资源,都能跟着我们的方法,做出自己的AI,甚至比我们的更好!
结果怎么样?小成本,大惊喜!
我们只用了8块A100显卡(这在学术界算是不错的配置,但在工业界就是个“小作坊”),花了不到10天时间,就训练出了我们的Open-Qwen2VL。
然后我们让它去参加“AI高考”,和那些“富二代”模型(比如部分开源的Qwen2-VL-2B)比试。结果是,在很多项目上,我们的“平民战神”表现得更出色! 特别是在一个叫MMBench的综合能力测试中,我们拿了全场最高分!
我的观点和理解
这篇论文最让我兴奋的,不仅仅是它做出了一个很棒的AI,更是它所倡导的一种精神和可能性。
- AI研究的“民主化”:它用事实证明,AI前沿研究不再是科技巨头的专利。只要有好的想法和聪明的策略,学术界和小型团队也能做出世界一流的成果。这为整个AI领域的创新注入了巨大的活力。
- 数据质量的胜利:它再次强调了一个核心观点——在AI时代,高质量数据的重要性甚至超过了海量数据。未来的竞争,可能不再是比谁的数据多,而是比谁的数据“干净”和“高效”。
- 开放才是王道:在一个技术飞速发展的领域,封闭和保密只会减缓整个社区的进步速度。像Open-Qwen2VL这样彻底的开放,能让成千上万的聪明人站在巨人的肩膀上,共同把技术推向新的高度。
总而言之,Open-Qwen2VL就像一个武林高手,用精妙的招式(高效的算法)和上乘的内功(高质量数据),击败了那些只靠“大力出奇迹”的对手。它不仅是一个模型,更是一份宣言,一份写给所有AI研究者的、充满希望的“平民逆袭指南”。
4.论文翻译
摘要
复现最先进的多模态大语言模型(MLLM)的预训练过程在流程的每个阶段都面临障碍,包括高质量数据过滤、多模态数据混合策略、序列打包技术和训练框架。我们介绍了Open-Qwen2VL,这是一个完全开源的2B参数多模态大语言模型,它仅使用220个A100-40G GPU小时,就在2900万个图文对上高效地完成了预训练。我们的方法采用从低到高动态图像分辨率和多模态序列打包技术,以显著提升预训练效率。训练数据集是使用基于MLLM的过滤技术(例如MLM-Filter)和传统的基于CLIP的过滤方法精心策划的,这大幅提高了数据质量和训练效率。
Open-Qwen2VL的预训练是在加州大学圣塔芭芭拉分校(UCSB)的学术级8xA100-40G GPU上,对50亿个打包后的多模态令牌进行的,这仅是Qwen2-VL 1.4万亿多模态预训练令牌的0.36%。最终经过指令微调的Open-Qwen2VL在MMBench、SEEDBench、MMstar和MathVista等多种多模态基准测试中,表现优于部分开放的SOTA MLLM Qwen2-VL-2B,显示了Open-Qwen2VL卓越的训练效率。
我们开源了我们工作的所有方面,包括计算高效和数据高效的训练细节、数据过滤方法、序列打包脚本、WebDataset格式的预训练数据、基于FSDP的训练代码库,以及基础和指令微调后的模型检查点。我们为多模态大语言模型重新定义了“完全开放”,即完整发布:1)训练代码库,2)详细的数据过滤技术,以及3)用于开发模型的所有预训练和监督微调数据。
- 网址: https://victorwz.github.io/Open-Qwen2VL
- 代码: https://github.com/Victorwz/Open-Qwen2VL
- 模型: https://huggingface.co/weizhiwang/Open-Qwen2VL
- 数据: https://huggingface.co/datasets/weizhiwang/Open-Qwen2VL-Data
1. 引言
多模态大语言模型(MLLMs) 在多模态理解和视觉推理方面展现出强大的涌现能力,催生了能够理解和分析图像、图表及PDF文档的人工智能应用。与传统的视觉语言模型(VLMs)(在小规模模型上从零开始训练图文标题数据)不同,MLLMs通常在一个训练有素的纯文本大语言模型(LLM)上构建,然后在多样化的大规模多模态数据上进行持续预训练。然而,近期的SOTA MLLMs对于社区复现而言既非“完全开放”,也对GPU资源有限的学术机构不够计算友好。在表1中,我们比较了近期SOTA MLLMs的开放性,如VILA、MM1、Idefics、BLIP-3、Llama-3.2-Vision、Phi-3.5-Vision和Qwen2VL。即使大多数SOTA MLLMs发布了它们的基础或指令微调模型检查点,但它们在数据过滤技术、序列打包脚本、预训练数据、训练代码库等方面的核心秘诀是完全闭源的,甚至在技术报告中也隐藏了这些技术细节。
在这项工作中,我们引入了Open-Qwen2VL,一个2B参数的MLLM,它在多种多模态基准测试中超越了闭源的Qwen2-VL-2B,并实现了卓越的计算效率。Open-Qwen2VL在约50亿个经过精心策划的高质量标题数据令牌上进行预训练,这仅是Qwen2-VL 预训练1.4万亿多模态令牌的0.36%。如此卓越的数据效率使我们能够在学术级的8*A100-40G GPU计算资源上进行预训练。此外,我们采用压缩视觉投影器将729个图像块缩减为144个视觉令牌,并执行多模态序列打包以进一步提升预训练效率。
我们对预训练数据混合策略和数据过滤模型进行了全面的消融研究。最佳的预训练数据由CLIP策划的CC3M-CC12M-SBU标题数据集和由DFN-CLIP及MLM-Filter共同策划的DataComp-Medium标题数据集组成。采用高效的MLLM作为数据过滤模型显著提升了模型在各种基准测试上的能力。此外,我们将视觉监督微调(SFT)数据扩展到10M级别,以进一步增强模型能力。
我们向社区开源所有内容,以便轻松便捷地复现我们的模型Open-Qwen2VL,包括数据过滤细节、序列打包脚本、webdataset格式的预训练数据、基于FSDP的训练代码库,以及基础模型和指令微调模型检查点。同时,我们的开源代码库是第一个支持多模态大语言模型训练所有阶段的综合解决方案,包括大规模标题数据准备、质量分数生成、数据过滤、多模态序列打包、预训练、监督微调以及在多模态基准上的评估。我们为多模态LLM重新定义“完全开放”为:完整发布1)训练代码库,2)详细的数据过滤技术,以及3)用于开发模型的所有预训练和监督微调数据。我们希望证明预训练研究不仅仅是科技巨头的游戏,并鼓励学术界即使在计算资源非常有限的情况下,也能从事预训练数据和流程研究。
2. 计算高效的多模态预训练
2.1. 数据集选择与高质量数据过滤
当前先进的多模态LLM通常在大型图文标题数据集上进行持续预训练。除图文标题数据集外,一些最新的MLLM如VILA、MM1、DeepSeek-VL2也混合了图文交错数据与标题数据进行多模态预训练。混合图文标题数据和交错数据将增强MLLM的多模态上下文学习和多图像推理能力。然而,MM1表明,在预训练数据中引入图文交错文档会降低基础MLLM的零样本单图像推理和理解能力。因此,为了控制预训练数据的规模并确保预训练效率,Open-Qwen2VL专注于仅使用图文标题数据的预训练范式。
为了激励社区能够轻松复现我们的工作,我们选择了表2中显示的4个最流行的图文标题数据集,这些数据集被广泛用于开源视觉语言模型的预训练。BLIP-1发布了使用基于CLIP的过滤方法从CC3M-CC12M-SBU(CCS)组合中筛选出的高质量标题数据。LAION-400M基于CLIP图文余弦相似度实施了严格的0.3阈值,以筛选其4亿图文对的高质量数据集。我们使用img2dataset工具根据发布的图像URL下载了CCS和LAION标题数据集。我们仅下载了15M的LAION数据,以在第2.5节中进行受控规模的数据混合消融研究。
其次,我们选择DataComp-Medium-128M作为另一个预训练数据选择。根据DataComp medium过滤赛道排行榜的性能,数据过滤网络(DFN)是排行榜上排名第一的独立数据过滤器¹。我们成功下载了1.28亿原始发布的128M DataComp-Medium数据中的99.8M。然后,我们采用官方的resharder脚本²,根据DFN发布的top-15%数据uids³,选择DFN筛选的高质量子集。值得注意的是,DFN仅发布了top-15%的筛选数据,而没有发布DFN模型检查点。因此,无法根据DFN模型生成的质量分数来更改保留数据比例。对于DataComp-DFN高质量数据集,我们最终得到15M的图文标题数据。
自MLM-Filter引入以来,基于MLLM的数据过滤方法应运而生,这些方法采用高效的MLLM作为高质量数据过滤器,而非CLIP模型。MLM-Filter为高质量数据过滤提供了四个不同的图文数据质量指标,包括图文匹配(ITM)、对象细节实现(ODF)、标题文本质量(CTQ)和语义理解(SU)。根据ATIQE的结论,语义理解(SU)质量指标在基于此指标筛选的高质量数据上训练的MLLM上表现最佳。因此,我们使用mlm-filter-qwen2.5-1.5b-gpt4o⁴数据过滤模型为DataComp-Medium数据生成SU质量分数,并将过滤分数阈值设为85(满分100)。通过此阈值,我们得到8M的MLM-Filter筛选数据。
¹https://www.datacomp.ai/dcclip/leaderboard.html
²https://github.com/mlfoundations/datacomp/blob/main/resharder.py
³https://huggingface.co/datasets/apf1/datafilteringnetworks_2b/blob/main/datacomp_medium_dfn_20m_inds.npy
⁴https://huggingface.co/weizhiwang/mlm-filter-qwen2.5-1.5b-gpt4o
[表1 | 几个最先进MLLMs之间的开放性比较]
| 模型 | 数据过滤技术 | 序列打包脚本 | 预训练数据 | 预训练代码库 | 基础模型检查点 | SFT数据 | 指令模型检查点 |
|---|---|---|---|---|---|---|---|
| VILA | 无 | 无 | 开放 | 开放 | 开放 | 开放 | 开放 |
| MM1 | 封闭 | 封闭 | 封闭 | 封闭 | 封闭 | 封闭 | 封闭 |
| Idefics | 开放 | 开放 | 开放 | 开放 | 开放 | 开放 | 开放 |
| BLIP-3 | 封闭 | 封闭 | 开放 | 封闭 | 开放 | 封闭 | 开放 |
| Llama-3.2-Vision | 封闭 | 封闭 | 封闭 | 封闭 | 开放 | 封闭 | 开放 |
| Phi-3.5-Vision | 封闭 | 封闭 | 封闭 | 封闭 | 封闭 | 封闭 | 开放 |
| Qwen2VL | 封闭 | 封闭 | 封闭 | 封闭 | 开放 | 封闭 | 开放 |
| Open-Qwen2VL | 开放 | 开放 | 开放 | 开放 | 开放 | 开放 | 开放 |
我们将策划的数据与DFN-15M数据联合。去重后,我们获得了19.9M的高质量数据。
2.2. 采用从低到高图像分辨率的模型架构
我们采用了一个简单的架构,包含Qwen2.5-1.5B-Instruct LLM主干、自适应平均池化视觉投影器和SigLIP-SO-400M视觉编码器。具体来说,自适应平均池化视觉投影器包含一个自适应平均池化层,后接一个两层MLP。通过自适应平均池化层,我们可以将SigLIP输出的729个视觉块缩放到任意分辨率。我们在预训练阶段采用144个视觉令牌来表示一张图像,并在SFT阶段将分辨率提升至原始的729个视觉令牌。这种从低到高的图像分辨率显著提升了MLLM预训练的效率,并且在SFT后不会损害最终MLLM的高分辨率图像理解能力。
Open-Qwen2VL没有采用2d-多模态RoPE和朴素动态分辨率等高级设计来节省计算资源并确保训练效率。此外,对于学术计算资源而言,下载并以原始分辨率保存图像需要巨大的磁盘空间,这在大多数学术机构中是不可用的。在我们使用img2dataset下载数据的过程中,我们将图像的较短边调整为512像素并保持宽高比,这使我们无法在预训练阶段采用朴素的动态分辨率。
在预训练和SFT阶段,我们都冻结了视觉编码器的参数,并使投影器和LLM主干的参数可训练,以节省更多计算资源。然而,最近的研究表明,使视觉编码器可训练可以进一步增强MLLM的视觉理解能力。我们将其作为未来研究的消融实验。
[表2 | Open-Qwen2VL预训练的图文标题数据集]
| ID | 数据集 | 过滤模型 | 图文对数量 | 资源 |
|---|---|---|---|---|
| 1 | CCS | CLIP | 8.5M | https://github.com/salesforce/BLIP |
| 2 | DataComp | DFN | 15M | huggingface:apf1/datafilteringnetworks_2b |
| 3 | LAION | CLIP | 15M | https://github.com/salesforce/BLIP |
| 4 | DataComp | MLMFilter & DFN | 19.9M | huggingface:weizhiwang/Open-Qwen2VL-Data |
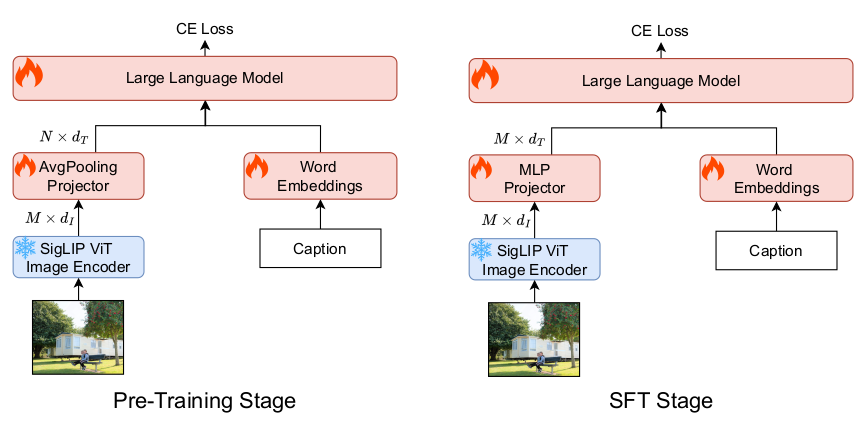
2.3. 多模态序列打包
由于大规模图文数据的长度各不相同,简单地根据相似长度对一组样本进行批处理,并填充到最长序列的长度,将导致每个训练批次中存在大量的填充令牌。如此大量的填充令牌会导致严重的计算浪费和训练效率低下。因此,我们引入了多模态序列打包,将图文标题数据重新组合成长度最接近4096上下文长度的序列组。
多模态序列打包的算法在算法1中呈现。由于我们将所有图文标题数据下载并打包成webdataset格式,且每个webdataset tar文件恰好包含10k个图文标题数据,因此我们提出的多模态序列打包旨在将这10k对数据重新组合成一组上下文长度为4096的多模态序列。

多模态序列打包涉及三个主要步骤:计算每个图文标题样本的多模态长度,将数据重组为几个容器(bin),其中每个容器的总长度最接近4096,以及连接input_ids向量和pillow格式的图像。我们采用首次适应递减(FFD)装箱算法将每个图文标题数据打包到几个容器中。我们还遵循LLaVA的做法,在每个图文标题的开头插入一个<image>占位符令牌。我们使用默认的序列结束令牌,以及<|im_end|>令牌作为每个图像标题文本之间的分隔符。
我们将每个打包的多模态序列存储为一个pickle文件,因为pickle支持将不同格式的数据(如pillow图像和torch input_ids张量)存储在单个文件中。最终,每个pickle文件包含以下字典,用于每个打包的多模态序列:
- “images”: pillow图像对象的列表;
- “input_ids”: 带有图像占位符令牌的torch Long Tensor;
- “lengths”: 一个整数列表,用于记录每个图文标题数据的多模态长度。
2.4. 训练基础设施和代码库
我们基于Prismatic-VLM开发了我们的训练代码库。原始代码库仅支持对单图像指令进行SFT,我们对其数据加载器和批处理准备部分进行了大量修改,以支持在一个序列中包含多个图像的多模态打包序列。我们保留了其完全分片数据并行(torch-FSDP)训练器,我们发现与使用DeepSpeed-Zero3的LLaVA代码库相比,它显著加快了训练速度。尽管FSDP和DeepSpeed-Zero3利用了相同的模型分片算法,我们基于FSDP的实现比DeepSpeed的实现每个训练步骤快约17%,这与Karamcheti等人报告的发现一致。
[表3 | 在不同预训练数据混合上预训练并在受控的LLaVA-665k指令上微调的MLLMs的基准性能。每个数据集的备注:1: CCS-CLIP; 2: DataComp-DFN; 3: LAION-CLIP; 4: DataComp-MLM-Filter & DFN。]
| 基准测试 | 1+2 (23.5M) | 1+3 (23.5M) | 1+2+3 (38.5M) | 1+4 (28.4M) |
|---|---|---|---|---|
| 通用基准 | ||||
| MMMUval | 38.9 | 37.2 | 36.7 | 38.0 |
| MMBenchdev | 75.6 | 75.9 | 75.9 | 77.3 |
| SEEDBench – Imgdev | 68.9 | 69.6 | 68.9 | 68.7 |
| MMStar | 39.6 | 41.7 | 41.7 | 41.3 |
| OCR VQA | ||||
| AI2Dtest | 56.3 | 55.5 | 57.3 | 56.8 |
| TextVQAval | 55.1 | 57.4 | 57.4 | 57.0 |
| 数学推理 | ||||
| MathVistatestmini | 28.6 | 28.1 | 28.7 | 28.6 |
| 幻觉 | ||||
| POPE | 79.2 | 80.1 | 77.7 | 80.1 |
| 平均 | 55.3 | 55.4 | 55.5 | 56.0 |
2.5. 数据混合的消融研究
在准备并序列化打包了4个图文标题数据集后,我们进行了消融研究,以调查不同数据混合对最终MLLM性能的影响。由于四个数据集之间有16种组合,我们只考虑了4种组合。CCS-CLIP数据是固定的,我们逐步加入其他三个数据集。对于每个数据集组,我们在打包的多模态序列上对MLLM进行一个epoch的预训练,然后在使用LLaVA-665k指令数据集对基础MLLM进行微调。训练细节和超参数可在附录表7中找到。然后我们在AI2D-test、TextVQA-val、POPE、MMMU-val、MMBench-v1.0-dev、SEEDBench-imge-dev、MMStar和MathVista-test-mini等多模态基准上评估每个模型消融。
结果。每个使用不同数据混合预训练和微调的MLLM的基准测试结果呈现在表3中。由于DataComp-DFN和LAION都是网络爬取的数据,并采用相似的基于CLIP的数据过滤技术,这两个数据集与CCS的数据混合取得了非常相似的模型性能。此外,简单地混合CCS-CLIP、DataComp-DFN和LAION-CLIP三个数据集并不能获得更好的性能,这可能是由于DataComp-DFN数据和LAION-CLIP数据之间的高度数据同质性造成的。令人惊讶的是,加入少量(5M)由一种不同的、高效的基于MLLM的数据过滤器(MLM-Filter)筛选的高质量数据,可以显著提升模型性能,平均性能提升+0.5。我们推测,基于MLLM的数据过滤器可能为预训练集引入了不同的数据分布,为增强MLLM的能力带来了新知识。
最终,在最佳数据混合上预训练Open-Qwen2VL大约需要220个A100-40G GPU小时,在LLaVA-665k指令上的SFT需要48个A100-40G GPU小时。
3. 扩大监督微调
3.1. SFT数据集
在预训练混合的消融研究之后,我们进一步将视觉SFT数据从LLaVA-665k扩展到MAmmoTH-VL-10M,以进一步增强MLLM的理解和推理能力。我们仅使用10M的单图像子集进行视觉SFT,不包括额外的LLaVA-OneVision-2M用于在混合图像和视频数据上进行进一步SFT。MAmmoTH-VL-10M数据如果采用原始的LLaVA风格数据加载器,在分布式多进程中将完整的10M json文件数据加载到内存中需要超过200GB的CPU内存。为了适应我们服务器有限的CPU内存,我们将10M完整json数据中的每个数据样本存储到单个json文件中,同时生成一个10M索引文件用于加载到内存。每个索引包含数据样本json的路径、文本或图文数据的布尔值,以及用于批处理的预计算图文数据长度。SFT超参数也遵循附录表7。
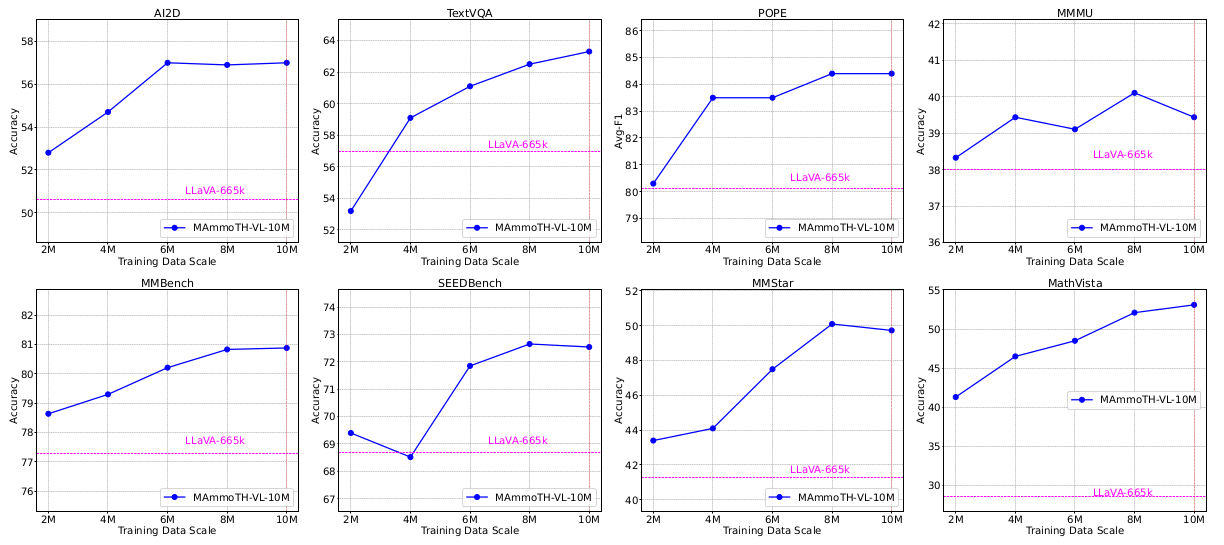
3.2. 扩展效果与结果
我们每2M SFT指令保存一次检查点,在批量大小为128的情况下是15625步。我们在图2中展示了每个保存检查点的基准性能。我们可以得出结论,扩大SFT显著提高了模型在各种多模态基准上的性能。大多数基准测试如POPE、MMMU、MMBench和SEEDBench的性能在SFT规模达到8M指令时收敛,并且在最后的2M数据上没有提升。TextVQA和MathVista的性能曲线与其他不同,呈现出随数据规模稳定提升的趋势。这可能是由于我们策划的预训练标题数据集中缺乏此类预训练的数学或OCR数据,使得视觉数学推理和基于文本的VQA成为分布外任务。对于通用知识型基准MMMU、SEEDBench和MMStar,我们甚至在最后的6M指令调整数据中观察到轻微的性能下降。
我们比较了最终的Open-Qwen2VL模型与最先进的部分开放MLLMs,如InternVL2.5-2B-MPO、DeepSeekVL-2-Tiny和Qwen2-VL-2B-Instruct,在一系列通用多模态基准、OCR VQA数据集、多模态数学推理基准和幻觉基准上的表现。从表4的结果可以得出,与其他2B参数的SOTA MLLM相比,Open-Qwen2VL在各项基准上展示了有竞争力的性能。它在MMBench中表现尤为出色,取得了80.9的最高分,同时在SEEDBench和MMStar基准上保持了可比的性能。此外,Open-Qwen2VL在MMBench、SEEDBench-img、MMStar和MathVista上优于最相关的竞争对手Qwen2-VL-2B-Instruct,而其训练所用的令牌数仅为Qwen2-VL的0.35%。然而,它在AI2D和TextVQA的OCR VQA任务上表现相对较弱。这是因为Open-Qwen2VL的预训练数据不包含像SynthDoG或LAIONCOCO-OCR这样的OCR特定标题数据集。简单地引入这类与OCR相关的预训练数据将显著提升MLLM的OCR-VQA任务性能。
4. 分析
4.1. 序列打包对多图像上下文学习与推理的影响
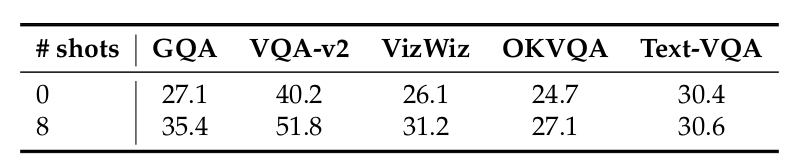
Flamingo 提出了MultiModal MassiveWeb (M3W) 数据集,使用标题数据构建伪交错数据结构,以激发MLLM的多模态上下文学习能力。多模态序列打包也构建了类似的伪图文交错数据结构。因此,我们进行了实验,以评估在打包的多模态序列上训练的预训练基础MLLM的少样本多模态上下文学习能力。我们在GQA、VQA-v2、VizWiz、OKVQA和Text-VQA数据集上评估了在CCS-CLIP和DataComp-MLM-Filter & DFN的标题数据混合上训练的基础非SFT MLLM。该基础模型是我们根据表3中预训练数据混合的消融研究得到的最佳模型。我们为8-shot多模态上下文学习实验选择了5个随机种子,并报告了5个随机种子的平均性能。
[表格:表4 | Open-Qwen2VL与其他2B参数SOTA MLLMs的基准性能]
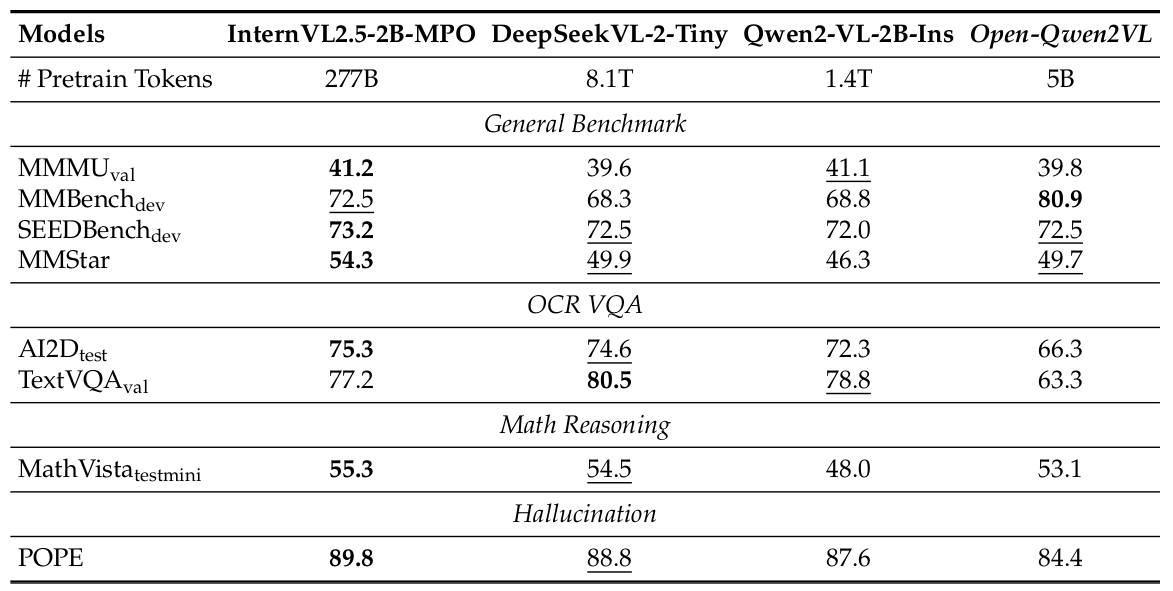
表5中的结果表明,使用打包多模态序列训练的基础MLLM可以从多模态演示示例中学习以很好地完成任务。与0-shot推理相比,8-shot上下文学习在VQA数据集上可以获得+3%到+12%的性能提升。这也证明了执行多模态序列打包的必要性和重要性,因为它可以增强MLLM的多模态上下文学习能力。
4.2. 解冻视觉编码器参数的影响
大多数SOTA MLLMs如InternVL-2.5表明,在SFT阶段使视觉编码器可训练将增强MLLM的多模态理解能力。因此,我们对在CCS+DataComp-MLM-Filter&DFN数据混合上预训练的基础非SFT MLLM进行了这样的消融研究。我们使用LLaVA-665k数据作为视觉SFT数据集,并评估了在SFT阶段视觉编码器冻结和可训练的两种SFT后的MLLM。表6中的结果表明,在SFT阶段使视觉编码器参数可训练可以获得更好的平均性能,尽管在MMMU基准上存在显著的性能下降。

5. 相关工作
开源多模态大语言模型。像GPT-4o和Claude-3.7-Sonnet这样的闭源MLLM具有强大的多模态理解和推理能力。为了复制闭源MLLM的强大能力,工业界的研究团队开发了部分开源的强大MLLM,包括InternVL-2.5、DeepSeek-VL2和Qwen2.5-VL,这些模型可以实现与闭源模型相当的能力。然而,这些模型的训练数据、代码库和数据过滤细节并未开源以供复现。
大规模图文数据。从ImageNet开始,大规模图像数据集极大地推动了计算机视觉和多模态基础模型的进步。…(此处省略对数据集发展的详细回顾)…
高质量图文数据过滤。超越了构建图文数据集中传统的基于规则或启发式的数据过滤方法,用于训练对比VLM的大规模图文数据集采用基于CLIPScore的过滤方法进行高质量数据筛选。…(此处省略对数据过滤技术发展的详细回顾)…
6. 结论
我们证明了高效的基于MLLM的高质量数据过滤技术和精心设计的数据混合策略可以实现开发SOTA MLLM的计算高效预训练。采用多模态序列打包和带有平均池化层的动态图像令牌数量可以进一步提升这种预训练效率。最终得到的MLLM,Open-Qwen2VL,在多种多模
态基准上优于部分开放的MLLM Qwen2-VL-2B,而Open-Qwen2VL的训练仅使用了Qwen2-VL 0.36%的预训练令牌。该训练在学术级计算资源上进行,并证明了先进的训练流程和数据过滤可以克服计算资源的限制。我们希望Open-Qwen2VL能够激励学术界进行完全开放、计算高效的多模态预训练研究。