面向对象数据分析实战编程题:销售数据统计与可视化(Python)
学习视频来源:https://www.bilibili.com/video/BV1qW4y1a7fU?t=1.1&p=124
所需文本文件:
1.面向对象数据分析实战编程题:销售数据统计与可视化(Python)所需文本文件-1资源-CSDN下载
2.面向对象数据分析实战编程题:销售数据统计与可视化(Python)所需文本文件-2资源-CSDN下载
一、题目描述
某电商平台存储了 2011 年 1-2 月的销售数据,其中 1 月数据以文本文件(.txt) 格式存储,每条数据按 “日期,订单 ID, 订单金额,销售省份” 格式分行排列;2 月数据以JSON 文件(.txt) 格式存储,每条数据为一个 JSON 对象(含 date、order_id、money、province 字段)。
请基于面向对象思想,完成以下需求:
- 设计数据封装类,实现对单条销售数据的结构化存储;
- 设计文件读取框架,支持同时读取文本格式和 JSON 格式的销售数据文件,并将每条数据转换为结构化数据对象;
- 读取 1 月和 2 月的销售数据文件,合并所有数据后,统计每日销售额(按日期聚合,计算当日所有订单金额总和);
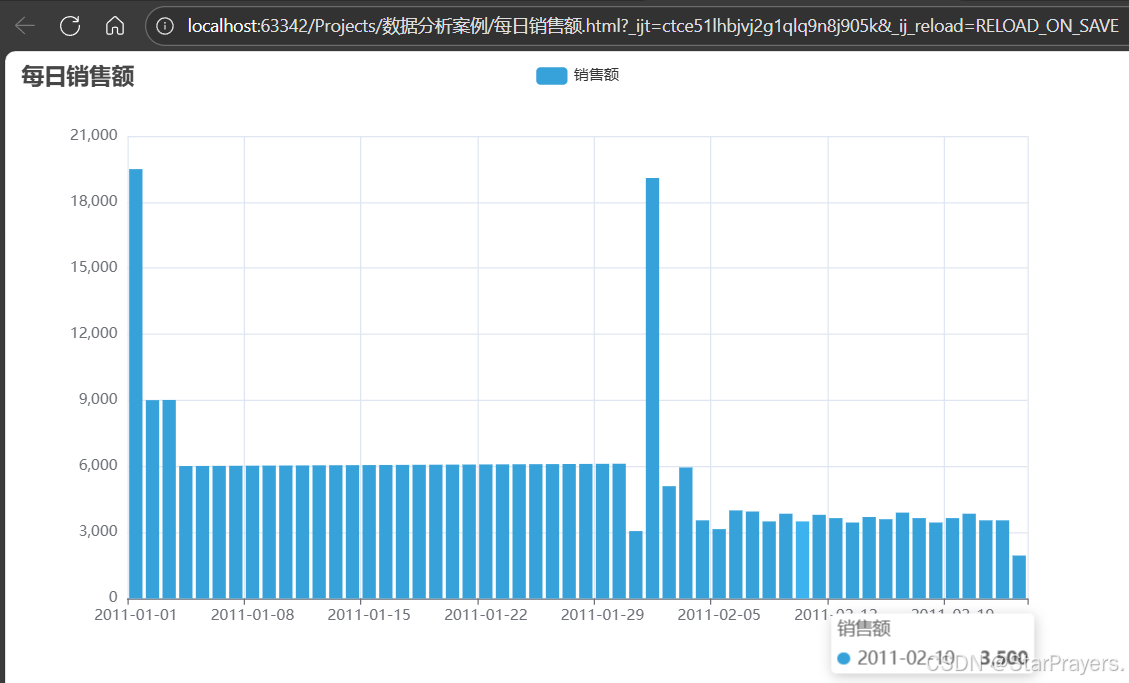
- 使用 PyEcharts 绘制 “每日销售额” 柱状图,生成可在浏览器中打开的 HTML 可视化文件,要求图表含标题、清晰的 X 轴(日期)和 Y 轴(销售额)标识。
二、已知条件
- 数据文件路径(可自行模拟数据):
- 1 月销售数据:
2011年1月销售数据.txt - 2 月销售数据:
2011年2月销售数据.txt
- 1 月销售数据:
- 文本文件数据示例(每行):
2011-01-01,4b34218c-9f37-4e66-b33e-327ecd5fb897,1689,湖南省
2011-01-01,5b6a6417-9a16-4243-9704-255719074bff,2353,河北省3.JSON 文件数据示例(每行一个 JSON):
{"date": "2011-02-01", "order_id": "caf99222-53d6-427b-925d-3187fc71a86a", "money": 1805, "province": "江西省"}
{"date": "2011-02-01", "order_id": "3dea6f83-a9b2-4197-ba9f-2b25704c530b", "money": 2547, "province": "广东省"} 4.需使用的第三方库:pyecharts(用于可视化),可通过pip install pyecharts安装。
三、实现思路
1. 数据封装设计(Record 类)
首先定义了Record类用于封装每条销售数据:
class Record:def __init__(self,date,order_id,money,province):self.date = date # 订单日期self.order_id = order_id # 订单IDself.money = money # 订单金额self.province = province # 销售省份- 这是典型的 "数据载体" 设计,将分散的数据字段整合到一个对象中
- 重写
__str__方法便于数据打印和调试 - 每个 Record 对象代表一条完整的销售记录
2. 文件读取框架设计(抽象类 + 子类)
采用了 "模板方法模式" 设计文件读取功能:
-
抽象类 FileReader:定义统一接口
class FileReader:def read_data(self) -> list[Record]:"""读取文件的数据,转换为Record对象列表返回"""pass只定义接口不实现,确保所有子类遵循相同的使用方式
- 子类 TextFileReader:处理文本文件
class TextFileReader(FileReader):def read_data(self) -> list[Record]:# 读取文本文件,按逗号分割数据# 转换为Record对象并返回列表- 子类 JsonFileReader:处理 JSON 文件
class JsonFileReader(FileReader):def read_data(self) -> list[Record]:# 读取JSON文件,解析为字典# 转换为Record对象并返回列表这种设计的优势:
- 统一接口:无论读取什么格式的文件,都用
read_data()方法 - 易于扩展:如果需要支持 Excel,只需新增
ExcelFileReader子类 - 隔离变化:不同文件格式的解析逻辑相互独立
3. 数据读取与合并
# 实例化不同的读取器
text_file_reader = TextFileReader("2011年1月销售数据.txt")
json_file_reader = JsonFileReader("2011年2月销售数据.txt")# 读取数据(返回Record对象列表)
jan_data:list[Record] = text_file_reader.read_data()
feb_data:list[Record] = json_file_reader.read_data()# 合并两个月数据
all_data:list[Record] = jan_data + feb_data- 利用多态特性,用相同方式处理不同格式的文件
- 类型注解提高代码可读性和安全性
- 数据合并为统一列表,便于后续处理
4. 业务逻辑计算(每日销售额统计)
# 初始化字典存储每日销售额
data_dict = {}
for record in all_data:if record.date in data_dict.keys():# 日期已存在则累加金额data_dict[record.date] += record.moneyelse:# 新日期则创建记录data_dict[record.date] = record.money- 采用字典进行聚合计算,键为日期,值为销售额
- 一次遍历完成所有数据的统计,时间复杂度为 O (n)
- 逻辑清晰:判断日期是否存在,存在则累加,否则新增
5. 数据可视化(PyEcharts 绘图)
# 创建柱状图
bar = Bar(init_opts=InitOpts(theme=ThemeType.LIGHT))
bar.add_xaxis(list(data_dict.keys())) # X轴为日期
bar.add_yaxis("销售额",list(data_dict.values())) # Y轴为销售额
bar.set_global_opts(title_opts=TitleOpts(title="每日销售额"))
bar.render("每日销售额.html") # 生成HTML文件- 调用 PyEcharts 的 Bar 组件绘制柱状图
- 将字典的键(日期)作为 X 轴数据,值(销售额)作为 Y 轴数据
- 生成独立 HTML 文件,可直接在浏览器查看
四、完整代码
data_define.py
""""
数据定义的类
"""class Record:def __init__(self,date,order_id,money,province):self.date = date # 订单日期self.order_id = order_id # 订单IDself.money = money # 订单金额self.province = province # 销售省份def __str__(self):return f"{self.date}, {self.order_id}, {self.money}, {self.province}"
file_define.py
"""
和文件相关的类定义
"""
import json# from pandas.io.parsers import TextFileReaderfrom data_define import Record
#先定义一个抽象类用来做顶层设计,确定有哪些功能需要实现
class FileReader:def read_data(self) -> list[Record]:"""读取文件的数据,读到的每一条数据都转换为Record对象,将他们都封装到list内返回即可"""passclass TextFileReader(FileReader):def __init__(self,path) :self.path = path #定义成员变量记录文件的路径#复写(实现抽象方法)父类的方法def read_data(self) -> list[Record]:f = open(self.path,'r',encoding='UTF-8')record_list : list[Record] = []for line in f.readlines():line = line.strip() #消除读取到的每一行数据中的\ndata_list = line.split(",")record = Record(data_list[0],data_list[1],int(data_list[2]),data_list[3])record_list.append(record)f.close()return record_listclass JsonFileReader(FileReader):def __init__(self,path) :self.path = path #定义成员变量记录文件的路径def read_data(self) -> list[Record]:f = open(self.path, 'r', encoding='UTF-8')record_list: list[Record] = []for line in f.readlines():data_dict = json.loads(line)record = Record(data_dict["date"],data_dict["order_id"],int(data_dict["money"]),data_dict["province"])record_list.append(record)f.close()return record_listif __name__ == '__main__':text_file_reader = TextFileReader("D:/2011年1月销售数据.txt")json_file_reader = JsonFileReader("D:/2011年2月销售数据.txt")list1 = text_file_reader.read_data()list2 = json_file_reader.read_data()for l in list1:print(l)for l in list2:print(l)main.py
"""
面向对象,数据分析案例,主业务逻辑代码
实现步骤:
1、设计一个类,可以完成数据的封装
2、设计一个抽象类,定义文件读取的相关功能,并使用子类实现具体功能
3、读取文件,生产数据对象
4、进行数据需求的逻辑计算(计算每一天的销售额)
5、通过PyEcharts进行图形绘制
"""from file_define import FileReader,TextFileReader,JsonFileReader
from data_define import Record
from pyecharts.charts import Bar
from pyecharts.options import *
from pyecharts.globals import ThemeTypetext_file_reader = TextFileReader("D:/2011年1月销售数据.txt")
json_file_reader = JsonFileReader("D:/2011年2月销售数据.txt")jan_data:list[Record] = text_file_reader.read_data()
feb_data:list[Record] = json_file_reader.read_data()
#将两个月份的数据合并成1个list来存储
all_data:list[Record] = jan_data + feb_data#开始进行数据计算
#{“2011-01-01”:1234}
data_dict = {}
for record in all_data:if record.date in data_dict.keys():#当前日期已经有记录了,所以和老记录做累加data_dict[record.date] += record.moneyelse:data_dict[record.date] = record.moneyprint(data_dict)#可视化图标开发
bar = Bar(init_opts=InitOpts(theme=ThemeType.LIGHT))
bar.add_xaxis(list(data_dict.keys())) #添加X轴的数据
bar.add_yaxis("销售额",list(data_dict.values()),label_opts=LabelOpts(is_show=False)) #添加Y轴的数据
bar.set_global_opts(title_opts=TitleOpts(title="每日销售额")
)
bar.render("每日销售额.html")五、实现效果图