(ICLR-2025)深度压缩自动编码器用于高效高分辨率扩散模型
深度压缩自动编码器用于高效高分辨率扩散模型
paper title:DEEP COMPRESSION AUTOENCODER FOR
EFFICIENT HIGH-RESOLUTION DIFFUSION MODELS
paper是MIT发表在ICLR 2025的工作
Code:链接
ABSTRACT
我们提出了深度压缩自动编码器(DC-AE),这是一种用于加速高分辨率扩散模型的新型自动编码器系列。现有的自动编码器在中等空间压缩比(例如 8×8\times8×)下已经展示出令人印象深刻的结果,
但在高空间压缩比(例如 64×64\times64×)时难以维持令人满意的重建精度。我们通过引入两个关键技术来解决这一挑战:(1) 残差自动编码(Residual Autoencoding),我们设计模型以在空间到通道变换(space-to-channel transformed)特征的基础上学习残差,以缓解高空间压缩自动编码器的优化困难;(2) 解耦高分辨率自适应(Decoupled High-Resolution Adaptation),这是一种高效的三阶段解耦训练策略,用于减轻高空间压缩自动编码器的泛化性能损失。通过这些设计,我们将自动编码器的空间压缩比提升至 128128128,同时保持重建质量。将我们的 DC-AE 应用于潜空间扩散模型(latent diffusion models)时,在不降低精度的情况下显著提升了速度。例如,在 ImageNet 512×512512 \times 512512×512 上,我们的 DC-AE 在 H100 GPU 上对 UViT-H 提供了 19.1×19.1\times19.1× 的推理加速和 17.9×17.9\times17.9× 的训练加速,同时相比广泛使用的 SD-VAE-f8 自动编码器取得了更优的 FID 分数。
1 INTRODUCTION
潜空间扩散模型(Rombach 等人,2022)已成为图像生成的主流框架,并在图像合成方面取得了巨大成功(Labs,2024;Esser 等人,2024)。它们通过使用自动编码器将图像投影到潜空间中,以降低扩散模型的计算成本。例如,目前主流的潜空间扩散模型解决方案(Rombach 等人,2022;Labs,2024;Esser 等人,2024;Chen 等人,2024a,b)是使用具有 888 倍空间压缩比(记作 f8)的自动编码器,将空间尺寸为 H×WH \times WH×W 的图像转换为空间尺寸为H8×W8\frac{H}{8} \times \frac{W}{8}8H×8W的潜特征。这一空间压缩比对低分辨率图像生成(如 256×256256 \times 256256×256)是令人满意的。然而,在高分辨率图像合成(例如 1024×10241024 \times 10241024×1024)中,进一步提高空间压缩比显得尤为关键,尤其是对于扩散 Transformer 模型(Peebles & Xie,2023;Bao 等人,2023),其计算复杂度与 token 数量成平方关系。

图 1:DC-AE 通过提高自动编码器的空间压缩比来加速扩散模型。
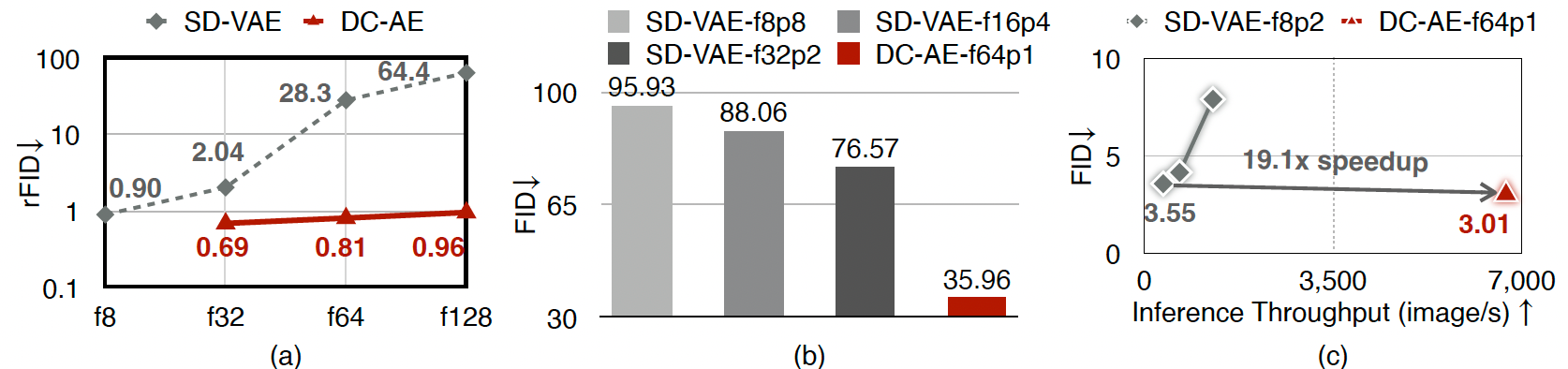
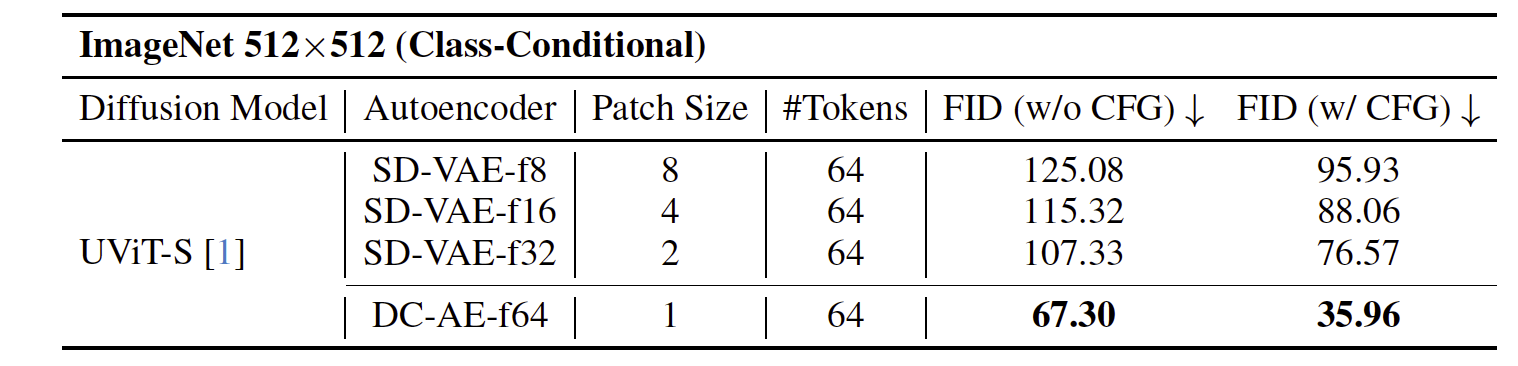
图 2:(a) ImageNet 256×256256 \times 256256×256 上的图像重建结果。f 表示空间压缩比。
随着空间压缩比的增加,SD-VAE 的重建精度显著下降(rFID 上升),而 DC-AE 不存在这一问题。
(b) 使用不同自动编码器的 UViT-S 在 ImageNet 512×512512 \times 512512×512 上的图像生成结果。p 表示 patch 大小。将 token 压缩任务转移到自动编码器使得扩散模型可以更加专注于去噪任务,从而获得更好的 FID。© 与 SD-VAE-f8 在 UViT 各变体上的 ImageNet 512×512512 \times 512512×512 表现对比。DC-AE-f64p1 相较于 SD-VAE-f8p2 在 UViT-H 上提供了 19.1×19.1\times19.1× 更高的推理吞吐量,并提升了 0.54 的 ImageNet FID。
目前进一步降低空间尺寸的常见做法是在扩散模型端进行下采样。
例如,在扩散 Transformer 模型中(Peebles & Xie,2023;Bao 等人,2023),这是通过使用 patch 嵌入层实现的,该层具有 patch 大小 ppp,能将潜特征压缩为H8p×W8p\frac{H}{8p} \times \frac{W}{8p}8pH×8pW的 token 数量。相比之下,在自动编码器方面投入的精力较少。阻碍高空间压缩自动编码器应用的主要瓶颈是其重建精度下降。例如,图 2(a) 展示了 SD-VAE(Rombach 等人,2022)在 ImageNet 256×256256 \times 256256×256 上不同空间压缩比下的重建结果。可以看出,rFID(重建 FID)从 f8 到 f64 会从 0.90 恶化为 28.3。
本工作提出了 深度压缩自动编码器(DC-AE),这是一个用于高分辨率图像合成的高空间压缩自动编码器新系列。通过分析高空间压缩和低空间压缩自动编码器之间精度退化的根本原因,我们发现高空间压缩自动编码器更难以优化(第 3.1 节),并在跨分辨率时存在较大的泛化惩罚(图 3b)。为了解决这两个挑战,我们引入了两个关键技术:首先,我们提出 残差自动编码(Residual Autoencoding)(图 4),以缓解高空间压缩自动编码器的优化难度。它为自动编码器引入了额外的非参数捷径,使网络模块可以基于空间到通道(space-to-channel)操作学习残差。其次,我们提出 解耦高分辨率适应(Decoupled High-Resolution Adaptation)(图 6)来应对另一个挑战。
该方法引入了一个高分辨率潜空间适应阶段和一个低分辨率局部细化阶段,以避免泛化惩罚,同时保持较低的训练成本。
通过这些技术,我们将自动编码器的空间压缩比提升到 32、64 和 128,同时保持良好的重建精度(表 2)。扩散模型可以完全专注于去噪任务,由我们的 DC-AE 负责整个 token 压缩任务,从而比以往方法获得更好的图像生成结果(表 3)。例如,将 SD-VAE-f8 替换为我们的 DC-AE-f64 时,我们在 UViT-H(Bao 等人,2023)上实现了:
- 17.9×17.9\times17.9× 的 H100 训练吞吐量提升
- 19.1×19.1\times19.1× 的 H100 推理吞吐量提升
- 并将 ImageNet 512×512512 \times 512512×512 的 FID 从 3.55 提升至 3.01
我们的贡献总结如下:
- 我们分析了提高自动编码器空间压缩比的挑战,并提供了应对这些挑战的见解。
- 我们提出了残差自动编码和解耦高分辨率适应,有效提高了高空间压缩自动编码器的重建精度,使其在潜空间扩散模型中成为可行选择。
- 我们构建了 DC-AE,一个基于我们技术的新型自动编码器系列。与现有自动编码器相比,它在训练和推理速度上为扩散模型带来了显著提升。
2 RELATED WORK
用于扩散模型的自动编码器。
在高分辨率像素空间中直接训练和评估扩散模型会带来极高的计算成本。
为了解决这一问题,Rombach 等人(2022)提出了潜空间扩散模型(latent diffusion models),
该模型在由预训练自动编码器生成的压缩潜空间中运行。
所提出的自动编码器具有 8×8\times8× 的空间压缩比和 4 个潜通道,
并在后续工作中被广泛采用(Peebles & Xie,2023;Bao 等人,2023)。
自那以后,后续研究主要集中在通过增加潜通道数量来提升 f8 自动编码器的重建精度
(Esser 等人,2024;Dai 等人,2023;Labs,2024)。
此外,为了提高重建质量,Zhu 等人(2023)采用了更复杂的解码器并结合了任务特定的先验。
与以往工作相比,我们的研究专注于一个正交方向,即提高自动编码器的空间压缩比(例如 f64)。
据我们所知,这是在这一关键但尚未深入探索的方向上的首次研究。
扩散模型加速。
扩散模型已被广泛用于图像生成,并取得了令人印象深刻的结果(Labs,2024;Esser 等人,2024)。
然而,扩散模型计算开销巨大,这促使许多研究致力于加速扩散模型。
一种典型策略是通过训练无关的少步采样器(Song 等人,2021;Lu 等人,2022a,b;Zheng 等人,2023;
Zhang & Chen,2023;Zhang 等人,2023;Zhao 等人,2024b;Shih 等人,2024;Tang 等人,2024)
或基于蒸馏的方法(Meng 等人,2023;Salimans & Ho,2022;Yin 等人,2024a,b;
Song 等人,2023;Luo 等人,2023;Liu 等人,2023),
来减少推理采样步骤的数量。
另一种典型策略是通过利用稀疏性(Li 等人,2022;Ma 等人,2024b)或量化(He 等人,2024;
Fang 等人,2024;Li 等人,2023;Zhao 等人,2024a)来实现模型压缩。
设计高效的扩散模型架构(Li 等人,2024d;Liu 等人,2024;Cai 等人,2024)
或推理系统(Li 等人,2024b;Wang 等人,2024)也是提高效率的有效方法。
此外,提升数据质量(Chen 等人,2024a,b)也能提高扩散模型的训练效率。
所有这些工作都专注于扩散模型本身,而自动编码器保持不变。
我们的工作为加速扩散模型开辟了一个新方向,可以同时提升训练和推理效率。
3 METHOD
在本节中,我们首先分析为什么现有的高空间压缩自动编码器(例如 SD-VAE-f64)无法达到低空间压缩自动编码器(例如 SD-VAE-f8)的精度。然后,我们介绍结合残差自动编码(Residual Autoencoding)和解耦高分辨率适应(Decoupled High-Resolution Adaptation)的深度压缩自动编码器(DC-AE),以弥合这一精度差距。最后,我们讨论 DC-AE 在潜空间扩散模型中的应用。
3.1 MOTIVATION
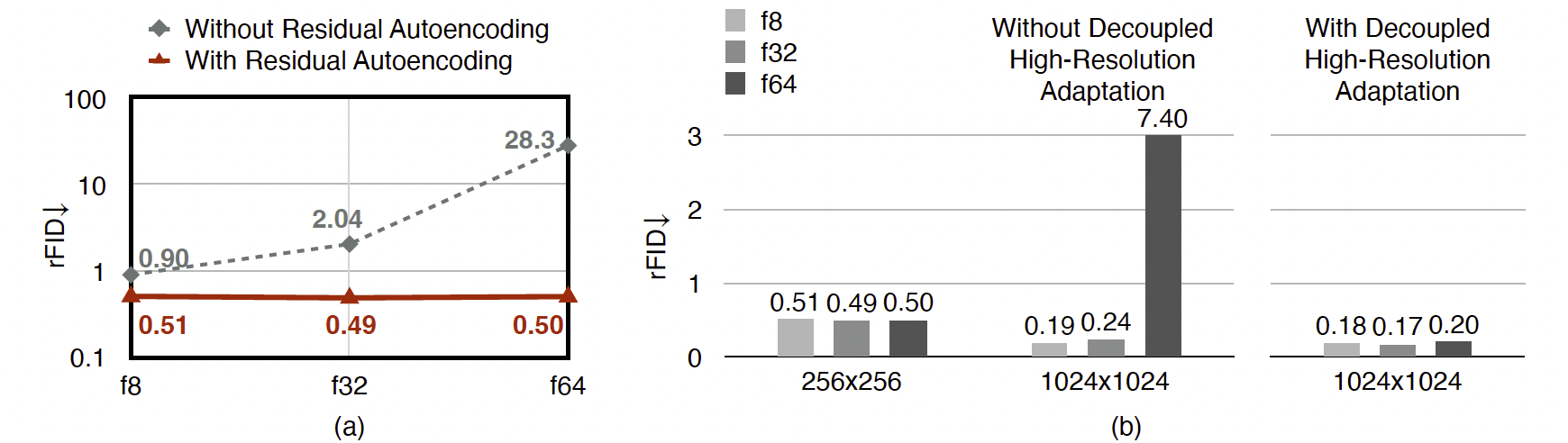
图 3:(a) 高空间压缩自动编码器更难以优化。即使具有相同的潜在形状和更强的学习能力,它仍然无法达到 f8 自动编码器的 rFID。(b) 高空间压缩自动编码器在从低分辨率泛化到高分辨率时会遭遇显著的重建精度下降。
我们进行了消融实验,以深入理解高空间压缩自动编码器与低空间压缩自动编码器之间精度差距的根本原因。具体而言,我们考虑了三种设置,其空间压缩比逐步增加,从 f8 到 f64。每次空间压缩比增加时,我们都会在当前自动编码器上堆叠额外的编码器和解码器阶段。通过这种方式,高空间压缩自动编码器包含低空间压缩自动编码器作为子网络,因此具有更高的学习能力。
此外,我们增加了潜通道数量,以在不同设置中保持相同的潜在总大小。然后我们可以通过应用空间到通道的操作(Shi et al., 2016),将潜在表示转换为更高空间压缩比的形式:$
H \times W \times C \rightarrow \frac{H}{p} \times \frac{W}{p} \times p^{2}C
$
我们在图 3 中总结了结果(a,灰色虚线)。即使在相同的潜在总大小和更强的学习能力下,当空间压缩比增加时,我们仍然观察到重建精度下降。这表明,增加的编码器和解码器阶段(由多个 SD-VAE 构建模块组成)的效果甚至比一个简单的空间到通道操作更差。
基于这一发现,我们推测精度差距来自模型学习过程:虽然我们在参数空间中有良好的局部最优解,但优化困难阻碍了高空间压缩自动编码器达到这些局部最优解。
3.2 DEEP COMPRESSION AUTOENCODER
图 4:残差自动编码示意图。它添加了非参数捷径,使神经网络模块能够基于空间到通道的操作学习残差。‘C’ 表示通道数。‘R’ 表示图像尺寸。
残差自动编码。受到前文分析的启发,我们引入了残差自动编码来解决精度差距。总体思路如图 4 所示。与传统设计的核心区别在于,我们显式地让神经网络模块基于空间到通道(space-to-channel)的操作来学习下采样残差,从而缓解优化困难。与 ResNet(He et al., 2016)不同,这里的残差不是恒等映射,而是空间到通道的映射。
在实践中,这通过在编码器的下采样模块和解码器的上采样模块中加入额外的非参数捷径来实现。具体而言,对于下采样模块,非参数捷径是空间到通道的操作,随后通过非参数的通道平均操作来匹配通道数量。例如,假设下采样模块的输入特征图形状为 H×W×CH \times W \times CH×W×C,其输出特征图形状为 H2×W2×2C\frac{H}{2} \times \frac{W}{2} \times 2C2H×2W×2C,则增加的捷径为:
H×W×C→space-to-channelH2×W2×4C→split into two groups[H2×W2×2C,H2×W2×2C]→averageH2×W2×2CH \times W \times C \ \xrightarrow{\text{space-to-channel}}\ \frac{H}{2} \times \frac{W}{2} \times 4C \ \xrightarrow{\text{split into two groups}}\ \Big[\frac{H}{2} \times \frac{W}{2} \times 2C,\ \frac{H}{2} \times \frac{W}{2} \times 2C\Big] \ \xrightarrow{\text{average}}\ \frac{H}{2} \times \frac{W}{2} \times 2C H×W×C space-to-channel 2H×2W×4C split into two groups [2H×2W×2C, 2H×2W×2C] average 2H×2W×2C
相应地,对于上采样模块,非参数捷径是通道到空间(channel-to-space)的操作,随后通过非参数的通道复制操作来实现:
H2×W2×2C→channel-to-spaceH×W×C2→duplicate[H×W×C2,H×W×C2]→concatH×W×C\frac{H}{2} \times \frac{W}{2} \times 2C \ \xrightarrow{\text{channel-to-space}}\ H \times W \times \frac{C}{2} \ \xrightarrow{\text{duplicate}}\ \Big[H \times W \times \frac{C}{2},\ H \times W \times \frac{C}{2}\Big] \ \xrightarrow{\text{concat}}\ H \times W \times C 2H×2W×2C channel-to-space H×W×2C duplicate [H×W×2C, H×W×2C] concat H×W×C
除了下采样和上采样模块之外,我们还根据相同的原则改变了中间阶段的设计(图 10b,右)。图 3(a) 展示了在 ImageNet 256×256256 \times 256256×256 上使用和不使用残差自动编码的对比。可以看出,残差自动编码有效提升了高空间压缩自动编码器的重建精度。

图 5:自动编码器在没有 GAN 损失的情况下已经能够学习重建内容和语义,而 GAN 损失则提升了局部细节并去除了局部伪影。我们用轻量化的局部细化训练替代了基于 GAN 损失的完整训练,该方法实现了相同的目标,同时具有更低的训练成本。
解耦高分辨率适应。仅使用残差自动编码可以在处理低分辨率图像时解决精度差距。然而,当将其扩展到高分辨率图像时,我们发现其效果不足。由于高分辨率训练的开销巨大,高分辨率扩散模型的常见做法是直接使用在低分辨率图像(例如 256×256256 \times 256256×256)上训练的自动编码器(Chen 等人,2024a,b)。这种策略对低空间压缩自动编码器效果良好。然而,高空间压缩自动编码器会遭遇显著的精度下降。例如,在图 3(b) 中,我们可以看到 f64 自动编码器在从 256×256256 \times 256256×256 泛化到 1024×10241024 \times 10241024×1024 时,其 rFID 从 0.50 恶化到 7.40。相比之下,f8 自动编码器在相同设置下的 rFID 从 0.51 改善为 0.19。此外,我们还发现,当使用更高的空间压缩比时,这一问题更为严重。在本研究中,我们将这一现象称为高空间压缩自动编码器的泛化惩罚。一个直接的解决方法是在高分辨率图像上进行训练。然而,这会导致极高的训练成本和不稳定的高分辨率 GAN 损失训练。
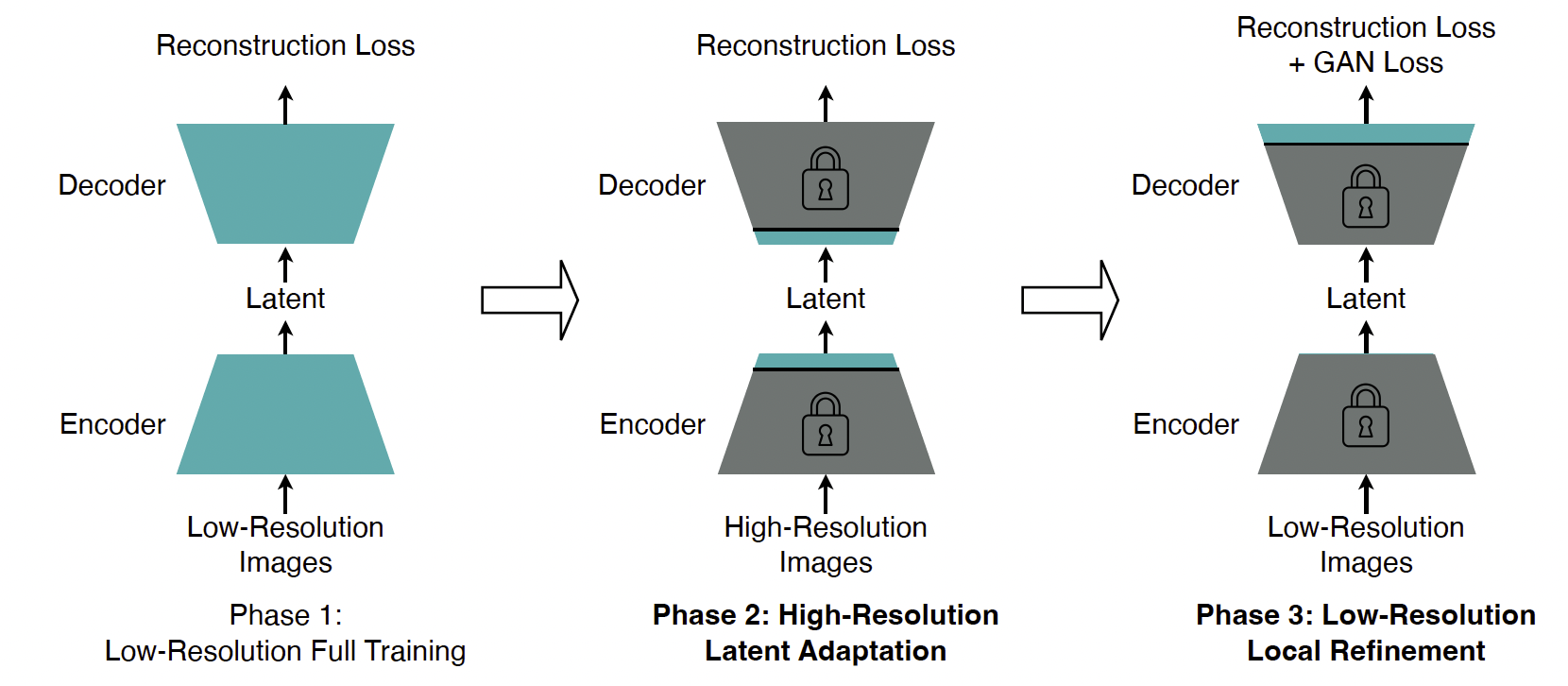
图 6:解耦高分辨率适应示意图。
为解决这一挑战,我们提出了解耦高分辨率适应。图 6 展示了详细的训练流程。与传统的单阶段训练策略(Rombach 等人,2022)相比,我们的解耦高分辨率适应有两个关键区别。
首先,我们将 GAN 损失训练与完整模型训练解耦,并引入专门的局部细化阶段用于 GAN 损失训练。在局部细化阶段(图 6,第 3 阶段),我们仅调整解码器的顶层,而冻结所有其他层。此设计的直觉基于以下发现:重建损失本身足以学习重建内容和语义;与此同时,GAN 损失主要用于提升局部细节和去除局部伪影(图 5)。为了实现相同的局部细化目标,仅调整解码器的顶层比完整训练具有更低的训练成本并带来更好的精度。
此外,这种解耦避免了 GAN 损失训练改变潜空间。这一方法使我们能够在低分辨率图像上进行局部细化阶段,而无需担心泛化惩罚。这进一步降低了第 3 阶段的训练成本,并避免了高分辨率 GAN 损失训练的高度不稳定性。
其次,我们引入了额外的高分辨率潜空间适应阶段(图 6,第 2 阶段),该阶段调整中间层(即编码器的顶层和解码器的输入层),以适配潜空间,从而缓解泛化惩罚。在实验中,我们发现仅调整中间层就足以解决这一问题(图 3b),同时其训练成本也低于高分辨率完整训练(内存消耗:153.98 GB → 67.81 GB)(Cai 等人,2020)。
3.3 APPLICATION TO LATENT DIFFUSION MODELS
将我们的 DC-AE 应用于潜空间扩散模型是直接而简单的。唯一需要改变的超参数是 patch 大小(Peebles & Xie,2023)。对于扩散 Transformer 模型(Peebles & Xie,2023;Bao 等人,2023),增加 patch 大小 ppp 是减少 token 数量的常见方法。这等价于先对给定潜表示应用空间到通道操作,将空间尺寸缩小 p×p\timesp×,然后使用 patch 大小为 1 的 Transformer 模型。
由于将低空间压缩自动编码器(例如 f8)与空间到通道操作结合也可以实现较高的空间压缩比,一个自然的问题是,这与直接使用 DC-AE 达到目标空间压缩比相比如何。
我们进行了消融实验,并在表 1 中总结了结果。可以看到,直接通过自动编码器达到目标空间压缩比在所有设置中表现最好。此外,我们还发现,将空间压缩比从扩散模型转移到自动编码器始终能带来更好的 FID。
表 1:关于 patch 大小和自动编码器空间压缩比的消融研究。