WenetSpeech-Yue数据集及其诞生之路
1. 引言:粤语语音资源–>WenetSpeech-Yue
粤语的语言特性——复杂的九声六调、文白异读、与英语的频繁语码转换(Code-switching)——都对AI模型的建模能力提出了极高的要求。然而,在此之前,公开的粤语语音数据集存在诸多问题:
- 规模小:最大的如Common Voice也仅有数百小时,与主流语言动辄数万小时的语料库相去甚远。
- 风格单一:大多为朗读式语音,缺乏真实对话场景。
- 标注维度少:通常只提供文本转录,缺少说话人信息(年龄、性别)、语音质量、情感等丰富的元数据,限制了其在风格化TTS、说话人识别、自监督学习等高级任务中的应用。
WenetSpeech-Yue的诞生,正是为了解决这一根本性的“资源之渴”。它通过一个自动化、模块化、可扩展的数据处理流水线,构建了一个规模达21,800小时、覆盖10个领域、包含多维度标注的迄今为止最大的开源粤语语音语料库。
2. WenetSpeech-Pipe流水线详解
WenetSpeech-Yue的成功,首先要归功于其背后的“总工程师”——WenetSpeech-Pipe。这是一个集成了六大核心模块的、端到端的数据处理与标注流水线,旨在从“野外”的原始音频中“炼”出高质量的结构化数据。
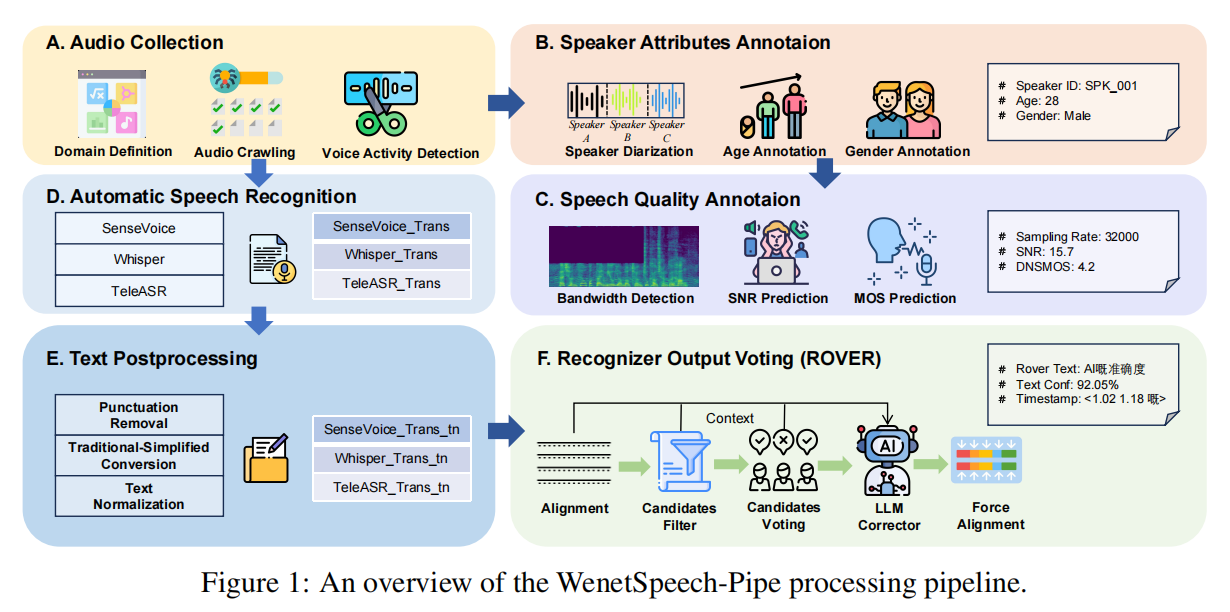
A. 音频收集 (Audio Collection)
- 数据源: 从互联网上广泛爬取覆盖多种领域的粤语长音频,如故事、戏剧、评论、Vlog、美食、娱乐、新闻、教育等。
- 处理:
- 领域定义 (Domain Definition): 首先对数据进行领域分类。
- 音频爬取 (Audio Crawling): 获取原始长音频。
- 语音活动检测 (VAD): 原始音频通常长达数十分钟,不适合直接处理。使用VAD模块将其自动切分成更短的、适合下游处理的语音片段(utterance-level)。
B. 说话人属性标注 (Speaker Attributes Annotation)
- 目标: 为数据添加说话人层面的元数据,以支持多说话人建模和风格控制。
- 处理:
- 说话人日志 (Speaker Diarization): 使用
pyannote工具包,对来自同一源音频的短片段进行聚类,为每个片段分配一个局部的说话人ID,实现录音内的说话人分离。 - 年龄与性别估计: 使用
Vox-
- 说话人日志 (Speaker Diarization): 使用