KronosTokenizer结构解析
文章目录
- 源码
- 整体结构(__init__部分)
- 1. 类继承结构
- 2. 初始化参数
- 模型维度参数
- 网络层数参数
- Dropout 参数
- BSQuantizer 参数
- 核心组件
- 1. 嵌入层
- 2. 编码器 (Encoder)
- 3. 解码器 (Decoder)
- 4. 量化相关层
- 5. BSQuantizer
- 数据流程
- 1. 前向传播 (forward)
- 2. 编码过程 (encode)
- 3. 解码过程 (decode)
- 调试的过程
- 1. 创建和初始化 KronosTokenizer
- 2. 基本前向传播
- 3. 编码-解码循环测试
- 导入模型参数和不导入模型参数的代码
- 可视化
- 训练的代码
Kronos 是首个用于金融 K 线(蜡烛图)的开源基础模型,在来自全球 45 家以上交易所的数据上进行了训练
Kronos的github
KronosTokenizer 模块
- 使用混合量化方法的分词器
- 结合了编码器-解码器Transformer结构
- 使用一个Binary Spherical Quantization (BSQuantizer)二值球形量化结构来对输入数据进行压缩和解压。
源码
class KronosTokenizer(nn.Module, PyTorchModelHubMixin):"""KronosTokenizer module for tokenizing input data using a hybrid quantization approach.This tokenizer utilizes a combination of encoder and decoder Transformer blocksalong with the Binary Spherical Quantization (BSQuantizer) to compress and decompress input data.Args:d_in (int): Input dimension.d_model (int): Model dimension.n_heads (int): Number of attention heads.ff_dim (int): Feed-forward dimension.n_enc_layers (int): Number of encoder layers.n_dec_layers (int): Number of decoder layers.ffn_dropout_p (float): Dropout probability for feed-forward networks.attn_dropout_p (float): Dropout probability for attention mechanisms.resid_dropout_p (float): Dropout probability for residual connections.s1_bits (int): Number of bits for the pre token in BSQuantizer.s2_bits (int): Number of bits for the post token in BSQuantizer.beta (float): Beta parameter for BSQuantizer.gamma0 (float): Gamma0 parameter for BSQuantizer.gamma (float): Gamma parameter for BSQuantizer.zeta (float): Zeta parameter for BSQuantizer.group_size (int): Group size parameter for BSQuantizer."""def __init__(self, d_in, d_model, n_heads, ff_dim, n_enc_layers, n_dec_layers, ffn_dropout_p, attn_dropout_p, resid_dropout_p, s1_bits, s2_bits, beta, gamma0, gamma, zeta, group_size):super().__init__()self.d_in = d_inself.d_model = d_modelself.n_heads = n_headsself.ff_dim = ff_dimself.enc_layers = n_enc_layersself.dec_layers = n_dec_layersself.ffn_dropout_p = ffn_dropout_pself.attn_dropout_p = attn_dropout_pself.resid_dropout_p = resid_dropout_pself.s1_bits = s1_bitsself.s2_bits = s2_bitsself.codebook_dim = s1_bits + s2_bits # Total dimension of the codebook after quantizationself.embed = nn.Linear(self.d_in, self.d_model)self.head = nn.Linear(self.d_model, self.d_in)# Encoder Transformer Blocksself.encoder = nn.ModuleList([TransformerBlock(self.d_model, self.n_heads, self.ff_dim, self.ffn_dropout_p, self.attn_dropout_p, self.resid_dropout_p)for _ in range(self.enc_layers - 1)])# Decoder Transformer Blocksself.decoder = nn.ModuleList([TransformerBlock(self.d_model, self.n_heads, self.ff_dim, self.ffn_dropout_p, self.attn_dropout_p, self.resid_dropout_p)for _ in range(self.dec_layers - 1)])self.quant_embed = nn.Linear(in_features=self.d_model, out_features=self.codebook_dim) # Linear layer before quantizationself.post_quant_embed_pre = nn.Linear(in_features=self.s1_bits, out_features=self.d_model) # Linear layer after quantization (pre part - s1 bits)self.post_quant_embed = nn.Linear(in_features=self.codebook_dim, out_features=self.d_model) # Linear layer after quantization (full codebook)self.tokenizer = BSQuantizer(self.s1_bits, self.s2_bits, beta, gamma0, gamma, zeta, group_size) # BSQuantizer moduledef forward(self, x):"""Forward pass of the KronosTokenizer.Args:x (torch.Tensor): Input tensor of shape (batch_size, seq_len, d_in).Returns:tuple: A tuple containing:- tuple: (z_pre, z) - Reconstructed outputs from decoder with s1_bits and full codebook respectively,both of shape (batch_size, seq_len, d_in).- torch.Tensor: bsq_loss - Loss from the BSQuantizer.- torch.Tensor: quantized - Quantized representation from BSQuantizer.- torch.Tensor: z_indices - Indices from the BSQuantizer."""z = self.embed(x)for layer in self.encoder:z = layer(z)z = self.quant_embed(z) # (B, T, codebook)bsq_loss, quantized, z_indices = self.tokenizer(z)quantized_pre = quantized[:, :, :self.s1_bits] # Extract the first part of quantized representation (s1_bits)z_pre = self.post_quant_embed_pre(quantized_pre)z = self.post_quant_embed(quantized)# Decoder layers (for pre part - s1 bits)for layer in self.decoder:z_pre = layer(z_pre)z_pre = self.head(z_pre)# Decoder layers (for full codebook)for layer in self.decoder:z = layer(z)z = self.head(z)return (z_pre, z), bsq_loss, quantized, z_indicesdef indices_to_bits(self, x, half=False):"""Converts indices to bit representations and scales them.Args:x (torch.Tensor): Indices tensor.half (bool, optional): Whether to process only half of the codebook dimension. Defaults to False.Returns:torch.Tensor: Bit representation tensor."""if half:x1 = x[0] # Assuming x is a tuple of indices if half is Truex2 = x[1]mask = 2 ** torch.arange(self.codebook_dim//2, device=x1.device, dtype=torch.long) # Create a mask for bit extractionx1 = (x1.unsqueeze(-1) & mask) != 0 # Extract bits for the first halfx2 = (x2.unsqueeze(-1) & mask) != 0 # Extract bits for the second halfx = torch.cat([x1, x2], dim=-1) # Concatenate the bit representationselse:mask = 2 ** torch.arange(self.codebook_dim, device=x.device, dtype=torch.long) # Create a mask for bit extractionx = (x.unsqueeze(-1) & mask) != 0 # Extract bitsx = x.float() * 2 - 1 # Convert boolean to bipolar (-1, 1)q_scale = 1. / (self.codebook_dim ** 0.5) # Scaling factorx = x * q_scalereturn xdef encode(self, x, half=False):"""Encodes the input data into quantized indices.Args:x (torch.Tensor): Input tensor of shape (batch_size, seq_len, d_in).half (bool, optional): Whether to use half quantization in BSQuantizer. Defaults to False.Returns:torch.Tensor: Quantized indices from BSQuantizer."""z = self.embed(x)for layer in self.encoder:z = layer(z)z = self.quant_embed(z)bsq_loss, quantized, z_indices = self.tokenizer(z, half)return z_indicesdef decode(self, x, half=False):"""Decodes quantized indices back to the input data space.Args:x (torch.Tensor): Quantized indices tensor.half (bool, optional): Whether the indices were generated with half quantization. Defaults to False.Returns:torch.Tensor: Reconstructed output tensor of shape (batch_size, seq_len, d_in)."""quantized = self.indices_to_bits(x, half)z = self.post_quant_embed(quantized)for layer in self.decoder:z = layer(z)z = self.head(z)return z
整体结构(__init__部分)
首先,我们来看这个类的继承关系。
class KronosTokenizer(nn.Module, PyTorchModelHubMixin):def __init__(self, d_in, d_model, n_heads, ff_dim, n_enc_layers, n_dec_layers, ffn_dropout_p, attn_dropout_p, resid_dropout_p, s1_bits, s2_bits, beta, gamma0, gamma, zeta, group_size):
1. 类继承结构
class KronosTokenizer(nn.Module, PyTorchModelHubMixin)
- 继承自
nn.Module:标准 PyTorch 神经网络模块 - 继承自
PyTorchModelHubMixin:支持 Hugging Face Hub 模型加载和保存
2. 初始化参数
模型维度参数
d_in(int): 输入维度d_model(int): 模型维度n_heads(int): 注意力头数量ff_dim(int): 前馈网络维度
网络层数参数
n_enc_layers(int): 编码器层数n_dec_layers(int): 解码器层数
Dropout 参数
ffn_dropout_p(float): 前馈网络 dropout 概率attn_dropout_p(float): 注意力机制 dropout 概率resid_dropout_p(float): 残差连接 dropout 概率
BSQuantizer 参数
s1_bits(int): 预标记的位数s2_bits(int): 后标记的位数beta(float): BSQuantizer 的 beta 参数gamma0(float): BSQuantizer 的 gamma0 参数gamma(float): BSQuantizer 的 gamma 参数zeta(float): BSQuantizer 的 zeta 参数group_size(int): BSQuantizer 的组大小参数
核心组件
1. 嵌入层
self.embed = nn.Linear(self.d_in, self.d_model)
self.head = nn.Linear(self.d_model, self.d_in)
embed: 将输入维度映射到模型维度head: 将模型维度映射回输入维度
2. 编码器 (Encoder)
self.encoder = nn.ModuleList([TransformerBlock(...) for _ in range(self.enc_layers - 1)
])
- 由多个 TransformerBlock 组成
- 负责将输入数据编码为高维表示
3. 解码器 (Decoder)
self.decoder = nn.ModuleList([TransformerBlock(...) for _ in range(self.dec_layers - 1)
])
- 由多个 TransformerBlock 组成
- 负责将量化后的表示解码回原始数据空间
4. 量化相关层
self.quant_embed = nn.Linear(in_features=self.d_model, out_features=self.codebook_dim)
self.post_quant_embed_pre = nn.Linear(in_features=self.s1_bits, out_features=self.d_model)
self.post_quant_embed = nn.Linear(in_features=self.codebook_dim, out_features=self.d_model)
quant_embed: 量化前的线性变换post_quant_embed_pre: 量化后的线性变换(仅 s1 位)post_quant_embed: 量化后的线性变换(完整码本)
5. BSQuantizer
self.tokenizer = BSQuantizer(self.s1_bits, self.s2_bits, beta, gamma0, gamma, zeta, group_size)
- 二进制球面量化器
- 负责将连续表示量化为离散标记
数据流程
def forward(self, x):"""Forward pass of the KronosTokenizer.Args:x (torch.Tensor): Input tensor of shape (batch_size, seq_len, d_in).Returns:tuple: A tuple containing:- tuple: (z_pre, z) - Reconstructed outputs from decoder with s1_bits and full codebook respectively,both of shape (batch_size, seq_len, d_in).- torch.Tensor: bsq_loss - Loss from the BSQuantizer.- torch.Tensor: quantized - Quantized representation from BSQuantizer.- torch.Tensor: z_indices - Indices from the BSQuantizer."""z = self.embed(x)for layer in self.encoder:z = layer(z)z = self.quant_embed(z) # (B, T, codebook)bsq_loss, quantized, z_indices = self.tokenizer(z)quantized_pre = quantized[:, :, :self.s1_bits] # Extract the first part of quantized representation (s1_bits)z_pre = self.post_quant_embed_pre(quantized_pre)z = self.post_quant_embed(quantized)# Decoder layers (for pre part - s1 bits)for layer in self.decoder:z_pre = layer(z_pre)z_pre = self.head(z_pre)# Decoder layers (for full codebook)for layer in self.decoder:z = layer(z)z = self.head(z)return (z_pre, z), bsq_loss, quantized, z_indices
1. 前向传播 (forward)
输入 x (batch_size, seq_len, d_in)↓
嵌入层 embed↓
编码器层 (多层 TransformerBlock)↓
量化嵌入层 quant_embed↓
BSQuantizer 量化↓
分离 s1_bits 和完整量化表示↓
后量化嵌入层 (两个分支)↓
解码器层 (多层 TransformerBlock)↓
输出头 head↓
输出 (z_pre, z), bsq_loss, quantized, z_indices
2. 编码过程 (encode)
输入 x → 嵌入 → 编码器 → 量化嵌入 → BSQuantizer → 量化索引
3. 解码过程 (decode)
量化索引 → 位表示 → 后量化嵌入 → 解码器 → 输出头 → 重构数据
调试的过程
1. 创建和初始化 KronosTokenizer
import torch
import torch.nn as nn
from model.kronos import KronosTokenizer# 定义模型参数
config = {'d_in': 5, # 输入维度 (如: OHLCV)'d_model': 256, # 模型维度'n_heads': 8, # 注意力头数'ff_dim': 1024, # 前馈网络维度'n_enc_layers': 6, # 编码器层数'n_dec_layers': 6, # 解码器层数'ffn_dropout_p': 0.1, # 前馈网络dropout'attn_dropout_p': 0.1, # 注意力dropout'resid_dropout_p': 0.1, # 残差dropout's1_bits': 8, # s1量化位数's2_bits': 8, # s2量化位数'beta': 1.0, # BSQuantizer参数'gamma0': 1.0, # BSQuantizer参数'gamma': 1.0, # BSQuantizer参数'zeta': 1.0, # BSQuantizer参数'group_size': 1 # BSQuantizer参数
}# 创建tokenizer
tokenizer = KronosTokenizer(**config)
print(f"模型参数量: {sum(p.numel() for p in tokenizer.parameters()):,}")
2. 基本前向传播
# 创建示例数据
batch_size = 4
seq_len = 100
d_in = 5# 模拟时间序列数据 (如股价数据)
x = torch.randn(batch_size, seq_len, d_in)
print(f"输入形状: {x.shape}")# 前向传播
with torch.no_grad():(z_pre, z), bsq_loss, quantized, z_indices = tokenizer(x)print(f"重构输出 (s1): {z_pre.shape}")
print(f"重构输出 (完整): {z.shape}")
print(f"量化损失: {bsq_loss.item():.4f}")
print(f"量化表示: {quantized.shape}")
print(f"量化索引: {z_indices.shape}")
3. 编码-解码循环测试
# 测试编码-解码的保真度
def test_encode_decode_fidelity(tokenizer, x, half=False):"""测试编码-解码循环的重构质量"""cwith torch.no_grad():# 编码indices = tokenizer.encode(x, half=half)print(f"编码索引形状: {indices.shape if not half else [idx.shape for idx in indices]}")# 解码reconstructed = tokenizer.decode(indices, half=half)print(f"重构数据形状: {reconstructed.shape}")# 计算重构误差mse = torch.mean((x - reconstructed) ** 2)mae = torch.mean(torch.abs(x - reconstructed))# 计算PSNR (Peak Signal-to-Noise Ratio)max_val = torch.max(x)psnr = 20 * torch.log10(max_val / torch.sqrt(mse))print(f"重构误差 - MSE: {mse.item():.6f}, MAE: {mae.item():.6f}")print(f"PSNR: {psnr.item():.2f} dB")return reconstructed, mse.item(), mae.item(), psnr.item()# 测试完整量化
print("=== 完整量化测试 ===")
recon_full, mse_full, mae_full, psnr_full = test_encode_decode_fidelity(tokenizer, x, half=False)# 测试半量化
print("\n=== 半量化测试 ===")
recon_half, mse_half, mae_half, psnr_half = test_encode_decode_fidelity(tokenizer, x, half=True)
可以看到,我们此时加载的是随机编码,之后我们会加载训练好的分词器。
使用随机参数的结果。
G:\Kronos-master\Kronos-master
=== 使用随机初始化模型 ===
模型参数量: 10,514,709随机初始化参数统计:
embed.weight: 均值=-0.005553, 标准差=0.263357
embed.bias: 均值=0.023413, 标准差=0.263413
head.weight: 均值=-0.000617, 标准差=0.036528
head.bias: 均值=-0.012492, 标准差=0.041956
encoder.0.norm1.weight: 均值=1.000000, 标准差=0.000000
encoder.0.self_attn.q_proj.weight: 均值=0.000220, 标准差=0.036019
encoder.0.self_attn.q_proj.bias: 均值=-0.002364, 标准差=0.037093
encoder.0.self_attn.k_proj.weight: 均值=-0.000208, 标准差=0.036013
encoder.0.self_attn.k_proj.bias: 均值=-0.003015, 标准差=0.036215
encoder.0.self_attn.v_proj.weight: 均值=0.000147, 标准差=0.036158
.................省略
重新拟合标准化器
模型设备: cpu
真实数据输入形状: torch.Size([4, 2000, 5])
数据设备: cpu
数据时间范围: 2025-09-05 00:25:00 到 2025-09-11 23:00:00
价格范围: $4248.71 - $4473.00
重构输出 (s1): torch.Size([4, 2000, 5])
重构输出 (完整): torch.Size([4, 2000, 5])
量化损失: 0.3223
量化表示: torch.Size([4, 2000, 16])
量化索引: torch.Size([4, 2000])
=== 完整量化测试 ===
编码索引形状: torch.Size([4, 2000])
重构数据形状: torch.Size([4, 2000, 5])
重构误差 - MSE: 1.110546, MAE: 0.803657
PSNR: 24.66 dB=== 半量化测试 ===
编码索引形状: [torch.Size([4, 2000]), torch.Size([4, 2000])]
重构数据形状: torch.Size([4, 2000, 5])
重构误差 - MSE: 1.107845, MAE: 0.801831
PSNR: 24.67 dB
PSNR是衡量重建的关键指标。
使用训练时的标准化参数
模型设备: cuda:0
真实数据输入形状: torch.Size([4, 2000, 5])
数据设备: cuda:0
数据时间范围: 2025-09-05 00:25:00 到 2025-09-11 23:00:00
价格范围: $4248.71 - $4473.00
重构输出 (s1): torch.Size([4, 2000, 5])
重构输出 (完整): torch.Size([4, 2000, 5])
量化损失: -0.0566
量化表示: torch.Size([4, 2000, 16])
量化索引: torch.Size([4, 2000])
=== 完整量化测试 ===
编码索引形状: torch.Size([4, 2000])
重构数据形状: torch.Size([4, 2000, 5])
重构误差 - MSE: 0.045214, MAE: 0.103612
PSNR: 38.97 dB=== 半量化测试 ===
编码索引形状: [torch.Size([4, 2000]), torch.Size([4, 2000])]
重构数据形状: torch.Size([4, 2000, 5])
重构误差 - MSE: 0.045649, MAE: 0.104486
PSNR: 38.93 dB
在经过一定的训练过后,mse,MAE都有了显著的降低,PSNR有了提高。
导入模型参数和不导入模型参数的代码
import torch
import torch.nn as nn
import numpy as np
import pandas as pd
from sklearn.preprocessing import StandardScalerimport os
print(os.getcwd())
import syssys.path.append("./")
from model.kronos import KronosTokenizer
from multi_timeframe_prediction.data_fetcher import CryptoDataFetcher#添加目录到sys.pathdef load_trained_model(model_path, device=None):"""加载训练好的KronosTokenizer模型参数:model_path: 模型文件路径 (如: './model_checkpoints/best_model.pth')device: 设备 ('cuda' 或 'cpu')返回:tuple: (tokenizer, scaler, checkpoint_info)"""if device is None:device = 'cuda' if torch.cuda.is_available() else 'cpu'print(f"正在从 {model_path} 加载训练好的模型...")# 加载检查点checkpoint = torch.load(model_path, map_location=device)# 获取配置config = checkpoint['config']print(f"模型配置: {config}")# 创建模型tokenizer = KronosTokenizer(**config)tokenizer.load_state_dict(checkpoint['model_state_dict'])tokenizer.to(device)tokenizer.eval() # 设置为评估模式# 恢复标准化器scaler = StandardScaler()if checkpoint['scaler_params']['mean_'] is not None:scaler.mean_ = np.array(checkpoint['scaler_params']['mean_'])scaler.scale_ = np.array(checkpoint['scaler_params']['scale_'])print("已恢复数据标准化器参数")else:print("警告: 未找到标准化器参数,将使用新的标准化器")# 打印模型信息total_params = sum(p.numel() for p in tokenizer.parameters())print(f"模型参数量: {total_params:,}")print(f"训练轮数: {checkpoint.get('epoch', 'Unknown')}")print(f"验证损失: {checkpoint.get('val_loss', 'Unknown')}")print(f"训练时间: {checkpoint.get('timestamp', 'Unknown')}")return tokenizer, scaler, checkpoint# =============================================================================
# 配置选项: 选择使用训练好的模型还是随机初始化的模型
# =============================================================================# 设置为True使用训练好的模型,False使用随机初始化的模型
USE_TRAINED_MODEL = True
TRAINED_MODEL_PATH = './model_checkpoints/best_model.pth' # 训练好的模型路径if USE_TRAINED_MODEL:print("=== 使用训练好的模型 ===")try:# 加载训练好的模型tokenizer, scaler, checkpoint_info = load_trained_model(TRAINED_MODEL_PATH)print("✓ 成功加载训练好的模型")except FileNotFoundError:print(f"❌ 未找到训练好的模型文件: {TRAINED_MODEL_PATH}")print("请先运行训练脚本或检查模型路径")print("切换到随机初始化模式...")USE_TRAINED_MODEL = Falseexcept Exception as e:print(f"❌ 加载模型时出错: {e}")print("切换到随机初始化模式...")USE_TRAINED_MODEL = Falseif not USE_TRAINED_MODEL:print("=== 使用随机初始化模型 ===")# 定义模型参数config = {'d_in': 5, # 输入维度 (如: OHLCV)'d_model': 256, # 模型维度'n_heads': 8, # 注意力头数'ff_dim': 1024, # 前馈网络维度'n_enc_layers': 6, # 编码器层数'n_dec_layers': 6, # 解码器层数'ffn_dropout_p': 0.1, # 前馈网络dropout'attn_dropout_p': 0.1, # 注意力dropout'resid_dropout_p': 0.1, # 残差dropout's1_bits': 8, # s1量化位数's2_bits': 8, # s2量化位数'beta': 1.0, # BSQuantizer参数'gamma0': 1.0, # BSQuantizer参数'gamma': 1.0, # BSQuantizer参数'zeta': 1.0, # BSQuantizer参数'group_size': 1 # BSQuantizer参数}# 创建tokenizertokenizer = KronosTokenizer(**config)print(f"模型参数量: {sum(p.numel() for p in tokenizer.parameters()):,}")# 检查模型参数的值范围(随机初始化的参数通常有特定分布)print("\n随机初始化参数统计:")for name, param in tokenizer.named_parameters():print(f"{name}: 均值={param.data.mean().item():.6f}, 标准差={param.data.std().item():.6f}")# 创建新的标准化器scaler = StandardScaler()# 使用真实数据进行测试
print("\n=== 获取真实加密货币数据 ===")# 创建数据获取器
data_fetcher = CryptoDataFetcher(symbol='ETHUSDT')# 获取5分钟K线数据
df, filepath = data_fetcher.get_data(timeframe='5m', limit=2000)
print(f"数据文件保存路径: {filepath}")# 准备数据 - 提取OHLCV特征
features = ['open', 'high', 'low', 'close', 'volume']
data_array = df[features].values# 数据标准化处理
if USE_TRAINED_MODEL and hasattr(scaler, 'mean_'):# 使用训练时的标准化参数print("使用训练时的标准化参数")data_normalized = scaler.transform(data_array)
else:# 重新拟合标准化器print("重新拟合标准化器")data_normalized = scaler.fit_transform(data_array)# 获取设备信息
device = next(tokenizer.parameters()).device
print(f"模型设备: {device}")# 创建批次数据
batch_size = 4
seq_len = min(2000, len(data_normalized)) # 使用实际数据长度或2000,取较小值
d_in = 5# 如果数据不够长,重复使用
if len(data_normalized) < seq_len:# 重复数据直到达到所需长度repeat_times = (seq_len // len(data_normalized)) + 1data_extended = np.tile(data_normalized, (repeat_times, 1))[:seq_len]
else:data_extended = data_normalized[:seq_len]# 创建批次 - 每个批次使用相同的数据序列,并移动到正确设备
x = torch.FloatTensor(data_extended).unsqueeze(0).repeat(batch_size, 1, 1).to(device)
print(f"真实数据输入形状: {x.shape}")
print(f"数据设备: {x.device}")
print(f"数据时间范围: {df['timestamps'].iloc[0]} 到 {df['timestamps'].iloc[-1]}")
print(f"价格范围: ${df['close'].min():.2f} - ${df['close'].max():.2f}")# 前向传播
with torch.no_grad():(z_pre, z), bsq_loss, quantized, z_indices = tokenizer(x)print(f"重构输出 (s1): {z_pre.shape}")
print(f"重构输出 (完整): {z.shape}")
print(f"量化损失: {bsq_loss.item():.4f}")
print(f"量化表示: {quantized.shape}")
print(f"量化索引: {z_indices.shape}")# 测试编码-解码的保真度
def test_encode_decode_fidelity(tokenizer, x, half=False):"""测试编码-解码循环的重构质量"""with torch.no_grad():# 编码indices = tokenizer.encode(x, half=half)print(f"编码索引形状: {indices.shape if not half else [idx.shape for idx in indices]}")# 解码reconstructed = tokenizer.decode(indices, half=half)print(f"重构数据形状: {reconstructed.shape}")# 计算重构误差mse = torch.mean((x - reconstructed) ** 2)mae = torch.mean(torch.abs(x - reconstructed))# 计算PSNR (Peak Signal-to-Noise Ratio)max_val = torch.max(x)psnr = 20 * torch.log10(max_val / torch.sqrt(mse))print(f"重构误差 - MSE: {mse.item():.6f}, MAE: {mae.item():.6f}")print(f"PSNR: {psnr.item():.2f} dB")return reconstructed, mse.item(), mae.item(), psnr.item()# 测试完整量化
print("=== 完整量化测试 ===")
recon_full, mse_full, mae_full, psnr_full = test_encode_decode_fidelity(tokenizer, x, half=False)# 测试半量化
print("\n=== 半量化测试 ===")
recon_half, mse_half, mae_half, psnr_half = test_encode_decode_fidelity(tokenizer, x, half=True)print("\n" + "="*60)
print("使用说明:")
print("1. 设置 USE_TRAINED_MODEL = True 来使用训练好的模型")
print("2. 设置 TRAINED_MODEL_PATH 为你的模型文件路径")
print("3. 如果没有训练好的模型,脚本会自动切换到随机初始化模式")
print("4. 训练模型请运行: python model/model_analysis/train_kronos.py")
print("="*60)虽然下一步应该是模型如何训练,但是我想要直观看一下编码器和解码器的工作输出情况
可视化
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
KronosTokenizer 编码和重建过程可视化这个脚本展示了KronosTokenizer的完整工作流程:
1. 原始数据输入
2. 编码过程
3. 量化过程
4. 重建过程
5. 结果对比和分析作者: AI Assistant
日期: 2025-01-11
"""import torch
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib.patches import Rectangle
import sys
import os
from datetime import datetime
sys.path.append("./")
# 添加项目路径
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))from model.kronos import KronosTokenizer
from multi_timeframe_prediction.data_fetcher import CryptoDataFetcher# 设置绘图样式
plt.rcParams['figure.figsize'] = (15, 10)
plt.rcParams['font.size'] = 10
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei', 'Arial Unicode MS']
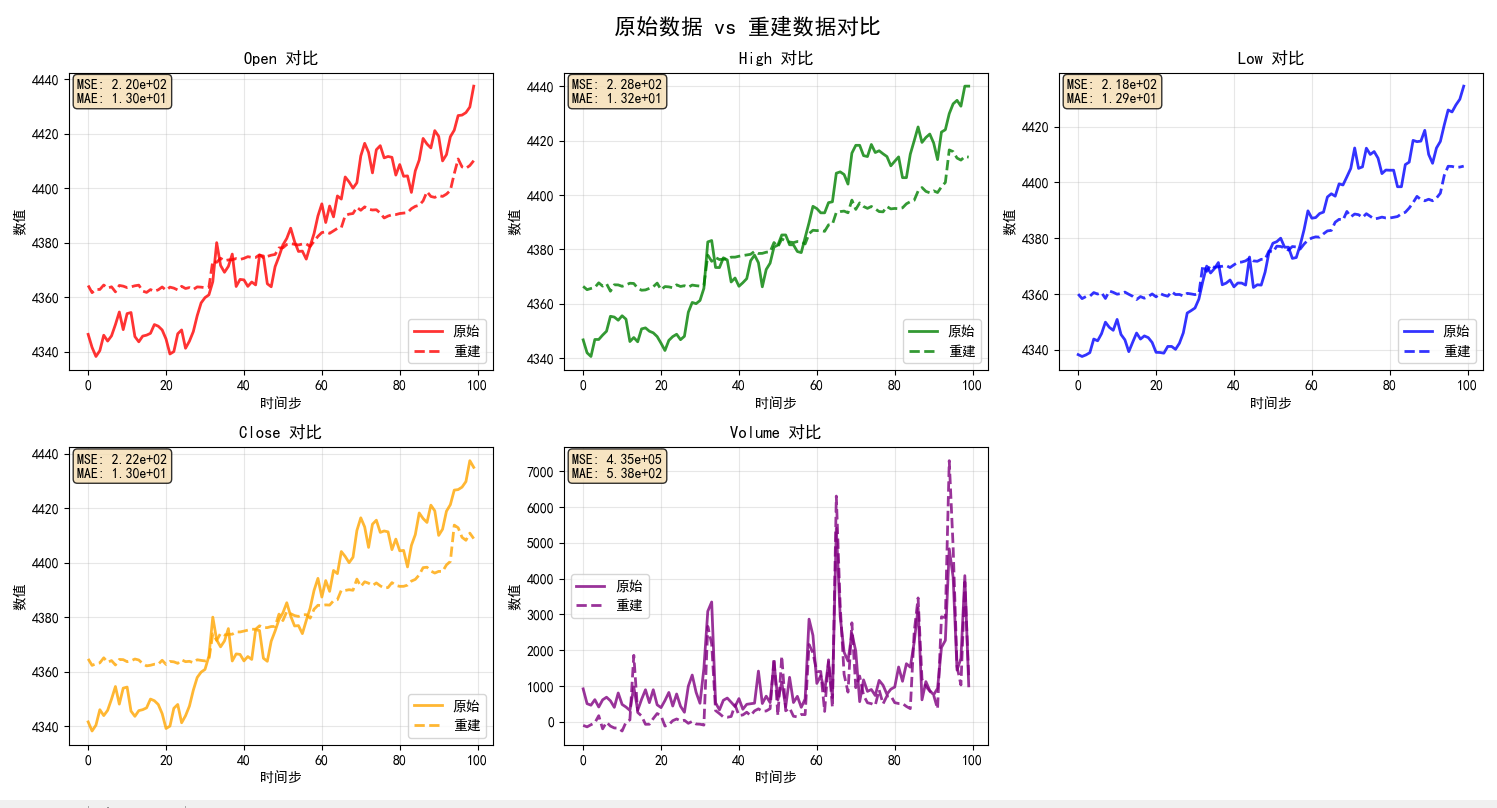
plt.rcParams['axes.unicode_minus'] = Falsedef simple_normalize(data):"""简单的数据标准化"""mean = np.mean(data, axis=0)std = np.std(data, axis=0)std = np.where(std == 0, 1, std) # 避免除零return (data - mean) / std, mean, stddef denormalize(data, mean, std):"""反标准化"""return data * std + meanclass KronosVisualization:"""KronosTokenizer可视化类"""def __init__(self, model_path=None, device=None):self.device = device or ('cuda' if torch.cuda.is_available() else 'cpu')print(f"使用设备: {self.device}")# 加载或创建模型self.tokenizer = self._load_or_create_model(model_path)self.tokenizer.eval()# 存储中间结果self.results = {}def _load_or_create_model(self, model_path):"""加载训练好的模型或创建新模型"""if model_path and os.path.exists(model_path):print(f"加载训练好的模型: {model_path}")try:checkpoint = torch.load(model_path, map_location=self.device)config = checkpoint.get('config', {})# 使用保存的配置tokenizer = KronosTokenizer(d_in=config.get('d_in', 5),d_model=config.get('d_model', 256),n_heads=config.get('n_heads', 8),n_enc_layers=config.get('n_enc_layers', 6),n_dec_layers=config.get('n_dec_layers', 6),ff_dim=config.get('ff_dim', 1024),ffn_dropout_p=config.get('ffn_dropout_p', 0.1),attn_dropout_p=config.get('attn_dropout_p', 0.1),resid_dropout_p=config.get('resid_dropout_p', 0.1),s1_bits=config.get('s1_bits', 8),s2_bits=config.get('s2_bits', 8),beta=config.get('beta', 1.0),gamma0=config.get('gamma0', 1.0),gamma=config.get('gamma', 1.0),zeta=config.get('zeta', 1.0),group_size=config.get('group_size', 1)).to(self.device)tokenizer.load_state_dict(checkpoint['model_state_dict'])print("✓ 成功加载训练好的模型")return tokenizerexcept Exception as e:print(f"加载训练模型失败: {e}")print("使用随机初始化模型")# 创建随机初始化模型print("使用随机初始化模型")return KronosTokenizer(d_in=5,d_model=256,n_heads=8,n_enc_layers=6,n_dec_layers=6,ff_dim=1024,ffn_dropout_p=0.1,attn_dropout_p=0.1,resid_dropout_p=0.1,s1_bits=8,s2_bits=8,beta=1.0,gamma0=1.0,gamma=1.0,zeta=1.0,group_size=1).to(self.device)def get_sample_data(self, symbol='ETHUSDT', timeframe='5min', limit=200):"""获取样本数据"""print(f"\n获取 {symbol} {timeframe} 数据...")try:fetcher = CryptoDataFetcher(symbol=symbol)df, filepath = fetcher.get_data(timeframe=timeframe, limit=limit)if df is None or df.empty:print("无法获取数据,使用模拟数据")# 创建模拟数据np.random.seed(42)data_array = np.random.randn(limit, 5) * 100 + 1000df = pd.DataFrame(data_array, columns=['open', 'high', 'low', 'close', 'volume'])else:print(f"获取到 {len(df)} 条数据")return dfexcept Exception as e:print(f"数据获取失败: {e},使用模拟数据")np.random.seed(42)data_array = np.random.randn(limit, 5) * 100 + 1000return pd.DataFrame(data_array, columns=['open', 'high', 'low', 'close', 'volume'])def analyze_encoding_process(self, data, seq_len=100):"""分析编码过程"""print("\n=== 分析编码和重建过程 ===")# 准备数据data_array = data[['open', 'high', 'low', 'close', 'volume']].valuesdata_normalized, mean, std = simple_normalize(data_array)# 截取序列if len(data_normalized) > seq_len:data_normalized = data_normalized[:seq_len]# 转换为张量x = torch.FloatTensor(data_normalized).unsqueeze(0).to(self.device) # [1, seq_len, 5]with torch.no_grad():# 1. 使用encode方法获取量化索引indices = self.tokenizer.encode(x)# 2. 使用decode方法重建数据reconstructed = self.tokenizer.decode(indices)# 3. 完整前向传播(用于对比)full_output_tuple = self.tokenizer(x)# forward返回 (z_pre, z), bsq_loss, quantized, z_indicesfull_output = full_output_tuple[0][1] if isinstance(full_output_tuple[0], tuple) else full_output_tuple[0]# 4. 获取中间结果用于可视化embedded = self.tokenizer.embed(x) # 输入嵌入# 编码器是ModuleList,需要遍历encoded = embeddedfor layer in self.tokenizer.encoder:encoded = layer(encoded)# 量化前的线性层pre_quant = self.tokenizer.quant_embed(encoded)# 量化过程bsq_loss, quantized, _ = self.tokenizer.tokenizer(pre_quant)# 解码过程post_quant = self.tokenizer.post_quant_embed(quantized)decoded = post_quantfor layer in self.tokenizer.decoder:decoded = layer(decoded)final_decoded = self.tokenizer.head(decoded)# 存储结果self.results = {'original': x.cpu().numpy(),'embedded': embedded.cpu().numpy(),'encoded': encoded.cpu().numpy(),'pre_quant': pre_quant.cpu().numpy(),'quantized': quantized.cpu().numpy(),'indices': indices.cpu().numpy(),'post_quant': post_quant.cpu().numpy(),'decoded': decoded.cpu().numpy(),'final_decoded': final_decoded.cpu().numpy(),'reconstructed': reconstructed.cpu().numpy(),'full_output': full_output.cpu().numpy(),'bsq_loss': bsq_loss.item(),'mean': mean,'std': std}print(f"原始数据形状: {x.shape}")print(f"嵌入后形状: {embedded.shape}")print(f"编码后形状: {encoded.shape}")print(f"量化后形状: {quantized.shape}")print(f"索引形状: {indices.shape}")print(f"解码后形状: {decoded.shape}")print(f"重建后形状: {reconstructed.shape}")return self.resultsdef visualize_data_flow(self, save_path=None):"""可视化数据流程"""if not self.results:raise ValueError("请先运行 analyze_encoding_process")fig, axes = plt.subplots(3, 3, figsize=(18, 12))fig.suptitle('KronosTokenizer 编码和重建过程可视化', fontsize=16, fontweight='bold')# 1. 原始数据ax = axes[0, 0]original = self.results['original'][0] # [seq_len, 5]im1 = ax.imshow(original.T, aspect='auto', cmap='viridis', interpolation='nearest')ax.set_title('1. 原始数据\n(OHLCV)', fontweight='bold')ax.set_xlabel('时间步')ax.set_ylabel('特征维度')ax.set_yticks(range(5))ax.set_yticklabels(['Open', 'High', 'Low', 'Close', 'Volume'])plt.colorbar(im1, ax=ax, shrink=0.8)# 2. 嵌入后数据ax = axes[0, 1]embedded = self.results['embedded'][0] # [seq_len, d_model]# 只显示前50个维度display_dims = min(50, embedded.shape[1])im2 = ax.imshow(embedded[:, :display_dims].T, aspect='auto', cmap='plasma', interpolation='nearest')ax.set_title(f'2. 输入嵌入\n(前{display_dims}维)', fontweight='bold')ax.set_xlabel('时间步')ax.set_ylabel('嵌入维度')plt.colorbar(im2, ax=ax, shrink=0.8)# 3. 编码器输出ax = axes[0, 2]encoded = self.results['encoded'][0] # [seq_len, d_model]im3 = ax.imshow(encoded[:, :display_dims].T, aspect='auto', cmap='coolwarm', interpolation='nearest')ax.set_title(f'3. 编码器输出\n(前{display_dims}维)', fontweight='bold')ax.set_xlabel('时间步')ax.set_ylabel('编码维度')plt.colorbar(im3, ax=ax, shrink=0.8)# 4. 量化后数据ax = axes[1, 0]quantized = self.results['quantized'][0] # [seq_len, d_model]im4 = ax.imshow(quantized[:, :display_dims].T, aspect='auto', cmap='coolwarm', interpolation='nearest')ax.set_title(f'4. 量化后数据\n(前{display_dims}维)', fontweight='bold')ax.set_xlabel('时间步')ax.set_ylabel('量化维度')plt.colorbar(im4, ax=ax, shrink=0.8)# 5. 量化索引ax = axes[1, 1]indices = self.results['indices'] # 直接使用indices,不取[0]if len(indices.shape) == 3: # [batch, seq_len, ...]indices = indices[0] # 取第一个batchif len(indices.shape) > 2:indices_flat = indices.reshape(indices.shape[0], -1)elif len(indices.shape) == 2:indices_flat = indiceselse: # 1D情况indices_flat = indices.reshape(-1, 1)display_idx_dims = min(20, indices_flat.shape[1])im5 = ax.imshow(indices_flat[:, :display_idx_dims].T, aspect='auto', cmap='tab20', interpolation='nearest')ax.set_title(f'5. 量化索引\n(前{display_idx_dims}维)', fontweight='bold')ax.set_xlabel('时间步')ax.set_ylabel('索引维度')plt.colorbar(im5, ax=ax, shrink=0.8)# 6. 解码器输出ax = axes[1, 2]decoded = self.results['decoded'][0] # [seq_len, d_model]im6 = ax.imshow(decoded[:, :display_dims].T, aspect='auto', cmap='plasma', interpolation='nearest')ax.set_title(f'6. 解码器输出\n(前{display_dims}维)', fontweight='bold')ax.set_xlabel('时间步')ax.set_ylabel('解码维度')plt.colorbar(im6, ax=ax, shrink=0.8)# 7. 重建数据ax = axes[2, 0]reconstructed = self.results['reconstructed'][0] # [seq_len, 5]im7 = ax.imshow(reconstructed.T, aspect='auto', cmap='viridis', interpolation='nearest')ax.set_title('7. 重建数据\n(OHLCV)', fontweight='bold')ax.set_xlabel('时间步')ax.set_ylabel('特征维度')ax.set_yticks(range(5))ax.set_yticklabels(['Open', 'High', 'Low', 'Close', 'Volume'])plt.colorbar(im7, ax=ax, shrink=0.8)# 8. 重建误差ax = axes[2, 1]error = np.abs(self.results['original'][0] - self.results['reconstructed'][0])im8 = ax.imshow(error.T, aspect='auto', cmap='Reds', interpolation='nearest')ax.set_title('8. 重建误差\n(绝对值)', fontweight='bold')ax.set_xlabel('时间步')ax.set_ylabel('特征维度')ax.set_yticks(range(5))ax.set_yticklabels(['Open', 'High', 'Low', 'Close', 'Volume'])plt.colorbar(im8, ax=ax, shrink=0.8)# 9. 数据流程图ax = axes[2, 2]ax.set_xlim(0, 10)ax.set_ylim(0, 10)# 绘制流程框boxes = [(1, 8, '原始数据'),(1, 6.5, '输入嵌入'),(1, 5, '编码器'),(1, 3.5, '量化器'),(1, 2, '解码器'),(1, 0.5, '输出头'),(6, 0.5, '重建数据')]for x, y, text in boxes:rect = Rectangle((x-0.8, y-0.3), 1.6, 0.6, linewidth=1, edgecolor='black', facecolor='lightblue')ax.add_patch(rect)ax.text(x, y, text, ha='center', va='center', fontsize=8, fontweight='bold')# 绘制箭头arrows = [(1, 7.7, 1, 6.8), # 原始数据 -> 输入嵌入(1, 6.2, 1, 5.3), # 输入嵌入 -> 编码器(1, 4.7, 1, 3.8), # 编码器 -> 量化器(1, 3.2, 1, 2.3), # 量化器 -> 解码器(1, 1.7, 1, 0.8), # 解码器 -> 输出头(1.8, 0.5, 5.2, 0.5) # 输出头 -> 重建数据]for x1, y1, x2, y2 in arrows:ax.annotate('', xy=(x2, y2), xytext=(x1, y1),arrowprops=dict(arrowstyle='->', lw=1.5, color='red'))ax.set_title('9. 数据流程图', fontweight='bold')ax.set_xticks([])ax.set_yticks([])ax.spines['top'].set_visible(False)ax.spines['right'].set_visible(False)ax.spines['bottom'].set_visible(False)ax.spines['left'].set_visible(False)plt.tight_layout()if save_path:plt.savefig(save_path, dpi=300, bbox_inches='tight')print(f"可视化结果已保存到: {save_path}")plt.show()def visualize_reconstruction_comparison(self, save_path=None):"""可视化重建对比"""if not self.results:raise ValueError("请先运行 analyze_encoding_process")fig, axes = plt.subplots(2, 3, figsize=(15, 8))fig.suptitle('原始数据 vs 重建数据对比', fontsize=16, fontweight='bold')original = self.results['original'][0] # [seq_len, 5]reconstructed = self.results['reconstructed'][0] # [seq_len, 5]# 反标准化到原始尺度original_denorm = denormalize(original, self.results['mean'], self.results['std'])reconstructed_denorm = denormalize(reconstructed, self.results['mean'], self.results['std'])feature_names = ['Open', 'High', 'Low', 'Close', 'Volume']colors = ['red', 'green', 'blue', 'orange', 'purple']for i, (feature, color) in enumerate(zip(feature_names, colors)):if i < 5: # 只显示前5个特征row = i // 3col = i % 3ax = axes[row, col]time_steps = range(len(original_denorm))ax.plot(time_steps, original_denorm[:, i], label='原始', color=color, linewidth=2, alpha=0.8)ax.plot(time_steps, reconstructed_denorm[:, i], label='重建', color=color, linestyle='--', linewidth=2, alpha=0.8)ax.set_title(f'{feature} 对比', fontweight='bold')ax.set_xlabel('时间步')ax.set_ylabel('数值')ax.legend()ax.grid(True, alpha=0.3)# 计算并显示误差统计mse = np.mean((original_denorm[:, i] - reconstructed_denorm[:, i]) ** 2)mae = np.mean(np.abs(original_denorm[:, i] - reconstructed_denorm[:, i]))ax.text(0.02, 0.98, f'MSE: {mse:.2e}\nMAE: {mae:.2e}', transform=ax.transAxes, verticalalignment='top',bbox=dict(boxstyle='round', facecolor='wheat', alpha=0.8))# 删除多余的子图if len(feature_names) < 6:axes[1, 2].remove()plt.tight_layout()if save_path:plt.savefig(save_path, dpi=300, bbox_inches='tight')print(f"重建对比图已保存到: {save_path}")plt.show()def print_statistics(self):"""打印统计信息"""if not self.results:raise ValueError("请先运行 analyze_encoding_process")print("\n=== 编码和重建统计信息 ===")original = self.results['original'][0]reconstructed = self.results['reconstructed'][0]# 计算各种误差指标mse = np.mean((original - reconstructed) ** 2)mae = np.mean(np.abs(original - reconstructed))rmse = np.sqrt(mse)# 按特征计算误差feature_names = ['Open', 'High', 'Low', 'Close', 'Volume']print(f"\n整体误差:")print(f" MSE: {mse:.6f}")print(f" MAE: {mae:.6f}")print(f" RMSE: {rmse:.6f}")print(f"\n各特征误差:")for i, name in enumerate(feature_names):feature_mse = np.mean((original[:, i] - reconstructed[:, i]) ** 2)feature_mae = np.mean(np.abs(original[:, i] - reconstructed[:, i]))print(f" {name}: MSE={feature_mse:.6f}, MAE={feature_mae:.6f}")# 量化统计indices = self.results['indices'][0]unique_indices = np.unique(indices)print(f"\n量化统计:")print(f" 唯一量化索引数量: {len(unique_indices)}")print(f" 索引范围: [{indices.min()}, {indices.max()}]")# 数据范围统计print(f"\n数据范围统计:")print(f" 原始数据范围: [{original.min():.4f}, {original.max():.4f}]")print(f" 重建数据范围: [{reconstructed.min():.4f}, {reconstructed.max():.4f}]")encoded = self.results['encoded'][0]quantized = self.results['quantized'][0]print(f" 编码数据范围: [{encoded.min():.4f}, {encoded.max():.4f}]")print(f" 量化数据范围: [{quantized.min():.4f}, {quantized.max():.4f}]")def main():"""主函数"""print("=== KronosTokenizer 编码和重建过程可视化 ===")# 配置MODEL_PATH = "model_checkpoints/best_model.pth" # 训练好的模型路径SYMBOL = 'ETHUSDT'TIMEFRAME = '5m'SEQ_LEN = 100# 创建可视化器visualizer = KronosVisualization(model_path=MODEL_PATH)# 获取数据data = visualizer.get_sample_data(symbol=SYMBOL, timeframe=TIMEFRAME, limit=200)# 分析编码过程results = visualizer.analyze_encoding_process(data, seq_len=SEQ_LEN)# 打印统计信息visualizer.print_statistics()# 生成可视化timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")# 数据流程可视化flow_path = f"figures/encoding_flow_{timestamp}.png"visualizer.visualize_data_flow(save_path=flow_path)# 重建对比可视化comparison_path = f"figures/reconstruction_comparison_{timestamp}.png"visualizer.visualize_reconstruction_comparison(save_path=comparison_path)print(f"\n=== 可视化完成 ===")print(f"数据流程图: {flow_path}")print(f"重建对比图: {comparison_path}")if __name__ == "__main__":main()
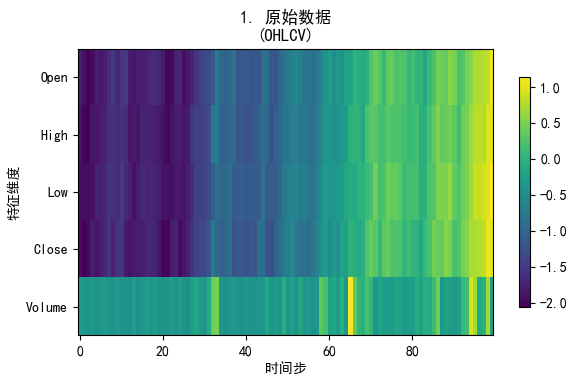
这个色块有一定的衰退,但是整体是可以反应这个数据的一些特征的。
其他值也看不出什么意义
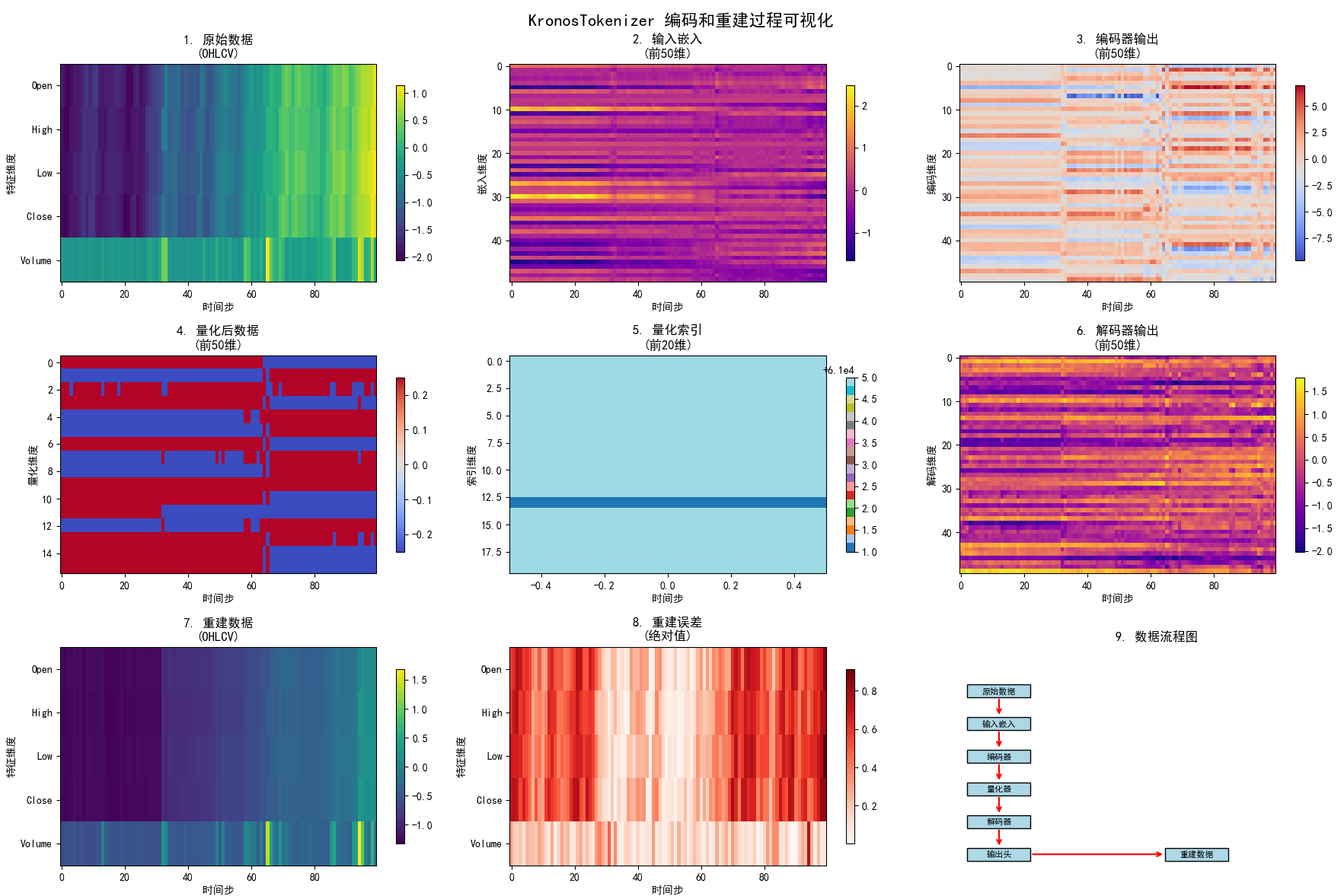
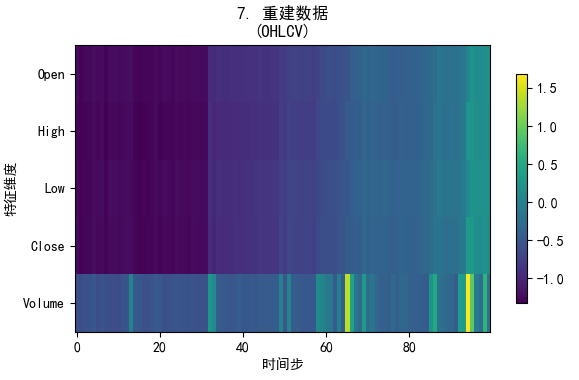
我们可以看到输入和输出编码有差异,但是大体是可以反应趋势和波动的。
训练的代码
"""
KronosTokenizer 训练脚本这个脚本提供了完整的KronosTokenizer训练流程,包括:
1. 数据准备和预处理
2. 模型初始化和配置
3. 训练循环和验证
4. 模型保存和加载
5. 性能评估和可视化作者: AI Assistant
日期: 2025-01-11
"""import os
import sys
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset, random_split
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from datetime import datetime
import json
from tqdm import tqdm
from sklearn.preprocessing import StandardScaler# 添加项目根目录到路径
sys.path.append(os.path.join(os.path.dirname(__file__), '..', '..'))from model.kronos import KronosTokenizer
from multi_timeframe_prediction.data_fetcher import CryptoDataFetcherclass KronosTokenizerTrainer:"""KronosTokenizer训练器类提供完整的训练、验证、保存和评估功能"""def __init__(self, config=None, device=None):"""初始化训练器参数:config: 模型配置字典device: 训练设备 ('cuda' 或 'cpu')"""self.device = device or ('cuda' if torch.cuda.is_available() else 'cpu')print(f"使用设备: {self.device}")# 默认配置self.default_config = {'d_in': 5, # 输入维度 (OHLCV)'d_model': 256, # 模型维度'n_heads': 8, # 注意力头数'ff_dim': 1024, # 前馈网络维度'n_enc_layers': 6, # 编码器层数'n_dec_layers': 6, # 解码器层数'ffn_dropout_p': 0.1, # 前馈网络dropout'attn_dropout_p': 0.1, # 注意力dropout'resid_dropout_p': 0.1, # 残差dropout's1_bits': 8, # s1量化位数's2_bits': 8, # s2量化位数'beta': 1.0, # BSQuantizer参数'gamma0': 1.0, # BSQuantizer参数'gamma': 1.0, # BSQuantizer参数'zeta': 1.0, # BSQuantizer参数'group_size': 1 # BSQuantizer参数}# 更新配置self.config = self.default_config.copy()if config:self.config.update(config)# 初始化模型self.tokenizer = Noneself.optimizer = Noneself.scheduler = Noneself.scaler = StandardScaler()# 训练历史self.train_history = {'epoch': [],'train_loss': [],'train_recon_loss': [],'train_quant_loss': [],'val_loss': [],'val_recon_loss': [],'val_quant_loss': [],'learning_rate': []}def create_model(self):"""创建KronosTokenizer模型"""self.tokenizer = KronosTokenizer(**self.config)self.tokenizer.to(self.device)# 打印模型信息total_params = sum(p.numel() for p in self.tokenizer.parameters())trainable_params = sum(p.numel() for p in self.tokenizer.parameters() if p.requires_grad)print(f"\n=== 模型信息 ===")print(f"总参数量: {total_params:,}")print(f"可训练参数量: {trainable_params:,}")print(f"模型配置: {self.config}")return self.tokenizerdef prepare_data(self, symbol='ETHUSDT', timeframe='5m', limit=5000, seq_len=512, train_ratio=0.8, val_ratio=0.1):"""准备训练数据参数:symbol: 交易对符号timeframe: 时间周期limit: 数据条数seq_len: 序列长度train_ratio: 训练集比例val_ratio: 验证集比例返回:tuple: (train_loader, val_loader, test_loader)"""print(f"\n=== 数据准备 ===")print(f"获取 {symbol} {timeframe} 数据,共 {limit} 条...")# 获取数据data_fetcher = CryptoDataFetcher(symbol=symbol)df, filepath = data_fetcher.get_data(timeframe=timeframe, limit=limit)print(f"数据文件保存路径: {filepath}")print(f"数据时间范围: {df['timestamps'].iloc[0]} 到 {df['timestamps'].iloc[-1]}")# 提取特征features = ['open', 'high', 'low', 'close', 'volume']data_array = df[features].values# 数据标准化data_normalized = self.scaler.fit_transform(data_array)# 创建序列数据sequences = []for i in range(len(data_normalized) - seq_len + 1):sequences.append(data_normalized[i:i+seq_len])sequences = np.array(sequences)print(f"创建了 {len(sequences)} 个长度为 {seq_len} 的序列")# 转换为张量sequences_tensor = torch.FloatTensor(sequences)# 创建数据集dataset = TensorDataset(sequences_tensor)# 划分数据集total_size = len(dataset)train_size = int(total_size * train_ratio)val_size = int(total_size * val_ratio)test_size = total_size - train_size - val_sizetrain_dataset, val_dataset, test_dataset = random_split(dataset, [train_size, val_size, test_size])print(f"数据集划分: 训练集 {train_size}, 验证集 {val_size}, 测试集 {test_size}")# 创建数据加载器batch_size = 32train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False)test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)return train_loader, val_loader, test_loaderdef setup_training(self, learning_rate=1e-4, weight_decay=1e-5):"""设置训练组件参数:learning_rate: 学习率weight_decay: 权重衰减"""if self.tokenizer is None:raise ValueError("请先创建模型")# 优化器self.optimizer = optim.AdamW(self.tokenizer.parameters(), lr=learning_rate, weight_decay=weight_decay)# 学习率调度器self.scheduler = optim.lr_scheduler.ReduceLROnPlateau(self.optimizer, mode='min', factor=0.5, patience=5)print(f"\n=== 训练设置 ===")print(f"优化器: AdamW, 学习率: {learning_rate}, 权重衰减: {weight_decay}")print(f"调度器: ReduceLROnPlateau")def compute_loss(self, batch_x, recon_weight=1.0, quant_weight=0.1):"""计算损失函数参数:batch_x: 输入批次recon_weight: 重构损失权重quant_weight: 量化损失权重返回:tuple: (总损失, 重构损失, 量化损失)"""# 前向传播(z_pre, z), bsq_loss, quantized, z_indices = self.tokenizer(batch_x)# 重构损失criterion = nn.MSELoss()recon_loss_pre = criterion(z_pre, batch_x)recon_loss_full = criterion(z, batch_x)recon_loss = 0.3 * recon_loss_pre + 0.7 * recon_loss_full# 总损失total_loss = recon_weight * recon_loss + quant_weight * bsq_lossreturn total_loss, recon_loss, bsq_lossdef train_epoch(self, train_loader, epoch):"""训练一个epoch参数:train_loader: 训练数据加载器epoch: 当前epoch返回:tuple: (平均总损失, 平均重构损失, 平均量化损失)"""self.tokenizer.train()total_loss_sum = 0recon_loss_sum = 0quant_loss_sum = 0num_batches = 0pbar = tqdm(train_loader, desc=f'Epoch {epoch+1} [训练]')for batch_idx, (batch_x,) in enumerate(pbar):batch_x = batch_x.to(self.device)# 清零梯度self.optimizer.zero_grad()# 计算损失total_loss, recon_loss, quant_loss = self.compute_loss(batch_x)# 反向传播total_loss.backward()# 梯度裁剪torch.nn.utils.clip_grad_norm_(self.tokenizer.parameters(), max_norm=1.0)# 更新参数self.optimizer.step()# 累计损失total_loss_sum += total_loss.item()recon_loss_sum += recon_loss.item()quant_loss_sum += quant_loss.item()num_batches += 1# 更新进度条pbar.set_postfix({'Loss': f'{total_loss.item():.4f}','Recon': f'{recon_loss.item():.4f}','Quant': f'{quant_loss.item():.4f}'})# 计算平均损失avg_total_loss = total_loss_sum / num_batchesavg_recon_loss = recon_loss_sum / num_batchesavg_quant_loss = quant_loss_sum / num_batchesreturn avg_total_loss, avg_recon_loss, avg_quant_lossdef validate_epoch(self, val_loader, epoch):"""验证一个epoch参数:val_loader: 验证数据加载器epoch: 当前epoch返回:tuple: (平均总损失, 平均重构损失, 平均量化损失)"""self.tokenizer.eval()total_loss_sum = 0recon_loss_sum = 0quant_loss_sum = 0num_batches = 0pbar = tqdm(val_loader, desc=f'Epoch {epoch+1} [验证]')with torch.no_grad():for batch_idx, (batch_x,) in enumerate(pbar):batch_x = batch_x.to(self.device)# 计算损失total_loss, recon_loss, quant_loss = self.compute_loss(batch_x)# 累计损失total_loss_sum += total_loss.item()recon_loss_sum += recon_loss.item()quant_loss_sum += quant_loss.item()num_batches += 1# 更新进度条pbar.set_postfix({'Loss': f'{total_loss.item():.4f}','Recon': f'{recon_loss.item():.4f}','Quant': f'{quant_loss.item():.4f}'})# 计算平均损失avg_total_loss = total_loss_sum / num_batchesavg_recon_loss = recon_loss_sum / num_batchesavg_quant_loss = quant_loss_sum / num_batchesreturn avg_total_loss, avg_recon_loss, avg_quant_lossdef train(self, train_loader, val_loader, num_epochs=50, save_dir='./checkpoints'):"""完整训练流程参数:train_loader: 训练数据加载器val_loader: 验证数据加载器num_epochs: 训练轮数save_dir: 模型保存目录"""if self.tokenizer is None or self.optimizer is None:raise ValueError("请先创建模型和设置训练组件")# 创建保存目录os.makedirs(save_dir, exist_ok=True)print(f"\n=== 开始训练 ===")print(f"训练轮数: {num_epochs}")print(f"模型保存目录: {save_dir}")best_val_loss = float('inf')patience_counter = 0max_patience = 10for epoch in range(num_epochs):print(f"\n--- Epoch {epoch+1}/{num_epochs} ---")# 训练train_loss, train_recon, train_quant = self.train_epoch(train_loader, epoch)# 验证val_loss, val_recon, val_quant = self.validate_epoch(val_loader, epoch)# 学习率调度self.scheduler.step(val_loss)current_lr = self.optimizer.param_groups[0]['lr']# 记录历史self.train_history['epoch'].append(epoch + 1)self.train_history['train_loss'].append(train_loss)self.train_history['train_recon_loss'].append(train_recon)self.train_history['train_quant_loss'].append(train_quant)self.train_history['val_loss'].append(val_loss)self.train_history['val_recon_loss'].append(val_recon)self.train_history['val_quant_loss'].append(val_quant)self.train_history['learning_rate'].append(current_lr)# 打印结果print(f"训练损失: {train_loss:.6f} (重构: {train_recon:.6f}, 量化: {train_quant:.6f})")print(f"验证损失: {val_loss:.6f} (重构: {val_recon:.6f}, 量化: {val_quant:.6f})")print(f"学习率: {current_lr:.2e}")# 保存最佳模型if val_loss < best_val_loss:best_val_loss = val_losspatience_counter = 0best_model_path = os.path.join(save_dir, 'best_model.pth')self.save_model(best_model_path, epoch, val_loss)print(f"✓ 保存最佳模型: {best_model_path}")else:patience_counter += 1# 定期保存检查点if (epoch + 1) % 10 == 0:checkpoint_path = os.path.join(save_dir, f'checkpoint_epoch_{epoch+1}.pth')self.save_model(checkpoint_path, epoch, val_loss)print(f"✓ 保存检查点: {checkpoint_path}")# 早停检查if patience_counter >= max_patience:print(f"\n早停触发!验证损失连续 {max_patience} 轮未改善")breakprint(f"\n=== 训练完成 ===")print(f"最佳验证损失: {best_val_loss:.6f}")# 保存训练历史history_path = os.path.join(save_dir, 'training_history.json')with open(history_path, 'w') as f:json.dump(self.train_history, f, indent=2)print(f"训练历史保存至: {history_path}")def save_model(self, save_path, epoch=None, val_loss=None):"""保存模型参数:save_path: 保存路径epoch: 当前epochval_loss: 验证损失"""checkpoint = {'model_state_dict': self.tokenizer.state_dict(),'optimizer_state_dict': self.optimizer.state_dict(),'scheduler_state_dict': self.scheduler.state_dict(),'config': self.config,'scaler_params': {'mean_': self.scaler.mean_.tolist() if hasattr(self.scaler, 'mean_') else None,'scale_': self.scaler.scale_.tolist() if hasattr(self.scaler, 'scale_') else None},'train_history': self.train_history,'epoch': epoch,'val_loss': val_loss,'timestamp': datetime.now().isoformat()}torch.save(checkpoint, save_path)def load_model(self, load_path):"""加载模型参数:load_path: 模型路径"""checkpoint = torch.load(load_path, map_location=self.device)# 恢复配置self.config = checkpoint['config']# 创建模型self.create_model()self.tokenizer.load_state_dict(checkpoint['model_state_dict'])# 恢复标准化器if checkpoint['scaler_params']['mean_'] is not None:self.scaler.mean_ = np.array(checkpoint['scaler_params']['mean_'])self.scaler.scale_ = np.array(checkpoint['scaler_params']['scale_'])# 恢复训练历史self.train_history = checkpoint.get('train_history', {})print(f"模型已从 {load_path} 加载")print(f"训练轮数: {checkpoint.get('epoch', 'Unknown')}")print(f"验证损失: {checkpoint.get('val_loss', 'Unknown')}")return checkpointdef evaluate(self, test_loader):"""评估模型性能参数:test_loader: 测试数据加载器返回:dict: 评估结果"""if self.tokenizer is None:raise ValueError("请先加载模型")self.tokenizer.eval()total_loss_sum = 0recon_loss_sum = 0quant_loss_sum = 0mse_sum = 0mae_sum = 0num_batches = 0num_samples = 0print("\n=== 模型评估 ===")with torch.no_grad():for batch_x, in tqdm(test_loader, desc='评估中'):batch_x = batch_x.to(self.device)# 计算损失total_loss, recon_loss, quant_loss = self.compute_loss(batch_x)# 重构数据indices = self.tokenizer.encode(batch_x)reconstructed = self.tokenizer.decode(indices)# 计算指标mse = torch.mean((batch_x - reconstructed) ** 2)mae = torch.mean(torch.abs(batch_x - reconstructed))# 累计total_loss_sum += total_loss.item()recon_loss_sum += recon_loss.item()quant_loss_sum += quant_loss.item()mse_sum += mse.item()mae_sum += mae.item()num_batches += 1num_samples += batch_x.size(0)# 计算平均指标results = {'total_loss': total_loss_sum / num_batches,'recon_loss': recon_loss_sum / num_batches,'quant_loss': quant_loss_sum / num_batches,'mse': mse_sum / num_batches,'mae': mae_sum / num_batches,'num_samples': num_samples}# 打印结果print(f"测试样本数: {results['num_samples']}")print(f"总损失: {results['total_loss']:.6f}")print(f"重构损失: {results['recon_loss']:.6f}")print(f"量化损失: {results['quant_loss']:.6f}")print(f"MSE: {results['mse']:.6f}")print(f"MAE: {results['mae']:.6f}")return resultsdef plot_training_history(self, save_path=None):"""绘制训练历史参数:save_path: 图片保存路径"""if not self.train_history['epoch']:print("没有训练历史数据")returnfig, axes = plt.subplots(2, 2, figsize=(15, 10))# 总损失axes[0, 0].plot(self.train_history['epoch'], self.train_history['train_loss'], label='训练损失', color='blue')axes[0, 0].plot(self.train_history['epoch'], self.train_history['val_loss'], label='验证损失', color='red')axes[0, 0].set_title('总损失')axes[0, 0].set_xlabel('Epoch')axes[0, 0].set_ylabel('Loss')axes[0, 0].legend()axes[0, 0].grid(True)# 重构损失axes[0, 1].plot(self.train_history['epoch'], self.train_history['train_recon_loss'], label='训练重构损失', color='blue')axes[0, 1].plot(self.train_history['epoch'], self.train_history['val_recon_loss'], label='验证重构损失', color='red')axes[0, 1].set_title('重构损失')axes[0, 1].set_xlabel('Epoch')axes[0, 1].set_ylabel('Reconstruction Loss')axes[0, 1].legend()axes[0, 1].grid(True)# 量化损失axes[1, 0].plot(self.train_history['epoch'], self.train_history['train_quant_loss'], label='训练量化损失', color='blue')axes[1, 0].plot(self.train_history['epoch'], self.train_history['val_quant_loss'], label='验证量化损失', color='red')axes[1, 0].set_title('量化损失')axes[1, 0].set_xlabel('Epoch')axes[1, 0].set_ylabel('Quantization Loss')axes[1, 0].legend()axes[1, 0].grid(True)# 学习率axes[1, 1].plot(self.train_history['epoch'], self.train_history['learning_rate'], color='green')axes[1, 1].set_title('学习率')axes[1, 1].set_xlabel('Epoch')axes[1, 1].set_ylabel('Learning Rate')axes[1, 1].set_yscale('log')axes[1, 1].grid(True)plt.tight_layout()if save_path:plt.savefig(save_path, dpi=300, bbox_inches='tight')print(f"训练历史图保存至: {save_path}")plt.show()def visualize_reconstruction(self, test_loader, num_samples=3, save_path=None):"""可视化重构结果参数:test_loader: 测试数据加载器num_samples: 可视化样本数save_path: 图片保存路径"""if self.tokenizer is None:raise ValueError("请先加载模型")self.tokenizer.eval()# 获取测试样本with torch.no_grad():for batch_x, in test_loader:batch_x = batch_x.to(self.device)# 重构indices = self.tokenizer.encode(batch_x)reconstructed = self.tokenizer.decode(indices)# 转换回CPUoriginal = batch_x.cpu().numpy()recon = reconstructed.cpu().numpy()break# 特征名称feature_names = ['Open', 'High', 'Low', 'Close', 'Volume']# 绘制fig, axes = plt.subplots(num_samples, 5, figsize=(20, 4*num_samples))if num_samples == 1:axes = axes.reshape(1, -1)for sample_idx in range(min(num_samples, original.shape[0])):for feature_idx in range(5):ax = axes[sample_idx, feature_idx]# 原始数据ax.plot(original[sample_idx, :, feature_idx], label='原始', color='blue', alpha=0.7)# 重构数据ax.plot(recon[sample_idx, :, feature_idx], label='重构', color='red', alpha=0.7, linestyle='--')ax.set_title(f'样本 {sample_idx+1} - {feature_names[feature_idx]}')ax.set_xlabel('时间步')ax.set_ylabel('标准化值')ax.legend()ax.grid(True, alpha=0.3)plt.tight_layout()if save_path:plt.savefig(save_path, dpi=300, bbox_inches='tight')print(f"重构可视化图保存至: {save_path}")plt.show()def main():"""主训练函数"""print("=== KronosTokenizer 训练脚本 ===")# 配置config = {'d_in': 5,'d_model': 256,'n_heads': 8,'ff_dim': 1024,'n_enc_layers': 6,'n_dec_layers': 6,'ffn_dropout_p': 0.1,'attn_dropout_p': 0.1,'resid_dropout_p': 0.1,'s1_bits': 8,'s2_bits': 8,'beta': 1.0,'gamma0': 1.0,'gamma': 1.0,'zeta': 1.0,'group_size': 1}# 创建训练器trainer = KronosTokenizerTrainer(config=config)# 准备数据train_loader, val_loader, test_loader = trainer.prepare_data(symbol='ETHUSDT',timeframe='5m',limit=5000,seq_len=512)# 创建模型trainer.create_model()# 设置训练trainer.setup_training(learning_rate=1e-4, weight_decay=1e-5)# 开始训练save_dir = './model_checkpoints'trainer.train(train_loader=train_loader,val_loader=val_loader,num_epochs=50,save_dir=save_dir)# 评估模型results = trainer.evaluate(test_loader)# 绘制训练历史trainer.plot_training_history(save_path=os.path.join(save_dir, 'training_history.png'))# 可视化重构结果trainer.visualize_reconstruction(test_loader, num_samples=3, save_path=os.path.join(save_dir, 'reconstruction_examples.png'))print("\n=== 训练完成 ===")if __name__ == '__main__':main()
首先是声明模型,准备数据,设置学习率和优化器。
损失计算的构建,
def compute_loss(self, batch_x, recon_weight=1.0, quant_weight=0.1):"""计算损失函数参数:batch_x: 输入批次recon_weight: 重构损失权重quant_weight: 量化损失权重返回:tuple: (总损失, 重构损失, 量化损失)"""# 前向传播(z_pre, z), bsq_loss, quantized, z_indices = self.tokenizer(batch_x)# 重构损失criterion = nn.MSELoss()recon_loss_pre = criterion(z_pre, batch_x)recon_loss_full = criterion(z, batch_x)recon_loss = 0.3 * recon_loss_pre + 0.7 * recon_loss_full# 总损失total_loss = recon_weight * recon_loss + quant_weight * bsq_lossreturn total_loss, recon_loss, bsq_loss
训练函数的写法
def train(self, train_loader, val_loader, num_epochs=50, save_dir='./checkpoints'):"""完整训练流程参数:train_loader: 训练数据加载器val_loader: 验证数据加载器num_epochs: 训练轮数save_dir: 模型保存目录"""if self.tokenizer is None or self.optimizer is None:raise ValueError("请先创建模型和设置训练组件")# 创建保存目录os.makedirs(save_dir, exist_ok=True)print(f"\n=== 开始训练 ===")print(f"训练轮数: {num_epochs}")print(f"模型保存目录: {save_dir}")best_val_loss = float('inf')patience_counter = 0max_patience = 10for epoch in range(num_epochs):print(f"\n--- Epoch {epoch+1}/{num_epochs} ---")# 训练train_loss, train_recon, train_quant = self.train_epoch(train_loader, epoch)# 验证val_loss, val_recon, val_quant = self.validate_epoch(val_loader, epoch)# 学习率调度self.scheduler.step(val_loss)current_lr = self.optimizer.param_groups[0]['lr']# 记录历史self.train_history['epoch'].append(epoch + 1)self.train_history['train_loss'].append(train_loss)self.train_history['train_recon_loss'].append(train_recon)self.train_history['train_quant_loss'].append(train_quant)self.train_history['val_loss'].append(val_loss)self.train_history['val_recon_loss'].append(val_recon)self.train_history['val_quant_loss'].append(val_quant)self.train_history['learning_rate'].append(current_lr)# 打印结果print(f"训练损失: {train_loss:.6f} (重构: {train_recon:.6f}, 量化: {train_quant:.6f})")print(f"验证损失: {val_loss:.6f} (重构: {val_recon:.6f}, 量化: {val_quant:.6f})")print(f"学习率: {current_lr:.2e}")# 保存最佳模型if val_loss < best_val_loss:best_val_loss = val_losspatience_counter = 0best_model_path = os.path.join(save_dir, 'best_model.pth')self.save_model(best_model_path, epoch, val_loss)print(f"✓ 保存最佳模型: {best_model_path}")else:patience_counter += 1# 定期保存检查点if (epoch + 1) % 10 == 0:checkpoint_path = os.path.join(save_dir, f'checkpoint_epoch_{epoch+1}.pth')self.save_model(checkpoint_path, epoch, val_loss)print(f"✓ 保存检查点: {checkpoint_path}")# 早停检查if patience_counter >= max_patience:print(f"\n早停触发!验证损失连续 {max_patience} 轮未改善")breakprint(f"\n=== 训练完成 ===")print(f"最佳验证损失: {best_val_loss:.6f}")# 保存训练历史history_path = os.path.join(save_dir, 'training_history.json')with open(history_path, 'w') as f:json.dump(self.train_history, f, indent=2)print(f"训练历史保存至: {history_path}")
先写到这里。
使用设备: cuda=== 数据准备 ===
获取 ETHUSDT 5m 数据,共 5000 条...
✓ 交易对 ETHUSDT 验证成功,当前价格: $4419.5500
初始化数据获取器 - 交易对: ETHUSDT
币种名称: Ethereum
正在获取ETHUSDT 5分钟K线数据...已获取: 1000 条...已获取: 2000 条...已获取: 3000 条...已获取: 4000 条...已获取: 5000 条...数据行数: 5000时间范围: 2025-08-25 14:55:00 到 2025-09-11 23:30:00当前ETH价格: $4419.54数据时间跨度: 17 days 08:35:00
数据文件保存路径: g:\Kronos-master\Kronos-master\multi_timeframe_data\ETHUSDT_5m_5000_20250911_233307.csv
数据时间范围: 2025-08-25 14:55:00 到 2025-09-11 23:30:00
创建了 4489 个长度为 512 的序列
数据集划分: 训练集 3591, 验证集 448, 测试集 450=== 模型信息 ===
总参数量: 10,514,709
可训练参数量: 10,514,709
模型配置: {'d_in': 5, 'd_model': 256, 'n_heads': 8, 'ff_dim': 1024, 'n_enc_layers': 6, 'n_dec_layers': 6, 'ffn_dropout_p': 0.1, 'attn_dropout_p': 0.1, 'resid_dropout_p': 0.1, 's1_bits': 8, 's2_bits': 8, 'beta': 1.0, 'gamma0': 1.0, 'gamma': 1.0, 'zeta': 1.0, 'group_size': 1}=== 训练设置 ===
优化器: AdamW, 学习率: 0.0001, 权重衰减: 1e-05
调度器: ReduceLROnPlateau=== 开始训练 ===
训练轮数: 50
模型保存目录: ./model_checkpoints--- Epoch 1/50 ---
Epoch 1 [训练]: 4%|▉ | 5/113 [00:12<03:15, 1.81s/it, Loss=0.6489, Recon=0.6343, Quant=0.1463]