中断系统介绍
1.中断执行流程
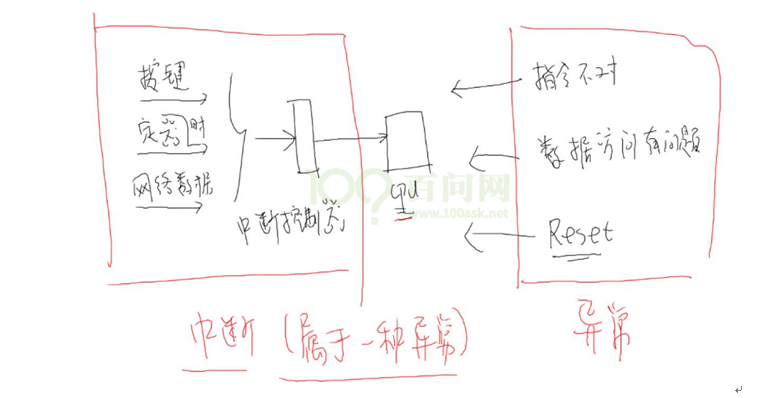
2.中断处理流程
arm对异常(中断)处理过程:
① 初始化:
a. 设置中断源,让它可以产生中断
b. 设置中断控制器(可以屏蔽某个中断,优先级)
c. 设置CPU总开关(使能中断)
② 执行其他程序:正常程序
③ 产生中断:比如按下按键--->中断控制器--->CPU
④ CPU 每执行完一条指令都会检查有无中断/异常产生
⑤ CPU发现有中断/异常产生,开始处理。
对于不同的异常,跳去不同的地址执行程序。
这地址上,只是一条跳转指令,跳去执行某个函数(地址),这个就是异常向量。
③④⑤都是硬件做的。
⑥ 这些函数做什么事情?
软件做的:
a. 保存现场(各种寄存器)
b. 处理异常(中断):
分辨中断源,再调用不同的处理函数
c. 恢复现场
3.Linux对中断的处理
1 进程、线程、中断的核心:栈
中断中断,中断谁?
中断当前正在运行的进程、线程。
进程、线程是什么?内核如何切换进程、线程、中断?
要理解这些概念,必须理解栈的作用。
1.1 ARM处理器程序运行的过程
ARM芯片属于精简指令集计算机(RISC:Reduced Instruction Set Computing),它所用的指令比较简单,有如下特点:
① 对内存只有读、写指令
② 对于数据的运算是在CPU内部实现
③ 使用RISC指令的CPU复杂度小一点,易于设计
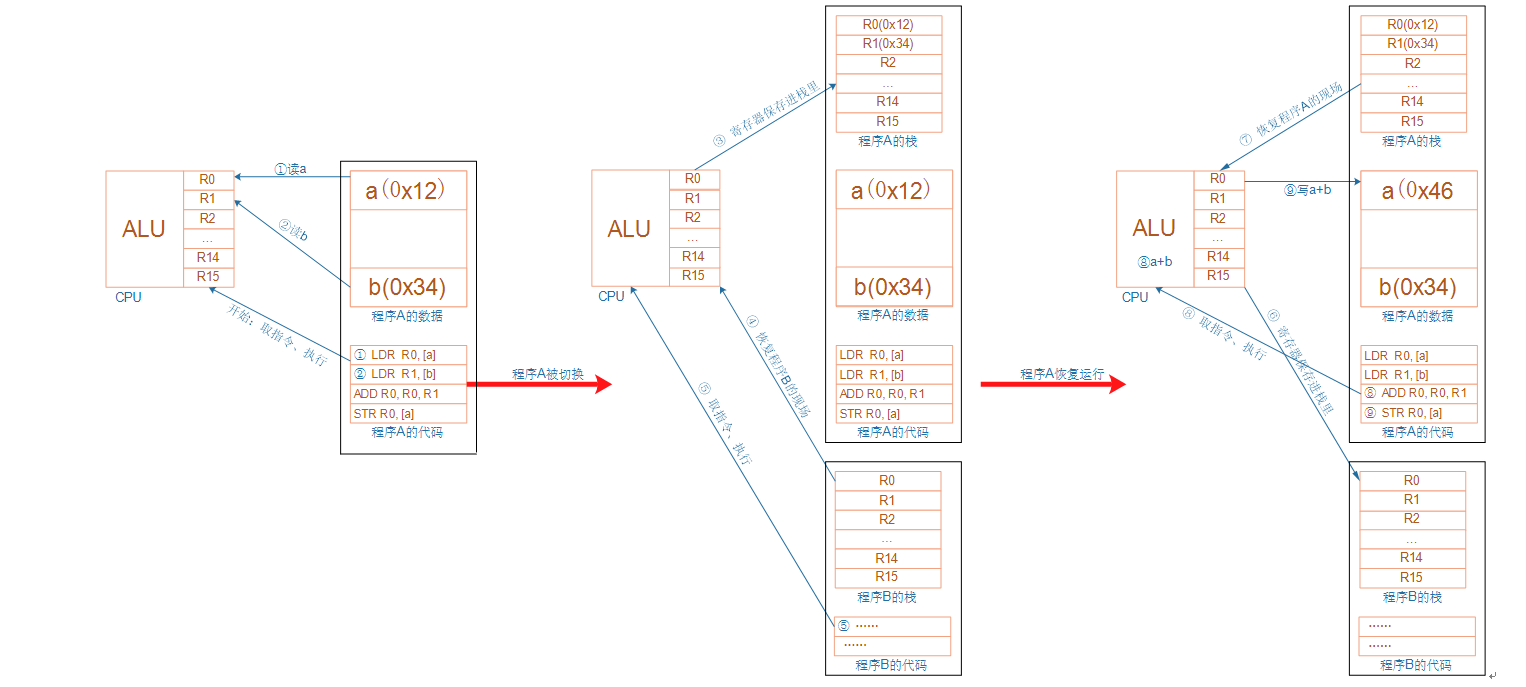
比如CPU计算a+b:CPU运行时,先去取得指令,再执行指令:
① 把内存a的值读入CPU寄存器R0
② 把内存b的值读入CPU寄存器R1
③ 把R0、R1累加,存入R0
④ 把R0的值写入内存a
1.2 程序被中断时,怎么保存现场
CPU内部的寄存器很重要,如果要暂停一个程序,中断一个程序,就需要把这些寄存器的值保存下来:这就称为保存现场。
保存在哪里?内存,这块内存就称之为栈。
程序要继续执行,就先从栈中恢复那些CPU内部寄存器的值。
这个场景并不局限于中断,下图可以概括程序A、B的切换过程,其他情况是类似的:
在函数A里调用函数B,实际就是中断函数A的执行。
那么需要把函数A调用B之前瞬间的CPU寄存器的值,保存到栈里;
再去执行函数B;
函数B返回之后,就从栈中恢复函数A对应的CPU寄存器值,继续执行。
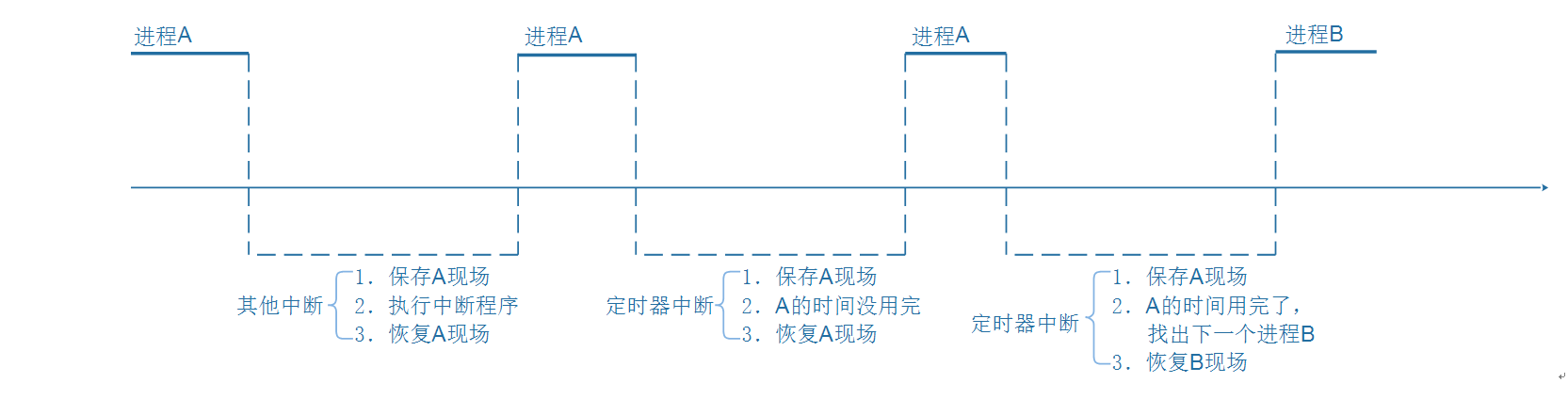
b. 中断处理
进程A正在执行,这时候发生了中断。
CPU强制跳到中断异常向量地址去执行,
这时就需要保存进程A被中断瞬间的CPU寄存器值,
可以保存在进程A的内核态栈,也可以保存在进程A的内核结构体中。
中断处理完毕,要继续运行进程A之前,恢复这些值。
c. 进程切换
在所谓的多任务操作系统中,我们以为多个程序是同时运行的。
如果我们能感知微秒、纳秒级的事件,可以发现操作系统时让这些程序依次执行一小段时间,进程A的时间用完了,就切换到进程B。
怎么切换?
切换过程是发生在内核态里的,跟中断的处理类似。
进程A的被切换瞬间的CPU寄存器值保存在某个地方;
恢复进程B之前保存的CPU寄存器值,这样就可以运行进程B了。
所以,在中断处理的过程中,伴存着进程的保存现场、恢复现场。
进程的调度也是使用栈来保存、恢复现场:
2 Linux系统对中断处理的演进
Linux系统中有硬件中断,也有软件中断。
对硬件中断的处理有2个原则:不能嵌套,越快越好。
2.1 Linux对中断的扩展:硬件中断、软件中断
Linux系统把中断的意义扩展了,对于按键中断等硬件产生的中断,称之为“硬件中断”(hard irq)。每个硬件中断都有对应的处理函数,比如按键中断、网卡中断的处理函数肯定不一样。
为方便理解,你可以先认为对硬件中断的处理是用数组来实现的,数组里存放的是函数指针:

相对的,还可以人为地制造中断:软件中断(soft irq),如下图所示:
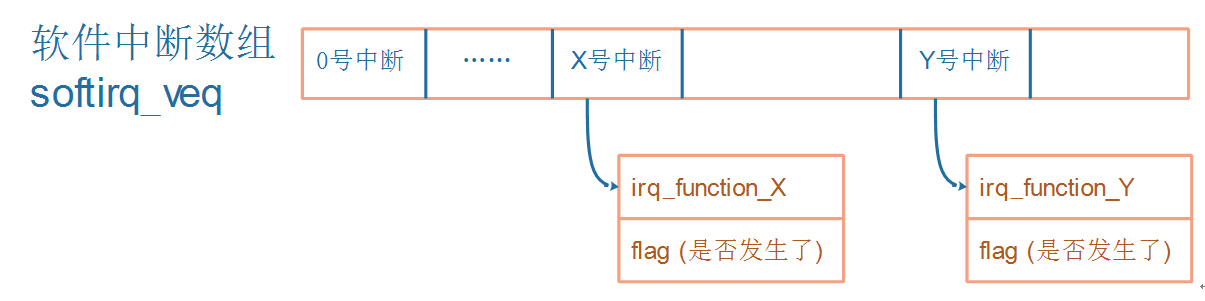
a. 软件中断何时生产?
由软件决定,对于X号软件中断,只需要把它的flag设置为1就表示发生了该中断。
b. 软件中断何时处理?
软件中断嘛,并不是那么十万火急,有空再处理它好了。
什么时候有空?不能让它一直等吧?
Linux系统中,各种硬件中断频繁发生,至少定时器中断每10ms发生一次,那取个巧?
在处理完硬件中断后,再去处理软件中断?就这么办!
2.2 要处理的事情实在太多,拆分为:上半部、下半部
一个中断要耗费很多时间来处理时,它的坏处是:在这段时间内,其他中断无法被处理。换句话说,在这段时间内,系统是关中断的。
如果某个中断就是要做那么多事,我们能不能把它拆分成两部分:紧急的、不紧急的?
在handler函数里只做紧急的事,然后就重新开中断,让系统得以正常运行;那些不紧急的事,以后再处理,处理时是开中断的。
中断下半部的实现有很多种方法,讲2种主要的:tasklet(小任务)、work queue(工作队列)。
2.3 下半部要做的事情耗时不是太长:tasklet
假设我们把中断分为上半部、下半部。发生中断时,上半部下半部的代码何时、如何被调用?
当下半部比较耗时但是能忍受,并且它的处理比较简单时,可以用tasklet来处理下半部。tasklet是使用软件中断来实现。
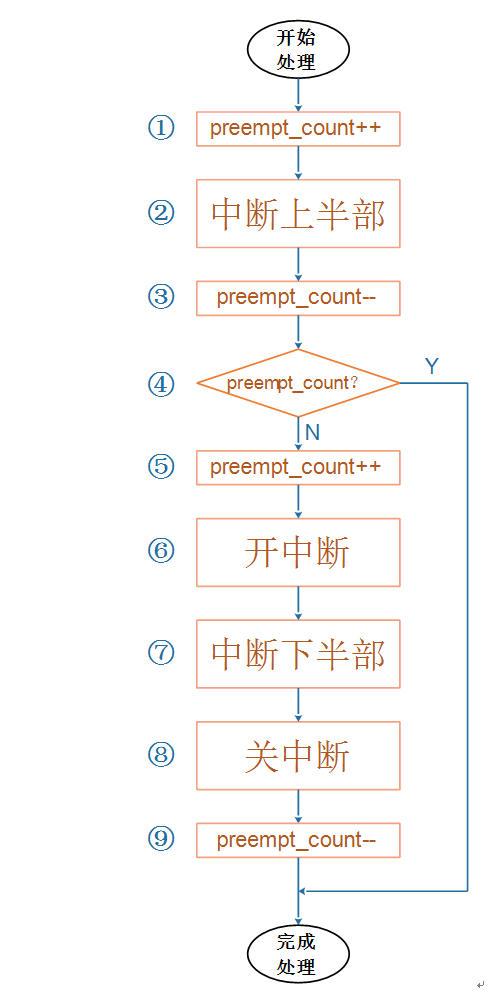
假设硬件中断A的上半部函数为irq_top_half_A,下半部为irq_bottom_half_A。
使用情景化的分析,才能理解上述代码的精华。
a. 硬件中断A处理过程中,没有其他中断发生:
一开始,preempt_count = 0;
上述流程图①~⑨依次执行,上半部、下半部的代码各执行一次。
b. 硬件中断A处理过程中,又再次发生了中断A:
一开始,preempt_count = 0;
执行到第⑥时,一开中断后,中断A又再次使得CPU跳到中断向量表。
注意:这时preempt_count等于1,并且中断下半部的代码并未执行。
CPU又从①开始再次执行中断A的上半部代码:
在第①步preempt_count等于2;
在第③步preempt_count等于1;
在第④步发现preempt_count等于1,所以直接结束当前第2次中断的处理;
注意:重点来了,第2次中断发生后,打断了第一次中断的第⑦步处理。当第2次中断处理完毕,CPU会继续去执行第⑦步。
可以看到,发生2次硬件中断A时,它的上半部代码执行了2次,但是下半部代码只执行了一次。
所以,同一个中断的上半部、下半部,在执行时是多对一的关系。
c. 硬件中断A处理过程中,又再次发生了中断B:
一开始,preempt_count = 0;
执行到第⑥时,一开中断后,中断B又再次使得CPU跳到中断向量表。
注意:这时preempt_count等于1,并且中断A下半部的代码并未执行。
CPU又从①开始再次执行中断B的上半部代码:
在第①步preempt_count等于2;
在第③步preempt_count等于1;
在第④步发现preempt_count等于1,所以直接结束当前第2次中断的处理;
注意:重点来了,第2次中断发生后,打断了第一次中断A的第⑦步处理。当第2次中断B处理完毕,CPU会继续去执行第⑦步。
在第⑦步里,它会去执行中断A的下半部,也会去执行中断B的下半部。
所以,多个中断的下半部,是汇集在一起处理的。
总结:
a. 中断的处理可以分为上半部,下半部
b. 中断上半部,用来处理紧急的事,它是在关中断的状态下执行的
c. 中断下半部,用来处理耗时的、不那么紧急的事,它是在开中断的状态下执行的
d. 中断下半部执行时,有可能会被多次打断,有可能会再次发生同一个中断
e. 中断上半部执行完后,触发中断下半部的处理
f. 中断上半部、下半部的执行过程中,不能休眠:中断休眠的话,以后谁来调度进程啊?
2.4 下半部要做的事情太多并且很复杂:工作队列
在中断下半部的执行过程中,虽然是开中断的,期间可以处理各类中断。但是毕竟整个中断的处理还没走完,这期间APP是无法执行的。
假设下半部要执行1、2分钟,在这1、2分钟里APP都是无法响应的。
这谁受得了?
所以,如果中断要做的事情实在太耗时,那就不能用软件中断来做,而应该用内核线程来做:在中断上半部唤醒内核线程。内核线程和APP都一样竞争执行,APP有机会执行,系统不会卡顿。
这个内核线程是系统帮我们创建的,一般是kworker线程,内核中有很多这样的线程:
kworker线程要去“工作队列”(work queue)上取出一个一个“工作”(work),来执行它里面的函数。
总结:
a. 很耗时的中断处理,应该放到线程里去
b. 可以使用work、work queue
c. 在中断上半部调用schedule_work函数,触发work的处理
d. 既然是在线程中运行,那对应的函数可以休眠。