具有区域引导参考和基础的大型语言模型,用于生成 CT 报告

现有方法及研究提出
自动生成CT报告——要求对每个解剖区域进行详细分析
从整个图像中提取全局特征——>忽略了CT作为三维成像方式的固有多样性吗,仅使用图像级嵌入来捕捉区域特异性异常对解码器来说是一个巨大挑战——>增强模型处理和整合区域特异性信息的能力,对于生成全面且临床相关的CT报告至关重要。
通用分割模型——零样本分割能力——从CT图像提取解剖掩码——生成关键区域信息——Reg2RG,用于报告生成的区域引导的参考与定位框架
参考和定位:参考侧重于理解图像中指定区域的语义并提供描述;而定位则根据文本信息定位特定区域,实现语言与视觉元素的连接。
计算成本减少:下采样或特征池化——丢失关键的高分辨率纹理细节;局部特征解耦策略——保留局部高分辨率纹理细节和重要几何信息,保持低计算开销。
不同区域的关联性:融合全局和局部特征——全局的信息可能会干扰特定区域的诊断——区域-报告对齐训练策略,增强局部特征与其对应区域报告之间的对齐,减少无关全局信息的影响。
可解释性:注意力图连接报告关键词和图像区域——注意力图缺乏精确性和可靠性;RRA训练策略链接参考区域与报告之间的明确关联,增强可解释性。
研究方法
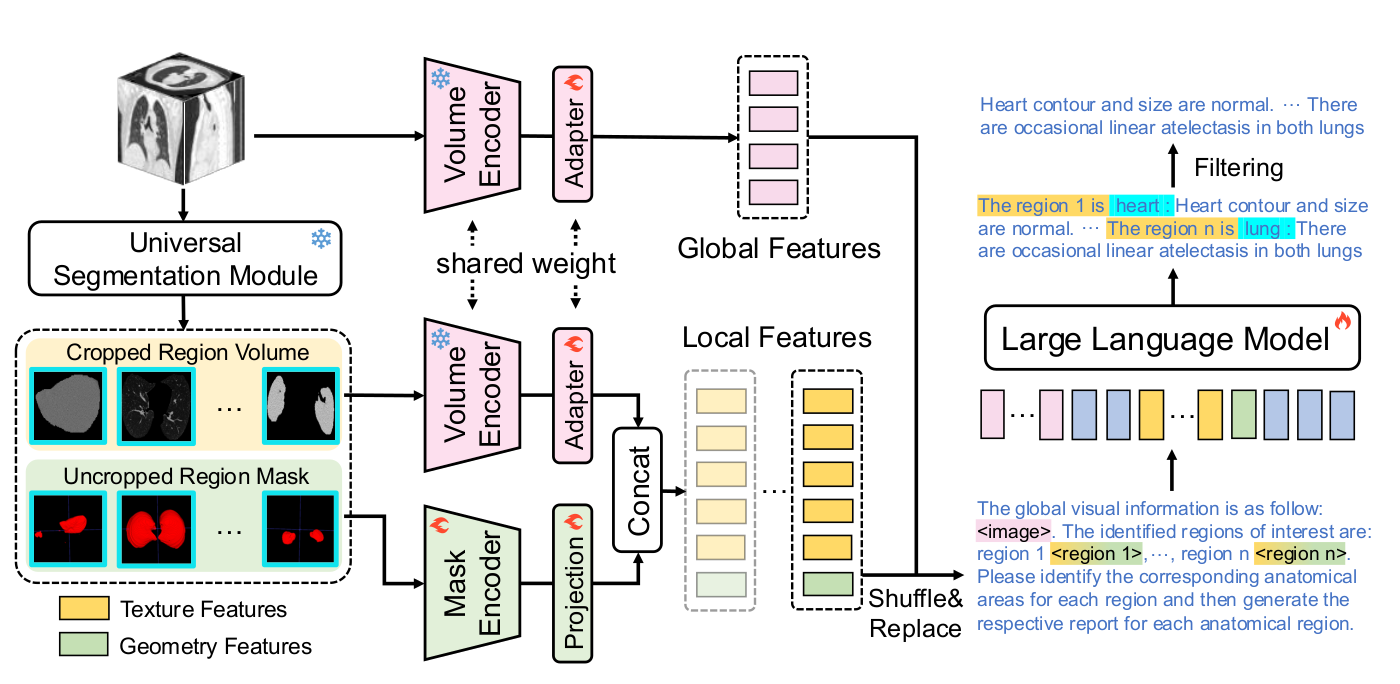
方法概览(Overview)
给定一个CT图像V(H*W*D),生成对应的报告;
额外引入一组局部特征L={L1,L2,...,Ln},通过通用分割模块获取;
将局部特征解耦为纹理和几何两部分;
融合局部和全局特征,输入到LLM生成报告;
提出的RRA训练策略来增强局部特征与对应报告R之间的对齐。
整个过程表示:R=LLM(G,L)=LLM(G,L1,L2,...,Ln)
局部特征解耦策略(Local Feature Decoupling,LFD)
使用一个通用分割模块fs从CT图像中提取解剖区域掩码:
![]()
每个区域掩码用于构建局部特征;
通过解耦策略将特征分为纹理信息和几何信息,其中纹理信息反映区域内组织结构的变化,几何信息包括区域的位置、大小和形状;
纹理特征提取:先用掩码提取区域体积,然后裁剪出有效区域,输入到3D编码中提取纹理特征,再通过适配器对齐到LLM的嵌入空间:
![]()
Crop表示裁剪操作;
fv表示3D编码器;
fa表示适配器。
几何特征提取:掩码保持原始尺寸,输入到一个轻量的掩码编码器中提取几何特征,再通过头隐层对齐:
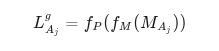
fm表示掩码编码器;
fp表示投影层。
局部特征融合:将纹理特征和纹理特征拼接得到完整的局部特征:
![]()
所有区域的局部特征构成集合:
![]()
全局-局部特征协作(Global-Local Feature Collaboration)
使用与局部特征提取器相同的体积编码器和适配器来提取全局特征
将全局特征和局部特征嵌入到一个提示模板中,输入到LLM中:
![]()
其中I表示视觉嵌入的特殊token,T是文本指令token,在LLM中,这些视觉token被替换为对应特征G和L,共同参与报告生成。
区域-报告对齐训练策略(Region-Report Alignment,RRA)
训练策略:先识别区域的解剖名称,再生成对应的区域报告。
虽然分割模块可以提供区域名称,但直接输入名称可能导致模型依赖于名称而非实际视觉特征,从而降低泛化能力。
因此,我们训练模型从局部特征中自主识别区域名称,而不是直接告诉它“这是肺”。
每个区域报告Ri前添加前缀Pi:“The region [i] is [area name]”;
模型需预测该前缀,从而学习将局部特征与解剖区域对齐;
在每次训练时,打乱局部特征的顺序,防止模型记住固定顺序;
使用标准的语言模型损失进行训练:
![]()
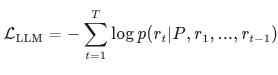 (自回归语言模型损失)
(自回归语言模型损失)
就是说将特征喂给LLM后,输出得到按照区域成对的(Pi,Ri),其中P是前缀:The region [i] is [area name],要求模型把区域i属于哪个解剖部位识别出来,再输出该区域的报告R。
在评估前,去掉前缀,只保留生成的区域报告内容。
评估指标:常规 NLG(BLEU-n、METEOR、ROUGE-L),并引入临床有效性(CE):用 RadBERT 从生成/真值报告中抽取 18 类异常标签,对比精确率、召回率、F1,更贴近临床。CE 只在 RadGenome-ChestCT 上用(与其标签体系匹配)。
通用文本生成指标——衡量生成的报告与参考报告有多像
BLEU-n(常用 n=1,4)
计算 n-gram 的精确率(生成文本里的短语有多少出现在参考里),对各阶 n-gram 做几何平均,并加长度惩罚(防止生成过短)。数字越大,字面重合越高。论文将其作为基础 NLG 指标之一。ROUGE-L
基于**最长公共子序列(LCS)**来衡量两段文本的对齐程度,常见是用 LCS 的 F1。对长句/段更友好,因为不要求连续匹配。论文将其描述为“比较最长公共词序列,关注文本对齐”。METEOR
同时考虑精确率与召回率,并引入词干/同义/释义匹配与碎片化惩罚,因此更能反映语义接近度而非纯字面重合。
NLG 指标看“像不像”,不看“对不对”。例如“The heart is enlarged”和“The heart is not enlarged”在字面上很像,分数可能不低,但医学结论相反。这正是论文强调要引入临床有效性(CE)指标的动机。
临床有效性指标——是否说对了
用 RadBERT 分类器从生成与参考报告中抽取18 类胸部 CT 异常标签,把两组标签做集合对比,计算精准率(Precision)/召回率(Recall)/F1。这样能直接衡量临床要点是否被正确覆盖。