分布式专题——8 京东热点缓存探测系统JDhotkey架构剖析
1 多级缓存
-
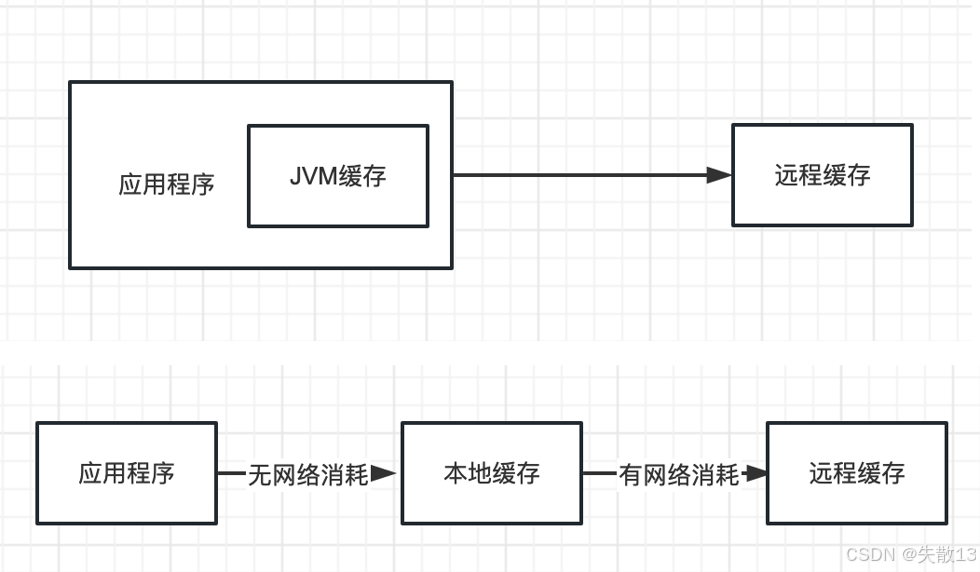
多级缓存架构示意图:应用程序先从自身的 JVM 缓存获取数据(无网络消耗),若未命中再去远程缓存(比如 Redis,有网络消耗)。
-
本地缓存的优点
-
减少网络请求,提高性能:本地缓存把数据存在应用程序所在的本地,应用程序读取数据时,无需通过网络去远程缓存或数据库获取,能大幅降低网络往返时间,提升数据访问速度,进而提高整体系统性能;
-
分布式系统中,天然分布式缓存:在分布式系统里,每个应用服务节点都有自己的本地缓存,这些本地缓存自然地构成了分布式的缓存架构,不同节点可利用自身本地缓存处理请求,分担负载;
-
减少远程缓存的读压力:很多请求可以直接从本地缓存命中并获取数据,不用去远程缓存读取,这样就减少了远程缓存被访问的次数,降低了远程缓存的负担;
-
-
本地缓存的缺点
-
进程空间大小有限,不支持大数据量存储:本地缓存依赖应用程序的进程内存,而进程内存空间是有限的,无法存储大量的数据,当需要缓存的数据量较大时,本地缓存就难以满足需求;
-
重启程序会丢失数据:本地缓存的数据是存储在内存中的,应用程序重启时,内存中的数据会被清除,导致缓存数据丢失,之后若要获取数据,可能需要重新从远程缓存或数据库加载;
-
分布式场景下,系统之间数据可能存在不一致:分布式系统中,不同节点的本地缓存是各自维护的,当数据发生变更时,若没有及时、统一的同步机制,不同节点的本地缓存数据可能会不一样,从而出现数据不一致的情况;
-
和远程缓存数据可能会存在不一致:本地缓存和远程缓存之间,数据更新可能存在延迟。比如远程缓存的数据更新了,但本地缓存还没同步,就会导致两者数据不一致,影响数据的准确性
-
-
需要用到多级缓存的场景:
- 热点商品详情页
- 热搜
- 热门帖子
- 热门用户主页
-
一般在高并发的情况下需要用到多级缓存。因为高并发场景下,对数据的访问请求量极大,单级缓存可能无法很好地应对,要么性能不足,要么缓存容量等方面受限,而多级缓存通过不同层级缓存的配合,能更高效地处理大量请求,提升系统的响应速度和稳定性。
2 热点探测服务
2.1 什么是热点?
-
从通常意义上讲,热点是指在一段时间内被广泛关注的物品或事件,比如微博热搜、热卖商品、热点新闻、明星直播等;
-
热点产生的两个主要条件:
-
有限时间:热点的关注度集中在某一特定的、较短的时间段内;
-
流量高聚:在这段时间里,有大量的关注流量聚集到该物品或事件上;

-
-
在互联网领域,热点主要分为两大类:
-
有预期的热点:是可以提前预知会成为热点的情况,像电商活动中推出的爆款联名限量款商品,或者秒杀会场活动等,这类热点是经过策划或有明显迹象会引发大量关注的;
-
无预期的热点:是突然出现、难以提前预料的热点,例如受到黑客恶意攻击、网络爬虫频繁访问,或者突发新闻带来的流量冲击等情况,这些情况会突然导致大量流量集中。
-
2.2 热点探测使用场景
- MySQL 中被频繁访问的数据:像热门商品的主键Id,这类数据在数据库中会被大量查询,通过热点探测能及时发现,以便采取如缓存等措施,减轻数据库压力;
- Redis 缓存中被密集访问的 Key:例如获取热门商品详情时用到的
get goods$Id这样的 Key,密集访问会给 Redis 带来压力,热点探测可识别这类 Key,优化缓存使用; - 恶意攻击或机器人爬虫的请求信息:比如特定标识的 userId、机器IP,热点探测能发现这类异常且高频的请求,助力系统识别并防范攻击或爬虫行为;
- 频繁被访问的接口地址:像获取用户信息的
/userInfo/ + userId接口,大量访问会对接口服务造成压力,热点探测可找出这类接口,进行性能优化等操作。
2.3 使用热点探测的好处
-
提升性能,规避风险:无预期的热数据(突发场景形成的热Key)可能给业务系统带来极大风险;
-
风险分为两个层次:
-
对数据层的风险:
- 正常情况下,Redis 缓存单机可支持约十万左右的 QPS,集群部署还能提高整体负载能力,对于并发量一般的系统足够了;
- 但面对瞬时过高的并发请求,由于 Redis 的单线程特性,会导致正常请求排队;或者因热点集中,分片集群压力过载瘫痪,进而击穿到数据库,引发服务器雪崩,即数据库因承受不住大量请求而崩溃,进而出现连锁反应导致整个服务不可用;
-
对应用服务的风险:每个应用单位时间能处理的请求量有限。若遭受恶意请求攻击,恶意用户占用大量请求处理资源,会使正常用户的请求无法及时响应;
-
-
应对措施:因此,需要一套动态热 Key 检测机制。通过配置热 Key 检测规则,实时监听统计热 Key 数据。当无预期的热点数据出现时,能第一时间发现,并对这些数据进行特殊处理,比如采用本地缓存、拒绝恶意用户请求、对接口进行限流或降级等,以此提升系统性能,规避上述风险。
2.4 如何实现热点探测?
- 热点产生有两个条件:时间和流量。基于此,可以定义规则,比如1秒内访问1000次的数据算作热数据。不过,具体的数值需要根据实际业务场景以及过往的数据情况来评估确定,不同业务可能有不同的阈值要求;
2.4.1 单机场景
-
对于单机应用,检测热数据比较简单。直接在本地为每个 Key 创建一个滑动窗口计数器,用来统计单位时间内该 Key 的访问总数(也就是访问频率),然后把检测到的热 Key 存放在一个集合里;
- 下图的时间轴上划分了多个时间片段(比如图中的200ms为一个片段),每个片段内有对应的访问次数;
- 当观察1秒的时间窗口(包含多个200ms片段)时,若这段时间内的访问次数总和达到设定的阈值(图中是1000),就说明对应的Key是热数据;
- 通过这种滑动窗口的方式,能动态统计单位时间内 Key 的访问量,从而判断是否为热点;

package com.jd.platform.sample.controller;import com.google.common.cache.Cache; import com.google.common.cache.CacheBuilder;import java.util.HashMap; import java.util.LinkedList; import java.util.Map; import java.util.Queue; import java.util.Random; import java.util.concurrent.TimeUnit;/*** 热点数据检测器* 使用滑动窗口算法检测在特定时间窗口内访问频率达到阈值的数据*/ public class HotSpotDetector {private final int WINDOW_SIZE = 10; // 滑动窗口大小,单位为秒,表示统计10秒内的访问频率private final int THRESHOLD = 5; // 阈值,在窗口时间内达到5次访问即视为热点数据private final Cache<String, Object> hotCache = CacheBuilder.newBuilder().expireAfterWrite(5, TimeUnit.SECONDS) // 热点数据缓存,5秒后自动过期.maximumSize(1000).build(); // 最大缓存1000个热点数据private Map<String, Queue<Long>> window = new HashMap<>(); // 存储每个数据key的时间戳队列,用于滑动窗口统计private Map<String, Integer> counts = new HashMap<>(); // 存储每个数据key在当前窗口内的访问计数/*** 判断指定数据是否为热点数据* @param data 要检测的数据key* @return true-是热点数据,false-不是热点数据*/public boolean isHot(String data) {// 如果热点缓存中已存在该数据,直接返回true(热点数据已确认)if (hotCache.getIfPresent(data) != null) {return true;}// 获取当前数据在滑动窗口内的访问次数int count = counts.getOrDefault(data, 0);// 如果访问次数达到阈值,确认为热点数据if (count >= THRESHOLD) {hotCache.put(data, 1); // 将热点数据加入缓存,值为1仅作标记,实际可存储业务数据clear(data); // 清空该数据的统计信息,避免重复触发return true;} else {// 未达到阈值,更新统计信息counts.put(data, count + 1); // 访问计数+1// 获取或创建该数据的时间戳队列Queue<Long> queue = window.get(data);if (queue == null) {queue = new LinkedList<Long>();window.put(data, queue);}// 获取当前时间(秒级时间戳)long currTime = System.currentTimeMillis() / 1000;queue.add(currTime); // 将当前时间加入队列// 清理超出滑动窗口范围的时间戳,并相应减少计数while (!queue.isEmpty() && currTime - queue.peek() > WINDOW_SIZE) {queue.poll(); // 移除超出窗口的旧时间戳counts.put(data, counts.get(data) - 1); // 计数减1}return false;}}/*** 清空指定数据的统计信息* @param data 要清空的数据key*/private void clear(String data) {window.remove(data);counts.remove(data);}/*** 添加数据到热点缓存* @param key 数据key* @param value 数据值(实际业务数据)*/public void set(String key, Object value) {hotCache.put(key, value);}/*** 从热点缓存获取数据* @param key 数据key* @return 缓存的数据值,不存在返回null*/public Object get(String key) {return hotCache.getIfPresent(key);}/*** 测试方法*/public static void main(String[] args) throws InterruptedException {HotSpotDetector detector = new HotSpotDetector();// 模拟连续访问数据"C"5次,触发热点检测detector.isHot("C");detector.isHot("C");detector.isHot("C");detector.isHot("C");detector.isHot("C");// 第6次检测时应被识别为热点boolean isHotspot = detector.isHot("C");if (isHotspot) {System.out.println("----Hotspot Detected: C");} else {System.out.println("----not Hotspot Detected: C");}} }
2.4.2 分布式场景
-
在分布式应用中,热Key的访问分散在不同机器上,无法在本地独立计算,所以需要一个独立、集中的热 Key 计算单元。实现过程可简单分为五个步骤:
- 热点规则:配置热 Key 的上报规则,明确需要重点监测的 Key,确定哪些 Key 是探测的目标;
- 热点上报:应用服务将自身的热 Key 访问情况上报给集中计算单元,让集中单元能收集到各节点的热 Key 相关数据;
- 热点统计:收集各应用实例上报的信息,使用滑动窗口算法来计算 Key 的热度,以此判断 Key 的热门程度;
- 热点推送:当 Key 的热度达到设定值时,把热 Key 信息推送给所有应用实例,让各实例知晓哪些是热 Key;
- 热点缓存:各应用实例收到热 Key 信息后,对该 Key 值进行本地缓存,这样后续访问该热 Key 时,可直接从本地缓存获取,提升访问性能,减轻分布式系统中集中存储或计算的压力。
2.4.3 JDHotkey
-
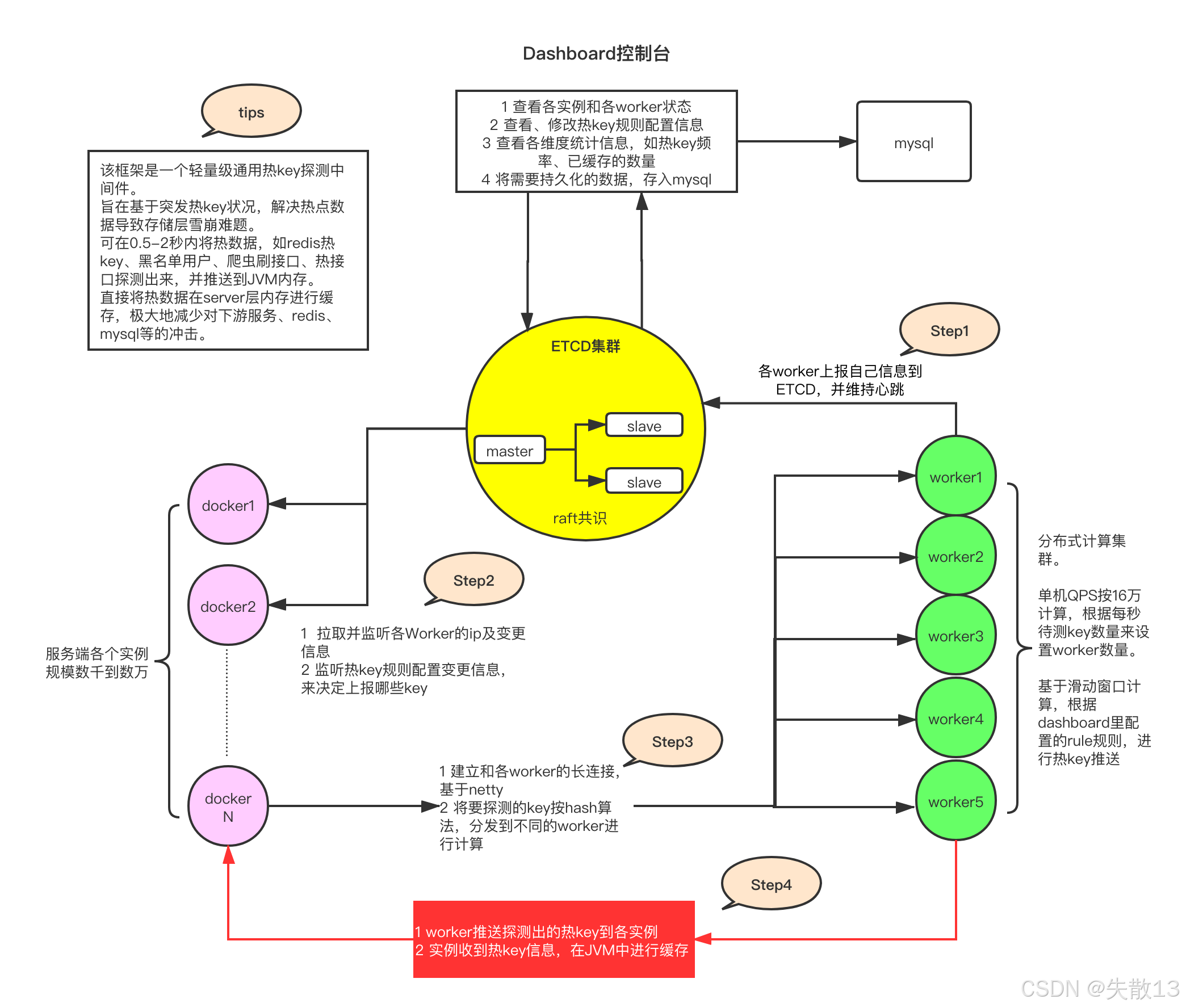
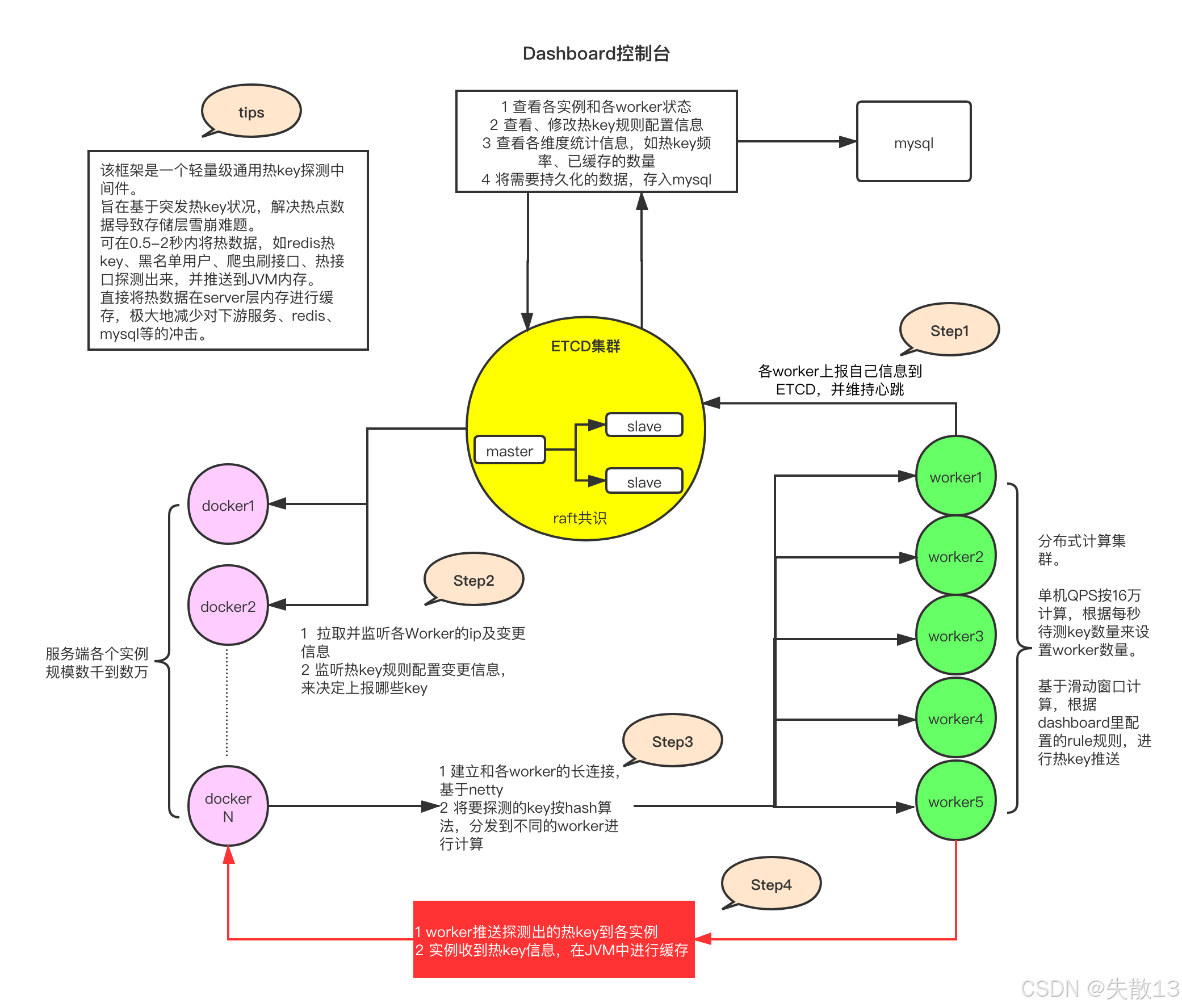
下图就是热 Key 探测中间件JDHotkey的整体架构与工作流程;
-
核心组件与角色:
- Dashboard 控制台:作为管理端,可查看 worker 状态、配置热 Key 规则、统计热 Key 数据,并将需要持久化的数据存入 MySQL;
- ETCD 集群:分布式协调服务(基于 Raft 共识算法),用于服务发现、配置同步和心跳维持,确保各节点状态一致;
- Worker 集群:分布式计算节点,负责实际的热 Key 计算(基于滑动窗口算法),单节点 QPS 可达 16 万,可根据需求横向扩展;
- Docker 实例(服务端):业务服务的容器化部署单元,数量可从数千到数万,负责接收热 Key 并在 JVM 中缓存;
-
工作流程:
-
Step1:各 Worker 节点向 ETCD 上报自身信息,并通过心跳机制维持与 ETCD 的连接,确保 ETCD 能感知 Worker 的存活状态;
-
Step2:Docker 实例从 ETCD 拉取并监听各 Worker 的 IP 及变更信息和热 Key 规则的配置变更(如哪些 Key 需要探测),通过这些信息,服务端能动态决定需要探测的 Key 范围;
-
Step3:服务端(基于 Netty 建立与 Worker 的长连接)将需要探测的 Key,通过哈希算法分发到不同的 Worker 节点,由 Worker 进行滑动窗口计算(统计单位时间内 Key 的访问频率);
-
Step4:Worker 将探测出的热 Key 推送给所有 Docker 实例,实例收到热 Key 后,在 JVM 中进行缓存,后续访问该 Key 时可直接从本地获取,避免请求穿透到下游的 Redis 或 MySQL;
-
-
更详细的内容,可见京东技术团队的京东毫秒级热key探测框架设计与实践,已实战于618大促;
-
下面看一下商品服务在“读操作”和“写操作”时,与热点探测服务、缓存及数据库的交互流程:
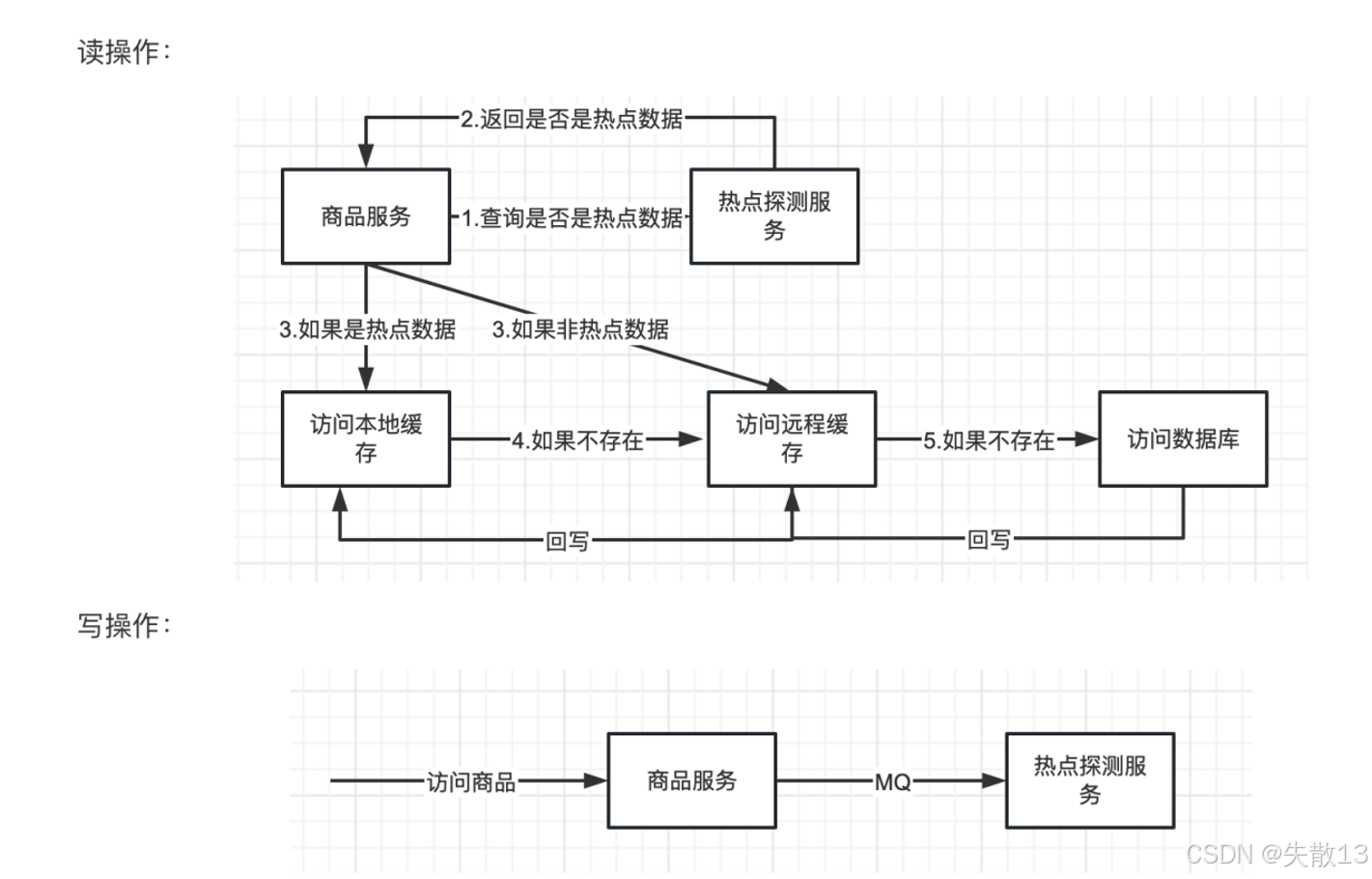
- 读操作流程。商品服务读取数据时,先判断是否为“热点数据”,再选择不同的缓存 / 数据库访问路径:
- 商品服务向热点探测服务查询“当前数据是否是热点数据”;
- 热点探测服务返回判断结果(是 / 否热点);
- 是热点数据
- 直接访问本地缓存;
- 若本地缓存不存在,则访问远程缓存;若远程缓存也不存在,最终访问数据库,并将数据回写到远程缓存和本地缓存;
- 非热点数据
- 直接访问远程缓存(热点数据才需要更高效的本地缓存,非热点用远程缓存即可);
- 若远程缓存不存在,最终访问数据库,并将数据回写到远程缓存;
- 写操作流程。商品服务写入数据时,通过消息队列(MQ)异步通知热点探测服务:
- 商品服务处理“访问商品”的写请求后,不直接同步通知热点探测服务,而是通过 MQ 异步发送消息;
- 热点探测服务接收 MQ 消息后,更新自身的“热点数据识别规则”;
- 这种“异步通知”的设计,能避免写操作被热点探测的同步逻辑阻塞,保证写操作的性能。
- 读操作流程。商品服务读取数据时,先判断是否为“热点数据”,再选择不同的缓存 / 数据库访问路径:
3 JDHotkey 快速实战
3.1 安装 Etcd
-
直接从Releases · etcd-io/etcd上下载最新版本的 Etcd 即可,选择对应的操作系统版本;
- 此处选择
etcd-v3.5.15;
- 此处选择
-
下载后在一个无英文目录下解压,会得到3个
.exe文件:- etcd:etcd 服务本身;
- etcdctl:客户端,用于操作 etcd,比如读写数据;
- etcdutl:备份恢复工具;
-
双击
etcd.exe启动 etcd 脚本后,可以启动 etcd 服务,服务默认占用 2379 和 2380 端口,作用分别如下:- 2379:提供 HTTP API 服务,和 etcdctl 交互;
- 2380:集群中节点间通讯。
3.2 安装 hotkey worker
-
从hotkey: 京东App后台中间件,毫秒级探测热点数据,毫秒级推送至服务器集群内存,大幅降低热key对数据层查询压力下载源码;
-
项目导入 IDEA 后,打开 worker 模块,直接启动即可;
- worker 是一个 SpringBoot项目,如有需要的话可以先修改
applicaiton.yml中的配置,比如端口配置;
如果因为报类不存在的错误导致启动不了,可以将下面这个类里面的代码全部删除:
- worker 是一个 SpringBoot项目,如有需要的话可以先修改
3.3 启动 hotkey 控制台
-
接着打开 dashboard 项目,执行
resource目录下的db.sql文件,创建 dashboard 所需的库表。hotkey 依赖 MySQL来存储用户账号信息、热点阈值规则等;
-
在执行脚本前,记得先配置好 MySQL 连接,并且在 SOL 脚本文件中创建和指定数据库,在
db.sql文件的最上面加上下面两行代码:create database hotkey_db; use hotkey_db; -
在
db.sql中可以看到内置了 admin 账号,密码为 123456;
-
修改
applicaiton.yml中的配置:spring :datasource:username: ${MYSQL_USER:root}password: ${MYSQL_PASS:1234} -
dashboard 也是一个 SpringBoot 项目,直接在 IDEA 内执行 DashboardApplication 启动即可:
-
成功启动后,访问
http://127.0.0.1:8081,即可看到:
-
输入管理员的账号密码(admin,123456)后,即可登录成功:
-
初次使用时需要先添加 APP。建议先在用户管理菜单中,添加一个新用户,设置昵称为 APP 名称、并填写所属 APP,如
demo,密码此处就设置为 123456。之后就可以登录这个新建的用户来给应用设置规则了(当然也可以使用admin账户来设置),而且系统会自动创建一个 APP;
-
随后,在规则配置中,选择对应的 APP,新增对应的热点探测规则:
-
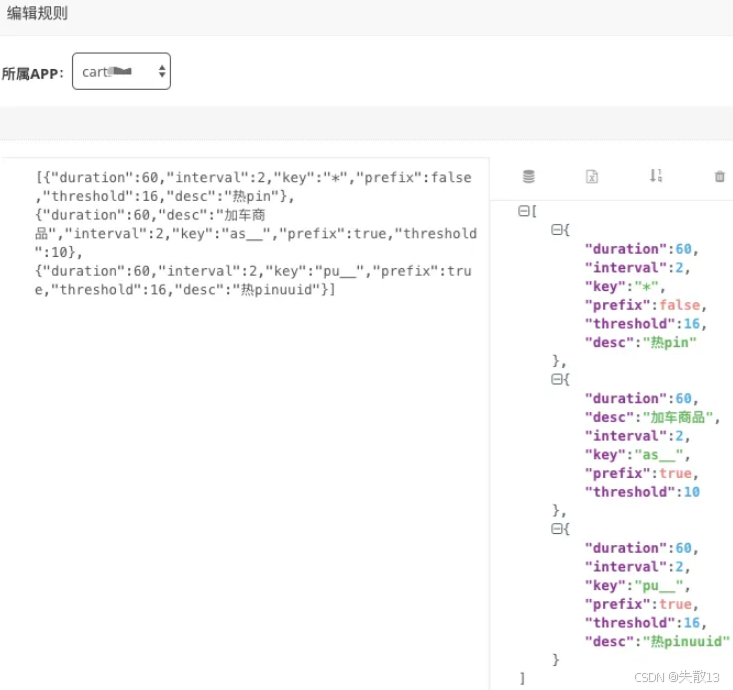
比如下面就是一组规则:
-
解析一下其中的第二条规则:
- 如果以
as_开头的 key 在interval(此处是 2)秒内出现了threshold(此处是 10)次就认为它是热 key,它就会被推送到JVM内存中,并缓存duration(此处是 60)秒;- 如果
"key": "*"(比如第一条规则),则表示匹配所有的key;
- 如果
“prefix”: true代表前缀匹配;- 那么在应用中,就可以把一组 key,都用 as 开头,用来探测。
- 如果以
3.4 JdHotKeyStore的方法
-
只要使用
JdHotKeyStore这个类即可非常方便地判断 key 是否成为热点和获取热点 kev 对应的本地缓存; -
这个类主要有如下4个方法可供使用:
boolean JdHotKeyStore.isHotKey(String key) Object JdHotKeyStore.get(String key) void JdHotKeyStore.smartSet(String key, Object value) Object JdHotKeyStore.getValue(String key)boolean isHotKey(String key)- 该方法会返回该 key 是否是热 key,如果是则返回 true,如果不是则返回 false,并且会将 key 上报到探测集群进行数量计算;
- 该方法通常用于判断“只需要判断 key 是否热、不需要缓存 value ”的场景,如刷子用户、接口访问频率等;
Object get(String key):该方法返回该 key 本地缓存的 value 值,可用于判断是热 key 后,再去获取本地缓存的 value 值,通常用于 redis 热 key 缓存;void smartSet(String key, Object value):该方法给热 key 赋值 value,如果是热 key,该方法才会赋值,若非热 key,什么也不做;Object getValue(String key)- 该方法是一个整合方法,相当于
isHotKey和get两个方法的整合,该方法直接返回本地缓存的 value; - 如果是热 key,则存在两种情况,返回 null 和非 null;
- 返回 null 是因为尚未给它 set 真正的 value,返回非 null 说明已经调用过 set 方法了,本地缓存 value 有值了;
- 如果不是热 key,则返回 null,并且将 key 上报到探测集群进行数量探测;
- 该方法是一个整合方法,相当于
-
官方推荐的最佳实践:
-
判断用户是否是刷子:
if (JdHotKeyStore.isHotKey(“pin__” + thePin)) {// 进行限流 } -
判断商品 id 是否是热点:
Object skuInfo = JdHotKeyStore.getValue("skuId__" + skuId); if(skuInfo == null) {JdHotKeyStore.smartSet("skuId__" + skuId, theSkuInfo); } else {// 使用缓存好的 value 即可 } -
推荐写法:
if (JdHotKeyStore.isHotKey(key)) {//注意是get,不是getValue。getValue会获取并上报,get是纯粹的本地获取Object skuInfo = JdHotKeyStore.get("skuId__" + skuId);if(skuInfo == null) {JdHotKeyStore.smartSet("skuId__" + skuId, theSkuInfo);} else {//使用缓存好的value即可} }
-
3.5 配置 hotkey 规则
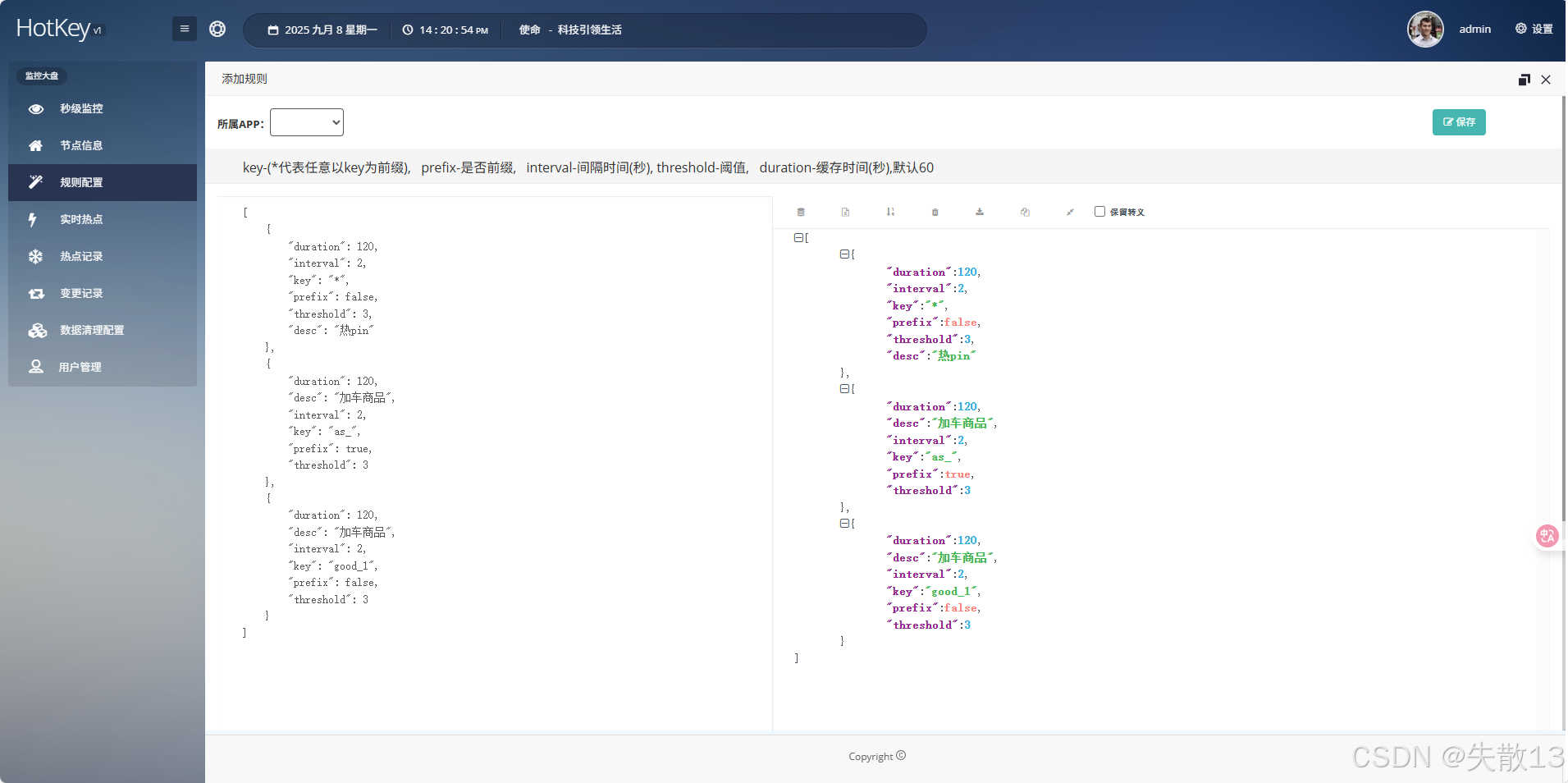
[{"duration": 120,"interval": 2,"key": "*","prefix": false,"threshold": 3,"desc": "热pin"},{"duration": 120,"desc": "加车商品","interval": 2,"key": "as_","prefix": true,"threshold": 3},{"duration": 120,"desc": "加车商品","interval": 2,"key": "good_1","prefix": false,"threshold": 3}
]
- 第一条规则
- 匹配所有键(
key: "*",prefix: false表示精确匹配通配符*,实际可理解为匹配任意键); - 每 2 秒(
interval: 2)统计一次,若任意键在 2 秒内被访问至少 3 次(threshold: 3),则判定为热点键,热点数据缓存 120 秒(duration: 120),用于 “热 pin” 相关业务场景;
- 匹配所有键(
- 第二条规则
- 匹配所有以
as_为前缀的键(key: "as_",prefix: true); - 每 2 秒统计一次,若以
as_为前缀的键在 2 秒内被访问至少 3 次,判定为热点键,缓存 120 秒,用于 “加车商品” 相关业务场景;
- 匹配所有以
- 第三条规则
- 精确匹配键
good_1(key: "good_1",prefix: false); - 每 2 秒统计一次,若键
good_1在 2 秒内被访问至少 3 次,判定为热点键,缓存 120 秒,用于 “加车商品” 相关业务场景。
- 精确匹配键
3.6 demo案例
-
写一个 demo:
package com.jd.platform.hotkey.demo.controller;import com.jd.platform.hotkey.client.ClientStarter; import com.jd.platform.hotkey.client.callback.JdHotKeyStore; import org.springframework.web.bind.annotation.PathVariable; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RestController;import javax.annotation.PostConstruct;/*** 热点数据检测控制器示例* 使用JD热点key检测框架实现热点数据的识别和处理*/ @RestController @RequestMapping("/index") public class IndexController {/*** 初始化热点key检测客户端* 在Spring容器初始化完成后自动执行*/@PostConstructpublic void initHotkey() {// 使用建造者模式创建客户端配置ClientStarter.Builder builder = new ClientStarter.Builder();// 注意:setAppName很重要,它和dashboard中的规则配置相关联ClientStarter starter = builder.setAppName("demo") // 设置应用名称,用于规则匹配(见4.15对于ClientStarter的详解).setEtcdServer("http://127.0.0.1:2379") // 设置etcd服务器地址,用于配置中心.setCaffeineSize(10) // 设置本地缓存大小(Caffeine缓存).build();starter.startPipeline(); // 启动热点key检测管道}/*** 获取商品信息接口* 演示热点key检测在商品查询场景的应用* @param key 商品ID* @return 商品信息*/@RequestMapping("/get/{key}")public Object get(@PathVariable String key) {// 构造缓存key,格式为"skuId__{商品ID}"String cacheKey = "skuId__" + key;// 检测该key是否为热点keyif (JdHotKeyStore.isHotKey(cacheKey)) {System.out.println("hotkey:" + cacheKey);// 注意:get()方法是纯粹的本地获取,不会上报;getValue()会获取并上报Object skuInfo = JdHotKeyStore.get(cacheKey);if (skuInfo == null) {// 如果热点缓存中没有数据,从数据源获取并设置到缓存Object theSkuInfo = "123" + "[" + key + "]" + key; // 模拟从数据库获取数据JdHotKeyStore.smartSet(cacheKey, theSkuInfo); // 智能设置到热点缓存return theSkuInfo;} else {// 使用缓存好的value直接返回return skuInfo;}// 支持的热点key示例:["skuId__1","skuId__2","skuId__3"]} else {// 非热点key,正常处理业务逻辑System.out.println("not hot:" + cacheKey);return "123" + "[" + key + "]" + key; // 模拟从redis或mysql获取数据}}/*** 获取商品详情接口* 演示热点key检测在接口限流场景的应用* @return 商品详情或限流提示*/@RequestMapping("/get/info")public Object getGoodsInfo() {// 示例URL:127.0.0.1/get/info/1// 构造缓存key,这里使用固定值"as_1"作为示例String cacheKey = "as_" + 1;// 检测是否为热点key(用于接口限流)if (JdHotKeyStore.isHotKey(cacheKey)) {System.out.println("hot:" + cacheKey);return "访问次数太多请稍后再试!"; // 热点key触发限流} else {System.out.println("not hot:" + cacheKey);return "ok"; // 正常返回业务数据}} } -
启动后,访问
localhost:8099/index/get/1:
-
可以多访问几次,当访问的频率超过 2 秒 3 次,就会被设置为 hotkey:
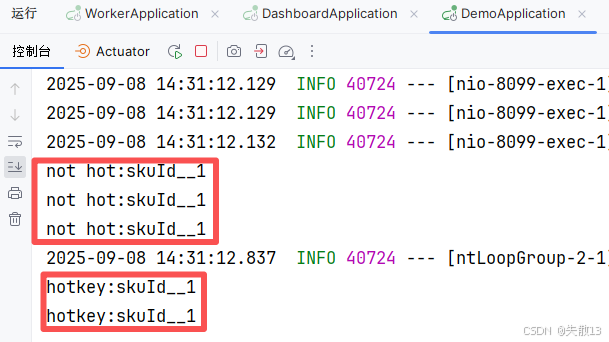
4 JDHotkey 原理与架构剖析
- 参考:京东毫秒级热key探测框架设计与实践,已实战于618大促。
4.1 热 key 的产生及危害
- 热 key 源于突发且难以预先感知的高并发访问,典型场景包括:
- 突发爆款商品(如某款商品突然走红,引发大量查询);
- 海量用户涌入某一店铺(如明星店铺、活动店铺的集中访问);
- 秒杀等场景中瞬间出现的爬虫请求(机器人高频访问抢占资源);
- 热 key 的危害主要体现在数据层和服务层,本质是超出系统承载能力的瞬时高并发对系统的冲击:
- 对数据层的冲击:
- 以 Redis 为例,热 key 会因哈希规则集中在某一 Redis 分片上。尽管 Redis 集群日常能支撑 20 万 QPS,但面对突发的百万级甚至数百万 QPS(如京东等头部平台的爆品场景),单线程的 Redis 会因请求排队、超时导致该分片瘫痪;
- 更严重的是,该分片上的其他数据操作也会被阻塞(“合租”数据受牵连),而短时间内无法通过扩容 Redis 解决(难以快速扩容 10 倍以上),最终 Redis 成为系统瓶颈;
- 对服务层的冲击:服务层(如 Tomcat 集群)的处理能力有限(例:1000 台服务器,单台 1000QPS,总承载 100 万 QPS)。若突发请求中包含大量机器人请求(如 50 万),总请求量超过承载上限(如 150 万),会挤占正常用户资源,导致部分正常用户无法访问,严重影响用户体验;
- 对数据层的冲击:
- 总结来看,有危害的热 key 需同时满足:
- 突发性与不可预知性:非预期的流量爆发,无法提前准备;
- 高并发集中性:请求量远超系统(数据层 / 服务层)的瞬时承载能力;
- 连锁破坏性:不仅影响自身,还会牵连同集群的其他数据 / 服务,导致系统局部或整体瘫痪。
4.2 什么是热 key?
-
热 key 并非单指某一类数据,而是涵盖所有被高频访问、可能带来系统风险的标识,具体包括7类:
- 数据库中的热数据标识:如被频繁查询的爆款商品的
skuId(数据库会因高频访问压力骤增); - Redis中的高频访问key:如存储爆款商品信息的
skuId、店铺shopId等(会导致Redis分片负载过高); - 异常用户/机器标识:如高频请求的机器人
userId、爬虫uuid或ip(可能挤占正常用户资源); - 高频访问的接口地址:如
/sku/query这类被大量请求的接口(会导致接口服务过载); - 用户与接口的组合标识:如
userId + /sku/query(反映单个用户对某接口的访问频率,可识别异常用户); - 服务器与接口的组合标识:如
ip + /sku/query(反映某台服务器上某接口的访问压力,可识别异常流量来源); - 用户、接口与具体资源的组合标识:如
userId + /sku/query + skuId(反映单个用户对某商品的访问频率,可识别针对性的异常行为);
- 数据库中的热数据标识:如被频繁查询的爆款商品的
-
这些“key”本质上是**“字符串形式的访问标识”,其风险在于高频访问**可能对数据库、缓存、服务接口等造成压力,引发系统性能问题;
-
热key探测框架的特点:框架不限制“key的具体形式”,仅关注“作为字符串的key本身”。使用者可根据需求自由组合信息生成key(如拼接用户ID、接口地址、资源ID等),因此框架能灵活支持多种场景:
-
热数据探测(识别高频访问的数据);
-
限流熔断(对高频key的请求进行限制,保护系统);
-
统计分析(了解访问分布、用户行为等)。
-
4.3 以往热 key 问题怎么解决?
-
热key问题涉及多个场景(如Redis热key、刷子用户、限流等),过去的解决方式分散且各有不足:
-
Redis 热 key 的解决方式
-
二级缓存(本地缓存):将 Redis 数据同步到 JVM 缓存(如 Guava Cache),设置过期时间和淘汰策略。但整体命中率低,且难以应对分布式场景下的一致性问题;
-
改写 Redis 源码:在 Redis 中加入热点探测功能,发现热 key 后推送到JVM。但方案不通用,开发难度大,难以适配不同版本或场景;
-
改写 Redis 客户端(Jedis/Letture):通过客户端本地计算探测热 key,本地缓存后通知集群其他机器。但客户端改造复杂度高,且跨集群同步逻辑难统一;
-
-
对于刷子/爬虫用户的解决方式
-
黑名单滞后推送:通过配置中心将累积的黑名单推送到 JVM 内存。但存在滞后性,无法实时识别新的刷子用户;
-
单机本地累加判断:本地统计用户请求频率,超过阈值则判定为刷子。但分布式场景下,用户请求可能分散在多台服务器,单机数据不完整,难以准确甄别;
-
Redis 集中式计数:用 Redis 集中累加用户请求次数,超过阈值则拉取到本地。但频繁读写 Redis 会导致 Redis 成为新的性能瓶颈;
-
-
限流的解决方式
-
单机限流:基于本地累加计数实现接口限流,仅适用于单节点,无法应对集群维度的统一管控;
-
集群限流:依赖第三方中间件(如 Sentinel),但需额外引入组件,增加架构复杂度;
-
网关层限流:通过 Nginx+Lua 实现,但主要针对入口流量,难以覆盖应用内部的细粒度限流需求;
-
-
-
尽管上述方案都围绕“热key”展开,但存在明显短板:
-
分散化:不同场景(Redis 热 key、刷子用户、限流)需单独设计方案,缺乏统一框架,维护成本高;
-
实时性不足:多数方案存在滞后(如黑名单推送),无法快速响应突发热 key;
-
分布式一致性差:单机计算难以覆盖集群场景,跨节点同步热 key 状态困难(如“要有都有,要删全删”);
-
性能瓶颈:依赖 Redis 等中间件时,可能引发新的性能问题(如集中式计数导致 Redis 压力过大);
-
-
理想的框架应具备以下能力:
-
通用性:支持任意类型的 key(无论维度、格式,只要拼接成字符串即可),覆盖热数据探测、限流、刷子识别等所有场景;
-
实时性:能在毫秒级感知热 key(如设定“2秒内出现20次即判定为热 key”),并快速同步到应用 JVM 内存;
-
集群一致性:确保热 key 在整个服务集群内状态统一(所有节点同时生效或同时失效)。
-
4.4 热 key 进内存后的优势
- 热 key 问题的关键在于定位热 key 并把它放到 JVM 内存里。一旦热 key 处于内存中,就能以极快的速度对其进行相关逻辑处理,因为内存访问速度和 Redis 访问速度完全不在一个层级;
- 以刷子用户为例,若用户标识这个热 key 在内存中,就能快速对这类用户执行屏蔽、服务降级或者限制访问速度等操作;
- 对于热接口,可进行限流,直接返回默认值;
- 针对 Redis 的热 key,能极大提升访问速度;
- 再以访问 Redis 中的 key 为例,假设有 1000 台服务器,某个 key 所在的 Redis 集群每秒能支撑 20 万次访问,平均下来每台机器每秒大概只能访问该 key 200 次,超过的请求就会进入等待状态。由于 Redis 本身的性能瓶颈,会极大限制服务器的性能;
- 但如果该 key 在本地内存中,读取内存里的值,每秒访问几十万次都很正常,不会存在数据层的瓶颈。当然,通过增加 Redis 集群规模也能提高数据访问上限,可问题是事先无法知道热 key 会出现在哪里,要是全量增加 Redis 规模,成本又高到难以接受。所以,将热 key 放入内存是更高效且经济的方式。
4.5 热 key 探测关键指标
-
实时性:应对突发风险的核心
-
热 key 的显著特点是“突发性、不可预知”(如商家活动瞬间引爆流量),若探测滞后,会错失规避风险的窗口期(如 Redis 集群被打爆);
-
要求:热 key 刚出现苗头时,需在 1 秒内被探测到并同步至整个服务集群的 JVM 内存,确保后续访问不再密集冲击 Redis;对于刷子用户,也需在 1 秒内完成识别并限制,避免资源被持续挤占;
-
实时性是框架的首要指标,直接决定能否有效拦截热key带来的瞬时冲击;
-
-
准确性:避免误判与漏判
-
热 key 的判定依赖“单位时间内的访问量是否超过阈值”,准确性是框架有效的基础;
-
要求:通过精准的累加计数逻辑,确保探测结果完全符合用户设定的阈值——既不把非热 key 误判为热 key(避免无意义的本地缓存占用资源),也不遗漏真正的热 key(防止风险漏检);
-
准确性相对容易实现,但需严谨的计数逻辑支撑(如滑动窗口算法);
-
-
集群一致性:保障分布式场景下的正确性
-
在分布式集群中,热 key 的状态(存在/删除)需在所有节点保持一致,否则会出现数据错误;
-
要求:例如删除某个热 key 时,集群内所有服务器的 JVM 内存中都要同步删除该 key,避免部分节点仍使用旧缓存数据,导致业务逻辑出错(如已下架商品仍被展示);
-
一致性确保了分布式系统中热 key 处理的统一性,避免因节点状态不一致引发新问题;
-
-
高性能:以低成本实现风险管控
-
热 key 探测的目标是“降低数据层负载、提升系统性能”,若框架自身消耗过多资源,会违背初衷(如比扩充 Redis 集群更费成本);
-
要求:在保证实时性的前提下,框架自身占用的机器资源越少越好。高性能意味着低成本,其经济价值体现在“用少量资源解决高并发风险”,比盲目扩容基础设施更高效。
-
4.6 京东热 key 探测框架架构设计
4.6.1 框架设计背景与核心定位
- JdHotkey 源于应对“突发海量请求压垮数据层”“爬虫/刷子用户高频访问”等问题的需求,是一套通用、轻量级的热key探测框架。其核心特点是:
-
无侵入性:不改 Redis 源码或客户端 jar,与 Redis 无关,不依赖特定组件;
-
易用性:引入 jar 包后即可像使用本地 HashMap 一样调用,框架自动处理 key 上报、热 key 推送、本地缓存等逻辑;
-
核心目标:毫秒级探测热 key,确保集群内热 key 状态一致,适配各类需判断“字符串热度”的场景。
-
4.6.2 核心组件(4大模块)
-
etcd集群。作为高性能配置中心,承担“全局数据一致性”角色:
- 存储规则配置(如“2秒内出现20次即为热key”)、worker节点IP、探测出的热key及手工添加的热key;
- 提供高效的监听订阅服务,确保 client 和 worker 能实时感知配置/节点变化;
-
client 端 jar 包。嵌入业务服务的客户端组件,负责:
- 上报待测 key 到 worker,监听 etcd 中规则、worker 信息、热 key 的变化;
- 用 caffeine 缓存本地热 key,处理过期与淘汰策略;
- 对外提供“判断某 key 是否为热 key ”的接口,业务方可基于此实现限流、降级等逻辑;
-
worker 端集群。独立部署的计算节点,核心职责是“分布式热 key 判定”:
- 启动后连接 etcd,定期上报自身 IP,供 client 建立长连接;
- 接收 client 上报的待测 key,按规则累加计算,当达到阈值时,将热 key 推送给所有 client,并同步到 etcd;
- 支持APP级隔离(避免不同应用竞争资源),单机性能强悍(8核机器每秒可处理16万 key,16核达30万+);
-
dashboard 控制台。可视化管理界面,用于:
- 配置各APP的热key规则(如“userId_开头的 key,2秒出现20次就视为热 key”);
- 监听 etcd 中的热 key 信息,记录入库;
- 支持手工添加/删除热 key,同步至整个集群。
4.6.3 工作流程(4步闭环)
- 搭建 etcd 集群:作为全局数据枢纽,确保所有节点获取一致的规则和 worker 信息;
- 配置规则(dashboard):在控制台为各APP设置热 key 判定规则(如时间窗口、访问次数阈值),规则存入 etcd;
- 启动 worker 集群:
- worker 从 etcd 读取规则并监听变化,定时上报IP供 client 连接;
- client 通过 hash 算法将待测 key 分配到不同 worker(固定 key 对应固定 worker),每500ms批量上报一次(已热的 key 不再上报,除非过期);
- worker 计算 key 的访问频率,达到阈值后推送给所有 client,并同步到 etcd;
- client端处理:
- 接收 worker 推送的热 key,用 caffeine 本地缓存(按规则设置过期时间);
- 监听 etcd 中手工增删的热 key,同步更新本地缓存,确保集群一致性;
- 业务方调用 client 接口判断是否为热 key,自主实现限流、降级等逻辑(如 Redis 热 key 需手动获取 value 并存入本地缓存);
4.6.4 核心优势
- 实时性:默认500ms内探测出热 key 并推送至 JVM 内存,避免 Redis 等数据层被突发流量击垮;
- 高性能与低成本:worker 单机处理能力强(10台机器可支撑每秒300万次探测),远低于扩容 Redis 集群的成本;
- 集群一致性:热 key 的增删在集群内实时同步,避免数据不一致;
- 通用性:仅关注“字符串 key”的热度,适配 Redis 热 key、刷子用户、接口限流等多场景,灵活度高。
client 端
4.7 JD热点key存储管理核心类JdHotKeyStore
package com.jd.platform.hotkey.client.callback;import com.jd.platform.hotkey.client.cache.CacheFactory;
import com.jd.platform.hotkey.client.cache.LocalCache;
import com.jd.platform.hotkey.client.core.key.HotKeyPusher;
import com.jd.platform.hotkey.client.core.key.KeyHandlerFactory;
import com.jd.platform.hotkey.client.core.key.KeyHotModel;
import com.jd.platform.hotkey.common.model.typeenum.KeyType;
import com.jd.platform.hotkey.common.tool.Constant;/*** JD热点key存储管理核心类* 提供热点key的检测、缓存管理和分布式协调功能*/
public class JdHotKeyStore {/*** 检查ValueModel是否即将过期(距离过期时间小于2秒)* @param valueModel 值模型对象* @return true-即将过期,false-未过期或为null*/private static boolean isNearExpire(ValueModel valueModel) { // 见4.8对于CacheFactory的详解if (valueModel == null) {return true;}// 计算剩余过期时间,小于等于2000毫秒视为即将过期return valueModel.getCreateTime() + valueModel.getDuration() - System.currentTimeMillis() <= 2000;}/*** 检测指定key是否为热点key* 如果是热点key则返回true,否则推送key到服务端进行统计* @param key 要检测的key* @return true-是热点key,false-不是热点key*/public static boolean isHotKey(String key) {try {// 首先检查key是否符合配置的规则模式,不符合规则直接返回falseif (!inRule(key)) {return false;}// 检查key是否已经是热点key(存在于本地缓存中)boolean isHot = isHot(key);if (!isHot) {// 如果不是热点key,推送key到服务端进行热度统计HotKeyPusher.push(key, null); // 见4.9对于HotKeyPusher的详解} else {// 如果是热点key,检查是否即将过期,即将过期时重新推送ValueModel valueModel = getValueSimple(key);if (isNearExpire(valueModel)) {HotKeyPusher.push(key, null);}}// 收集key的热度统计信息,用于后续分析KeyHandlerFactory.getCounter().collect(new KeyHotModel(key, isHot)); // 见4.14对于TurnCountCollector类对collect()的详解return isHot;} catch (Exception e) {return false;}}/*** 从本地缓存中获取key对应的值* @param key 要获取的key* @return key对应的值,如果不存在或为默认值则返回null*/public static Object get(String key) {ValueModel value = getValueSimple(key);if (value == null) {return null;}Object object = value.getValue();// 检查是否为魔法数字默认值,如果是则返回nullif (object instanceof Integer && Constant.MAGIC_NUMBER == (int) object) {return null;}return object;}/*** 智能设置key的值:只有当key是热点key时才设置值* @param key 要设置的key* @param value 要设置的值*/public static void smartSet(String key, Object value) {if (isHot(key)) {ValueModel valueModel = getValueSimple(key);if (valueModel == null) {return;}valueModel.setValue(value);}}/*** 强制设置key的值,无论key是否为热点key* @param key 要设置的key* @param value 要设置的值*/public static void forceSet(String key, Object value) {ValueModel valueModel = ValueModel.defaultValue(key);if (valueModel != null) {valueModel.setValue(value);}setValueDirectly(key, valueModel);}/*** 获取key的值,如果值不存在则推送key到服务端进行热度检测* @param key 要获取的key* @param keyType key的类型* @return key对应的值,不存在则返回null*/public static Object getValue(String key, KeyType keyType) {try {// 检查key是否符合规则,不符合则直接返回nullif (!inRule(key)) {return null;}Object userValue = null;ValueModel value = getValueSimple(key);if (value == null) {// 值不存在,推送key到服务端HotKeyPusher.push(key, keyType);} else {// 值存在但即将过期,也推送key到服务端if (isNearExpire(value)) {HotKeyPusher.push(key, keyType);}Object object = value.getValue();// 过滤魔法数字默认值if (object instanceof Integer && Constant.MAGIC_NUMBER == (int) object) {userValue = null;} else {userValue = object;}}// 收集统计信息KeyHandlerFactory.getCounter().collect(new KeyHotModel(key, value != null));return userValue;} catch (Exception e) {return null;}}/*** 获取key的值(简化版,不指定key类型)*/public static Object getValue(String key) {return getValue(key, null);}/*** 简单获取ValueModel对象,不会触发key的上报*/static ValueModel getValueSimple(String key) {Object object = getCache(key).get(key);if (object == null) {return null;}return (ValueModel) object;}/*** 直接设置key的值到本地缓存,不进行热点判断*/static void setValueDirectly(String key, Object value) {getCache(key).set(key, value);}/*** 删除key,并通知整个集群同步删除*/public static void remove(String key) {getCache(key).delete(key);HotKeyPusher.remove(key);}/*** 判断key是否为热点key(仅检查本地缓存是否存在)*/static boolean isHot(String key) {return getValueSimple(key) != null;}/*** 获取key对应的本地缓存实例*/private static LocalCache getCache(String key) { // 见4.10对于LocalCache的详解return CacheFactory.getNonNullCache(key);}/*** 检查key是否符合配置的规则模式* 用于过滤不需要进行热点检测的key*/private static boolean inRule(String key) {return CacheFactory.getCache(key) != null;}
}
_4.8 缓存工厂类CacheFactory类
package com.jd.platform.hotkey.client.cache;import com.jd.platform.hotkey.client.core.rule.KeyRuleHolder;/*** 缓存工厂类* 负责创建和管理本地缓存实例,提供统一的缓存实例获取接口*/
public class CacheFactory {// 默认缓存实例,当key没有匹配到任何规则时使用private static final LocalCache DEFAULT_CACHE = new DefaultCaffeineCache();/*** 创建指定过期时间的本地缓存实例* @param duration 缓存过期时间(秒)* @return 新创建的LocalCache实例*/public static LocalCache build(int duration) {return new CaffeineCache(duration);}/*** 获取key对应的缓存实例,确保返回非空的缓存实例* @param key 缓存键* @return 匹配的LocalCache实例,如果未匹配则返回默认缓存实例*/public static LocalCache getNonNullCache(String key) {LocalCache localCache = getCache(key);if (localCache == null) {return DEFAULT_CACHE;}return localCache;}/*** 根据key查找对应的缓存实例* @param key 缓存键* @return 匹配的LocalCache实例,如果key不符合任何规则则返回null*/public static LocalCache getCache(String key) {// 委托给KeyRuleHolder根据规则配置查找匹配的缓存实例return KeyRuleHolder.findByKey(key); // 见4.11对于KeyRuleHolder的详解}
}
_4.9 热点key推送器HotKeyPusher类
package com.jd.platform.hotkey.client.core.key;import com.jd.platform.hotkey.client.Context;
import com.jd.platform.hotkey.client.core.rule.KeyRuleHolder;
import com.jd.platform.hotkey.client.etcd.EtcdConfigFactory;
import com.jd.platform.hotkey.common.model.HotKeyModel;
import com.jd.platform.hotkey.common.model.typeenum.KeyType;
import com.jd.platform.hotkey.common.tool.Constant;
import com.jd.platform.hotkey.common.tool.HotKeyPathTool;import java.util.concurrent.atomic.LongAdder;/*** 热点key推送器* 客户端向服务端上报热点key的核心入口,支持key的上报、删除和批量聚合*/
public class HotKeyPusher {/*** 推送热点key的核心方法* @param key 要推送的key* @param keyType key的类型(如REDIS_KEY、SQL等)* @param count key的访问计数* @param remove 是否为删除操作*/public static void push(String key, KeyType keyType, int count, boolean remove) {// 参数校验和默认值处理if (count <= 0) {count = 1;}if (keyType == null) {keyType = KeyType.REDIS_KEY; // 默认类型为Redis key}if (key == null) {return; // key为空直接返回}// 使用LongAdder进行高并发场景下的计数累加,避免性能瓶颈LongAdder adderCnt = new LongAdder();adderCnt.add(count);// 构建热点key模型对象HotKeyModel hotKeyModel = new HotKeyModel(); // 见4.12对于HotKeyModel的详解hotKeyModel.setAppName(Context.APP_NAME); // 设置应用名称hotKeyModel.setKeyType(keyType); // 设置key类型hotKeyModel.setCount(adderCnt); // 设置访问计数hotKeyModel.setRemove(remove); // 设置是否为删除操作hotKeyModel.setKey(key); // 设置key值if (remove) {// 删除操作处理:直接操作etcd,不进行聚合// 注意:只能删除手动添加的key,无法删除worker自动探测的key// 通过先设置再删除的方式触发集群监听器的删除事件EtcdConfigFactory.configCenter().putAndGrant(HotKeyPathTool.keyPath(hotKeyModel), Constant.DEFAULT_DELETE_VALUE, 1);EtcdConfigFactory.configCenter().delete(HotKeyPathTool.keyPath(hotKeyModel));// 同时删除worker自动探测目录下的key记录EtcdConfigFactory.configCenter().delete(HotKeyPathTool.keyRecordPath(hotKeyModel));} else {// 正常上报操作:检查key是否符合规则,符合则进行收集聚合if (KeyRuleHolder.isKeyInRule(key)) {// 将热点key模型收集到聚合器中,等待批量发送(默认每半秒发送一次)KeyHandlerFactory.getCollector().collect(hotKeyModel); // 见4.13对于TurnKeyCollector类对collect()的详解}}}/*** 推送热点key(重载方法,默认非删除操作)*/public static void push(String key, KeyType keyType, int count) {push(key, keyType, count, false);}/*** 推送热点key(重载方法,默认计数为1,非删除操作)*/public static void push(String key, KeyType keyType) {push(key, keyType, 1, false);}/*** 推送热点key(重载方法,默认类型为REDIS_KEY,计数为1,非删除操作)*/public static void push(String key) {push(key, KeyType.REDIS_KEY, 1, false);}/*** 删除热点key(快捷方法)*/public static void remove(String key) {push(key, KeyType.REDIS_KEY, 1, true);}
}
_4.10 LocalCache接口与CaffeineCache实现类
-
LocalCache 接口:
package com.jd.platform.hotkey.client.cache;/*** 本地缓存接口定义* 提供统一的本地缓存操作规范,支持多种缓存实现(如Caffeine、Guava Cache等)*/ public interface LocalCache {/*** 根据key获取缓存值* @param key 缓存键* @return 对应的缓存值,如果不存在返回null*/Object get(String key);/*** 根据key获取缓存值,如果不存在则返回默认值* @param key 缓存键* @param defaultValue 默认值* @return 对应的缓存值,如果不存在返回指定的默认值*/Object get(String key, Object defaultValue);/*** 删除指定的缓存项* @param key 要删除的缓存键*/void delete(String key);/*** 设置缓存项(使用默认过期时间)* @param key 缓存键* @param value 缓存值*/void set(String key, Object value);/*** 设置缓存项(指定过期时间)* @param key 缓存键* @param value 缓存值* @param expire 过期时间(毫秒)*/void set(String key, Object value, long expire);/*** 清空所有缓存项* 用于缓存重置或内存清理场景*/void removeAll(); } -
CaffeineCache 实现类:
package com.jd.platform.hotkey.client.cache;import com.github.benmanes.caffeine.cache.Cache;/*** Caffeine缓存实现类* 基于Caffeine缓存库实现LocalCache接口,提供高性能本地缓存功能*/ public class CaffeineCache implements LocalCache {// Caffeine缓存实例,使用String作为key,Object作为valueprivate Cache<String, Object> cache;/*** 构造函数,初始化Caffeine缓存* @param duration 缓存项的默认过期时间(单位:秒)*/public CaffeineCache(int duration) {// 使用CaffeineBuilder创建配置好的缓存实例this.cache = CaffeineBuilder.cache(duration);}/*** 根据key获取缓存值* @param key 缓存键* @return 对应的缓存值,如果不存在返回null*/@Overridepublic Object get(String key) {return get(key, null);}/*** 根据key获取缓存值,如果不存在则返回默认值* @param key 缓存键* @param defaultValue 默认值* @return 对应的缓存值,如果不存在返回指定的默认值*/@Overridepublic Object get(String key, Object defaultValue) {// 使用getIfPresent方法获取缓存值,如果不存在返回nullObject o = cache.getIfPresent(key);if (o == null) {return defaultValue;}return o;}/*** 删除指定的缓存项* @param key 要删除的缓存键*/@Overridepublic void delete(String key) {// 使用invalidate方法使指定key的缓存项失效cache.invalidate(key);}/*** 设置缓存项(使用构造函数中配置的默认过期时间)* @param key 缓存键* @param value 缓存值*/@Overridepublic void set(String key, Object value) {// 使用put方法将key-value对存入缓存cache.put(key, value);}/*** 设置缓存项(指定过期时间)* 注意:此实现中忽略了expire参数,使用统一的过期时间配置* @param key 缓存键* @param value 缓存值* @param expire 过期时间(毫秒)- 在此实现中未使用*/@Overridepublic void set(String key, Object value, long expire) {// 当前实现中忽略自定义过期时间,使用统一的配置set(key, value);}/*** 清空所有缓存项* 用于缓存重置或内存清理场景*/@Overridepublic void removeAll() {// 使用invalidateAll方法清空所有缓存项cache.invalidateAll();} }
_4.11 热点key规则管理器KeyRuleHolder类
package com.jd.platform.hotkey.client.core.rule;import cn.hutool.core.collection.CollectionUtil;
import cn.hutool.core.util.StrUtil;
import com.google.common.eventbus.Subscribe;
import com.jd.platform.hotkey.client.cache.CacheFactory;
import com.jd.platform.hotkey.client.cache.LocalCache;
import com.jd.platform.hotkey.client.log.JdLogger;
import com.jd.platform.hotkey.common.rule.KeyRule;import java.util.ArrayList;
import java.util.List;
import java.util.Set;
import java.util.concurrent.ConcurrentHashMap;
import java.util.stream.Collectors;/*** 热点key规则管理器* 负责管理key的缓存规则,根据规则配置为不同的key分配相应的本地缓存实例*/
public class KeyRuleHolder {// 缓存过期时间与缓存实例的映射表,key为过期时间(秒),value为对应的LocalCache实例private static final ConcurrentHashMap<Integer, LocalCache> RULE_CACHE_MAP = new ConcurrentHashMap<>();// 存储所有的key规则配置private static final List<KeyRule> KEY_RULES = new ArrayList<>();/*** 更新规则配置,根据规则变化重建缓存实例* @param keyRules 新的规则列表*/public static void putRules(List<KeyRule> keyRules) {synchronized (KEY_RULES) {// 清空规则和缓存映射(如果新规则为空)if (CollectionUtil.isEmpty(keyRules)) {KEY_RULES.clear();RULE_CACHE_MAP.clear();return;}// 更新规则列表KEY_RULES.clear();KEY_RULES.addAll(keyRules);// 获取新规则中的所有过期时间Set<Integer> durationSet = keyRules.stream().map(KeyRule::getDuration).collect(Collectors.toSet());// 清理不再使用的缓存实例for (Integer duration : RULE_CACHE_MAP.keySet()) {if (!durationSet.contains(duration)) {RULE_CACHE_MAP.remove(duration);}}// 为每个规则的过期时间创建对应的缓存实例for (KeyRule keyRule : keyRules) {int duration = keyRule.getDuration();if (RULE_CACHE_MAP.get(duration) == null) {LocalCache cache = CacheFactory.build(duration);RULE_CACHE_MAP.put(duration, cache);}}}}/*** 根据key查找对应的缓存实例* @param key 要查找的key* @return 匹配的LocalCache实例,未匹配返回null*/public static LocalCache findByKey(String key) {if (StrUtil.isEmpty(key)) {return null;}KeyRule keyRule = findRule(key);if (keyRule == null) {return null;}// 根据匹配规则的过期时间返回对应的缓存实例return RULE_CACHE_MAP.get(keyRule.getDuration());}/*** 获取key匹配的规则内容* @param key 要匹配的key* @return 匹配的规则key,未匹配返回空字符串*/public static String rule(String key) {KeyRule keyRule = findRule(key);if (keyRule != null) {return keyRule.getKey();}return "";}/*** 获取key对应的缓存过期时间* @param key 要查询的key* @return 过期时间(秒),未匹配返回0*/public static int duration(String key) {KeyRule keyRule = findRule(key);if (keyRule != null) {return keyRule.getDuration();}return 0;}/*** 查找key匹配的规则(精确匹配 > 前缀匹配 > 通配符匹配)* @param key 要匹配的key* @return 匹配的KeyRule对象,未匹配返回null*/private static KeyRule findRule(String key) {KeyRule prefix = null; // 前缀匹配规则KeyRule common = null; // 通配符匹配规则for (KeyRule keyRule : KEY_RULES) {// 精确匹配:key完全相等if (key.equals(keyRule.getKey())) {return keyRule;}// 前缀匹配:key以规则key开头且规则标记为前缀匹配if ((keyRule.isPrefix() && key.startsWith(keyRule.getKey()))) {prefix = keyRule;}// 通配符匹配:规则key为"*"if ("*".equals(keyRule.getKey())) {common = keyRule;}}// 优先返回前缀匹配,其次返回通配符匹配if (prefix != null) {return prefix;}return common;}/*** 判断key是否在规则配置范围内* @param key 要检查的key* @return true-在规则内,false-不在规则内*/public static boolean isKeyInRule(String key) {if (StrUtil.isEmpty(key)) {return false;}// 检查key是否匹配任何规则(精确、前缀或通配符)for (KeyRule keyRule : KEY_RULES) {if ("*".equals(keyRule.getKey()) || key.equals(keyRule.getKey()) ||(keyRule.isPrefix() && key.startsWith(keyRule.getKey()))) {return true;}}return false;}/*** 规则变更事件监听器* @param event 规则变更事件*/@Subscribepublic void ruleChange(KeyRuleInfoChangeEvent event) {JdLogger.info(getClass(), "new rules info is :" + event.getKeyRules());List<KeyRule> ruleList = event.getKeyRules();if (ruleList == null) {return;}// 接收到规则变更事件后更新规则配置putRules(ruleList);}
}
_4.12 热点key模型类HotKeyModel与基础模型类BaseModel
-
HotKeyModel:
package com.jd.platform.hotkey.common.model;import com.jd.platform.hotkey.common.model.typeenum.KeyType;/*** 热点key模型类* 用于在客户端和工作节点之间传输热点key信息的核心数据模型*/ public class HotKeyModel extends BaseModel {/*** 热点key所属的应用名称* 用于在多应用环境下区分key的来源*/private String appName;/*** key的类型枚举* 用于区分不同类型的key(如接口、用户、Redis key等)*/private KeyType keyType;/*** 是否为删除操作标志* true表示这是一个删除key的请求,false表示正常的热点key上报*/private boolean remove;/*** 简化toString方法,便于日志记录和调试*/@Overridepublic String toString() {return "appName:" + appName + "-key=" + getKey();}// Getter和Setter方法public boolean isRemove() {return remove;}public void setRemove(boolean remove) {this.remove = remove;}public String getAppName() {return appName;}public void setAppName(String appName) {this.appName = appName;}public KeyType getKeyType() {return keyType;}public void setKeyType(KeyType keyType) {this.keyType = keyType;} } -
BaseModel:
package com.jd.platform.hotkey.common.model;import com.alibaba.fastjson.annotation.JSONField; import com.jd.platform.hotkey.common.convert.LongAdderSerializer; import com.jd.platform.hotkey.common.tool.IdGenerater;import java.util.concurrent.atomic.LongAdder;/*** 基础模型类* 提供热点key模型的基础字段和通用功能*/ public class BaseModel {/*** 唯一标识符,使用IdGenerater生成* 确保每个热点key记录都有唯一的ID*/private String id = IdGenerater.generateId();/*** 模型创建时间戳* 记录热点key被检测到的时间*/private long createTime;/*** 实际的key值* 存储业务系统中的原始key名称*/private String key;/*** key的访问计数,使用LongAdder解决多线程计数问题* 通过JSONField注解指定自定义序列化器*/@JSONField(serializeUsing = LongAdderSerializer.class)private LongAdder count;/*** 完整的toString方法,用于调试和日志输出*/@Overridepublic String toString() {return "BaseModel{" +"id='" + id + '\'' +", createTime=" + createTime +", key='" + key + '\'' +", count=" + count +'}';}/*** 获取计数总和* @return 当前的总计数值*/public long getCount() {return count.sum();}/*** 设置LongAdder计数对象* @param count LongAdder实例*/public void setCount(LongAdder count) {this.count = count;}/*** 增加指定数量的计数* @param count 要增加的数量*/public void add(long count){this.count.add(count);}// Getter和Setter方法public String getId() {return id;}public void setId(String id) {this.id = id;}public long getCreateTime() {return createTime;}public void setCreateTime(long createTime) {this.createTime = createTime;}public String getKey() {return key;}public void setKey(String key) {this.key = key;} }
_4.13 轮换式热点key收集器TurnKeyCollector
package com.jd.platform.hotkey.client.core.key;import cn.hutool.core.collection.CollectionUtil;
import cn.hutool.core.util.StrUtil;
import com.jd.platform.hotkey.common.model.HotKeyModel;import java.util.List;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.atomic.AtomicLong;/*** 轮换式热点key收集器* 采用双Map轮换机制实现无锁的高并发数据收集,确保上报过程中不阻塞写入操作*/
public class TurnKeyCollector implements IKeyCollector<HotKeyModel, HotKeyModel> {// 双Map结构,用于轮换存储热点key数据private ConcurrentHashMap<String, HotKeyModel> map0 = new ConcurrentHashMap<>();private ConcurrentHashMap<String, HotKeyModel> map1 = new ConcurrentHashMap<>();// 原子计数器,用于控制Map的轮换选择private AtomicLong atomicLong = new AtomicLong(0);/*** 锁定当前Map并获取其中的所有数据* 通过原子计数器切换Map,实现读写分离* @return 当前Map中所有的热点key数据列表*/@Overridepublic List<HotKeyModel> lockAndGetResult() {// 原子递增计数器,触发Map切换atomicLong.addAndGet(1);List<HotKeyModel> list;// 根据计数器的奇偶性选择要读取的Mapif (atomicLong.get() % 2 == 0) {// 偶数时读取map1并清空list = get(map1);map1.clear();} else {// 奇数时读取map0并清空list = get(map0);map0.clear();}return list;}/*** 从指定Map中提取所有值并转换为列表* @param map 要提取数据的Map* @return Map中所有值的列表*/private List<HotKeyModel> get(ConcurrentHashMap<String, HotKeyModel> map) {return CollectionUtil.list(false, map.values());}/*** 收集热点key数据* 根据当前计数器的状态选择写入的Map,支持计数累加* @param hotKeyModel 要收集的热点key模型*/@Overridepublic void collect(HotKeyModel hotKeyModel) {String key = hotKeyModel.getKey();if (StrUtil.isEmpty(key)) {return;}// 根据计数器的奇偶性选择写入的Mapif (atomicLong.get() % 2 == 0) {// 偶数时写入map0HotKeyModel model = map0.putIfAbsent(key, hotKeyModel);if (model != null) {// 如果key已存在,累加计数而不是覆盖model.add(hotKeyModel.getCount());}} else {// 奇数时写入map1HotKeyModel model = map1.putIfAbsent(key, hotKeyModel);if (model != null) {model.add(hotKeyModel.getCount());}}}/*** 完成一次处理(空实现,用于接口兼容)*/@Overridepublic void finishOnce() {// 预留扩展方法}
}
_4.14 热点数量统计收集器TurnCountCollector
package com.jd.platform.hotkey.client.core.key;import cn.hutool.core.util.StrUtil;
import com.jd.platform.hotkey.client.core.rule.KeyRuleHolder;
import com.jd.platform.hotkey.common.model.KeyCountModel;
import com.jd.platform.hotkey.common.tool.Constant;import java.text.SimpleDateFormat;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.atomic.AtomicLong;
import java.util.concurrent.atomic.LongAdder;
import java.util.stream.Collectors;/*** 热点数量统计收集器* 用于收集和统计热点key的访问次数,支持按时间窗口和规则进行聚合统计*/
public class TurnCountCollector implements IKeyCollector<KeyHotModel, KeyCountModel> {/*** 双Map结构用于存储命中统计,格式为:* 规则key_时间 -> HitCount对象* 例如:* pin_2020-06-24 09:10:24 -> 10次命中* pin_2020-06-24 09:10:25 -> 20次命中* sku_2020-06-24 09:10:24 -> 123次命中*/private ConcurrentHashMap<String, HitCount> HIT_MAP_0 = new ConcurrentHashMap<>(512);private ConcurrentHashMap<String, HitCount> HIT_MAP_1 = new ConcurrentHashMap<>(512);// 时间格式化模板private static final String FORMAT = "yyyy-MM-dd HH:mm:ss";// 原子计数器,用于控制双Map的轮换private AtomicLong atomicLong = new AtomicLong(0);// 数据转换的并行处理阈值,超过5000条数据时启用并行处理private static final int DATA_CONVERT_SWITCH_THRESHOLD = 5000;/*** 锁定当前Map并获取统计结果* 通过原子计数器切换Map,实现读写分离* @return 统计结果列表*/@Overridepublic List<KeyCountModel> lockAndGetResult() {// 原子递增计数器,触发Map切换atomicLong.addAndGet(1);List<KeyCountModel> list;// 根据计数器的奇偶性选择要读取的Mapif (atomicLong.get() % 2 == 0) {// 偶数时读取HIT_MAP_1并清空list = get(HIT_MAP_1);HIT_MAP_1.clear();} else {// 奇数时读取HIT_MAP_0并清空list = get(HIT_MAP_0);HIT_MAP_0.clear();}return list;}/*** 从指定Map中提取统计结果* 根据数据量大小选择并行或串行转换方式* @param map 要处理的统计Map* @return 转换后的统计模型列表*/private List<KeyCountModel> get(ConcurrentHashMap<String, HitCount> map) {// 根据数据量阈值选择转换方式if (map.size() > DATA_CONVERT_SWITCH_THRESHOLD) {return parallelConvert(map);} else {return syncConvert(map);}}/*** 并行数据转换(大数据量时使用)* @param map 统计数据Map* @return 转换后的统计模型列表*/private List<KeyCountModel> parallelConvert(ConcurrentHashMap<String, HitCount> map) {return map.entrySet().parallelStream().map(entry -> {String key = entry.getKey();HitCount hitCount = entry.getValue();KeyCountModel keyCountModel = new KeyCountModel();keyCountModel.setTotalHitCount((int) hitCount.totalHitCount.sum());keyCountModel.setRuleKey(key);keyCountModel.setHotHitCount((int) hitCount.hotHitCount.sum());return keyCountModel;}).collect(Collectors.toList());}/*** 同步数据转换(小数据量时使用)* @param map 统计数据Map* @return 转换后的统计模型列表*/private List<KeyCountModel> syncConvert(ConcurrentHashMap<String, HitCount> map) {List<KeyCountModel> list = new ArrayList<>(map.size());for (Map.Entry<String, HitCount> entry : map.entrySet()) {String key = entry.getKey();HitCount hitCount = entry.getValue();KeyCountModel keyCountModel = new KeyCountModel();keyCountModel.setTotalHitCount((int) hitCount.totalHitCount.sum());keyCountModel.setRuleKey(key);keyCountModel.setHotHitCount((int) hitCount.hotHitCount.sum());list.add(keyCountModel);}return list;}/*** 收集热点key统计信息* @param keyHotModel 热点key模型*/@Overridepublic void collect(KeyHotModel keyHotModel) {// 根据计数器的奇偶性选择写入的Mapif (atomicLong.get() % 2 == 0) {put(keyHotModel.getKey(), keyHotModel.isHot(), HIT_MAP_0);} else {put(keyHotModel.getKey(), keyHotModel.isHot(), HIT_MAP_1);}}@Overridepublic void finishOnce() {// 预留扩展方法}/*** 将统计信息放入指定Map* @param key 原始key* @param isHot 是否为热点key* @param map 目标Map*/public void put(String key, boolean isHot, ConcurrentHashMap<String, HitCount> map) {// 获取key匹配的规则String rule = KeyRuleHolder.rule(key);// 不在规则内的key不处理if (StrUtil.isEmpty(rule)) {return;}String nowTime = nowTime();// 构建Map的key:规则 + 分隔符 + 时间String mapKey = rule + Constant.COUNT_DELIMITER + nowTime;// 线程安全地获取或创建HitCount对象HitCount hitCount = map.computeIfAbsent(mapKey, v -> new HitCount());// 更新统计计数if (isHot) {// 热点命中计数增加hitCount.hotHitCount.increment();}// 总命中计数增加hitCount.totalHitCount.increment();}/*** 获取当前格式化的时间字符串* @return 格式化的时间字符串*/private String nowTime() {Date nowTime = new Date(System.currentTimeMillis());SimpleDateFormat sdFormatter = new SimpleDateFormat(FORMAT);return sdFormatter.format(nowTime);}/*** 内部类:命中计数统计*/private class HitCount {// 热点key命中次数统计private LongAdder hotHitCount = new LongAdder();// 总命中次数统计private LongAdder totalHitCount = new LongAdder();}
}
_4.15 热点key检测客户端启动器ClientStarter
package com.jd.platform.hotkey.client;import com.jd.platform.hotkey.client.callback.ReceiveNewKeySubscribe;
import com.jd.platform.hotkey.client.core.eventbus.EventBusCenter;
import com.jd.platform.hotkey.client.core.key.PushSchedulerStarter;
import com.jd.platform.hotkey.client.core.rule.KeyRuleHolder;
import com.jd.platform.hotkey.client.core.worker.WorkerChangeSubscriber;
import com.jd.platform.hotkey.client.core.worker.WorkerRetryConnector;
import com.jd.platform.hotkey.client.etcd.EtcdConfigFactory;
import com.jd.platform.hotkey.client.etcd.EtcdStarter;
import com.jd.platform.hotkey.client.log.JdLogger;/*** 热点key检测客户端启动器* 负责初始化并启动整个热点key检测客户端的各个组件*/
public class ClientStarter {private String etcdServer; // etcd服务器地址/*** key推送间隔时间(毫秒)* 推送频率越高,热点检测越及时,但客户端资源消耗也越大*/private Long pushPeriod;/*** 本地Caffeine缓存的最大容量* 默认值20万,用于存储热点key数据*/private int caffeineSize;/*** 构造函数,初始化应用名称* @param appName 应用名称,用于区分不同应用的热点key*/public ClientStarter(String appName) {if (appName == null) {throw new NullPointerException("APP_NAME cannot be null!");}Context.APP_NAME = appName; // 设置全局上下文的应用名称}/*** 建造者模式内部类,用于链式配置客户端参数*/public static class Builder {private String appName; // 应用名称private String etcdServer; // etcd服务器地址private Long pushPeriod; // 推送间隔private int caffeineSize = 200000; // 缓存容量默认20万public Builder() {}public Builder setAppName(String appName) {this.appName = appName;return this;}public Builder setCaffeineSize(int caffeineSize) {if (caffeineSize < 128) {caffeineSize = 128; // 设置最小容量为128}this.caffeineSize = caffeineSize;return this;}public Builder setEtcdServer(String etcdServer) {this.etcdServer = etcdServer;return this;}public Builder setPushPeriod(Long pushPeriod) {this.pushPeriod = pushPeriod;return this;}/*** 构建ClientStarter实例*/public ClientStarter build() {ClientStarter clientStarter = new ClientStarter(appName);clientStarter.etcdServer = etcdServer;clientStarter.pushPeriod = pushPeriod;clientStarter.caffeineSize = caffeineSize;return clientStarter;}}/*** 启动客户端管道,初始化所有组件* 这是客户端启动的核心方法*/public void startPipeline() {JdLogger.info(getClass(), "etcdServer:" + etcdServer);// 设置全局缓存容量Context.CAFFEINE_SIZE = caffeineSize;// 初始化etcd配置中心EtcdConfigFactory.buildConfigCenter(etcdServer);// 启动key推送调度器PushSchedulerStarter.startPusher(pushPeriod); // 见4.16对于PushSchedulerStarter的详解// 启动统计信息推送调度器(固定10秒间隔)PushSchedulerStarter.startCountPusher(10);// 启动worker重连器,确保与工作节点的连接WorkerRetryConnector.retryConnectWorkers();// 注册事件总线监听器registEventBus();// 启动etcd相关监听器EtcdStarter starter = new EtcdStarter();starter.start();}/*** 注册事件总线监听器* 将各个组件注册到事件总线,实现组件间的事件通信*/private void registEventBus() {// 注册worker变化订阅器,监听worker节点变化事件EventBusCenter.register(new WorkerChangeSubscriber());// 注册新key接收订阅器,监听热点key发现事件EventBusCenter.register(new ReceiveNewKeySubscribe()); // 见4.17对于ReceiveNewKeySubscribe的详解// 注册规则持有器,监听规则变化事件EventBusCenter.register(new KeyRuleHolder());}
}
_4.16 定时推送调度器启动器PushSchedulerStarter
package com.jd.platform.hotkey.client.core.key;import cn.hutool.core.collection.CollectionUtil;
import cn.hutool.core.thread.NamedThreadFactory;
import com.jd.platform.hotkey.client.Context;
import com.jd.platform.hotkey.common.model.HotKeyModel;
import com.jd.platform.hotkey.common.model.KeyCountModel;import java.util.List;
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;/*** 定时推送调度器启动器* 负责启动定时任务,定期将收集的热点key数据和统计信息推送到worker节点*/
public class PushSchedulerStarter {/*** 启动热点key推送定时任务* 定期将待检测的热点key推送到worker节点进行分析* @param period 推送间隔时间(毫秒),如果为null或小于等于0则使用默认值500ms*/public static void startPusher(Long period) {// 参数校验和默认值设置if (period == null || period <= 0) {period = 500L; // 默认500毫秒(0.5秒)推送一次}// 创建单线程定时任务执行器,确保任务顺序执行@SuppressWarnings("PMD.ThreadPoolCreationRule")ScheduledExecutorService scheduledExecutorService =Executors.newSingleThreadScheduledExecutor(new NamedThreadFactory("hotkey-pusher-service-executor", true));// 定时执行推送任务scheduledExecutorService.scheduleAtFixedRate(() -> {// 获取热点key收集器实例IKeyCollector<HotKeyModel, HotKeyModel> collectHK = KeyHandlerFactory.getCollector();// 锁定并获取当前批次的热点key数据List<HotKeyModel> hotKeyModels = collectHK.lockAndGetResult();// 如果存在待推送的数据,则发送到worker节点if(CollectionUtil.isNotEmpty(hotKeyModels)){KeyHandlerFactory.getPusher().send(Context.APP_NAME, hotKeyModels);// 标记当前批次处理完成collectHK.finishOnce();}}, 0, period, TimeUnit.MILLISECONDS); // 初始延迟0,固定间隔执行}/*** 启动统计信息推送定时任务* 定期将热点key的统计信息推送到worker节点用于监控和分析* @param period 推送间隔时间(秒),如果为null或小于等于0则使用默认值10秒*/public static void startCountPusher(Integer period) {// 参数校验和默认值设置if (period == null || period <= 0) {period = 10; // 默认10秒推送一次统计信息}// 创建单线程定时任务执行器@SuppressWarnings("PMD.ThreadPoolCreationRule")ScheduledExecutorService scheduledExecutorService = Executors.newSingleThreadScheduledExecutor(new NamedThreadFactory("hotkey-count-pusher-service-executor", true));// 定时执行统计信息推送任务scheduledExecutorService.scheduleAtFixedRate(() -> {// 获取统计信息收集器实例IKeyCollector<KeyHotModel, KeyCountModel> collectHK = KeyHandlerFactory.getCounter();// 锁定并获取当前批次的统计信息List<KeyCountModel> keyCountModels = collectHK.lockAndGetResult();// 如果存在待推送的统计信息,则发送到worker节点if(CollectionUtil.isNotEmpty(keyCountModels)){KeyHandlerFactory.getPusher().sendCount(Context.APP_NAME, keyCountModels);// 标记当前批次处理完成collectHK.finishOnce();}}, 0, period, TimeUnit.SECONDS); // 初始延迟0,固定间隔执行}
}
_4.17 新热点key事件订阅器ReceiveNewKeySubscribe
package com.jd.platform.hotkey.client.callback;import com.google.common.eventbus.Subscribe;
import com.jd.platform.hotkey.common.model.HotKeyModel;/*** 新热点key事件订阅器* 监听并处理从服务端推送过来的新热点key发现事件*/
public class ReceiveNewKeySubscribe {// 新key监听器实例,默认使用DefaultNewKeyListenerprivate ReceiveNewKeyListener receiveNewKeyListener = new DefaultNewKeyListener();/*** 事件监听方法 - 新热点key到达事件* 使用@Subscribe注解注册为Guava EventBus的事件处理器* @param event 接收到的新热点key事件对象*/@Subscribepublic void newKeyComing(ReceiveNewKeyEvent event) {// 从事件中获取热点key模型数据HotKeyModel hotKeyModel = event.getModel();if (hotKeyModel == null) {return; // 模型为空直接返回,避免空指针异常}// 接收到新热点key推送,调用监听器进行处理if (receiveNewKeyListener != null) {receiveNewKeyListener.newKey(hotKeyModel); // 见4.18对于DefaultNewKeyListener中newKey()的详解}}
}
_4.18 默认新热点key监听器实现DefaultNewKeyListener
package com.jd.platform.hotkey.client.callback;import com.jd.platform.hotkey.client.cache.CacheFactory;
import com.jd.platform.hotkey.client.log.JdLogger;
import com.jd.platform.hotkey.common.model.HotKeyModel;/*** 默认新热点key监听器实现* 处理从worker节点或etcd接收到的新增和删除热点key事件*/
public class DefaultNewKeyListener implements ReceiveNewKeyListener {@Overridepublic void newKey(HotKeyModel hotKeyModel) {long now = System.currentTimeMillis();// 检测key是否延迟到达:如果创建时间与当前时间相差超过1秒,记录警告日志// 注意:手动删除的key没有createTime,需要跳过检测if (hotKeyModel.getCreateTime() != 0 && Math.abs(now - hotKeyModel.getCreateTime()) > 1000) {JdLogger.warn(getClass(), "the key comes too late : " + hotKeyModel.getKey() + " now " ++now + " keyCreateAt " + hotKeyModel.getCreateTime());}// 处理删除事件if (hotKeyModel.isRemove()) {deleteKey(hotKeyModel.getKey());return;}// 处理重复热点key:如果key已经是热点,记录警告日志但仍会刷新if (JdHotKeyStore.isHot(hotKeyModel.getKey())) {JdLogger.warn(getClass(), "receive repeat hot key :" + hotKeyModel.getKey() + " at " + now);}// 添加新的热点keyaddKey(hotKeyModel.getKey());}/*** 添加热点key到本地缓存* @param key 要添加的热点key*/private void addKey(String key) {// 创建默认的ValueModel,包含过期时间等信息ValueModel valueModel = ValueModel.defaultValue(key);if (valueModel == null) {// key不符合任何配置规则,执行删除操作确保清理deleteKey(key);return;}// 设置key到本地缓存:如果已存在则覆盖并重置过期时间,不存在则新增JdHotKeyStore.setValueDirectly(key, valueModel);}/*** 从本地缓存删除key* @param key 要删除的key*/private void deleteKey(String key) {CacheFactory.getNonNullCache(key).delete(key);}
}
worker 端
4.19 滑动窗口计数器SlidingWindow
package com.jd.platform.hotkey.worker.tool;import cn.hutool.core.date.SystemClock;import java.util.concurrent.BrokenBarrierException;
import java.util.concurrent.CyclicBarrier;
import java.util.concurrent.atomic.AtomicLong;/*** 滑动窗口计数器* 用于在固定时间窗口内统计事件数量,判断是否超过阈值,支持高并发环境*/
public class SlidingWindow {/*** 循环队列,存储多个时间片的计数,长度为windowSize的2倍* 采用双倍长度避免数据覆盖问题*/private AtomicLong[] timeSlices;/*** 循环队列的总长度(timeSliceSize = windowSize * 2)*/private int timeSliceSize;/*** 每个时间片的时长(毫秒)* 决定时间窗口的精度*/private int timeMillisPerSlice;/*** 窗口包含的时间片数量(窗口长度)* 窗口总时长 = timeMillisPerSlice * windowSize*/private int windowSize;/*** 窗口期内允许通过的最大阈值* 超过该阈值则认为达到热点条件*/private int threshold;/*** 滑动窗口的起始创建时间戳* 用于计算当前时间片位置*/private long beginTimestamp;/*** 最后一次添加计数的时间戳* 用于检测窗口重置条件*/private long lastAddTimestamp;/*** 测试方法:演示多线程环境下的滑动窗口使用*/public static void main(String[] args) {// 创建滑动窗口:每个时间片2毫秒,窗口阈值20SlidingWindow window = new SlidingWindow(2, 20);// 使用CyclicBarrier模拟10个线程同时操作CyclicBarrier cyclicBarrier = new CyclicBarrier(10);for (int i = 0; i < 10; i++) {new Thread(new Runnable() {@Overridepublic void run() {try {cyclicBarrier.await(); // 等待所有线程就绪} catch (InterruptedException | BrokenBarrierException e) {e.printStackTrace();}boolean hot = window.addCount(2); // 每个线程增加2个计数System.out.println(hot);}}).start();}}/*** 简化构造函数:根据duration自动计算窗口参数* @param duration 窗口总时长(秒)* @param threshold 窗口期内允许的最大阈值*/public SlidingWindow(int duration, int threshold) {// 限制最大时长为10分钟(600秒)if (duration > 600) {duration = 600;}// 5秒内的探测使用精细粒度窗口if (duration <= 5) {this.windowSize = 5; // 5个时间片this.timeMillisPerSlice = duration * 200; // 每个时间片200ms * duration} else {this.windowSize = 10; // 10个时间片this.timeMillisPerSlice = duration * 100; // 每个时间片100ms * duration}this.threshold = threshold;// 双倍长度避免数据覆盖this.timeSliceSize = windowSize * 2;reset(); // 初始化窗口}/*** 完整构造函数:自定义所有参数*/public SlidingWindow(int timeMillisPerSlice, int windowSize, int threshold) {this.timeMillisPerSlice = timeMillisPerSlice;this.windowSize = windowSize;this.threshold = threshold;this.timeSliceSize = windowSize * 2;reset();}/*** 重置滑动窗口,初始化所有时间片*/private void reset() {beginTimestamp = SystemClock.now();// 初始化时间片数组,所有计数归零AtomicLong[] localTimeSlices = new AtomicLong[timeSliceSize];for (int i = 0; i < timeSliceSize; i++) {localTimeSlices[i] = new AtomicLong(0);}timeSlices = localTimeSlices;}/*** 计算当前时间所在的时间片索引* @return 当前时间片在循环队列中的索引位置*/private int locationIndex() {long now = SystemClock.now();// 如果超过整个窗口时长没有操作,重置窗口if (now - lastAddTimestamp > timeMillisPerSlice * windowSize) {reset();}// 计算当前时间片索引:(经过时间/时间片长度) % 队列长度int index = (int) (((now - beginTimestamp) / timeMillisPerSlice) % timeSliceSize);if (index < 0) {return 0;}return index;}/*** 增加指定数量的计数* @param count 要增加的数量* @return true-超过阈值(热点),false-未超过阈值*/public synchronized boolean addCount(long count) { // 见4.20中的热点key监听器`KeyListener`对该方法的调用// 获取当前时间片索引int index = locationIndex();// 清理过期的时间片数据(当前索引后面的windowSize个时间片)clearFromIndex(index);int sum = 0;// 在当前时间片增加计数sum += timeSlices[index].addAndGet(count);// 累加前windowSize-1个时间片的计数for (int i = 1; i < windowSize; i++) {sum += timeSlices[(index - i + timeSliceSize) % timeSliceSize].get();}lastAddTimestamp = SystemClock.now();// 判断是否超过阈值return sum >= threshold;}/*** 从指定索引开始清理过期数据* 清理index后面windowSize个时间片的数据* @param index 起始索引*/private void clearFromIndex(int index) {for (int i = 1; i <= windowSize; i++) {int j = index + i;// 处理循环队列的索引越界if (j >= windowSize * 2) {j -= windowSize * 2;}timeSlices[j].set(0); // 清空计数}}
}
_4.20 热点key监听器KeyListener
package com.jd.platform.hotkey.worker.keylistener;import cn.hutool.core.date.SystemClock;
import com.github.benmanes.caffeine.cache.Cache;
import com.google.common.base.Function;
import com.google.common.base.Joiner;
import com.jd.platform.hotkey.common.model.HotKeyModel;
import com.jd.platform.hotkey.common.rule.KeyRule;
import com.jd.platform.hotkey.worker.cache.CaffeineCacheHolder;
import com.jd.platform.hotkey.worker.netty.pusher.IPusher;
import com.jd.platform.hotkey.worker.rule.KeyRuleHolder;
import com.jd.platform.hotkey.worker.starters.EtcdStarter;
import com.jd.platform.hotkey.worker.tool.SlidingWindow;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.stereotype.Component;import javax.annotation.Resource;
import java.util.List;/*** 热点key事件监听处理器* 负责处理新key的检测、热点判断和推送,以及key的删除操作*/
@Component
public class KeyListener implements IKeyListener {@Resource(name = "hotKeyCache")private Cache<String, Object> hotCache; // 热点key缓存,存储已确认为热点的key@Resourceprivate List<IPusher> iPushers; // 推送器列表,支持多种推送方式private static final String SPLITER = "-"; // key构建分隔符private Logger logger = LoggerFactory.getLogger(getClass());private static final String NEW_KEY_EVENT = "new key created event, key : ";private static final String DELETE_KEY_EVENT = "key delete event key : ";/*** 处理新key事件* @param hotKeyModel 热点key模型数据* @param original 事件来源*/@Overridepublic void newKey(HotKeyModel hotKeyModel, KeyEventOriginal original) { // 见4.23KeyConsumer对该方法的调用// 构建缓存key:应用名-key类型-原始keyString key = buildKey(hotKeyModel);// 检查key是否已经是热点(防止重复处理)Object o = hotCache.getIfPresent(key);if (o != null) {return; // 已经是热点key,直接返回避免重复处理}// 获取或创建该key对应的滑动窗口SlidingWindow slidingWindow = checkWindow(hotKeyModel, key);// 增加计数并判断是否达到热点阈值boolean hot = slidingWindow.addCount(hotKeyModel.getCount());if (!hot) {// 未达到热点阈值,重新放入缓存以刷新过期时间CaffeineCacheHolder.getCache(hotKeyModel.getAppName()).put(key, slidingWindow); // 见4.21对于CaffeineCacheHolder的详解} else {// 达到热点阈值,标记为热点keyhotCache.put(key, 1);// 从应用缓存中移除滑动窗口(热点key不再需要计数)CaffeineCacheHolder.getCache(hotKeyModel.getAppName()).invalidate(key);// 设置热点key的创建时间hotKeyModel.setCreateTime(SystemClock.now());// 根据配置决定是否记录日志(大促期间可关闭)if (EtcdStarter.LOGGER_ON) {logger.info(NEW_KEY_EVENT + hotKeyModel.getKey());}// 通过所有推送器向客户端和etcd推送热点key信息for (IPusher pusher : iPushers) {pusher.push(hotKeyModel); // 见4.22AppServerPusher对push()的详解}}}/*** 处理key删除事件* @param hotKeyModel 热点key模型数据* @param original 事件来源*/@Overridepublic void removeKey(HotKeyModel hotKeyModel, KeyEventOriginal original) {// 构建缓存keyString key = buildKey(hotKeyModel);// 从热点缓存和应用缓存中移除keyhotCache.invalidate(key);CaffeineCacheHolder.getCache(hotKeyModel.getAppName()).invalidate(key);// 设置删除时间并记录日志hotKeyModel.setCreateTime(SystemClock.now());logger.info(DELETE_KEY_EVENT + hotKeyModel.getKey());// 通过所有推送器通知客户端删除keyfor (IPusher pusher : iPushers) {pusher.remove(hotKeyModel);}}/*** 获取或创建key对应的滑动窗口* @param hotKeyModel 热点key模型* @param key 构建后的缓存key* @return 滑动窗口实例*/private SlidingWindow checkWindow(HotKeyModel hotKeyModel, String key) {// 从应用缓存中获取滑动窗口,如果不存在则创建新的return (SlidingWindow) CaffeineCacheHolder.getCache(hotKeyModel.getAppName()).get(key, (Function<String, SlidingWindow>) s -> {// 新key:根据规则配置创建滑动窗口KeyRule keyRule = KeyRuleHolder.getRuleByAppAndKey(hotKeyModel);return new SlidingWindow(keyRule.getInterval(), keyRule.getThreshold());});}/*** 构建缓存key* @param hotKeyModel 热点key模型* @return 格式化的缓存key*/private String buildKey(HotKeyModel hotKeyModel) {return Joiner.on(SPLITER).join(hotKeyModel.getAppName(), hotKeyModel.getKeyType(), hotKeyModel.getKey());}
}
_4.21 Caffeine缓存持有期CaffeineCacheHolder
package com.jd.platform.hotkey.worker.cache;import cn.hutool.core.util.StrUtil;
import com.github.benmanes.caffeine.cache.Cache;import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;/*** Caffeine缓存持有器* 为每个应用提供独立的本地缓存实例,实现多租户缓存隔离*/
public class CaffeineCacheHolder {/*** 应用缓存映射表:key为应用名称,value为对应的Caffeine缓存实例* 使用ConcurrentHashMap保证线程安全*/private static final Map<String, Cache<String, Object>> CACHE_MAP = new ConcurrentHashMap<>();// 默认缓存名称,用于处理应用名为空的情况private static final String DEFAULT = "default";/*** 获取指定应用的缓存实例* 如果应用缓存不存在,则自动创建新的缓存实例* @param appName 应用名称* @return 对应的Caffeine缓存实例*/public static Cache<String, Object> getCache(String appName) {if (StrUtil.isEmpty(appName)) {// 应用名为空时使用默认缓存if (CACHE_MAP.get(DEFAULT) == null) {Cache<String, Object> cache = CaffeineBuilder.buildAllKeyCache();CACHE_MAP.put(DEFAULT, cache);}return CACHE_MAP.get(DEFAULT);}// 获取或创建指定应用的缓存if(CACHE_MAP.get(appName) == null) {Cache<String, Object> cache = CaffeineBuilder.buildAllKeyCache();CACHE_MAP.put(appName, cache);}return CACHE_MAP.get(appName);}/*** 清空指定应用的所有缓存数据* 用于应用重启或缓存重置场景* @param appName 要清空缓存的应用名称*/public static void clearCacheByAppName(String appName) {if(CACHE_MAP.get(appName) != null) {CACHE_MAP.get(appName).invalidateAll();}}/*** 获取所有应用缓存的当前大小统计* 用于监控和调试目的* @return 应用名称到缓存大小的映射表*/public static Map<String, Integer> getSize() {Map<String, Integer> map = new HashMap<>();for (String appName : CACHE_MAP.keySet()) {Cache cache = CACHE_MAP.get(appName);Map caffMap = cache.asMap();// 获取缓存中当前存储的key数量map.put(appName, caffMap.size());}return map;}
}
_4.22 应用服务器推送器AppServerPusher
package com.jd.platform.hotkey.worker.netty.pusher;import cn.hutool.core.collection.CollectionUtil;
import com.google.common.collect.Queues;
import com.jd.platform.hotkey.common.model.HotKeyModel;
import com.jd.platform.hotkey.common.model.HotKeyMsg;
import com.jd.platform.hotkey.common.model.typeenum.MessageType;
import com.jd.platform.hotkey.worker.model.AppInfo;
import com.jd.platform.hotkey.worker.netty.holder.ClientInfoHolder;
import com.jd.platform.hotkey.worker.tool.AsyncPool;
import org.springframework.stereotype.Component;import javax.annotation.PostConstruct;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.TimeUnit;/*** 应用服务器推送器* 负责将热点key信息批量推送到各个客户端应用服务器*/
@Component
public class AppServerPusher implements IPusher {/*** 热点key存储队列,用于缓冲待推送的热点key数据* 采用LinkedBlockingQueue实现生产-消费者模式*/private static LinkedBlockingQueue<HotKeyModel> hotKeyStoreQueue = new LinkedBlockingQueue<>();/*** 推送单个热点key到客户端* 实际是将key放入队列,由批量推送线程处理* @param model 热点key模型数据*/@Overridepublic void push(HotKeyModel model) {hotKeyStoreQueue.offer(model);}/*** 删除key操作(通过推送删除消息实现)* @param model 要删除的热点key模型*/@Overridepublic void remove(HotKeyModel model) {push(model); // 删除操作也通过推送机制实现}/*** 初始化批量推送任务* 使用@PostConstruct注解在Spring容器初始化后自动执行*/@PostConstructpublic void batchPushToClient() {AsyncPool.asyncDo(() -> {while (true) {try {List<HotKeyModel> tempModels = new ArrayList<>();// 每10毫秒批量获取一次数据,最多获取10条Queues.drain(hotKeyStoreQueue, tempModels, 10, 10, TimeUnit.MILLISECONDS);if (CollectionUtil.isEmpty(tempModels)) {continue; // 没有数据时继续等待}// 按应用名称对热点key进行分组Map<String, List<HotKeyModel>> allAppHotKeyModels = new HashMap<>();for (HotKeyModel hotKeyModel : tempModels) {List<HotKeyModel> oneAppModels = allAppHotKeyModels.computeIfAbsent(hotKeyModel.getAppName(), (key) -> new ArrayList<>());oneAppModels.add(hotKeyModel);}// 遍历所有已注册的应用,进行分组推送for (AppInfo appInfo : ClientInfoHolder.apps) {List<HotKeyModel> list = allAppHotKeyModels.get(appInfo.getAppName());if (CollectionUtil.isEmpty(list)) {continue; // 该应用没有待推送数据}// 构建热点key消息包HotKeyMsg hotKeyMsg = new HotKeyMsg(MessageType.RESPONSE_NEW_KEY);hotKeyMsg.setHotKeyModels(list);// 向该应用的所有客户端进行组播推送appInfo.groupPush(hotKeyMsg);}// 释放内存,帮助GCallAppHotKeyModels = null;} catch (Exception e) {e.printStackTrace(); // 异常处理,避免推送线程终止}}});}
}
_4.23 热点key消费者KeyConsumer
package com.jd.platform.hotkey.worker.keydispatcher;import com.jd.platform.hotkey.common.model.HotKeyModel;
import com.jd.platform.hotkey.worker.keylistener.IKeyListener;
import com.jd.platform.hotkey.worker.keylistener.KeyEventOriginal;import static com.jd.platform.hotkey.worker.keydispatcher.DispatcherConfig.QUEUE;
import static com.jd.platform.hotkey.worker.tool.InitConstant.totalDealCount;/*** 热点key消费者* 从队列中消费热点key事件并进行处理的核心消费者类*/
public class KeyConsumer {// 热点key事件监听处理器private IKeyListener iKeyListener;/*** 设置key事件监听器* @param iKeyListener 实现了IKeyListener接口的事件处理器*/public void setKeyListener(IKeyListener iKeyListener) {this.iKeyListener = iKeyListener;}/*** 开始消费热点key事件* 无限循环从队列中获取事件并进行处理*/public void beginConsume() { // 队列中的内容从哪来的呢?见4.24while (true) {try {// 从全局队列中阻塞获取热点key事件(队列为空时等待)HotKeyModel model = QUEUE.take();// 根据事件类型调用不同的处理方法if (model.isRemove()) {// 处理key删除事件iKeyListener.removeKey(model, KeyEventOriginal.CLIENT);} else {// 处理新key事件(热点检测)iKeyListener.newKey(model, KeyEventOriginal.CLIENT);}// 处理完成,增加总处理计数(用于监控和统计)totalDealCount.increment();} catch (InterruptedException e) {e.printStackTrace(); // 处理中断异常,保持消费循环继续运行}}}
}
_4.24 基于 Netty 的消息过滤处理器
-
下图
filter包下的五个类均属于com.jd.platform.hotkey.worker.netty.filter包,是基于 Netty 的消息过滤处理器,通过实现INettyMsgFilter接口形成责任链模式,按@Order注解定义的顺序(1→2→3→4)处理不同类型的HotKeyMsg消息;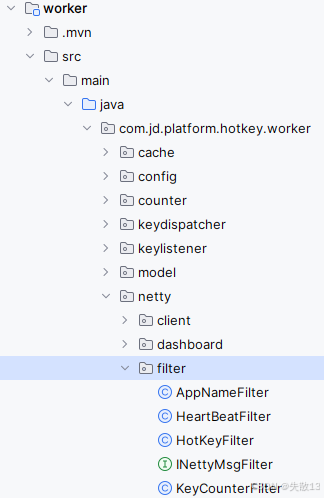
- INettyMsgFilter 接口:定义了消息过滤的核心方法
chain(HotKeyMsg message, ChannelHandlerContext ctx),所有过滤器需实现该接口。返回true表示消息继续传递给下一个过滤器,返回false表示消息被当前过滤器处理完毕,终止传递; - HeartBeatFilter(@Order(1)):处理心跳消息,优先级最高
- 当消息类型为
MessageType.PING时,立即返回PONG响应给客户端,确保连接存活; - 避免心跳消息进入后续业务过滤器,减轻处理负担;
- 当消息类型为
- AppNameFilter(@Order(2)):处理客户端上报的应用名称(
MessageType.APP_NAME)。接收客户端发送的appName,通过IClientChangeListener记录客户端信息(IP、上下文等),用于客户端管理和后续消息的应用隔离; - HotKeyFilter(@Order(3)):处理新热点 key 上报消息(
MessageType.REQUEST_NEW_KEY)- 对收到的
HotKeyModel列表进行过滤(忽略白名单 key),并检查消息超时(创建时间超过 1 秒时记录日志); - 将合法的 key 通过
KeyProducer推入队列(结合下方beginConsume方法,最终由iKeyListener.newKey处理热点检测); - 维护
totalReceiveKeyCount计数器,统计总接收量;
- 对收到的
- KeyCounterFilter(@Order(4)):处理 key 访问次数统计消息(
MessageType.REQUEST_HIT_COUNT)- 为消息补充
appName(若为空则使用workerPath),校验消息超时(超过阈值则忽略); - 将
KeyCountModel封装为KeyCountItem放入COUNTER_QUEUE延时队列,用于后续累计访问次数并发送统计结果;
- 为消息补充
- INettyMsgFilter 接口:定义了消息过滤的核心方法
-
4.23的beginConsume()方法是热点 key 事件的消费入口,与上述过滤器的关联如下:- 消息来源:
HotKeyFilter中通过keyProducer.push(model, now)推送的HotKeyModel最终会进入QUEUE,成为beginConsume方法的处理对象; - 业务流转:
- 客户端上报的新热点 key 经
HotKeyFilter过滤后入队,beginConsume循环取出并调用iKeyListener.newKey进行热点检测(如判断访问频率是否达到阈值); - 若为删除事件(
model.isRemove()),则调用iKeyListener.removeKey移除对应 key;
- 客户端上报的新热点 key 经
- 整体流程:过滤器负责消息的初步筛选、格式处理和入队,
beginConsume负责从队列中消费消息并执行核心业务逻辑(热点检测 / 删除),形成 “生产 - 消费” 模式,实现异步解耦。
- 消息来源:
4.25 CPU核数检测工具类CpuNum
package com.jd.platform.hotkey.worker.tool;/*** CPU核心数检测工具类* 用于智能检测Docker环境下的CPU核心数,解决老版本JDK在容器中的CPU识别问题*/
public class CpuNum {/*** 获取Netty worker线程的推荐数量(CPU密集型任务)* 根据JDK版本自动适配Docker环境下的CPU核心数识别问题* @return 优化的worker线程数量*/public static int workerCount() {// 获取JVM识别的CPU核心数int count = Runtime.getRuntime().availableProcessors();// 判断是否为新版JDK(正确支持Docker CPU限制的版本)if (isNewerVersion()) {return count; // 新版JDK直接返回实际分配的CPU核心数} else {// 老版JDK在Docker中会获取到宿主机的CPU数量,需要手动调整count = count / 2; // 折半处理作为保守策略if (count == 0) {count = 1; // 确保至少有一个线程}}return count;}/*** 测试方法:显示当前CPU核心数和版本检测结果*/public static void main(String[] args) {System.out.println(Runtime.getRuntime().availableProcessors());}/*** 检测是否为支持Docker CPU限制的新版JDK* 主要针对JDK 1.8.0_191及以上版本* @return true-新版JDK,false-老版JDK*/private static boolean isNewerVersion() {try {// 获取Java版本字符串,格式如:1.8.0_20, 1.8.0_181, 1.8.0_191-b12String javaVersion = System.getProperty("java.version");// 提取前5位版本号(1.8.0)String topThree = javaVersion.substring(0, 5);// 版本比较逻辑if (topThree.compareTo("1.8.0") > 0) {return true; // 高于1.8.0的版本(如9+、11+等)都支持} else if (topThree.compareTo("1.8.0") < 0) {return false; // 低于1.8.0的版本都不支持} else {// 1.8.0版本,需要检查小版本号// 提取小版本号(去掉"1.8.0_"前缀)String smallVersion = javaVersion.replace("1.8.0_", "");// 处理带后缀的版本号(如191-b12)if (smallVersion.contains("-")) {smallVersion = smallVersion.substring(0, smallVersion.indexOf("-"));}// 191及以上版本支持Docker CPU限制return Integer.valueOf(smallVersion) >= 191;}} catch (Exception e) {// 异常情况下保守返回falsereturn false;}}
}