PySpark EDA 完整案例介绍,附代码(三)
本篇文章Why Most Data Scientists Are Wrong About PySpark EDA — And How to Do It Right适合希望高效处理大数据的从业者。文章的亮点在于强调了使用PySpark进行探索性数据分析(EDA)的重要性,避免了将Spark数据框转换为Pandas的低效做法。几点建议:
- 留在 Spark 中:不要强行将 Pandas 引入大数据工作流。
- 明智地使用采样:Spark 完成繁重的工作,你绘制小样本。
- 分布式思考:将过滤、连接和聚合推送到 Spark 中。
关联Pyspark文章:
- 90% 的机器学习团队仍停留在 2019 年的建模方式: Spark+XGBoost大规模训练
- 在 PySpark ML 中LightGBM比XGBoost更好(二)
- 在 PySpark 中解锁窗口函数的力量,实现高级数据转换
- (早年帖子) PySpark︱DataFrame操作指南:增/删/改/查/合并/统计与数据处理
- (早年帖子) pySpark | pySpark.Dataframe使用的坑 与 经历
- (早年帖子) PySpark︱pyspark.ml 相关模型实践
文章目录
- 1 为什么在 PySpark 中进行 EDA 是不同的(并且更适合大数据)
- 2 步骤 1 — 从免费数据集开始
- 3 步骤 2 — 大规模数据分析
- 3.1 摘要统计
- 3.2 缺失值
- 3.3 唯一值(基数)
- 4 步骤 3 — 分布与可视化
- 4.1 示例:行程距离分布
- 4.2 示例 2:按乘客数量划分的平均票价(条形图)
- 4.3 分类分布
- 5 步骤 4 — 相关性与关系
- 5.1 相关矩阵
- 5.2 示例 3:相关性热力图(距离、票价、小费)
- 5.3 分组洞察
- 6 步骤 5 — 使用 Spark SQL 进行高级 EDA
- 7 常见错误(以及如何避免)
- 8 PySpark EDA 的未来

如果你是一名数据科学家、AI/ML 从业者或数据分析专业人士,你可能经历过这样的噩梦:你获得了海量数据集,渴望对其进行探索,然后……你基于 Pandas 的笔记本就卡死了。
大多数人错误地认为:探索性数据分析 (EDA) 是一种Pandas + Seaborn 的仪式。这种信念如此普遍,以至于整个团队浪费数小时将 Spark DataFrames 转换为 Pandas——结果却遇到了内存错误。
在这篇文章中,我将向你展示如何在 PySpark 中构建一个完整、端到端的 EDA 工作流。无需 Pandas 转换。无需“对所有数据进行降采样”的借口。只有干净、可扩展的技术。
这基于我自己在领导数亿行数据分析项目中的经验,在这些项目中,Pandas 不仅效率低下——它根本不可能使用。
读完本文,你将知道如何:
- 直接在 Spark 中分析海量数据集
- 使用 Spark SQL 和 PySpark 函数进行统计摘要
- 生成可视化而不会耗尽内存
- 为实际项目构建一个可重复、可扩展的 EDA 流水线
1 为什么在 PySpark 中进行 EDA 是不同的(并且更适合大数据)
当你在 Pandas 中打开数据集时,所有数据都会加载到内存中。如果你正在分析一个包含 50 万行数据的 CSV 文件,这没问题。但如果将其扩展到5 亿行,你的笔记本电脑就会直接罢工。
我仍然记得我在金融领域的第一个大型项目:我们有数十亿条交易记录。我天真地以为我“只需使用 Pandas 进行采样”。我的笔记本在不到一分钟内就卡死了。更糟糕的是:即使我设法获得了一个样本,我意识到它不够具代表性——分布具有误导性。
这时 Spark 进入了视野。与 Pandas 不同,Spark 不会在你要求它处理数据之前进行处理。它是惰性的、分布式的,并且旨在处理数 TB 的数据而不会崩溃。
让我们比较一下:
Pandas:
- 在单台机器上运行
- 所有数据都在内存中
- 非常适合中小型数据集
PySpark:
- 分布在多个节点上
- 惰性求值——只在需要时处理
- 专为海量数据集构建
然而,许多教程仍然告诉你:“将你的 Spark DataFrame 转换为 Pandas,然后用 Matplotlib 绘图。”这不仅是糟糕的建议——它很危险。你正在丢弃 Spark 为之构建的可扩展性。
👉 要点:如果你的数据集已经存在于 Spark 中,你的 EDA 也应该留在 Spark 中。
2 步骤 1 — 从免费数据集开始
你不需要公司权限来练习 Spark EDA。有大量免费的真实世界数据集。我最喜欢的是:
- 纽约市出租车行程数据(数亿次乘车):NYC Open Data
- Airbnb 房源数据:Inside Airbnb
- MovieLens(电影评分和元数据):MovieLens
对于本指南,让我们使用 NYC 出租车行程数据集。它足够大,符合实际,并且文档完善。
from pyspark.sql import SparkSessionspark = SparkSession.builder.appName("EDA_PySpark").getOrCreate()df = spark.read.csv("yellow_tripdata_2023-01.csv", header=True, inferSchema=True)
df.printSchema()
df.show(5)
输出:
root|-- VendorID: integer (nullable = true)|-- tpep_pickup_datetime: timestamp (nullable = true)|-- tpep_dropoff_datetime: timestamp (nullable = true)|-- passenger_count: integer (nullable = true)|-- trip_distance: double (nullable = true)|-- fare_amount: double (nullable = true)|-- tip_amount: double (nullable = true)
👉 专业提示:inferSchema=True 对于探索很方便。但在生产环境中,手动定义模式——当 Spark 预先知道列类型时,运行速度会快得多。
3 步骤 2 — 大规模数据分析
EDA 的第一步是分析:了解数据集的形状、完整性和特性。
3.1 摘要统计
df.describe().show()
这会计算数值列的计数、均值、标准差、最小值和最大值——并在集群中分布式执行。
3.2 缺失值
Pandas 用户通常会写 df.isnull().sum()。在 Spark 中,你可以这样复制它:
from pyspark.sql.functions import col, sumdf.select([sum(col(c).isNull().cast("int")).alias(c) for c in df.columns]).show()
这会告诉你每列有多少个空值。
3.3 唯一值(基数)
for c in ["passenger_count", "VendorID"]:print(c, df.select(c).distinct().count())
高基数通常表示类似 ID 的字段(不利于建模)。低基数?是分组的好选择。
👉 提示:.distinct() 可能会很昂贵。如果你只需要一个估计值,请使用 .approx_count_distinct()。
4 步骤 3 — 分布与可视化
这就是有趣的地方。大多数人认为:“你不能直接在 Spark 中进行可视化。”这不正确。
诀窍在于智能采样。Spark 拥有完整的数据集,但你只提取绘图所需的数据。
4.1 示例:行程距离分布
import matplotlib.pyplot as pltsample = df.select("trip_distance").sample(fraction=0.01).toPandas()plt.hist(sample["trip_distance"], bins=50, range=(0,20))
plt.title("Trip Distance Distribution")
plt.xlabel("Distance (miles)")
plt.ylabel("Frequency")
plt.show()
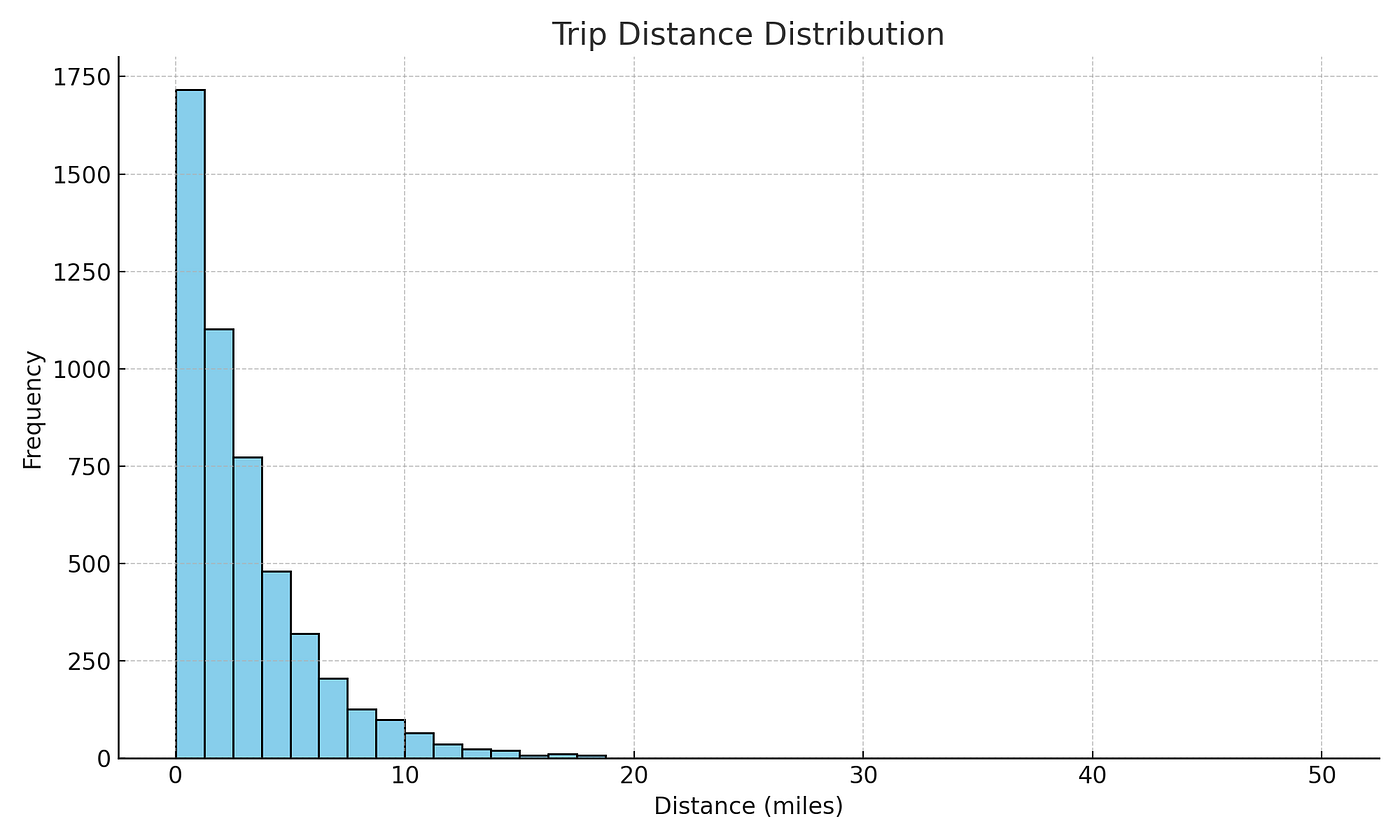
行程距离直方图
你不需要加载所有 1000 万行,只需提取 1%。这足以生成一个具有代表性的直方图。
👉 专业提示:在绘图前始终过滤掉不切实际的异常值。在出租车数据中,200 英里的行程很可能是数据录入错误。
4.2 示例 2:按乘客数量划分的平均票价(条形图)
我们可以使用 Spark 进行聚合,然后绘制结果。
import pandas as pdavg_fares = (df.groupBy("passenger_count").avg("fare_amount").orderBy("passenger_count").toPandas()
)
plt.figure(figsize=(8,6))
plt.bar(avg_fares["passenger_count"], avg_fares["avg(fare_amount)"], color="orange")
plt.title("Average Fare by Passenger Count")
plt.xlabel("Passenger Count")
plt.ylabel("Average Fare ($)")
plt.show()
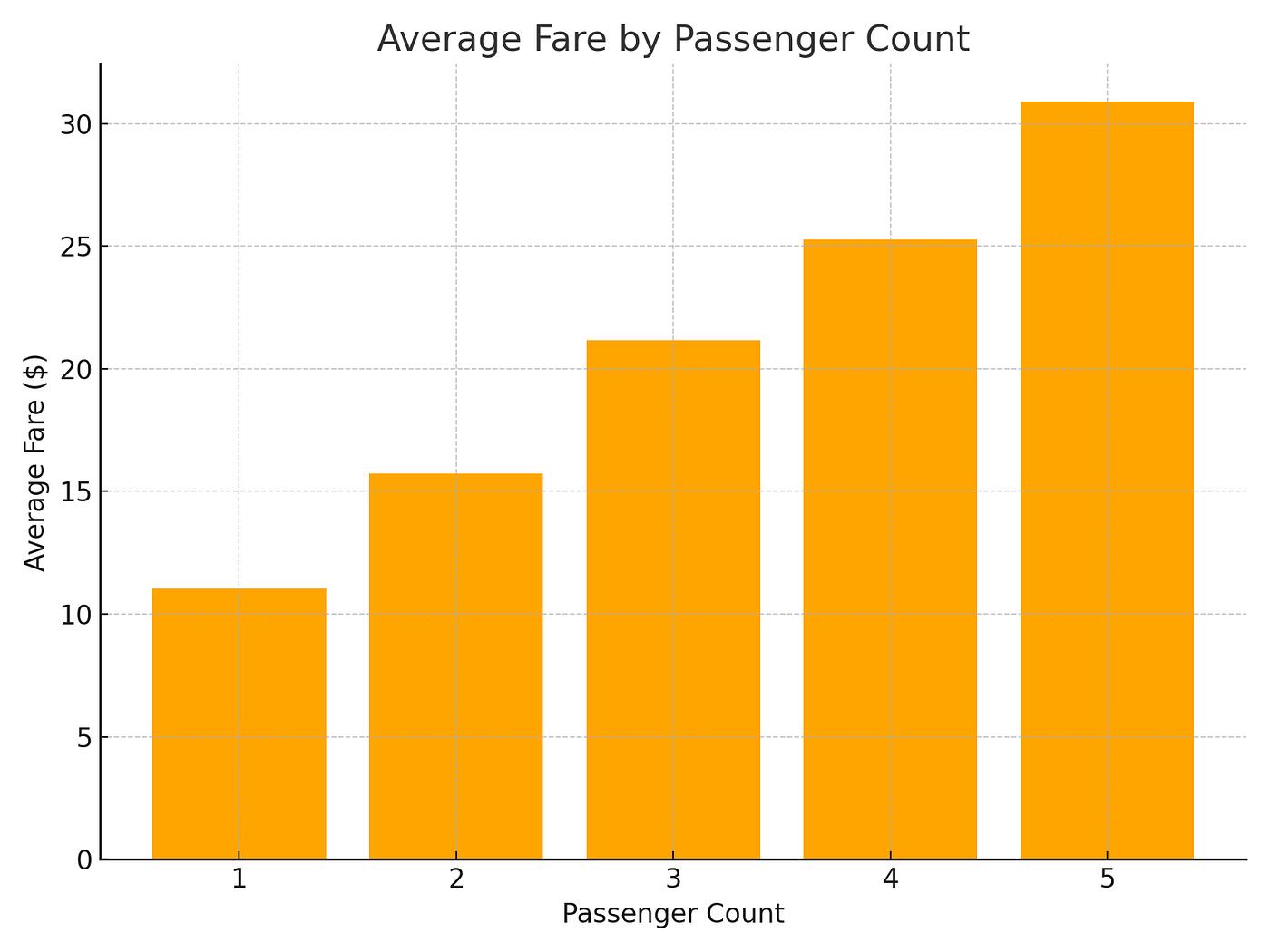
按乘客数量划分的平均票价(条形图)
👉 这显示了更大的团体是否倾向于支付更多费用。在纽约市出租车中,单人乘车占主导地位,但票价确实会随着团体人数的增加而略有上涨。
4.3 分类分布
df.groupBy("passenger_count").count().orderBy("passenger_count").show()
这一行代码就能告诉你有多少次行程有 1、2、3……位乘客。
5 步骤 4 — 相关性与关系
EDA 不仅仅是单变量分析——你还需要了解变量之间的关系。
5.1 相关矩阵
from pyspark.ml.stat import Correlation
from pyspark.ml.feature import VectorAssemblercols = ["trip_distance", "fare_amount", "tip_amount"]
vec = VectorAssembler(inputCols=cols, outputCol="features").transform(df)corr = Correlation.corr(vec, "features").head()[0]
print(corr.toArray())
输出(截断):
[[ 1.0, 0.78, 0.32],[0.78, 1.0, 0.55],[0.32, 0.55, 1.0]]
👉 解释:票价和行程距离强相关(合情合理)。小费金额与两者都有中等相关性。
5.2 示例 3:相关性热力图(距离、票价、小费)
import seaborn as sns
from pyspark.ml.stat import Correlation
from pyspark.ml.feature import VectorAssemblercols = ["trip_distance", "fare_amount", "tip_amount"]
vec = VectorAssembler(inputCols=cols, outputCol="features").transform(df)corr_matrix = Correlation.corr(vec, "features").head()[0].toArray()import pandas as pd
corr_df = pd.DataFrame(corr_matrix, index=cols, columns=cols)plt.figure(figsize=(8,6))
sns.heatmap(corr_df, annot=True, cmap="coolwarm", fmt=".2f")
plt.title("Correlation Heatmap")
plt.show()
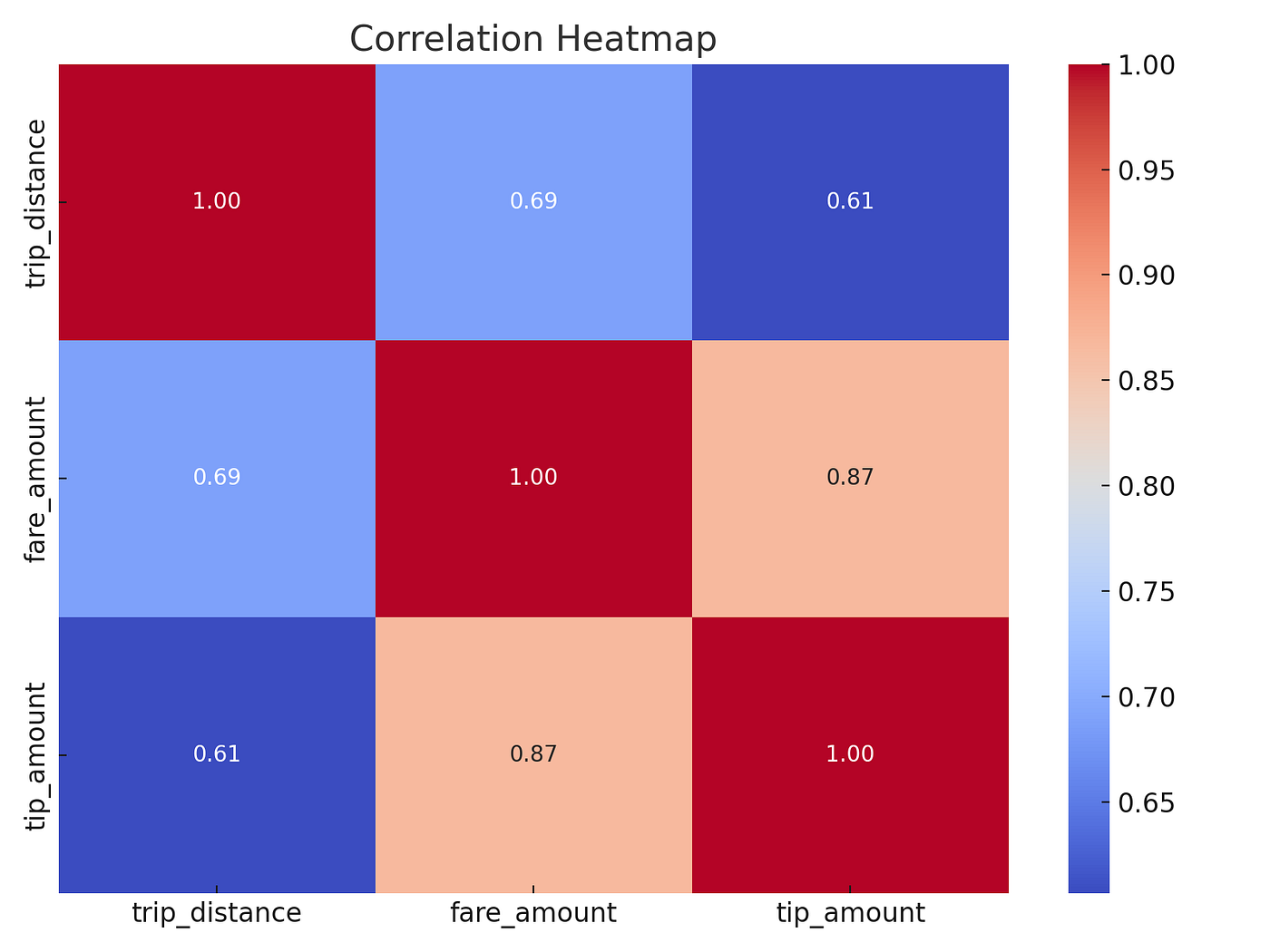
相关性热力图
👉 现在你得到了一个漂亮的相关性热力图,显示行程距离和票价强相关,而小费金额与它们的关系较弱但呈正相关。
5.3 分组洞察
df.groupBy("passenger_count").avg("fare_amount", "tip_amount").show()
这能快速显示小费如何随团体人数变化。
6 步骤 5 — 使用 Spark SQL 进行高级 EDA
有时,SQL 是最快的思考方式。Spark 允许你无缝切换。
df.createOrReplaceTempView("trips")spark.sql("""
SELECT passenger_count,AVG(fare_amount) AS avg_fare,AVG(tip_amount) AS avg_tip
FROM trips
WHERE trip_distance BETWEEN 1 AND 20
GROUP BY passenger_count
ORDER BY passenger_count
""").show()
该查询:
- 过滤掉极端异常值
- 按乘客数量分组
- 给出平均票价和小费
结果:清晰、可解释的 EDA 洞察。
7 常见错误(以及如何避免)
-
将整个 DataFrames 转换为 Pandas
- 💥 内存立即崩溃。
- ✅ 解决方案:使用
.sample()或.limit()进行采样。
-
忘记 Spark 是惰性的
- “为什么我的代码没有运行?”因为 Spark 等待一个_动作_。
- ✅ 解决方案:使用
.show()、.count()或.collect()来触发执行。
-
使用大型
.collect()使本地机器过载- ✅ 在将结果带到本地内存之前,始终在 Spark 中进行聚合。
-
不智能地进行缓存
- 如果你反复重用同一个子集,请对其进行
.cache()以避免重复计算。
- 如果你反复重用同一个子集,请对其进行
👉 经验法则:将 Spark 视为你的计算引擎,而不仅仅是数据容器。
8 PySpark EDA 的未来
我们正处于一个激动人心的转折点。
- Spark 上的 Pandas API (Koalas):为 Spark DataFrames 带来了类似 Pandas 的语法。
- 自动化 EDA 工具,如 ydata-profiling,正在适应 Spark。
- 可视化库(Plotly、Altair)正在构建直接的 Spark 连接器。
- LLMs + Spark:想象一下,输入“显示一月份行程中的异常”,然后立即获得 SQL 和图表。这已经不远了。
👉 EDA 的未来是可扩展、自动化和对话式的。