前端全链路质量监控体系建设与实践分享
一、引言:构建全方位质量防护网
在前端应用复杂度日益提升的今天,单一维度的质量监控已无法满足业务需求。从 H5 页面上线前的即时检测到 App 发版后的持续监控,全链路质量监控体系如同一张精密的防护网,贯穿产品生命周期的每个阶段。本次分享将围绕 HTML5 与 App 的质量监控场景,从上线前检测、上线后监控、业务基调监控等维度,详解技术方案与落地实践。
二、上线前:H5 质量即时检测体系
(一)页面错误检测:筑牢第一道防线
上线前的错误检测需覆盖前端运行时的核心风险点:
JS 报错检测:通过 ESLint 静态扫描 + JSHint 运行时检查,捕捉语法错误、未定义变量等问题,例如:
// 检测示例:未使用的变量警告
if (true) {const unusedVar = 123; // ESLint会提示'no-unused-vars'错误
}接口报错模拟:使用 Postman 或自研接口检测工具,模拟网络异常场景(如 404、500 错误),验证前端错误处理逻辑。
白屏检测:通过 Puppeteer 无头浏览器渲染页面,监控 onload/error 事件,识别因 JS 执行阻塞导致的白屏问题。
(二)页面性能检测:从加载速度到资源优化
性能检测需建立多维度指标体系:
核心加载指标:
完全加载时间(window.load 事件)
首屏渲染时间(First Contentful Paint, FCP)
资源优化检测:
HTML/JS/CSS 压缩率(gzip 后文件大小对比)
大文件识别(单 JS 文件 > 500KB、单图 > 2MB 自动告警)
资源数量控制(JS/CSS 文件数建议≤20 个,避免过多请求)
服务器配置检测:
Gzip 压缩启用状态(通过 curl -I 检测 Content-Encoding 头)
缓存策略验证(Cache-Control/Expires 字段是否合理)
(三)页面安全检测:防患于未然
安全检测需聚焦前端常见风险:
HTTP/HTTPS 合规性:确保生产环境强制启用 HTTPS,通过 SSL Labs 检测证书有效性。
XSS 防护检测:
验证 DOM 操作是否使用 innerText 而非 innerHTML
检测表单输入是否添加防抖 + 正则过滤
模拟恶意脚本注入,验证 CSP(Content Security Policy)策略是否生效
(四)流程卡口:让检测融入研发链路
运营卡口:在活动配置平台增加 “性能检测” 按钮,自动触发资源合规性检查。
研发卡口:在上线系统中设置强制检测环节,未通过性能 / 安全检测的版本无法发布。
三、上线后:H5 性能与错误实时监控
(一)运行时监控核心模块
上线后的监控需实现 “问题发现 - 定位 - 解决” 闭环:
页面性能监控:
采集指标:LCP(最大内容绘制)、TTFB(首字节时间)、FID(首次输入延迟)
工具推荐:Google Analytics、自研埋点系统
JS 错误监控:
捕获 Error 事件与 unhandledrejection 事件
错误信息需包含:堆栈轨迹、错误类型、发生页面路径
API 接口监控:
记录接口响应时间、成功率、错误码分布
示例:对超时接口(>500ms)自动标记为红色告警
(二)数据可视化与分析
统计报表体系:
大盘走势:按小时 / 天展示性能指标趋势,设置阈值触发告警
地域分布:识别不同地区网络环境对性能的影响
运营商维度:针对性优化弱网环境(如移动 2G)的加载策略
用户轨迹追踪:
通过 session 记录用户操作路径,复现错误场景
示例:用户在提交表单时遇到 JS 报错,轨迹可定位到具体操作步骤
(三)智能告警与闭环处理
告警规则配置:
性能指标同比下降 10% 自动触发告警
错误率超过 0.5% 时通知前端团队
告警收敛机制:
相同错误 10 分钟内仅通知一次,避免告警风暴
与 IM 工具集成(如飞书、钉钉),告警直接推送到对应业务群
四、线上业务:基调监控与竞品分析
(一)多点基调监控:模拟真实用户体验
监控节点部署:
国内:北上广深等核心城市部署探测点
海外:覆盖东南亚、欧美主要节点
监控频率与指标:
每 10 分钟模拟用户访问核心页面
采集指标:DNS 解析时间、TCP 连接时间、首屏渲染时间
(二)竞品性能对比:知己知彼
竞品监控维度:
核心页面加载速度对比(如电商首页、结算页)
资源加载策略分析(同步 / 异步加载方式)
数据应用场景:
性能优化优先级排序:针对落后于竞品的指标重点优化
技术方案选型参考:如竞品使用 WebP 图片格式,可评估引入可行性
(三)智能告警与应急响应
告警联动机制:
基调监控发现页面加载超时,自动触发线上用户真实数据核查
与 CDN 厂商 API 联动,检测是否因节点故障导致性能波动
应急响应流程:
告警触发 → 2. 自动抓取错误现场数据 → 3. 通知核心团队 → 4. 执行降级策略 → 5. 故障复盘
五、发版后:App 性能与错误监控体系
(一)移动端特有监控场景
App 监控需考虑设备碎片化、网络环境复杂等特点:
启动性能监控:
冷启动时间(从点击图标到首屏渲染)
热启动时间(从后台切回前台的恢复时间)
崩溃监控:
捕获 Java 层崩溃(Force Close)与 Native 层崩溃(Segmentation Fault)
崩溃日志需包含:设备型号、系统版本、操作路径
页面切换监控:
记录页面跳转耗时,识别因组件卸载 / 加载导致的卡顿
采集 FPS(帧率)数据,定位动画渲染问题
(二)网络与 WebView 专项监控
网络请求监控:
按网络类型(2G/3G/4G/WiFi)分类统计请求耗时
弱网环境下的请求重试策略有效性验证
WebView 监控:
内存泄漏检测:监听 WebView 的 onDestroy 事件,防止 JS 对象与原生对象互相引用
资源加载监控:识别 WebView 中 H5 页面的加载瓶颈
(三)报警服务与用户体验优化
分级报警策略:
P0 级:App 崩溃率突增 50% 以上,立即通知全员
P1 级:启动时间超过 3000ms,通知前端与客户端团队
用户体验优化方向:
基于监控数据做针对性优化:如发现某机型崩溃率高,优先适配该机型
弱网优化:根据运营商监控数据,针对 2G 用户启用资源懒加载策略
六、全链路监控体系落地实践
(一)工具选型与集成方案
H5 监控工具组合:
基础埋点:Google Analytics + 自研日志上报系统
错误监控:Sentry + 前端日志中心
性能检测:WebPageTest + 自研检测脚本
App 监控方案:
崩溃监控:Bugly + Firebase Crashlytics
性能监控:PerfDog + 自研 SDK
网络监控:Charles + 移动端日志系统
(二)团队协作与流程规范
监控数据共享机制:
每周生成《质量监控报告》,同步产品、设计、开发团队
建立 “监控数据驱动决策” 的例会制度,例如:根据线上错误率调整测试用例优先级
问题闭环处理流程:
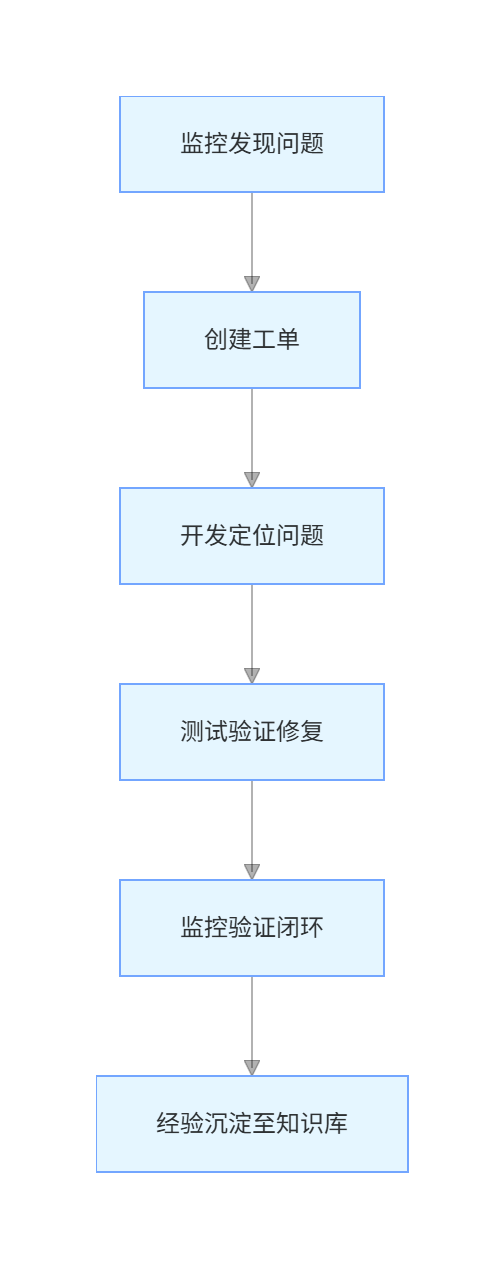
(三)持续优化与技术演进
监控指标迭代:
每季度评估现有指标覆盖率,新增业务特有的监控项(如电商的 “加入购物车” 按钮点击成功率)
新技术引入:
探索 AI 驱动的异常检测:使用机器学习识别性能指标的异常波动(如 LSTM 时间序列模型)
尝试全链路追踪:通过 OpenTelemetry 实现前端与后端请求的关联追踪,快速定位跨层问题
七、总结:监控体系的价值与未来
全链路质量监控体系不仅是发现问题的工具,更是驱动团队技术升级的引擎。通过从上线前到发版后的全周期监控,我们能够:
提前预防:上线前检测机制将 80% 的潜在问题拦截在开发阶段
快速响应:线上监控实现 90% 的故障在 5 分钟内发现并告警
数据驱动:用真实用户数据指导技术决策,避免经验主义
未来,随着边缘计算、5G 网络的普及,前端监控体系将向 “智能化、自动化、全链路” 方向演进。建议团队分阶段落地:
基础阶段:3 个月内完成 H5 与 App 的基础监控埋点,实现错误与性能的实时告警
进阶阶段:6 个月内构建基调监控与竞品分析能力,建立数据可视化大盘
成熟阶段:1 年内实现监控数据与研发流程的深度融合,如自动生成优化建议、智能推荐修复方案
附件:团队可参考的监控指标清单与工具配置模板,可联系技术负责人获取详细文档。