【Python】pytorch数据操作
目录
一、数据操作
1. 张量创建
编辑
2.随机张量创建
3.张量的属性
4.张量的操作
5.张量与Numpy转换
6.广播机制
二、数据预处理csv文件
一、数据操作
首先需要导入pytorch
import torch1. 张量创建
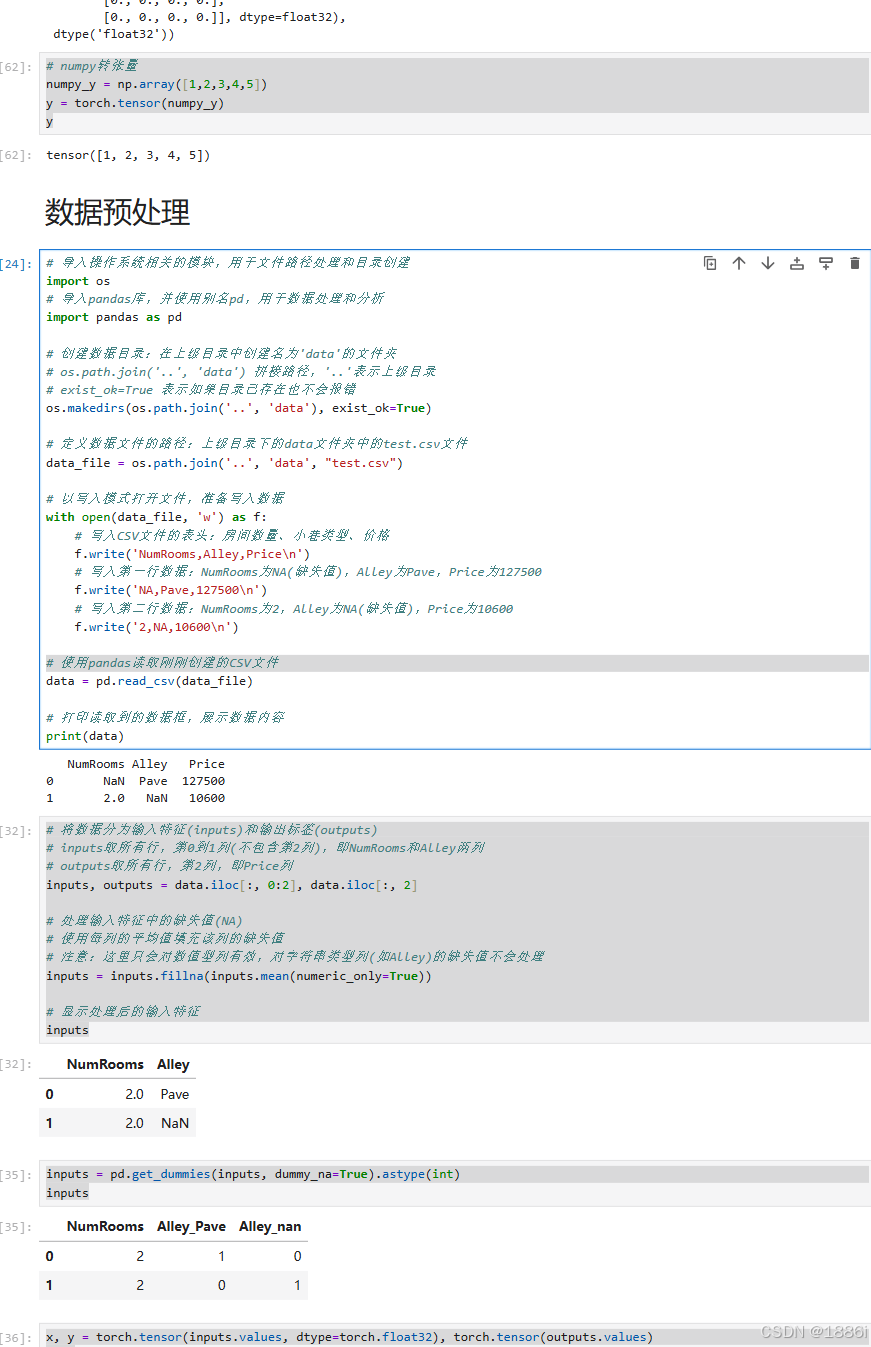
import torch# 创建未初始化的张量
x = torch.empty(3, 4) # 3行4列的未初始化张量# 创建随机初始化的张量
x = torch.rand(3, 4) # 元素值在[0,1)区间# 创建全零张量
x = torch.zeros(3, 4, dtype=torch.long) # 指定数据类型为长整型# 从列表创建张量
x = torch.tensor([5.5, 3])# 基于已有张量创建新张量(默认重用输入张量的属性)
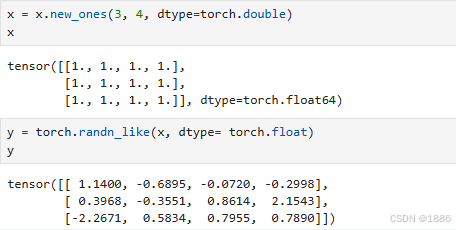
x = x.new_ones(3, 4, dtype=torch.double) # new_* 方法接收大小参数
y = torch.randn_like(x, dtype=torch.float) # 重用x的大小,但更改数据类型torch.empty创建未初始化全为0的张量
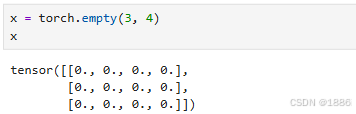
torch.rand()创建随机张量 元素的值在0-1之间
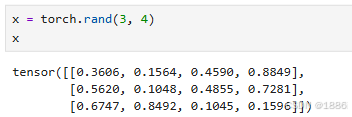
torch.zeros创建全零张量
torch.tensor()列表创建张量
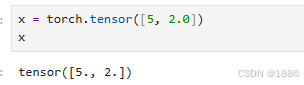
基于已有创建张量
2.随机张量创建
import torch# 设置随机种子,保证结果可复现
torch.manual_seed(42)# 均匀分布 [0, 1)
rand_uniform = torch.rand(2, 3)
print("均匀分布随机张量:")
print(rand_uniform)# 正态分布 (均值为0,方差为1)
rand_normal = torch.randn(2, 3)
print("\n标准正态分布随机张量:")
print(rand_normal)# 在[low, high)范围内生成整数随机张量
rand_int = torch.randint(low=0, high=10, size=(2, 3))
print("\n整数随机张量:")
print(rand_int)# 生成0和1的随机二进制张量
rand_binary = torch.randint(low=0, high=2, size=(2, 3))
print("\n二进制随机张量:")
print(rand_binary)# 从给定的张量中随机采样
source = torch.tensor([10, 20, 30, 40, 50])
rand_sample = torch.randperm(5) # 生成0到4的随机排列
sampled = source[rand_sample]
print("\n随机采样结果:")
print(sampled)
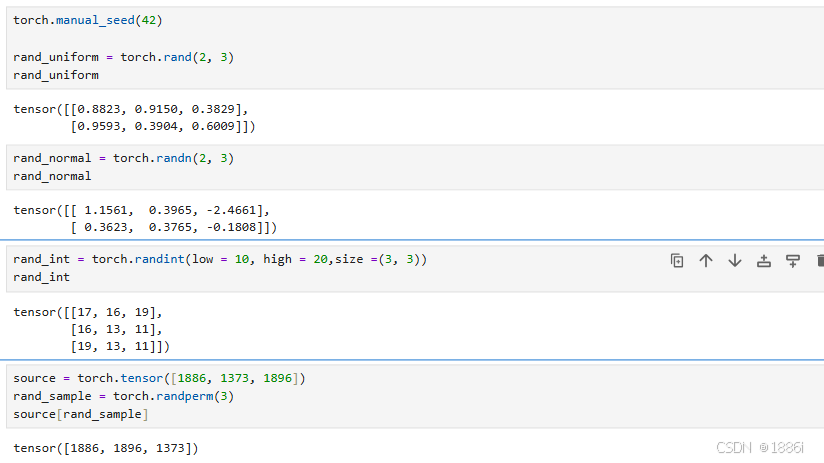
3.张量的属性
x = torch.randn(3, 4)print(x.size()) # 张量的形状,返回torch.Size对象
print(x.shape) # 与size()相同,返回张量的形状
print(x.dtype) # 张量的数据类型
print(x.device) # 张量所在的设备(CPU或GPU)
print(x.layout) # 张量的内存布局
print(x.requires_grad) # 是否需要计算梯度
4.张量的操作
运算
x = torch.tensor([2.0, 1.1, 1.2])
y = torch.tensor([2, 5, 6])
x + y, x - y, x * y, x / y, x ** y
切片
import torch# 创建一个4x5的张量
x = torch.arange(20).view(4, 5)
print("原始张量:")
print(x)# 基本索引
print("\n获取第二行:")
print(x[1]) # 索引从0开始print("\n获取第二行第三列的元素:")
print(x[1, 2])# 切片操作
print("\n获取前两行:")
print(x[:2])print("\n获取所有行的第2到4列:")
print(x[:, 1:4])print("\n获取第1到3行,第2到4列:")
print(x[0:3, 1:4])# 高级索引
print("\n获取特定行:")
print(x[[0, 2, 3]]) # 获取第0、2、3行print("\n使用布尔掩码:")
mask = x % 2 == 0 # 创建布尔掩码
print(mask)
print(x[mask]) # 获取所有偶数元素# 多维张量索引
y = torch.arange(24).view(2, 3, 4)
print("\n3D张量:")
print(y)print("\n获取第一个2D张量的第1行第2列:")
print(y[0, 1, 2])

5.张量与Numpy转换
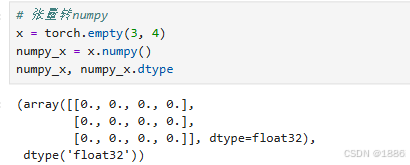
# 张量转numpy
x = torch.empty(3, 4)
numpy_x = x.numpy()
numpy_x, numpy_x.dtype# numpy转张量
numpy_y = np.array([1,2,3,4,5])
y = torch.tensor(numpy_y)
y6.广播机制
x = torch.arange(3).reshape(3, 1)
y = torch.arange(2).reshape(1, 2)
x + y # 广播机制:将x变为3 x 2将y变为3 x 2 对于x直接复制一列对于y直接复制2行 x:[[[0,0],[1,1],[2,2]] y:[[0,1],[0,1],[0,1]]
二、数据预处理csv文件
# 导入操作系统相关的模块,用于文件路径处理和目录创建
import os
# 导入pandas库,并使用别名pd,用于数据处理和分析
import pandas as pd# 创建数据目录:在上级目录中创建名为'data'的文件夹
# os.path.join('..', 'data') 拼接路径,'..'表示上级目录
# exist_ok=True 表示如果目录已存在也不会报错
os.makedirs(os.path.join('..', 'data'), exist_ok=True)# 定义数据文件的路径:上级目录下的data文件夹中的test.csv文件
data_file = os.path.join('..', 'data', "test.csv")# 以写入模式打开文件,准备写入数据
with open(data_file, 'w') as f:# 写入CSV文件的表头:房间数量、小巷类型、价格f.write('NumRooms,Alley,Price\n')# 写入第一行数据:NumRooms为NA(缺失值),Alley为Pave,Price为127500f.write('NA,Pave,127500\n')# 写入第二行数据:NumRooms为2,Alley为NA(缺失值),Price为10600f.write('2,NA,10600\n')# 使用pandas读取刚刚创建的CSV文件
data = pd.read_csv(data_file)# 打印读取到的数据框,展示数据内容
print(data)# 将数据分为输入特征(inputs)和输出标签(outputs)
# inputs取所有行,第0到1列(不包含第2列),即NumRooms和Alley两列
# outputs取所有行,第2列,即Price列
inputs, outputs = data.iloc[:, 0:2], data.iloc[:, 2]# 处理输入特征中的缺失值(NA)
# 使用每列的平均值填充该列的缺失值
# 注意:这里只会对数值型列有效,对字符串类型列(如Alley)的缺失值不会处理
inputs = inputs.fillna(inputs.mean(numeric_only=True))# 显示处理后的输入特征
inputsinputs = pd.get_dummies(inputs, dummy_na=True).astype(int)
inputsx, y = torch.tensor(inputs.values, dtype=torch.float32), torch.tensor(outputs.values)
x, y