分布式专题——10.1 ShardingSphere介绍
1 介绍
1.1 ShardingSphere
-
官网:Apache ShardingSphere;

-
Apache ShardingSphere 是一款分布式 SQL 事务和查询引擎,能通过数据分片、弹性伸缩、加密等能力,对任意数据库进行增强,并非直接做数据存储,而是整合其他数据库产品,定位为 “Database plus”;
-
发展历程:
- 起源与早期:2015 年诞生于当当网内部,最初叫 ShardingJDBC;
- 发展与开源:2016 年被带入京东数科继续开发,历经多家大型互联网企业考验后,2017 年开源,从仅关注关系型数据库增强的 ShardingJDBC,升级为以数据分片为基础的数据生态圈,更名为 ShardingSphere;
- 项目升级:2020 年 4 月,成为 Apache 软件基金会的顶级项目,发展为业界分库分表最成熟的产品;
-
ShardingSphere 这个词可以分为两个部分:
- “Sharding”:代表数据分片,这是核心功能,可将任意数据库组合成分布式数据库,提供数据集集群服务;
- “Sphere”:代表生态,说明 ShardingSphere 不是单一框架或产品,而是由多个框架、产品构成的完整技术生态;
- 核心产品:成熟的有 ShardingJDBC、ShardingProxy;
- 子项目:用于数据迁移的 ElasticJob;还有基于公有云的云上服务 ShardingSphere-on-Cloud;
-
经过多年发展,ShardingSphere 形成围绕分库分表核心的技术生态,核心功能涵盖数据分片、分布式事务、读写分离、高可用、数据迁移、联邦查询、数据加密、影子库、DistSQL 等庞大技术体系;
特性 定义 数据分片 数据分片,是应对海量数据存储与计算的有效手段。ShardingSphere 基于底层数据库提供分布式数据库解决方案,可以水平扩展计算和存储 分布式事务 事务能力,是保障数据库完整、安全的关键技术,也是数据库的核心技术。基于 XA 和 BASE 的混合事务引擎,ShardingSphere 提供在独立数据库上的分布式事务功能,保证跨数据源的数据安全 读写分离 读写分离,是应对高压力业务访问的手段。基于对 SQL 语义理解及对底层数据库拓扑感知能力,ShardingSphere 提供灵活的读写流量拆分和读流量负载均衡 数据迁移 数据迁移,是打通数据生态的关键能力。ShardingSphere 提供跨数据源的数据迁移能力,并可支持重分片扩展 联邦查询 联邦查询,是面对复杂数据环境下利用数据的有效手段。ShardingSphere 提供跨数据源的复杂查询分析能力,实现跨源的数据关联与聚合 数据加密 数据加密,是保证数据安全的基本手段。ShardingSphere 提供完整、透明、安全、低成本的数据加密解决方案 影子库 在全链路压测场景下,ShardingSphere 支持不同工作负载下的数据隔离,避免测试数据污染生产环境 -
目前 ShardingSphere 已经演进到了 5.x 大版本。在这个大版本中,ShardingSphere 的核心是可插拔。其核心设计哲学就是连接、增强以及可拔插。
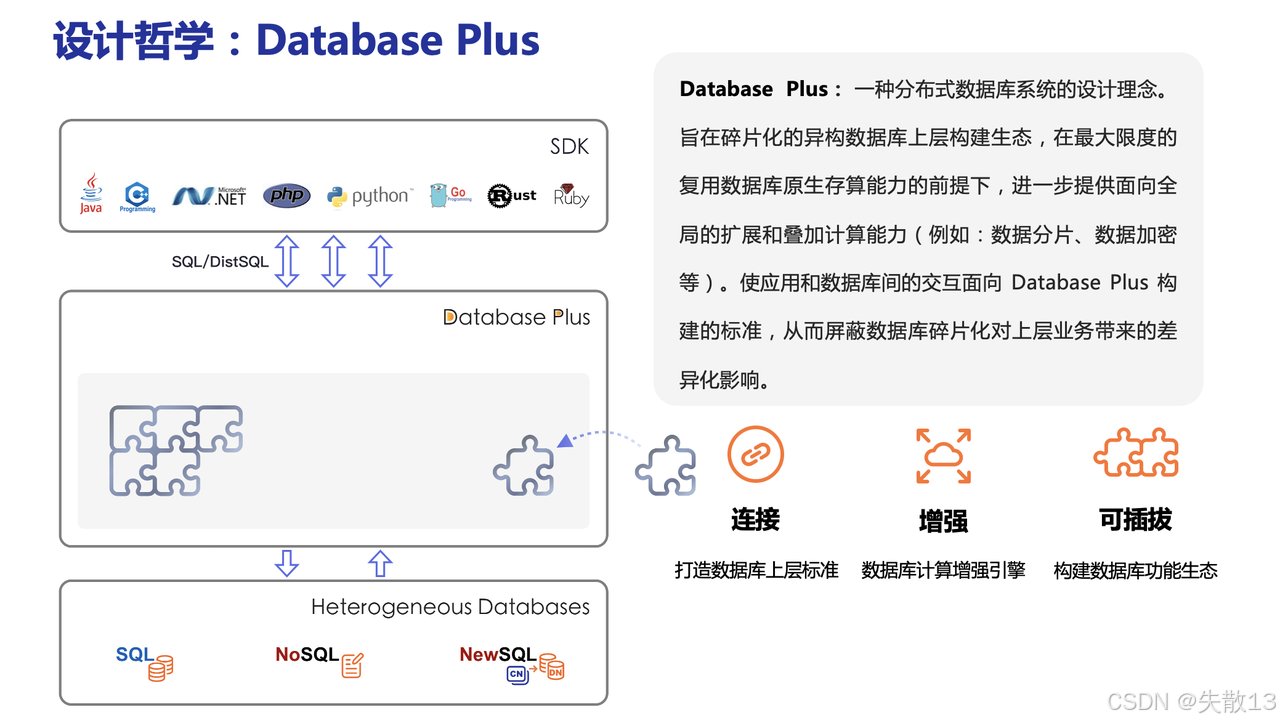
1.2 设计哲学:Database Plus
1.2.1 概述
-
“Database Plus”是一种分布式数据库系统的设计理念;
-
核心目标:旨在碎片化的异构数据库上层构建生态,在最大限度复用数据库原生存算能力的前提下,进一步提供面向全局的扩展和叠加计算能力(如数据分片、数据加密等)。让应用和数据库间的交互遵循“Database Plus”构建的标准,从而屏蔽数据库碎片化对上层业务带来的差异化影响;
-
架构层次:
-
上层(SDK 层):支持 Java、.NET、PHP、Python、Go、Rust、Ruby 等多种开发语言,通过 SQL/DistSQL 与中间的“Database Plus”层进行交互;
-
中间层(Database Plus 层):处于异构数据库与上层应用之间,起到整合、扩展的核心作用,能像拼图一样,将不同的数据库能力进行组合与拓展;
-
下层(异构数据库层):包含 SQL、NoSQL、NewSQL 等各类数据库,是数据存储与计算的基础层。
-
1.2.2 连接:打造数据库上层标准
- 连接:通过灵活适配数据库协议、SQL 方言以及数据库存储,快速构建多模异构数据库上层的标准。同时,借助内置的 DistSQL,为应用提供标准化的连接方式,让应用能更便捷、统一地与各类数据库交互。
1.2.3 增强:数据库计算增强引擎
- 增强:在原生数据库基础能力之上,提供两方面增强能力:
- 分布式增强:突破底层数据库在计算与存储上的瓶颈,提升数据库的处理能力与存储拓展性;
- 流量增强:通过对流量的变形、重定向、治理、鉴权及分析等能力,为数据应用提供更为丰富的增强能力,优化数据使用体验与安全性。
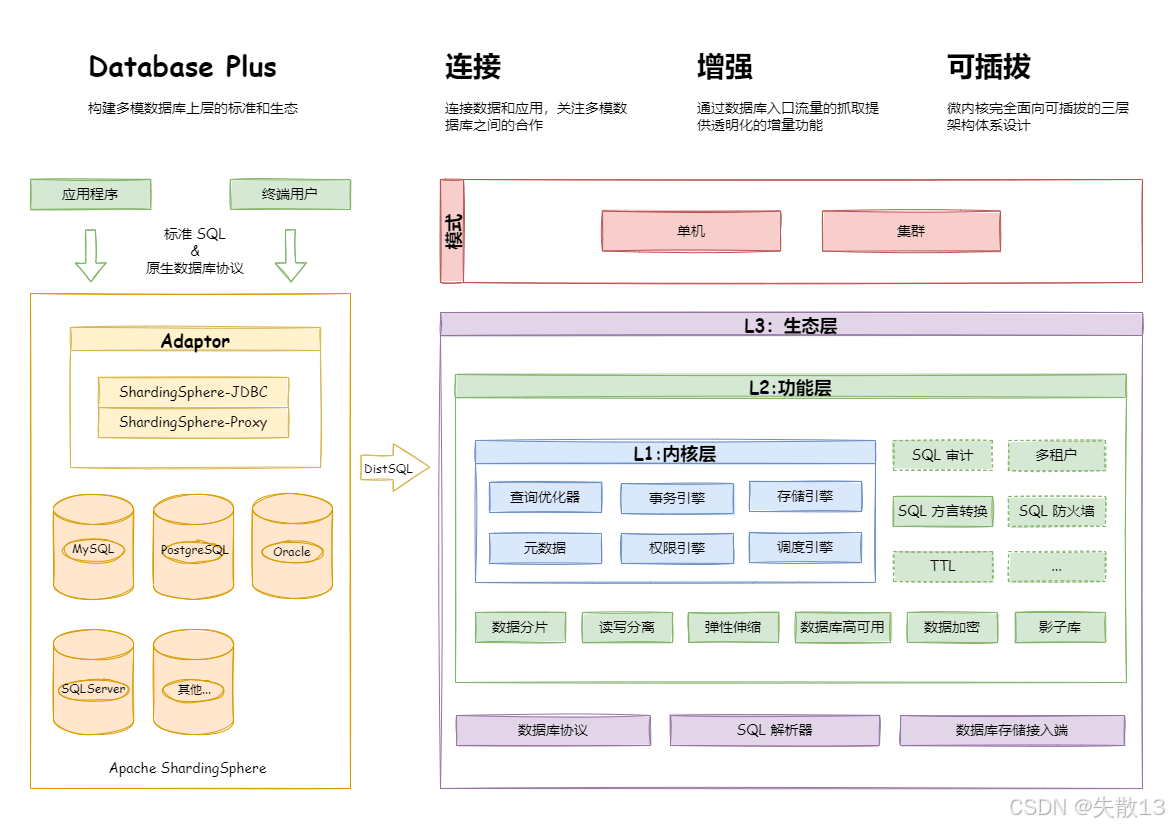
1.2.4 可插拔:构建数据库功能生态
-
可插拔:构建数据库功能生态,各种功能模块可灵活地接入或移除,满足不同场景下的需求;
-
Apache ShardingSphere 的可插拔架构分为 L1 内核层、L2 功能层、L3 生态层:
- L1 内核层:是数据库基本能力的抽象,所有组件必须存在,但具体实现方式可通过可插拔的方式更换。主要包含查询优化器、分布式事务引擎、分布式执行引擎、权限引擎和调度引擎等,为数据库提供基础且核心的支撑;
- L2 功能层:用于提供增量能力,所有组件均是可选的,可包含零至多个组件。组件之间完全隔离、互无感知,多组件可通过叠加的方式相互配合使用。主要有数据分片、读写分离、数据加密、影子库等功能,用户还可基于 Apache ShardingSphere 定义的顶层接口,进行自定义功能的定制化扩展,且无需改动内核代码;
- L3 生态层:用于对接和融入现有数据库生态,包含数据库协议、SQL 解析器和存储适配器,分别对应 Apache ShardingSphere 以数据库协议提供服务的方式、SQL 方言操作数据的方式以及对接存储节点的数据库类型,助力其更好地与现有数据库生态融合。
2 部署形态
- ShardingSphere 最为核心的产品有两个:
- 一个是 ShardingSphere-JDBC,这是一个进行客户端分库分表的框架;
- 另一个是 ShardingSphere-Proxy,这是一个进行服务端分库分表的产品;
- 他们代表了两种不同的分库分表的实现思路。
2.1 ShardingSphere-JDBC独立部署
-
ShardingSphere-JDBC 是轻量级 Java 框架,在 Java 的 JDBC 层提供额外服务。它以客户端直连数据库,通过 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
-
适用于任何基于 JDBC 的 ORM 框架,如 JPA、Hibernate、Mybatis、Spring JDBC Template,也支持直接使用 JDBC;
-
支持任何第三方的数据库连接池,如 DBCP、C3P0、BoneCP、HikariCP 等;
-
支持任意实现 JDBC 规范的数据库,目前支持 MySQL、PostgreSQL、Oracle、SQLServer 以及任何可使用 JDBC 访问的数据库;
-
-
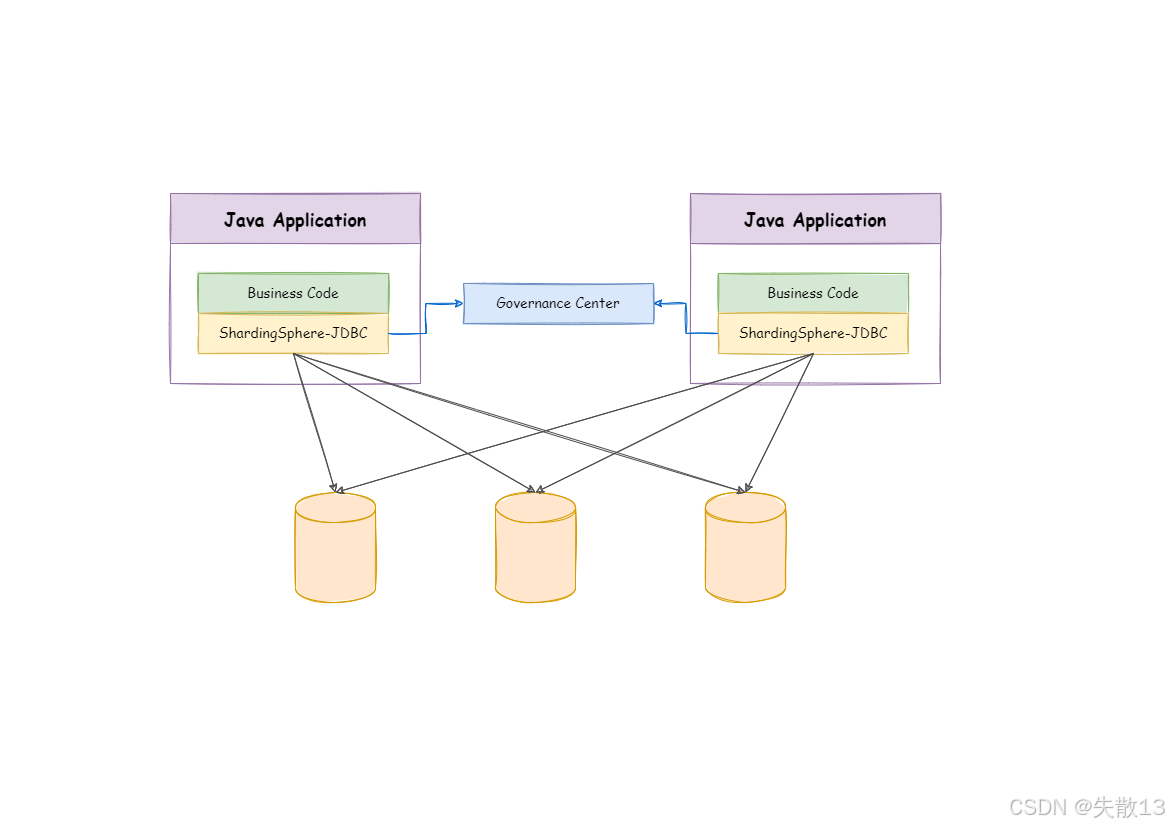
架构图:
-
Java Application(Java 应用):包含业务代码(Business Code)和 ShardingSphere-JDBC。业务代码是应用的核心业务逻辑部分,ShardingSphere-JDBC 作为增强层,为业务代码与数据库的交互提供分库分表等额外能力;
-
Governance Center(治理中心):用于对 ShardingSphere-JDBC 进行治理,比如配置管理、状态监控等,让多个 Java 应用中的 ShardingSphere-JDBC 能协同工作,保证分库分表等规则的一致性;
-
数据库:存储数据的底层载体,ShardingSphere-JDBC 对应用隐藏了数据库的分库分表等细节,让应用能像操作单一数据库一样进行操作。
-
2.2 ShardingSphere-Proxy独立部署
-
ShardingSphere-Proxy 是透明化的数据库代理端,通过实现数据库二进制协议,为异构语言提供支持。目前提供 MySQL 和 PostgreSQL 协议,能透明化数据库操作,对数据库管理员(DBA)更加友好。
-
向应用程序完全透明,可直接当做 MySQL/PostgreSQL 使用;
-
兼容 MariaDB 等基于 MySQL 协议的数据库,以及 openGauss 等基于 PostgreSQL 协议的数据库;
-
适用于任何兼容 MySQL/PostgreSQL 协议的客户端,如 MySQL Command Client、MySQL Workbench、Navicat 等;
-
-
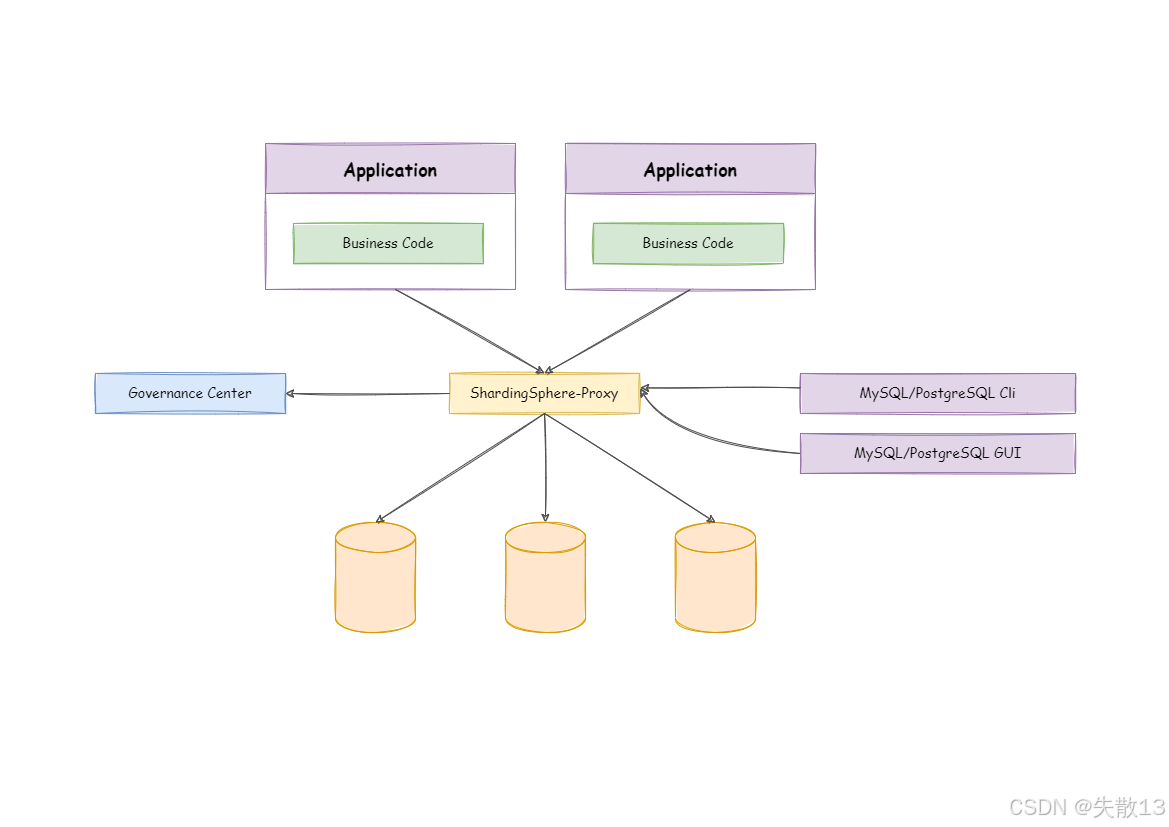
架构图:
-
Application(应用):包含业务代码(Business Code),应用通过 ShardingSphere-Proxy 与数据库交互,无需感知分库分表等底层细节;
-
Governance Center(治理中心):用于对 ShardingSphere-Proxy 进行治理,比如配置管理、状态监控等,保障代理服务的稳定与规则一致性;
-
ShardingSphere-Proxy:作为数据库代理核心,接收应用、MySQL/PostgreSQL 命令行客户端(Cli)、图形界面客户端(GUI)的请求,转发并处理后与底层数据库交互,实现分库分表等功能;
-
数据库:存储数据的底层载体,ShardingSphere-Proxy 隐藏了数据库的分库分表等实现,让各类客户端能便捷操作。
-
2.3 ShardingSphere混合部署架构
-
ShardingSphere-JDBC 采用无中心化架构,与应用程序共享资源,适用于 Java 开发的高性能的轻量级 OLTP 应用; ShardingSphere-Proxy 提供静态入口以及异构语言的支持,独立于应用程序部署,适用于 OLAP 应用以及对分片数据库进行管理和运维的场景;
对比项 ShardingSphere-JDBC ShardingSphere-Proxy 支持数据库 任意支持 JDBC 规范的数据库 MySQL、PostgreSQL 及兼容其协议的数据库(如 MariaDB、openGauss) 连接消耗数 高(与客户端紧密结合,每个客户端连接都需处理) 低(独立代理,集中管理连接) 异构语言支持 仅 Java(基于 Java 的 JDBC 层) 任意(通过数据库二进制协议,支持多语言客户端) 性能 损耗低(客户端直连,无额外网络代理开销) 损耗略高(多了代理层的网络与处理开销) 无中心化 是(无独立中心节点,客户端自带能力) 否(独立部署的服务,属于中心化组件) 静态入口 无 有(作为独立服务,有固定的访问入口) -
在 ShardingSphere-JDBC 和 ShardingSphere-Proxy 的架构图中都出现的 Governance Center,类似于微服务架构中的配置中心,可使用第三方服务(如 Zookeeper、Nacos、Etcd 等)统一管理分库分表的配置信息,方便对配置进行集中化、动态化的管控;
-
由于 ShardingSphere-JDBC 和 ShardingSphere-Proxy 都支持通过 Governance Center 将配置信息交由第三方服务管理,因此能支持混合部署架构。即部分应用使用 ShardingSphere-JDBC(轻量级,适合 Java 应用嵌入),部分场景通过 ShardingSphere-Proxy(独立代理,支持多语言客户端),且它们的配置由同一 Governance Center 统一管理,灵活适配不同业务需求与技术栈;
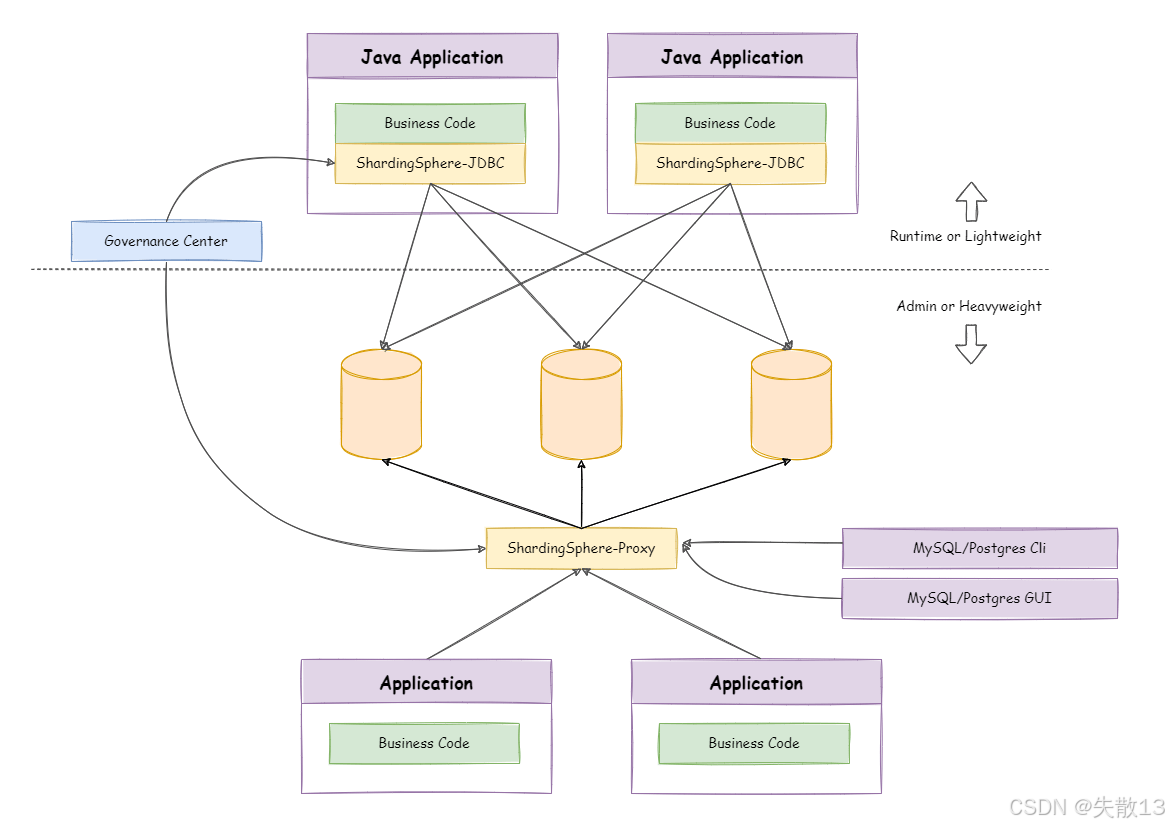
3 分库分表
3.1 为什么要分库分表?
-
数据库是一个应用的核心价值载体,也是开发必须掌握的工具,此前已学习过MySQL调优(如优化SQL、索引等)。但随着互联网应用规模扩大,数据库频繁成为性能瓶颈,面临三大核心问题:数据量过大、访问过于频繁、读写速度过快。而传统的调优方式在海量数据冲击下,效果有限。因此现在互联网对于数据库的使用也越来越小心谨慎。例如添加 Redis 缓存、增加 MQ 进行流量削峰等。但是数据库本身如果性能得不到提升,这就相当于是水桶理论中的最短板;
-
要提升数据库的性能,最直接的思路就是直接优化数据库本身,比如优化 MySQL 配置、SQL 逻辑、索引结构,甚至像大厂那样修改 MySQL 源码。但是这种思路在面对互联网环境时,会有很多非常明显的弊端:
- 无法应对数据量和业务量的快速增长,易出现性能瓶颈、服务宕机;
- 单点部署的数据库无法保证高可用(一旦服务器故障,服务中断);
- 单点部署无法水平扩展,难以应对业务爆发式增长(服务器存储、处理能力有限);
-
这些问题背后的核心还是数据:数据是数据库的核心,其重要性甚至超过服务本身:需保证数据持续稳定写入,且不能因服务故障丢失。而现在大型互联网应用的数据量动辄几千万、上亿,即便压缩后也可能超过单台服务器的存储能力。而服务器的单点部署,就像是把“鸡蛋放一个篮子”那样子:服务器崩溃可能导致数据丢失,且这些问题无法通过单纯优化 MySQL 或服务器配置解决。
3.2 分库分表的优势
-
上面提到的最直接的思路不行,自然就需要换种解决方式了:
- 我们可以像微服务架构一样,来维护数据库的服务,如同微服务将单体应用拆分为多个独立服务,数据库也可从单体服务升级为数据库集群;
- 通过集群化实现全方位解放数据库性能瓶颈,并借助水平扩展灵活提升存储能力——这就是分库分表的核心思路;
-
分库分表通过将大型数据库拆分为多个小型数据库/表,能从多维度优化系统,具体优势如下:
-
提高系统性能:拆分后,每个小型数据库/表仅处理部分数据,减少单库/单表的数据量和访问压力,从而提升并发处理能力(同时处理更多请求)和查询速度(数据量小,检索更快);
-
提高系统可用性:分库分表可配合数据复制,将数据存储在多个数据库中。若某一数据库崩溃,其他数据库可接管其工作,避免单点故障导致整个系统瘫痪,保障服务持续运行;
-
提高系统可扩展性:当数据量增长时,无需替换整个数据库(成本高、风险大),只需新增更多数据库或表即可承载新增数据,实现水平扩展,灵活应对业务增长;
-
提高系统灵活性:可根据数据特性针对性优化,例如将高频访问的数据放在性能更强的数据库中,将特定类型数据(如订单、用户)拆分到专属表中,按需调整存储和处理策略;
-
降低系统成本:拆分后单个数据库/表对资源(硬件、存储)的需求降低,可使用更经济的设备;同时系统效率提升,减少资源浪费,降低整体运营成本。
-
3.3 分库分表的挑战
-
很多人认为分库分表很简单:数据太多就拆到多个库/表,多建几个JDBC连接、改改SQL就行。但这种想法是错误的:分库分表并非简单的“物理拆分”,而是需要一整套分布式解决方案,背后涉及大量复杂问题。
-
与微服务不同,数据库服务几乎零试错成本:
-
在微服务阶段,从单机架构升级到微服务架构是很灵活的,中间很多细节步骤都可以随时做调整:
- 比如对于微服务的接口限流功能,并不需要一上来就用 Sentinel 这样复杂的流控工具。一开始不考虑性能,自己实现限流是很容易的事情;
- 然后可以慢慢尝试用 Guava 等框架提供的一些简单的流控工具进行零散的接口限流。直到整个应用的负载真正上来了之后,对流控的要求更高更复杂了,再开始引入 Sentinel 进行统一流控;
-
而对于数据库就不一样了,数据库的核心是数据,数据的安全性比服务本身更重要:若分库分表初期方案不成熟、数据规划不合理,问题会随数据永久沉淀,成为后续调整的最大障碍;
-
-
所以:在决定分库分表之前,必须充分考量所有问题,若未想清楚数据的存储、计算、使用逻辑,切勿在真实项目中贸然实施;
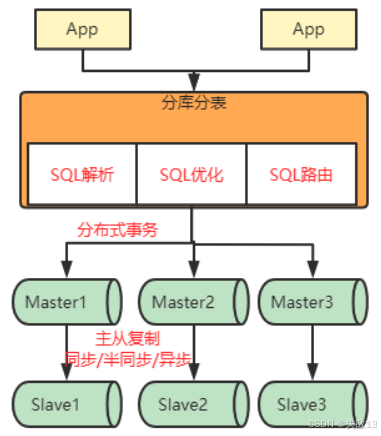
-
分库分表,也称为 Sharding(数据分片),Sharding 其实比中文的“分库分表”更贴切地描述了分库分表的本质——将数据拆分到不同数据片。由于数据往往是一个应用的基础,随着数据从单体服务拆分到多个数据分片,应用层面也需要面临很多新的问题。比如:
-
主键避重问题:数据分散在多个库/表后,单库生成的ID无法保证全局唯一,需设计全局主键避免跨库主键重复;
-
数据备份问题:数据库从单机变为集群后,整体稳定性可能下降。需保证在部分服务不稳定时,集群仍能正常运行,同时需重点保障数据安全性;
-
数据迁移问题:集群扩缩容时,数据需随服务迁移,如何在不影响业务的前提下完成迁移是关键;
-
分布式事务问题:单机数据库的事务机制可保证数据一致性,但分库分表后,数据分布在不同库/服务器,会产生分布式事务难题;
-
SQL路由问题:数据分散在多个库后,执行SQL时需快速定位目标数据所在的库/表,将请求转发到对应节点,以提升检索效率;
-
跨节点查询与归并问题:跨节点查询时,每个节点仅返回部分数据,需对结果进行归并(如处理
limit、order by等操作),逻辑复杂;
-
-
在实际项目中,遇到的问题还会更多。所以 Sharding 其实是一个很复杂的问题,往往很难通过项目定制的方式整体解决。因此,大部分情况下,都是通过第三方的服务来解决 Sharding 的问题。比如:
-
NewSQL产品(如TiDB、ClickHouse、Hadoop):将数据问题整体封装,提供 Sharding 方案,但产品较重,灵活性较低;
-
轻量型中间件:基于传统数据库,通过软件层面解决多库数据问题,更灵活。例如早期的 MyCat,以及 ShardingSphere;
-
-
最后,何时开始考虑分库分表呢?
- 当数据量过大导致数据库服务器压力过高时,需考虑分库分表;
- 当然这无绝对标准,需结合项目实际。业界较权威的参考是阿里开发手册:预估3年内单表数据超500万条,或单表大小超2G,建议考虑分库分表。